最近关于 Agent 自进化的讨论越来越多。今天我们来看论文「MOSS: Self-Evolution through Source-Level Rewriting in Autonomous Agent Systems」。论文中提出了一个名为 MOSS 的源码级自进化系统,面向生产级 Agent 基座,尝试把 Agent 的自我改进范围从 prompt、skill、memory 等文本层,推进到源码级重写,也就是直接修改系统代码。
过去我们说 Agent 自进化,通常指更新 prompt、沉淀 skill、写入 memory、调整 workflow。这些能力都有价值,但它们主要发生在文本层,改变的是模型可以读到、参考或调用的内容。MOSS 关注的问题是:如果 Agent 的失败不在这些文本对象里,而是在系统执行层,它能不能通过修改自身源码来完成自进化?
论文认为,生产级 Agent 的很多失败并不发生在模型"怎么想",而发生在系统"怎么跑"。比如消息路由错误、工具结果被错误合并、hook 执行顺序不对、session 状态传递出错。这些问题属于 Agent Harness,通常写在代码里,不在 prompt、skill 或 memory 里。因此,MOSS 讨论的不是"Agent 会不会改代码",而是 Agent 自进化如何从文本层推进到源码层,尤其是推进到 Harness 代码。
现有自进化 Agent 的边界
论文首先讨论了现有应用级自进化 self-evolving Agent 的一个共同限制:它们大多只能修改 text-mutable artifacts,也就是文本层面的可变对象。包括 skill、prompt、memory schema、workflow graph 等。一个 Agent 可以在任务失败后写一个新的 skill;可以调整系统提示词,让模型下次更注意某些规则;也可以更新 memory,把用户偏好或历史经验保存下来。这些方式能改善模型行为,但它们并不直接改变系统执行逻辑。
论文中,MOSS 对比了自己和 Hermes Agent、SkillClaw、GenericAgent、EvoAgentX 等系统的不同之处------把 harness 也纳入可修改范围。
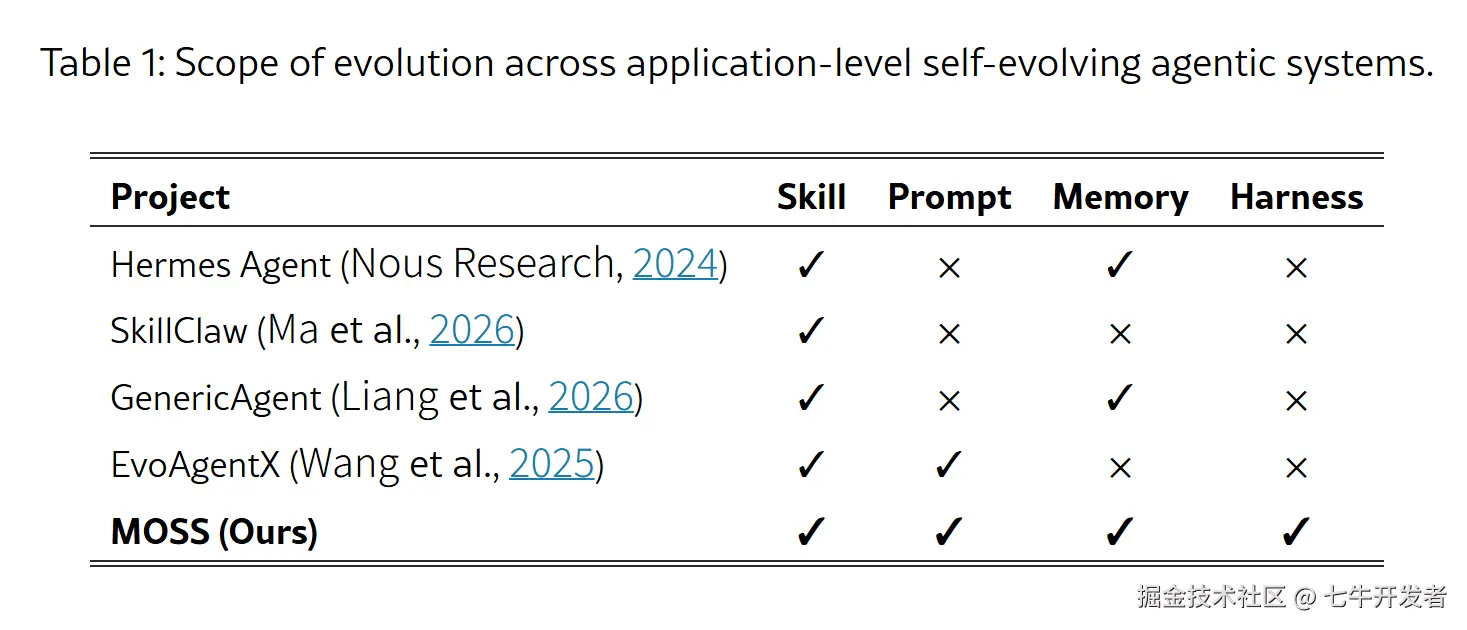
图注:不同自进化 Agent 的可修改范围对比------关键区别在于 MOSS 把 Harness 也纳入可进化对象。
上表指出了现有 Agent 自进化的一条边界:很多系统可以改模型读到的文本,但不能改系统实际执行的代码。
