目录
[1 E4M3 E5M2的问题](#1 E4M3 E5M2的问题)
[2 BF16 FP16](#2 BF16 FP16)
[2.1 fp16(IEEE half,半精度)](#2.1 fp16(IEEE half,半精度))
[2.2 bf16(bfloat16,Brain Float)](#2.2 bf16(bfloat16,Brain Float))
[2.3 区别对比](#2.3 区别对比)
[3 VLLM里面的kv cache的量化与反量化过程](#3 VLLM里面的kv cache的量化与反量化过程)
[4 先梳理一下读取KV CACHE的代码大体流程:以后会详细梳理整个kv cache相关完整代码,这次只看一部分](#4 先梳理一下读取KV CACHE的代码大体流程:以后会详细梳理整个kv cache相关完整代码,这次只看一部分)
[4.1 Host 入口:谁发起「读 KV 做 Attention」](#4.1 Host 入口:谁发起「读 KV 做 Attention」)
[4.2 宏分发:把 "fp8_e5m2" 绑到 kFp8E5M2](#4.2 宏分发:把 "fp8_e5m2" 绑到 kFp8E5M2)
[4.3 宏链展开:一路传到 kernel 启动](#4.3 宏链展开:一路传到 kernel 启动)
[4.4 GPU 核函数外壳](#4.4 GPU 核函数外壳)
[4.5 核心逻辑:从 cache 读 K(uint8)→ 反量化 → QK](#4.5 核心逻辑:从 cache 读 K(uint8)→ 反量化 → QK)
[4.5.1 定义向量类型(一次读 16 字节)](#4.5.1 定义向量类型(一次读 16 字节))
[4.5.2 从 paged k_cache 读出一段 FP8](#4.5.2 从 paged k_cache 读出一段 FP8)
