本章定位:解决「AI 功能写好了,但无法面向用户」这个从开发到生产最关键的跨越。
核心主题 :用三项技术 解决三个具体问题,让你的 AI 服务能支撑真实用户访问。
前期回顾
开篇:一个真实困境
你花了几周时间,终于用 LangChain 搭好了一个 AI 问答机器人。本地运行一切正常:输入问题,等待 2 秒,得到答案。
然后你把它部署到服务器,迎来了第一批用户------
用户 A 发来问题,等了 2 秒,得到答案。😊
用户 B、C、D 同时 发来问题......用户 B 等了 2 秒,用户 C 等了 4 秒,用户 D 等了 6 秒。😡
用户 E 问了一个「什么是 Python 装饰器」------这个问题你的系统今天已经回答了 500 次,每次都花 2 秒、调用 1 次付费 API。💸
前端同学想接入你的 AI,问你 API 地址,你愣了:我是个 Python 脚本,没有 API......😅
这三个场景,浓缩了 AI 服务从"能跑"到"能用"之间的三道坎:
| 问题 | 现象 | 根本原因 |
|---|---|---|
| 多用户并发慢 | 10 个用户排队等,第 10 个等 20 秒 | 同步调用:一次只能处理一个请求 |
| 无法对外提供服务 | 前端/App/其他系统无法调用 AI | 没有 HTTP API,只是个脚本 |
| 重复调用浪费钱 | 同一个问题每天调用 1000 次 | 没有缓存,每次都去调用付费 API |
本章的目标,就是用三项技术逐一解决这三个问题,最终搭出一个可以真正面向用户的生产级 AI 服务。
本章你将学到
- ✅ 异步(async/await):让 10 个并发请求从等待 20 秒变成等待 2 秒
- ✅ FastAPI:用 20 行代码把 AI 能力封装成任何客户端都能调用的 REST API
- ✅ LLM 缓存:让重复问题 0 延迟、0 费用,把 API 成本降低 30-70%
- ✅ 三者整合:搭建完整的生产级 AI 服务架构
前置条件
| 要求 | 说明 |
|---|---|
| Python 版本 | 3.10+ |
| 已完成章节 | 第1章(LLM 基础调用)、第3章(Chain 链式调用) |
| 环境变量 | DASHSCOPE_API_KEY 已配置 |
| 安装依赖 | uv sync(基础)、uv sync --extra api(FastAPI 端点) |
全局架构:三项技术如何协作
在深入每项技术之前,先看清楚它们共同构成的完整系统:
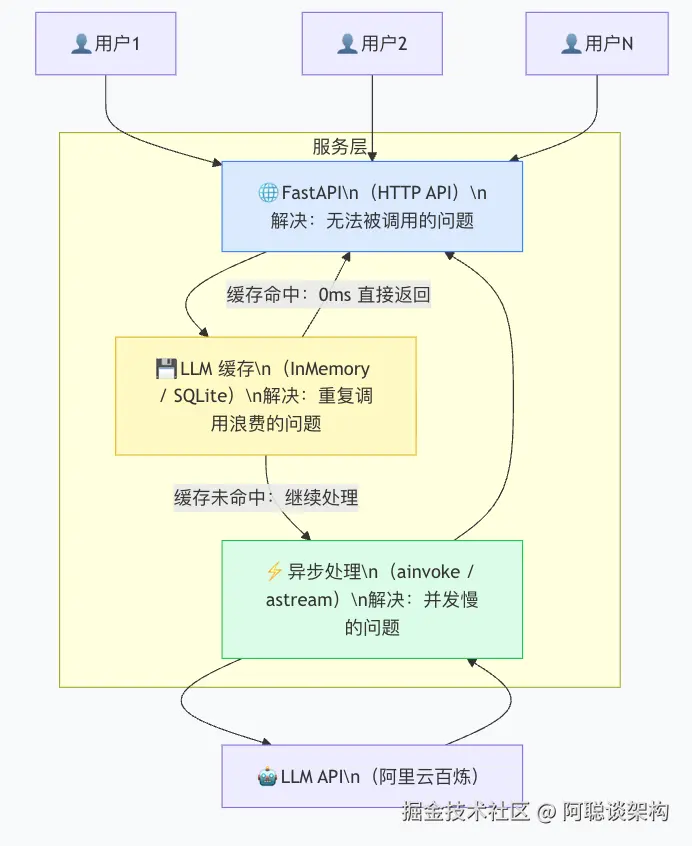
读图方式:
- 用户请求进入 FastAPI(解决"可被调用"问题)
- FastAPI 先检查 缓存(解决"重复调用"问题)
- 缓存未命中,用 异步 方式调用 LLM(解决"并发慢"问题)
三项技术各司其职,串联成完整的服务链路。
一、问题一:并发慢 → 用异步解决
1.1 同步调用为什么慢?
