董晃|菜鸟 AI 平台数据技术专家
导读
作为 DataWorks Data Agent 的首批深度共创用户,菜鸟集团结合物流行业十余年数仓建设经验,自主研发 SuperETL 智能体系统 。通过精细化 Skill 编排、Hooks 生产级安全阻断与结构化知识沉淀,将数据研发效率提升 2-3倍,部分核心场景AI自动完成率超80%,成功实现从"工具辅助"到"智能体主导"的范式跃迁。
研发现状与核心痛点:为什么传统链路难以为继?
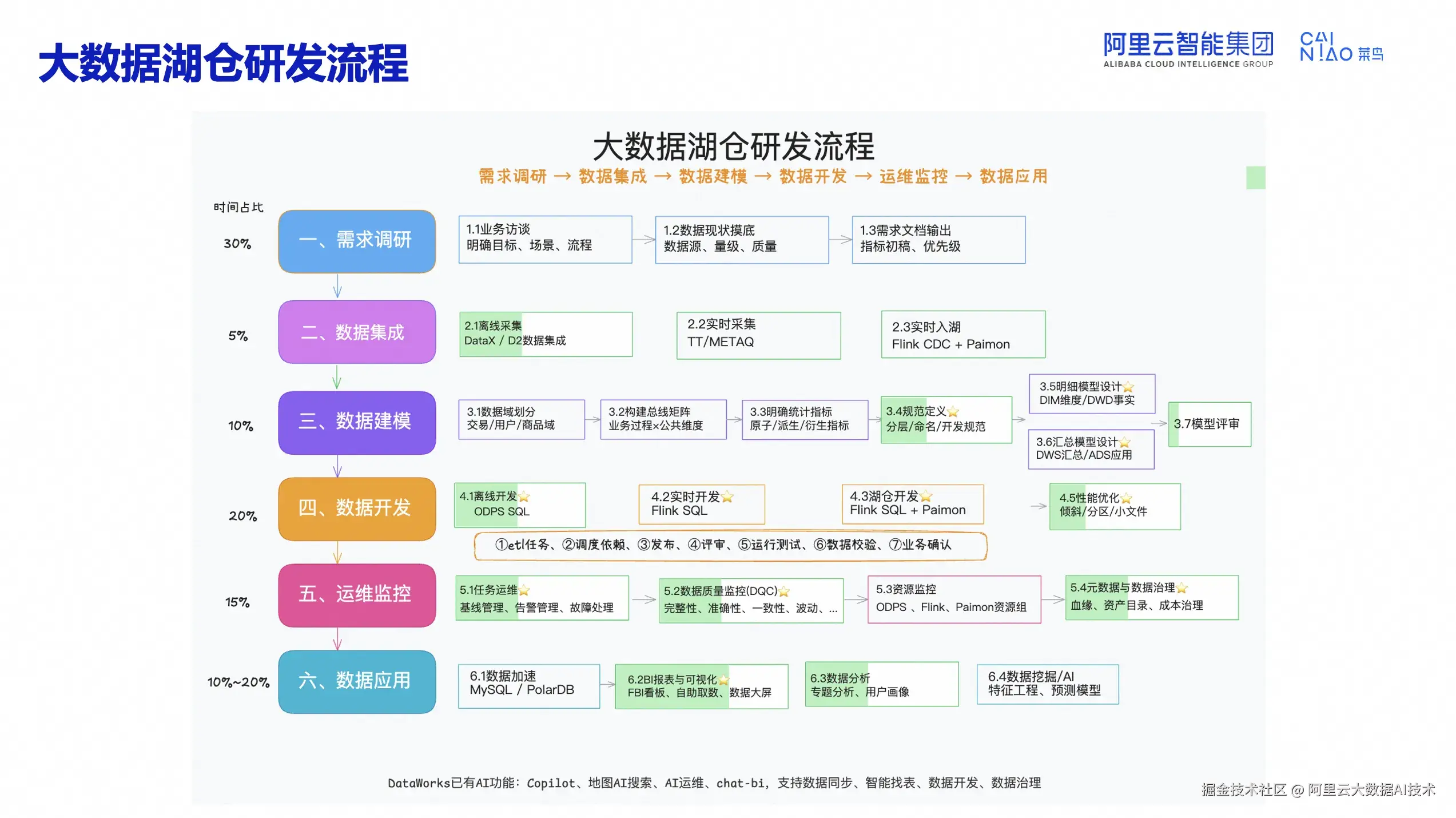
菜鸟的数据研发流程与多数企业类似,从需求到交付可分为6个阶段,精力分布呈 3:5:2(30%需求调研 / 50%同步+建模+开发运维 / 20%数据应用)。链路横跨Aone 需求管理、DataWorks 离线开发、Flink 实时计算、Paimon 湖仓及 FBI 报表等多平台。
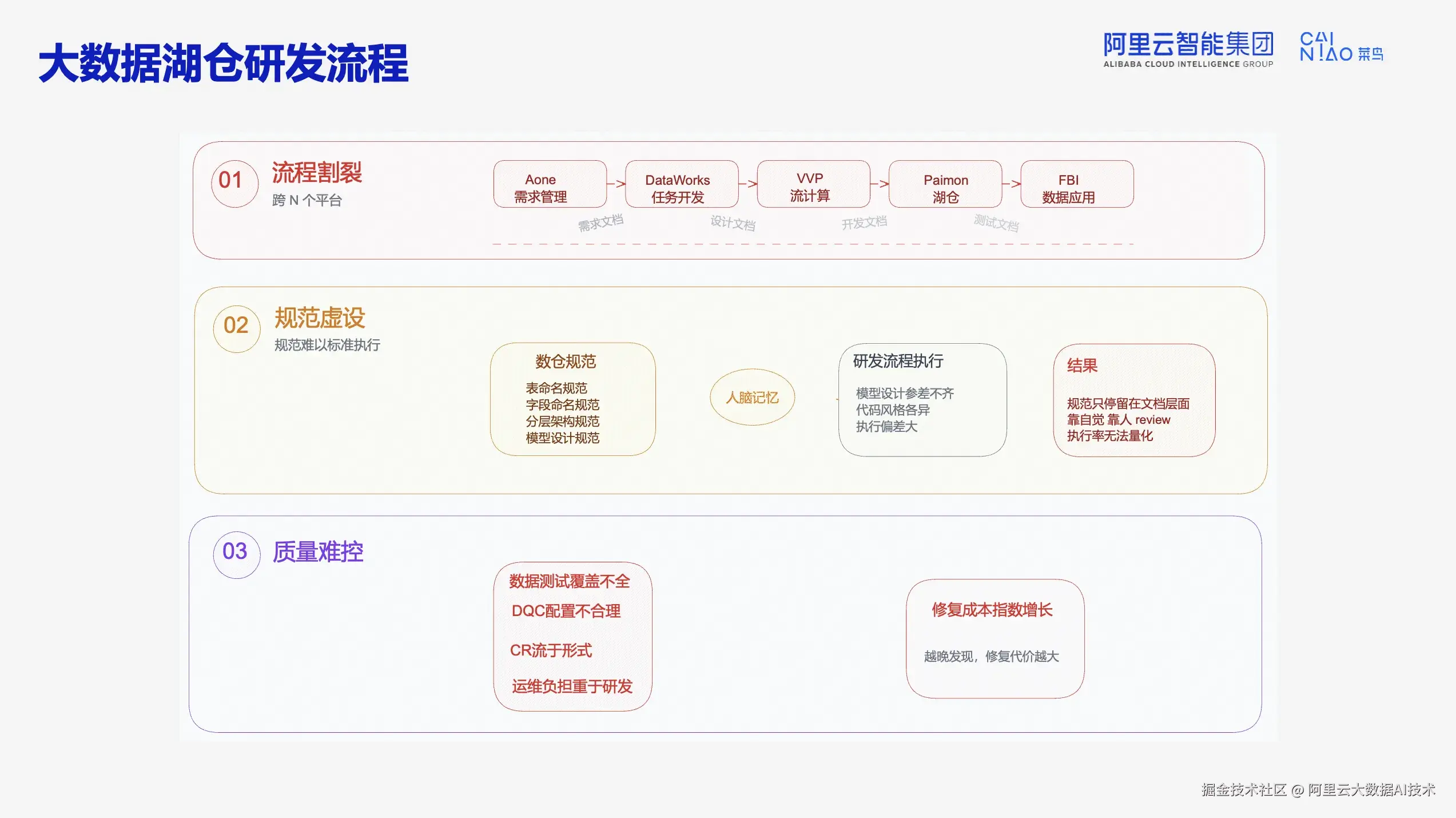
系统性复盘后,团队发现三大瓶颈:
