1. 注意力机制规则
它需要三个指定的输入Q(query), K(key), V(value),然后通过计算公式得到注意力的结果,这个结果代表 query在 key和 value作用下的注意力表示;当输入的 Q=K=V时,称作自注意力计算规则;当 Q、K、V不相等时称为一般注意力计算规则。
1.1 常见的注意力计算规则
(常见的注意力计算规则(计算公式):有三种,最常用的第三种,第一种用得少,第二种基本不用;)
1️⃣ 将Q,K进行纵轴拼接,做一次线性变化,再使用 softmax处理获得结果最后与 V做张量乘法; (即假设Q、k的纵轴都是4维则拼接后 的纵轴是8维;然后经过Linear 目的是进行形状变换;再经过Softmax得到一个注意力权重 ,在乘以V得到注意力 ;)
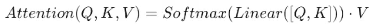
2️⃣ 将Q,K进行纵轴拼接,做一次线性变化后再使用tanh函数激活,然后再进行内部求和,最后使用softmax处理获得结果再与V做张量乘法;(现将QK拼接,在经过linear线性变化,然后使用tanh激活函数,在进行sum内部求和,然后进行softmax,最后乘以V。此种方式基本不用 )
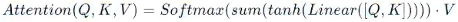
3️⃣ 将Q与K的转置做点积运算,然后除以一个缩放系数,再使用softmax处理获得结果最后与V做张量乘法;(Q与K的转置即K相乘,除以缩放系数(根号dk),dk即为词嵌入维度(词嵌入几维则dk几维),(括号内)原因是:① 使其结果符合标准正太分布,均值为0方差为1;② 除以根号dk目的是防止梯度消失;在经过softmax得到注意力权重,最后乘以V得到Attention;最常用)
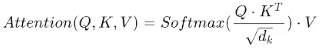
1.2 Seq2Seq架构加入Attention
在上述机器翻译架构中加入Attention的方式有两种:
1.2.1 第一种tensorflow版本(传统方式):
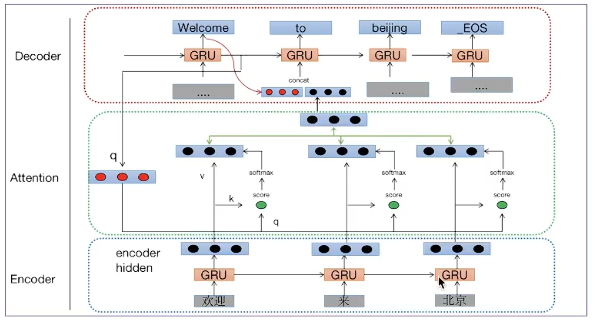
上图翻译应用中的Q、K、V解释:
查询张量Q:解码器上一时间步的隐藏层输出结果 ;
键张量K:编码部分每个时间步的结果组合而成;
值张量V:编码部分每个时间步的结果组合而成。
(有三部分:Query、Key、Value,若想在Seq2Seq架构(或者说Encoder-Decoder架构)中加入Attention,要分别找到QKV,图中由下往上:最下部分是编码器、中间叫注意力也叫中间语义张量C(每一个时间步的C都不一样)、最上面是解码器。
详细步骤:"欢迎""来""北京"三个单词都要送入GRU模型,然后得到三个隐藏层张量(假设都为图中的1行3列 3黑点),此时编码器任务结束;假如目的是拿三个中文单词预测 'to'这个单词, Q是Decoder部分的红线箭头指向部分,预测"to"时拿到上一时间步的隐藏层张量'welcome'(右向箭头),中间绿色部分表示将红色部分的Q复制3次,当第一个时间步"欢迎"的词向量(黑色三点)过来后,认为是Key;复制的Q和Key作用得到3个分数,再分别进行Softmax归一化,得到对应的权重,权重分别再和对应的 V相乘,再求和得到一个中间语义张量C(中间上面的三黑点);
