提示:本文原创作品,良心制作,干货为主,简洁清晰,一看就会
文章目录
- 前言
- 一、整体流程概述
- 二、安装NFS
-
- [2.1 安装NFS服务端](#2.1 安装NFS服务端)
- [2.2 安装NFS服务端](#2.2 安装NFS服务端)
- [2.3 安装nfs驱动](#2.3 安装nfs驱动)
- [2.4 测试动态存储](#2.4 测试动态存储)
- [三、Prometheus Operator安装](#三、Prometheus Operator安装)
-
- [3.1 下载release并更换镜像源](#3.1 下载release并更换镜像源)
- [3.2 数据持久化](#3.2 数据持久化)
- [3.3 service暴露](#3.3 service暴露)
- [3.4 ingress暴露](#3.4 ingress暴露)
-
- [创建ingress controller](#创建ingress controller)
- [创建grafana ingress](#创建grafana ingress)
- [创建prometheus ingress](#创建prometheus ingress)
- [创建alertmanager ingress](#创建alertmanager ingress)
- 四、监控etcd
-
- [4.1 确认etcd集群状态](#4.1 确认etcd集群状态)
- [4.2 创建endpoints和svc](#4.2 创建endpoints和svc)
- [4.3 准备证书secret](#4.3 准备证书secret)
- [4.4 创建servicemonitor](#4.4 创建servicemonitor)
- [4.5 在grafana中添加dashboard](#4.5 在grafana中添加dashboard)
前言
随着 Kubernetes 成为容器编排的主流方案,集群运维与资源监控的重要性愈发凸显。Prometheus 凭借轻量化、高可用、生态丰富等优势,成为 K8s 环境下的首选监控组件。本文将结合实际部署场景,讲解基于 Prometheus 搭建整套监控体系的思路、架构与实践,助力运维人员实时掌握集群运行状态
一、整体流程概述
我的实验环境:
| 主机名 | ip | 作用 |
|---|---|---|
| K8s-master1 | 192.168.13.136 | k8s控制节点 |
| K8s-master2 | 192.168.13.137 | k8s控制节点 |
| K8s-master3 | 192.168.13.138 | k8s控制节点 |
| k8s-node1 | 192.168.13.139 | k8s工作节点 |
| k8s-node2 | 192.168.13.140 | k8s工作节点 |
| NFS | 192.168.13.141 | NFS服务端,提供存储 |
本文档用于在 Kubernetes 1.28 高可用集群中部署一套完整、可用于生产环境的 Prometheus 监控系统,实现数据持久化、外部访问及集群核心组件 etcd 的专项监控,整体部署流程分为四个核心阶段:
一、准备 NFS 动态存储
搭建集群外部 NFS 服务端,在所有集群节点安装 NFS 客户端;部署 nfs-subdir-external-provisioner 组件,为 Prometheus、Grafana、Alertmanager 提供动态 PVC 存储能力,并通过测试验证动态存储功能可用性,保障监控数据持久化基础
二、部署 Prometheus Operator 监控栈
拉取 kube-prometheus release对应版本资源,替换国内镜像源解决拉取慢问题。为 Grafana、Prometheus、Alertmanager 配置 PVC 持久化存储,批量创建监控相关资源对象。通过 svc 暴露各组件访问端口,支持搭配 Ingress Controller 实现域名外部访问
三、配置 etcd 集群专项监控
针对 Master 节点上开启 mTLS 认证的 etcd 集群进行定制化监控配置:先校验 etcd 集群健康状态,创建专属 Endpoints 与 Service 实现服务发现;将 etcd 证书以 Secret 形式同步至监控命名空间,配置 ServiceMonitor 规则抓取 etcd 监控指标,最终通过 Grafana 仪表盘实现数据可视化展示
四、功能验证与使用
通过外部访问地址登录 Grafana、Prometheus 可视化界面,校验监控数据正常采集、展示,重点确认 etcd 核心指标抓取生效,确保整套监控系统稳定可用
本方案完整覆盖存储适配、监控组件部署、外部访问、核心组件精细化监控全流程,适配生产环境落地使用
下面开始实操
二、安装NFS
部署监控组件前搭建 NFS,主要用于持久化监控数据
Prometheus、Grafana 等组件运行产生的指标、面板配置等数据,无法依靠容器临时目录保存
借助 NFS 构建集群共享存储,配合 K8s PV/PVC 实现数据落地,避免 Pod 重建、节点故障导致监控数据丢失,保障监控服务稳定运行
2.1 安装NFS服务端
我们需要准备一台设备,安装nfs服务端,专门来存储Prometheus采集到的监控数据
yaml
#服务端
root@NFS:~# apt -y install nfs-kernel-server
root@NFS:~# systemctl start nfs-kernel-server
root@NFS:~# mkdir /k8s
root@NFS:~# vim /etc/exports
/k8s 192.168.13.0/24(rw,sync,no_root_squash,no_subtree_check)
root@NFS:~# systemctl restart nfs-kernel-server
root@NFS:~# systemctl enable nfs-kernel-server2.2 安装NFS服务端
建议为k8S集群内所有节点部署nfs服务端
yaml
root@k8s-master1:~# apt -y install nfs-common2.3 安装nfs驱动
接下来需要安装nfs驱动,为 K8s 提供 NFS 动态存储供给能力,K8s 原生仅支持手动创建静态 PV,效率低且难以维护
该组件作为官方推荐的 NFS 驱动,可监听 PVC 请求,自动在 NFS 共享目录中创建独立子目录并生成 PV,实现存储与应用的解耦与自动化管理,特别适合 Prometheus、Grafana 等监控组件的持久化需求
NFS驱动下载地址:https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
找个K8S matser节点下载nfs驱动即可
yaml
## 1. 下载解压nfs驱动
root@k8s-master1:~# wget https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner/archive/refs/tags/nfs-subdir-external-provisioner-4.0.18.tar.gz
root@k8s-master1:~# ls
nfs-subdir-external-provisioner-4.0.18.tar.gz
root@k8s-master1:~# tar xf nfs-subdir-external-provisioner-4.0.18.tar.gz
root@k8s-master1:~# ls
nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18 nfs-subdir-external-provisioner-4.0.18.tar.gz tigera-operator.yaml
root@k8s-master1:~# cd nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy/
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# ls
class.yaml deployment.yaml kustomization.yaml objects rbac.yaml test-claim.yaml test-pod.yaml
## 2. 修改镜像地址,nfs服务器地址和数据存放目录
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# vim deployment.yaml 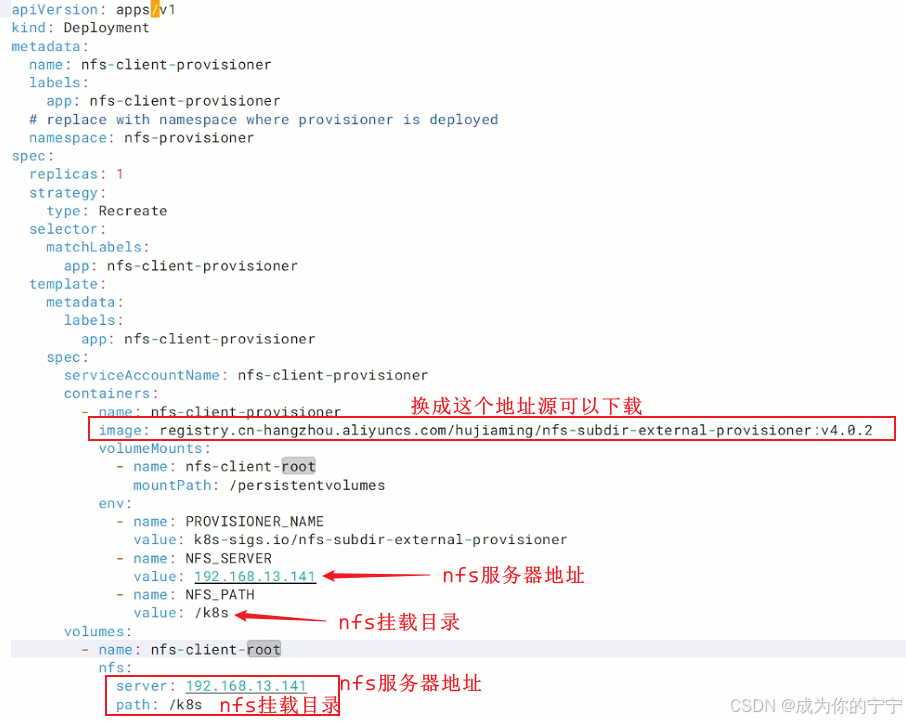
yaml
## 3. 该参数控制目录留存:false删除 Pod 即清除持久化数据;设为 true,重建 Pod 保留原有存储目录
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# vim class.yaml 
yaml
## 4. 找出当前目录下所有写了namespace: default的文件列表
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# grep -rl 'namespace: default' ./
./objects/serviceaccount.yaml
./objects/rolebinding.yaml
./objects/role.yaml
./objects/deployment.yaml
./objects/clusterrolebinding.yaml
./deployment.yaml
./rbac.yaml
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# yamls=$(grep -rl 'namespace: default' ./)
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# for yaml in ${yamls}; do echo ${yaml} cat ${yaml} | grep 'namespace: default' done
yaml
## 5. --dry-run=client不真创建,只模拟;-oyaml输出成yaml文件
## 只生成一个命名空间的yaml文件,不真正创建命名空间
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# kubectl create namespace nfs-provisioner --dry-run=client -oyaml > nfs-provisioner-ns.yaml
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# ls
class.yaml deployment.yaml kustomization.yaml nfs-provisioner-ns.yaml objects rbac.yaml test-claim.yaml test-pod.yaml
## 创建名为nfs-provisioner的命名空间
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# kubectl create -f nfs-provisioner-ns.yaml
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# kubectl get ns | grep nfs
nfs-provisioner Active 14s
yaml
## 6. 替换资源创建默认命名空间
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# sed -i 's/namespace: default/namespace: nfs-provisioner/g' `grep -rl 'namespace: default' ./`
## 7. 查看是否修改
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# yamls=$(grep -rl 'namespace: nfs-provisioner' ./)
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# for yaml in ${yamls}; do echo ${yaml} cat ${yaml} | grep 'namespace: nfs-provisioner' done
yaml
## 8. 创建该目录下的所有资源对象
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# kubectl apply -k .