流程割裂: 多引擎架构导致链路被拆散。从需求管理(Aone)→任务开发(DataWorks)→流计算(VVP)→湖仓(Paimon)→数据应用(FBI),协同成本高昂。
规范虚设: 物流领域沉淀的表命名、字段标准、分层架构等规范,因人员流动和缺乏执行机制,往往只停留在文档层面,实际执行率无法量化。
质量难控: 数据测试覆盖不全、DQC 配置不合理、代码评审流于形式,导致运维负担重于研发。模型一旦发布,下游可能存在十层依赖、数百个任务,修复成本呈指数级增长。
破局思路:结合DataWorks Data Agent 构建SuperETL智能体系统
DataWorks Data Agent:不只是写 SQL,而是懂业务的智能体 DataWorks Data Agent 覆盖数据集成、开发、运维、治理、分析全链路,能够用自然语言完成复杂的数据开发任务,为用户提供高效可信的智能化数据开发体验。可以深度适配用户的业务 ,成为真正懂行的"AI同事"。 
基于 DataWorks Data Agent 底座,菜鸟构建了 SuperETL 智能体系统。 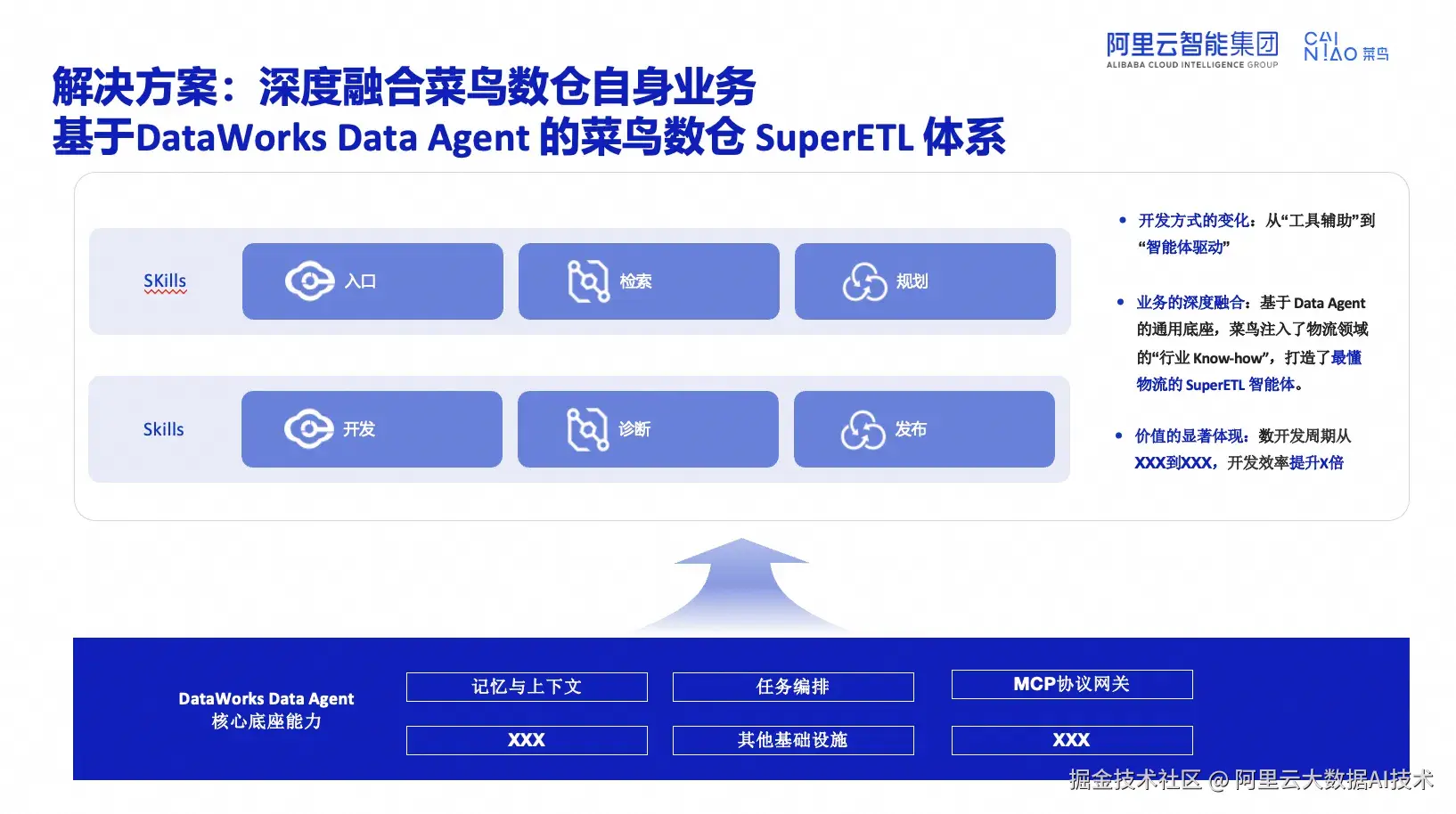
实现三个核心转变:
开发方式转变: 从"工具辅助"到"智能体驱动",AI成为研发流程主导者,人类专家负责规则制定和质量把关。
业务深度融合: 注入物流领域的"行业 Know-how",包括数仓规范、表命名标准、指标口径定义等,通过结构化方式沉淀为 AI 可执行的 Skills。
价值显著体现: 部分场景开发效率提升2-3倍,特别是采购领域的数据建设,AI能自动完成大部分工作。
DataWorks Data Agent 提供完整底座能力:
-
交互层:CLI / IDE / IM / OpenAPI 多入口统一负载
-
资源层:Serverless Resource Group 实现弹性伸缩
-
执行层: CodeAgent Sandbox 代码沙箱 + Claw 运维服务 + MCP/Skill Runtime 工具执行
→ 实现 免运维、可弹性、强隔离 的企业级全托管体系

SuperETL核心架构:九大精细化Skill编排体系
SuperETL 本质上是一个集成了菜鸟物流行业经验的中间层研发 Skill 编排体系。 
设计理念: 为什么不将全链路打包进一个Skill ?
