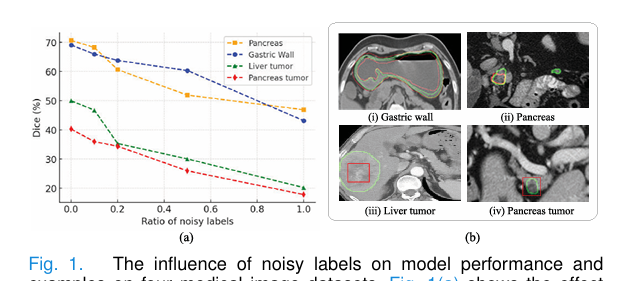
本文面向CT医学图像分割中的噪声标签学习 问题。3D医学分割依赖大量体素级精标注,但专家标注成本高;MedSAM等基础模型虽可利用点、框、涂鸦等稀疏提示降低成本,但在胃壁、胰腺/肝脏肿瘤等边界模糊、低对比区域上仍容易失效。论文在图1中展示:噪声标签比例增加会明显降低分割性能,且粗标注、形态学膨胀/腐蚀、内外包围框都会引入边界偏差。
已有噪声标签方法多依赖标签修正或标签选择。前者可能因错误修正造成误差累积,后者常只在样本级或体素级单一层面筛选,难以同时利用不同质量标签。作者的核心动机是:边界区域更容易体现噪声与不确定性,因此应先在样本级区分低质量数据可信度,再在体素级筛选可靠监督,实现从全局到局部的可靠标签传播。
我整理了文中提出的区域不确定性估计(RUE)+ 样本分层训练(SST) 的关键公式解读与伪代码实现指南,帮助你快速复现"从边界引导不确定性到样本筛选"的完整流程。感兴趣的自取,希望能帮到你!

另外,我整理了一份可直接引用的论文笔记:**边界引导不确定性估计+样本分层训练,附核心公式、对比表格与局限性分析。**感兴趣的dd,希望能帮到你!
二、核心方法
-
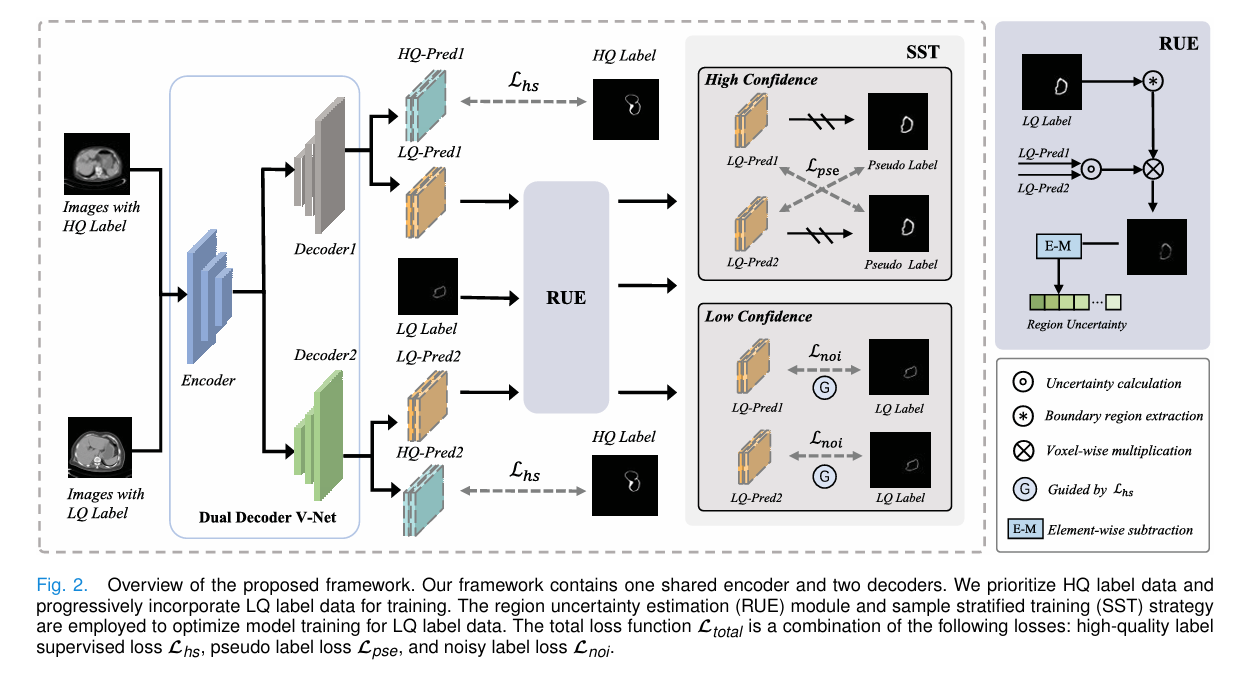
整体思路:在双解码器网络中,利用边界引导的不确定性估计对低质量样本分层训练,并在体素级筛选伪标签与噪声标签中的可靠部分。
-
区域不确定性估计 RUE:双解码器输出类别概率,计算体素级模型不确定性:
U ( x , y , z ) ≈ 1 2 C ∑ j = 1 2 ∑ c = 1 C P c , j ( x , y , z ) 2 − 1 2 C ∑ j = 1 2 ∑ c = 1 C P c , j ( x , y , z ) 2 U^{(x,y,z)} \approx \frac{1}{2C}\sum_{j=1}^{2}\sum_{c=1}^{C}P_{c,j}\^{(x,y,z)}^2-\left\\frac{1}{2C}\\sum_{j=1}\^{2}\\sum_{c=1}\^{C}P_{c,j}\^{(x,y,z)}\\right^2 U(x,y,z)≈2C1j=1∑2c=1∑CPc,j(x,y,z)2−2C1j=1∑2c=1∑CPc,j(x,y,z)2