[4.5.3 反量化成 K_vec(bf16 向量)--- 整条 bug 链的入口](#4.5.3 反量化成 K_vec(bf16 向量)— 整条 bug 链的入口)
[4.5.4 用反量化后的 K 和 Q 算分](#4.5.4 用反量化后的 K 和 Q 算分)
[4.6 scaled_convert:统一入口](#4.6 scaled_convert:统一入口)
[4.7 scaled_vec_conversion:向量拆包,最后落到单字节 E5M2 反量化](#4.7 scaled_vec_conversion:向量拆包,最后落到单字节 E5M2 反量化)
[4.8 最底层:E5M2 字节 → float 也是这次新增加的函数](#4.8 最底层:E5M2 字节 → float 也是这次新增加的函数)
提问、abstract:
exponent 英/ ɪkˈspəʊnənt / 美/ ɪkˈspoʊnənt /
- n.拥护者,倡导者;代表人物;指数,幂;大师,行家;成分;说明者,说明物
- adj.说明的
mantissa 英/ mænˈtɪsə / 美/ mænˈtɪsə /
- n.数尾数;假数;定点部分;小数部分
FP8:E4M3 / E5M2(8bit = 1符号 + E + M)
FP16:E5M10(16bit)← 和 E5M2 同 5 指数,尾数 10 不是 2
BF16就是E8M7**(16bit)← 指数同 fp32,尾数砍短**
值 = 符号 × 2^指数 × (1.xxx)
zero point(零点), scale(缩放因子)
1 E4M3 E5M2的问题
这里的命名是硬件/浮点格式里的习惯写法,不是数学里的自然常数 e。
| 字母 | 英文全称 | 中文常见叫法 |
|---|---|---|
| E | Exponent | 指数(表示 2 的多少次方 那一部分) |
| M | Mantissa | 尾数(表示有效数字/小数精细程度那一部分) |
exponent 英/ ɪkˈspəʊnənt / 美/ ɪkˈspoʊnənt /