数据规范、Checklist、运维经验构成的上下文极其庞大。若单点塞入,大模型难以精确控制每一步操作。SuperETL 参考开源 Superpower 模式,针对数据研发场景重构为9个独立 Skill+ 铁律约束 ,实现"意图路由→分步执行→安全拦截"。 
九大技能体系的精细编排:
-
using-superetl(元技能):入口路由器,负责意图识别,禁止直跳子技能。
-
etl-deepresearch(检索):先搜后答,将行业经验沉淀为MD文档检索。铁律:先搜索后回答,禁止先问用户。
-
etl-debugging(诊断):处理数据问题。铁律:无数据证据前绝不提修复方案。
-
etl-brainstorming(需求沟通):压制AI幻觉。铁律:设计未确认前禁止发布。
-
etl-writing-plans(计划编写):输出MD格式实施计划。铁律:计划确认前禁止写SQL。
-
etl-validated-coding(验证式开发):边探查边编写,包含单元测试。铁律:没有验证证据的SQL禁止发布。
-
etl-review-and-release(评审与发布):人工与AI审查结合。铁律:未通过检查项禁止发布,没有例外。
-
etl-dispatch-parallel(并行分派):处理独立任务。铁律:有依赖时禁止并行。
-
etl-subagent-driven(子代理驱动):独立子代理加两阶段审查。
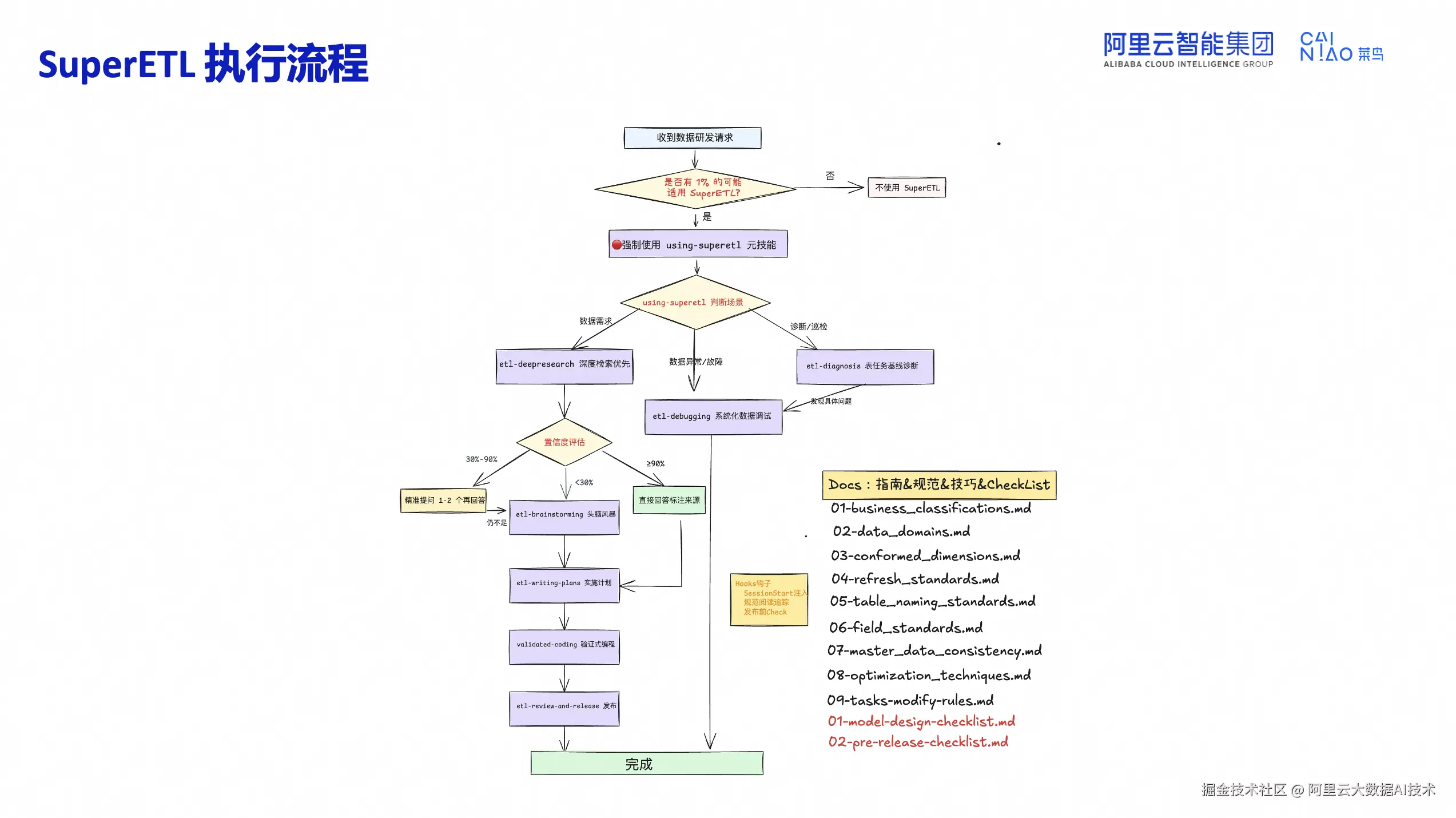
执行流程从需求接入开始,强制注入 using-superetl 元技能进行场景判断。数据需求走 etl-deepresearch 深度检索;诊断巡检走 etl-diagnosis;数据异常走 etl-debugging。deepresearch 进行置信度评估:30%-90%精准提问1-2个问题,低于30%进入头脑风暴,90%以上直接回答。随后依次经过计划编写、验证式编程、评审发布。
