大家好,我是 Ivan。
提示词工程这个名字,第一次听确实有点装。
Prompt Engineering,翻译过来叫提示词工程,好像突然从写业务代码变成搞研究了。说实话,我一开始也觉得,这不就是会不会提问吗?后来项目跑起来以后,我才发现它没这么简单。
尤其是做 Agent 的时候,Prompt 写不好,不只是回答丑一点,而是接口挂、JSON 解析挂、教师端页面挂、学生画像误判,最后后端还要背锅。
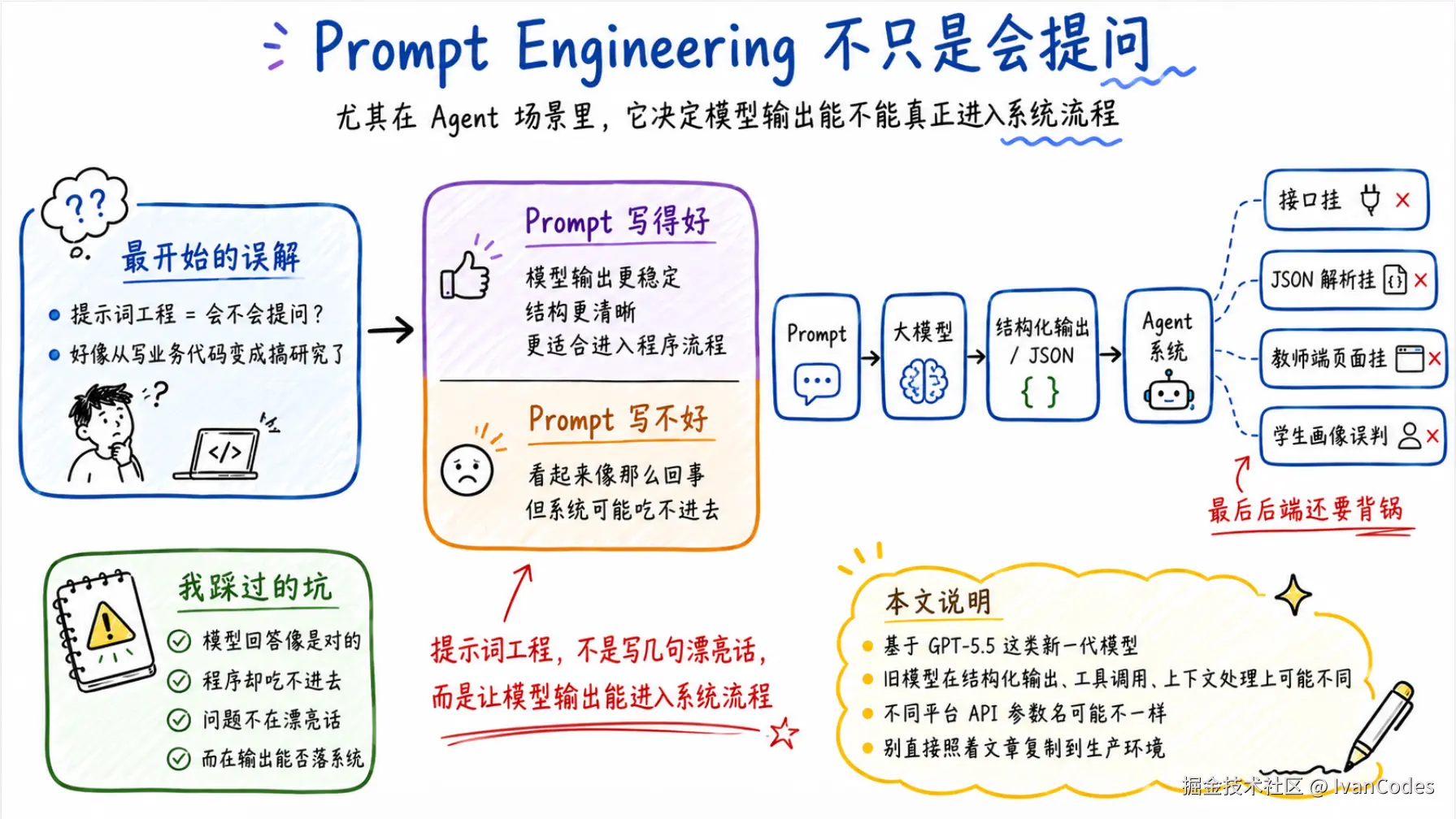
我之前做高校学情分析 Agent 的时候,就被这个东西反复折磨。模型回答看起来挺像那么回事,但程序就是吃不进去。那一刻我才意识到,提示词工程不是写几句漂亮话,而是要让模型输出能进入系统流程。
我这次基于 GPT-5.5 这类新一代模型的能力来讲。低于 GPT-5.5 的旧模型,结构化输出、工具调用、上下文处理能力可能会不一样。还有一点要提前说:不同平台的 API 参数名可能不同,别照着一篇文章就直接复制到生产环境。
一、先讲结构化输出,不是最基础,但最容易出事
正常教程一般会先讲什么是 Prompt、Zero-shot、Few-shot、角色提示。
我不按这个顺序来。
因为我在真实项目里最先被坑的,不是模型听不懂问题,而是它看起来答对了,但是程序解析失败。
这个痛苦谁接过后端接口谁知道。
场景很简单:系统输入学生最近 30 天的学习数据,让模型判断学习风险等级,然后返回给后端,后端再给教师端展示。
我最开始写的 Prompt 是这样:
text
请分析下面学生是否存在学习风险,并严格返回 JSON,不要输出其他内容。
学生数据:
登录次数:3
作业提交率:52%
测验平均分:58模型返回:
json
{
"riskLevel": "高风险",
"reason": "学生登录次数较少,作业提交率偏低,测验成绩不及格。"
}你看,它是不是挺合理?