LLM API 的调用分为两个阶段:
- 网络 I/O 等待:发送请求、等服务器响应(~95% 的时间)
- CPU 计算:解析响应、处理数据(~5% 的时间)
同步调用的问题是:在等待网络 I/O 期间,线程什么也做不了,只是阻塞地等待:
ini
同步处理 4 个请求(每个 2 秒):
时间轴 → 0s 2s 4s 6s 8s
请求1: [───等待 LLM 响应───]✓
请求2: [───等待───]✓
请求3: [───等待───]✓
请求4: [───等待───]✓
总耗时:8 秒(4 × 2秒)1.2 异步调用如何提速?
异步(async/await)的核心思想:等待期间,不是发呆,而是去处理其他请求。
ini
异步处理 4 个请求(每个 2 秒):
时间轴 → 0s 2s
请求1: [───发出,等待响应─────]✓
请求2: [───发出,等待响应─────]✓ ← 同时发出!
请求3: [───发出,等待响应─────]✓
请求4: [───发出,等待响应─────]✓
总耗时:~2 秒(≈ 最慢的那一个)提速原理 :4 个请求同时发出,同时在"等",但等待是交错的------等待期间线程会切换去处理其他协程。这正是 Python asyncio 事件循环干的事。
1.3 Python asyncio 三个核心概念(速览)
理解异步只需要掌握三个概念:
python
# ① async def ------ 定义一个"可以暂停的函数"(协程)
async def fetch_answer(question: str) -> str:
response = await llm.ainvoke(question) # ← await 是暂停点
return response.content
# ② await ------ "暂停当前函数,让出控制权,等待结果"
# 只能在 async def 内部使用
# 在等待期间,事件循环可以去执行其他协程
# ③ asyncio.gather() ------ "同时执行多个协程,等所有都完成"
async def main():
results = await asyncio.gather(
fetch_answer("问题1"), # 三个协程同时运行
fetch_answer("问题2"),
fetch_answer("问题3"),
)
return results
# asyncio.run() ------ 同步代码进入异步世界的入口
answers = asyncio.run(main())1.4 LangChain 异步 API 完整对照表
LangChain 所有调用方法都有对应的异步版本,用法完全相同:
| 同步方法 | 异步对应 | 适用场景 |
|---|---|---|
llm.invoke(msg) |
await llm.ainvoke(msg) |
单个请求,需要完整响应 |
llm.stream(msg) |
async for chunk in llm.astream(msg) |
流式输出,打字机效果 |
chain.batch(inputs) |
await chain.abatch(inputs) |
批量并发处理多条数据 |
1.5 代码实战:性能对比
代码文件:lessons/13_production/01_async_llm.py
python
import asyncio
import os
import time
from typing import Optional
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
temperature=0.3,
)
# ── 同步版本:逐个等待,串行执行 ────────────────────────────────
def sync_batch(questions: list[str]) -> list[str]:
"""同步处理:每个问题等待完成,才处理下一个。"""
results = []
for q in questions:
response = llm.invoke([HumanMessage(content=q)]) # 阻塞 2 秒
results.append(response.content[:50])
return results
# ── 异步版本:同时发出所有请求 ──────────────────────────────────
async def async_batch(questions: list[str]) -> list[str]:
"""异步并发:同时发出所有请求,等最慢的那个返回。"""
async def one(q: str) -> str:
response = await llm.ainvoke([HumanMessage(content=q)]) # 非阻塞
return response.content[:50]