## 查看 nfs-provisioner 这个命名空间下的所有资源
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# kubectl get all -n nfs-provisioner
NAME READY STATUS RESTARTS AGE
pod/nfs-client-provisioner-56977cdf4d-62sn9 1/1 Running 0 18s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nfs-client-provisioner 1/1 1 1 18s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nfs-client-provisioner-56977cdf4d 1 1 1 18s
## 查看动态存储
root@k8s-master1:~/nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-client k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 26s2.4 测试动态存储
yaml
## 创建一个动态存储的控制器,测试在nfs上能否生成相应挂载目录
root@k8s-master1:~# mkdir -p /project/k8s/test/
root@k8s-master1:~# vim /project/k8s/test/test.yaml
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: nginx
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 2 # 副本数
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.26
ports:
- containerPort: 80
name: nginx
volumeMounts:
- name: test-nfs
mountPath: /tmp
volumeClaimTemplates:
- metadata:
name: test-nfs
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-client" # 动态存储名称
resources:
requests:
storage: 1Gi
yaml
## 创建后查看pod,pv,pvc
root@k8s-master1:~# kubectl apply -f /project/k8s/test/test.yaml
root@k8s-master1:~# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-0 1/1 Running 0 9s 10.244.36.81 k8s-node1 <none> <none>
nginx-1 1/1 Running 0 5s 10.244.169.151 k8s-node2 <none> <none>
root@k8s-master1:~# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-0c87cb92-1754-4b23-a832-44bfe395e5be 1Gi RWO Delete Bound default/test-nfs-nginx-0 nfs-client 15s
pvc-99670e29-7082-4db7-a9bb-6ac24a08031b 1Gi RWO Delete Bound default/test-nfs-nginx-1 nfs-client 11s
root@k8s-master1:~# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-nfs-nginx-0 Bound pvc-0c87cb92-1754-4b23-a832-44bfe395e5be 1Gi RWO nfs-client 17s
test-nfs-nginx-1 Bound pvc-99670e29-7082-4db7-a9bb-6ac24a08031b 1Gi RWO nfs-client 13s
## 查看nfs设备,可以看到生成了相应目录
root@NFS:~# ls /k8s/
default-test-nfs-nginx-0-pvc-0c87cb92-1754-4b23-a832-44bfe395e5be default-test-nfs-nginx-1-pvc-99670e29-7082-4db7-a9bb-6ac24a08031b
## 实验完成后可以删除相关pod,数据目录等
root@k8s-master1:~# kubectl delete -f /project/k8s/test/test.yaml
root@k8s-master1:~# kubectl delete pvc test-nfs-nginx-0
root@k8s-master1:~# kubectl delete pvc test-nfs-nginx-1
root@NFS:~# rm -rf /k8s/*三、Prometheus Operator安装
前文已部署 NFS 与动态存储供给组件,完成持久化目录挂载,接下来开始在 Kubernetes 集群部署 Prometheus。区别于传统二进制部署方式,集群环境采用 Prometheus Operator 方案安装
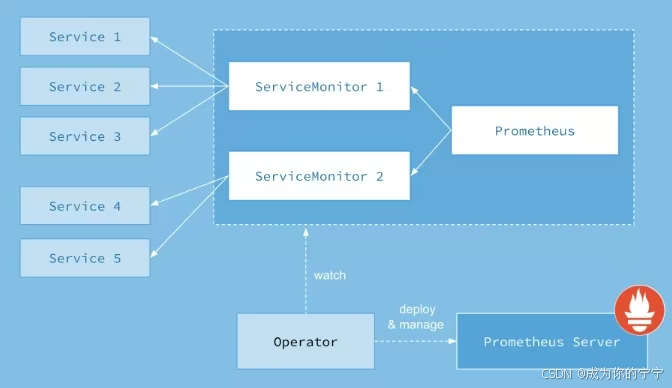
上图是Prometheus-Operator官方提供的架构图
其中Operator是最核心的部分,作为一个控制器,它会去创建Prometheus,serviceMonitor,altermanager以及PrometheusRule四个资源对象,然后会一直监控并维持这个4个资源对象的状态
prometheus 这种资源对象就是作为Prometheus Server 存在
ServiceMonitor 就是对exporter 的配置,用来提供专门提供metrics数据接口的工具 ,Prometheus就是通过ServiceMonitor的配置去 pull 数据的
alertmanager 这种资源对象就是对应的AlertManager 的抽象
PrometheusRule 是用来被Prometheus实例使用的报警规则文件
Service简单的说就是 Prometheus监控的对象
3.1 下载release并更换镜像源
kubernetes和kube-prometheus版本选择官网:https://github.com/prometheus-operator/kube-prometheus
我这里采用的是kube-prometheus stack安装方式,对新手比较友好,它是一套开箱即用的完整监控解决方案
我的K8S是1.28的版本,所以我这里就安装release-0.14;如果是K8S 1.29也可以安装release-0.14
下面是某些K8S对应的release版本,大家可以自行选择
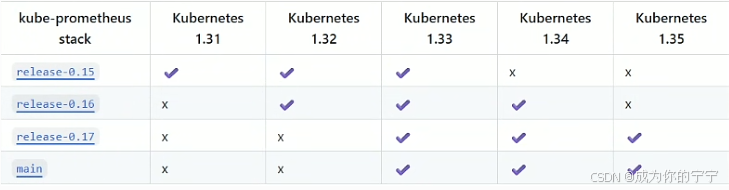
yaml
## 1. 克隆仓库
root@k8s-master1:~# git clone https://github.com/prometheus-operator/kube-prometheus.git
root@k8s-master1:~# cd kube-prometheus/
root@k8s-master1:~/kube-prometheus# git branch -a # 查看所在位置
yaml
## 2. 切换对应分支
root@k8s-master1:~/kube-prometheus# git checkout release-0.14
root@k8s-master1:~/kube-prometheus# git branch -a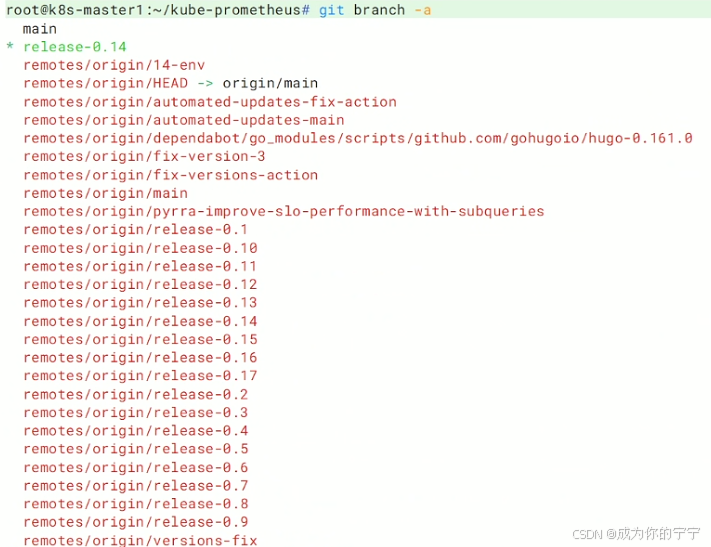
yaml
## 切换工作目录
root@k8s-master1:~/kube-prometheus# cd manifests/setup/
## 3. 创建监控组件所需的自定义资源定义
root@k8s-master1:~/kube-prometheus/manifests/setup# kubectl apply --server-side -f .
root@k8s-master1:~/kube-prometheus/manifests/setup# kubectl get ns | grep monitoring
NAME STATUS AGE
monitoring Active 47s
## 切换工作目录
root@k8s-master1:~/kube-prometheus/manifests/setup# cd ..