但后端直接不认。
因为我后端枚举只认:
text
low
medium
high它给我来了个中文的高风险。
还有更烦的情况:
json
{
"riskLevel": "medium",
"reason": "该学生存在一定学习风险",
"suggestion": "建议老师关注"
}
// 以上是根据学生学习行为数据生成的分析结果最后那行注释一出来,JSON.parse() 直接报错。
很多人以为写一句只返回 JSON 就够了,但这只是软约束。软约束的意思就是:模型大部分时候会听,但它偶尔不听,而你不知道它什么时候不听。
如果你做的是聊天机器人,这还能忍。
如果你做的是 Agent、RAG、自动评分、后台审核、数据抽取,这就不能靠运气。
要稳定,最好把 Prompt 约束和 API 层的结构化输出一起用。
也就是你不仅告诉模型:
text
请返回 JSON。还要告诉接口层:
text
字段有哪些;
字段类型是什么;
枚举只能有哪些值;
不能多返回字段;
哪些字段必须存在。这就是结构化输出。
比如你希望模型必须返回这种格式:
json
{
"userId": "S202604001",
"riskLevel": "high",
"reason": "近 30 天登录次数过低,测验平均分低于 60。",
"suggestion": "建议教师进行一次学习状态确认。"
}那你就不要只在 Prompt 里写格式示例,最好用 JSON Schema 约束它。
这里还有一个版本坑。很多人以为所有模型都支持结构化输出,但旧模型可能不支持。比如你把新接口参数套到旧模型上,可能会看到类似这种完整报错:
text
BadRequestError: 400 Invalid parameter: 'response_format' of type 'json_schema' is not supported with this model.
type: 'invalid_request_error'
param: 'response_format'
code: null这个报错我见过类似的。StackOverflow 上也有人问过,编号好像是 79 开头,反正搜关键词 json_schema not supported model 基本能找到。
这也是为什么我现在写 Prompt 不会只看文本本身,还会看模型版本、API 能力、SDK 版本和后端解析方式。
提示词工程不是脱离工程环境存在的技巧。
终于把最烦的一块讲完了。这部分我当初真的想直接关电脑。
二、提示词的本质
提示词 Prompt,是用户或系统输入给大语言模型的完整上下文。它可以包含任务说明、背景信息、输入数据、格式要求、示例、限制条件和安全边界。
提示词工程 Prompt Engineering,是通过设计、组织、约束和迭代提示词,使模型输出更接近目标结果的一组方法。
提示词不是代码。提示词不能像传统程序一样保证确定执行。
提示词也不是咒语。提示词不会因为写得玄学就变强。
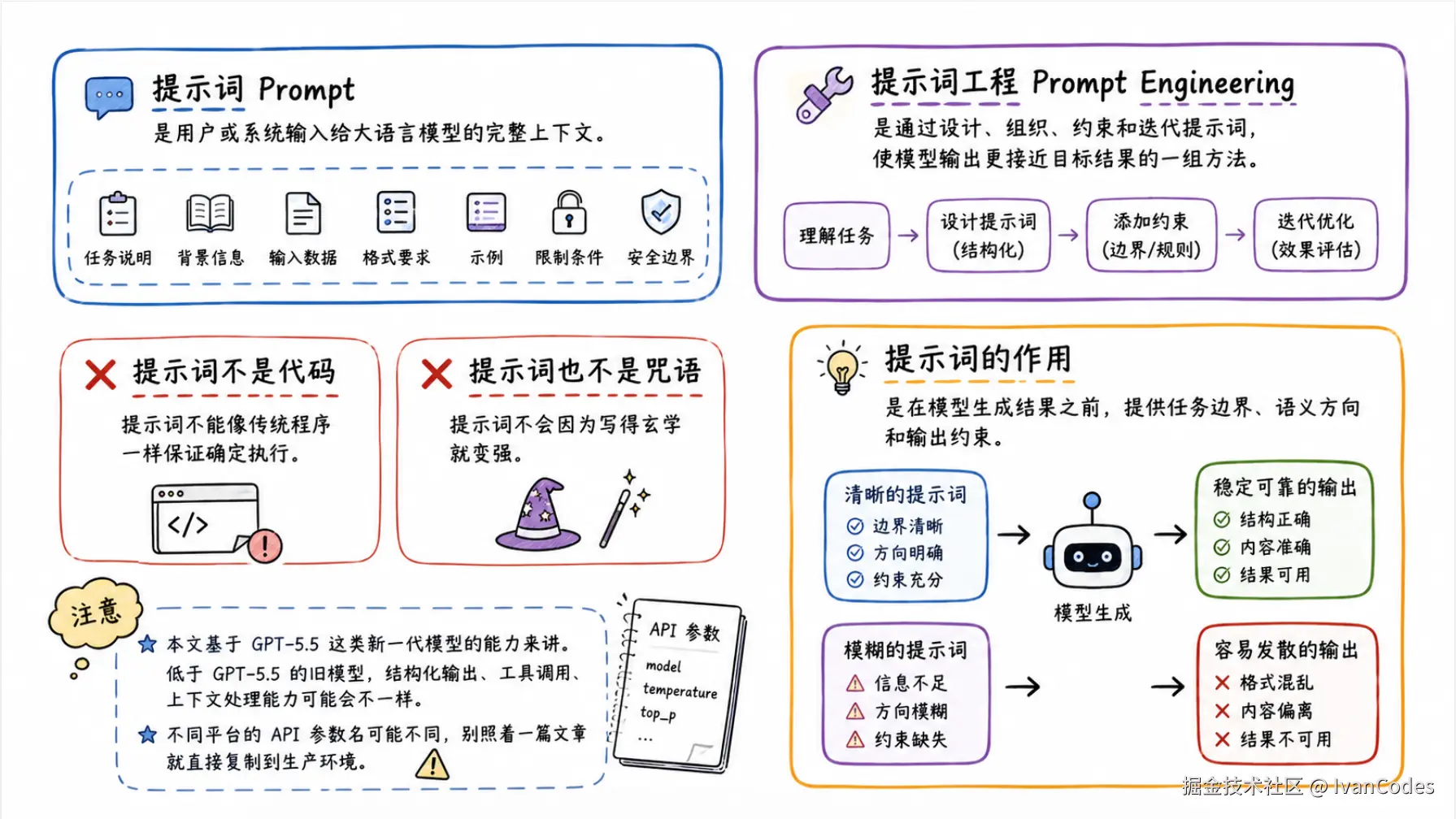