results = await asyncio.gather(*[one(q) for q in questions])
return list(results)
# ── 测试 ────────────────────────────────────────────────────────
questions = [
"用一句话介绍 Python",
"用一句话介绍 LangChain",
"用一句话介绍向量数据库",
"用一句话介绍 Transformer",
]
print(f"处理 {len(questions)} 个问题\n")
t0 = time.time()
sync_batch(questions)
print(f"同步耗时:{time.time() - t0:.2f}s") # 预期 ~8 秒
t0 = time.time()
asyncio.run(async_batch(questions))
print(f"异步耗时:{time.time() - t0:.2f}s") # 预期 ~2 秒实测结果参考(因网络状况而异):
| 并发数 | 同步耗时 | 异步耗时 | 提速倍数 |
|---|---|---|---|
| 4 个请求 | ~8 秒 | ~2 秒 | 4x |
| 10 个请求 | ~20 秒 | ~2-3 秒 | 7-10x |
| 翻译 50 条 | ~100 秒 | ~5-8 秒 | 12-20x |
1.6 生产必备:超时控制 + 并发限制
直接 asyncio.gather 有两个生产问题:
- 没有超时限制:一个慢请求会"拖死"整批任务
- 没有并发限制:100 个请求同时发出,可能触发 API 速率限制(429 错误)
python
async def safe_invoke(question: str, timeout: float = 15.0) -> Optional[str]:
"""带超时控制的安全调用------生产环境必须使用这个版本。"""
try:
# asyncio.wait_for:超过 timeout 秒则抛 asyncio.TimeoutError
response = await asyncio.wait_for(
llm.ainvoke([HumanMessage(content=question)]),
timeout=timeout,
)
return response.content
except asyncio.TimeoutError:
print(f" ⏰ 超时(>{timeout}s):{question[:30]}...")
return None
except Exception as e:
print(f" ❌ 调用失败:{e}")
return None
async def batch_with_limit(
questions: list[str],
max_concurrent: int = 5, # 同时最多 5 个请求
) -> list[Optional[str]]:
"""带并发限制的批量处理------防止触发 API 速率限制。"""
# Semaphore(信号量):控制同时持有"通行证"的协程数量上限
semaphore = asyncio.Semaphore(max_concurrent)
async def one_with_sem(q: str) -> Optional[str]:
async with semaphore: # 获取通行证(超限则排队等)
return await safe_invoke(q)
# with 块结束自动释放通行证,下一个排队协程可以进来
return list(await asyncio.gather(*[one_with_sem(q) for q in questions]))1.7 流式输出:打字机效果
python
async def stream_response(question: str) -> None:
"""流式输出:边生成边显示,不用等全部完成才显示。"""
print("回答:", end="", flush=True)
async for chunk in llm.astream([HumanMessage(content=question)]):
# 每个 chunk 是 1-3 个字符,end="" 不换行,flush=True 立即刷新
print(chunk.content, end="", flush=True)
print() # 结束换行
asyncio.run(stream_response("用 100 字介绍什么是 RAG"))二、问题二:无法被调用 → 用 FastAPI 解决
2.1 为什么需要 API?
异步解决了并发问题,但你的 AI 还只是个 Python 脚本。
前端工程师用 React,他们不能 import 你的 Python 模块。移动 App 用 Swift / Kotlin,同样无法调用 Python 代码。其他后端服务要接入你的 AI 能力,也需要一个标准接口。
