初学者建议先看redis导论[https://blog.csdn.net/m0_58718491/article/details/161198350?spm=1001.2014.3001.5502](https://blog.csdn.net/m0_58718491/article/details/161198350?spm=1001.2014.3001.5502 "https://blog.csdn.net/m0_58718491/article/details/161198350?spm=1001.2014.3001.5502")提及的分布式系统演进的变化背景,再看本篇
一、redies简介
要点
键值对:Redis(Remote Dictionary Server)提供了基于键值对(key-value)的存储系统,key是String,value是五大数据类型
性能:
快!数据都存放在内存中,所以读写性能非常出色,不涉及磁盘 I/O(持久化除外);
核心功能操作简单,操作内存不怎么消耗cpu;网络角度使用了io多路复用(epoll;
单线程减少线程竞争开销,后续引入了多线程但只是在io方面(多线程适用适合 I/O 密集型任务,一个线程发起 I/O 请求时(比如等 MySQL 返回数据),这个线程就会进入阻塞,CPU 是完全闲着的可以切换给另一个线程去执行别的任务)
IO 多路复用 :允许单个线程同时监控多个网络连接(套接字)的技术;Redis 利用了网络通信中'绝大多数 Socket 都在潜水'的客观规律**。** 它抛弃了高内耗的'一连接一线程'模式,采用了基于
epoll的 I/O 多路复用技术单线程:redis只用一个线程,处理所有的命令请求,多个线程是在处理网络IO,比如多个redies客户端申请修改数据(I/O多线程),但是在redies服务端还要排队,一个一个取处理请求(单线程)
原子:Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行
可编程:
用户可以编写一段脚本或程序,并将其发送到 Redis 服务器端执行的能力,Redis 最主要的可编程性是通过集成Lua 脚本引擎 实现;
没有可编程性前:想实现"如果余额足够则扣款"的逻辑,从 Redis 读余额--在服务器里判断--如足够写回新余额;
有了可编程性:你直接写一段 Lua 逻辑交给 Redis。Redis 内部会帮你锁定数据、判断逻辑、执行修改,一气呵成
可扩展:
开发者可以使用 C, C++, 或 Rust 等底层语言来编写扩展程序,在编译后本质上是一个动态链接库,在 Windows 上表现为
.dll文件,供 exe 程序调用;可以通过扩展让 Redis 支持全新的数据类型(如复杂的地理信息、全文搜索索引);
可以为 Redis 增加自定义命令,这些命令执行起来就像原生命令(如
SET或GET)一样高效持久化:它会利用快照和日志的形式将内存的数据持久化到硬盘上,防止数据丢失。
支持集群:Redis 作为中间件,支持集群模式;
主从集群模式:主写从读;
水平扩展:引入多个主机并部署多个 Redis 节点,让每个节点只存储数据的一部分;
基于哈希的分片:集群规模增长时,系统支持自动重新分区
高可用:
①冗余与备份
Redis 原生支持主从结构。从节点本质上就是主节点的一个完整数据备份
通过冗余或备份来消除单点故障
②自动故障转移
系统自动监控主节点状态;一旦主挂掉,会自动将一个从节点提升为新的主节点,接管服务
场景:
常用于实时性数据库(如广告搜索,存广告相关全量数据);
热点数据缓存;会话缓存(缓存session);
消息队列(网络版本的生产者消费者模型,解耦合,削峰填谷);业界也有很多知名的消息队列,如RabbitMQ, Kafka, RocketMQ
计数器、排行榜、社交网络、分布式锁等应用场景。
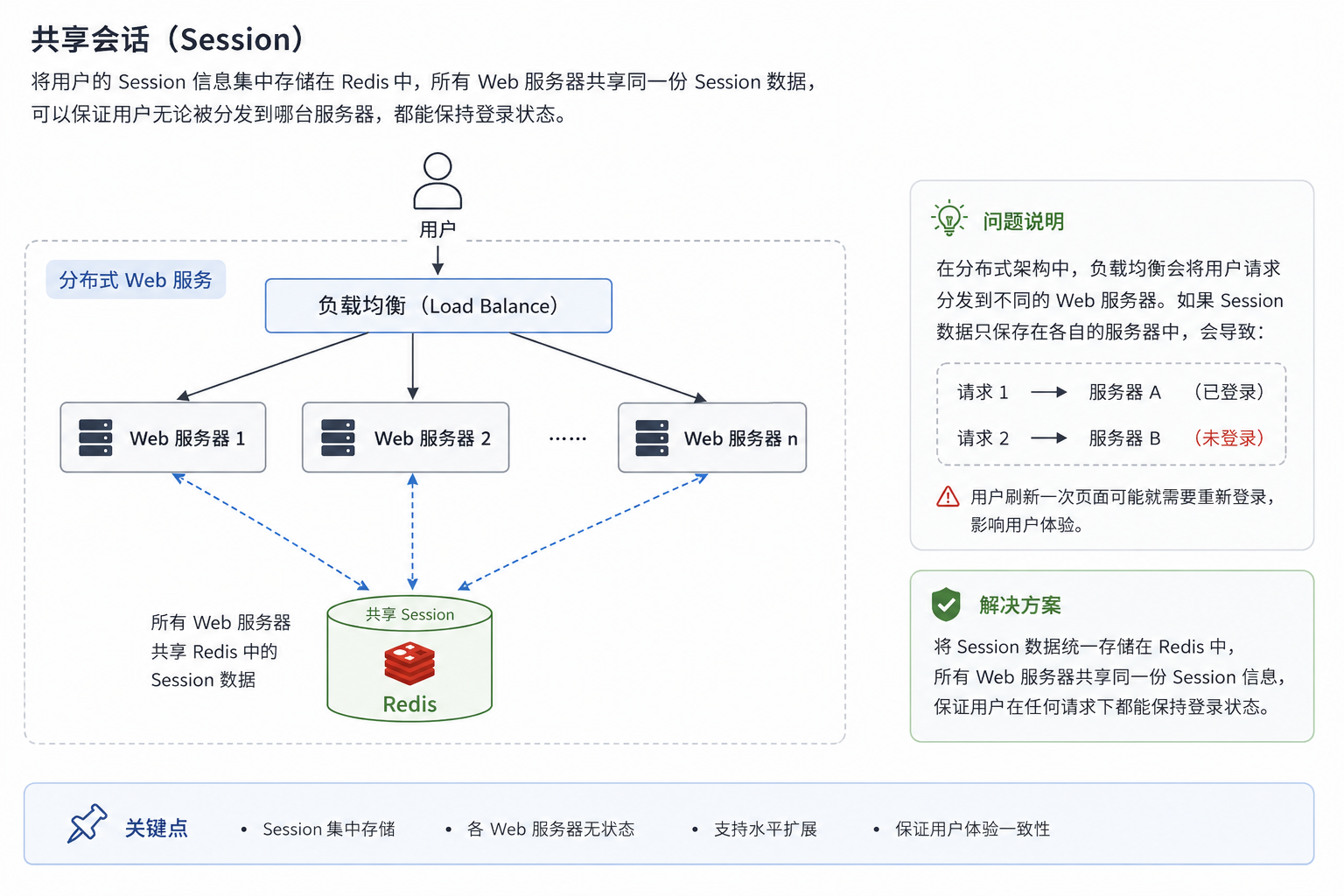
session缓存问题:早期的 Session 数据直接存储在对应的应用服务器内存;当引入负载均衡器(Load Balancer)后,用户的第一次请求可能打在 A 机器(并记录了 Session),但第二次请求可能被分发到 B 机器。由于 B 机器内存中没有该用户的 Session,会导致用户被迫重新登录
会话粘滞:让负载均衡器不再简单地进行轮询到哪个服务器上,而是通过