提示词的作用,是在模型生成结果之前,提供任务边界、语义方向和输出约束。模型会基于这些上下文进行生成,提示词越清楚,输出越稳定;提示词越模糊,输出越容易发散。
结构化提示词通常包含以下部分:
text
角色
背景
输入
任务
规则
输出格式
示例
安全边界系统提示词 System Prompt 或 Instructions,通常用于定义模型的默认行为、身份、语气和不可违反的规则。
用户提示词 User Prompt,通常用于提交具体任务和输入数据。
在 Agent 开发中,提示词经常不是一次性文本,而是由后端模板、用户输入、检索内容、工具返回结果拼接而成。
三、分隔符 vs XML 标签,我项目里更偏向 XML
官方文档里经常推荐把指令放前面,然后用 ###、三个引号,或者类似分隔符把上下文隔开。
比如:
text
请总结下面的内容。
###
这里是文章正文
###这种写法没问题。简单任务很好用,摘要、翻译、分类,基本够了。
但我在复杂 Agent 项目里更常用 XML 标签。
不是因为 XML 高级。它一点都不高级,甚至有点土。但它清楚。
2026 年 4 月,我做过一个高校学情分析系统。项目不大,但数据源很碎:学生画像、课程访问记录、作业记录、测验分数、教师备注、RAG 检索出来的课程资料,全都要塞给 Agent。
当时我用普通编辑器写后端模板,凌晨 2 点还在调一个学生风险等级为什么总是偏高的问题。
后来发现不是模型坏了,是 Prompt 拼接以后,教师备注和系统规则混在了一起。
原来是这样写的:
text
你是高校学习分析助手。
学生数据如下:
张同学,大二,近 30 天登录 3 次,作业逾期 5 次。
教师备注:
这个学生最近状态不好,但不要直接判高风险。
请判断风险等级。模型很容易把教师备注当成判断规则。
后来我改成这样:
xml
<role>
你是高校学习分析系统中的 AI 学情预警助手。
</role>
<student_profile>
姓名:张同学
年级:大二
近 30 天登录次数:3
作业逾期次数:5
测验平均分:58
</student_profile>
<teacher_note>
这个学生最近状态不好,但不要直接判高风险。
</teacher_note>
<rules>
只能根据学习行为数据判断风险等级。
教师备注只能作为辅助背景,不能覆盖硬性规则。
如果测验平均分低于 60,riskLevel 必须为 high。
</rules>
<output_format>
只返回 JSON。
riskLevel 只能是 low、medium、high。
</output_format>效果稳定很多。
这里不是说 XML 标签一定比分隔符好。
我的经验是:
简单任务,用分隔符就行。
复杂任务,尤其是多段上下文、多角色、多数据源、多规则的时候,XML 标签更稳一点。
官方文档推荐分隔符,但我实际项目中用 XML 标签更多,因为后端模板拼接更清楚,也更容易排查是哪一段上下文影响了输出。
我之前刷到一篇博客,忘了作者是谁,大概意思是 Prompt 其实更像一种实验出来的工程习惯,不是背模板。这个说法我挺认同。Lilian Weng 那篇标题里好像有 Prompt Engineering,链接我懒得找了,你搜名字应该能看到。