## 4. 查看镜像拉取地址,由于这些地址国内拉取非常困难,所以接下来我们需要换成国内源
root@k8s-master1:~/kube-prometheus/manifests# grep -r -i "image:" .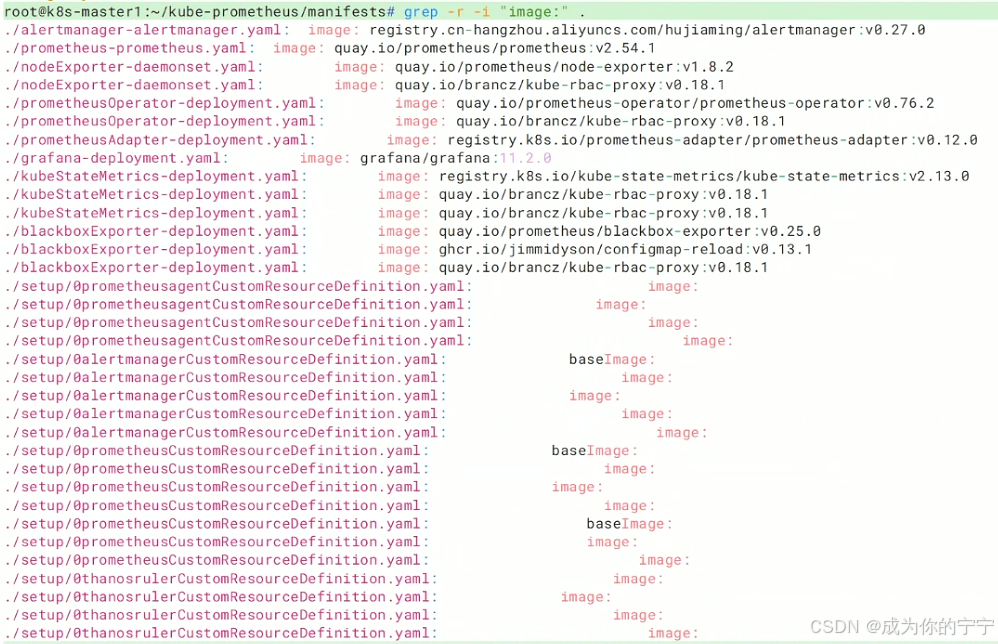
yaml
## 下面就是切换每个镜像源的地址
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|quay.io/prometheus/alertmanager:v0.27.0|registry.cn-hangzhou.aliyuncs.com/hujiaming/alertmanager:v0.27.0|g' ./alertmanager-alertmanager.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|quay.io/prometheus/blackbox-exporter:v0.25.0|registry.cn-hangzhou.aliyuncs.com/hujiaming/blackbox-exporter:v0.25.0|g' ./blackboxExporter-deployment.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|ghcr.io/jimmidyson/configmap-reload:v0.13.1|registry.cn-hangzhou.aliyuncs.com/hujiaming/configmap-reload:v0.13.1|g' ./blackboxExporter-deployment.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|quay.io/brancz/kube-rbac-proxy:v0.18.1|registry.cn-hangzhou.aliyuncs.com/hujiaming/kube-rbac-proxy:v0.18.1|g' ./blackboxExporter-deployment.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|grafana/grafana:11.2.0|registry.cn-hangzhou.aliyuncs.com/hujiaming/grafana:11.2.0|g' ./grafana-deployment.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.13.0|registry.cn-hangzhou.aliyuncs.com/hujiaming/kube-state-metrics:v2.13.0|g' ./kubeStateMetrics-deployment.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|quay.io/brancz/kube-rbac-proxy:v0.18.1|registry.cn-hangzhou.aliyuncs.com/hujiaming/kube-rbac-proxy:v0.18.1|g' ./kubeStateMetrics-deployment.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|quay.io/prometheus/node-exporter:v1.8.2|registry.cn-hangzhou.aliyuncs.com/hujiaming/node-exporter:v1.8.2|g' ./nodeExporter-daemonset.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|quay.io/brancz/kube-rbac-proxy:v0.18.1|registry.cn-hangzhou.aliyuncs.com/hujiaming/kube-rbac-proxy:v0.18.1|g' ./nodeExporter-daemonset.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|quay.io/prometheus/prometheus:v2.54.1|registry.cn-hangzhou.aliyuncs.com/hujiaming/prometheus:v2.54.1|g' ./prometheus-prometheus.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0|registry.cn-hangzhou.aliyuncs.com/hujiaming/prometheus-adapter:v0.12.0|g' ./prometheusAdapter-deployment.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|quay.io/prometheus-operator/prometheus-operator:v0.76.2|registry.cn-hangzhou.aliyuncs.com/hujiaming/prometheus-operator:v0.76.2|g' ./prometheusOperator-deployment.yaml
root@k8s-master1:~/kube-prometheus/manifests# sed -i 's|quay.io/brancz/kube-rbac-proxy:v0.18.1|registry.cn-hangzhou.aliyuncs.com/hujiaming/kube-rbac-proxy:v0.18.1|g' ./prometheusOperator-deployment.yaml
## 再次查看镜像拉取地址,保证每个镜像都切换成国内源
root@k8s-master1:~/kube-prometheus/manifests# grep -r -i "image:" .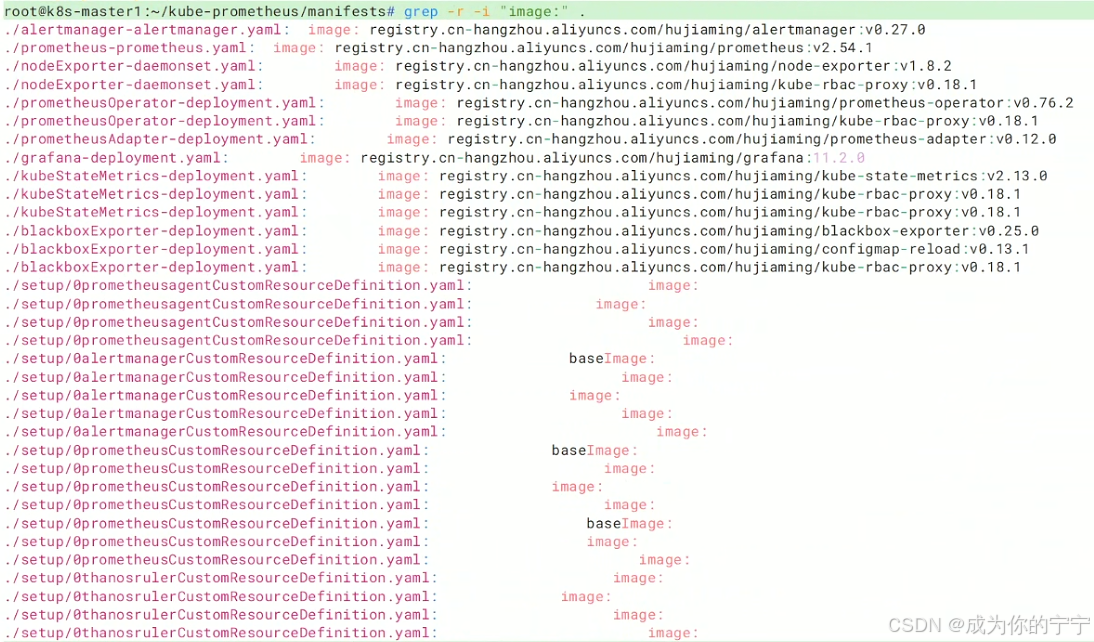
3.2 数据持久化
grafana数据持久化
yaml
## 创建PVC
root@k8s-master1:~/kube-prometheus/manifests# vim grafana-pvc.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc-nfs
namespace: monitoring
spec:
accessModes:
- ReadWriteMany
resources:
requests:
# 在nfs类型的StorageClass下,这个值通常没有实际限制作用,Provisioner会忽略它,直接使用整个nfs共享的可用空间
storage: 10Gi
storageClassName: nfs-client
root@k8s-master1:~/kube-prometheus/manifests# kubectl apply -f grafana-pvc.yaml
root@k8s-master1:~/kube-prometheus/manifests# kubectl get pvc -n monitoring
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
grafana-pvc-nfs Bound pvc-e38216d0-8b46-4fb2-976e-c2140780dfec 10Gi RWX nfs-client 22s
yaml
root@k8s-master1:~/kube-prometheus/manifests# vim grafana-deployment.yaml 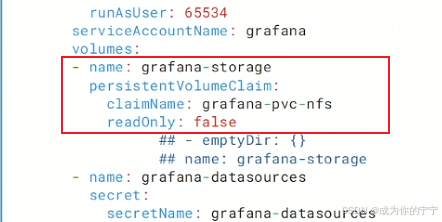
prometheus数据持久化
yaml
root@k8s-master1:~/kube-prometheus/manifests# vim prometheus-prometheus.yaml 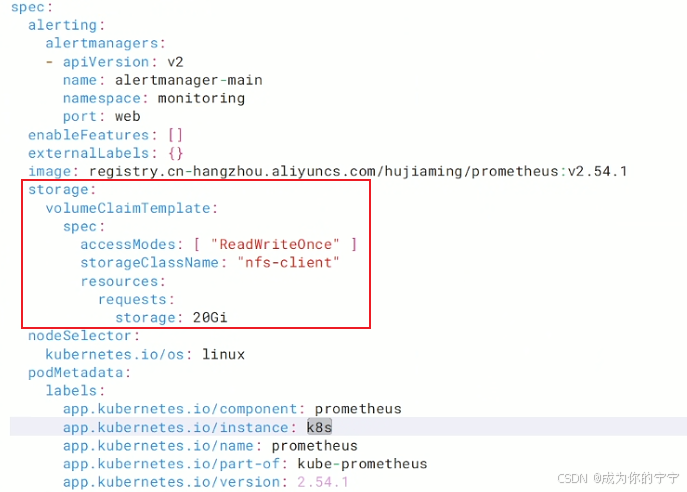
alertmanager数据持久化
yaml
root@k8s-master1:~/kube-prometheus/manifests# vim alertmanager-alertmanager.yaml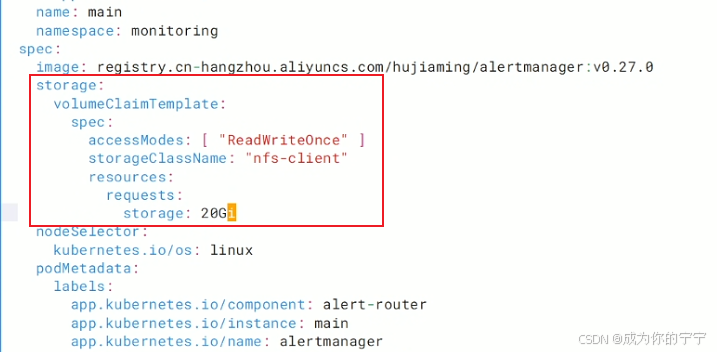
创建资源对象
yaml
## 创建该目录下的所有资源对象
root@k8s-master1:~/kube-prometheus/manifests# kubectl apply -f .