如前文提到一个生产级 Agent 系统不只有模型和 prompt,还包括工具调用、路由、状态管理、hook、调度、会话生命周期等组件。这些组件决定模型输出如何变成实际动作。这些地方一旦出错,只改 prompt 很难根治。
可以这么理解:prompt、skill、memory 可视作 Agent 的"认知材料";而 harness 才是 Agent 的"执行结构"。前者影响模型看到什么、倾向于怎么做;后者决定系统实际怎么走、工具怎么调、状态怎么变。
这也是论文强调源码级重写 source-level rewriting 的原因。通过修改源码层可以直接改变 routing、state invariants、dispatch、hook ordering 等系统行为;而修改文本层只能通过新指令间接影响结果。
论文认为,相比只能修改文本层内容的 text-mutable evolution,source-level adaptation(源码级自适应)面对的是一个更大的搜索空间。原因主要有四点:
-
源码是图灵完备的;
-
源码层是 prompt、skill、memory 等文本层修改的严格超集;
-
源码修改的效果更确定,不依赖模型每次是否读懂并遵守提示;
-
源码逻辑也不会因为长上下文堆积而逐渐失效。
简单来说,就是:如果 Agent 的问题在系统执行路径里,就应该去改执行路径,而不是只在 prompt 里提醒模型"下次注意"。
MOSS 的系统位置:自修复编排层
MOSS 不是一个新的基础模型,也不是一个单独的 coding agent。它更像一个围绕生产级 Agent 系统搭建的自修复编排层。论文中使用 OpenClaw 作为基座,也就是被进化的 Agent 系统。MOSS 自己负责收集失败、控制进化流程、调用外部 coding agent、验证候选版本,以及在用户授权后执行容器替换。
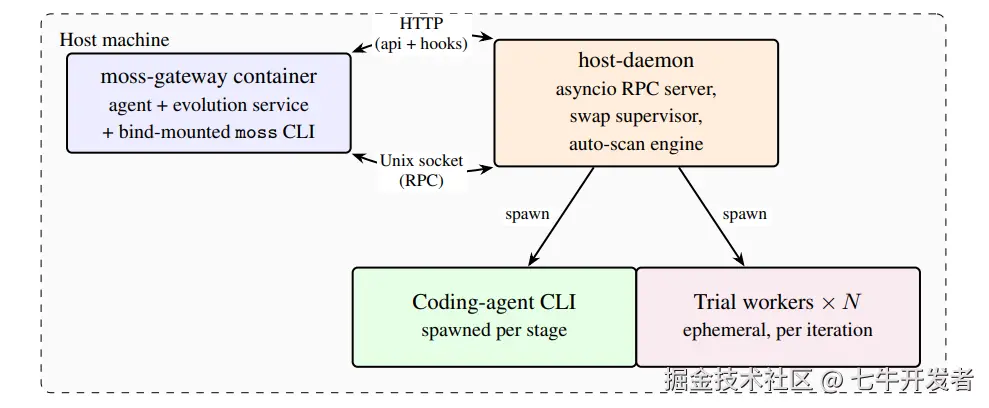
图注:上图展示了 MOSS 的主机侧拓扑。moss-gateway 运行用户侧 Agent 和进化服务,host-daemon 负责编排 coding-agent CLI、trial workers、镜像构建和容器替换。
这个图可以帮助理解 MOSS 的角色分工。moss-gateway container 是长时间运行的主容器,里面有用户实际交互的 Agent、进化服务和 moss CLI。host-daemon 跑在宿主机上,负责主容器不能或不适合自己完成的事情,比如启动外部 coding-agent CLI、构建候选镜像、启动 trial workers、执行 swap 和回滚。