四、五种常见设计范式,这次都讲
提示词设计范式一般会讲很多,我这里就讲五种常见的:结构化、Zero-shot、Few-shot、角色、迭代式提示。
别被名字吓到,本质都不复杂。
1. 结构化提示 Structured Prompting
结构化提示就是把任务拆成几块,不要一坨文字扔给模型。
比如你别这么写:
text
帮我看看这个学生有没有风险。你要这样写:
markdown
# 角色
你是高校学习分析系统中的 AI 助手。
# 输入
学生近 30 天学习数据。
# 判断规则
- 登录次数低于 5,至少 medium;
- 作业提交率低于 60%,至少 medium;
- 测验平均分低于 60,必须 high;
- 不要编造输入中没有的数据。
# 输出
只返回 JSON。结构化提示的重点不是格式好看,而是让模型知道每一段文字是什么用途。
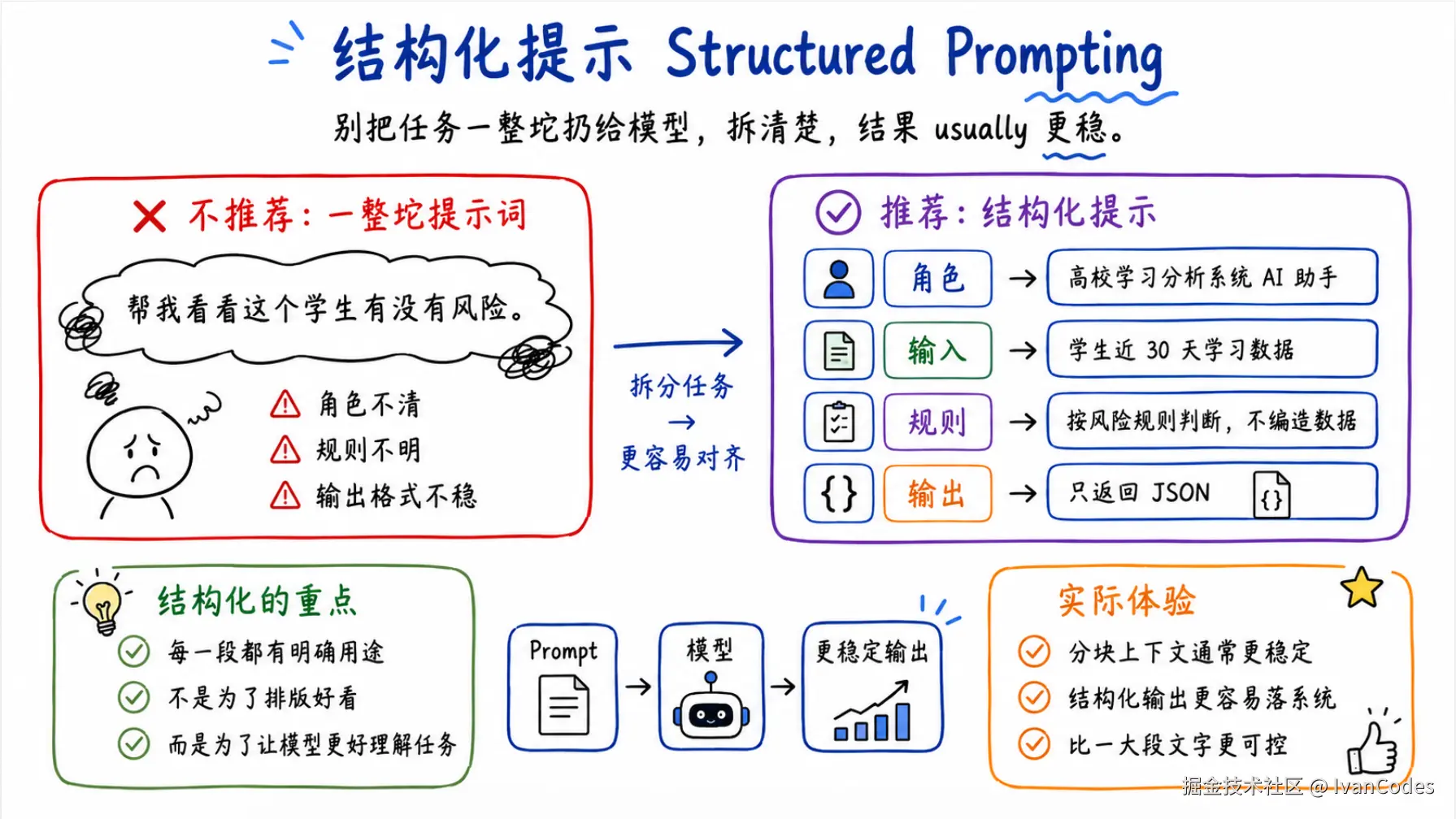
我从某个群里看到过一张截图,据说是某个大模型团队的人发的,大概意思是清晰分块的上下文会更容易让模型对齐任务。真假我不确定,别当证据。但我项目里试下来,确实比一整坨文字稳定。
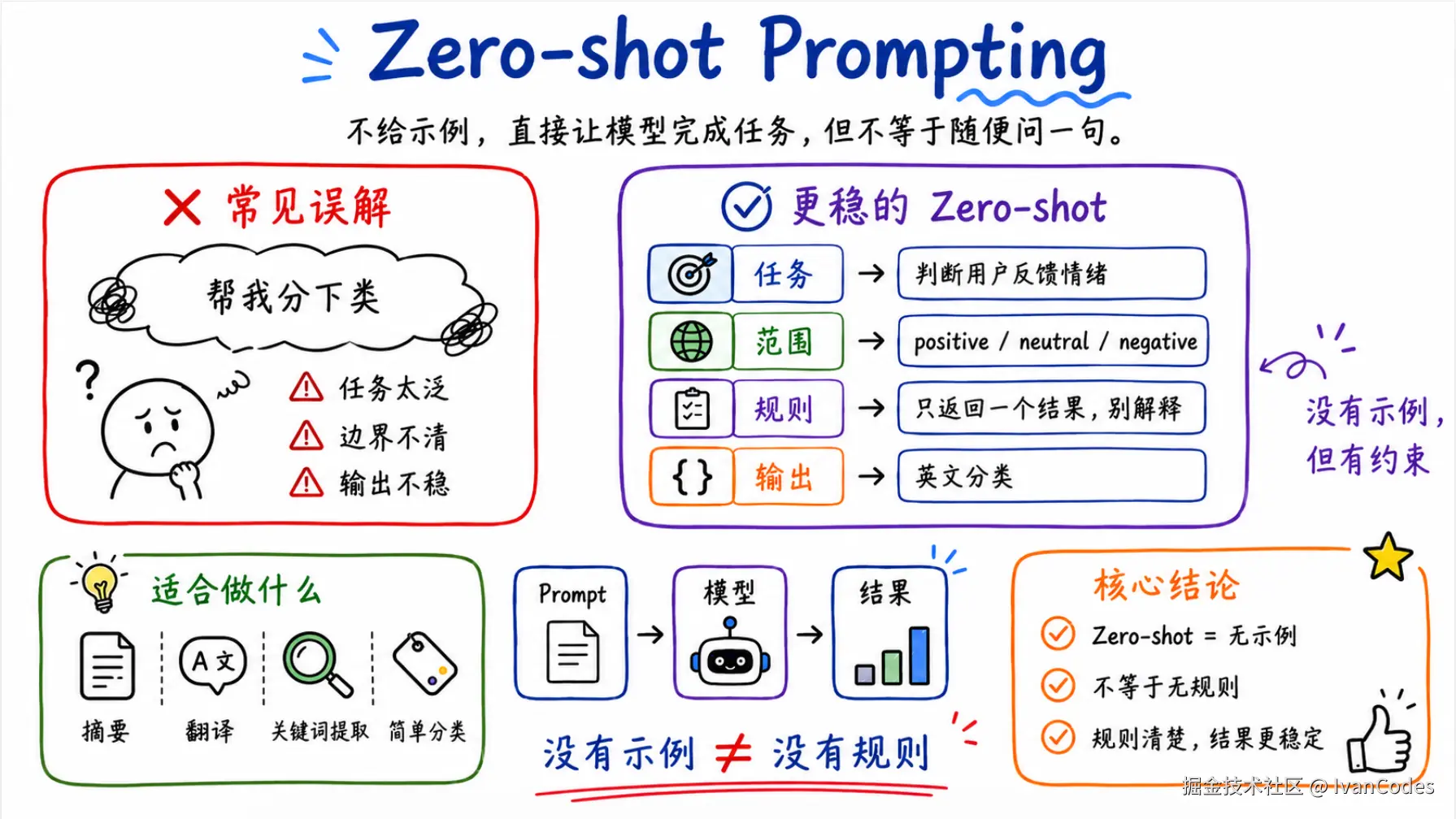
2. Zero-shot Prompting
Zero-shot 就是不给示例,直接让模型完成任务。
比如:
text
请把下面这段文本分类为:正面、负面、中性。
只返回分类结果,不要解释。
文本:
这个系统功能挺全,但页面加载太慢了。这就是 Zero-shot。
它适合简单、通用、低风险的任务,比如:
text
摘要
翻译
关键词提取
情绪分类
简单改写但很多人会误解 Zero-shot。
Zero-shot 不是随便写一句话就完事。它只是没有示例,不代表没有规则。
比如下面这个就比单纯一句帮我分类稳定:
text
任务:判断用户反馈情绪。
分类范围:
positive
neutral
negative
要求:
1. 只返回一个英文分类;
2. 不要输出解释;
3. 如果反馈同时包含好坏两面,但整体偏抱怨,返回 negative。
用户反馈:
这个系统功能挺全,但页面加载太慢了。这里没有给样例,所以还是 Zero-shot。
但它已经有任务、分类范围、输出限制和边界规则了。
我也不知道为什么很多教程会把 Zero-shot 讲得像什么都不用写,直接问就行。真实项目里这么写,迟早要回来补规则。
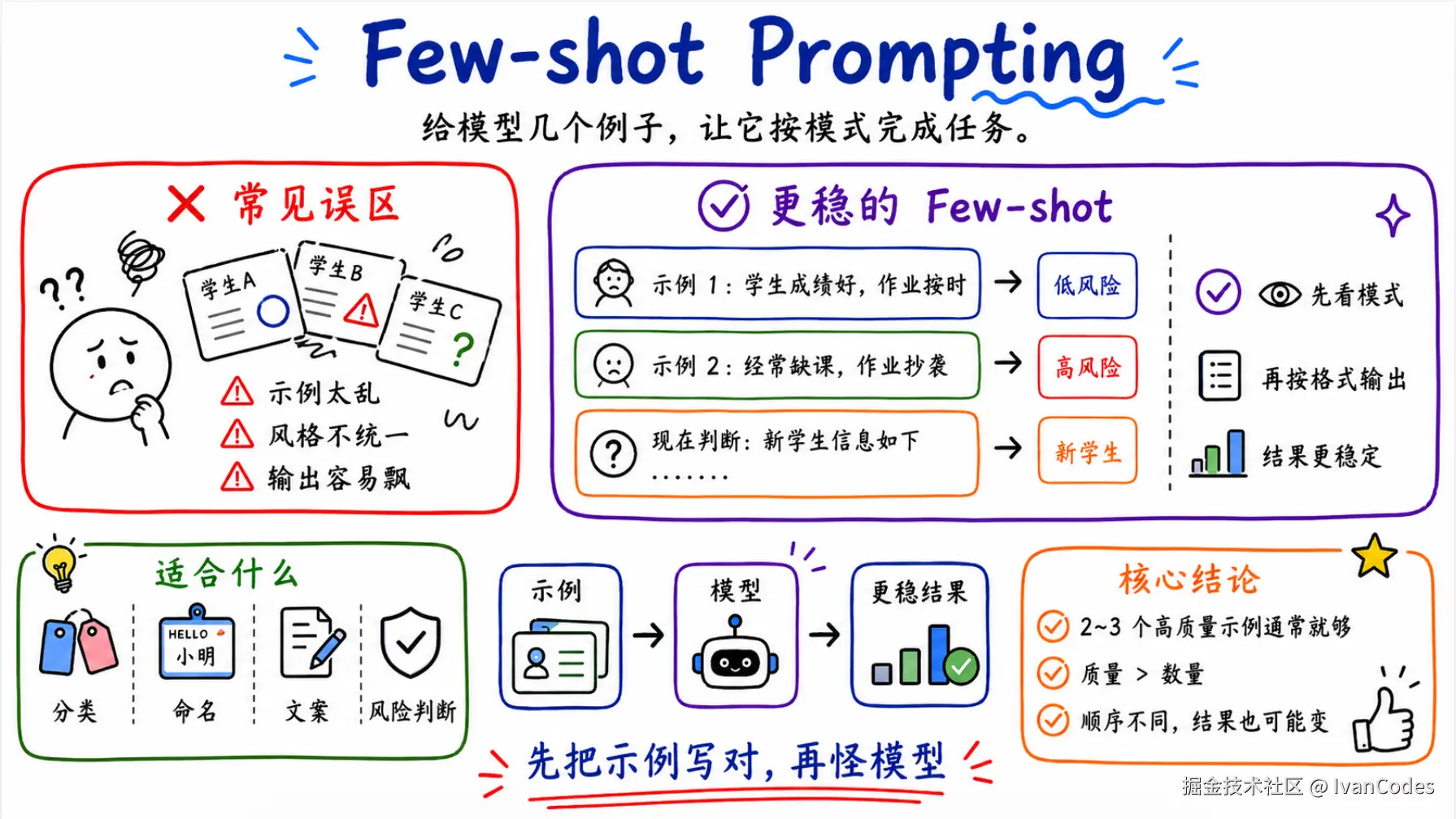
3. Few-shot Prompting
Few-shot 就是给模型几个例子,让它照着学。
这个在分类、命名、文案、风险判断里很好用。
比如学生风险判断:
text
任务:根据学生学习数据判断风险等级。
示例 1:
输入:
loginCount30Days: 20
homeworkSubmitRate: 0.95
avgQuizScore: 86
输出:
{
"riskLevel": "low",
"reason": "学习行为稳定,成绩正常。",