userId或IP进行哈希计算,确保同一个用户的请求始终打到同一台机器上分布式会话:将会话数据从应用服务器中"单独拎出来",放到一组独立的机器上存储,通常使用 Redis
redis客户端和服务器可以在同一个主机上,也可以在不同主机上;
同一时刻一个服务器可以服务多个客户端;服务器是(本体)负责存储和管理数据;
客户端可以通过cli、图形化界面、通过api自己开发客户端操作
自己使用一般只有一台机器,此时客户端和服务器就是在同一个机器
使用hash map是直接操作内存;使用redis是先通过网络!!再操作内存
二、场景举例-String的使用
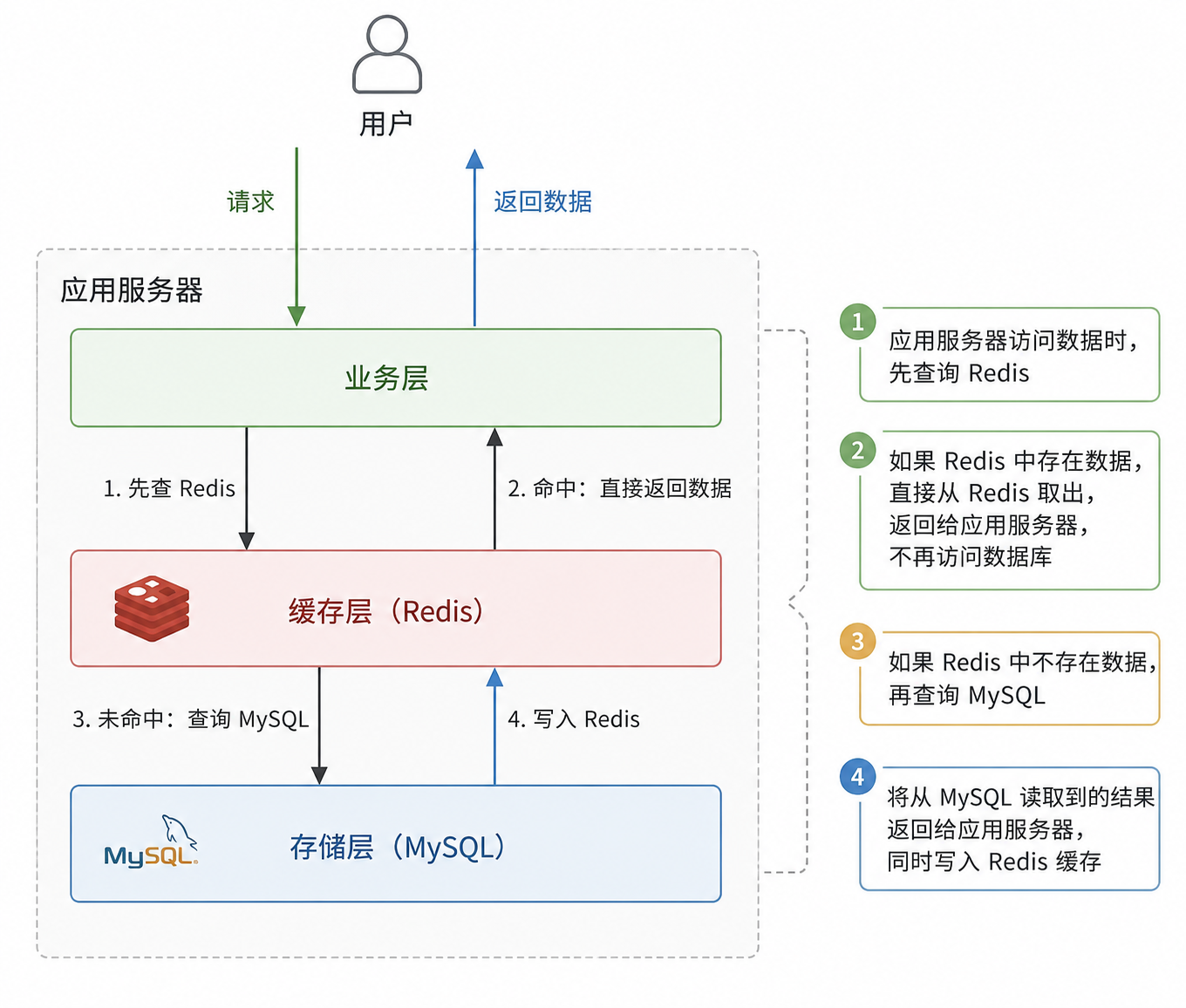
缓存(Cache)功能
比如通过用户id获取用户信息-----首先从 Redis获取用户信息,我们假设用户信息保存在"user:info:<uid>"对应的键中-----如果没有从Redis中得到用户信息,及缓存miss,则进一步从MySQL中获取对应的信息,随后写入缓存设置过期时间并返回-----通过增加缓存功能,在理想情况下,每个用户信息,一个小时期间只会有一次MySQL查询,极大地提升了查询效率,也降低了MySQL的访问数。
应用服务器访问数据的时候,先查Redis
如果Redis上数据存在了,就直接从Redis 取数据交给应用服务器,不继续访问数据库了
如果Redis上数据不存在,再读取MySQL,把读到的结果, 返回给应用服务器同时,把这个数据也写入到Redis中
Redis上数据越写越多怎么办?1)把数据写给redis的同时,给这个key 设置一个过期时间;2)内存不足时,使用淘汰策略
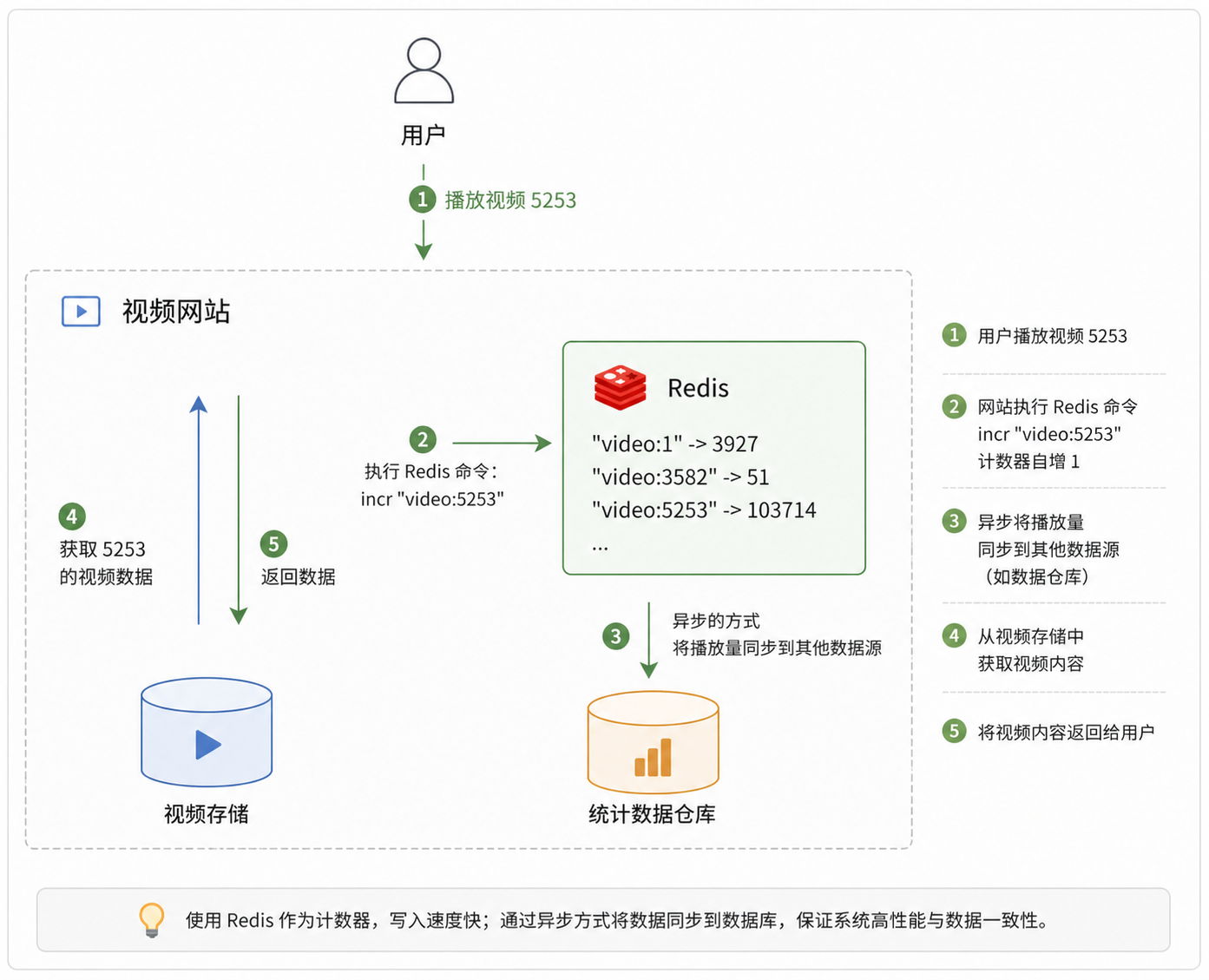
视频播放量计数
异步写入:写入统计数据仓库(可能是mysql,也可能是hdfs..)的步骤,不是说,来一个播放请求,这里就必须立即马上写一个数据;
实际中要开发一个成熟、稳定的计数系统,要面临的挑战远不止如此简单:防作弊、按照不同维度计数、避免单点问题、数据持久化到底层数据源等。
共享会话(Session)
手机验证码
由于验证码具备"高并发、高吞吐、时效性极强(通常5分钟失效)、用完即毁"的特点,如果直接塞进 MySQL 这种传统关系型数据库,不仅会把数据库的 I/O 瞬间拖垮,还会留下大量无用的历史垃圾数据。【优势:自带 TTL 自动过期机制;内存级抗高并发】
核心业务流水线
生成并发送验证码(写入 Redis)
操作 :用户点击"获取验证码",后端生成一个 6 位的随机数字(如
573921)。存储结构 :通常使用 Redis 的 String(字符串) 结构。
Key 设计 :
lock:sms:code:手机号(例如:lock:sms:code:138xxxx1234)Value :
573921关键指令 :使用
SETEX指令,在写入的同时强制设置过期时间(比如 5 分钟,即 300 秒):后端将验证码对接给第三方短信网关(如阿里云、腾讯云),发送到用户手机
用户登录验证(读取并比对 Redis)
操作 :用户收到短信,在输入框填入
573921并提交登录。校验逻辑:
后端接收到手机号和用户输入的验证码。
去 Redis 中执行
GET lock:sms:code:138xxxx1234。比对结果:
如果返回为空(
nil),说明验证码已过期或从未发送,拒绝登录。如果返回的值和用户输入的不一致,提示"验证码错误"。
如果值完全一致,则通过验证。
安全销毁 :一旦验证通过,通常会立刻执行
DEL指令把这个 Key 删掉,防止同一个验证码在有效期内被二次利用。
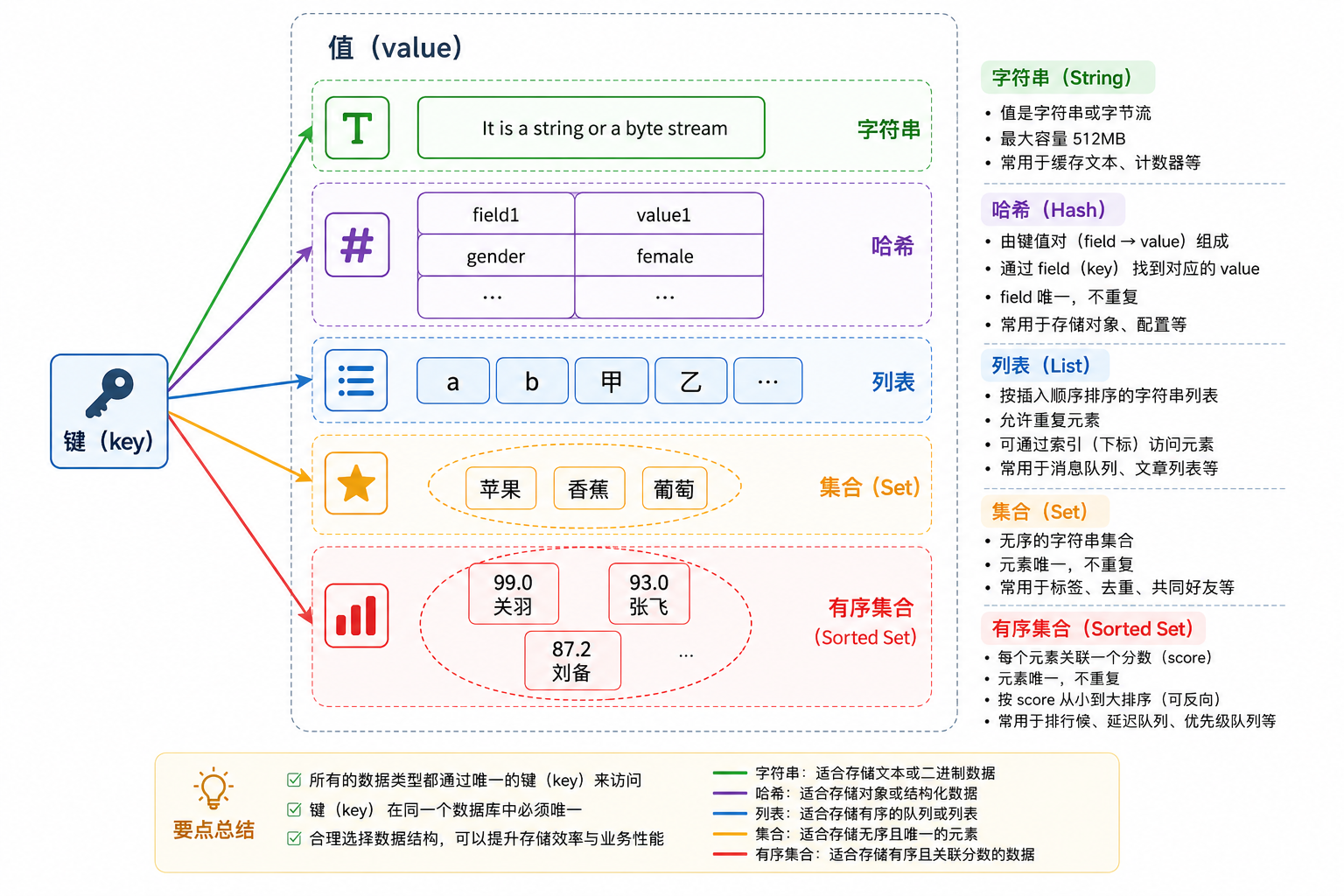
二、五大数据类型
它通常被称为数据结构服务器,因为值(value)可以是字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
redis自身的这些键值对,是通过哈希表的方式来组织的,redis具体的某个值,又可以是一些数据结构
五大数据类型及应用场景
String:验证码、计数器、分布式 Session。
Hash:存储对象信息(如用户信息、购物车)。
List:消息队列(简易版)、时间线--只能存储字符串(Strings)类型的数据。
Set:共同好友、抽奖、点赞。
ZSet:排行榜、带权重的任务队列。
Redis中的字符串,直接就是按照二进制数据的方式存储的,遇到乱码概率小(不会做任何的编码转换,存啥取啥)不仅仅可以存储文本数据,JSON、xml二进制数据(视频,音频...
