一、KNN算法简介
1. 概述
K-近邻算法(K-Nearest Neighbors,简称 KNN)是一种有监督学习算法,它既可以用于分类任务,也可以用于回归任务。通过寻找样本间的相似性进行预测的一种模型。
核心思想:物以类聚 。如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。
- 分类任务 :根据 K 个最近邻居的多数类别 来决定新样本的类别(投票法)。
- 回归任务 :根据 K 个最近邻居的平均值 来预测新样本的数值(平均法)。
2. 工作原理
那么如何确定样本的相似性呢?通常我们使用样本间的距离 来度量,样本距离越近,越相似。下面我们介绍一下KNN算法的工作原理。
-
分类问题
- 计算未知样本到每个训练样本的距离
- 将训练样本根据距离大小升序排列
- 取出距离最近的K个训练样本
- 进行多数表决,统计K个样本中哪个类别的样本个数最多
- 将未知样本归类到出现次数最多的类别
-
回归问题
- 计算未知样本到每个训练样本的距离
- 将训练样本根据距离大小升序排列
- 取出距离最近的K个训练样本
- 把K个样本的目标值计算其平均值
- 作为未知样本的预测值
二、常用的距离度量方法
1. 欧式距离(Euclidean Distance)
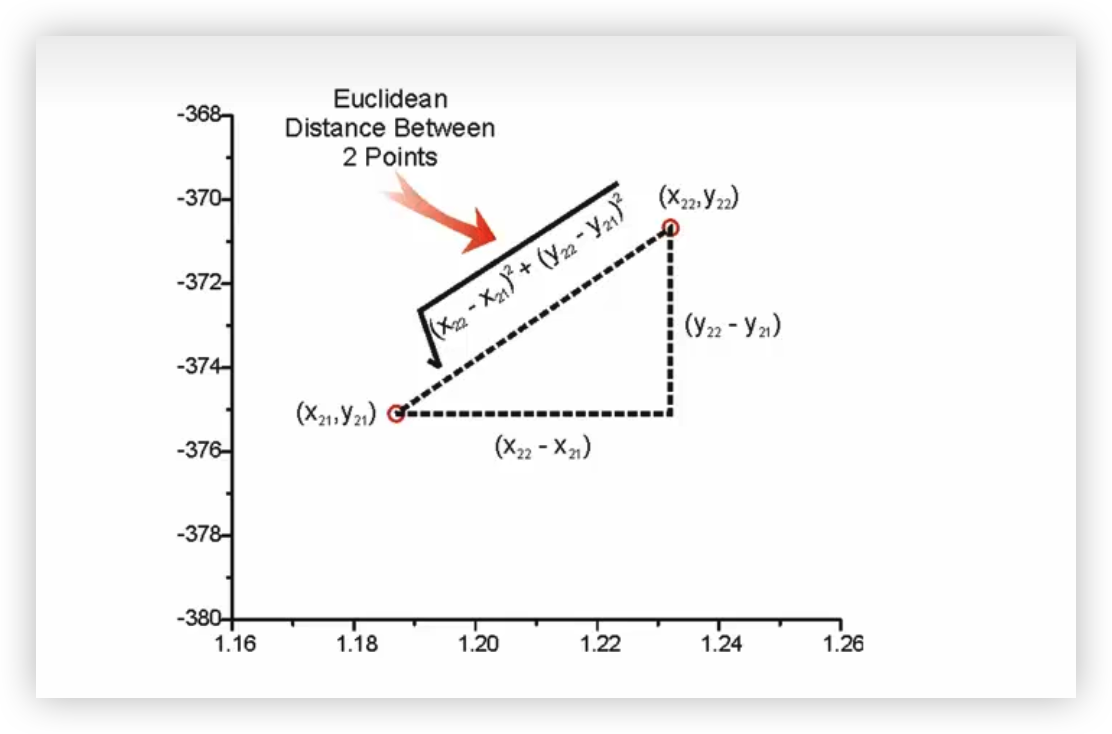
- 定义:在欧几里得空间中最常见的直线距离,各坐标轴上的差值的平方和,开平方根。
- 公式 :d(x,y)=∑i=1n(xi−yi)2d(x,y)=\sqrt{\sum_{i=1}^{n}(x_i-y_i)^2}d(x,y)=i=1∑n(xi−yi)2
- 特点:对特征尺度敏感,要求各维度量纲一致(需标准化)。适用于数据稠密、各维度重要性相近的情况。
- KNN 中最常用 :默认选择,当特征大致服从正态分布或无明显异常值时效果好。
2. 曼哈顿距离(Manhattan Distance)
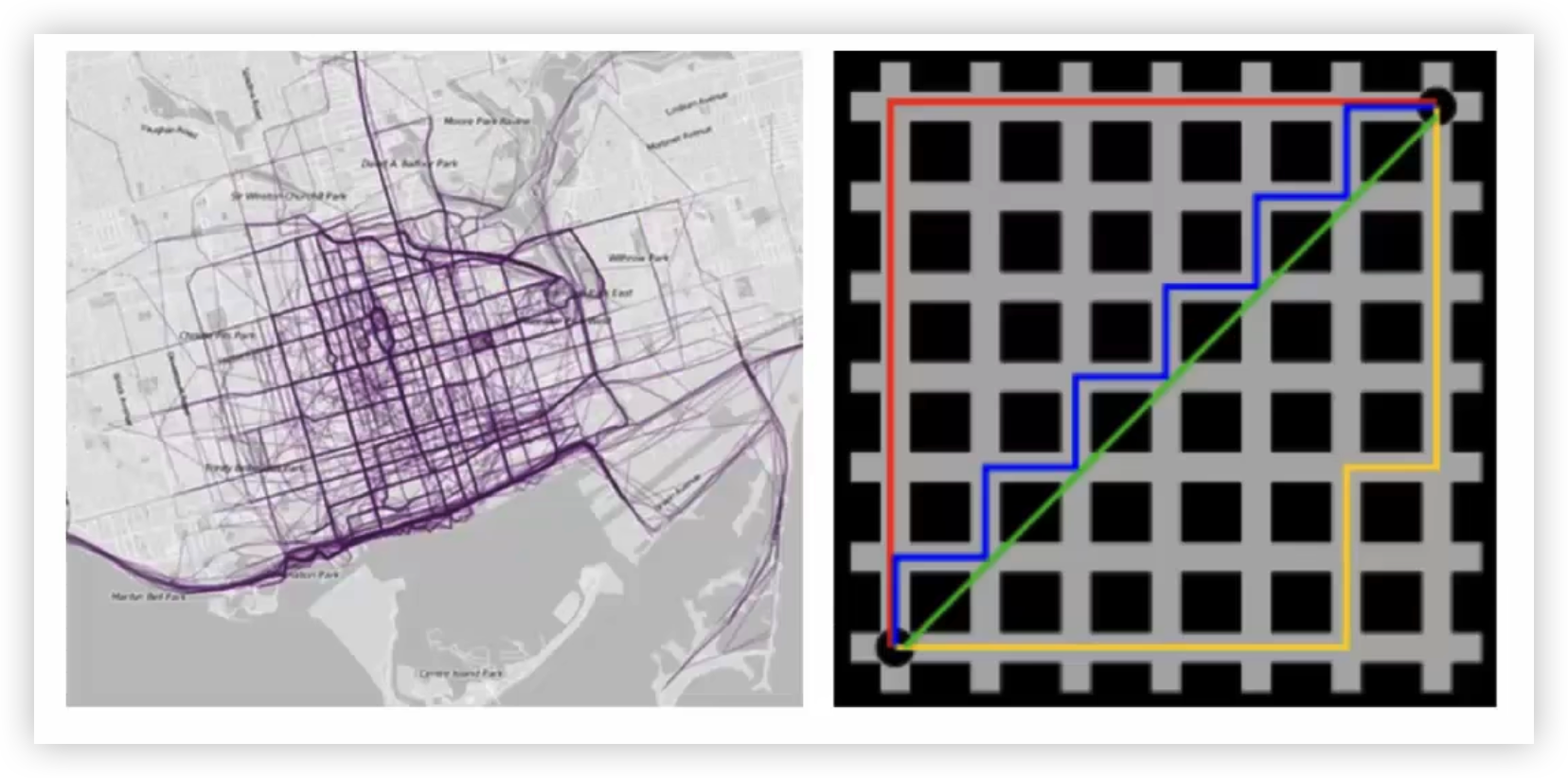
- 定义:各坐标轴上的绝对差值之和,也称为 L1 距离、城市街区距离。