- n.拥护者,倡导者;代表人物;指数,幂;大师,行家;成分;说明者,说明物
- adj.说明的
mantissa 英/ mænˈtɪsə / 美/ mænˈtɪsə /
- n.数尾数;假数;定点部分;小数部分
bash
最终值 = 符号 × 2^(指数) × (1.xxx)
↑
这里的 1.xxx 来自尾数位- 存进 M(尾数位) 的,是
1.后面的小数部分(有的格式隐含开头的 1,不占用 bit) - 所以 (1.xxx) 这一段 一般在 1.0 到不到 2.0 之间
例如:1.0、1.25、1.5、1.75,不会是5.01这种"已经放大过的整数" - 整体值小于 1 时,不靠「尾数小于 1」,而是靠 指数为负,把结果缩小。
- 所以这里尾数永远都是1.xx的形式。
2 BF16 FP16
和 FP8 一样,都是:
| 符号 S | 指数 E | 尾数 M |
数值(归一化时)仍是:
值 = (-1)^S × 2^(指数) × (1.xxx)
- 指数:2 的多少次方(不是 10,也不是 e)
- 尾数 (1.xxx) 仍在 1~2 之间;小于 1 的数用 负指数;大于 1 用正指数
差别只在:16 bit 怎么分给 S、E、M。
2.1 fp16(IEEE half,半精度)
| 字段 | 位数 |
|---|---|
| 符号 S | 1 |
| 指数 E | 5 |
| 尾数 M | 10 |
和 E5M2 一样,指数只有 5 bit → 能表示的 2 的幂次范围较窄;尾数 10 bit → 在 1~2 之间台阶很密 → 相对更精细。
2.2 bf16(bfloat16,Brain Float)
| 字段 | 位数 |
|---|---|
| 符号 S | 1 |
| 指数 E | 8 |
| 尾数 M | 7 |
设计目标:指数和 fp32 一样(8 bit),尾数只留 7 bit。
可以把它想成:
bash
