B端技术产品的核心指标体系搭建实战
前言
创业初期,我们团队做了一个面向研发团队的技术文档协作平台。上线两个月,注册用户3000+,但投资人问了一个让我哑口无言的问题:"你们的DAU为什么涨不动?"
我翻了翻当时的监控面板------只有PV、UV、注册数三个指标。坦白讲,这跟看黑盒子没区别。后来我被邀请回前司做了一次分享,技术VP说了一句让我醍醐灌顶的话:"B端产品不看DAU绝对值,要看核心链路渗透率。"
从那天起,我开始系统性地搭建B端技术产品的指标体系。今天把这套方法论完整地分享出来。
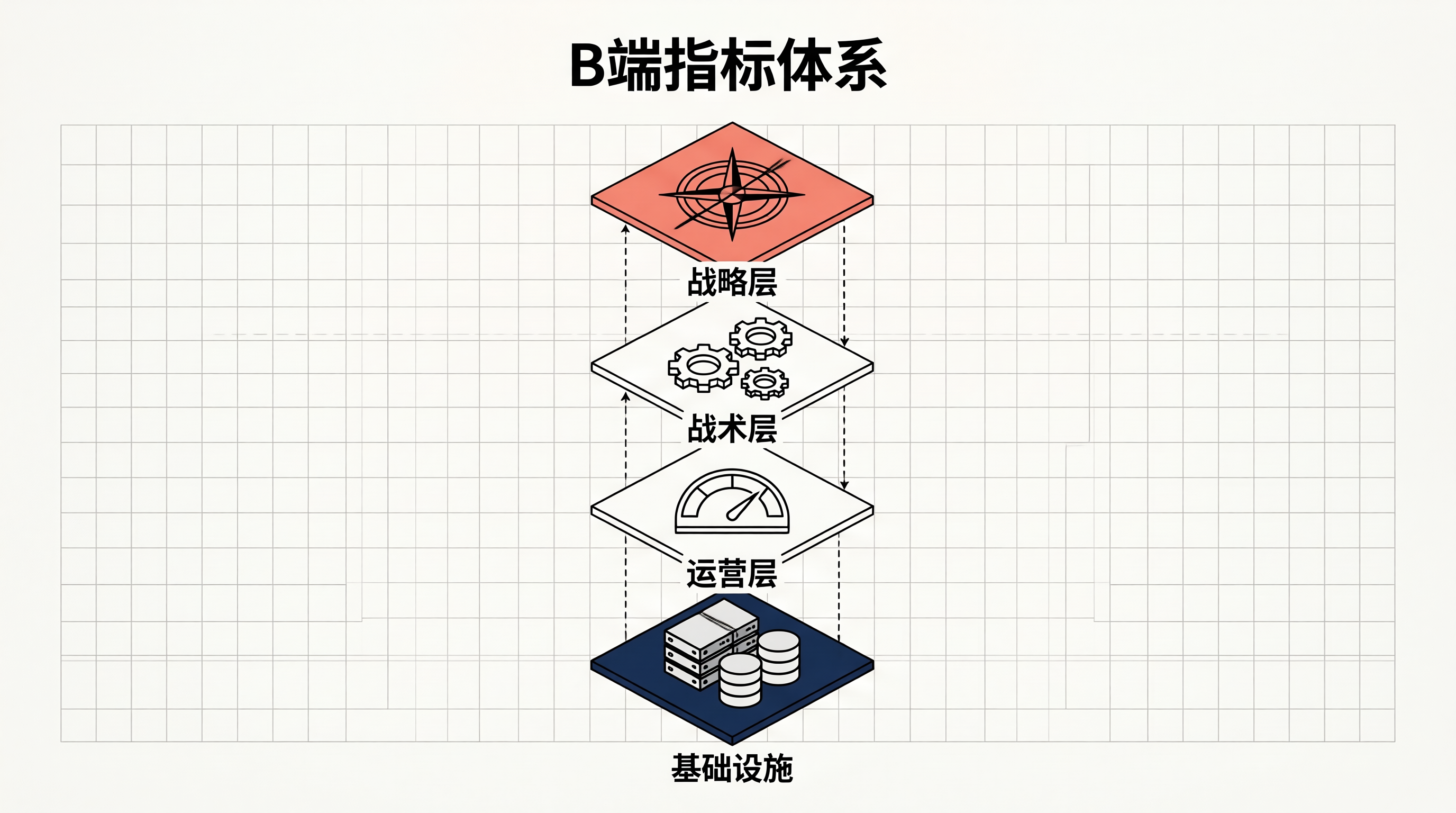
一、指标体系设计
B端技术产品和C端最大的区别在于:用户的成功不等于产品的成功,客户的业务目标达成才是。
我的指标体系分层如下:
graph TD
subgraph 战略层
A1[北极星指标: 核心链路DAU]
end
subgraph 战术层
B1[功能渗透率]
B2[任务完成率]
B3[跳出率]
end
subgraph 运营层
C1[页面加载时长]
C2[API响应时长]
C3[错误率]
C4[用户留存]
end
subgraph 基础设施层
D1[服务器QPS]
D2[数据库连接数]
D3[缓存命中率]
end
A1 --> B1 --> C1
A1 --> B2 --> C2
A1 --> B3 --> C3
B1 --> C4
C1 --> D1
C2 --> D2
C3 --> D3
核心指标体系定义:
| 指标层级 | 指标名称 | 计算公式 | 告警阈值 |
|---|---|---|---|
| 北极星 | 核心链路DAU | 完成核心事件用户数/7天MAU | <30%触发 |
| 战术层 | 功能渗透率 | 使用功能A的用户/总活跃用户 | 周环比降>10% |
| 战术层 | 任务完成率 | 完成任务用户/进入任务用户 | <60%触发 |
| 运营层 | P99 API延迟 | 升序排列第99%请求耗时 | >2000ms触发 |
| 运营层 | 跳出率 | 单页停留<5s且无交互 | >50%触发 |
二、数据采集管道
数据管道的设计直接影响指标准确性和系统开销。我选择了日志采集+消息队列+流式计算的经典架构:
python
import asyncio
import aiohttp
import json
from datetime import datetime
from aiokafka import AIOKafkaProducer
class DataPipeline:
def __init__(self):
self.producer = AIOKafkaProducer(
bootstrap_servers='localhost:9092',
acks='all',
retry_backoff_ms=100
)
self.buffer = []
self.buffer_size = 100
self.flush_interval = 5 # 秒
async def start(self):
await self.producer.start()
asyncio.create_task(self._periodic_flush())
async def collect_metric(self, metric_name, value, tags=None):
point = {
'metric': metric_name,
'value': value,
'tags': tags or {},
'timestamp': int(datetime.now().timestamp() * 1000)
}
self.buffer.append(point)
if len(self.buffer) >= self.buffer_size:
await self._flush()
async def _flush(self):
if not self.buffer:
return
batch = self.buffer[:]
self.buffer = []
futures = []
for point in batch:
key = f"{point['metric']}:{point['timestamp']}".encode()
futures.append(
self.producer.send('metrics', key=key,
value=json.dumps(point).encode())
)
await asyncio.gather(*futures)
async def _periodic_flush(self):
while True:
await asyncio.sleep(self.flush_interval)
await self._flush()
# 使用示例
async def collect_metrics():
pipeline = DataPipeline()
await pipeline.start()
# 模拟采集DAU数据
for i in range(100):
await pipeline.collect_metric(
'core_dau', 12500,
tags={'version': 'v2.3.1', 'module': 'doc_editor'}