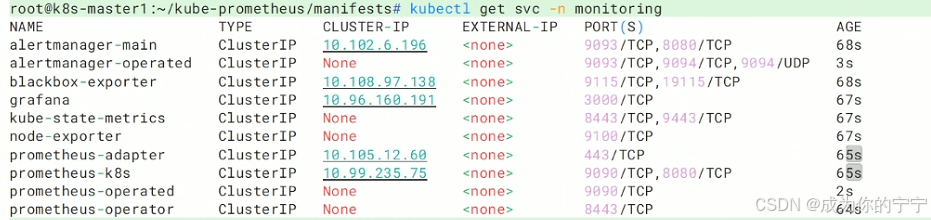
root@k8s-master1:~/kube-prometheus/manifests# kubectl get svc -n monitoring
root@k8s-master1:~/kube-prometheus/manifests# kubectl get pod -n monitoring观察下图可以看到所有svc都正常生成,ClusterIP 正常分配,但只能集群内部访问,外部浏览器打不开 Grafana/Prometheus
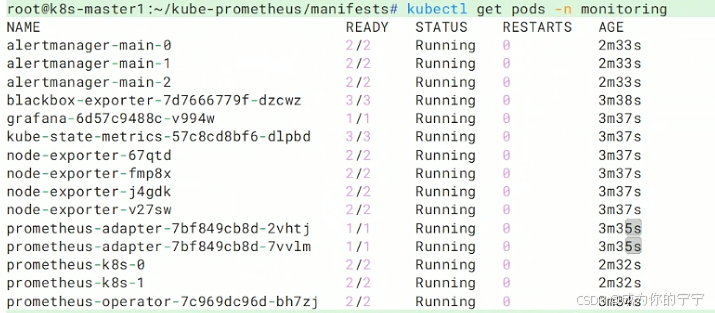
观察下图可以看到所有Pod正常运行,8大组件齐全:
prometheus-operator :管控整套监控
prometheus-k8s :存指标、配告警(双副本)
alertmanager :接收发送告警(三实例)
grafana :监控图表展示
node-exporter :采集服务器硬件指标
kube-state-metrics :采集k8s资源状态
blackbox-exporter :端口/网址连通探测
prometheus-adapter:对接HPA弹性伸缩
yaml
## 查看nfs设备上是否挂载了相应目录
root@NFS:~# ls /k8s/
monitoring-alertmanager-main-db-alertmanager-main-0-pvc-4bc2b064-3acb-409a-9fb1-30381580f018 monitoring-grafana-pvc-nfs-pvc-e38216d0-8b46-4fb2-976e-c2140780dfec
monitoring-alertmanager-main-db-alertmanager-main-1-pvc-7e884746-4e11-4b82-b62b-23893f772491 monitoring-prometheus-k8s-db-prometheus-k8s-0-pvc-49f1f9f2-4e17-4e06-b80f-8d88f0b670a5
monitoring-alertmanager-main-db-alertmanager-main-2-pvc-c15e287d-8a34-45a7-a16d-71914e14008e monitoring-prometheus-k8s-db-prometheus-k8s-1-pvc-76e2e723-0a65-496c-b328-534d95c4f6ea3.3 service暴露
由于上面svc都是ClusterIP,只能集群内部访问,我们想要在浏览器上访问到grafana/prometheus就需要对它们做端口暴露,作完之后我们就可以在浏览器上实现ip:端口访问了
grafana暴露端口
yaml
root@k8s-master1:~# kubectl get svc grafana -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana ClusterIP 10.96.160.191 <none> 3000/TCP 3d3h
# 热更新,不需要重启pod
root@k8s-master1:~# kubectl edit svc grafana -n monitoring 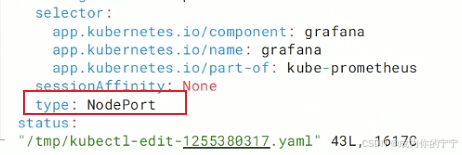
yaml
root@k8s-master1:~# kubectl get svc grafana -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.96.160.191 <none> 3000:32457/TCP 3d3h浏览器访问:http://192.168.13.136:32457,grafana默认账号密码都是admin
此处是重新设置新的密码
登录grafana,可以看到它的控制面板里已经自动添加了很多监控模板
随便点进去就可以看到监控数据
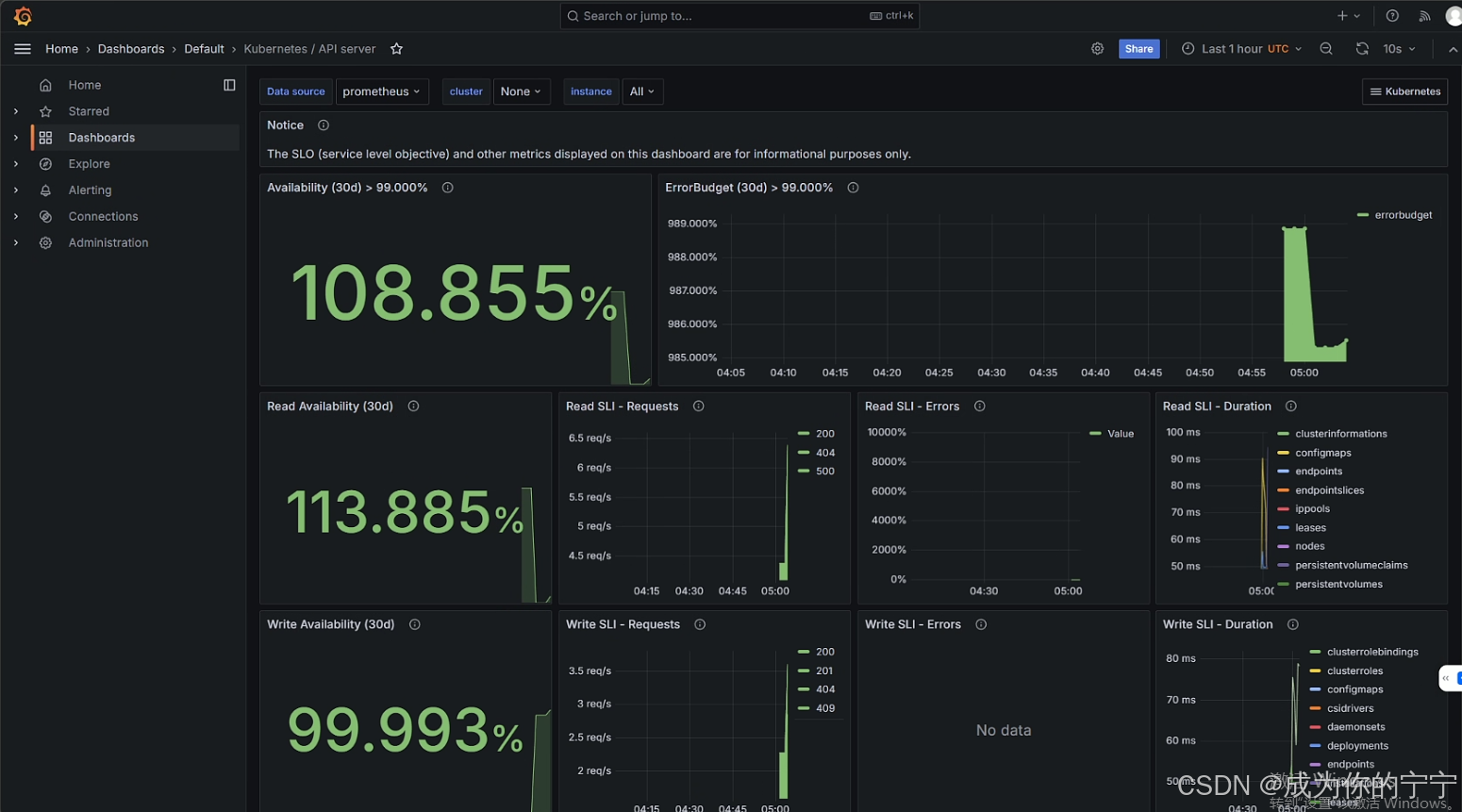
prometheus暴露端口
yaml
root@k8s-master1:~# kubectl get svc -n monitoring | grep prometheus-k8s
prometheus-k8s ClusterIP 10.99.235.75 <none> 9090/TCP,8080/TCP 3d3h
root@k8s-master1:~# kubectl edit svc prometheus-k8s -n monitoring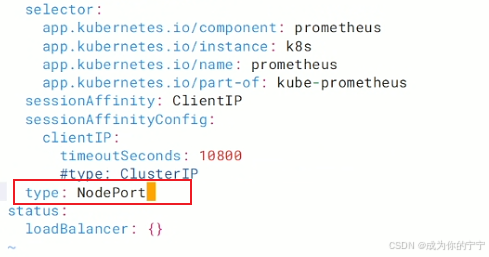
yaml
root@k8s-master1:~# kubectl get svc -n monitoring | grep prometheus-k8s
prometheus-k8s NodePort 10.99.235.75 <none> 9090:32291/TCP,8080:31936/TCP 3d3h浏览器访问:http://192.168.13.136:32291
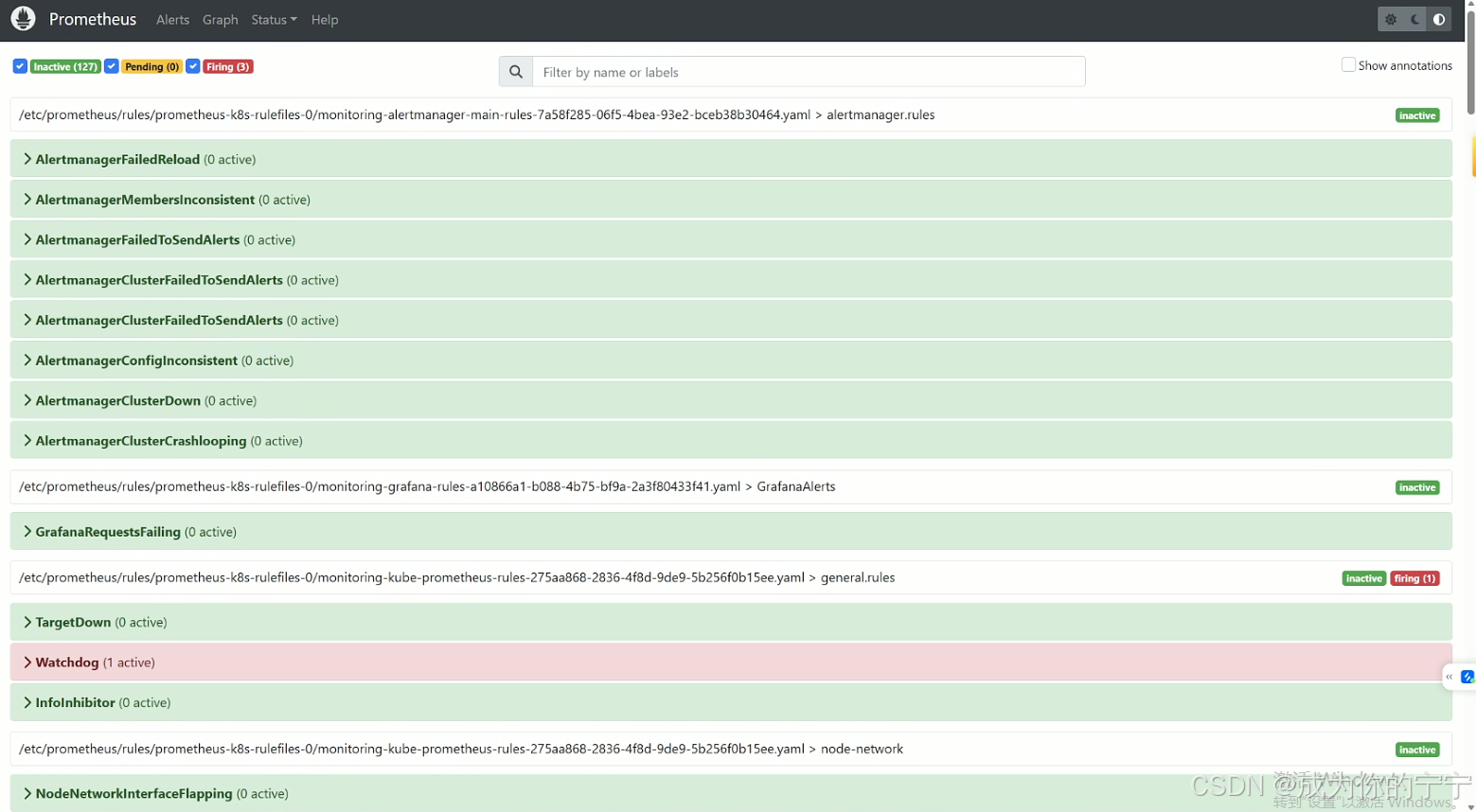
观察targets,可以看到自动添加了很多监控实例
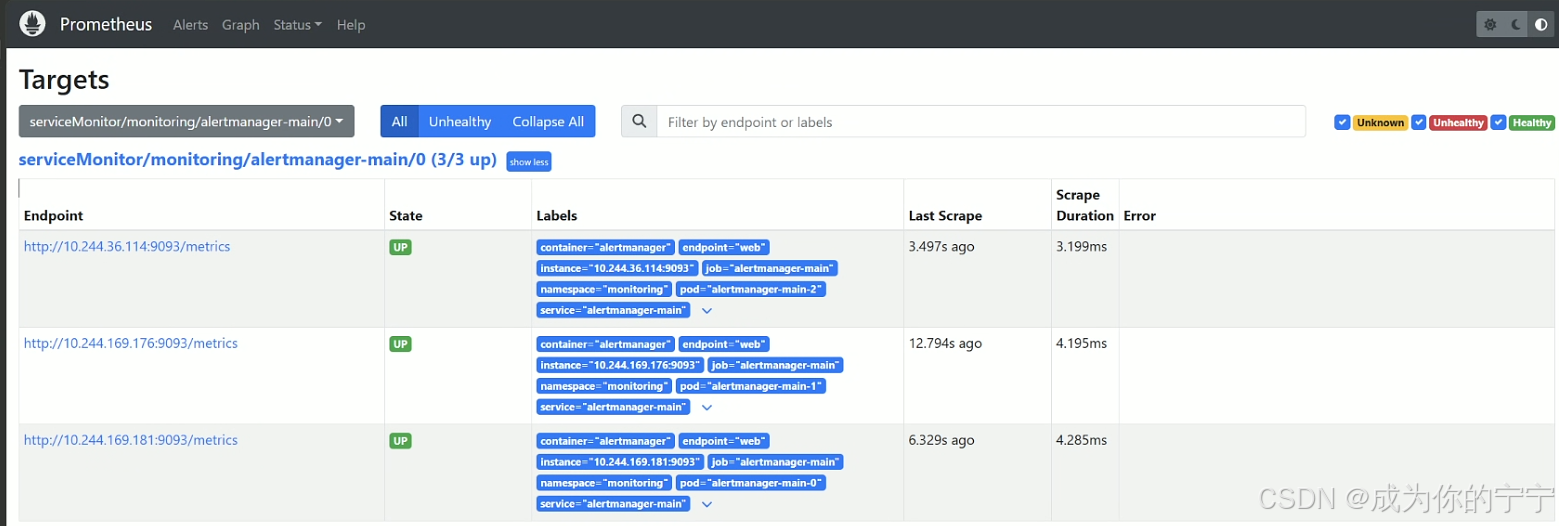
还可以看到有自动添加的alert
alertmanager暴露端口