- 公式 :d(x,y)=∑i=1n∣xi−yi∣d(x,y)=\sum_{i=1}^{n}|x_i-y_i|d(x,y)=i=1∑n∣xi−yi∣
- 特点 :对异常值的鲁棒性优于欧氏距离(不平方放大误差)。适用于高维稀疏数据或特征维度之间相互独立(如网格路径)。
3. 切比雪夫距离(Chebyshev Distance)
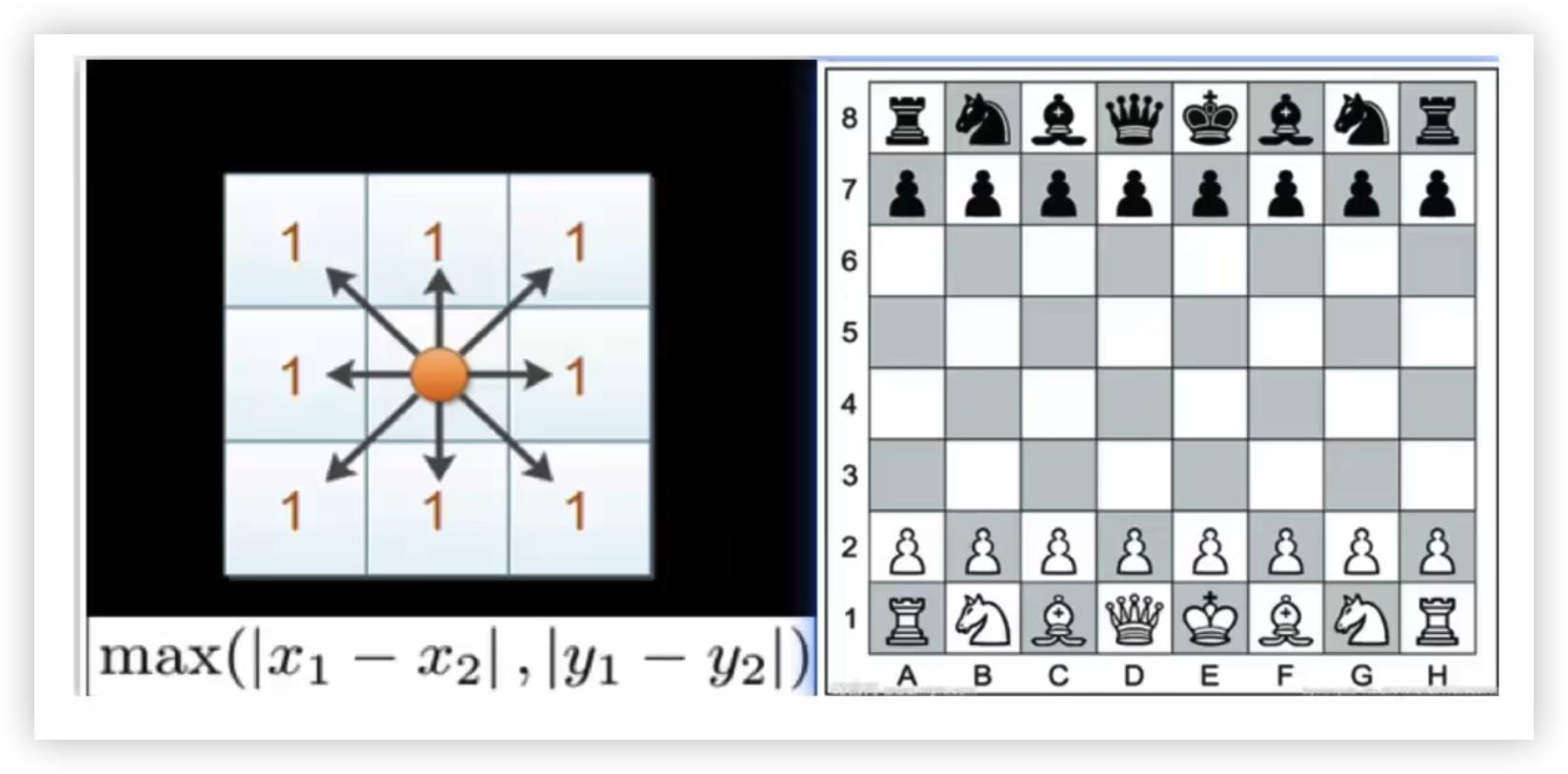
- 定义:各坐标轴上的差值的最大值,即国际象棋中王移动的步数。
- 公式 :d(x,y)=maxi∣xi−yi∣d(x,y)=\max_{i}|x_i-y_i|d(x,y)=imax∣xi−yi∣
- 特点 :适合定义"任意维度上的最大差距"为距离的场景。
4. 闵可夫斯基距离(Minkowski Distance)
- 定义 :欧氏距离、曼哈顿距离和切比雪夫距离的一般化形式,引入参数ppp。它不是一种新的距离的度量方式,而是对多个距离度量公式的概括性的表述。
- 公式 :d(x,y)=(∑i=1n∣xi−yi∣p)1pd(x,y)=\left(\sum_{i=1}^{n}|x_i-y_i|^p\right)^{\frac{1}{p}}d(x,y)=(i=1∑n∣xi−yi∣p)p1
ppp取值不同,对应不同的距离
- p=1→p=1 \rightarrowp=1→ 曼哈顿距离
- p=2→p=2 \rightarrowp=2→ 欧氏距离
- p→∞→p \to \infty \rightarrowp→∞→ 切比雪夫距离
三、特征预处理
1. 概述
特征预处理是机器学习流程中至关重要的一步,指在将数据输入模型之前,对原始数据进行一系列转换、清洗和缩放 操作,使数据更适合算法学习。它的质量直接影响模型的性能、收敛速度和泛化能力,尤其对基于距离的算法(如KNN、SVM、K-Means)和使用梯度下降的算法(如线性回归、神经网络)影响显著。
2. 为什么需要特征预处理
- 消除量纲差异:不同特征的尺度(如年龄0-100、收入0-100000)如果直接使用,会使得尺度大的特征主导距离计算或梯度更新,导致模型偏向某个特征。
- 处理缺失值与异常值:大多数模型无法处理缺失值;异常值可能扭曲统计分布或使模型学不到规律。