解决方案:将 AI 能力封装为 HTTP API。
HTTP API 是互联网通信的通用语言------任何语言、任何平台,只要能发 HTTP 请求,就能调用你的 AI。
2.2 FastAPI 是什么?为什么选它?
FastAPI 是 Python 最流行的现代 Web 框架,三个核心优势让它特别适合 AI 服务:
| 特性 | 说明 | AI 服务的价值 |
|---|---|---|
| 原生异步 | 基于 Python asyncio,天然支持 async def |
与 LangChain 异步 API 无缝结合 |
| 自动文档 | 访问 /docs 自动生成可交互的 Swagger UI |
无需手写 API 文档 |
| Pydantic 校验 | 请求/响应自动类型校验和转换 | 防止非法输入崩溃 AI 服务 |
2.3 SSE(Server-Sent Events):流式输出的标准协议
普通 HTTP 请求是"问-答"模式:发请求 → 等完整响应。但 AI 流式输出需要"持续推送":服务端边生成边推送文字片段。
SSE(Server-Sent Events) 正是为此设计的:浏览器/客户端发起一个 HTTP 连接,服务端通过这个连接持续推送数据片段,直到发送结束信号。ChatGPT 的打字机效果用的就是 SSE。
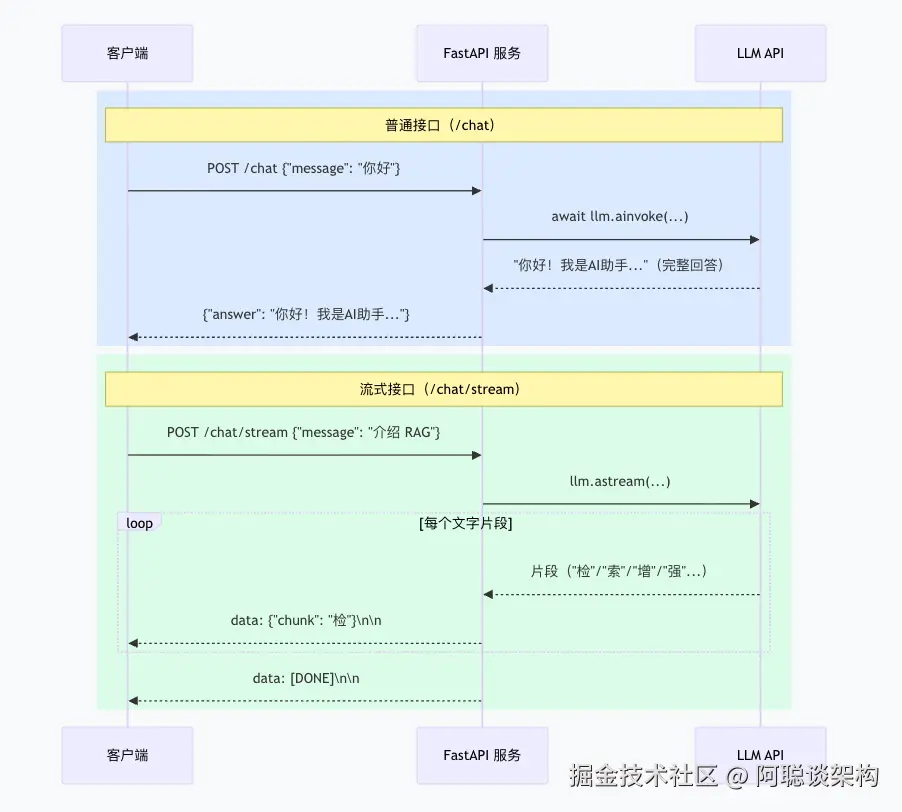
2.4 完整 FastAPI 应用代码
代码文件:lessons/13_production/02_fastapi_app.py
python
import asyncio
import os
from typing import AsyncGenerator, Optional
import uvicorn
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import StreamingResponse
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from dotenv import load_dotenv
load_dotenv()
# ── FastAPI 应用初始化 ─────────────────────────────────────────
app = FastAPI(
title="AI 问答服务",
description="基于 LangChain + 阿里云百炼 的 AI 问答 API",
version="1.0.0",
)
# CORS 中间件:允许浏览器跨域调用(生产环境应替换 * 为具体域名)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# ── LLM 工厂(每次请求动态创建,支持按请求自定义 temperature)─
def create_llm(temperature: float = 0.7) -> ChatOpenAI:
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
raise ValueError("DASHSCOPE_API_KEY 环境变量未设置")
return ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=api_key,
temperature=temperature,
)
# ── Pydantic 请求/响应模型(自动校验输入,防止非法参数)────────
class ChatRequest(BaseModel):
message: str = Field(..., description="用户消息", min_length=1, max_length=4000)
system_prompt: Optional[str] = Field(
default="你是一个有帮助的 AI 助手,请用中文回答。",
description="系统提示词",
)
temperature: float = Field(default=0.7, ge=0.0, le=2.0)
class ChatResponse(BaseModel):
answer: str = Field(description="AI 的回答")
model: str = Field(description="使用的模型")
# ── 端点一:健康检查(监控/负载均衡探针使用)──────────────────
@app.get("/health")
async def health_check() -> dict:
"""返回服务状态,用于 Kubernetes 就绪探针或负载均衡健康检查。"""
return {
"status": "healthy",
"llm_configured": bool(os.getenv("DASHSCOPE_API_KEY")),
}
# ── 端点二:标准聊天(等待完整回答)──────────────────────────
@app.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest) -> ChatResponse:
"""等待 LLM 生成完整回答后返回。
适用:需要完整答案后再处理的场景(如结果分析、格式化输出)。
"""
try:
llm = create_llm(temperature=request.temperature)
response = await llm.ainvoke([
SystemMessage(content=request.system_prompt or "你是一个有帮助的 AI 助手。"),
HumanMessage(content=request.message),
])
return ChatResponse(answer=response.content, model="qwen-plus")
except ValueError as e:
raise HTTPException(status_code=500, detail=str(e)) from e
except Exception as e:
raise HTTPException(status_code=502, detail=f"LLM 调用失败: {str(e)}") from e
# ── 端点三:流式聊天(SSE 逐字推送)──────────────────────────
@app.post("/chat/stream")
async def chat_stream(request: ChatRequest) -> StreamingResponse:
"""以 SSE 格式逐块推送 AI 回答,实现打字机效果。
适用:交互式聊天界面,长文本生成,需要减少首字节延迟的场景。
SSE 数据格式(每行):data: <内容>\\n\\n
结束信号:data: [DONE]\\n\\n
"""
async def generate() -> AsyncGenerator[str, None]:
try:
llm = create_llm(temperature=request.temperature)
messages = [
SystemMessage(content=request.system_prompt or "你是一个有帮助的 AI 助手。"),
HumanMessage(content=request.message),
]
async for chunk in llm.astream(messages):
if chunk.content:
# SSE 标准格式:每条消息以 "data: " 开头,以 "\n\n" 结尾
yield f"data: {chunk.content}\n\n"
yield "data: [DONE]\n\n"
except Exception as e:
yield f"data: [ERROR] {str(e)}\n\n"
return StreamingResponse(
generate(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache", # 禁止代理缓存
"X-Accel-Buffering": "no", # 禁止 Nginx 缓冲(确保实时推送)
},
)
# ── 启动服务 ──────────────────────────────────────────────────
if __name__ == "__main__":
print("🚀 AI 问答服务启动中...")
print(" 文档地址:http://localhost:8000/docs")
uvicorn.run(app, host="0.0.0.0", port=8000, log_level="info")2.5 测试你的 API
bash
# 1. 安装依赖
uv sync --extra api
# 2. 启动服务
python 02_fastapi_app.py
# 3. 浏览器打开 http://localhost:8000/docs (Swagger UI)
# 4. 命令行测试------标准聊天
curl -X POST http://localhost:8000/chat \
-H "Content-Type: application/json" \
-d '{"message": "用一句话介绍 RAG 技术"}'
# 5. 命令行测试------流式聊天(--no-buffer 禁用 curl 的输出缓冲)
curl -X POST http://localhost:8000/chat/stream \
-H "Content-Type: application/json" \
-d '{"message": "详细介绍一下 Python 的异步编程"}' \
--no-buffer预期输出(流式接口):
kotlin
data: Python
data: 的
data: 异步
data: 编程
data: 基于
data: asyncio
...
data: [DONE]三、问题三:重复调用浪费 → 用缓存解决
3.1 重复调用有多浪费?