"suggestion": "保持当前学习节奏。"
}
示例 2:
输入:
loginCount30Days: 2
homeworkSubmitRate: 0.40
avgQuizScore: 51
输出:
{
"riskLevel": "high",
"reason": "登录次数低、作业提交率低且测验成绩不及格。",
"suggestion": "建议教师尽快进行人工跟进。"
}
现在判断下面这个学生:
loginCount30Days: 4
homeworkSubmitRate: 0.52
avgQuizScore: 58注意,示例不是越多越好。
2 到 3 个高质量示例,通常比 10 个乱七八糟的示例强。
有时候示例顺序一换,模型输出就变保守了。可能和上下文里的模式学习有关,也可能是我样例设计太差。反正遇到这种情况,别先怪模型,先换一下示例顺序试试。
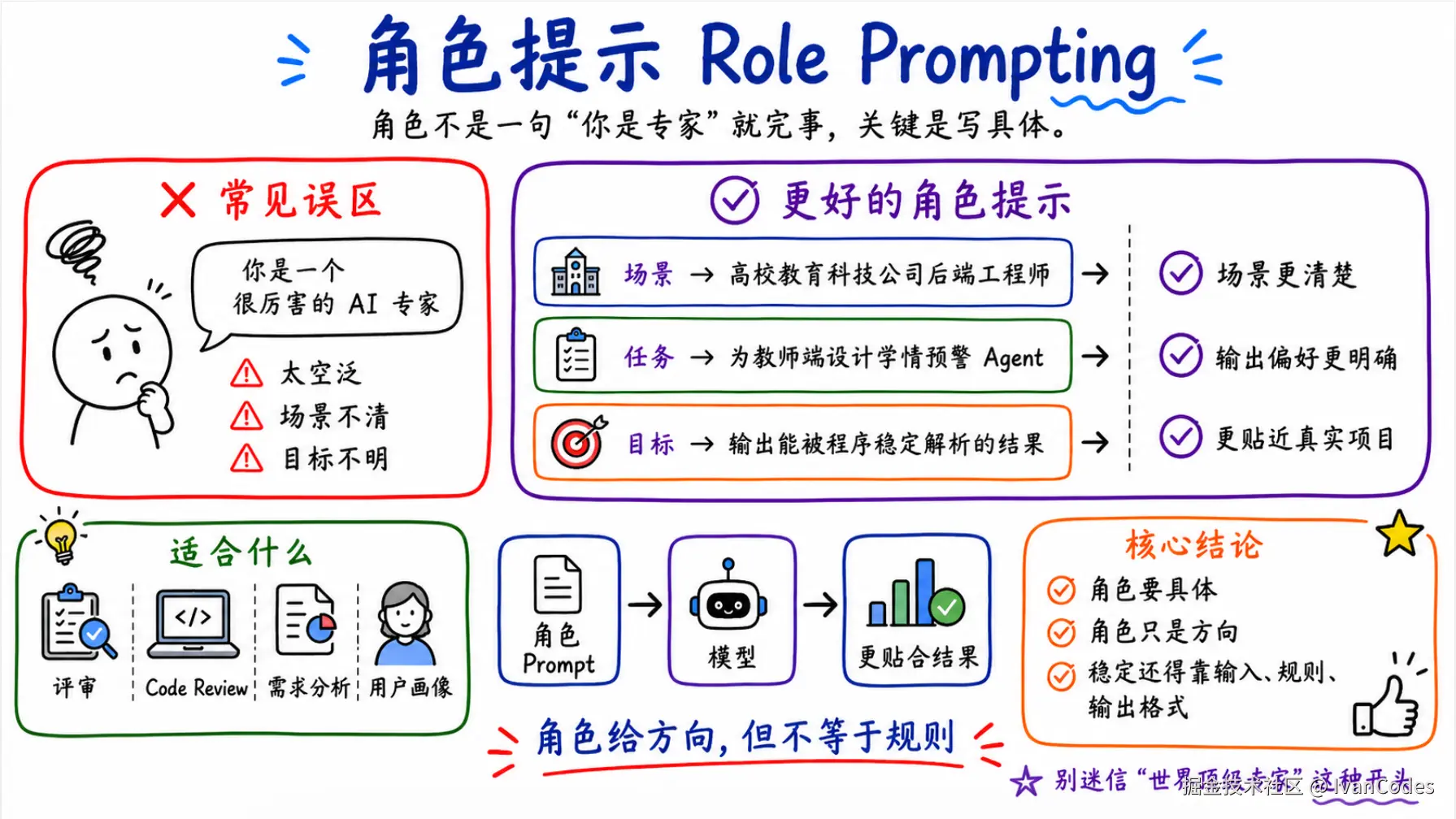
4. 角色提示 Role Prompting
角色提示不是写一句你是专家就完事。
说实话,我现在看到你是一名世界顶级专家这种开头,已经有点麻了。
角色要写具体。
比如:
text
你是一名高校教育科技公司的后端工程师,正在为教师端后台设计学情预警 Agent。
你的目标不是写漂亮分析,而是输出能被程序稳定解析的风险判断结果。这比下面这种强:
text
你是一个非常厉害的 AI 专家。因为前者给了场景、目标和输出偏好。后者只有情绪价值。
角色提示在评审、代码 Review、需求分析、用户画像分析里都挺好用。
但不要迷信。角色只是方向,不是规则。真正稳定的还是输入、规则、输出格式和 schema。
5. 迭代式提示 Multi-turn Prompting
迭代式提示就是不要指望一次 Prompt 直接把复杂任务搞定。
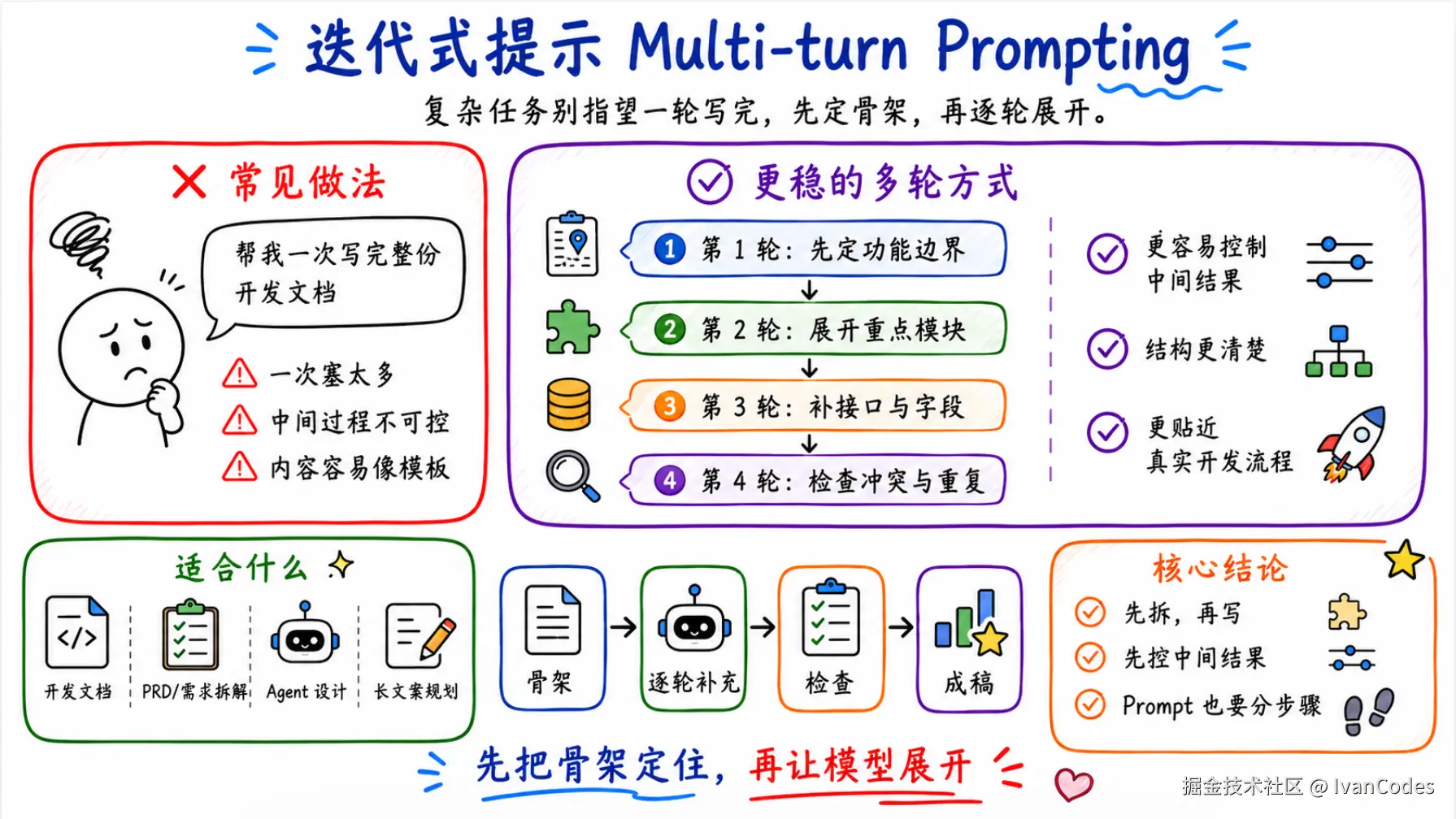
比如你要写一份 Agent 开发文档,很多人会直接这样问:
text
帮我写一份高校学情分析 Agent 的开发文档,越详细越好。模型确实能写。
但大概率会写得很完整、很顺、很像模板,也很难直接用。
更好的方式是拆成几轮:
text
第一轮:
请先帮我整理高校学情分析 Agent 的功能边界。
不要写正文,只列模块和每个模块的输入输出。
第二轮:
保留上面的模块,把教师端后台相关功能展开。
重点写学情预警、学生画像、干预建议。
第三轮:
现在补充后端接口设计。
每个接口写清楚请求参数、响应字段、异常情况。
第四轮:
检查整份文档有没有功能重复、字段冲突、权限边界不清楚的问题。迭代式提示的重点是控制中间结果。
你先把骨架定住,再让模型展开。这样比一上来让它写几千字稳定很多。
这点和写代码有点像。你不会上来就把所有业务逻辑一口气写完,总得先拆模块、定接口、跑通主流程。
Prompt 也是一样。
五、代码示例,这部分长一点,因为更重要
前面说了半天,核心其实就一句话:
别只靠 Prompt 约束 JSON。
这里我给一个简化版 Node.js 示例。不是完整项目代码,别复制就上线。里面故意保留了一点我平时开发会出现的东西,比如忘删的 console.log,还有注释掉的旧代码。