在此我就不做alertmanager的端口暴露了,因为我待会会做alertmanager的ingress暴露,也就是可以直接用域名访问;想做alertmanager端口暴露的同学可以自行操作,操作步骤和grafana/prometheus类似
3.4 ingress暴露
ingress暴露不是必须做的,只不过是在浏览器上可以用域名访问,大家可做可不做
创建ingress controller
ingress 只是一段规则配置(yaml资源对象),本身不会处理流量
ingress controller 是真正干活的程序,实时监听 K8s 里所有 Ingress 规则,自动把规则转换成 Nginx 配置,真正接管、转发七层HTTP/HTTPS流量,所以我们需要先创建ingress controller
yaml
root@k8s-master1:~# mkdir /k8s/ingress-nginx -p
root@k8s-master1:~# cd /k8s/ingress-nginx/
root@k8s-master1:/k8s/ingress-nginx# vim ingress-nginx.yaml
##这里是Ingress Controller文件由于Ingress Controller yaml文件非常长,我在本文不显示,具体可以去看下文的2.1小节,直接复制Ingress Controller yaml即可
yaml
root@k8s-master1:/k8s/ingress-nginx# kubectl apply -f ingress-nginx.yaml
root@k8s-master1:/k8s/ingress-nginx# kubectl get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-jj54t 0/1 Completed 0 2m27s
ingress-nginx-admission-patch-k4pg8 0/1 Completed 0 2m27s
ingress-nginx-controller-68d5d5f554-6t6s4 1/1 Running 0 2m28s
ingress-nginx-controller-68d5d5f554-bz24d 1/1 Running 0 2m28s
root@k8s-master1:/k8s/ingress-nginx# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.110.87.216 <none> 80:32389/TCP,443:31513/TCP 3m
ingress-nginx-controller-admission ClusterIP 10.98.157.61 <none> 443/TCP 3m创建grafana ingress
yaml
root@k8s-master1:/k8s/ingress-nginx# vim grafana-ingress.yaml
---
apiVersion: networking.k8s.io/v1 # Ingress资源的API版本
kind: Ingress
metadata:
name: nginx-ingress # Ingress 名称
namespace: monitoring
spec:
ingressClassName: nginx # 指定IngressController的类型(haproxy等)
rules: # 路由转发规则,可以写多个
- host: grafana.qingqing.cn # Ingress 规则应用的域名
http:
paths:
- backend:
service:
name: grafana # service名称
port:
number: 3000
path: /
pathType: ImplementationSpecific
root@k8s-master1:/k8s/ingress-nginx# kubectl apply -f grafana-ingress.yaml
root@k8s-master1:/k8s/ingress-nginx# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
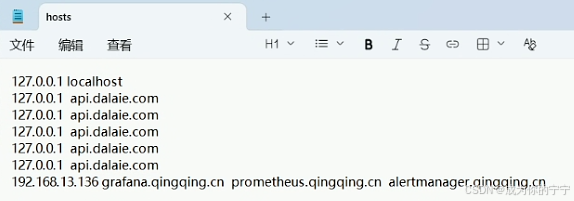
nginx-ingress nginx grafana.qingqing.cn 192.168.13.139,192.168.13.140 80 3m我们需要去本机的/etc/hosts文件中配置域名解析
浏览器访问grafana.qingqing.cn:32389
创建prometheus ingress
yaml
root@k8s-master1:/k8s/ingress-nginx# vim prometheus-ingress.yaml
---
apiVersion: networking.k8s.io/v1 # Ingress资源的API版本
kind: Ingress
metadata:
name: prometheus-ingress # Ingress 名称
namespace: monitoring
spec:
ingressClassName: nginx # 指定IngressController的类型(haproxy等)
rules: # 路由转发规则,可以写多个
- host: prometheus.qingqing.cn # Ingress 规则应用的域名
http:
paths:
- backend:
service:
name: prometheus-k8s # service名称
port:
number: 9090
path: /
pathType: ImplementationSpecific #路由的匹配方式
root@k8s-master1:/k8s/ingress-nginx# kubectl apply -f prometheus-ingress.yaml
root@k8s-master1:/k8s/ingress-nginx# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
nginx-ingress nginx grafana.qingqing.cn 192.168.13.139,192.168.13.140 80 26m
prometheus-ingress nginx prometheus.qingqing.cn 192.168.13.139,192.168.13.140 80 13s浏览器访问:http://prometheus.qingqing.cn:32389
创建alertmanager ingress
yaml
root@k8s-master1:/k8s/ingress-nginx# vim alertmanager-ingress.yaml
---
apiVersion: networking.k8s.io/v1 # Ingress资源的API版本
kind: Ingress
metadata:
name: alertmanager-ingress # Ingress 名称
namespace: monitoring
spec:
ingressClassName: nginx # 指定IngressController的类型(haproxy等)
rules: # 路由转发规则,可以写多个
- host: alertmanager.qingqing.cn # Ingress 规则应用的域名
http:
paths:
- backend:
service:
name: alertmanager-main # service名称
port:
number: 9093
path: /
pathType: ImplementationSpecific
root@k8s-master1:/k8s/ingress-nginx# kubectl apply -f alertmanager-ingress.yaml
root@k8s-master1:/k8s/ingress-nginx# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
alertmanager-ingress nginx alertmanager.qingqing.cn 192.168.13.139,192.168.13.140 80 4m4s
nginx-ingress nginx grafana.qingqing.cn 192.168.13.139,192.168.13.140 80 38m
prometheus-ingress nginx prometheus.qingqing.cn 192.168.13.139,192.168.13.140 80 11m浏览器访问:http://alertmanager.qingqing.cn:32389
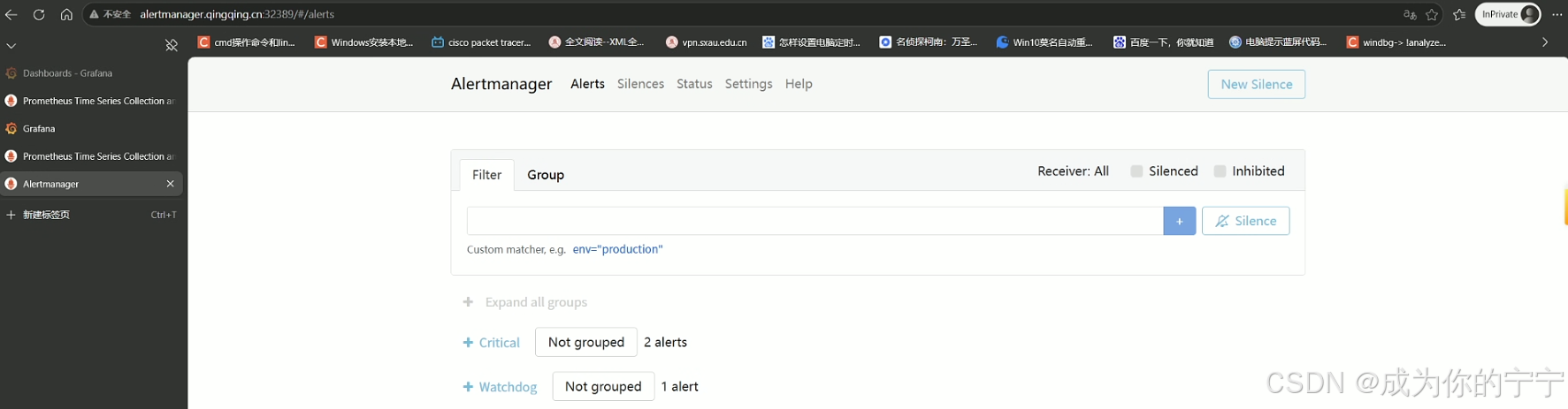
四、监控etcd
etcd默认以系统进程部署在Master节点,非集群Pod,无内置Service;访问依赖TLS证书、节点IP固定不可自动发现。而apiserver、kubelet可依托K8s服务发现自动采集,因此Prometheus-Operator无法默认接入etcd,需手动配置地址、证书与监控资源
etcd集群属于云原生应用,不需要安装exporter,可以直接通过servicemonitor和service进行监控
4.1 确认etcd集群状态
首先我们需要验证etcd端口,证书和成员列表,确认etcd集群健康
yaml
## 1. 查看etcd证书存放位置
root@k8s-master1:~# grep -E "key-file|cert-file" /etc/kubernetes/manifests/etcd.yaml
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
## 2. 手动测试从当前节点能否通过mTLS认证成功访问etcd的metrics接口,并查看返回的一条指标数据
root@k8s-master1:~# curl -s --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key https://192.168.13.136:2379/metrics -k | tail -1
promhttp_metric_handler_requests_total{code="503"} 0
## 3. 确认etcd服务是否正常启动、监听了哪些端口
root@k8s-master1:~# ss -tunlp | grep etcd
tcp LISTEN 0 4096 192.168.13.136:2379 0.0.0.0:* users:(("etcd",pid=3227,fd=9))
tcp LISTEN 0 4096 127.0.0.1:2379 0.0.0.0:* users:(("etcd",pid=3227,fd=8))