先用数字说话:
arduino
场景:一个 FAQ 问答系统,用户每天问 10,000 个问题
其中 30% 是重复问题(如"什么是 Python"被问了 3,000 次)
没有缓存:
10,000 次 × 0.01元/次 = 100元/天
其中 3,000 次重复调用 = 30元/天(纯浪费)
有缓存:
第一次问"什么是 Python":调用 LLM(0.01元)
后续 2,999 次:命中缓存(0元,0延迟)
节省:2,999 × 0.01 = 29.99元/天
一年下来:29.99 × 365 ≈ 11,000 元缓存的价值不只是省钱,命中缓存的响应时间从 ~2000ms 降至 ~1ms------用户完全感知不到延迟。
3.2 LangChain 缓存的工作原理
ini
缓存键 = hash(模型名称 + 提示词 + temperature)
↓
相同模型 + 相同问题 + 相同 temperature = 相同 key = 命中缓存
注意:temperature > 0 时,同一问题每次输出不同,
缓存的意义是保证"第二次问同样的问题,返回第一次的答案"
仅适合 temperature=0 的确定性场景开启缓存只需一行代码,之后所有 LLM 调用自动使用缓存,无需修改业务代码:
python
from langchain_core.globals import set_llm_cache
set_llm_cache(InMemoryCache()) # 这一行之后,所有 llm.invoke() 自动缓存3.3 两种内置缓存选型
方案 A:InMemoryCache(开发/测试首选)
python
# 进程内存缓存------重启后失效,适合开发调试
import os
import time
from langchain_core.globals import set_llm_cache
from langchain_community.cache import InMemoryCache
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
temperature=0, # ← 缓存必须用 temperature=0(确定性输出)
)
set_llm_cache(InMemoryCache()) # 开启内存缓存
question = "Python 中什么是装饰器?用一句话回答"
# 第一次调用:缓存未命中,实际调用 LLM
t0 = time.time()
r1 = llm.invoke([HumanMessage(content=question)])
print(f"第一次(LLM 调用):{time.time()-t0:.3f}s → {r1.content[:60]}")
# 第二次调用:相同问题,命中缓存,直接返回
t0 = time.time()
r2 = llm.invoke([HumanMessage(content=question)])
print(f"第二次(缓存命中):{time.time()-t0:.3f}s → {r2.content[:60]}")
# 典型输出:
# 第一次(LLM 调用):2.135s → 装饰器是一种函数,用于在不修改原函数代码的情况下...
# 第二次(缓存命中):0.001s → 装饰器是一种函数,用于在不修改原函数代码的情况下...方案 B:SQLiteCache(单机生产推荐)
python
# SQLite 文件缓存------程序重启后缓存仍然有效
from langchain_community.cache import SQLiteCache
# 缓存数据存储在本地 SQLite 文件
# 程序重启后,已缓存的答案依然存在
set_llm_cache(SQLiteCache(database_path="./llm_cache.db"))
questions = [
"什么是 LangChain?一句话",
"什么是向量数据库?一句话",
"什么是 RAG?一句话",
]
print("第一轮(实际调用 LLM,写入缓存):")
for q in questions:
t0 = time.time()
r = llm.invoke([HumanMessage(content=q)])
print(f" [{time.time()-t0:.2f}s] {q[:20]}... → {r.content[:40]}")
print("\n第二轮(全部命中 SQLite 缓存,即使重启程序也一样快):")
for q in questions:
t0 = time.time()
r = llm.invoke([HumanMessage(content=q)])
print(f" [{time.time()-t0:.3f}s] {q[:20]}... → {r.content[:40]}")
set_llm_cache(None) # 测试完毕关闭缓存3.4 缓存选型指南
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 本地开发、快速调试 | InMemoryCache |
无需文件,进程内零配置 |
| 单机生产部署 | SQLiteCache |
重启后缓存保留,无需额外服务 |
| 多进程 / 多机部署 | RedisCache(langchain-community) |
分布式共享,进程间隔离安全 |
注意:多个 uvicorn worker 进程共写同一个 SQLite 文件会有锁竞争。多进程生产环境必须用 Redis 缓存。
四、三者整合:完整生产级 AI 服务
现在把三项技术整合成一个服务,看看它们如何协同工作。
代码文件:lessons/13_production/02_fastapi_app.py(启动即包含完整功能)
python
"""
三技术整合示意(不可单独运行,仅展示整合逻辑):
FastAPI(接口层)+ 异步(并发处理)+ 缓存(重复命中)
"""
from langchain_core.globals import set_llm_cache
