很多团队第一次做 RAG,最容易把精力放在"怎么把文档切块、向量化、写入向量库"上。Demo 很快能跑起来:上传 PDF,切成 chunk,调用 Embedding,存进 PGvector,然后用 Spring AI 的 QuestionAnswerAdvisor 做问答。
真正上线后,麻烦才开始。
业务文档会改,制度会废止,产品手册会补丁更新,合同模板会换版本。如果知识库只会"新增向量",不会识别"哪些内容已经变了、哪些内容应该删除",RAG 系统就会慢慢变脏:旧答案和新答案同时被召回,模型看起来很自信,实际引用的是过期内容。
RAG 的增量更新不是一个批处理脚本,而是知识库长期可维护的核心能力。
错误做法:每次都追加 chunk
最常见的做法是这样的:
- 用户上传文档。
- 后端解析文本。
- 文本分块。
- 每个 chunk 写入向量数据库。
- 问答时按相似度召回。
这个流程适合第一次导入,不适合持续更新。因为它没有回答三个问题:
- 同一份文档重新上传时,旧 chunk 怎么处理?
- 文档只改了一小段时,要不要整篇重新向量化?
- 文档被删除或下线后,向量库里的内容是否同步删除?
如果这些问题不处理,向量库会变成"历史垃圾场"。相似度检索不会天然理解业务版本,它只会把语义接近的内容找出来。旧制度和新制度都和用户问题很接近时,模型很可能混着回答。
增量更新要先定义文档身份
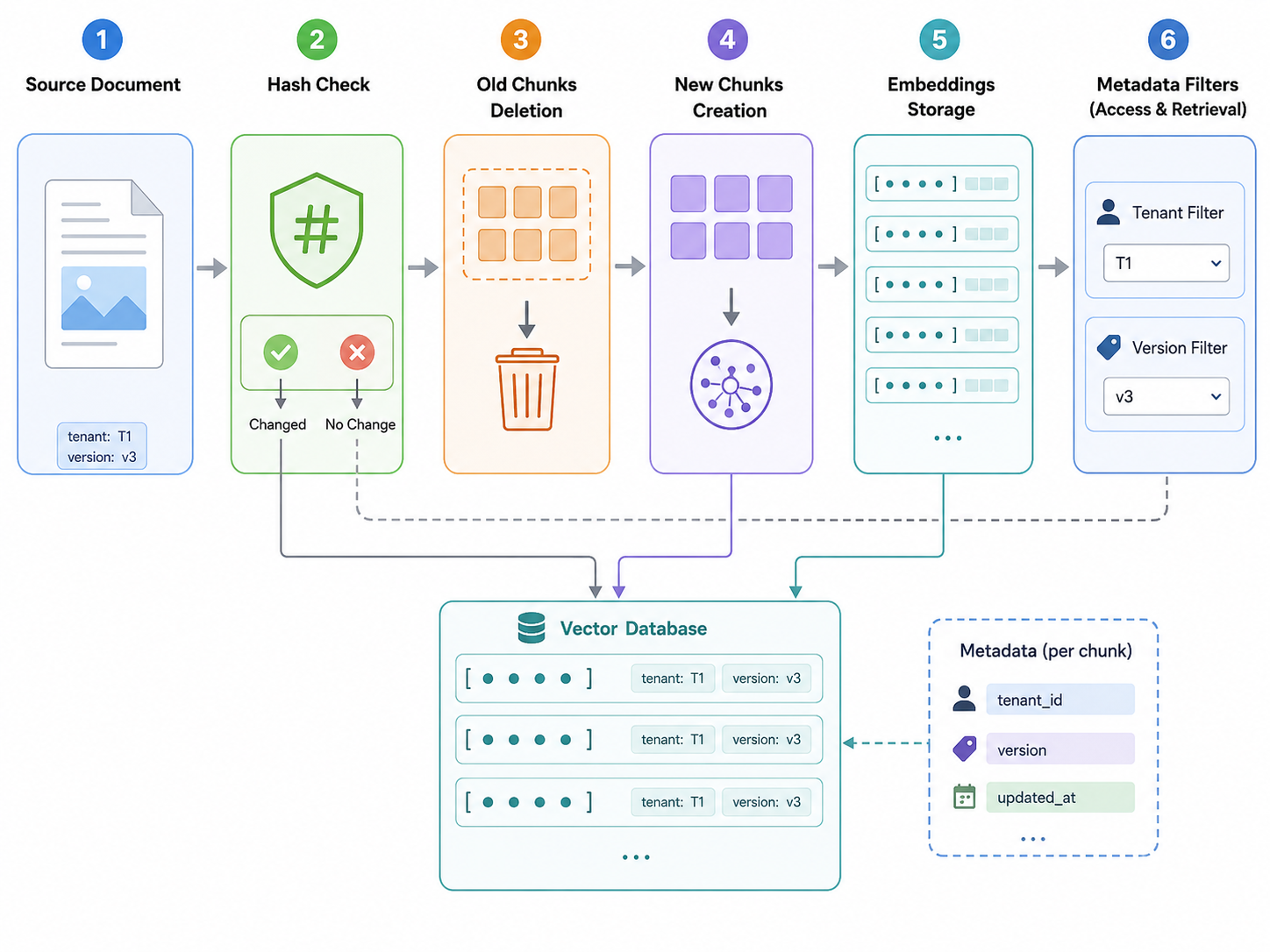
在 Java 后端项目里,不要直接把"文件名"当作唯一标识。文件名会重复,用户会改名,同一个文件也可能来自不同租户、不同业务线。
更稳妥的做法是给知识库文档设计一组元数据:
| 字段 | 作用 |
|---|---|
| tenant_id | 租户或业务空间隔离 |
| doc_id | 业务文档唯一标识 |
| source_hash | 原始内容哈希,用于判断内容是否变化 |
| doc_version | 文档版本,便于审计和回滚 |
| chunk_index | 当前 chunk 在文档中的位置 |
| enabled | 是否参与检索 |
| updated_at | 最近更新时间 |
这里的关键不是字段多,而是 doc_id 和 source_hash。
doc_id 解决"这是谁"的问题,source_hash 解决"它变没变"的问题。没有这两个字段,后面很难做可靠的删除、替换和审计。
一种更靠谱的同步流程
RAG 知识库的增量同步可以拆成四种状态:
- 新文档:向量库不存在,直接解析、分块、写入。
- 未变化文档:source_hash 一致,跳过向量化。
- 已变化文档:删除旧 chunk,再写入新 chunk。
- 已删除文档:删除或禁用对应 chunk。
很多项目会纠结"文档改了一小段,能不能只更新局部 chunk"。理论上可以,但第一版不建议这么做。局部更新需要稳定分块策略、chunk 对齐、版本映射和失败补偿,复杂度很快上升。
工程上更务实的第一版是:以文档为单位替换 chunk。只要发现 source_hash 变化,就删除该 doc_id 下的旧 chunk,再写入新 chunk。对于大多数企业知识库,这个方案已经足够稳定。
Spring AI 里的关键实现思路
Spring AI 提供了文档、文本切分、VectorStore、metadata filter、RAG Advisor 等能力,可以把增量更新做进 Spring Boot 服务里。下面示例只保留关键逻辑,具体 API 可能会随版本变化,实际项目中应以官方文档为准。
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>
java
@Service
public class KnowledgeSyncService {
private final VectorStore vectorStore;
private final TokenTextSplitter textSplitter;
private final DocumentRepository documentRepository;
public KnowledgeSyncService(VectorStore vectorStore,
DocumentRepository documentRepository) {
this.vectorStore = vectorStore;
this.documentRepository = documentRepository;
this.textSplitter = new TokenTextSplitter();
}
public void sync(String tenantId, String docId, String content) {
String sourceHash = DigestUtils.sha256DigestAsHex(
