目录
[一、什么是 JMM](#一、什么是 JMM)
[二、为什么需要 JMM](#二、为什么需要 JMM)
[1. CPU缓存导致可见性问题](#1. CPU缓存导致可见性问题)
[2. 指令重排序导致有序性问题](#2. 指令重排序导致有序性问题)
[3. 线程切换导致原子性问题](#3. 线程切换导致原子性问题)
[三、JMM 的核心抽象模型](#三、JMM 的核心抽象模型)
[主内存(Main Memory)](#主内存(Main Memory))
[工作内存(Working Memory)](#工作内存(Working Memory))
[四、JMM 引发的三大并发问题](#四、JMM 引发的三大并发问题)
[1. 可见性问题](#1. 可见性问题)
[2. 原子性问题](#2. 原子性问题)
[3. 有序性问题](#3. 有序性问题)
[五、JMM 如何解决这些问题](#五、JMM 如何解决这些问题)
[六、Happens-Before 规则](#六、Happens-Before 规则)
[七、JMM 的实现手段](#七、JMM 的实现手段)
一、什么是 JMM
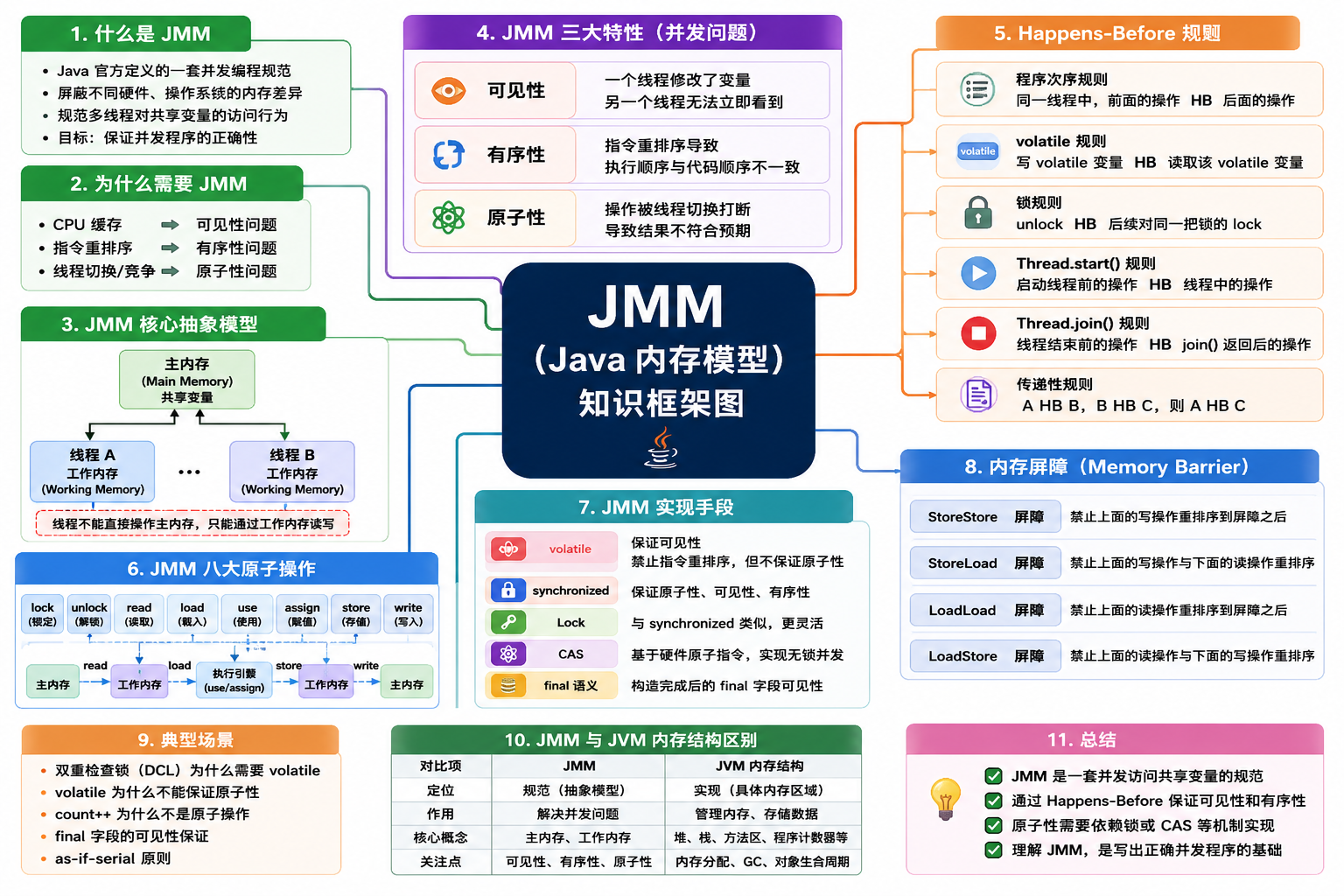
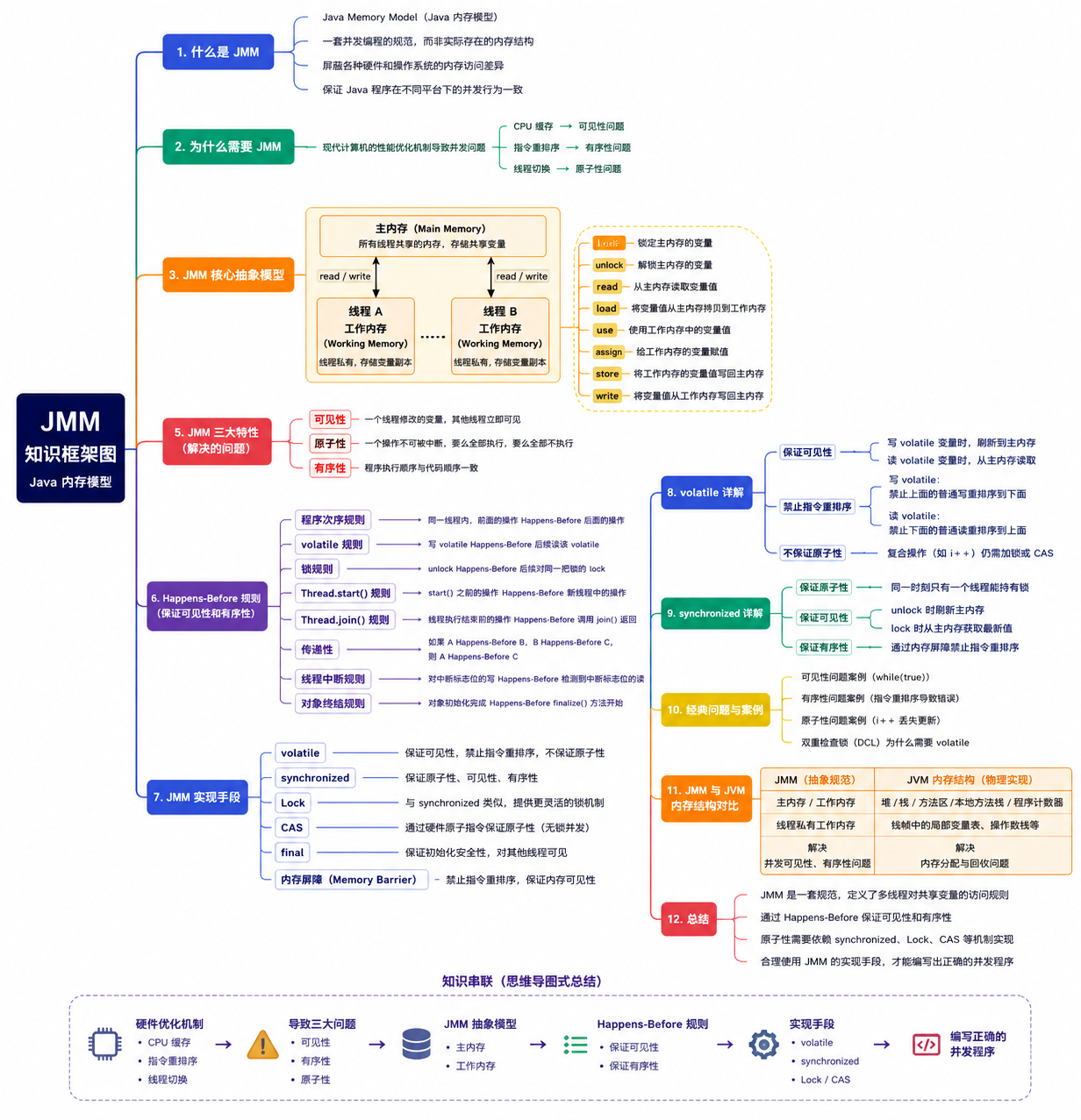
JMM(Java Memory Model,Java 内存模型)是 Java 官方定义的一套并发编程规范
它不是实际存在的内存结构,而是一套规则,用于规范多线程环境下共享变量的访问行为
JMM 的目标是:
-
屏蔽不同 CPU 架构的差异
-
屏蔽不同缓存模型的差异
-
保证 Java 程序在不同平台上的并发行为一致
JMM 就是 Java 为多线程读写共享变量制定的一套规则
二、为什么需要 JMM
现代计算机为了提升运行效率,引入了大量性能优化机制,这些优化让程序运行得更快,但同时也给多线程编程带来了新的问题
主要包括:
-
CPU缓存
-
指令重排序
-
线程切换
这些机制分别对应并发编程中的:
-
可见性问题
-
有序性问题
-
原子性问题
1. CPU缓存导致可见性问题
为什么需要CPU缓存
CPU的执行速度远远快于内存,所以为了减少CPU等待内存的时间,现代计算机引入了多级缓存:
CPU寄存器
↓
L1 Cache
↓
L2 Cache
↓
L3 Cache
↓
主内存(RAM)
当CPU读取变量时:
java
int count = 0;通常不会每次都访问主内存,而是先把数据加载到缓存中,这样可以大幅提高性能:
主内存
↓
CPU缓存
↓
CPU执行