from langchain_community.cache import SQLiteCache
# ① 应用启动时:开启全局缓存(一次配置,所有请求自动受益)
set_llm_cache(SQLiteCache(database_path="./llm_cache.db"))
# ② FastAPI 端点中:异步调用 LLM(LangChain 内部自动检查缓存)
@app.post("/chat")
async def chat(request: ChatRequest) -> ChatResponse:
llm = create_llm(temperature=0) # temperature=0 才能命中缓存
# ainvoke 内部流程:
# 1. 检查缓存 → 命中 → 直接返回(0ms,0成本)
# 2. 未命中 → 异步调用 LLM → 存入缓存 → 返回
response = await llm.ainvoke(messages)
return ChatResponse(answer=response.content, model="qwen-plus")三技术协同的效果:
| 场景 | 无任何优化 | 三技术整合后 |
|---|---|---|
| 10 用户并发同一问题 | 第 10 人等 20 秒 | 第一人等 2 秒,其余 9 人等 <1ms |
| 10 用户并发不同问题 | 第 10 人等 20 秒 | 所有人等 ~2 秒 |
| 前端如何接入 | 无法接入(Python 脚本) | 调用 HTTP API 即可 |
| 1000 次重复问题/天 | 1000 次 API 调用 | 1 次 LLM + 999 次缓存命中 |
4.1 生产启动配置
bash
# 开发模式(单进程,热重载)
python 02_fastapi_app.py
# 生产模式------方式1:uvicorn 直接启动(单机推荐)
uvicorn 02_fastapi_app:app \
--host 0.0.0.0 \
--port 8000 \
--workers 1 # 使用 SQLiteCache 时保持单进程;用 Redis 时可增加
# 生产模式------方式2:Gunicorn + Uvicorn(更健壮的进程管理)
# 需先 pip install gunicorn
gunicorn 02_fastapi_app:app \
--workers 1 \
--worker-class uvicorn.workers.UvicornWorker \
--bind 0.0.0.0:8000 \
--timeout 60 \
--access-logfile -五、常见错误与排查
| 错误 | 原因 | 解决方法 |
|---|---|---|
RuntimeError: This event loop is already running |
在 Jupyter Notebook 或已有事件循环的环境里调用 asyncio.run() |
改为直接 await,或安装 nest_asyncio 后调用 nest_asyncio.apply() |
RateLimitError: 429 |
并发请求超过 API 速率限制 | 用 asyncio.Semaphore(5) 控制最大并发数 |
| 流式响应前端收不到数据 | Nginx 等代理缓冲了 SSE 响应 | 响应头加 X-Accel-Buffering: no;Nginx 配置 proxy_buffering off |
| SQLiteCache 多进程冲突 | 多个 uvicorn worker 同时写同一个 SQLite 文件 | 多进程部署换用 RedisCache |
| 缓存命中但答案对不上 | temperature > 0,缓存存储了某一次随机输出 |
只在 temperature=0 的确定性场景使用缓存 |
asyncio.TimeoutError 频繁触发 |
超时时间设置过短,或 LLM API 响应偏慢 | 调大 timeout 参数;先监控平均响应时间再设阈值 |
六、关键决策速查
bash
我的 AI 服务要对外提供接口吗?
→ 是 → 用 FastAPI(02_fastapi_app.py)
→ 否,只是批量脚本 → 跳过 FastAPI,只用 asyncio
我需要支持打字机效果吗?
→ 是 → 用 /chat/stream 端点 + SSE(astream + StreamingResponse)
→ 否 → 用 /chat 端点(ainvoke + 完整响应)
我有并发用户吗?
→ 是 → 必须用 async def 端点 + ainvoke(FastAPI 默认就是异步)
→ 否,批处理脚本 → asyncio.gather + Semaphore 限速
我的 API 调用重复率高吗?(FAQ 问答、文档分析等)
→ 高(>20%)→ 加缓存,明显降低成本和延迟
→ 低(创意写作、随机生成)→ 不适合缓存
单机还是多机部署?
→ 单机 → SQLiteCache
→ 多机 / 多进程 → RedisCache本章小结
r
学了什么 解决什么 带来什么
──────────────────────────────────────────────────────────────
异步 (ainvoke/astream) → 并发慢(N×T 秒) → ~T 秒(近似并发数无关)
FastAPI + SSE → 无法被外部调用 → 任何客户端可调用 HTTP API
LangChain 缓存 → 重复调用浪费 → 命中时 0ms 0 成本
三者整合 → 无法上生产的脚本 → 可面向用户的生产级 AI 服务技术是工具,产品是目的。掌握这三项,你的 AI 就从"只有我能用"变成了"所有人都能用"。
下一步探索
完成本章后,你已掌握 AI 服务从开发到生产的完整技能链。进阶方向:下一步继续学习一些扩充的知识点,多模态AI实践
AI入门开发系列文章合集
作者:阿聪谈架构公众号:阿聪谈架构 (分享后端架构 / AI / Java 技术文章)
相关代码关注公众号:【阿聪谈架构】 回复:AI专栏代码