1.作者介绍
郭焱琳 女 西安工程大学电子信息学院,2025级研究生
研究方向:模式识别与人工智能
电子邮件:250412112@stu.xpu.edu.cn
胥乾信,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:2692797728@qq.com
一、XGBoost算法简介
1.1 什么是XGBoost?
XGBoost 全称 eXtreme Gradient Boosting(极端梯度提升),是 GBDT(梯度提升决策树)的高效工程实现。由陈天奇于 2014 年提出,因其优异的性能和速度,在 Kaggle 数据竞赛中几乎成为标配算法。
1.2 核心原理(三步理解)
1.加法模型(Additive Training):不断地添加决策树,每棵新树去拟合当前模型预测值与真实值之间的残差(也就是先前模型还没学好的那部分误差)。
2.叶子节点打分:训练完成后得到多棵树。预测一个样本时,根据该样本的特征,它会落到每棵树的某个叶子节点上,每个叶子节点对应一个分数。
3.分数求和输出:将该样本在所有树上对应的叶子节点分数加起来,就是最终的预测值。
二、鸢尾花数据集介绍
2.1 数据集概览
Iris(鸢尾花)数据集是机器学习领域最经典的入门数据集之一,由统计学家 Ronald Fisher 于 1936 年收集。
2.2 为什么做这个任务?
这是一个经典的回归预测任务。我们只用花萼长、花萼宽、花瓣宽三个特征去预测花瓣长度。选择这个任务的好处是:
•数据量小(150条),代码可以秒级运行,适合入门学习。
•特征和目标之间存在明显的线性/非线性关系,既能验证模型能力,又方便可视化分析。
•作为 sklearn 内置数据集,无需额外下载,开箱即用。
三、完整代码实现
3.1 环境准备与库导入
需要安装的 Python 包:
pip install xgboost scikit-learn matplotlib numpy
导入所需库并设置中文字体:
python
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
# 设置中文字体(Windows 用 SimHei,macOS 用 Heiti SC)
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False3.2 数据加载与划分
python
iris = load_iris()
# 输入特征:去掉花瓣长度(第3列,索引为2)
X = np.delete(iris.data, 2, axis=1)
# 回归目标:花瓣长度
y = iris.data[:, 2]
feature_names = ['花萼长度', '花萼宽度', '花瓣宽度']
# 划分训练集和测试集(80%训练,20%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"训练集大小: {X_train.shape[0]}")
print(f"测试集大小: {X_test.shape[0]}")3.3 创建并训练基础 XGBoost 模型
python
model = xgb.XGBRegressor(
n_estimators=100, # 树的数量
max_depth=4, # 树的最大深度
learning_rate=0.1, # 学习率
subsample=0.8, # 样本采样比例
colsample_bytree=0.8, # 特征采样比例
reg_alpha=0.1, # L1正则化
reg_lambda=1.0, # L2正则化
random_state=42 # 随机种子
)
model.fit(X_train, y_train)
print("模型训练完成!")3.4 模型评估
python
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"MSE (均方误差): {mse:.4f}")
print(f"RMSE (均方根误差): {rmse:.4f}")
print(f"MAE (平均绝对误差): {mae:.4f}")
print(f"R2 (决定系数): {r2:.4f}")四个关键评估指标的含义:
•MSE(均方误差):预测值与真实值差值的平方平均,越小越好。对大误差特别敏感。
•RMSE(均方根误差):MSE 开根号,量纲与目标变量一致(单位:cm),比 MSE 更直观。
•MAE(平均绝对误差):只看绝对误差的平均大小,不管正负。比 RMSE 更抗异常值干扰。
R²(决定系数):取值范围 (-∞, 1]。0.97 意味着模型能解释 97% 的花瓣长度变化,只剩 3% 无法解释。越接近 1 越好。
3.5 超参数优化 --- GridSearchCV
基础模型的参数是凭经验设定的。为了找到最优参数组合,我们使用网格搜索配合 5 折交叉验证:
python
print("开始超参数搜索(可能需要1-2分钟)...")