这么设计有一个现实原因:容器替换不能由主容器自己完成。候选版本收敛后,旧容器需要停止并被新镜像替换;一旦主容器退出,它就不能再负责启动新容器。因此,MOSS 把容器生命周期和 swap supervisor 放在宿主机上的 host-daemon 里。
外部 coding-agent CLI 也是这个架构里的关键组件。MOSS 本身不绑定某个模型,而是通过 runner 接入 Claude Code、OpenAI Codex、DeepSeek-TUI、OpenCode 等工具。MOSS 负责阶段顺序、循环退出、判定和上线时机,coding agent 负责具体代码修改。也就是说,MOSS 不是要替代 coding agent,而是把 coding agent 放进一个有目标、有阶段、有验证、有上线控制的流程里。
如何把真实失败变成源码修复
让 Agent 修改自己的源码,听起来风险很高。MOSS 的处理方式不是让 Agent 随机修改自己,而是把每次进化都锚定到一批真实失败样本上。论文称之为 directed evolution。
这一点和很多benchmark-driven(基准测试驱动)的自进化系统不同。在研究环境里,我们可以让 Agent 面向一个固定 benchmark 反复试错,哪个版本分数高就保留哪个版本。但生产级 Agent 很难这样做。真实用户并不关心系统在某个榜单上多涨了几分,而更在乎自己遇到的问题有没有被修好。
所以,MOSS 的进化目标来自 production-failure batch(生产环境失败样本批次)。失败样本有两个来源:
-
后台周期性扫描用户 session JSONL,找出表现较弱的对话片段;
-
当用户在对话中表达不满时,Agent 可以调用
moss evo flag标记当前问题。
两类证据都会进入同一个 batch,后续的定位、计划、实现和验证都围绕这批失败展开。
这个设计解决的是一个基本问题:真实环境里,Agent 应该根据什么进化?MOSS 的答案是"根据真实失败修复"。它不要求 Agent 无方向地探索整个代码空间,而是要求每次修改都服务于一个明确目标:修复这批失败样本暴露出来的问题。
这也让源码级自修改更接近工程排障。开发者修线上问题时,通常不会先问"系统整体能不能更强",而是先看哪条链路失败、日志里有什么、能否复现、改哪个模块可以避免同类错误。MOSS 试图把这个流程自动化。
如何约束、验证和上线代码修改?
