文章目录
- 一、数据类型分类
- 二、数值类型
-
- [1. bit类型](#1. bit类型)
- [2. int系列类型(TINYINT、SMALLINT、MEDIUMINT、INT 和 BIGINT)](#2. int系列类型(TINYINT、SMALLINT、MEDIUMINT、INT 和 BIGINT))
-
- [2.1 int系列类型 的存储范围](#2.1 int系列类型 的存储范围)
- [2.2 指定有符号 和 无符号的字段类型](#2.2 指定有符号 和 无符号的字段类型)
- [3. 小数类型](#3. 小数类型)
-
- [3.1 float(double类似)](#3.1 float(double类似))
- [3.2 decimal(比较 float、double 和 decimal的精度)](#3.2 decimal(比较 float、double 和 decimal的精度))
- [4. bool / boolean类型](#4. bool / boolean类型)
- 三、字符串类型
-
- [1. char(定长字符串)](#1. char(定长字符串))
- [2. varchar(变长字符串)](#2. varchar(变长字符串))
- [3. char 和 varchar比较](#3. char 和 varchar比较)
- [4. BLOB 和 TEXT 类型](#4. BLOB 和 TEXT 类型)
- [5. 日期和时间类型](#5. 日期和时间类型)
- [6. enum 和 set](#6. enum 和 set)
-
- [6.1 enum 和 set的语法](#6.1 enum 和 set的语法)
- [6.2 使用案例(创建 和 插入 enum、set类型)](#6.2 使用案例(创建 和 插入 enum、set类型))
- [6.3 使用案例(通过 set 类型进行查询)](#6.3 使用案例(通过 set 类型进行查询))
一、数据类型分类
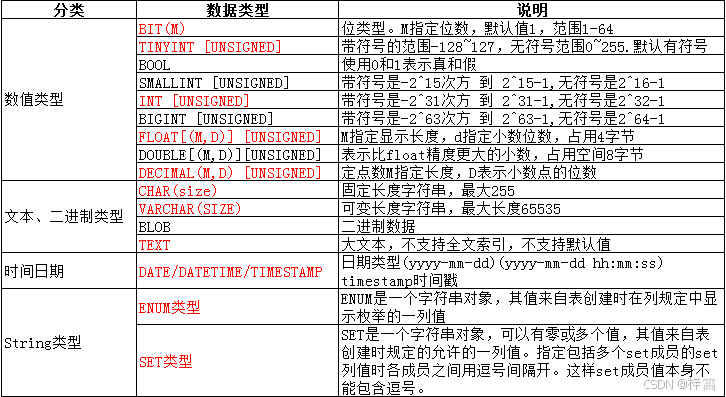
二、数值类型
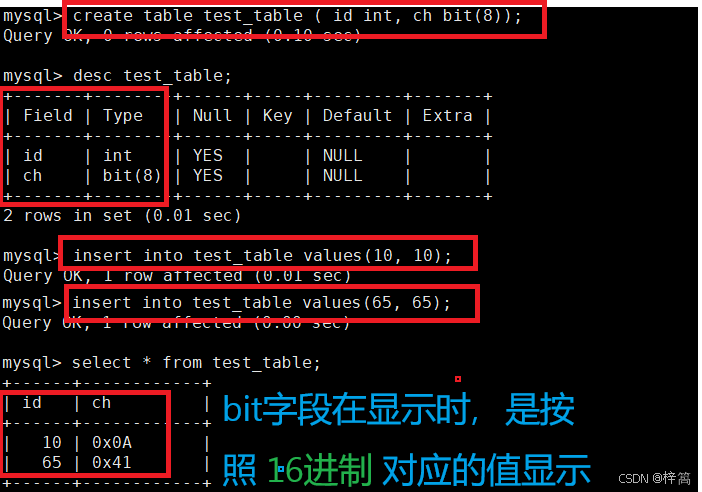
1. bit类型
- 基本语法:
bash
bit[(M)] : 位字段类型。M表示每个值的bit位的位数,范围从1到64。如果M被忽略,默认为1。(1)示例:
bit字段在显示时,是按照 16进制 对应的值显示
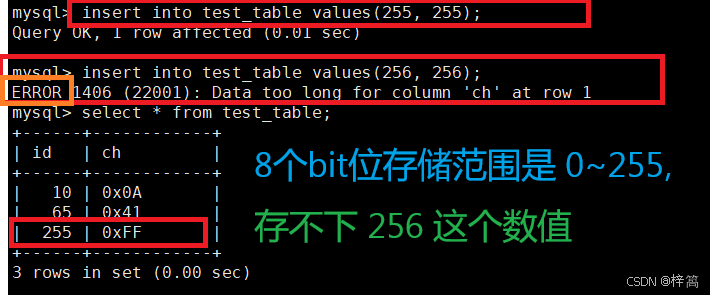
bit类型无法存储超过范围的数据
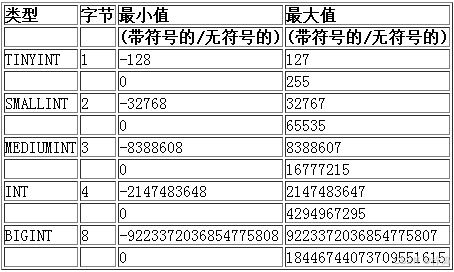
2. int系列类型(TINYINT、SMALLINT、MEDIUMINT、INT 和 BIGINT)
2.1 int系列类型 的存储范围
2.2 指定有符号 和 无符号的字段类型
- 在MySQL中,整型可以指定是有符号的和无符号的,默认是有符号的。