其中, j j j为解码器索引, c c c为类别, C C C为类别数。论文通过不同初始化、上采样方式和dropout率增强两个解码器差异。
- 边界区域提取:
M ( Y n ( x ) ) = F ( m 1 ) { max e ∈ E S ( x + e ) } − F ( m 2 ) { min e ∈ E S ( x + e ) } M(Y^{n(x)})=F^{(m_1)}\left\{\max_{e\in E}S(x+e)\right\}-F^{(m_2)}\left\{\min_{e\in E}S(x+e)\right\} M(Yn(x))=F(m1){e∈EmaxS(x+e)}−F(m2){e∈EminS(x+e)}
- 样本置信度评分:
Ψ = ∑ x , y , z U ( x , y , z ) ⊙ M ( Y n ( x , y , z ) ) ∑ x , y , z 1 U ( x , y , z ) ⊙ M ( Y n ( x , y , z ) ) \> 0 \Psi=\frac{\sum_{x,y,z}U^{(x,y,z)}\odot M(Y^{n(x,y,z)})}{\sum_{x,y,z}\mathbf{1}U\^{(x,y,z)}\\odot M(Y\^{n(x,y,z)})\>0} Ψ=∑x,y,z1U(x,y,z)⊙M(Yn(x,y,z))\>0∑x,y,zU(x,y,z)⊙M(Yn(x,y,z))
- 样本分层训练 SST :按 Ψ \Psi Ψ排序,选前 k k k个高置信低质量样本做伪标签学习,其余继续用原噪声标签训练:
S o r t Ψ i ( X i n ) → X ( 1 ) , . . . , X ( k ) , X ( k + 1 ) , . . . , X ( B n ) Sort_{\Psi_i}(X_i^n)\rightarrowX\^{(1)},...,X\^{(k)},X\^{(k+1)},...,X\^{(B_n)} SortΨi(Xin)→X(1),...,X(k),X(k+1),...,X(Bn)
- 语义一致性与多样性保证 :
- 高置信样本用交叉伪监督,避免单解码器自我确认;