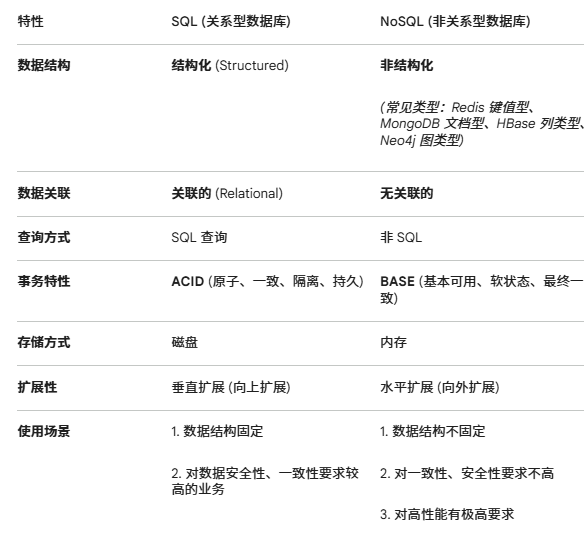
sql vs redies
其他数据类型
(特殊场景下使用)
Streams(流):一个只追加(Append-only)的日志型数据流
Geospatial(GEO/地理位置):基于ZSet 实现的地理位置数据结构。它利用 GeoHash 算法
HyperLogLog:一种用于 基数统计的概率性算法数据结构
Bitmaps(位图):底层是普通的 Strings ,但它允许你按位(Bit,即 0 和 1)进行操作
Bitfields(位域):在 Bitmaps 基础上的进一步增强,允许开发者操作任意位长度的整数
Redis存储优化
同一个数据类型,背后可能的编码实现方式是不同的,它会根据特定场景进行优化,来达到节省时间/节省空间效果
1. String(字符串)的底层优化
String 是最基础的结构,但在底层为了榨干内存,分成了三种内部编码:
int(整数编码):
优化场景 :当字符串的值是一个纯整数 (如计数器
100、2026)时。原理 :Redis 会直接将其转换为
long类型的整数来保存,不需要额外的内存分配(利用**指针的宽度刚好等于整数的宽度,**直接把数据硬塞进了指针变量的身体里),非常适合做计数、限流等高频操作。embstr(嵌入式字符串):
优化场景 :针对短字符串(小于等于 44 字节)的特殊优化。
原理 :它将 Redis 对象头(RedisObject)和实际的字符串结构体(SDS)分配在一块连续的内存空间中。由于只需要一次内存分配和释放,且对 CPU 缓存极为友好,性能极高。
raw(普通字符串):
优化场景 :当字符串长度超过 44 字节时。
原理:由于空间太大,Redis 会分别调用两次内存分配,将对象头和字符串结构体存放在不同的内存碎片中。
2. Hash(哈希)的底层优化
ziplist(压缩列表):
优化场景:当 Hash 中的元素个数较少,且每个元素的键值对长度都很短时。
原理 :它在底层是一块连续的内存空间,像数组一样紧凑排列。没有指针的额外开销,极大节省了内存空间(因为元素少,遍历查询不费时。
hashtable(字典/散列表):
优化场景:当元素数量变多或某些 field 的值太大时。
原理 :自动升级为标准链式哈希表(类似 Java 的
HashMap),确保在数据量巨大时,查找和修改的时间复杂度依然保持在 O(1)。
3. List(列表)的底层优化
linkedlist(双向链表)与 ziplist(压缩列表):
- 早期 Redis 也是小数据量用
ziplist节省内存,大数据量升级为linkedlist(双向链表)。🌟 现代优化:quicklist(快速列表):
- 在现代 Redis 版本中,List 的底层基本被统一优化为了 quicklist 。它完美结合了前两者的优点:将多个 ziplist(相当于元素) 用双向链表连接起来。既避免了纯链表频繁开辟指针带来的内存浪费,又避免纯压缩列表扩容时的内存复制成本。
4. Set(集合)的底层优化
intset(整数集合):
优化场景 :当集合中的所有元素全是整数,且数量较少时。
原理:底层是一个完全连续的、有序的整数数组。查找时采用二分查找。由于没有哈希冲突指针的开销,极度省内存。
hashtable(散列表):
优化场景 :一旦集合中出现了非整数元素 (如字符串
apple),或者元素数量超过阈值。原理 :直接转为
hashtable,其中所有的 Value 都指向NULL(类似于 Java 中HashSet底层依赖HashMap)。
5. ZSet(有序集合)的底层优化
ziplist(压缩列表):
优化场景:当有序集合的元素数量较少,且成员长度较短时。
原理 :在一块连续内存里,紧挨着存放
member和score,通过空间紧凑性来换取低内存消耗。skiplist(跳跃表):
优化场景:当数据量变大时。
原理 :升级为跳跃表 + 字典的复合结构。字典用来保证根据 member 查找 score 的复杂度为 O(1),而跳跃表,每个节点上有多个指针域,巧妙的搭配这些指针域的指向,就可以做到,从跳表上查询元素的时间复杂度是O(logN)
三、redies全局命令
操作不同的数据结构就会有不同的命令;
全局命令,就是能够搭配任意一个数据结构来使用的命令
redis是单线程的程序,主要的任务(处理每个命令的任务,扫描过期key....)