param_grid = {
'max_depth': [3, 4, 5],
'learning_rate': [0.05, 0.1, 0.2],
'n_estimators': [50, 100, 200],
}
grid = GridSearchCV(
estimator=xgb.XGBRegressor(random_state=42),
param_grid=param_grid,
cv=5, # 5折交叉验证
scoring='r2', # 用R2评价
n_jobs=-1 # 用所有CPU核心加速
)
grid.fit(X_train, y_train)
print(f"最优参数: {grid.best_params_}")
print(f"交叉验证最优R2: {grid.best_score_:.4f}")
best = grid.best_estimator_
y_pred_best = best.predict(X_test)
print(f"测试集R2: {r2_score(y_test, y_pred_best):.4f}")搜索策略说明:
•参数组合:max_depth(3种)× learning_rate(3种)× n_estimators(3种)= 27 种组合。
•5 折交叉验证:每种组合在训练集上做 27 × 5 = 135 次训练评估。
•n_jobs=-1:调用全部 CPU 核心并行训练,将搜索时间从十余分钟缩短到 1~2 分钟。
•scoring='r2':以 R² 作为交叉验证的评价标准,选择 R² 最高的参数组合。
3.6 可视化代码
生成四合一图表(特征重要性、预测散点图、残差分布、误差分析):
python
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
# ---- 图1:特征重要性 ----
ax1 = axes[0, 0]
imp = best.feature_importances_
idx = np.argsort(imp)[::-1]
ax1.barh([feature_names[i] for i in idx], imp[idx],
color=['#ff6b6b', '#4ecdc4', '#45b7d1'])
ax1.set_title('特征重要性', fontsize=14, fontweight='bold')
# ---- 图2:预测值 vs 真实值 ----
ax2 = axes[0, 1]
ax2.scatter(y_test, y_pred_best, alpha=0.7, color='#4ecdc4',
s=80, edgecolors='white')
lo = min(y_test.min(), y_pred_best.min()) - 0.3
hi = max(y_test.max(), y_pred_best.max()) + 0.3
ax2.plot([lo, hi], [lo, hi], "r--", lw=2)
ax2.set_xlabel('真实值 (cm)', fontsize=12)
ax2.set_ylabel('预测值 (cm)', fontsize=12)
ax2.set_title(f'预测 vs 真实 (R2={r2_score(y_test, y_pred_best):.4f})',