- 可以通过 UNSIGNED 来说明某个字段是无符号的
(1)示例:
有符号 tinyint 类型的存储范围:-128~127
无符号 tinyint 类型的存储范围:0~255
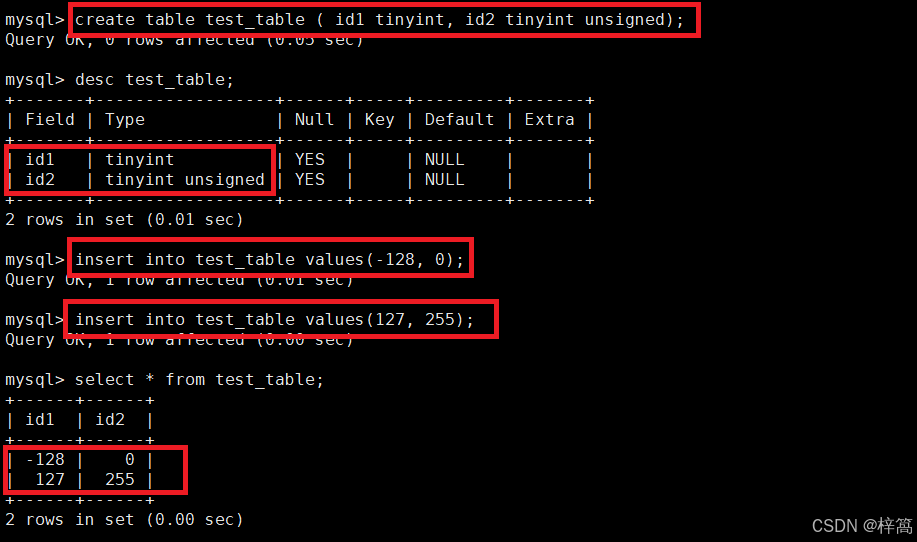
无法存储超出范围的数据

3. 小数类型
3.1 float(double类似)
- 语法:
bash
float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节(1)示例:
float(4,2) 表示的范围是-99.99 ~ 99.99,MySQL在保存值时会进行四舍五入。
如果定义的是 float(4,2) unsigned 这时,因为把它指定为无符号的数,范围是 0 ~ 99.99
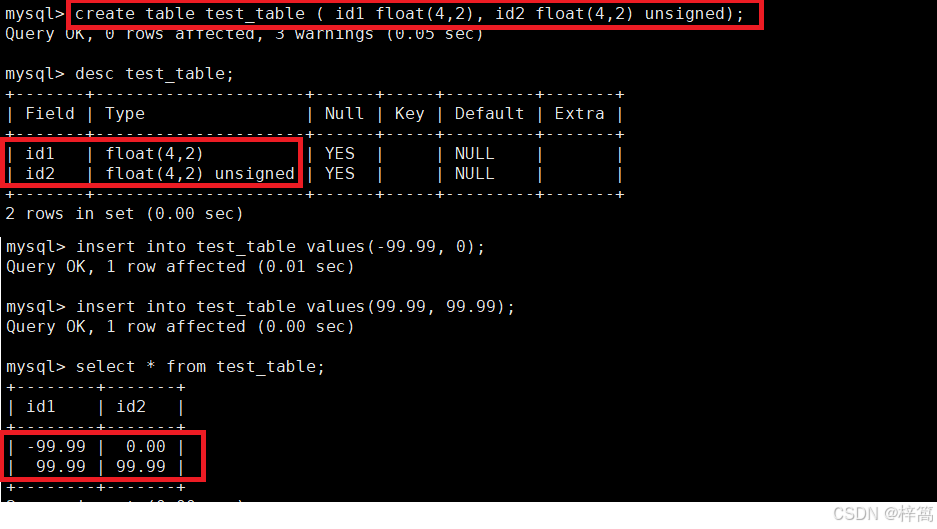
验证MySQL在保存浮点值时会进行四舍五入
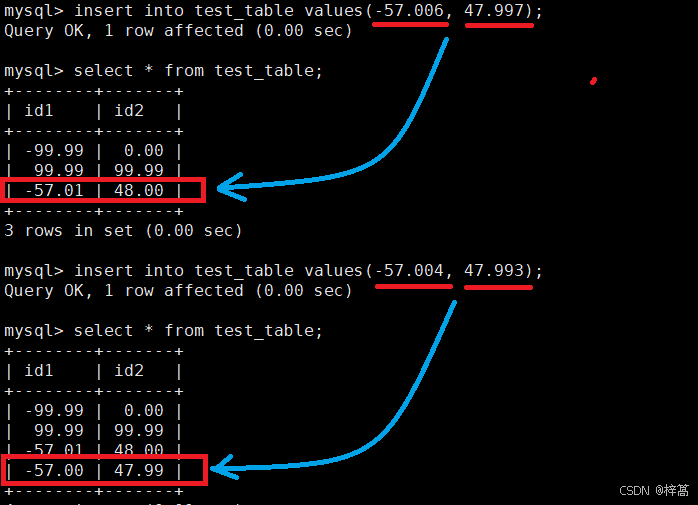
同理,如果是 float(6,3),表示的范围就是-999.999 ~ 999.999
float(6,3) unsigned 表示的范围就是0 ~ 999.999
double的存储精度比float高,占用字节数比float大,占用8个字节
3.2 decimal(比较 float、double 和 decimal的精度)
- 语法:
bash
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数(1)示例:
decimal(5,2) 表示的范围是 -999.99 ~ 999.99
decimal(5,2) unsigned 表示的范围 0 ~ 999.99
decimal和float很像,但是有区别:float和decimal表示的精度不一样
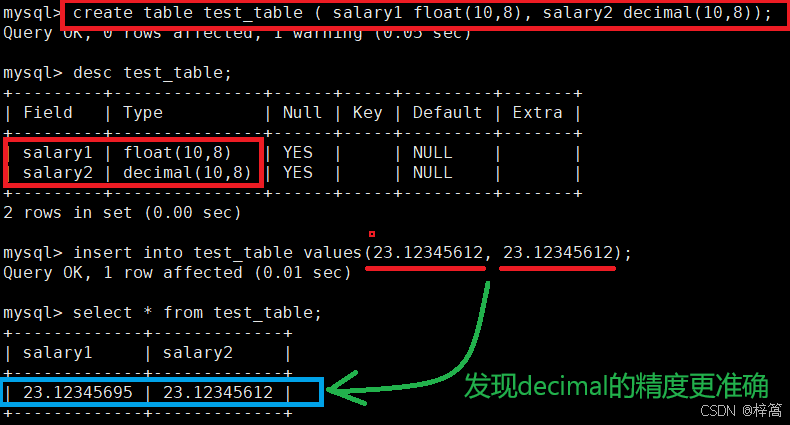
- 核心区别总结(精度对比)
| 特性 | FLOAT | DOUBLE | DECIMAL |
|---|---|---|---|
| 存储方式 | 单精度浮点数 (IEEE 754) | 双精度浮点数 (IEEE 754) | 定点数 (以字符串形式精确存储) |
| 占用空间 | 4 字节 | 8 字节 | 可变长度,每9位数字占4字节 |
| 精度范围 | 约7位有效数字 | 约15位有效数字 | 精确精度 ,由 (m,d) 定义 |
| 适用场景 | 科学计算、对精度要求不高的数据(如温度、百分比) | 需要比FLOAT更高精度的科学计算 | 金融、货币计算、需要绝对精确的数值(如金额、库存) |
| 计算速度 | 最快 | 较快 | 较慢(因为需要精确计算) |
| 是否近似值 | 是,可能存在舍入误差 | 是,但误差比FLOAT小 | 否,精确值 |
4. bool / boolean类型