object encoding key
查看key 对应的value的实际编码方式
sqlset key1 111 --返回ok get key1 --返回"111" type key1 --string OBJECT encoding key1 --"int"set/get
对于GET只支持,字符串类型的value;如果value是其他类型,使用GET获取就会出错
sqlset key1 value1 --返回ok get key1 --返回"valuel" get key100 --(nil)--不存在keys
用来查询当前服务器上匹配的key;返回所有满足样式(pattern)的key。时间复杂O(N)
在生产环境上禁止使用keys命令,尤其是keys *时间非常长,就使redis 服务器被阻塞了,无法给其他客户端提供服务
pattern:包含特殊符号的字符串,存在的意义,是去描述字符串长啥样的
sqlset hello 1 --OK set hallo 1 --OK set heeeeeeeello --OK keys h?llo --"hello" --"hallo" keys h*llo --"hello" --"hallo" --"heeeeeeeello"exists
exists 判定key是否存在,时间复杂度O(1),redis组织这些key就是按照哈希表的方式来组织的
sqlEXISTS hello --(integer) 1 EXISTS hello hallo --(integer) 2 --分开写exists hello;exists hallo需要两次网络请求 --性能稍低,接收方收到一个数据,这个数据就要从物理层,到应用层层层分用del (delete)
删除指定的key,时间复杂度O(1)
sqldel hello hallo --(integer) 2 del aaa --(integer) 0expire
作用是给指定的 key 设置过期时间,key存活时间超出这个指定的值,就会被自动删除,时间复杂度O(1)
如手机验证码;限时优惠券;分布式锁的过期时间
EXPIRE key seconds
pexpire key 毫秒
sqlset he 111 --OK expire he 10 --(integer) 1--表示设置成功 get he --"111" get he --(nil)--十秒后ttl
获取指定key的过期时间,秒级。语法:TTL key;间复杂度O(1)
返回值剩余过期时间。-1表示没有关联过期时间,-2表示key不存在
sqlttl hello --(integer) -2--表示key不存在过期策略
一个redis中可能同时存在很多很多key,redis 服务器咋知道哪些key已经过期要被删除,哪些key还没过期?
定期删除:每次抽取一部分,进行验证过期时间,保证这个抽取检查的过程,足够快
惰性删除:访问key时就会让redis服务器触发删除key的操作,同时再返回一个nil
淘汰策略:过期的key被残留了,没有及时删除掉,使用内存淘汰策略
定时器
基于优先级队列/堆:可以通过"过期时间越早,就是优先级越高";此时只要分配一个线程,去检查队首元素,如果队首元素还没过期,后续元素一定没过期(不用检查太频繁,防止cpu忙等空转)此时做法就是可以根据当前时刻和队首元素的过期时间,设置一个等待;---需要多个独立线程专门维护定时器队列【redies不采用,因为是单线程】
基于时间轮:把时间划分成很多小段,每个小段是一个链表,每个链表表示一个要执行的任务;指针(是一个单独线程)就会每隔固定的间隔每次走到一个格子,就会把这个格子上链表的任务尝试执行一下【redies没采用】
redies采用的是上面的定期、惰性、淘汰方案
type
查看key对应值的数据类型;none表示key不存在;间复杂度O(1)
list,string,set,zset有序集合,hash哈希表,stream(redies作为消息队列时候使用的
sqltype key --none set key1 111 --OK type key1 --string lpush key2 111 222 333 --(integer) 3---lpush是头插创建一个list,sadd是创建set,hset是创建哈希表 type key2 --listFLUSHALL
清空所有数据
小结
keys:用来查看匹配规则的key
exists:用来判定指定key是否存在
del:删除指定的key
expire:给key设置过期时间.
ttl:查询key的过期时间
type:查询key对应的value的类型

五、redies数据命令
1.对于String
SET key value
SET key value expiration EX seconds \| PX milliseconds NX\|XX
过期时间参数(二选一):
EX seconds:设置键的过期时间,单位为秒。
PX milliseconds:设置键的过期时间,单位为毫秒。存在性条件参数(二选一):
NX(Not Exists):只有当 Key 不存在时才执行设置(常用于实现分布式锁)。
XX:只有当 Key 已经存在时才执行设置,用于更新值。执行
set key value ex 10它的实际效果完全等同于连续执行以下两条命令:
set key value
expire key 10MSET/MGET
一次性设置多个key的值:MSET key value key value ...
时间复杂度O(N);N是当前命令key的数量约等于O(1)
sqlmset key1 111 key2 222 key3 3333 --OK mget key1 key2 key3 --1)"111" --2)"222" --3)"3333"SETNX/SETEX/PSETEX
SETNX (Set if Not Exists):如果key不存在,则设置
value,并返回1SETEX(Set with Expiration):设置值并指定生存时间(秒),原子性操作
PSETEX(Precise Set with Expiration):设置值并指定生存时间(毫秒)
sqlsetnx key1 111 --(integer) 1 get key1 --"111" setnx key1 222 --(integer) 0 setex key2 10 222 --OK--设置key2的值为222有效期为10s psetex key3 5000 333 --OK--设置key3的值为333有效期为5000ms pttl key3 --(integer)1633--还剩1633ms pttl key3 --(integer) -2--已过期,key不存在incr/incrby/decr/decrby/incrbyfloat
【可以用于实现计数器,如统计视频播放次数,时间复杂度都是O(1),由于redis处理命令的时候,是单线程模型.多个客户端同时针对同一个key 进行incr操作,不会引起"线程安全"问题】
incr key n:针对value +1,key对应的value必须得是整数(8byte--java_long),返回+1后的值