fp32:|S| 8位指数 | 23位尾数 |
bf16:|S| 8位指数 | 7位尾数 | ← 相当于 fp32 砍掉后面一截尾数2.3 区别对比
| fp16 | bf16 |
|-----------|-----------|-------------------------------|
| 总位数 | 16 | 16 |
| 指数 | 5 bit | 8 bit(与 fp32 一致) |
| 尾数 | 10 bit | 7 bit |
| 动态范围 | 小(易溢出/下溢) | 大(接近 fp32) |
| 精度 | 高(尾数多) | 低(尾数少) |
| 和 fp32 转换 | 要专门转换 | 很常见:取 fp32 高 16 bit |
| 大模型里 | 推理、部分训练 | 训练/推理主精度很常见(DeepSeek、Llama 等) |
3 VLLM里面的kv cache的量化与反量化过程
这里对称量化,没有zeropoint,只有一个scale,
bash
写 KV 读 KV
┌─────────────────────────┐ ┌─────────────────────────┐
K/V │ bf16 (或 fp16/float) │ │ cache 里 8bit FP8 │
计算 │ ÷ scale │ │ × scale │
结果 ──┤ → E5M2 或 E4M3 编码 ├───►│ → float/bf16/fp16 ├──► Attention
│ → 存入 KV cache │ │ (寄存器里即时转换) │
└─────────────────────────┘ └─────────────────────────┘4 先梳理一下读取KV CACHE的代码大体流程:以后会详细梳理整个kv cache相关完整代码,这次只看一部分
前提:启动参数 --kv-cache-dtype fp8_e5m2,模型计算用 bf16,cache 里每个 K/V 元素是 1 字节 uint8(FP8 E5M2)。