- 核心本质
MySQL 8.0 并没有原生实现独立的布尔类型,BOOL 和 BOOLEAN 只是 TINYINT(1) 的语法别名,当你在建表时声明字段为BOOL/BOOLEAN,MySQL会自动将其转换为TINYINT(1),底层实际占用1字节存储空间,和普通TINYINT完全一致。
- 取值规则(MySQL对布尔值的语义规则约定如下)
FALSE: 关键字等价于整数0,代表逻辑假;
TRUE: 关键字等价于整数1,代表逻辑真;
所有非0值都会被MySQL识别为逻辑真,即使你存入2/-1这类其他值,判断时也会被当作真处理。
由于底层是TINYINT(1),理论上可以存储 -128 ~ 127(有符号默认)范围内的任意整数,规范开发中仅使用0和1来表示二元状态。
- 实际使用示例
bash
# 1. 建表:两种声明方式完全等价,最终都会转为TINYINT(1)
CREATE TABLE product (
name VARCHAR(100) NOT NULL,
is_on_sale BOOL, # 使用BOOL声明
is_deleted BOOLEAN DEFAULT FALSE # 使用BOOLEAN声明,设置默认假
);
# 2. 插入数据:三种写法均可正常工作
INSERT INTO product (name, is_on_sale, is_deleted)
VALUES ("无线耳机", TRUE, 0); # TRUE等价1,0等价FALSE
INSERT INTO product (name, is_on_sale, is_deleted)
VALUES ("机械键盘", 1, FALSE); # 直接使用数字也兼容
# 3. 条件查询:支持直观的布尔语义判断
# 方式1:直接根据布尔值过滤,等价于 WHERE is_on_sale != 0
SELECT * FROM product WHERE is_on_sale;
# 方式2:明确判断真假
SELECT * FROM product WHERE is_deleted = FALSE;- 使用注意与最佳实践
(1)添加约束保证数据规范(如果需要严格限制只能存储0和1,可以新增CHECK约束):
bash
CREATE TABLE user (
id INT PRIMARY KEY,
is_active BOOL CHECK (is_active IN (0, 1))
);(2)不要用BIT(1)替代BOOL: BIT类型读写兼容性差,很多编程语言的MySQL驱动会错误映射BIT(1)为字节数组,TINYINT(1)的兼容性和可维护性更好;
(3)默认值兼容性: MySQL 8.0.13及之后的版本才支持BOOL类型设置非NULL常量默认值,更低版本仅支持默认NULL。
(4)常见适用场景: 适合存储所有二元逻辑状态,比如用户激活状态、订单支付状态、功能开关、逻辑删除标记等。
三、字符串类型
1. char(定长字符串)
- 语法:
bash
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255(1)示例一:
char(2) 表示可以存放两个字符,可以是字母或汉字,但是不能超过2个
bash
mysql> create table test_table( name char(2));
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test_table values( 'ab');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test_table values( '中国');
Query OK, 1 row affected (0.00 sec)
mysql> select * from test_table;
+------+
| name |
+------+
| ab |
| 中国 |
+------+(2)示例二:
char(L)中,L是可以存储的长度,单位为字符,L最多只能是255
bash
mysql> create table test_table( name char(256));
ERROR 1074 (42000): Column length too big for column 'name' (max = 255); use
BLOB or TEXT instead2. varchar(变长字符串)
- 语法:
bash
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节(1)示例:
bash
mysql> create table test_table(id int ,name varchar(6)); --表示这里可以存放6个字符
mysql> insert into test_tablevalues( 'hello');
mysql> insert into test_tablevalues( '我爱你,中国');
mysql> select * from test_table;
+------------+
| name |
+------------+
| hello |
| 我爱你,中国 |
+------------+说明(关于varchar(len),len到底是多大,这个len值,和表的编码密切相关):
-
varchar 所占字节数最大为65535,但是有1 - 3 个字节用于记录数据大小,所以说 有效字节数是65532。
-
当我们的表的编码是utf8mb4时,varchar(n) 的参数n最大值是65532/4=16383(因为utf8mb4中,一个字符占用4个字节);
如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符占用2字节)。


3. char 和 varchar比较

如何选择定长或变长字符串?