sqlset key 10 --OK incr key --(integer) 11 get key --"11" incr key66 ----(integer) 1--key66不存在,初始值默认从0开始+1incrby key n:针对value+n,value必须得是整数,可以是负数,相当于减法
sqlincrby key 10 --(integer) 21decr key n:针对value -1
sqldecr key68 ----(integer) -1--key68不存在,初始值默认从0开始-1decrby key n:针对value -n
incrbyfloat key n:把key对应的value进行+-n运算,运算的操作数可以是浮点数
append/getrange/setrange/strlen
APPEND KEY VALUE:如果key 已经存在并且是一个string,命令会将value 追加到原有string的后边。如果key 不存在,则效果等同于SET命令;
时间复杂度:O(1);
返回值:追加完成之后string的长度,长度的单位是字节
sqlset key hello --OK APPEND key world --(integer) 10 get key --"helloworld" append key2 你好 --(integer) 6 --redis不认识字符,只认识字节 --xshell终端,默认的字符编码是utf8. --在终端输入汉字之后,也就是按utf8编码的 --一个汉字在utf8字符集中,通常是3个字节 get key2 --"\xe4\xbd\xa0\xe5\xa5\xbd"--以16进制utf8编码返回GETRANGE key start end:获取字符串的子串(java为substring),由start和end确定(左闭右闭),可以使用负数表示倒数。-1代表倒数第一个字符,超过范围的偏移量会根据string的长度调整成正确的值。
时间复杂度:O(N)
返回值:string类型的子串
若字符串中保存的是汉字,进行切分是强行切出了中间的几个字节,结果在utf8码表上不知道能查出啥了,不一定是完整的汉字,Java中String帮我们把汉字的编码转换都处理好了
sqlset key helloworld --OK getrange key 0 -1 --helloworld getrange key 1 -2 --elloworlSETRANGE key offset value:偏移量offset(表示从第几个字节,开始进行替换),返回值是 替换之后 新的字符串的长度
sqlset key helloworld --OK setrange key 5 aaaaaaaa --(integer) 10 get key --"helloaaaaaaaa" setrange key2 1 aaa --get key2 --"\x00aaa"-- --对于不存在的key2,凭空生成了一个字节, --这个字节里的内容就是0x00,aaa就被追加到0x00的后面了STRLEN key:获取到字符串的长度,单位是字节(Java中,字符串的长度则是以字符为单位的,1char=2byte,是unicode编码,2字节表示一个汉字)
MySQL的varchar(N)此处N的单位就是字符,可用存N个汉字,这样的一个字符,可能是多个字节
时间复杂度:O(1)
返回值:string的长度。或者当key不存在时,返回0
sqlset key 你好 --OK strlen key --(integer) 6--三字节一个汉字(redis是utf8--raw
CTRL+D退出Redies客户端(CTRL+S谨慎按,在xshell中的作用是"冻结当前画面",效果像卡死,CTRL+Q解除冻结
在启动redis客户端的时候,加上一个--raw这样的选项,就可以使redis客户端能够自动的把二进制数据尝试翻译
sqlredis-cli --raw get key2 --你好小结
命令 执行效果 时间复杂度 核心应用场景 set key value设置指定 key的值为valueO(1) 基础数据缓存、Token 存储 get key获取指定 key的值O(1) 获取缓存数据 del key [key ...]删除一个或多个指定的 keyO(k) (k为删除的key个数) 清理过期缓存、注销登录 mset key value [key value ...]批量设置多个 key和valueO(k) (k为设置的key个数) 批量初始化数据,减少网络往返 mget key [key ...]批量获取多个 key的值,和并多次操作减少通信成本O(k) (k为获取的key个数) 批量查询(如:同时查多个用户的基本信息) incr key将指定 key的整数值 +1O(1) 文章点赞数、视频播放量统计 decr key将指定 key的整数值 -1O(1) 保证不超卖的秒杀库存扣减(简单场景) incrby key n将指定 key的整数值 +nO(1) 游戏积分累加 decrby key n将指定 key的整数值 -nO(1) 扣除账户余额/积分 incrbyfloat key n将指定 key的浮点数值 +nO(1) 涉及小数的业务统计(如:资金变动)

2.对于Hash
Redis自身的键值对就是通过哈希的方式来组织的;把key这一层组织完成之后,到了value这一层;value的其中一种类型还可以再是哈希 field-value
结构:【key】-【value field-value 】
HSET
设置hash中指定的字段(field)的值(value)
时间复杂度:O(1)
返回值:添加的字段的个数。
sql--一次命令,设置多组,减少io开销 HSET key field value [field value ...] hset key f2 222 f3 333 f4 444 --(integer) 3HGET
获取hash中指定字段的值
sqlHGET key field hget key f1 --(nil) hget key f2 --"222" --⭐进行两次hash计算,第一次计算key名字,第二次计算f2名字HEXISTS
判断hash中是否有指定的字段
时间复杂度:O(1)
返回值:1表示存在,0表示不存在
sqlHEXISTS key f2 --(integer) 1 HEXISTS key2 f2 --(integer) 0 HEXISTS key f100 --(integer) 0HDEL
删除hash中的指定字段;del 删除的是key;hdel 删除的是field
时间复杂度:O(1)
返回值:成功删除的字段的个数。
sql--一次命令,设置多组,减少网络传输开销 HDEL key field value [field value ...] hdel key f2 f3 --(integer) 2 hdel key2 f4 --(integer) 0 del key --(integer) --把整个key存的hash value都删了HKEYS
获取hash中的所有字段field---有一定风险,类似keys *
时间复杂度:O(N)
返回值:字段列表
---先根据key找到对应的hash,O(1)
---然后再遍历hash, O(N),N为key中hash对个数