CPU缓存带来的问题
假设存在共享变量:
java
boolean flag = true;线程A:
java
while (flag) {
}线程B:
java
flag = false;按照直觉:
线程B修改flag
↓
线程A退出循环
但实际运行时:
线程A可能永远不会退出
原因是:线程A把flag=true缓存到了CPU缓存
之后一直读取缓存:
CPU缓存
flag=true
线程B虽然修改了:
主内存
flag=false
但线程A并没有重新读取主内存,因此就会导致 while(true)无限循环
这就是可见性问题:
一个线程修改了变量,另一个线程无法立即看到最新值
2. 指令重排序导致有序性问题
什么是指令重排序
为了提高CPU执行效率,编译器和CPU会对指令顺序进行优化
例如:
java
int a = 1;
int b = 2;理论执行顺序:
a=1
↓
b=2
但实际上可能执行:
b=2
↓
a=1
因为:两个操作互不依赖,执行结果完全一致
这种优化称为:
Instruction Reordering
指令重排序
指令重排序带来的问题
假设:
java
int num = 0;
boolean ready = false;线程A:
java
num = 42;
ready = true;线程B:
java
if (ready) {
System.out.println(num);
}正常理解:
num=42
↓
ready=true
因此:
ready=true时
num一定是42
但实际上CPU可能重排序:
java
ready = true;
num = 42;于是出现:
线程B读取ready=true
线程B读取num=0
最终输出:0
这就是有序性问题:
程序执行顺序与代码编写顺序不一致
3. 线程切换导致原子性问题
什么是线程切换
CPU核心数量有限,例如:8核CPU
但程序中可能有:100个线程
CPU无法同时执行所有线程,因此操作系统会不断切换:
线程A
↓
线程B
↓
线程C
↓
线程A
这种过程称为:上下文切换(Context Switch)
线程切换带来的问题
假设:
java
int count = 0;两个线程同时执行:
java
count++;很多人认为:最终结果为2
实际上:count++; 并不是原子操作
底层会拆成:
读取count
↓
count+1
↓
写回count
假设执行过程如下:
线程A:
读取count=0
此时发生线程切换
线程B:
读取count=0
count+1
写回count=1
再次切换回线程A:
count+1