- 如果数据确定长度都一样,就使用定长(char),比如:身份证,手机号,md5
- 如果数据长度有变化,就使用变长(varchar), 比如:名字,地址,但是你要保证最长的能存的进去。
- 定长的磁盘空间比较浪费,但是效率高。
- 变长的磁盘空间比较节省,但是效率低。
- 定长的意义是,直接开辟好对应的空间
- 变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
4. BLOB 和 TEXT 类型
(1) BLOB 类型(二进制大对象)
-
核心定义: 用于存储二进制数据(图片、音频、视频、PDF、加密数据等),不处理字符集/排序规则,完全保留原始字节。
-
细分类型(按容量区分):
| 类型 | 最大存储容量 | 长度前缀开销 | 适用场景 |
|---|---|---|---|
| TINYBLOB | 255 字节 | 1 字节 | 短加密串、极小二进制数据 |
| BLOB | ≈ 64 KB | 2 字节 | 小图标、短音频等小文件 |
| MEDIUMBLOB | ≈ 16 MB | 3 字节 | 中等图片、短视频 |
| LONGBLOB | ≈ 4 GB | 4 字节 | 超大二进制文件(谨慎用) |
- 核心特点:
排序/比较按字节数值进行,天然区分大小写;
MySQL 8.0.13 之前不支持非NULL默认值,8.0.13+ 支持常量默认值;
无法对整列建立高效索引,仅支持前缀索引;
实际可用容量受系统参数 max_allowed_packet 限制。
(2) TEXT 类型(文本大对象)
-
核心定义: 用于存储大文本数据(文章、日志、长描述、JSON文档等),支持字符集和排序规则,会自动做编码转换,适合文本存储。
-
细分类型(按容量区分,UTF8MB4字符集下的实际存储参考):
| 类型 | 最大字符数 | 对应最大容量 | 长度前缀开销 | 适用场景 |
|---|---|---|---|---|
| TINYTEXT | 255 | ≤ 255 字节 | 1 字节 | 短备注、个人简介 |
| TEXT | ≈ 1.6万 | ≈ 64 KB | 2 字节 | 文章摘要、普通留言 |
| MEDIUMTEXT | ≈ 419万 | ≈ 16 MB | 3 字节 | 长篇文章、完整日志 |
| LONGTEXT | ≈ 10亿 | ≈ 4 GB | 4 字节 | 超大文档、全量代码(谨慎用) |
注:UTF8MB4中单个字符最多占用4字节,因此TEXT实际可存储的字符数约为 65535 ÷ 4 = 16383 个字符。
- 核心特点:
排序/比较遵循绑定的字符集排序规则,可灵活配置是否区分大小写;
写入时会自动截断末尾空格,读取时不保留;
同样MySQL 8.0.13+ 才支持常量默认值;
MySQL 8.0+ 支持整列索引,但受限于16KB默认索引页大小,长字段索引效率很低,依然推荐使用前缀索引。
(3) BLOB vs TEXT 核心区别
| 对比维度 | BLOB 类型 | TEXT 类型 |
|---|---|---|
| 数据本质 | 二进制字节流 | 文本字符流 |
| 字符集处理 | 无字符集,不做编码转换 | 绑定表字符集,自动编解码 |
| 排序规则 | 按字节数值排序,区分大小写 | 按字符集规则排序,可自定义 |