content.getBytes(StandardCharsets.UTF_8)
);
KnowledgeDocument existing = documentRepository.findByTenantIdAndDocId(tenantId, docId);
if (existing != null && sourceHash.equals(existing.sourceHash())) {
return;
}
if (existing != null) {
deleteOldChunks(tenantId, docId);
}
Document source = new Document(content, Map.of(
"tenant_id", tenantId,
"doc_id", docId,
"source_hash", sourceHash,
"doc_version", UUID.randomUUID().toString(),
"enabled", true
));
List<Document> chunks = textSplitter.apply(List.of(source));
for (int i = 0; i < chunks.size(); i++) {
chunks.get(i).getMetadata().put("chunk_index", i);
}
vectorStore.add(chunks);
documentRepository.upsert(tenantId, docId, sourceHash);
}
private void deleteOldChunks(String tenantId, String docId) {
FilterExpressionBuilder b = new FilterExpressionBuilder();
var filter = b.and(
b.eq("tenant_id", tenantId),
b.eq("doc_id", docId)
).build();
vectorStore.delete(filter);
}
}这个代码的重点不是 TokenTextSplitter,而是更新顺序:先判断内容是否变化,再按元数据删除旧 chunk,最后写入新 chunk 并更新业务表。
如果担心"删除成功但新增失败",不要把同步逻辑写成无补偿的一次性流程。生产环境里可以把文档状态拆成 SYNCING、READY、FAILED,失败后重试。更严格的场景还可以先写入新版本 chunk,再把旧版本标记为不可检索,最后异步清理。
查询时也要带上过滤条件
增量更新只解决"库里有什么",查询过滤解决"本次能看什么"。如果用户属于某个租户、部门或知识空间,检索时必须把这些条件传给向量库。
java
String answer = ChatClient.builder(chatModel)
.build()
.prompt()
.user(question)
.advisors(QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.filterExpression("tenant_id == '" + tenantId + "' && enabled == true")
.topK(5)
.build())
.build())
.call()
.content();真实项目里不要随手拼接复杂过滤表达式,尤其是过滤条件来自用户输入时。更好的方式是把租户、知识空间、权限范围这些信息从登录态或服务端上下文生成,避免让前端决定检索边界。
另外,topK 不是越大越好。旧 chunk 没删干净时,topK 调大只会让更多脏数据进入上下文。先把数据生命周期管住,再谈召回优化。
还有几个容易忽略的坑
第一,分块策略变化也应该触发重建。比如你把 chunk size 从 800 改到 500,旧 chunk 和新 chunk 混在一起,召回效果会变得难以评估。可以给 metadata 加一个 chunk_strategy_version。
第二,Embedding 模型变化也应该触发重建。不同模型生成的向量空间不一定兼容,把两种 embedding 混在一个集合里检索,结果可能很怪。
第三,删除策略要可审计。很多企业文档不是物理删除,而是下线、失效、权限变更。向量库里可以物理删,但业务库里最好保留同步记录,方便排查"为什么这份文档搜不到"。
第四,知识库更新不一定要同步阻塞用户请求。上传文档后先落业务库和对象存储,再通过消息队列或异步任务做解析和向量化,用户看到的状态是"处理中"。这比让上传接口卡在 Embedding 调用上稳定得多。
RAG 系统的质量,不只取决于模型和向量数据库。很多时候,决定它能不能长期使用的,是后端工程里这些朴素的设计:文档身份、版本、删除、过滤、重试和审计。先把知识库维护干净,再去优化 rerank、query rewrite 和更复杂的 Agent 编排,顺序会更稳。