tcp LISTEN 0 4096 192.168.13.136:2380 0.0.0.0:* users:(("etcd",pid=3227,fd=7))
tcp LISTEN 0 4096 127.0.0.1:2381 0.0.0.0:* users:(("etcd",pid=3227,fd=15))
yaml
## 4. 在etcd容器内部查看当前etcd集群的所有成员信息
root@k8s-master1:~# kubectl exec -it -n kube-system etcd-k8s-master1 -- sh -c '
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member list -w table'
+------------------+---------+-------------+-----------------------------+-----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-------------+-----------------------------+-----------------------------+------------+
| 75ce36bc25c7a327 | started | k8s-master2 | https://192.168.13.137:2380 | https://192.168.13.137:2379 | false |
| b37efb70492212de | started | k8s-master1 | https://192.168.13.136:2380 | https://192.168.13.136:2379 | false |
| e85a424858816f25 | started | k8s-master3 | https://192.168.13.138:2380 | https://192.168.13.138:2379 | false |
+------------------+---------+-------------+-----------------------------+-----------------------------+------------+4.2 创建endpoints和svc
为etcd成员ip定义固定服务发现入口
yaml
root@k8s-master1:~# mkdir /k8s/etcd
root@k8s-master1:~# cd /k8s/etcd
## 5. 为运行在k8s集群外的etcd集群,提供一个固定的、可被prometheus自动发现的k8s service
root@k8s-master1:/k8s/etcd# vim etcd-svc.yaml
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
app: etcd-prom
name: etcd-prom
namespace: kube-system
# 手动声明etcd成员的真实ip和端口
subsets:
- addresses:
- ip: 192.168.13.136 # etcd宿主机的IP地址
- ip: 192.168.13.137 # etcd宿主机的IP地址
- ip: 192.168.13.138 # etcd宿主机的IP地址
ports:
- name: https-metrics
port: 2379 # etcd 端口
protocol: TCP
---
# 提供一个稳定的clusterip和标签,供servicemonitor选择
apiVersion: v1
kind: Service
metadata:
labels:
app: etcd-prom
name: etcd-prom
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 2379
protocol: TCP
targetPort: 2379
type: ClusterIP
root@k8s-master1:/k8s/etcd# kubectl apply -f etcd-svc.yaml
root@k8s-master1:/k8s/etcd# kubectl get svc etcd-prom -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-prom ClusterIP 10.101.28.178 <none> 2379/TCP 33s4.3 准备证书secret
将etcd的CA,客户端证书和密钥导入prometheus所在的命名空间
yaml
## 6. 通过svc,测试抓取监控数据
root@k8s-master1:/k8s/etcd# curl -s --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key https://10.101.28.178:2379/metrics -k | tail -1
promhttp_metric_handler_requests_total{code="503"} 0
## 7. 创建etcd证书secret
root@k8s-master1:/k8s/etcd# kubectl -n monitoring create secret generic etcd-ssl --from-file=/etc/kubernetes/pki/etcd/ca.crt --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/server.key