javascript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.OPENAI_API_KEY
});
const student = {
userId: "S202604001",
loginCount30Days: 3,
homeworkSubmitRate: 0.52,
avgQuizScore: 58,
courseVisitMinutes: 41
};
async function analyzeStudentRisk(student) {
// 旧写法,先别用这个了,当时就是这里开始不稳定的
// const response = await client.chat.completions.create({
// model: "old-model",
// messages: [
// { role: "system", content: "你是高校学情分析助手。" },
// { role: "user", content: `请分析学生风险,并返回 JSON:${JSON.stringify(student)}` }
// ],
// response_format: { type: "json_object" }
// });
const response = await client.responses.create({
// 这里写 GPT-5.5 是文章示例,真实项目请以你控制台可用的 model id 为准
model: "gpt-5.5",
instructions: `
你是高校智能学习平台中的学情分析助手。
你只能根据输入数据判断风险等级。
不要编造学生家庭情况、心理状态、疾病信息。
不要输出解释性废话。
判断规则:
1. 如果 avgQuizScore < 60,则 riskLevel 必须为 high;
2. 如果 homeworkSubmitRate < 0.6,则 riskLevel 至少为 medium;
3. 如果 loginCount30Days < 5,则 riskLevel 至少为 medium;
4. 如果多个规则冲突,取更高风险等级;
5. 只能基于输入字段判断。
`,
input: `
<student>
userId: ${student.userId}
loginCount30Days: ${student.loginCount30Days}
homeworkSubmitRate: ${student.homeworkSubmitRate}
avgQuizScore: ${student.avgQuizScore}
courseVisitMinutes: ${student.courseVisitMinutes}
</student>
请判断该学生的学习风险等级。
`,
text: {
format: {
type: "json_schema",
name: "student_learning_risk",
strict: true,
schema: {
type: "object",