| 空格处理 | 完整保留所有空格(包括末尾) | 自动截断末尾空格 |
| 适用场景 | 图片、音频、文件等二进制数据 | 文章、日志、JSON等文本数据 |
(4) 使用注意与最佳实践
- 存储建议: 除非特殊需求,不建议直接将大文件(图片/视频)存储在数据库中,推荐数据库只存储文件在文件系统/对象存储的路径,能大幅提升数据库备份和查询性能;
- 索引优化: 对BLOB/TEXT字段建立索引时,必须指定前缀长度(例如 INDEX(content(100))),仅对常用前缀建立索引,避免整列索引带来的性能浪费;
- 性能注意: 如果查询中包含对BLOB/TEXT字段的排序、分组操作,会导致MySQL使用磁盘临时表替代内存临时表,性能下降明显,尽量避免这类操作;
- 容量选择: 不要过度选择大类型,例如能存下的情况下优先用TEXT而非MEDIUMTEXT,减少不必要的空间开销;
- 默认值限制: 如果使用低于8.0.13的MySQL版本,BLOB/TEXT不支持非NULL默认值,只能默认NULL。
5. 日期和时间类型
常用的日期和时间类型有如下三个:
- date: 日期 'yyyy-mm-dd' ,占用三字节
- datetime: 时间日期格式 'yyyy-mm-dd HH:ii:ss' 表示范围从 1000 到 9999 ,占用八字节
- timestamp: 时间戳,从1970年开始的 yyyy-mm-dd HH:ii:ss 格式和 datetime 完全一致,占用
四字节
(1)示例:
将时间戳类型设置为 t3 timestamp DEFAULT current_timestamp;
添加数据时,时间戳自动被设置为当前时间
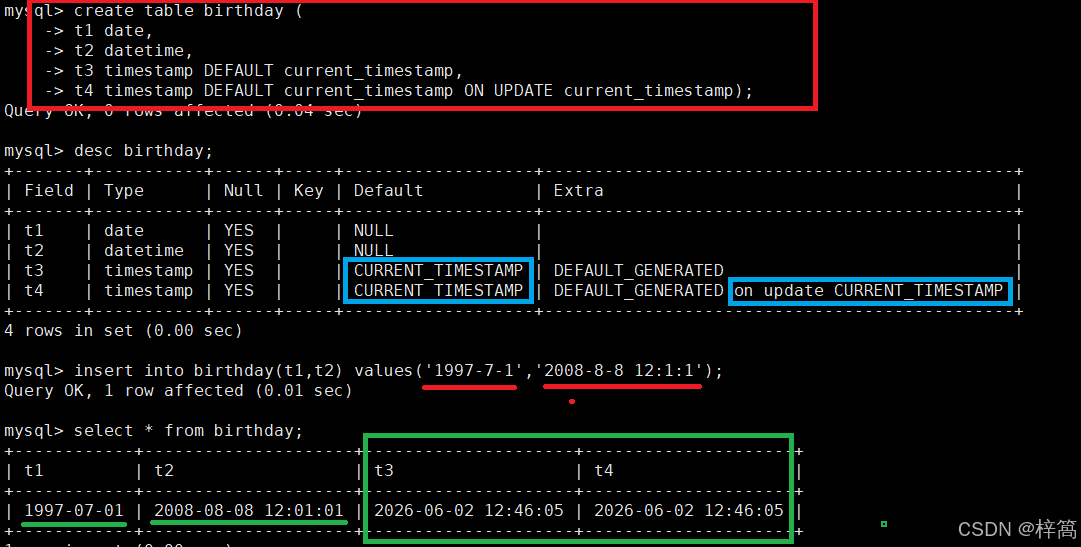
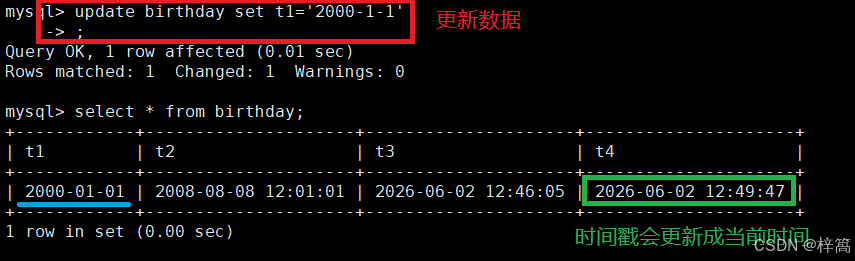
将时间戳类型设置为 t4 timestamp DEFAULT current_timestamp ON UPDATE current_timestamp;
添加数据时,时间戳自动被设置为当前时间;
更新数据时,时间戳会自动更新成当前时间
6. enum 和 set
6.1 enum 和 set的语法
- enum 的语法:
bash
enum('选项1','选项2','选项3',...);enum:枚举,"单选"类型;
该设定只是提供了若干个选项的值,最终一个单元格中,实际只存储了其中一个值;而且出于效率考虑,这些值实际存储的是"数字",因为这些选项的每个选项值依次对应如下数字:1,2,3,...最多65535个;当我们添加枚举值时,也可以添加对应的数字编号。
- set 的语法:
bash
set('选项值1','选项值2','选项值3', ...);set:集合,"多选"类型;
该设定只是提供了若干个选项的值,最终一个单元格中,设计可存储了其中任意多个值;而且出于效率考虑,这些值实际存储的是"数字",因为这些选项的每个选项值依次对应如下数字:1,2,4,8,16,32,... 最多64个。
6.2 使用案例(创建 和 插入 enum、set类型)
- 案例:
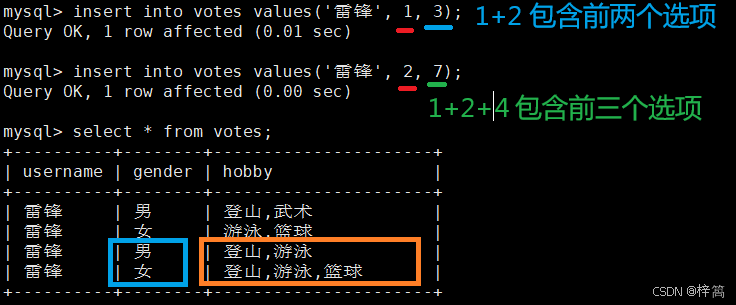