- 体素不确定性熵筛掉不可靠伪标签:
H j ( x , y , z ) = − 1 C ∑ c = 1 C P c , j ( x , y , z ) log P c , j ( x , y , z ) H_j^{(x,y,z)}=-\frac{1}{C}\sum_{c=1}^{C}P_{c,j}^{(x,y,z)}\log P_{c,j}^{(x,y,z)} Hj(x,y,z)=−C1c=1∑CPc,j(x,y,z)logPc,j(x,y,z)
- 总损失:
L t o t a l = L h s + λ ( t ) ( L p s e + L n o i ) L_{total}=L_{hs}+\lambda(t)(L_{pse}+L_{noi}) Ltotal=Lhs+λ(t)(Lpse+Lnoi)
λ ( t ) = α e − β ( 1 − t t m a x ) 2 \lambda(t)=\alpha e^{-\beta(1-\frac{t}{t_{max}})^2} λ(t)=αe−β(1−tmaxt)2
三、实验验证与效果
- 数据集与任务:在Pancreas-NIH、GWS、MSD、LiMT四个CT数据集上验证,噪声包括人工粗标、形态学膨胀/腐蚀、内外框标注;默认使用10%高质量标签和90%低质量标签。
- 主结果:表I显示,本文方法在DSC、Jaccard、95HD、ASD上整体优于TriNet、ADELE、MedSAM、MTCL、MixSegNet等方法。
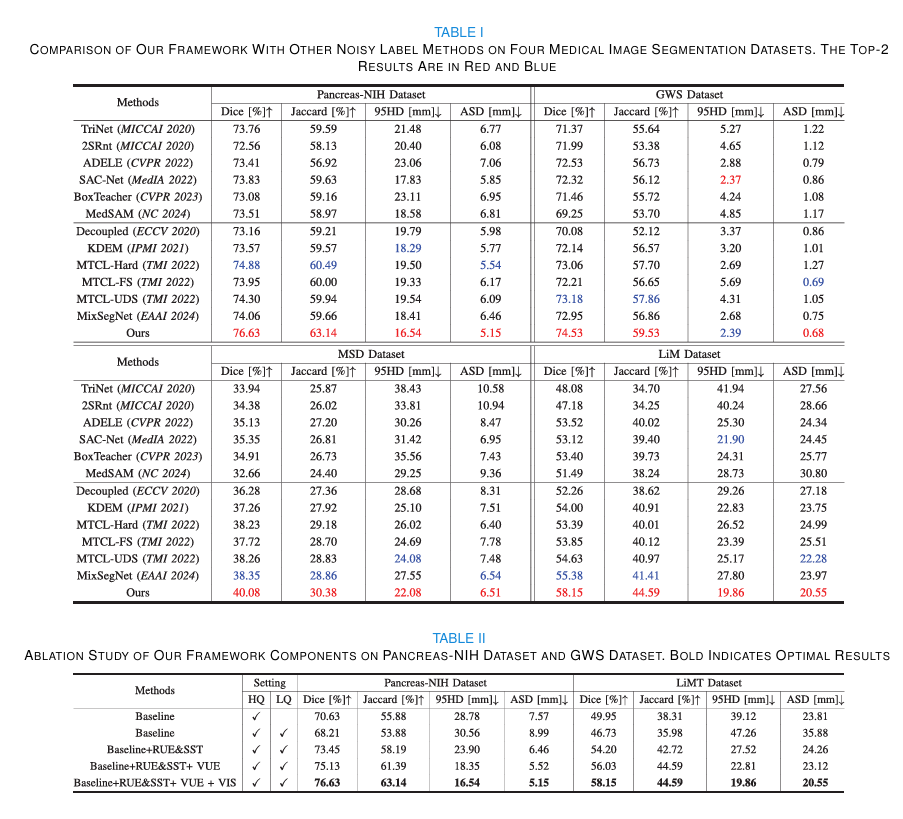
- 深入分析 :消融实验表明,RUE&SST带来主要性能提升,VUE和VIS进一步优化结果;区域提取优于无边界区域建模。超参数分析显示, k k k过大或过小都会影响训练, γ \gamma γ采用动态高斯ramp-up更有效。
- 推广价值:方法可无缝集成到双解码器架构中,论文认为未来可扩展到MRI、PET等模态。
四、小编总结
这篇论文的重点不是简单"修正"噪声标签,而是先判断哪些低质量样本更可信,再在体素层面挑出更可靠的监督信号。它特别关注医学图像中最容易出错的边界区域,用区域不确定性服务样本分层训练。实验覆盖多个CT任务,结果说明该框架能在标注不完美时提升分割稳定性和精度。