additionalProperties: false,
properties: {
userId: {
type: "string",
description: "学生 ID,必须原样返回"
},
riskLevel: {
type: "string",
enum: ["low", "medium", "high"],
description: "学习风险等级"
},
reason: {
type: "string",
description: "一句话说明判断原因"
},
suggestion: {
type: "string",
description: "给教师的一句话干预建议"
}
},
required: ["userId", "riskLevel", "reason", "suggestion"]
}
}
}
});
console.log("debug raw response:", response); // 忘删了,上线前记得删
const text = response.output_text;
let result;
try {
result = JSON.parse(text);
} catch (err) {
throw new Error("模型返回内容不是合法 JSON:" + text);
}
if (result.userId !== student.userId) {
throw new Error("模型返回的 userId 和输入不一致");
}
if (!["low", "medium", "high"].includes(result.riskLevel)) {
throw new Error("模型返回了非法 riskLevel:" + result.riskLevel);
}
return result;
}
analyzeStudentRisk(student)
.then((res) => {
console.log("risk result:", res);
})
.catch((err) => {
console.error("analyze failed:", err.message);
});这段代码重点看几个地方。
第一,模型版本别乱写。
javascript
model: "gpt-5.5"这里为了文章阅读方便写成 GPT-5.5。真实项目里要用你控制台实际支持的 model id,不要自己猜。
第二,strict: true 要打开。
javascript
strict: true它的作用是让模型尽量严格贴合 schema。注意,不是所有 JSON Schema 写法都适合直接塞进去,schema 太复杂也可能带来额外问题。能简单就简单。
第三,additionalProperties: false 很有用。
javascript
additionalProperties: false不然模型可能给你多返回字段,比如:
json
{
"riskLevel": "high",
"confidence": 0.87,
"extraComment": "该学生可能存在心理压力"