六大知识资源库:
| 目录 | 内容示例 | 作用 |
|---|---|---|
| spec/ | 数仓架构、表设计、字段标准 | 提供AI检索的权威依据 |
| checklists/ | 模型设计Checklist、发布前Checklist | 强制质量卡点 |
| templates/ | DDL模板、ETL SQL模板 | 保障代码风格统一 |
| guides/ | 离线建模理论、Medallion架构 | 补充领域知识 |
| techniques/ | SQL优化、运维排障经验 | 沉淀实战Know-how |
| wiki/ | 原始业务文档、实体关系 | 构建知识图谱基座 |

Hooks 机制:生产安全的核心保障 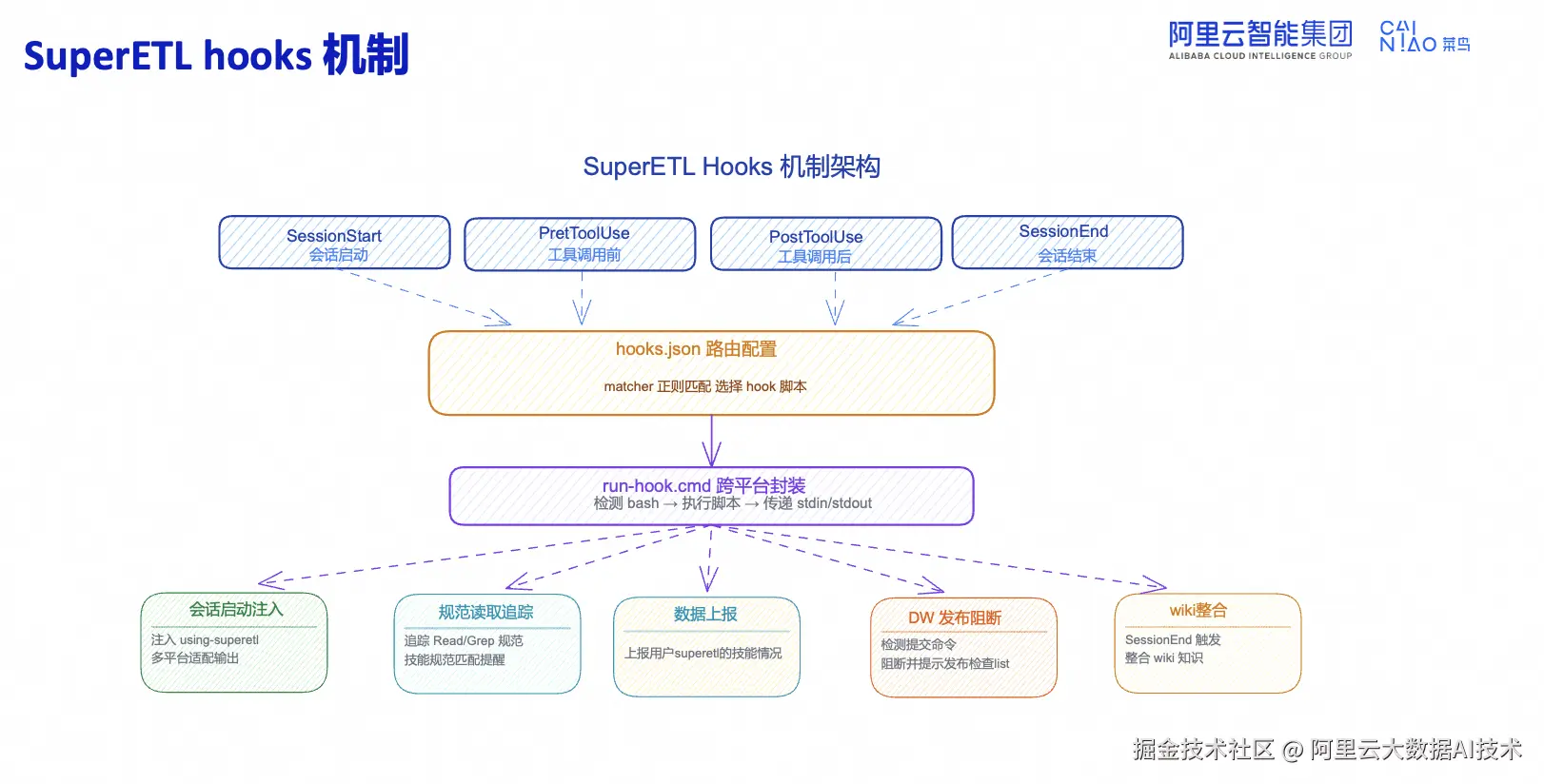 Hooks 机制定义四个触发时机:SessionStart(会话启动)、PreToolUse(工具调用前)、PostToolUse(工具调用后)、SessionEnd(会话结束)。通过 hooks.json 路由配置,使用 matcher 正则匹配选择 hook 脚本,由 run-hook.cmd 执行。
Hooks 机制定义四个触发时机:SessionStart(会话启动)、PreToolUse(工具调用前)、PostToolUse(工具调用后)、SessionEnd(会话结束)。通过 hooks.json 路由配置,使用 matcher 正则匹配选择 hook 脚本,由 run-hook.cmd 执行。
-
典型能力场景: 会话启动注入 using-superetl、规范读取追踪、数据上报、DataWorks发布阻断、wiki 整合。
-