有一个调查表votes,需要调查人的喜好, 比如(登山,游泳,篮球,武术)中去选择(可以多选),(男,女)单选
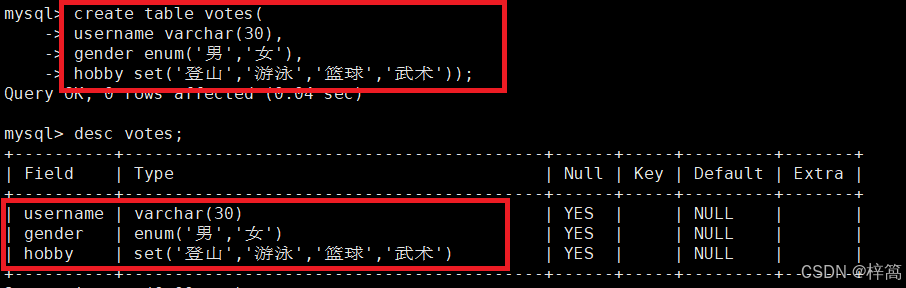
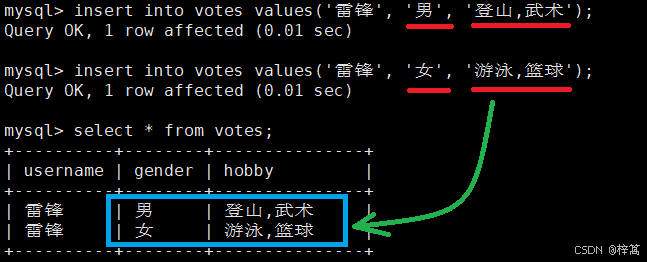
enum类型 使用数字标识的时候,就是正常的数组下标;
set类型 使用数字标识每个爱好的时候,采用比特位位置(位图)与 set中的爱好对应起来
例如:0011 代表选择前两个选项,0111 代表选择前三个选项
6.3 使用案例(通过 set 类型进行查询)
- 有如下数据,想查找只喜欢登山的人 和 所有喜欢登山的人:
bash
mysql> select * from votes;
+----------+--------+----------------------+
| username | gender | hobby |
+----------+--------+----------------------+
| jack | 男 | 登山,游泳 |
| rose | 女 | 登山,篮球 |
| john | 男 | 游泳,武术 |
| lucky | 女 | 游泳,篮球 |
| jane | 女 | 登山,游泳,篮球 |
| macal | 男 | 登山 |
+----------+--------+----------------------+
6 rows in set (0.00 sec)查找只喜欢登山的人:select * from votes where hobby='登山';
bash
mysql> select * from votes where hobby='登山';
+----------+--------+--------+
| username | gender | hobby |
+----------+--------+--------+
| macal | 男 | 登山 |
+----------+--------+--------+
1 row in set (0.00 sec)补充知识:集合查询使用find_ in_ set函数
find_in_set(sub, str_list) :
如果 sub 在 str_list中,则返回下标;如果不在,返回0; str_list 用逗号分隔的字符串。
查找所有喜欢登山的人:select * from votes where find_in_set('登山', hobby);

bash
mysql> select * from votes where find_in_set('登山', hobby);
+----------+--------+----------------------+
| username | gender | hobby |
+----------+--------+----------------------+
| jack | 男 | 登山,游泳 |
| rose | 女 | 登山,篮球 |
| jane | 女 | 登山,游泳,篮球 |
| macal | 男 | 登山 |
+----------+--------+----------------------+
4 rows in set (0.00 sec)