MOSS 并不是把整个代码库交给一个 coding agent,然后让它一次性完成诊断、计划、实现和验证。论文把一次进化拆成七个阶段:Locate、Plan、Plan-Review、Implement、Code-Review、Task-Evaluate、Verdict。
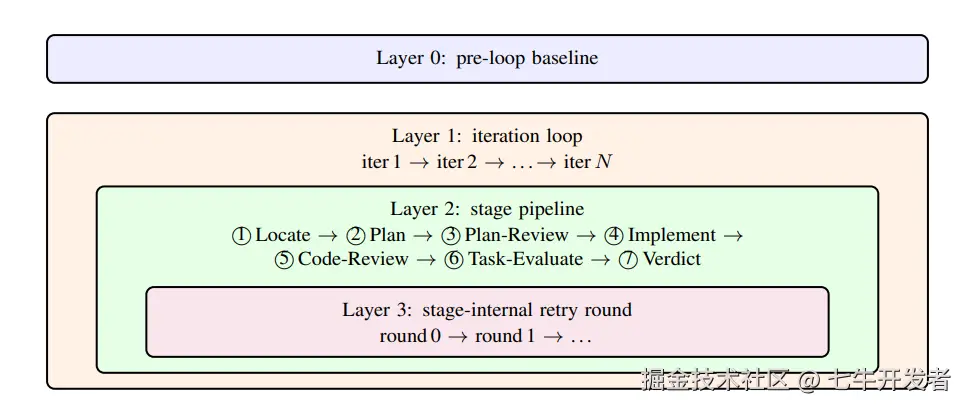
上图是 MOSS evolution 的四层结构:pre-loop baseline、iteration loop、stage pipeline,以及 stage 内部的 retry round。
这张图说明,MOSS 的进化不是一次性 patch,而是一个嵌套流程。最外层先有 pre-loop baseline,用来确定当前失败表现;然后进入 iteration loop,每一轮都执行固定的七阶段 pipeline;在 Plan-Review 和 Code-Review 这类质量门内部,还可以有多轮重试。
这七个阶段可以理解为一套机器可执行的工程修复流程:
-
Locate 只负责定位问题,不急着给修复方案;
-
Plan 负责提出修改计划,明确要改哪些文件、增加什么逻辑、哪些部分不该动;
-
Plan-Review 是第一个质量门,用来判断方案是否偏离架构或范围过窄;
-
Implement 才真正修改代码;
-
Code-Review 检查 diff 是否符合计划;
-
Task-Evaluate 负责对候选版本的运行结果打分;
-
Verdict 最后决定是否收敛、是否继续迭代,或者是否属于模型能力或架构限制。
这里的关键不在于阶段数量,而在于职责拆分。MOSS 不让 coding agent 一次性"想明白并改好",而是用阶段边界限制它的行为。计划要先被审查,代码要再被审查,运行结果还要单独评估。
对 Agent Harness 来说,只做静态代码审查或单元测试并不够。很多错误只有在真实执行链路里才会暴露出来,比如工具结果如何被模型消费、hook 顺序是否影响状态、session 生命周期是否正确、多个工具调用的输出是否能被准确归因。
因此,MOSS 在 Code-Review 之后还会进行 runtime 验证。host-daemon 会构建候选镜像,然后启动多个临时 trial workers。这些 trial workers 是短生命周期容器,用候选镜像运行同一批失败样本。任务完成后,MOSS 再比较候选版本和 baseline 的表现。
这和只跑单元测试的思路不同。MOSS 要验证的不是代码看起来是否合理,而是候选系统在同一批失败任务上是否产生了更好的行为。对于 Agent 系统来说,这个差别很关键。因为一个 patch 可能语法正确,也能通过局部测试,但在工具调用链、状态传递和上下文组织里仍然失败。
候选版本通过验证后,也不会直接替换线上系统。论文设计了用户授权步骤:当 evolution loop 给出 CONVERGED verdict 后,系统会通知用户,等待用户执行 moss evo apply。只有用户确认后,host-daemon 才会执行容器替换。
上线过程也不是简单重启。MOSS 使用原容器环境 swap:主容器被替换为候选镜像,但用户状态保存在独立 volume(数据卷)中,所以 sessions、memory、credentials、agent configs 等不会丢失。替换后,host-daemon 会进入 90 秒健康检查窗口,每 5 秒检查一次。只有连续 3 次通过,swap 才算成功;否则回滚到 last-known-good image(最后一个已知良好的镜像)。
所以,MOSS 真正强调的不是代码生成能力,而是把代码修改放进可验证、可回滚的工程闭环里。
OpenClaw 实验:它到底修了什么?