4.1 Host 入口:谁发起「读 KV 做 Attention」
vllm015/csrc/attention/paged_attention_v1.cu 160--182
cpp
void paged_attention_v1(
torch::Tensor& out, // [num_seqs, num_heads, head_size]
torch::Tensor& query, // [num_seqs, num_heads, head_size]
torch::Tensor&
key_cache, // [num_blocks, num_heads, head_size/x, block_size, x]
torch::Tensor&
value_cache, // [num_blocks, num_heads, head_size, block_size]
int64_t num_kv_heads, // [num_heads]
double scale,
torch::Tensor& block_tables, // [num_seqs, max_num_blocks_per_seq]
torch::Tensor& seq_lens, // [num_seqs]
int64_t block_size, int64_t max_seq_len,
const std::optional<torch::Tensor>& alibi_slopes,
const std::string& kv_cache_dtype, torch::Tensor& k_scale,
torch::Tensor& v_scale, const int64_t tp_rank,
const int64_t blocksparse_local_blocks,
const int64_t blocksparse_vert_stride, const int64_t blocksparse_block_size,
const int64_t blocksparse_head_sliding_step) {
const bool is_block_sparse = (blocksparse_vert_stride > 1);
DISPATCH_BY_KV_CACHE_DTYPE(query.dtype(), kv_cache_dtype,
CALL_V1_LAUNCHER_BLOCK_SIZE)
}4.2 宏分发:把 "fp8_e5m2" 绑到 kFp8E5M2
vllm015/csrc/quantization/w8a8/fp8/amd/quant_utils.cuh 746--794行
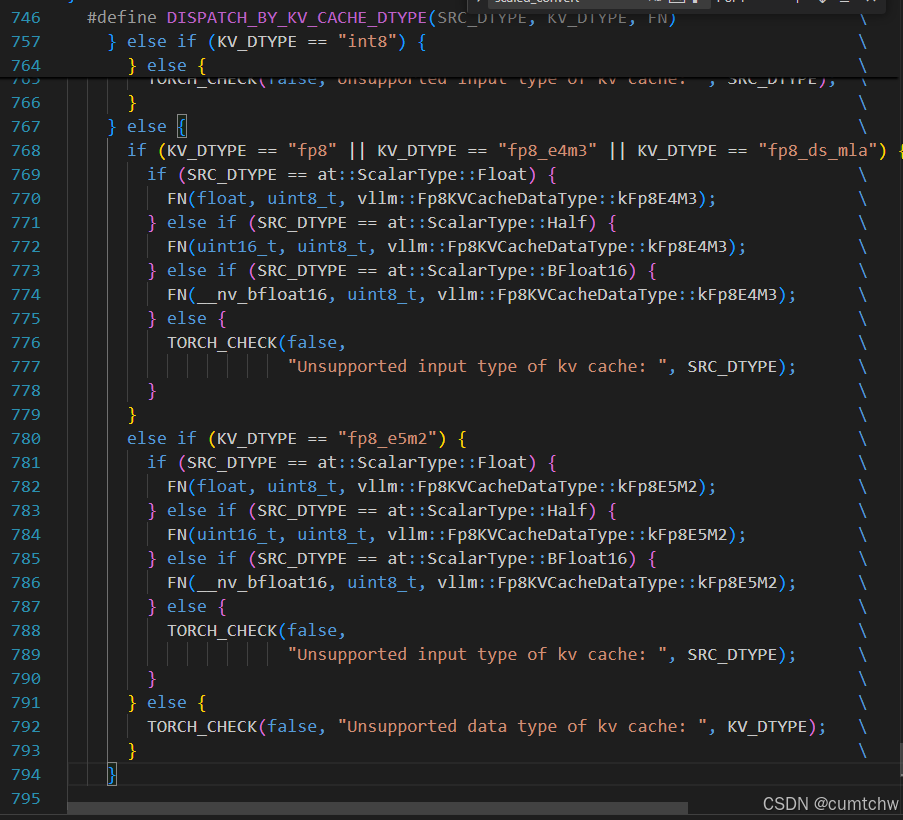
当 kv_cache_dtype == "fp8_e5m2" 且 query 是 bf16 时,预处理器展开为
cpp
CALL_V1_LAUNCHER_BLOCK_SIZE(__nv_bfloat16, uint8_t, kFp8E5M2);4.3 宏链展开:一路传到 kernel 启动
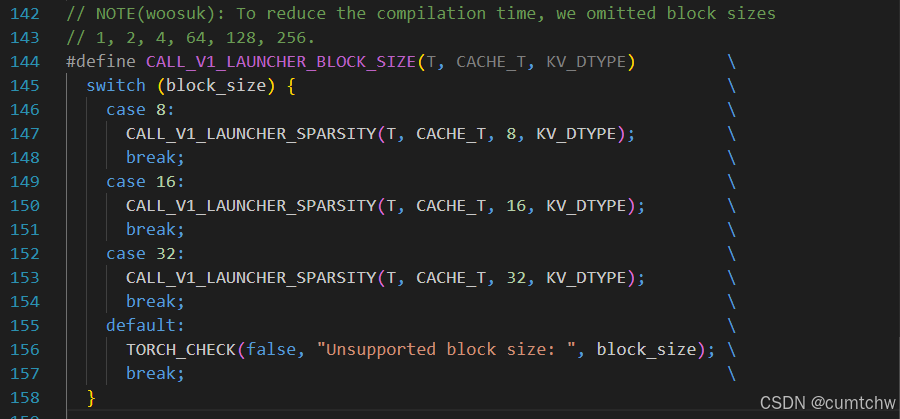
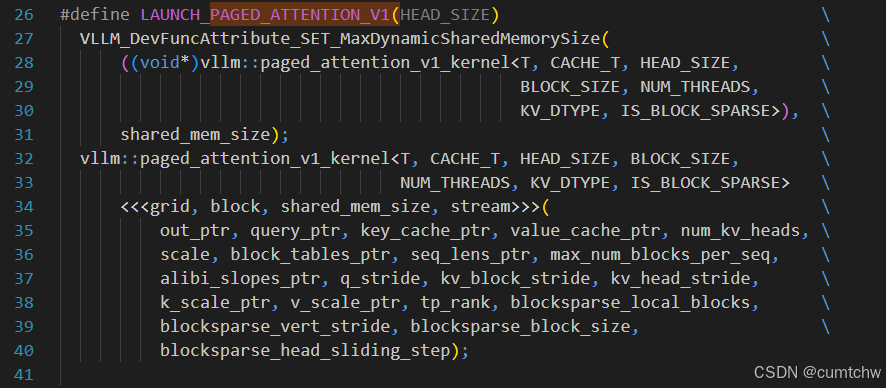
vllm015/csrc/attention/paged_attention_v1.cu
| 子步 | 行号 | 宏 / 函数 | 作用 |
|---|---|---|---|
| 3a | 144--153 | CALL_V1_LAUNCHER_BLOCK_SIZE |
按 block_size(8/16/32)分支 |
| 3b | 135--139 | CALL_V1_LAUNCHER_SPARSITY |
是否 block sparse |
