针对传统人脸库全量构建存在的耗时冗长及维护困难等瓶颈,本文设计并实现了一种基于 SQLite 与 face_recognition 的管理架构。该方案支持特征数据的增量更新与删除同步机制,有效提升了系统的响应速度与数据管理的灵活性。
其中,人脸识别我们使用face_recognition库,其作为基于dlib的Python封装,以其简洁的API设计和卓越的识别精度(基于ResNet-34模型)成为开发者首选。
人脸识别代码
python
@app.route('/recognize', methods=['POST'])
def api_recognize():
if not gallery_built:
return jsonify({"error": "人脸库未加载"}), 500
if 'image' not in request.files:
return jsonify({"error": "缺少 image 文件"}), 400
file = request.files['image']
try:
in_memory = file.read()
nparr = np.frombuffer(in_memory, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
except Exception as e:
return jsonify({"error": f"图像处理异常: {str(e)}"}), 400
face_locations = face_recognition.face_locations(rgb_img)
if not face_locations:
return jsonify({"results": [], "message": "未检测到任何人脸"})
face_encodings = face_recognition.face_encodings(rgb_img, face_locations)
results = []
THRESHOLD = 0.6
for encoding in face_encodings:
distances = face_recognition.face_distance(known_encodings, encoding)
best_match_index = np.argmin(distances)
min_distance = distances[best_match_index]
if min_distance < THRESHOLD:
name = name_list[best_match_index]
confidence = float(1.0 - min_distance)
else:
name = "Unknown"
confidence = 0.0
results.append({"name": name, "confidence": round(confidence, 4)})
return jsonify({"results": results, "total_faces": len(results)})人脸库增量构建
系统在录入前会首先检索 SQLite 数据库进行身份去重校验。若检测到身份证号已存在则自动跳过;否则,将调用 face_recognition 算法提取人脸特征向量,并将该特征数据序列化后追加至 NPY 特征库中。
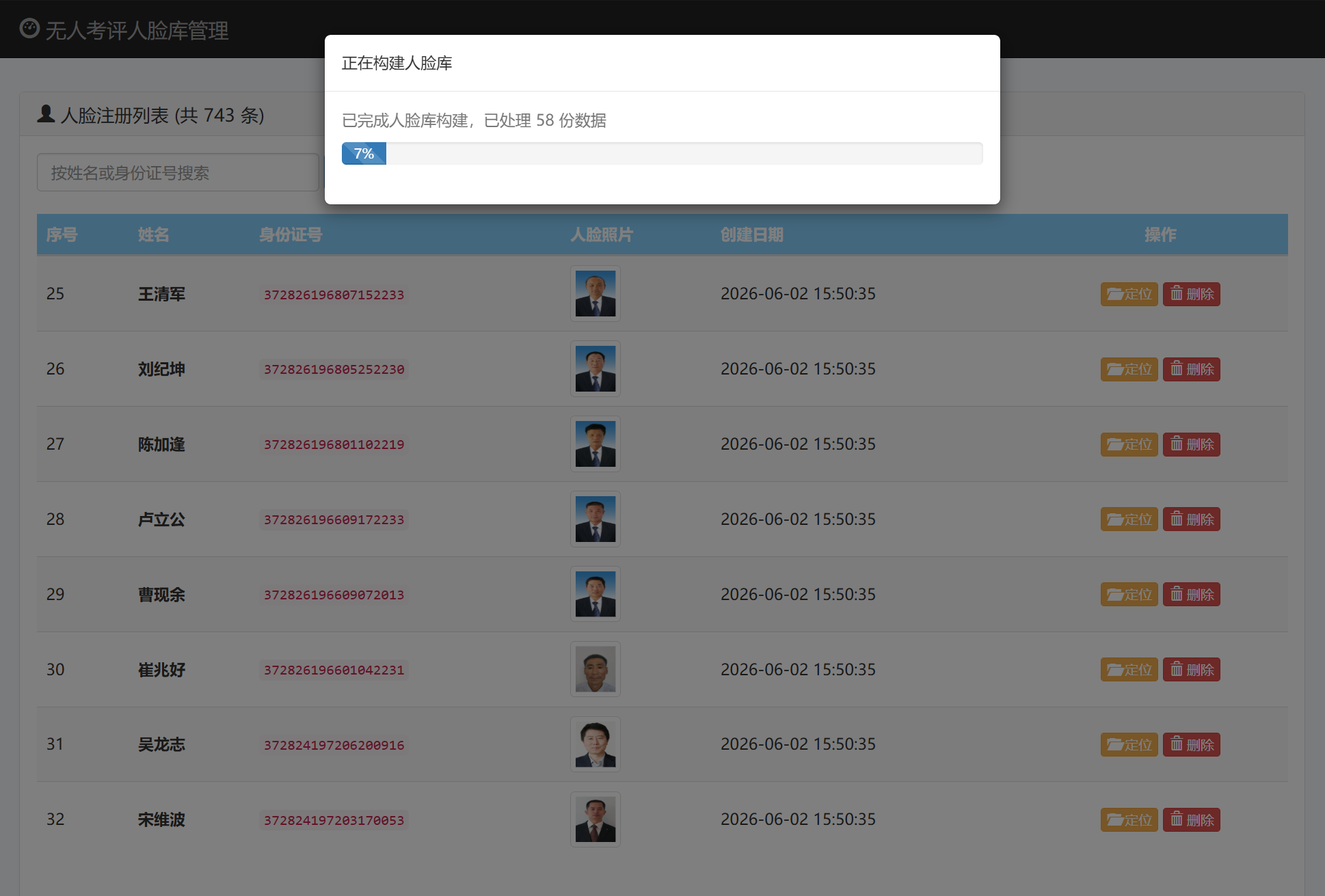
人脸库文件定位
通过文件定位功能可以直接定位到图像文件夹,便于问题定位与修改。
人脸库删除
针对冗余人员的清理,系统采用了"批量标记+统一触发"的异步处理机制。用户可连续执行多条删除指令而不立即重构;待所有目标人员确认移除后,手动点击"清除并重建"按钮,系统将集中执行一次底层人脸库的重构与同步。