- 提升收敛速度:对于迭代优化算法,经过标准化/归一化的数据能使损失函数更圆润,梯度下降更快达到最优。
- 满足算法假设:某些模型假设特征服从正态分布(如线性回归中的误差项)或特征间相互独立(如朴素贝叶斯)。
- 防止数值溢出:极端大或小的数值可能导致计算中的数值不稳定。
3. 常见的特征处理方法
按目标可以分为以下几类:
3.1. 数据清洗
- 缺失值处理:删除缺失值过多的样本/特征;用均值、中位数、众数填充;或用模型预测填充(如KNN、回归)。
- 异常值处理:通过箱线图(IQR)、Z-score等方法检测,进行截尾、转换或删除。
3.2. 特征缩放
| 方法 | 公式 | 公式说明 | 输出范围 | 适用场景 |
|---|---|---|---|---|
| 标准化(Standardization, Z-score) | X′=x−meanσX' = \frac{x - \mathrm{mean}}{\sigma}X′=σx−mean | mean 为特征的平均值,σ 为特征的标准差 | 均值为0,方差为1(无固定边界) | 适合数据近似正态分布、特征存在离群点、需要保持异常值信息时(如线性回归、KNN);(最常用) |
| 归一化(Min-Max Scaling) | X′=x−minmax−minX' = \frac{x - \mathrm{min}}{\mathrm{max} - \mathrm{min}}X′=max−minx−min | min为特征的最小值,max为特征的最大值 | 0, 1 或 -1, 1 | 需要严格边界、数据分布无明显离群点时(如神经网络、图像像素值) |
3.3. 处理分类特征
- 标签编码(Label Encoding):将类别转为整数(如红→0,绿→1,蓝→2)。避免用于无序类别,否则会引入错误的大小顺序。
- 独热编码(One-Hot Encoding):为每个类别创建一个二值特征(0/1)。适合无序类别,但会增加特征维度。
- 目标编码(Target Encoding):用类别对应的目标变量均值替换,适合高基数类别特征。
3.4. 处理非线性/偏态分布