Q是来自解码器的上一层的隐藏层输出结果,拿到Q'welcome'的词向量 与 中间语义张量C进行拼接,经过linear层,再和上一时间步隐藏层的输出结果融合,共同预测"to";在预测"北京"时要拿着前一个Q"to"和K运算得到中间语义张量C;预测"welcome"拿的Q是"GO"(一个初始化的张量h0);每次预测时,中间语义张量C都改变了。只要是做文本生成式任务,分别给他一个开始、结束的说明;)
1.2.2 第二种Pytorch版本(改进版):
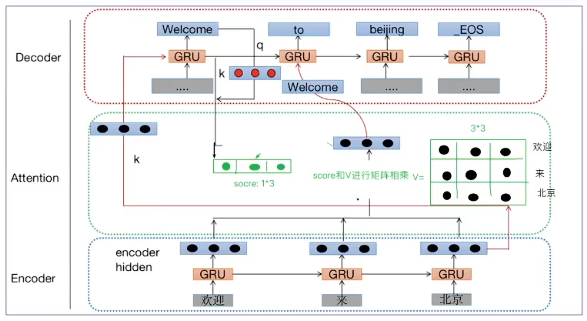
上图翻译应用中的Q、K、V解释
查询张量Q:解码器每一步的输出(预测结果)或者是当前输入的x;
键张量K:解码器上一步的隐藏层输出;
值张量V:编码部分每个时间步输出结果组合而成;
(由下往上,"欢迎""来""北京"3个词经过编码器得到3个隐藏层张量输出结果(下部分三黑点);但是一开始送到解码器中的GRU翻译'welcome'时会有一个上一时间步隐藏层输出结果:对于第一种传统方式在预测第一个值"welcome"时传入的是一个初始化的值GO(h0),但这里第二种方式把编码器最后一个单词"北京"这个词的隐藏层张量的输出结果(它包含了整个编码器的语义)直接送给解码器中的第一个时间步翻译出第一个单词"welcome",同时有一个当前时间步的隐藏层输出结果 就是 k-Key(图中红点)、q-Query即为翻译出来的'welcome'的词向量 ,都是1行3列 拼接 得到 ---》1行6列,经过linear 可以改变形状再次变成 1行3列(中间score)得到权重值 ;再将权重值与原来的V (每个时间步的隐藏层输出结果组合而成,中间的 3*3部分)相乘,得到中间语义张量C 即为注意力 。
再将得到的中间语义张量C与 'welcome'拼接(向上箭头),经过linear,再与上一时间步隐藏层输出结果q,共同作用,预测出单词'to';q是上一时间步预测出的真实的结果 'Welcome'(向上output的)、k是上一时间步的隐藏层输出结果,两者进行向量的拼接通过linear,再经过softmax得到权重分数(中间);权重分数再分别乘以对应的V(每个编码器中每个单词的隐藏层输出结果)得到中间语义张量C,再和'welcome'拼接,linear后得到当前时间步的真实输入,加上上一时间步的隐藏层输出结果共同作用,预测出单词'to';
这是第二种计算注意力的方式;)
(为什么k、q两者作用的这种方式有效?:因为上一时间步的隐藏层输出结果k包含了编码器中所有单词的信息;
预测第一个单词'welcome'时如何得知那个单词的权重最大呢?:此时 q指的是GO(第一个灰色块),k是编码器过来的k,两者作用;)
第一种传统方式是点乘运算,第二种是拼接运算;
2. 什么是深度神经网络注意力机制
注意力机制是注意力计算规则能够应用的深度学习网络的载体,同时包括一些必要的全连接层以及相关张量处理,使其与应用网络融为一体,使用自注意力计算规则的注意力机制称为自注意力机制。(注意力计算规则即 输入Q=K=V)
说明:NLP领域中,当前的注意力机制大多数应用于 seq2seq架构,即编码器和解码器模型.
请思考:为什么要在深度神经网络中引入注意力机制?