论文在 OpenClaw 上做了一个案例研究。OpenClaw 是一个生产级 agentic system,包含多渠道网关、插件和 hook 机制、session 和 skill 管理,以及持久化用户状态。实验使用 DeepSeek V3.2 作为底层模型。
实验任务来自 CLAWEval,覆盖 4 个 operations / compliance-audit 场景,可以概括为两类:SLA 合规审计 与 补货链路检查。
在 SLA 合规审计中,Agent 需要识别优先级为 P1 的违规工单,并依据不同的 SLA 规则计算其合规状态。
在补货链路检查中,Agent 需要跨调度任务、集成配置、库存水平等多个服务进行链路追踪,从而定位执行失败的任务、断开的集成配置,以及库存不足的商品。
这些任务有一个共同点:都要求 Agent 多次调用工具,并保持多实体之间的准确对应关系。baseline 表现并不好,四个任务平均分只有 0.2526,远远低于 0.75 的通过线。失败表现包括:只列出部分工单、无法判断部分合规状态、混淆客户名称,以及无法完整串起补货链路。
在 MOSS 的 Locate 阶段,研究者发现问题并不只是模型能力不足,而是出在执行框架的 tool-result handling(工具调用结果处理) 上。
具体来说,Agent 经常会选择一条比较通用的执行路径,也就是 generic execution path。但 mediator 并没有为这条路径准备对应的 annotation branch,因此工具返回的结果缺少必要标注。
另一个问题是,当 Agent 把多个查询合并成一个 shell 命令结构时,底层的 dispatch-synthesis pipeline 会把多个结果混在一起输出,导致后续很难判断每个结果分别来自哪个查询。
最终,模型看到的工具结果就不够清晰:它可能只能拿到一段难以归因的混合输出,于是后续回答就容易出现半截答案,或者把错误归因到不该归因的地方。
MOSS 最终的修复发生在 harness 层,也就是负责组织任务执行、工具调用、结果返回和状态流转的运行框架。它在 tool-result mediator(工具结果中介层) 中增加了一个 annotation branch,用于给工具返回结果补充更清晰的说明;当执行路径返回 multi-entity payload(多实体结果) 时,系统会注入更明确的使用提示,帮助 Agent 判断每一段结果分别对应什么对象。同时,它还在 before-tool-call hook chain 中增加了一个 pre-call deny gate,在工具真正被调用前拦截某些容易制造混乱的 batched-shell pattern(批量 shell 调用模式),引导 Agent 改用更容易解析的独立调用。论文提到,这次实现一共修改了 3 个文件,新增 177 行,删除 1 行。
这个 patch 的重点,不是提醒模型"回答时要更仔细",而是改变系统执行路径,让模型更难走向那些容易混淆结果的调用方式。换句话说,MOSS 修的不是回答风格,而是工具调用和结果处理链路。
经过一轮进化后,4 个任务的平均分从 0.2526 提升到 0.6100。其中,T138_restock_chain_check 从 0.2090 提升到 0.9049,超过了 0.75 的通过线。两个 SLA 任务也有所提升,但最终仍停留在 0.53 到 0.55 左右。
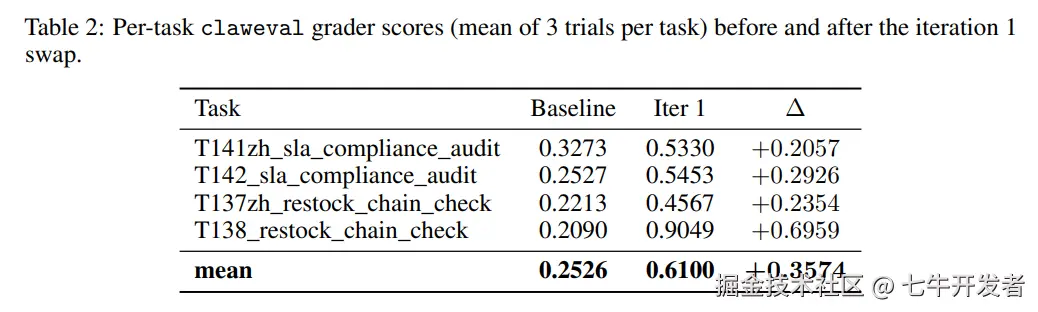