fontsize=14, fontweight='bold')
# ---- 图3:残差分布 ----
ax3 = axes[1, 0]
res = y_test - y_pred_best
ax3.hist(res, bins=10, color='#45b7d1', edgecolor='white')
ax3.axvline(0, color="red", ls="--")
ax3.set_xlabel('残差 (真实值 - 预测值)', fontsize=12)
ax3.set_ylabel('频数', fontsize=12)
ax3.set_title('残差分布', fontsize=14, fontweight='bold')
# ---- 图4:各样本预测误差 ----
ax4 = axes[1, 1]
colors = ['#ff6b6b' if abs(e) > 0.3 else '#4ecdc4' for e in res]
ax4.bar(range(len(y_test)), res, color=colors)
ax4.axhline(0, color="black", lw=0.5)
ax4.set_xlabel('测试集样本序号', fontsize=12)
ax4.set_ylabel('预测误差 (cm)', fontsize=12)
ax4.set_title('各样本预测误差(红色>0.3cm)', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('xgboost_results.png', dpi=150)
print("图表已保存为 xgboost_results.png")
plt.show()四、模型评估与可视化分析
4.1 基础模型 vs 优化后模型
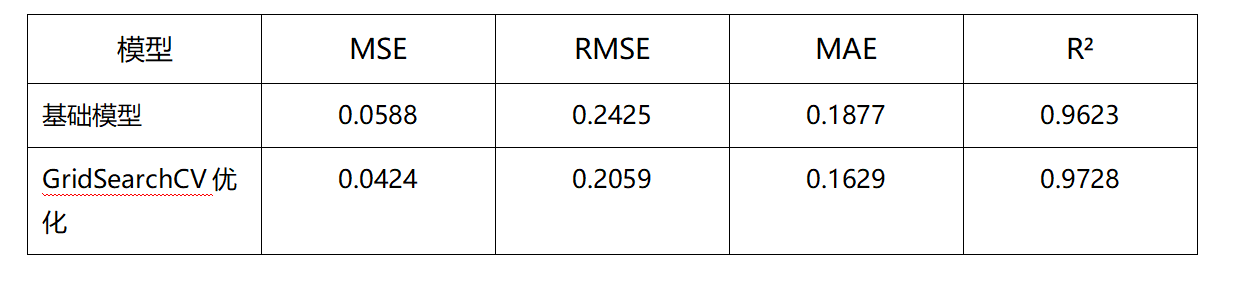
优化后 R² 从 0.9623 提升到 0.9728,各项误差指标均有下降,说明网格搜索找到了更适合的参数组合。
4.2 特征重要性分析
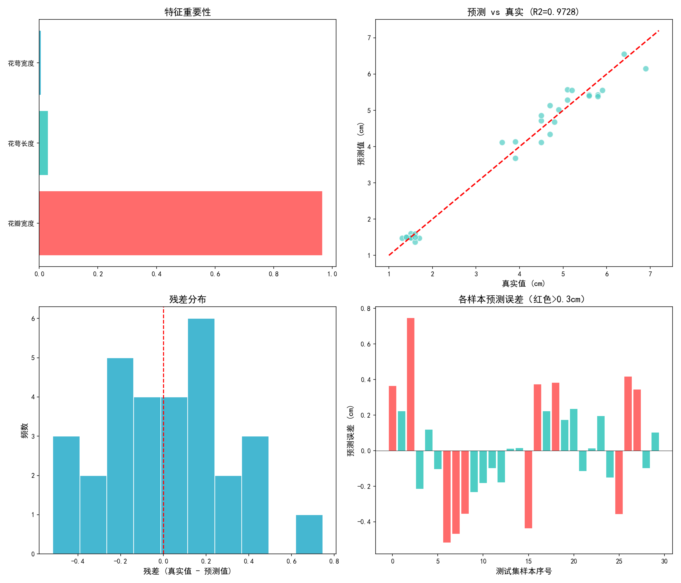
XGBoost 训练后直接输出特征重要性分数(基于该特征在树分裂中被使用的总增益):
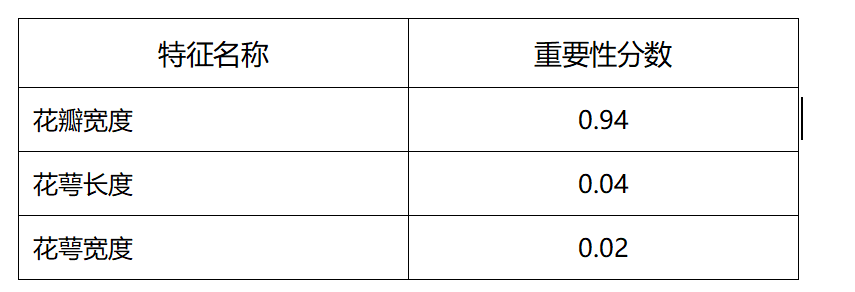
结论:花瓣宽度是预测花瓣长度的核心特征,重要性高达 94%。这与我们的直觉完全一致------花瓣的宽和长天然高度相关,而花萼的尺寸对花瓣长度的预测贡献非常有限。
4.3 预测效果可视化
解释四张可视化的含义:
•特征重要性(左上):水平条形图展示各特征的重要性分数,花瓣宽度占绝对主导地位。
•预测 vs 真实散点图(右上):红色虚线为理想预测线(预测=真实),青色点越靠近红线说明预测越准确。图中的点几乎紧贴红线,R²=0.9728,拟合效果很好。
•残差分布直方图(左下):残差范围约 -0.5 ~ +0.8 cm,以 0 为中心呈近似正态分布,绝大部分样本残差在 ±0.4 cm 以内,说明模型无系统性偏差。
•各样本预测误差(右下):30 个测试样本中有 11 个红色标记的大误差样本(误差 > 0.3 cm),可重点关注这些样本的特征是否有异常值。