发布阻断机制: 检测到写操作/发布命令时,Hook 拦截并提示:"检测到发布/写操作,必须先完成发布前检查清单。" 仅当逐项验证通过、命令前携带 CHECKLIST_VERIFIED=1 前缀时才放行。彻底杜绝"带病上线"。
CLI 工具与未来研发范式
为支撑SuperETL,菜鸟构建了cn-odpscmd统一CLI工具,覆盖ODPS/DataWorks/元数据/FBI报表等能力。工具严格区分开发环境(带_dev后缀)和生产环境,所有SQL查询必须在开发环境执行。 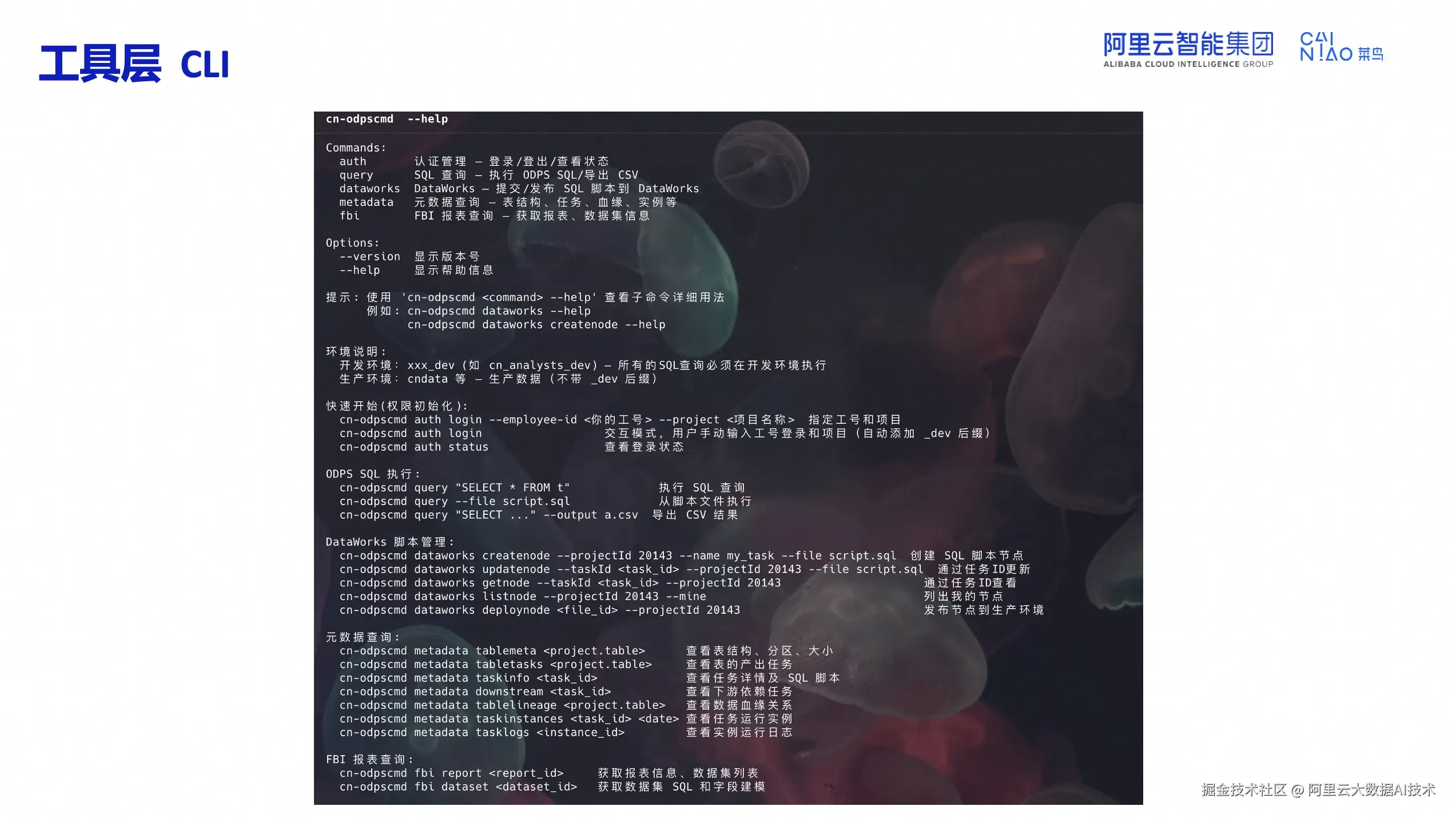
核心能力包括:权限初始化与登录、SQL 查询执行(query 执行 SQL,query --file 从脚本执行,query --output 导出 CSV)、DataWorks 脚本管理(createnode 创建、updatenode 更新、deploynode 发布)、元数据查询(tablemeta 查表结构、tablelineage 查血缘、tasklogs 查日志)、FBI 报表查询、项目空间权限查询。
实战推演:物流单量汇总表新增字段
以一个典型场景为例:为物流单量汇总表 dws_lgt_order_1d 新增"签收及时率"字段。整个流程分为六个步骤,完整展示了 SuperETL 的实战应用: 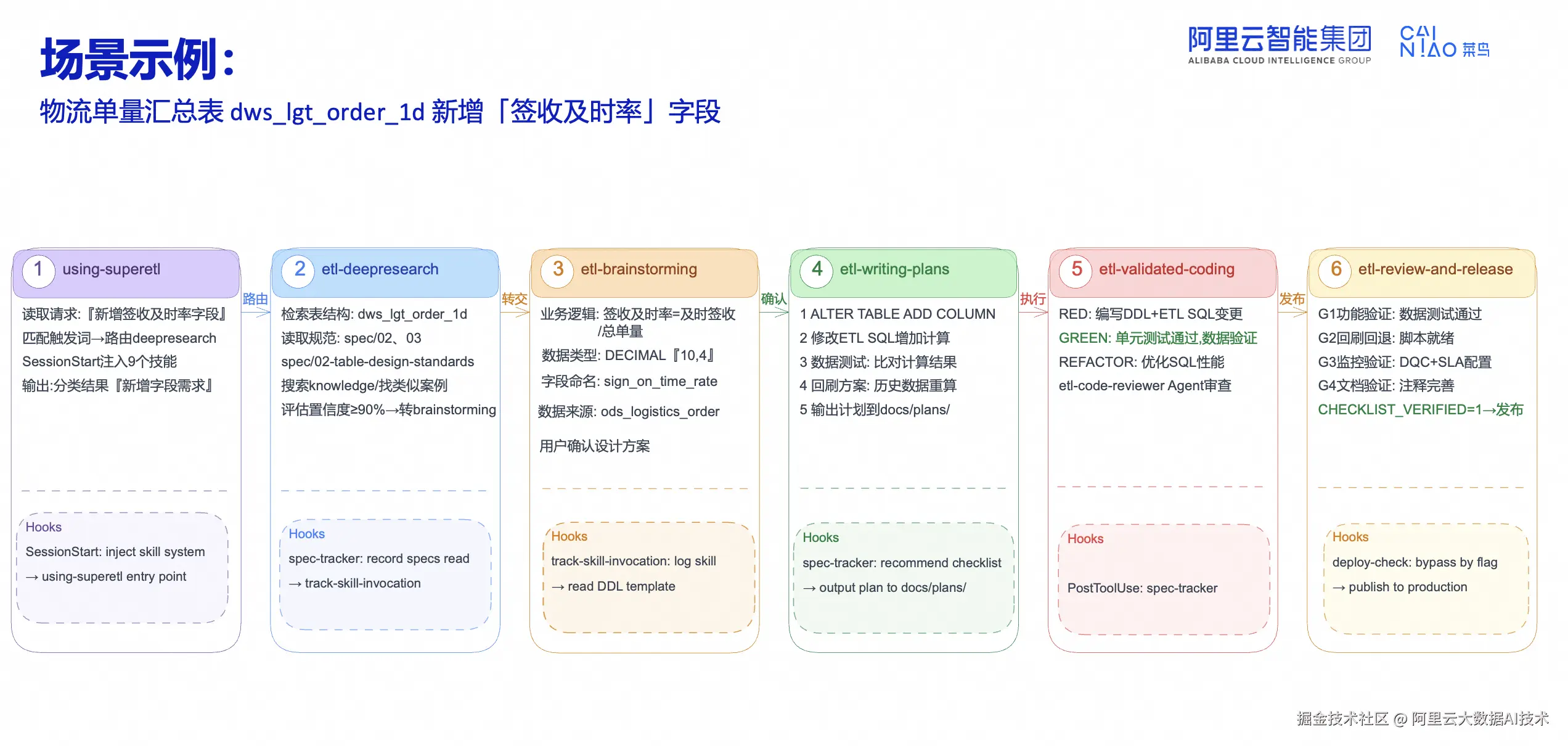
第一步-意图路由: using-superetl------读取请求"新增签收及时率字段",匹配触发词后路由到deepresearch,SessionStart注入9个技能,输出分类结果为"新增字段需求"。Hook机制在SessionStart时inject skill system,确保using-superetl作为入口。