- 对数变换、Box-Cox变换、Ye-Johnson变换:将长尾分布拉向正态分布,提高线性模型表现。
3.5. 生成多项式特征 & 特征交叉
- 增加特征的非线性组合(如 x12,x1x2x_1^2, x_1x_2x12,x1x2),提升线性模型的表达能力。
4. 特征预处理的执行顺序
- 划分训练集和测试集
- 缺失值填充
- 异常值处理(可选)
- 特征缩放(用训练集的统计量拟合,然后转换训练集和测试集)
- 编码分类特征
- 特征选择/降维(如PCA,通常在缩放之后)
重要原则 :对训练集计算的所有参数(如均值、方差、最小值、最大值)必须保存,并完全相同地应用于测试集或新数据。
5. 特征缩放对KNN的特殊重要性
KNN依赖距离(如欧氏距离),特征尺度差异会直接导致大尺度特征主导邻居判断。例如,年龄范围0-100,收入范围0-100000,收入哪怕差100元也比年龄差10岁对距离贡献大。因此使用KNN前,必须进行标准化或归一化。
四、超参数选择方法
在 KNN 中,K 值的选择直接决定了模型的性能。K 太小易过拟合(对噪声敏感),K 太大则易欠拟合(决策边界过于平滑)。
1. K值的影响直观理解
| K值 | 特点 | 风险 |
|---|---|---|
| 过小(如K=1) | 仅由最近的一个样本决定分类,决策边界非常曲折,几乎完全贴合训练数据 | 过拟合:对异常点、噪声极度敏感,在测试集上表现差 |
| 过大(如K=N) | 所有样本投票或平均,决策边界极度平滑,趋向于整体多数类 | 欠拟合:无法捕捉局部模式,忽略了数据的真实结构 |
| 适中 | 既能容忍一定噪声,又能保证局部特征,决策边界较平滑但有区分能力 | 泛化能力最佳 |
2. 选择K值的常用方法
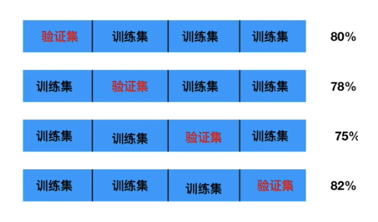
2.1. 交叉验证
将训练数据划分为 k 份(如 5 或 10 折),轮流用其中 k-1 份训练,1 份验证,计算不同 K 值下的平均验证误差(或准确率)。
- 步骤 :
- 预设一个 K 值候选列表(如 1, 3, 5, 7, ..., 30)。
- 对每个候选 K 值,执行 k 折交叉验证,得到平均性能指标(如分类准确率、F1 分数或回归的 MSE)。