| 3c | 127--133 | CALL_V1_LAUNCHER |
调用 paged_attention_v1_launcher<bf16, uint8_t, block_size, kFp8E5M2, ...> |
| 3d | 46--125 | paged_attention_v1_launcher |
按 head_size switch,准备 grid/block/shared mem |
| 3e | 26--40 | LAUNCH_PAGED_ATTENTION_V1 |
paged_attention_v1_kernel<<<grid, block, stream>>>(...) |
4.4 GPU 核函数外壳
vllm015/csrc/attention/attention_kernels.cuh
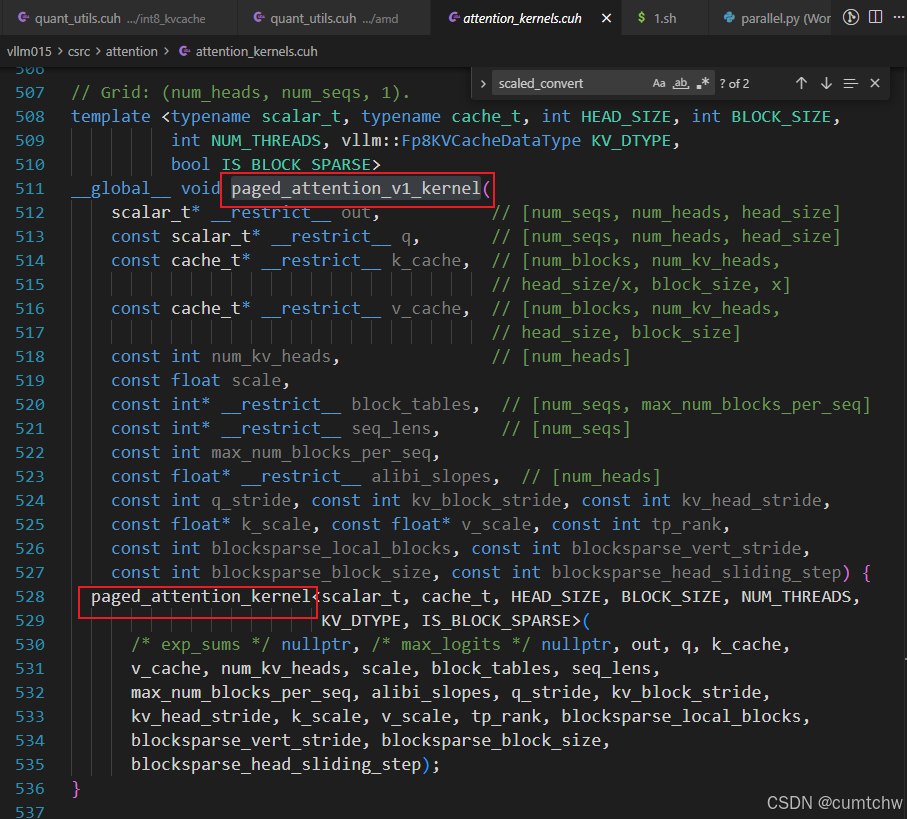
4.5 核心逻辑:从 cache 读 K(uint8)→ 反量化 → QK
vllm015/csrc/attention/attention_kernels.cuh
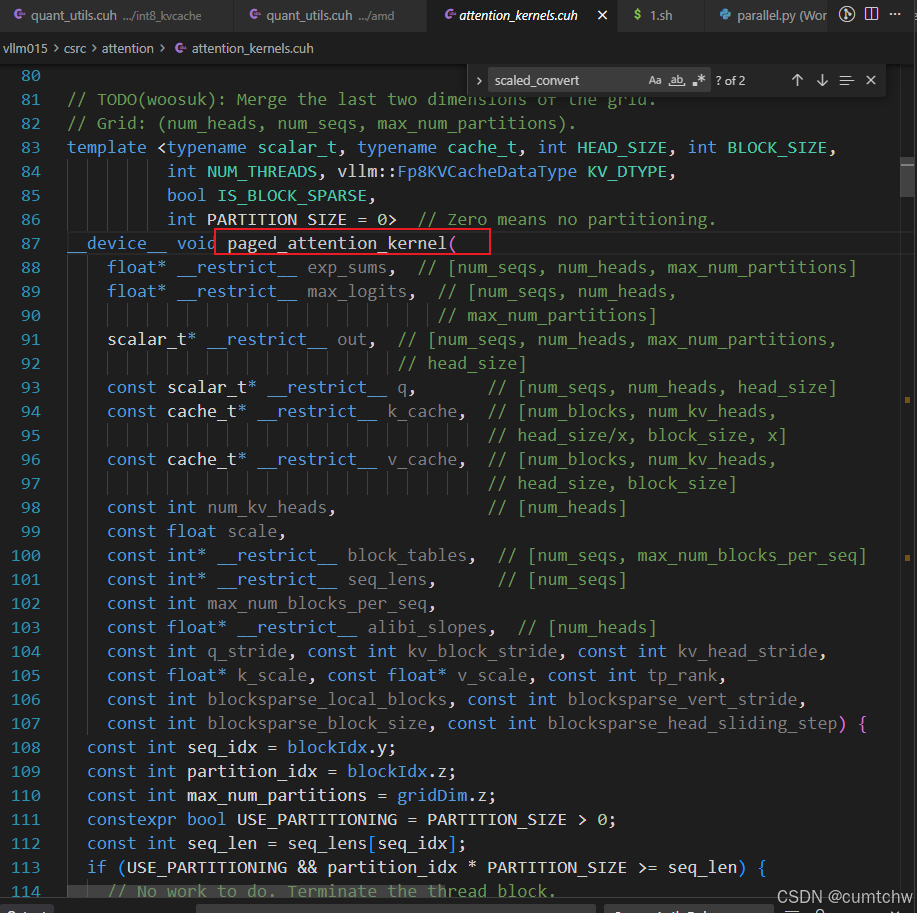
4.5.1 定义向量类型(一次读 16 字节)
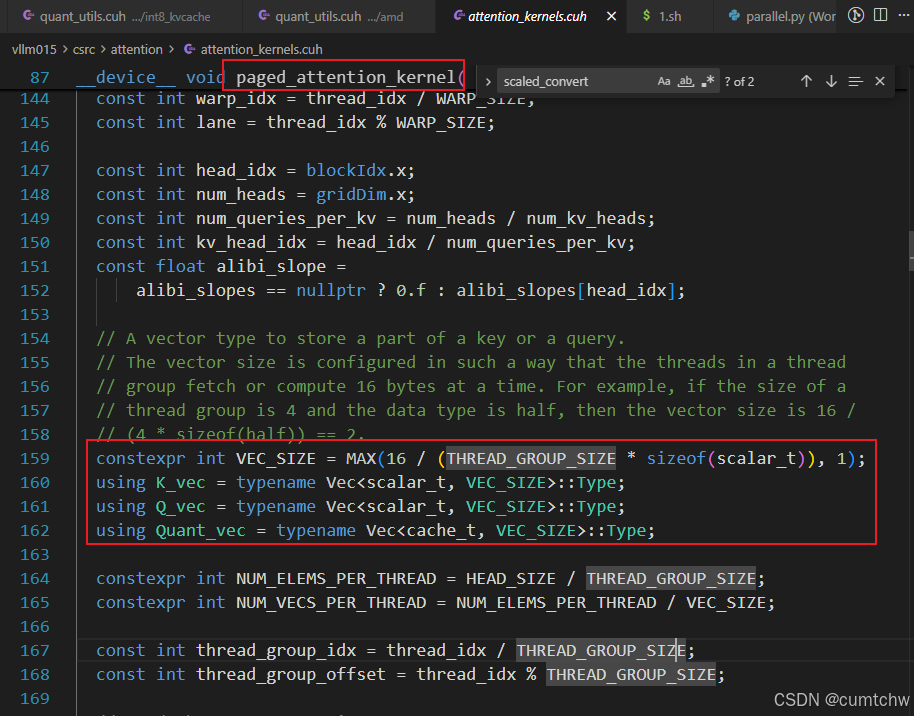
4.5.2 从 paged k_cache 读出一段 FP8
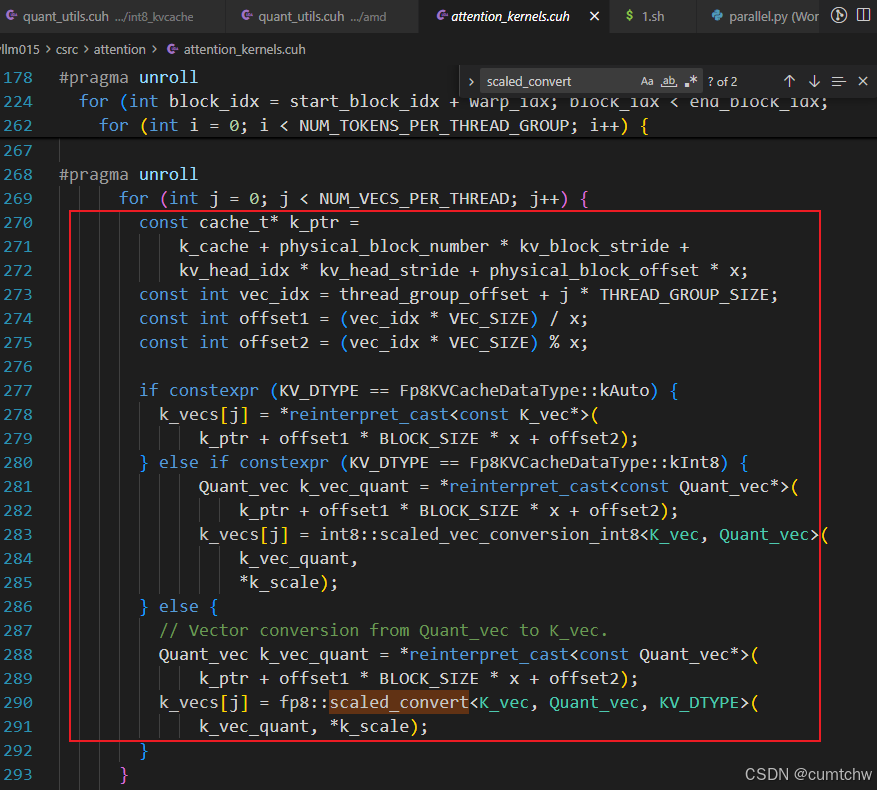
k_ptr指向 cache 里某个 token 的 Kk_vec_quant:reinterpret_cast成Quant_vec(例如 4 个 uint8 打包在一个uint32_t里)
4.5.3 反量化成 K_vec(bf16 向量)--- 整条 bug 链的入口
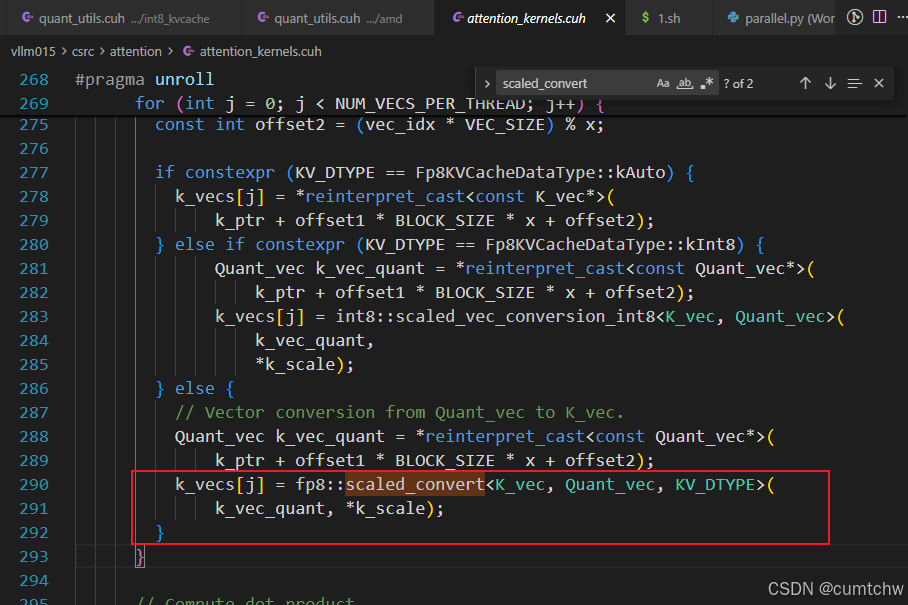
4.5.4 用反量化后的 K 和 Q 算分
