面试技巧:回答要条理清晰,用术语但要解释清楚,避免过于深入实现细节。
1、数据库的隔离级别
概念
- 隔离级别是用于控制多个事务同时执行时,它们之间的相互影响程度。
- 核心 - 是为了平衡数据一致 性和并发性能。
如果不隔离,主要会出现三种"读异常":
- 脏读:同时刻的两个事务中,事务A读取了事务B尚未提交的修改数据(磁盘值为200,内存中值为100)。如果B之后回滚了,A读到的就是无效的"脏"数据:100。
- 不可重复读:在同一个事务A内,两次读取同一条数据,得到的结果不一样。这是因为在这两次读取之间,事务B修改并提交了这条数据。
- 幻读:在同一个事务A内,两次执行同一个查询条件,得到的记录条数不一样。这是因为两次查询之间,事务B新增或删除了符合条件的数据行。
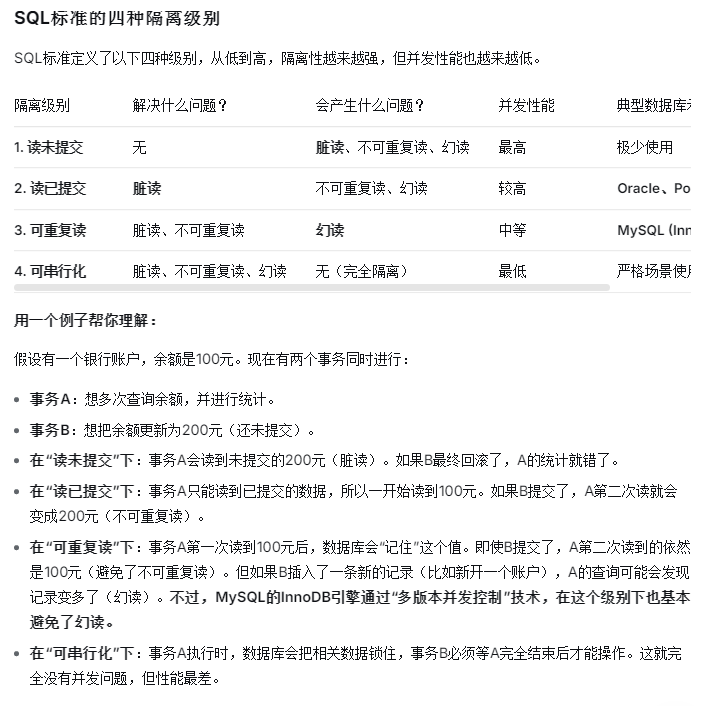
注意:脏读特指读未提交的数据。
在"可重复读"下,A第二次读到的依然是100元不算脏读,
所以事务A读到的100元,是一个已提交的历史数据(或称快照数据),而不是一个尚未确定的"脏"数据。不符合脏读的定义。如何选择隔离级别?这需要在"数据准确度"和"系统响应速度"之间做权衡:
- 读未提交:几乎不用。除非你对数据准确性完全不在意,只追求极致速度。
- 读已提交:很多在线交易系统的默认选择。保证不会读到脏数据,性能也不错,但需容忍同一事务内查询结果的变化。
- 可重复读:适合需要一致数据快照进行报表统计的场景。MySQL的默认级别表现很好,多数情况下足够安全。
- 可串行化:只在严格禁止任何并发数据冲突的场景使用(如余额绝对精确的金融核心系统),但会严重影响并发性能。