1、rnn等循环神经网络,随着时间步的增长,前面单词的特征会遗忘,造成对句子特征提取不充分;
2、rnn等循环神经网络是一个时间步一个时间步的提取序列特征,效率低下;
3、研究者开始思考,能不能对32个单词(序列)同时提取事物特征,而且还是并行的,所以引入注意力机制。
3. 注意力机制的作用
在解码器端的注意力机制 :能够根据模型目标有效的聚焦编码器的输出结果,当其作为解码器的输入时提升效果,改善以往编码器输出是单一定长张量,无法存储过多信息的情况;(即以前是一个固定的中间语义张量C,有了注意力机制,中间语义张量C长度可变。)
在编码器端的注意力机制 :主要解决表征问题,相当于特征提取过程,得到输入的注意力表示.一般使用自注意力(self-attention;
注意力机制在网络中实现的图形表示:
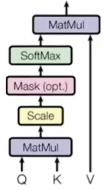
(此图是transformer中进行自注意力计算的公式:Q * K,MatMul是pytorch中矩阵点积运算,Scale缩放即归一化标准化除以根号dk,Mask(opt) opt-optional可选择的,经过softmax归一化得到权重,再乘以V,得到注意力;此为前面的第三种注意力机制图形展示;)
4. 注意力机制实现步骤
4.1 步骤

第一步:根据注意力计算规则,对Q,K,V进行相应的计算;
第二步:根据第一步采用的计算方法,如果是拼接方法,则需要将Q与第一步的计算结果再进行拼接,如果是转置点积,一般是自注意力,Q与V相同,则不需要进行与Q的拼接;
第三步:最后为了使整个attention机制按照指定尺寸输出,使用线性层作用在第二步的结果上做个线性变换,得到最终对Q的注意力表示.。
(如果第一步采用的计算方法是拼接方式(第一种、第二种),计算完结果后还需要将Q与第一步的计算结果再进行拼接;最后为了使整个attention机制按照指定尺寸输出,使用线性层作用在第二步拼接的结果上做个线性变换,得到最终对Q的注意力表示。
如果第一步采用的不是拼接方式,而是点积运算,则不需要与Q进行拼接了。不需要第三步了。)
(总结:注意力的计算规则即方法,当真正用到神经网络中写代码时,需要按照注意力计算的步骤进行:第一步:选择三种计算方式中的一种进行QKV的计算;第二步:如果第一部采用的是拼接的方式(前两种),需要将原来的Q与 第一步计算的结果即注意力再进行拼接,拼接完成后再经过第三步 线性的变换,得到最终的注意力的表示;如果第二步没有采用拼接方式,而是采用第三种点积方式,可以进行第三步、也可以不进行第三步线性变换。)
4.2 代码实现
使用第一种方式实现:


4.2.1 init方法
init方法:output_size是第三步进行线性变换时指定的模型输出维度;定义一个全连接层即线性层1:按照第一种计算方式,首先Q K进行拼接,拼接后经过一个linear层,Q(1,1,32)、K(1,1,32)拼接后 - -》(1,1,64)当送给linear层时,输入特征的维度是64,所以定义linear时是:self.query_size 32+self.key_size 32;输出是 value_size1 32,得到结果后要与V(1,32,64)相乘,所以 softmax之后的结果的最后一个维度一定是32,所以是value_size1 32;即 softmax - -> 1, 1, 32 - -> 1, 32, 64 - -> 1, 1, 64 ?? 第一步得到 1, 1, 64 的结果,第二步 如果第一步是拼接的方式,需要将第一步的结果与 Q再次拼接,再第三步送到linear层:所以代码中线性层2 query_size 32+value_size2 64,即将Q1, 1, 32 与第一步计算结果Q1, 1, 64 拼接,得到 1, 1, 96,所以 输入特征维度query_size 32+value_size2 64 - - > 1, 1, 96,output_size自己设定为 32;
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 进行按照第一种规则实现注意力的计算
class MyAttention(nn.Module):
def __init__(self, query_size, key_size, value_size1, value_size2, output_size):
super().__init__()
# query_size:Q张量的最后一个维度
self.query_size = query_size
# key_size:K张量的最后一个维度
self.key_size = key_size
# value_size1:V张量的中间的维度
self.value_size1 = value_size1
# value_size2:V张量的最后一个维度
self.value_size2 = value_size2
# output_size:注意力指定最后的输出维度
self.output_size = output_size
# 定义第一个全连接层:计算注意力的权重值
# 输入特征,注意: Q和k要进行拼接,然后在输入:Q-->[1,1,32],K-->[1,1,32]-->[1,1,64]
# 输出特征,注意: 因为Linear之后的结果要和 V--》[1,32,64],所以输出的维度一定是32
self.attweight = nn.Linear(self.query_size + self.key_size, self.value_size1)
# 定义第二个全连接层:计算最终的注意力结果
# 输入特征,注意:0和第一步计算的结果要进行拼接,然后在输入:0-->[1,1,32],步骤1-->[1,1,64]-->[1,1,96]
# 输出特征,指定的输出output_size
self.out = nn.Linear(query_size + value_size2, output_size)
if __name__ == '__main__':
query_size = 32
key_size = 32
value_size1 = 32
value_size2 = 64
output_size = 32
attention = MyAttention(query_size, key_size, value_size1, value_size2, output_size)
print(attention)