第二步-拉取检索: etl-deepresearch------检索表结构dws_lgt_order_1d,读取规范spec/02、03,通过dataworks skills检索任务和下游,评估置信度低于90%后转交brainstorming。Hook机制通过spec-tracker记录规范读取情况,track-skill-invocation记录技能调用。
第三步-明确逻辑: etl-brainstorming------明确业务逻辑(签收及时率=及时签收/总单量),确定数据类型DECIMAL10,4,字段命名sign_on_time_rate,数据来源ods_logistics_order,最终由用户确认设计方案。Hook机制记录技能调用并读取DDL template。
第四步-生成计划: etl-writing-plans------编写实施计划:ALTER TABLE ADD COLUMN,修改ETL SQL增加计算,数据测试比对计算结果,制定回刷方案重算历史数据,输出计划到docs/plans/。Hook机制推荐checklist并将计划输出到指定目录。
第五步-验证开发: etl-validated-coding------编写DDL+ETL SQL变更,单元测试通过并进行数据验证,优化SQL性能,由etl-code-reviewer Agent进行审查。Hook机制在PostToolUse阶段通过spec-tracker追踪。
第六步-安全发布: etl-review-and-release------完成功能验证(数据测试通过),准备回刷回退脚本,配置DQC+SLA监控,完善注释,在 CHECKLIST_VERIFIED=1 确认后发布到生产。Hook 机制在 deploy-check 时通过 flag 判断是否放行。
这个案例完整展示了 SuperETL 如何将一个简单的字段新增需求,通过标准化的技能编排、规范检索、交互式确认、计划编写、验证式开发、checklist 审查,最终安全发布到生产环境。