写回count=1
最终结果:
count=1
而不是:count=2
这就是原子性问题:
一个操作在执行过程中被其他线程打断,导致结果不符合预期
4、小结
现代计算机为了提升性能,引入了:
CPU缓存
↓
导致可见性问题
指令重排序
↓
导致有序性问题
多个线程对共享数据进行竞争
↓
导致原子性问题
为了统一规范这些行为,屏蔽不同硬件平台之间的差异,Java提出了JMM(Java Memory Model)
JMM通过定义一套统一的内存访问规则,主要解决可见性和有序性问题,原子性则需要依赖 synchronized、Lock、CAS 等同步机制实现
5、JMM的本质
JMM其实是在做一个平衡:性能 VS 正确性
如果追求绝对正确:
所有变量实时同步
禁止所有重排序
但是会导致性能极差
如果追求绝对性能:
无限缓存
无限优化
无限重排序
程序可能错误
所以JMM的目标:
尽可能允许优化
同时保证程序正确
三、JMM 的核心抽象模型
为了统一描述多线程访问共享变量的行为,JMM 抽象出了两个概念:
主内存(Main Memory)
所有共享变量存放的位置,所有线程共享
可以理解为:RAM
工作内存(Working Memory)
每个线程私有,保存共享变量的副本
可以理解为:CPU Cache寄存器
模型如下:
主内存
+-------------+
| 共享变量 |
+-------------+
↑ ↑
↓ ↓
线程A工作内存 线程B工作内存线程不能直接操作主内存,必须:
主内存
↓
工作内存
↓
执行修改
↓
刷新主内存
四、JMM 引发的三大并发问题
由于线程操作的是变量副本,因此会产生三类经典问题
1. 可见性问题
线程A修改变量,线程B无法立即看到
例如:
java
boolean flag = true;线程A:
java
while(flag){}线程B:
java
flag = false;线程A可能永远不会退出循环 ,原因是线程A始终读取缓存中的旧值
2. 原子性问题
例如:
java
count++;看似一个操作,实际上包含:读取 + 计算 + 写回
多个线程同时执行时会产生数据覆盖
3. 有序性问题
例如:
java
num = 42;
ready = true;可能被重排序为:
java
ready = true;
num = 42;导致其他线程读取到错误结果
五、JMM 如何解决这些问题
JMM并没有禁止CPU优化,而是定义了一套可见性和有序性规则
核心思想:
如果两个操作满足 Happens-Before 关系,那么前一个操作的结果必须对后一个操作可见