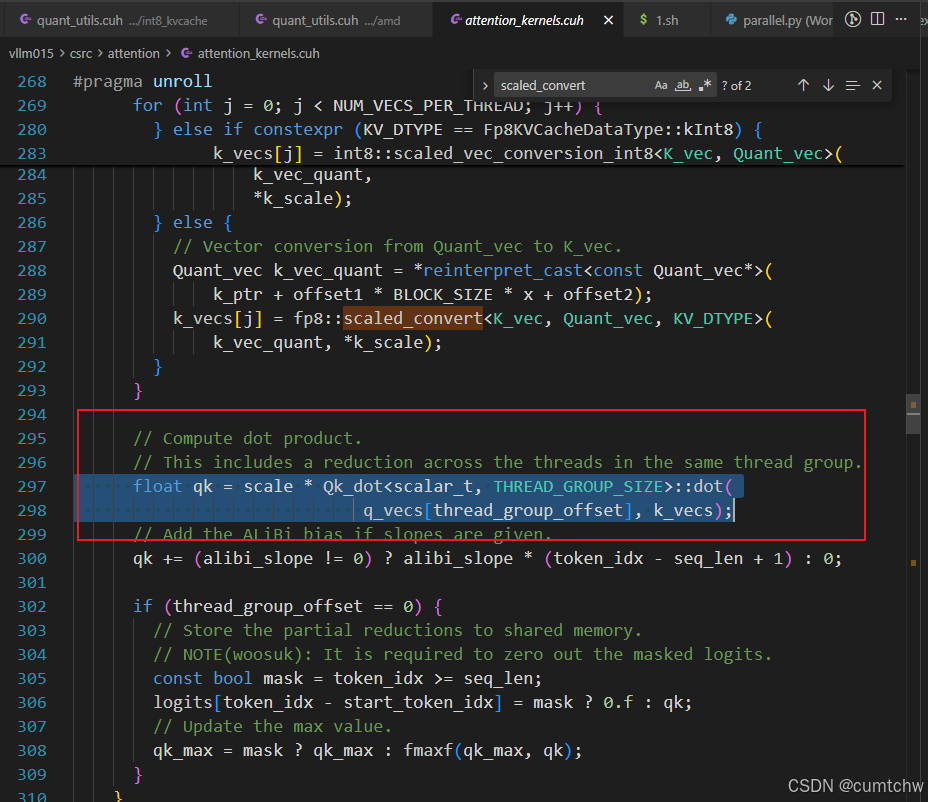
后面还有 softmax、再读 V(423--427 行,同样 scaled_convert,逻辑与 K 类似)。
在干什么:每个 thread 从 cache 读 FP8 字节 → 转成 bf16 的 K → 参与 attention;读错 = gsm8k 答非所问。
4.6 scaled_convert:统一入口
vllm015/csrc/quantization/w8a8/fp8/amd/quant_utils.cuh
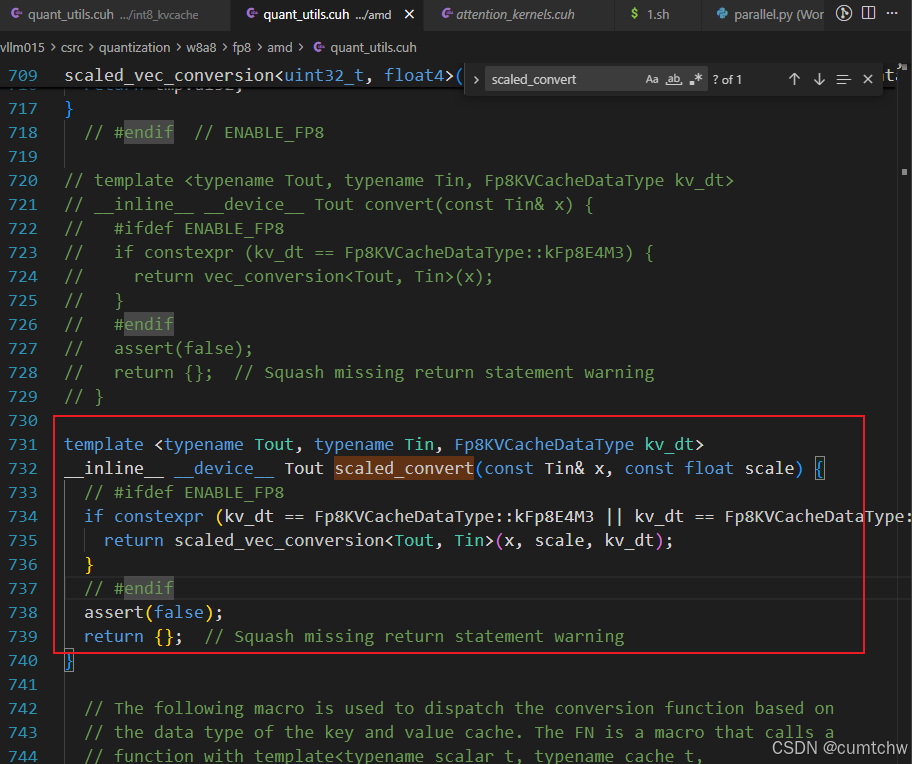
这里:
Tout=K_vec(如bf16_4_t)Tin=Quant_vec(如uint32_t)kv_dt=kFp8E5M2
4.7 scaled_vec_conversion:向量拆包,最后落到单字节 E5M2 反量化
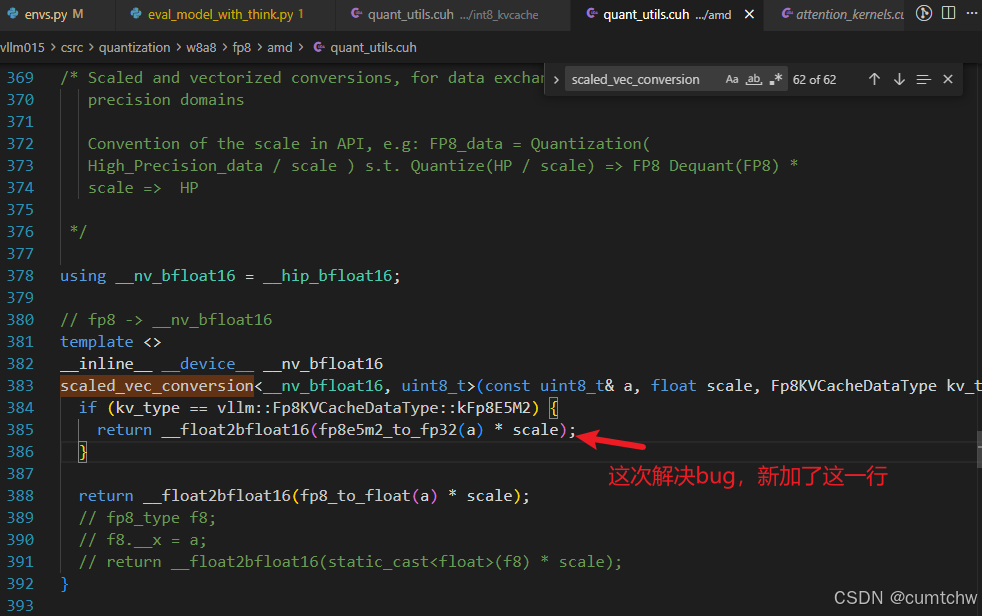
其他两个函数也顺便增加了
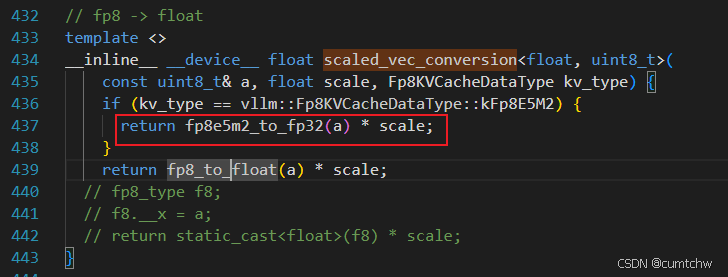
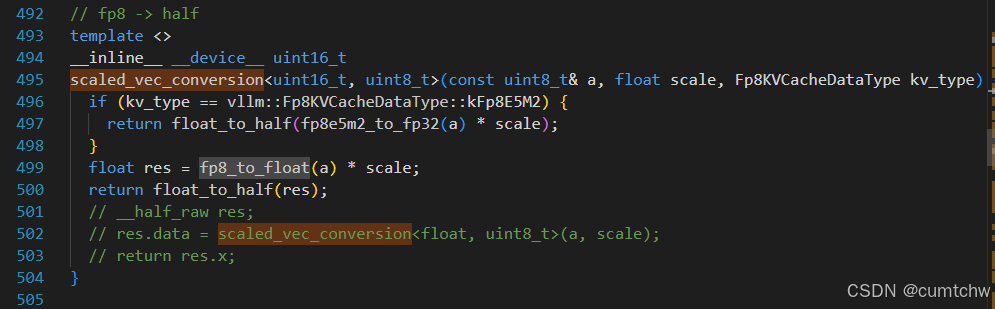
4.8 最底层:E5M2 字节 → float 也是这次新增加的函数
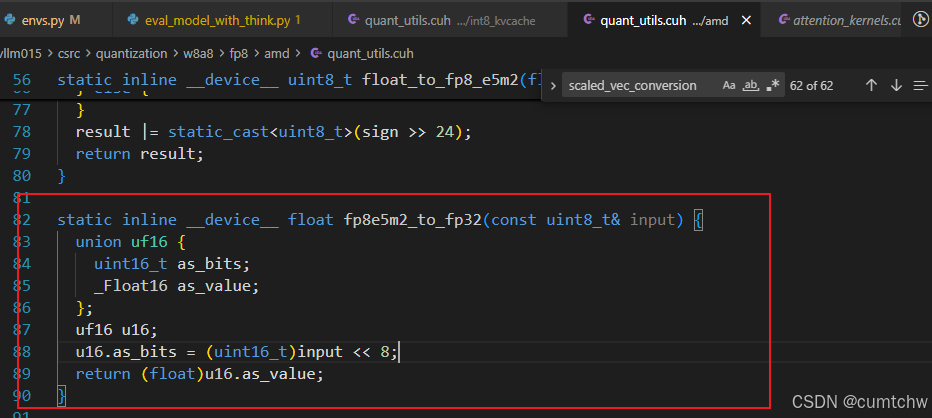
cpp
static inline __device__ float fp8e5m2_to_fp32(const uint8_t& input) {
union uf16 {
uint16_t as_bits;
_Float16 as_value;
};
uf16 u16;
u16.as_bits = (uint16_t)input << 8;
return (float)u16.as_value;
}参考文献:
VLLM开源代码