我们在查阅 Domain-Driven Design(DDD)相关资料时,经常会看到 CQRS(Command Query Responsibility Segregation)。继续深挖后又会牵出 Event Sourcing、Outbox、最终一致性等概念,越看越容易混乱。本文做一次简明整理:CQRS 到底有哪几种常见设计方式,以及在实际项目中该如何选择。
版本 1:Event Sourcing + CQRS(最常见的讨论版本)
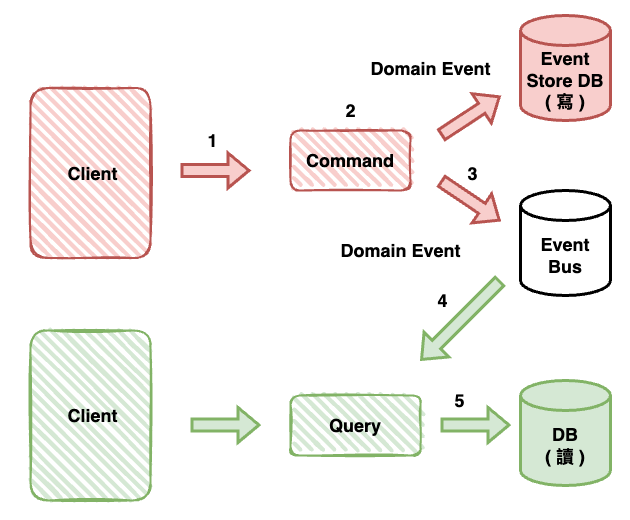
上面这张图是最常见的 Event Sourcing + CQRS 架构,流程大致如下:
- Client 发送 Command 请求到 Command Service。
- Command Service 执行 Aggregate(聚合根)业务逻辑,产生 Domain Event,并写入 Event Store。
- 同时将 Domain Event 发布到 Event Bus。
- Query Service 订阅 Event Bus 并接收 Domain Event。
- Query Service 将变更同步到查询侧数据库(Read Model DB)。
下面先看 Event Sourcing(ES)的优缺点。
最开始只有 Event Sourcing
Event Sourcing 严格来说是在 DDD 圈子里被大规模推广的,其核心概念是:
数据库只存 Domain Event,而不是传统的 Domain State(领域对象当前状态)。
因为在 DDD 中,Aggregate 的变化会产生 Domain Event,所以理论上只保留事件流也可以重建最终状态。
这样做的好处通常有:
- 有所有事件的存档,意味着可以恢复到任一时间点下的状态。
- 因为有整个状态的变更历史记录,有利于排查问题。
- 一定程度上减少状态与事件"双写不一致"问题。若采用状态存储,需要确保状态持久化与事件发布在同一事务边界内;而 Event Sourcing 天然以事件为事实来源。
- 可以降低并发写冲突复杂度。事件通常是追加写,不是原地更新(但仍需要处理 duplicate event 和幂等)。
PS:第 3 点在非 Event Sourcing 架构里也可以通过 transactional outbox(发件箱模式)来解决。
为什么这里会出现 CQRS?
因为每次查询都从事件流重放来恢复状态,读取成本高,所以才需要 CQRS。
在大多数业务系统里,Query 次数远大于 Command。纯 ES 的"写优化"并不能直接满足查询性能诉求,因此通常要引入读模型(Read Model),也就是 CQRS 中的 Query 模式。
这个版本有什么问题?
- Write Service 不直接保存对象最终状态,某些"先读再写"的业务判断会变复杂,且会遇到读写延迟。
- 存储与运维成本较高(事件量膨胀、回放成本、快照策略、归档策略等)。
- 事件模型演进困难:当事件结构变化时,历史事件兼容、重放逻辑、Query 侧投影都要一起考虑。
- 数据同步是最终一致性,不是强一致性。
- 事务边界与失败补偿设计复杂(发布失败、重复消费、顺序保证、幂等处理等)。
版本 2:读写分离(更常见的工程化 CQRS)
我认为这才是 CQRS 在工程实践中的主流形态:将模型拆分为两套职责。
- Write:用 DDD 处理业务规则、状态变更与持久化。
- Query:围绕 UI 与报表需求,做高性能、可定制查询。
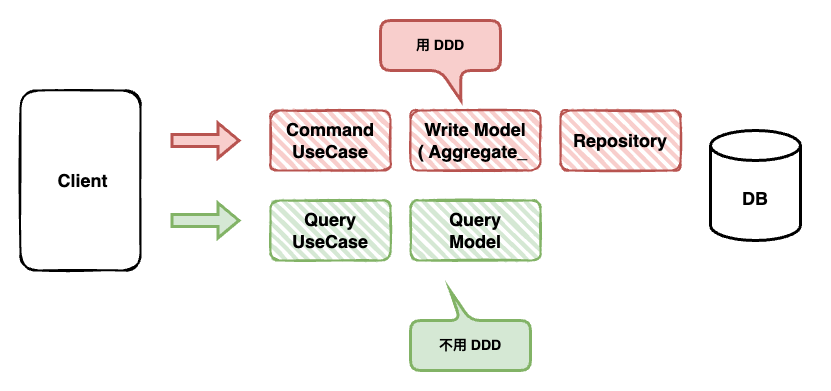
Write 与 Query 分开的原因在于:
Aggregate Model 并不天然适合查询场景:查询成本高,且字段结构不一定匹配前端展示需求。
这种设计方式的常见好处:
- 职责边界清晰:哪些是 Command、哪些是 Query 一目了然,能显著减少在查询流程里"顺手改数据"的问题。
- 模型解耦:不会为了查询便利去污染 Aggregate 模型,符合单一职责原则。
- 支持物理隔离与异构存储:例如写入 MySQL、同步到 PostgreSQL 或 Elasticsearch 做查询。
我在项目里通常采用这种方式。很多开发者也有类似实践,例如 Amichai Mantinband 在视频 Understand Clean Architecture in 7 Minutes 中提到的设计,本质上也是在 Application 层做命令与查询分离。

小结
实际项目中,大多数团队会优先落地"读写分离版 CQRS",而不是"Event Sourcing + CQRS 全家桶"。
Event Sourcing + CQRS 并非不能用,但它更适合这些场景:
- 对审计追踪、可回放、时点恢复有强需求。
- 团队具备事件建模、投影构建、幂等消费、事件版本演进的工程能力。
- 业务复杂度和收益足够覆盖其架构成本。
如果你的目标是"让系统边界清晰、查询性能更好、代码职责更干净",从读写分离开始通常是更稳妥的选择。