六、Happens-Before 规则
Happens-Before 可以理解为:
前面的操作结果,对后面的操作一定可见
常见规则:
程序次序规则
同一线程中:
java
a = 1;
b = 2;a=1 Happens-Before b=2
volatile规则
写 volatile 变量:
flag = true;Happens-Before
读取 volatile 变量:
if(flag)锁规则
释放锁:
unlock()Happens-Before
后续获取同一把锁:
lock()Thread.start()规则
启动线程前的操作,对新线程可见
Thread.join()规则
线程结束前的操作,对调用 join() 的线程可见
理解Happends-Before
JMM 确实定义了 Happens-Before 规则,但 JMM 并不会自动给所有操作建立 Happens-Before 关系
所以:
JMM 存在 ≠ 所有线程之间都有 Happens-Before
JMM 想解决的问题是:
CPU缓存
编译器优化
指令重排序
多核CPU
导致的并发行为不一致,因此 JMM 制定了一套规则:
如果满足某些条件
↓
必须保证可见性和有序性
这个条件就是:Happens-Before
JMM 并不是自动同步所有线程
假设:
java
int num = 0;
线程A:
num = 10;
线程B:
System.out.println(num);这里:线程A写num , 线程B读num
JMM 不会帮你同步,因为:
没有任何 Happens-Before 关系
所以:0、10都堆
加速理解
JMM 像交通法规:
红灯停
绿灯行
限速120
法规存在,但你不开车遵守:
闯红灯
超速
法规不会自动帮你刹车
JMM 也是一样:
java
volatile
synchronized
Lock
start
join这些就是需要主动使用的规则
使用后:JMM 才提供保证
七、JMM 的实现手段
JMM 本身只是规范
真正实现这些规则依赖于:
volatile
保证:
-
可见性
-
禁止指令重排序
但不保证原子性
synchronized
保证:
-
原子性
-
可见性
-
有序性
Lock
与 synchronized 类似,提供更灵活的锁控制能力
CAS
通过硬件级原子指令实现无锁并发,大量应用于 JUC 包
八、总结
JMM 并不是物理内存结构,而是一套并发访问规范
它通过:
-
主内存与工作内存模型
-
Happens-Before规则
-
内存屏障机制
解决了以下三个问题:
-
可见性
-
原子性
-
有序性