sqlHKEYS key hkeys key --"f4"HVALS
获取hash中的所有字段field的value
这个操作的时间复杂度,也是O(N),N是哈希的元素个数
如果哈希非常大,这个操作就可能导致redis服务器被阻塞住
sqlHVALS key hvals key --"444"HGETALL
获取hash中的所有字段field+对应value
sqlhgetall key --"f4" --"444"HMGET
可以一次查询多个field;HGET一次只能查一个field
HMSET和HSET都可以设置多个
sqlhmget key f1 f2 f3HLEN
获取指定kay对应hash中的所有字段的个数
时间复杂度:O(1)-----有一个遍量存储这个个数,不用遍历
返回值:字段个数
sqlHSET key2 f1 111 f2 222 f3 333 --(integer) 3 hlen key2 --(integer) 3HSETNX
类似于setnx,不存在的时候,才能设置成功.如果存在,则失败.
sqlHSETNx key field value hsetnx key f5 555 --(integer) 1 hsetnx key f5 666 --(integer) 0HINCRBY
将hash中字段对应的数值添加指定的值
时间复杂度:O(1)
返回值:该字段变化之后的值
sqlHINCRBY key field increment hincrby key f5 -55 --(integer) 500hash这里的value,也可以当做数字来处理,hincrby就可以加减(加负数)整数
hincrbyfloat就可以加减小数
小结
**hkeys, hvals, hgetall:**存在一定风险,hash的元素个数太多,耗时较长,从而阻塞redis
**hscan:**遍历redis的hash,但属于"渐进式遍历";敲一次命令,遍历一小部分(时间可控)
**ConcurrentHashMap:**哈希表在扩容的时候,也是按照化整为零的方式进行
命令 执行效果 时间复杂度 核心解析与注意事项 hset key field value [field value ...]设置单个或多个 field-value 对 O(1)或 O(K) K为设置的字段对数。若 field 已存在则直接覆盖。 hget key field获取指定 field 的值 O(1) 若 key 或 field 不存在,返回 nil。hdel key field [field ...]删除一个或多个 field O(K) K 为要删除的 field 个数。返回成功删除的个数。 hlen key计算指定 key 中 field 的个数 O(1) 内部有计数器直接读取,无需全表扫描。 hgetall key获取该 key 下所有的 field-value O(N) N 为该 Hash 的总元素量。大 key 慎用,容易阻塞单线程。 hmget key field [field ...]批量获取指定 field 的值 O(K) k 为请求的 field 个数。(修正了原图漏掉 key的问题)hmset key field value [field value ...]批量设置多个 field-value 对 O(K) 旧版常用,新版直接用 hset即可。hexists key field判断指定 field 是否存在 O(1) 存在返回 1,不存在或 key 不存在返回0。hkeys key获取该 key 下所有的 field 名 O(N) N 为 field 总数。相当于 Java 中 Map 的 keySet()。hvals key获取该 key 下所有的 value 值 O(N) N 为 field 总数。相当于 Java 中 Map 的 values()。hsetnx key field value只有在 field 不存在时才设置成功 O(1) 原子性操作,常用于分布式锁细粒度键值的安全初始化。 hincrby key field n将对应 field 的值加上整数 n O(1) n 可以为负数。要求原本的 value 必须是能解析的整数。 hincrbyfloat key field n将对应 field 的值+-上浮点数 n O(1) 针对双精度浮点数的数学自增计数器。 hstrlen key field计算指定 field 对应 value 的字符串长度 O(1) 如果 field 不存在,则返回 0。

哈希的内部编码
ziplist (压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries 配置(默认512个)同时所有值都小于hash-max-ziplist-value 配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面hashtable更加优秀。
hashtable (哈希表):当哈希类型无法满足ziplist的条件时,Redis 会使用hashtable 作为哈希的内部实现,因为ziplist 的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
控制哈希在ziplist和hashtable两种内部编码的转换,可能会造成内存的较大消耗。
sqlhmset hashkey f1 v1 f2 v2 --OK object encoding hashkey --"ziplist"string(jison): 如果使用 string(jison)的格式来表示Userlnfo,万一只想获取其中的某个field,或者修改某个field;就需要把整个json都读出来,解析成对象,操作field,再重写转成json字符串,再写回去
hash:如果使用hash的方式来表示Userlnfo就可以使用field表示对象的每个属性(数据表的每个列)此时就可以非常方便的修改/获取任何一个属性的值了;使用hash的方式,确实读写field更直观高效,但是付出的是空间的代价
原生字符串类型:使用字符串类型,每个属性一个键。这种方式,相当于把同一个数据的各个属性,给分散开表示了,低内聚~~
set user:1:name James
set user:1:age23
3.关于List
列表(List)相当于数组或者顺序表;列表中的元素是有序的
如果把元素位置颠倒,顺序调换;此时得到的新的List和之前的List是不等价的
列表中的元素是允许重复的,像hash这样的类型,field是不能重复的
List,头和尾都能高效的插入删除元素,就可以把这个List当做一个栈/队列来使用了
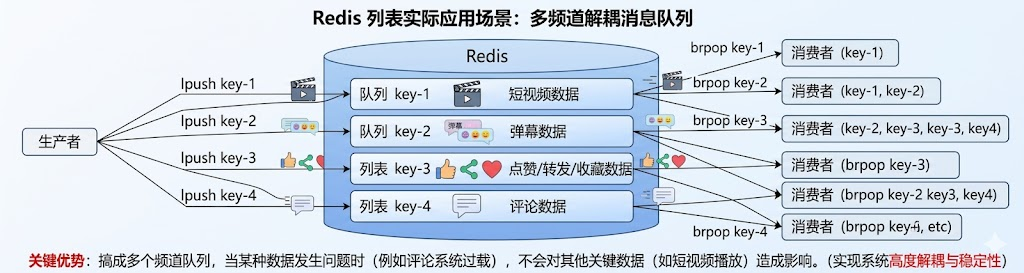
【Redis有一个典型的应用场景,就是作为消息队列.最早的时候,就是通过List类型;Redis又提供了一个steam类型,但用起来较复杂】
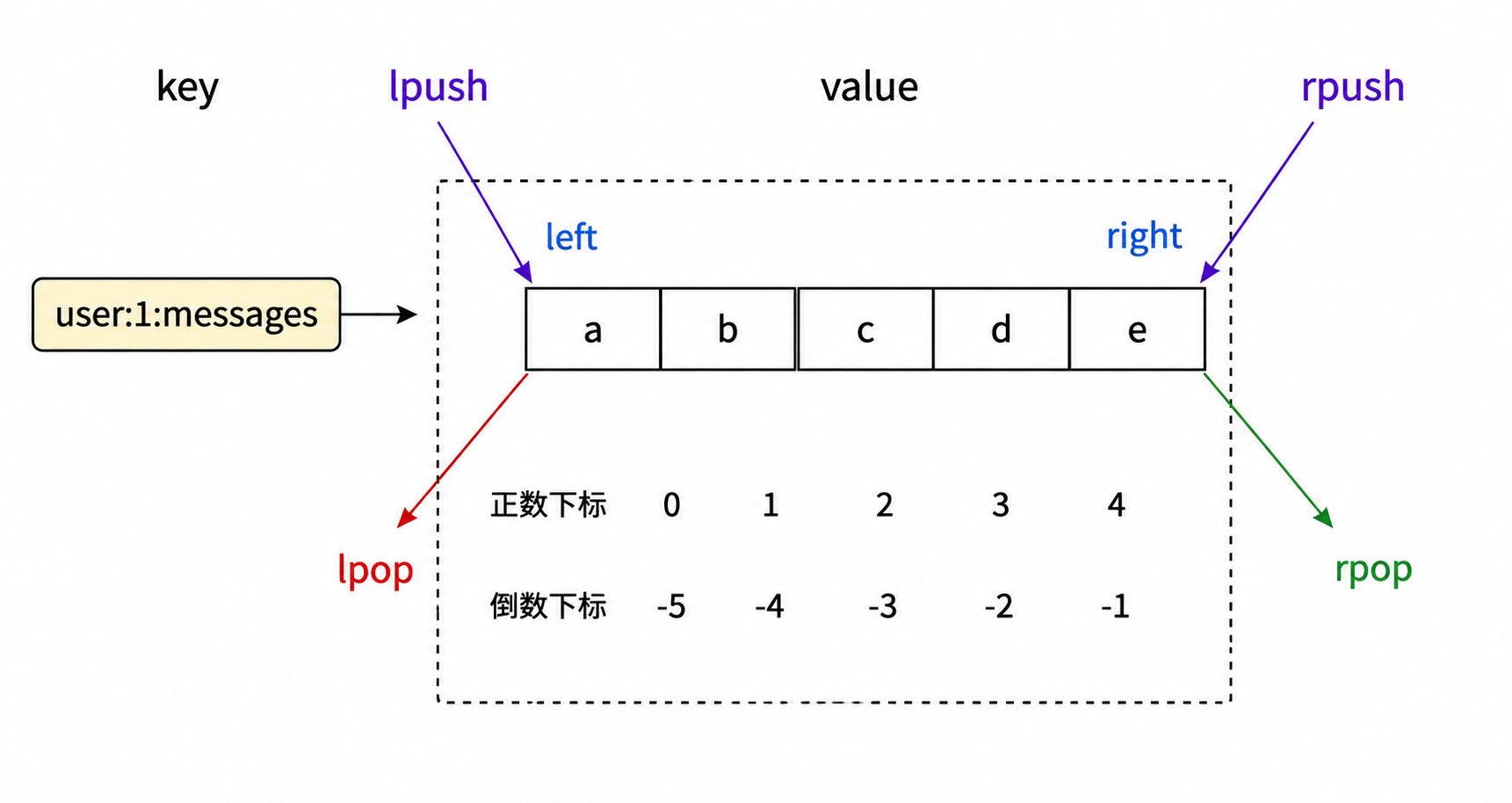
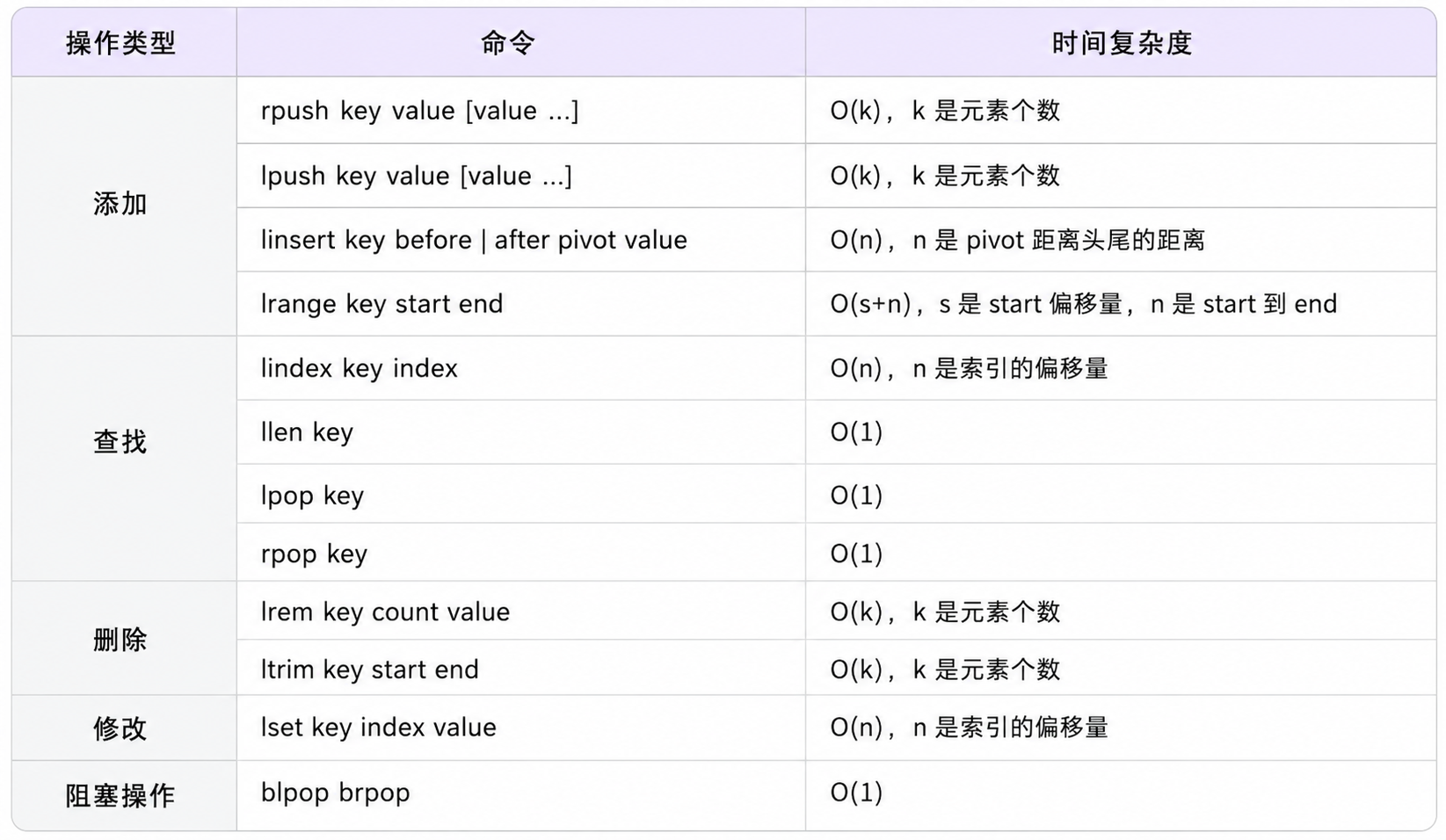
LPUSH/RPUSH
一次可以插入一个元素,也可以插入多个元素,按顺序头插
时间复杂度O(1)
返回值是list的长度.