}看起来很贴心,但系统没这个字段,前端也没设计这个字段,最后还是你来处理。
第四,枚举要用 enum 锁死。
javascript
enum: ["low", "medium", "high"]前面讲过一次,这里再补一句:不要以为 Prompt 里写只返回 low、medium、high 就一定稳定。模型可能输出 Medium,也可能输出 moderate,还可能输出 中风险。
如果后端只认小写枚举,直接出问题。
第五,Prompt 还是要写。
有些人用了 schema,就觉得 Prompt 可以随便写。也不行。
schema 负责形状,Prompt 负责判断逻辑。
比如 schema 能限制 riskLevel 只能是 low、medium、high,但它不知道什么情况下应该是 high。判断规则还是要写在 instructions 或 input 里。
可以这样补规则:
text
如果 avgQuizScore < 60,则 riskLevel 必须为 high。
如果 homeworkSubmitRate < 0.6,则 riskLevel 至少为 medium。
如果 loginCount30Days < 5,则 riskLevel 至少为 medium。
只能基于输入字段判断,不要推测心理、家庭、疾病等敏感信息。这个规则最好也进 Prompt,不要只放在你脑子里。
我以前就犯过这个错。后端代码里有规则,Prompt 里没规则,结果模型按自己的理解判断,后端再二次修正。最后两边逻辑打架,查 bug 查到头疼。
还有一点,错误处理我这里写得不完整。
生产环境你还要考虑超时、重试、日志脱敏、用户权限、请求 traceId、模型拒答、返回空文本、账单成本等等。
但这篇不写了。再写就偏离入门了。
六、常见的术语
| 术语 | 意思 |
|---|---|
| Prompt | 输入给模型的完整上下文,不只是问题本身 |
| System Prompt / Instructions | 高优先级指令,用来定义模型身份、语气、边界 |
| Token | 模型处理文本的基本单位,不完全等于字或单词 |
| Context Window | 模型一次能看到的上下文范围 |
| Temperature | 控制输出随机性的参数,越低越稳定,越高越发散 |
| Structured Outputs | 让模型按 JSON Schema 等结构输出,方便程序解析 |
这些是常见的,其他的如果你感兴趣,可以自己查一下。
RAG、Tool Calling、Function Calling、Embedding、Agent Memory,这些都重要,在后续的教程中,我会讲给大家。
PS:刚才忘了说,temperature 默认值不同接口可能不一样,别默认它一定是你想要的。写代码的时候最好显式配置,尤其是分类、抽取、JSON 输出这种任务,温度别开太高。
再补一句,Zero-shot 不是不写规则,Few-shot 也不是示例越多越好。这个前面说过,但我还是想重复一下,因为很多 Agent 的问题最后都不是模型不行,而是输入边界太松。
先这样,有问题评论区见。