图注:论文中展示了四个 claweval 任务在 baseline 和 iteration 1 后的分数变化。平均分从 0.2526 提升到 0.6100。
这组结果的重点不只是分数提升,而是 MOSS 修复的位置。它没有只改 prompt 或 skill,而是定位并修改了 tool-result mediator 和 before-tool-call hook,也就是论文前面强调的 harness 层。这说明 source-level rewriting 确实可以修复一类 prompt、skill、memory 难以触达的问题。
但这个结果也有局限性。一次 harness patch 并没有解决所有任务难点。SLA 任务仍然存在 per-ticket 时间差计算和 SLA-tier 分类等问题,这些可能需要后续迭代或其他层面的改进。
论文的启发与边界
这篇论文对于正在做 AI 开发的朋友们的价值在于:
**1、不要把 Agent 优化只理解成 prompt 优化。**Prompt 很重要,但它只是 Agent 系统的一层。当应用进入生产阶段,工具返回格式、状态传递、hook 顺序、错误恢复、权限控制和部署回滚,都会影响最终效果。
**2、失败样本需要被系统化保存。**MOSS 的定向进化依赖失败样本。如果你希望 Agent 能持续改进,就需要记录关键执行 trace,保存工具调用输入输出,支持失败任务回放,并允许用户标记问题。没有这些数据,Agent 很难知道自己应该修哪里。
**3、AI Coding 要进入工程闭环。**让模型生成代码只是第一步,更重要的是把代码生成放到可审查、可测试、可回滚的流程里。对于 Agent 系统尤其如此,因为很多问题只有运行时才会暴露。trial worker、沙箱环境、候选镜像、健康检查和回滚机制,会成为 AI 修改系统代码时的基础设施。
未来 Agent 框架的竞争可能不只在"能接多少工具"或"能支持多少模型",还在于能不能把真实失败转化为可验证的系统修复。一个成熟的 Agent 框架,可能需要内置失败采集、trace 回放、代码修改、沙箱验证、用户授权和上线回滚这些能力。
当然,这篇论文的边界也比较明确。首先,实验规模较小,主要是四个任务上的案例研究。其次,进化 batch 和测试任务是同一批,因此结果更适合说明定向修复能力,而不是泛化能力。第三,源码级自修改天然有安全风险,比如错误 patch、隐藏副作用、权限扩大、供应链风险,以及对失败样本过拟合。论文已经设计了用户授权、健康检查和回滚,但安全治理仍然需要更多讨论。
另外,MOSS 仍然依赖外部 coding agent 完成具体代码修改。MOSS 负责流程和判定,但 patch 质量取决于外部 coding agent 的能力。随着 coding agent 能力提升,这类系统的效果可能会更好;但它也意味着 MOSS 的上限并不是由编排系统单独决定的。
总结
这篇论文讨论的其实是一个底层的问题:当 Agent 的失败来自工具链、状态管理、Hook 顺序或执行路径时,只改 prompt、skill 和 memory 并不能触达问题本身。
MOSS 给出的做法,是把真实失败样本转化为源码级修复目标,再通过分阶段计划、代码修改、运行时验证和容器级回滚,把这类修改纳入受控流程。它的价值不在于证明 Agent 已经可以完全自我进化,而在于展示了一条更接近生产系统的路径:让 Agent 不只是记录失败,而是有机会把失败转化为可验证、可回滚的系统修复。