sqlLPUSH key element [element...] 1push key 1 2 3 4 --(integer) 4 1push key 5 6 7 8 --(integer) 8LPUSHX/RPUSHX
X,其实就是 **eXists(存在),**只有当这个 Key(列表)原本就存在时,它才会往里塞数据时间复杂度:O(1)
返回值:list的长度
sqlLPUSH key value [value ...]LRANGE
Irange命令查看list 中指定范围的元素,此处描述的区间也是闭区间,下标支持负数
-1:代表倒数下标的起点,即最后一个元素(最右侧尾部)Java中,下标超出范围,一般会抛出异常;多出一步下标合法性的验证;缺点:速度比上面要慢优点:出现问题能及时发现
在Redis中直接尽可能的获取到给定区间的元素.如果给定区间非法,比如超出下标就会尽可能的获取对应的内容
sqlLRANGE key start stop lrange key 0 -1 --"8" --"7" --"6" --"5" --"4" --"3" --"2" --"1"LPOP/RPOP
头删/尾删
时间复杂度:O(1)
返回值:取出的元素或者nil
COUNT : 从redis 6.2版本,新增了一个count参;count 就描述这次要删几个元素
lindex / linsert / llen
--LLEN key(Length - 获取列表长度)O(1)
如果这个
key不存在,返回0;如果这个key不是列表类型,报错
--LINDEX key index(Index - 按下标获取单个元素)O(N)
Redis 的列表底层是基于链表 实现的。链表不像数组,它不能根据下标直接做数学计算定位。如果输入一个很深的索引(比如
LINDEX my_list 50000),Redis 必须从头或从尾开始一个一个节点往后数,数到第 50000 个才能拿出来。--
LINSERT key BEFORE|AFTER pivot value(Insert - 定向精准插队)在列表里寻找第一个名字叫
pivot(基准点)的元素,然后在它的 前面(BEFORE) 或者 后面(AFTER) 强行插进去一个新值valueO(N)
LREM
key:列表的名字。
value:你想删除的那个具体元素的值(比如要删掉"abc")。
count:一个整数,用来控制删除的个数 和搜索的方向。
count < 0------ 从右往左,删除指定个数;count = 0------ 全部删除
sqlLREM key count valueO(N + k):N 是整个列表的长度,k 是被删除的元素个数
返回值是实际成功删除的元素个数
LTRIM/LSET
对一个列表进行修剪,只保留指定区间内的元素,不在区间内的元素统统删掉。
时间复杂度: O(N) ------ N 为被移除的元素个数。
核心看点 : 常用于维持一个定长列表(比如只保留最新的 100 条日志),防止列表无限增长撑爆内存。
sql--只保留正数下标 0 到 2 的元素(即前 3 个),其余的全部砍掉 --my_list 内部数据为:["8", "7", "6", "5", "4", "3", "2", "1"] ltrim my_list 0 2 # 返回值:OK --再次查看列表,发现只剩下前三个了 lrange my_list 0 -1 --"8" --"7" --"6"LSET修改(设置)列表中指定下标(Index)的元素的值
时间复杂度 : O(N) ------ N 为到达指定索引需要遍历的节点数。特殊情况:修改头尾(
0或-1)是 O(1)。返回值 : 成功返回
OK;如果下标越界,直接报错
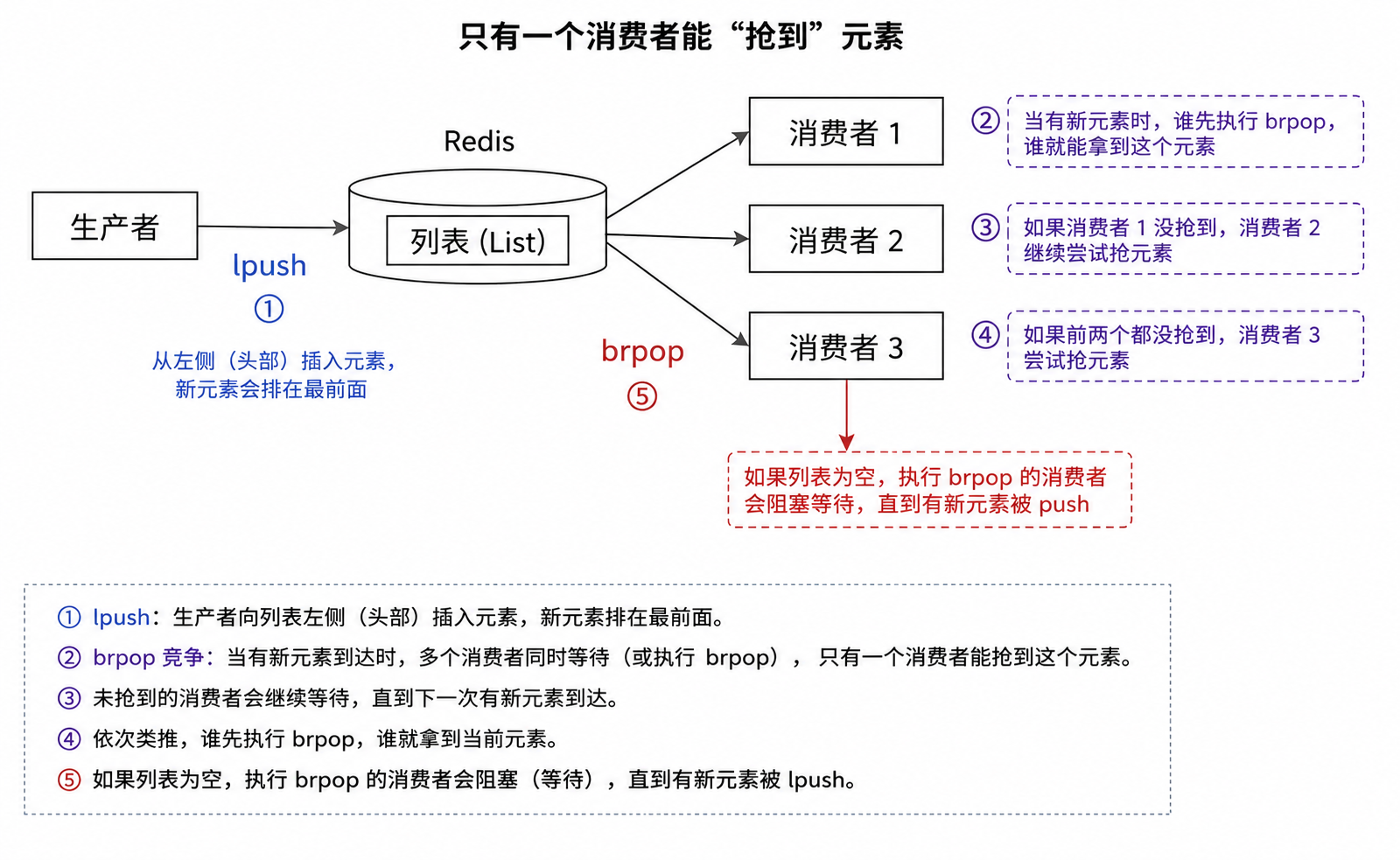
sqlLSET key index value --假设目前 my_list 内部数据为:["8", "7", "6"] --将正数下标为 1 的元素(原本是 "7"),强行修改为 "999" lset my_list 1 "999" --返回值:OK --查看修改后的结果 lrange my_list 0 -1 --"8" --"999" # 已经被成功篡改 --"6" --⚠️ 踩坑点:如果指定的下标超出了当前列表的实际长度 lset my_list 10 "error" --返回值:(error) ERR index out of range(报错:索引越界)BLPOP/BRPOP
Blocking(阻塞)从列表的头部(L)或 尾部(R)弹出一个元素。如果列表中有数据 ,它们的效果和普通的
LPOP / RPOP完全一样,;但如果列表中没有数据(空列表) ,它们不会返回nil,而是会让当前的客户端根据timeout,阻塞一段时间期间Redis可以执行其他命令时间复杂度: O(1)
返回值: Key 的名字+弹出的值
sqlBLPOP key [key ...] timeout --消费者 BRPOP empty_list 20 --进入倒计时20s等待... --生产者 LPUSH empty_list "Tesla" --(integer) 1 --消费者,瞬间被唤醒,并打印出数据和耗时 "empty_list" # 告诉你哪个队列来货了 "Tesla" # 拿到的商品 (3.45s) # 自动记录:你刚好苦苦等待了 3.45 秒 【一直没数据(超时解脱】等了 5 秒钟依然没有任何人往里面放数据,客户端会自动醒来 BRPOP empty_list 5 (nil) (5.02s) # 超时退出,返回 nil此处的这俩阻塞命令用途主要就是用来作为"消息队列",整体来说,这俩命令功能还是比较有限
小结
内部编码
列表类型的内部编码有两种:
ziplist(压缩列表) :当列表的元素个数小于list-max-ziplist-entries 配置(默认512个--现在已经不再使用),同时列表中每个元素的长度都小于list-max-ziplist-value 配置(默认64字节)时,Redis会选用ziplist来作为列表的内部编码实现来减少内存消耗。
linkedlist(链表) :当列表类型无法满足ziplist 的条件时,使用linkedlist 作为列表的内部实现。
新版本quicklist:相当于是链表和压缩列表的结合,整体还是一个链表,链表的每个节点,是一个压缩列表
场景
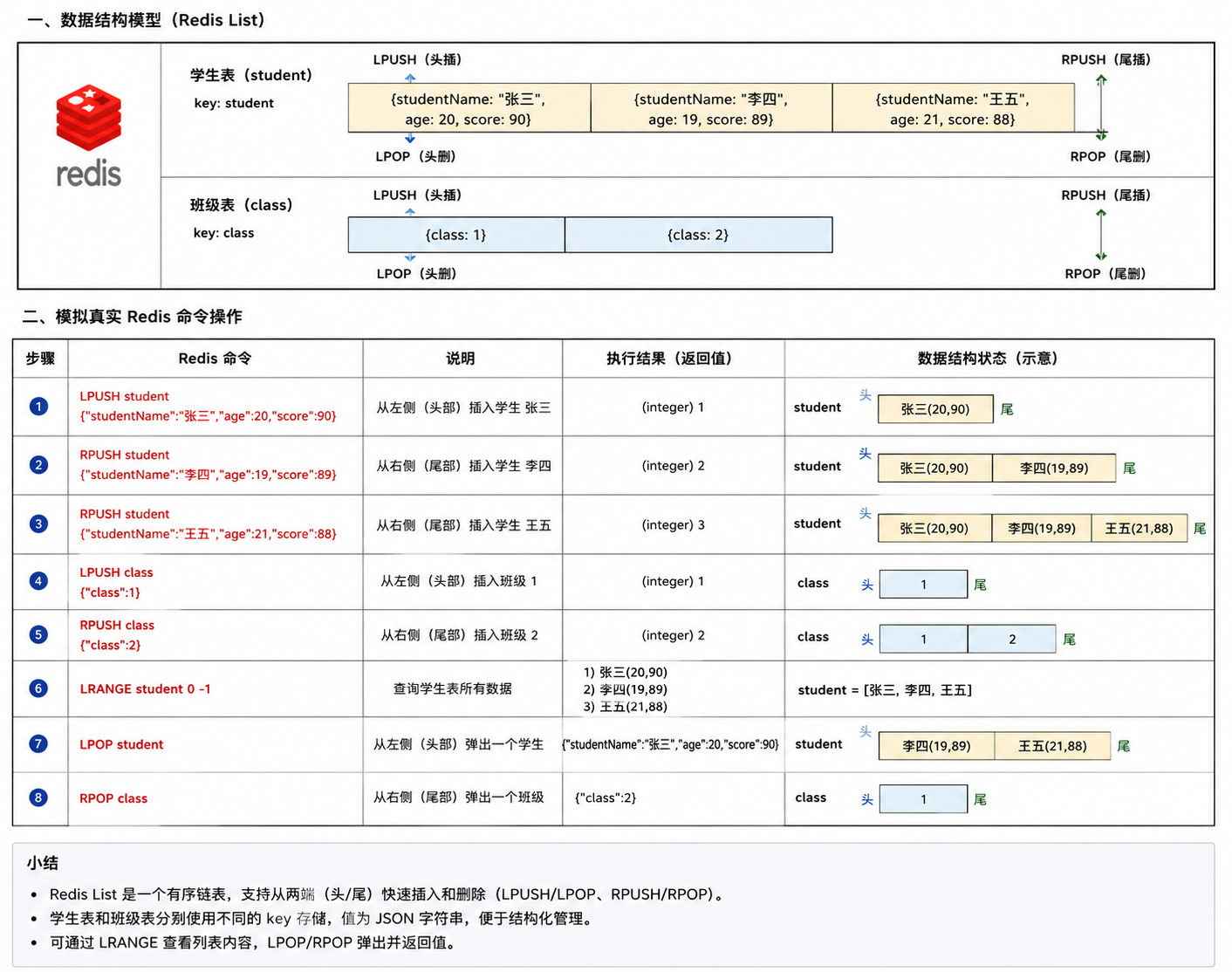
存储表
sql--将张三、李四写入 1 班的 List RPUSH class:1 '{"studentId":1,"studentName":"张三","age":20,"score":90}' RPUSH class:1 '{"studentId":2,"studentName":"李四","age":19,"score":89}' --将王五写入 2 班的 List RPUSH class:2 '{"studentId":3,"studentName":"王五","age":21,"score":88}'消息队列
多频道多通道
微博 Timeline
每个用户都有属于自己的T:hneline(微博列表),现需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。
1)每篇微博使用哈希结构存储,例如微博中3个属性:title、timestamp、content:
sqlhmset mblog:1 title xx timestamp 1476536196 content xxxxx ... ... hmset mblog:n title xx timestamp 1476536196 content xxxxx2)向用户微博列表添加微博,user:<uid>:mblogs作为微博的键:【表示用户和微博间的存储关系】
sqllpush user:1:mblogs mblog:1 mblog:3 ... ... lpush user:k:mblogs mblog:93)分页获取用户的Timeline,例如获取用户1的前10篇微博:
sqlkeylist = lrange user:1:mblogs 0 9 for key in keylist { hgetall key }4.关于set
set:集合中的元素是无序的:顺序不重要,变化一下顺序,集合还是那个集合
list:顺序很重要.变换一下顺序,就是不同的list了
SADD
sqlSADD keymember[member...] sadd key2 1 1 2 3 4 --(integer ) 4SMEMBERS
获取一个set中的所有元素,注意,元素间的顺序是无序的
O(N)
返回所有元素的列表
sqlSMERBERS KEY2SISMEMBER
判断一个元素在不在set中
O(1)
返回值:1表示元素在set中。0表示元素不在set中或者key不存在
SPOP/SRANDMEMBER
随机删除coount个元素,不写count为随机删一个
sqlSPOP key [count]srandmember:能够随机获取多个或一个元素
SMOVE/SREM
sqlSMOVE source destination member把member从 source 上删除,再插入到destination中
SREM : SREM key membermember...
SINTER/SINTERSTORE
交集(inter)、并集(union)、差集(diff):差集:A和B做差集,就是找出在A中存在,在B中不存在
sqlSINTER key [key ...]SINTER:获取给定set的交集中的元素
O(N*M),N是最小的集合元素个数.M是最大的集合元素个数 ; 返回值:交集的元素
sqlSINTERSTORE key3 key key2 --对key和key2求交集,放到key3SINTERSTORE:直接把算好的交集,放到destination这个key对应的集合中,返回个数
SUNION/SUNIONSTORE/SDIFF/SDIFFSTORE
SUNION:返回的就是并集结果
SDIFF:返回差集
SET内部编码
intset(整数集合):为了节省空间,当元素均为整数,并且元素个数不是很多的时候.
hashtable (哈希表):有整数外的存入哈希表
小结
命令 时间复杂度 说明 sadd key element [element ...]O(k) k 是元素个数 srem key element [element ...]O(k) k 是元素个数 scard keyO(1) - sismember key elementO(1) - srandmember key [count]O(n) n 是 count spop key [count]O(n) n 是 count smembers keyO(k) k 是元素个数 sinter key [key ...] sinterstoreO(m * k) k 是几个集合中元素最小的个数,m 是集合数 sunion key [key ...] sunionstoreO(k) k 是多个集合的元素个数总和 sdiff key [key ...] sdiffstoreO(k) k是多个集合的元素个数总和

应用场景
用户画像:使用Set来保存用户的"标签",分析出你这个人的一些特征,分析清楚特征之后,再投其所好;Set方便计算交集~很容易的找到两个用户之间的公共标签;基于这样的标签,衍生出一些"用户关系"
共同好友:使用Set来计算用户之间的共同好友~基于"集合求交集"
统计UV :. PV--page view:用户每次访问该服务器,每次访问都会产生一个pv.
UV--user view:每个用户,访问服务器,都会产生一个uv.但是同一个用户多次访问,不会使uv增加~uv需要按照用户进行去重~~上述的去重过程,就可以使用set来实现
5.关于Zset
有序集合;升序/降序
Zset 中的member 要求是唯一的(score用来排序,可以重复)
ZADD
之前Hash,Set,List很多时候,添加一个元素,都是O(1)此处,
Zset则是logN,由于zset是有序结构,要求新增的元素,要放到合适的位置上(找位置)
参数名称 可选/必选 含义与功能说明 key必选 有序集合的键名。 NX可选 只添加新元素,不更新已存在的元素。 XX可选 只更新已存在的元素,不添加新元素。【 NX与XX互斥GT可选 仅当新分数大于当前分数时,才更新已存在的元素。 LT可选 仅当新分数小于 当前分数时,才更新已存在的元素。【 NX与GT/LT互斥CH可选 修改返回值的行为。默认情况下, ZADD只返回新添加的元素个数。加上CH后,返回值会包含新添加 以及分数被更新的元素总数。INCR可选 将指定元素的分数加上 score值。在此模式下,只能指定一对score member,且返回值会变成该元素更新后的新分数。score必选 元素的分数(可以是整数或双精度浮点数),用于排序。 member必选 要添加到有序集合中的元素成员,需唯一 [score member ...]可选 支持同时添加或更新多个"分数-成员"对(批量操作)。

小结
命令 时间复杂度 含义与参数说明 zadd key score member [score member ...]O(k *log(n)) k 是添加的成员个数,n 是当前有序集合的元素个数。 zcard keyO(1) 获取当前有序集合的元素总个数。 zscore key memberO(1) 获取指定成员的分数。 zrank key memberzrevrank key memberO(log(n)) n 是当前有序集合的元素个数。 zrank为正序 (分数从小到大)排名;zrevrank为倒序 (分数从大到小)排名。 (注:原图拼写错误已修正)zrem key member [member ...]O(k *log(n)) k 是删除的成员个数,n 是当前有序集合的元素个数。 zincrby key increment memberO(log(n)) n 是当前有序集合的元素个数。为指定成员的分数加上增量 increment。zrange key start end [withscores]zrevrange key start end [withscores]O(k + log(n)) k 是获取的成员个数,n 是当前有序集合的元素个数。返回指定索引区间内的成员。 zrangebyscore key min max [withscores]zrevrangebyscore key max min [withscores]O(k + log(n)) k 是获取的成员个数,n 是当前有序集合的元素个数。返回指定分数区间内的成员。 zcount key min maxO(\log(n)) n 是当前有序集合的元素个数。返回指定分数区间内的成员数量。 zremrangebyrank key start endO(k + log(n)) k是删除的成员个数,n 是当前有序集合的元素个数。删除指定排名区间内的所有成员。 zremrangebyscore key min maxO(k + \log(n)) k 是删除的成员个数,n 是当前有序集合的元素个数。删除指定分数区间内的所有成员。 zinterstore destination numkeys key [key ...]O(n * k) + O(m *log(m)) n 是输入集合中元素最少 的那个集合的元素个数;k 是输入的集合个数;m 是合并后目标结果集合 的元素个数。计算交集并存储。( numkeys:参与计算的源 Zset 的**数量,**必须与后面给出的 key 的数量一致)zunionstore destination numkeys key [key ...]O(n) + O(m *log(m)) n 是所有输入集合的元素个数总和 ;m 是合并后目标结果集合的元素个数。计算并集并存储。 编码方式
ziplist :如果有序集合中的元素个数较少,或者单个元素体积较小.使用ziplist来存储.
压缩列表,节省内存空间.
skiplist跳表:当前元素个数多,或单个元素体积非常大,用 skiplist来存,时复O(logN)
应用场景
排行榜 :热搜、游戏天梯、成绩(排行榜要求实时变化
【热度:浏览量,点赞量,转发量,评论... ...(每个维度有权重分配)】