- 选择性能最优的 K 值。若多个 K 值相近,则倾向于取较大的 K(模型更简单、更稳健)。
- 为了降低方差,可重复多次交叉验证取平均。
- 优点 :充分利用数据,能有效防止过拟合,找到泛化能力最好的 K。
2.2. 网格搜索
网格搜索(Grid Search)是一种系统性的超参数调优方法。它通过穷举给定的候选参数组合,分别评估每种组合的性能,从而选出最优的一组超参数。在机器学习中,超参数(如KNN中的K值、距离度量)无法从数据中直接学习,需要人工设定,而网格搜索提供了自动化的最优选择方案。
核心思想:穷举 + 评估
- 定义参数网格 :为每个超参数指定一组候选值。例如:
- K = 3, 5, 7, 9
- 距离度量 = 'euclidean', 'manhattan', 'cosine'
- 组合所有可能性:生成所有参数组合的笛卡尔积。上例共 4 × 3 = 12 种组合。
- 交叉验证评估:对每一种组合,通常采用k折交叉验证(如5折)计算平均性能(准确率、F1等)。
- 选择最优组合:比较所有组合的交叉验证得分,选出得分最高的一组超参数。
- 使用最优参数在全训练集上重新训练(可选),最后在测试集上评估。
网格搜索的优缺点
| 优点 | 缺点 |
|---|---|
| 简单直观:理解容易,Sklearn提供实现标准 | 计算开销大:组合数随参数数量和候选值指数增长(维度灾难) |
| 保证找到网格内全局最优:只要网格覆盖足够细,就能获取到最优组合 | 浪费计算资源:评估了所有组合,但许多组合性能可能相近或无效 |
| 易于并行化:各组合评估相互独立,可多核/分布式运行 | 网格粒度难以确定:网格太粗可能错过最优,太细则计算爆炸 |
| 可解释性好:能直观对比不同参数组合的效果 | 不适合连续型超参数(如学习率),需先离散化为候选值 |
与交叉验证的强绑定
网格搜索几乎总是与交叉验证联合使用,称为 GridSearchCV。交叉验证的作用是:
- 提供对泛化性能的稳健估计,避免选择只对特定验证集过拟合的参数。
- 充分利用有限数据(不单独留出验证集)。
常用折叠数:5折或10折。对于小数据集,可增加折数;对于大数据集,可减少折数以节省时间。