root@k8s-master1:/k8s/etcd# kubectl get secret etcd-ssl -n monitoring
NAME TYPE DATA AGE
etcd-ssl Opaque 3 40s
## 8. prometheus绑定etcd的secret资源
root@k8s-master1:/k8s/etcd# cd /root/kube-prometheus/manifests/
root@k8s-master1:~/kube-prometheus/manifests# vim prometheus-prometheus.yaml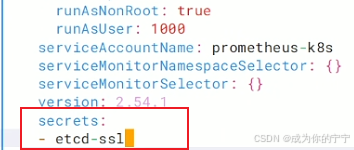
yaml
## 9. 更新资源
root@k8s-master1:~/kube-prometheus/manifests# kubectl replace -f prometheus-prometheus.yaml
root@k8s-master1:~/kube-prometheus/manifests# kubectl get pod prometheus-k8s-0 -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-k8s-0 2/2 Running 2 (8h ago) 3d6h
## 10. 查看secret证书挂在情况
root@k8s-master1:~/kube-prometheus/manifests# sleep 5 && kubectl exec prometheus-k8s-0 -n monitoring -c prometheus -- ls /etc/prometheus/secrets/etcd-ssl
ca.crt
server.crt
server.key4.4 创建servicemonitor
创建servicemonitor,配置抓取间隔,端口,TLS和证书引用
yaml
## 11. 创建servicemonitor
root@k8s-master1:~/kube-prometheus/manifests# vim etcd-servicemonitor.yaml
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd
namespace: monitoring
labels:
app: etcd
spec:
jobLabel: k8s-etcd-cluster-apps
endpoints: # 目标
- interval: 30s # 监控指标抓取时间间隔
port: https-metrics # 这个port对应Service.spec.ports.name
scheme: https # 监控接口对应的协议
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-ssl/ca.crt # 证书路径
certFile: /etc/prometheus/secrets/etcd-ssl/server.crt
keyFile: /etc/prometheus/secrets/etcd-ssl/server.key
insecureSkipVerify: true # 关闭证书校验
selector:
matchLabels:
app: etcd-prom # 监控目标service的标签
namespaceSelector:
matchNames:
- kube-system # 监控目标service存在的命名空间
root@k8s-master1:~/kube-prometheus/manifests# kubectl apply -f etcd-servicemonitor.yaml
root@k8s-master1:~/kube-prometheus/manifests# kubectl get servicemonitor -n monitoring| grep etcd
etcd 35s登录prometheus,可以看到etcd数据库添加成功
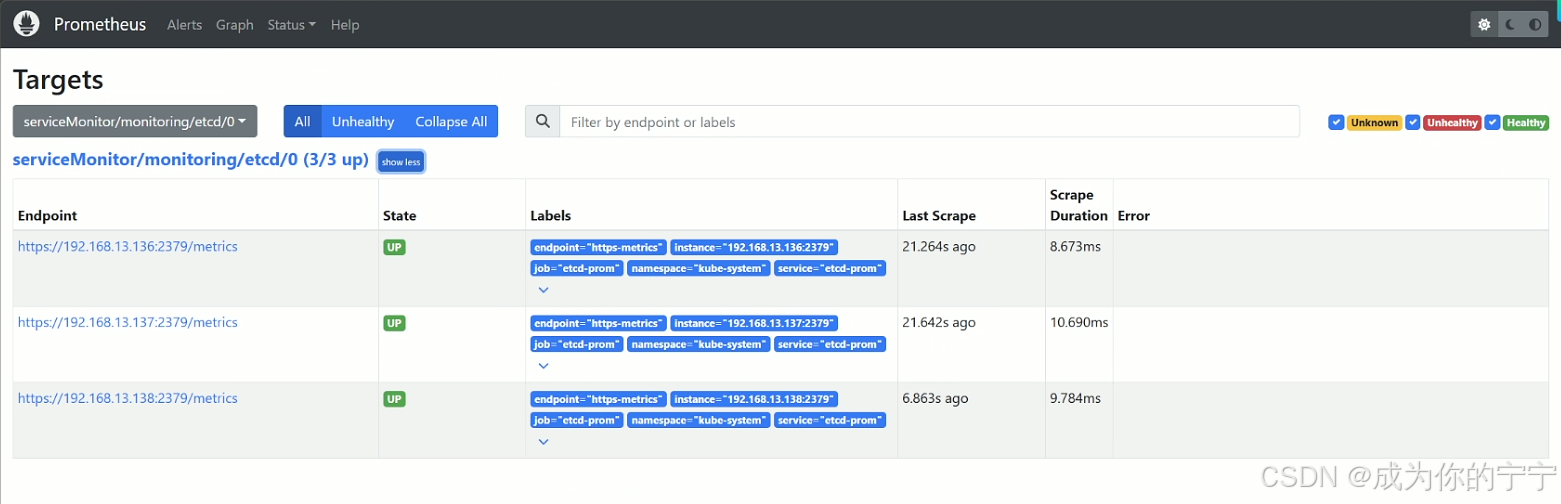
4.5 在grafana中添加dashboard
大家可以自行登录grafana官网,自行选择适合的面板
Grafana dashboard官网:https://grafana.com/grafana/dashboards/
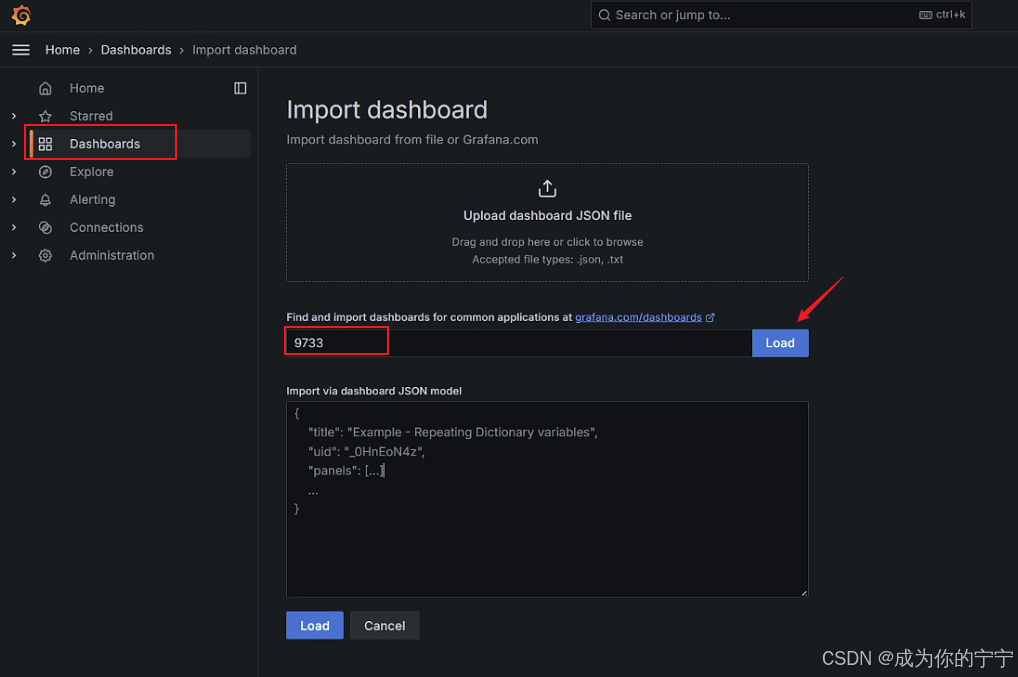
登录grafana,添加dashboard面板
我选择的是这个面板https://grafana.com/grafana/dashboards/9733-etcd-for-k8s-cn/
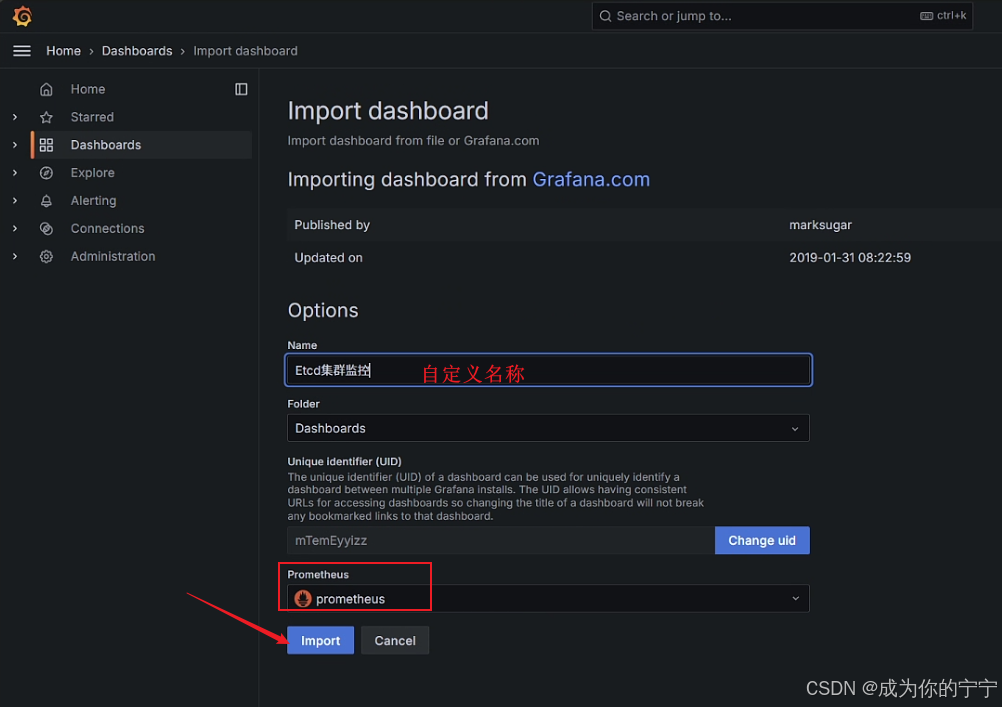
添加好后就会显示etcd数据监控情况
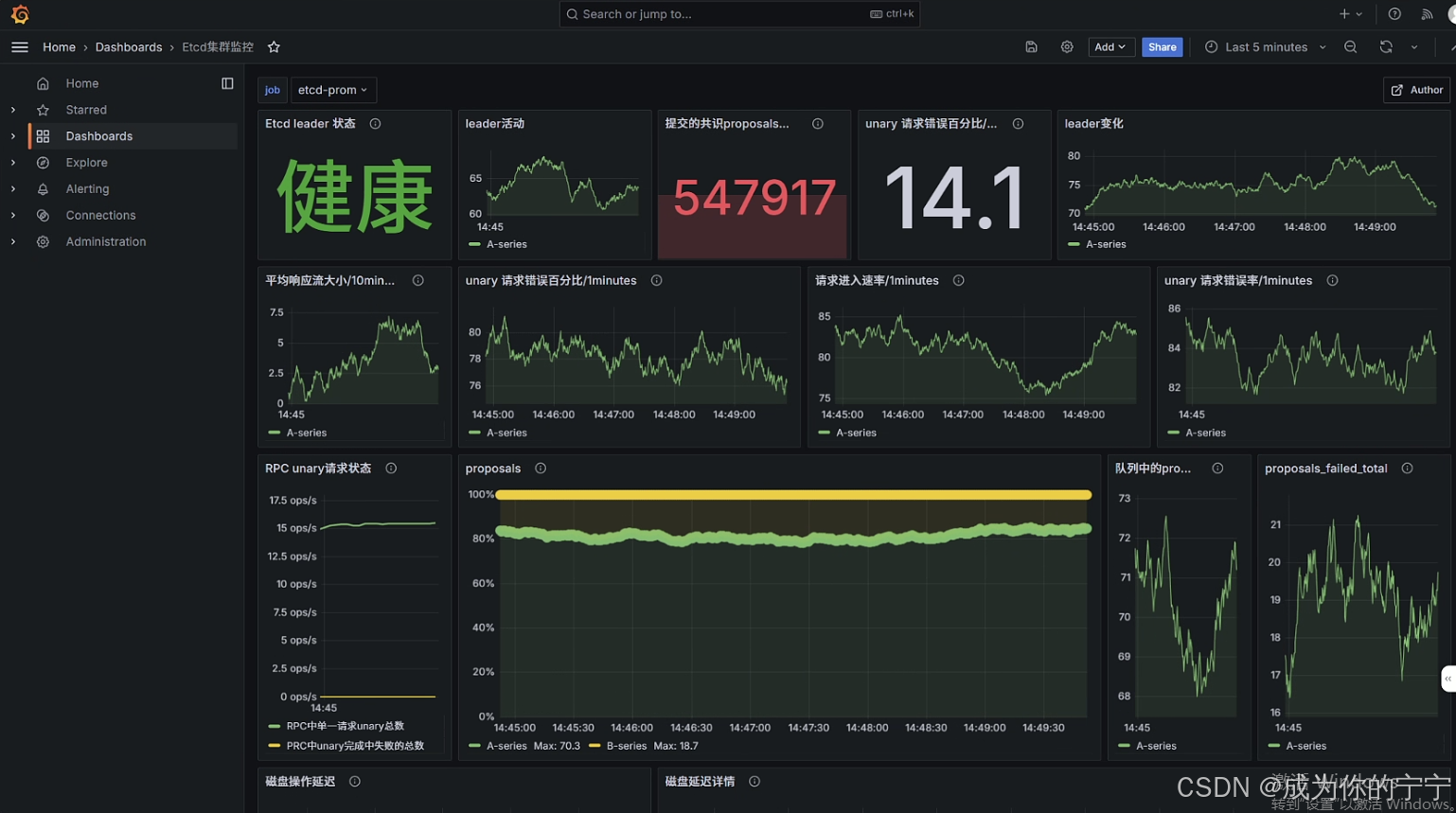
至此,K8s集群Prometheus基础监控部署流程全部完成。后续将持续更新教程,拓展各类业务与组件指标的监控配置
注:
文中若有疏漏,欢迎大家指正赐教。
本文为100%原创,转载请务必标注原创作者,尊重劳动成果。
求赞、求关注、求评论!你的支持是我更新的最大动力,评论区等你~