)
await asyncio.sleep(1)
asyncio.run(collect_metrics())三、实时监控看板
指标采回来只是第一步,怎么让团队直观看到问题才是关键。我用Go写了一个轻量级的指标聚合服务,配合Grafana实现实时看板:
go
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"net/http"
"sync"
"time"
"github.com/segmentio/kafka-go"
)
type MetricAggregator struct {
mu sync.RWMutex
metrics map[string]*AggregatedMetric
}
type AggregatedMetric struct {
Name string `json:"name"`
Avg float64 `json:"avg"`
P50 float64 `json:"p50"`
P99 float64 `json:"p99"`
Count int64 `json:"count"`
UpdatedAt time.Time `json:"updated_at"`
}
func NewMetricAggregator() *MetricAggregator {
return &MetricAggregator{
metrics: make(map[string]*AggregatedMetric),
}
}
func (ma *MetricAggregator) ConsumeFromKafka(brokers []string, topic string) {
reader := kafka.NewReader(kafka.ReaderConfig{
Brokers: brokers,
Topic: topic,
GroupID: "metric-aggregator",
})
for {
msg, err := reader.ReadMessage(context.Background())
if err != nil {
log.Printf("read message error: %v", err)
continue
}
var point struct {
Metric string `json:"metric"`
Value float64 `json:"value"`
Tags map[string]string `json:"tags"`
Timestamp int64 `json:"timestamp"`
}
json.Unmarshal(msg.Value, &point)
ma.updateMetric(point.Metric, point.Value)
}
}
func (ma *MetricAggregator) updateMetric(name string, value float64) {
ma.mu.Lock()
defer ma.mu.Unlock()
agg, exists := ma.metrics[name]
if !exists {
agg = &AggregatedMetric{Name: name}
ma.metrics[name] = agg
}
agg.Count++
agg.Avg = agg.Avg + (value-agg.Avg)/float64(agg.Count)
agg.UpdatedAt = time.Now()
}
// HTTP接口供Grafana抓取
func (ma *MetricAggregator) ServeHTTP(w http.ResponseWriter, r *http.Request) {
ma.mu.RLock()
defer ma.mu.RUnlock()
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(ma.metrics)
}
func main() {
agg := NewMetricAggregator()
go agg.ConsumeFromKafka([]string{"localhost:9092"}, "metrics")
http.HandleFunc("/metrics", agg.ServeHTTP)
log.Fatal(http.ListenAndServe(":8080", nil))
}四、落地效果
这套指标体系上线后,我们发现了一个之前完全没注意到的问题:文档编辑器的P99延迟在下午3-4点飙到4秒,直接导致该时段跳出率从32%升到61%。
排查后发现是CDN预热策略的问题。优化后,核心链路DAU从1.2万涨到了2.8万,跳出率稳定在18%以下。
| 指标 | 优化前 | 优化后 | 变化 |
|---|---|---|---|
| 核心链路DAU | 1.2万 | 2.8万 | +133% |
| 文档编辑跳出率 | 61% | 18% | -43% |
| P99延迟 | 4000ms | 380ms | -90% |
| 功能渗透率 | 23% | 47% | +24% |
指标体系不是搭建完就一劳永逸的,它需要随着产品迭代不断演进。但有了这套体系,至少你不再是"盲人摸象"------每一行代码改动对业务的影响,数据都会告诉你答案。