展望AI时代的数据研发范式
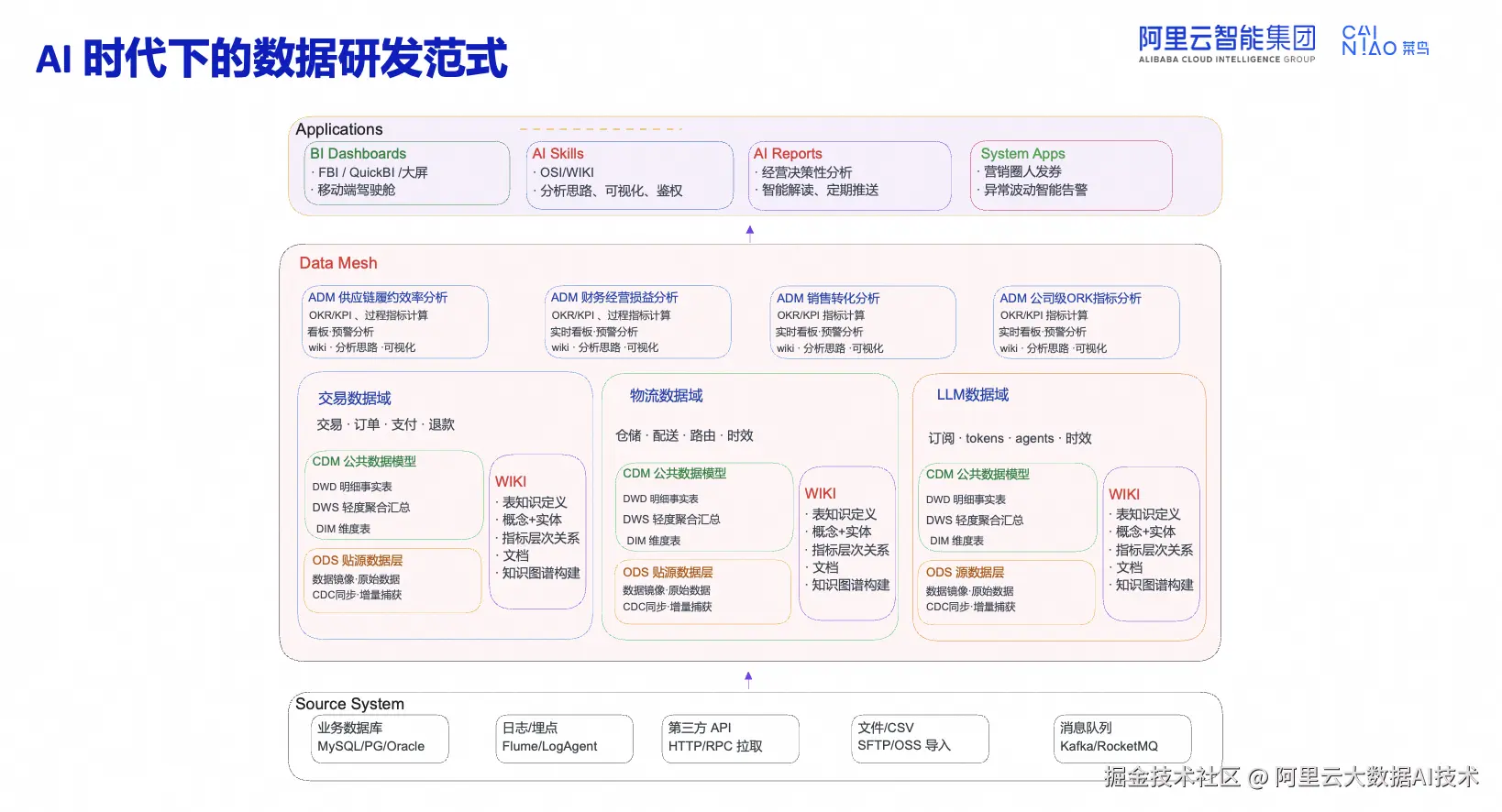
未来的研发范式,不变的是数据分层架构(ODS-CDM-ADM)与维度建模方式。每个数据域包含 ODS 贴源层、CDM 公共模型(DWD/DWS/DIM)、ADM 分析域。
变化的是组织方式与交付物。从项目制数仓走向数据网格/数据域,按业务域拆分(交易、物流、LLM 数据域)。强化知识层 WIKI/知识图谱,将表知识定义、概念实体、指标层次关系纳入研发范式。
-
应用层全面 AI 化。传统 BI 看板之外,新增 AI Skills(自然语言知识检索)、AI Reports(自动生成经营分析)、System Apps(数据驱动业务动作)。LLM 数据域被显式纳入,将大模型调用、成本、时效纳入数据平台治理。
-
交付物从报表转向 AI 分析 Skill、分析思路及深度分析报告。数据研发不再是"建表---出数---做报表",而是"源系统采集→域化建模→知识化沉淀→AI 可用→应用自动化"的闭环。
总结: 菜鸟 SuperETL 实践证明:这场 AI 时代的数据研发升级,是将 DataWorks Data Agent 与行业知识、研发规范、质量标准有机结合,并系统性地转化为AI可执行的技能体系。 通过九大 Skill 编排、Hooks 安全阻断、CLI 工程支撑与知识资产沉淀,最终实现从"人写代码"到"人定规则、AI 执行交付"的跨越,为数据研发效率与质量保障提供了一条可复制、可落地的工程路径。
DataWorks Data Agent 入口: dataworks.data.aliyun.com/product/age...
DataWorks Data Agent官方文档: help.aliyun.com/zh/datawork...