Task04 打卡笔记:分支 A 继续做 LeWorldModel
Task03 我选的是分支 A,先把 MuJoCo + ACT 的操作链路理了一遍:示教数据进来,ACT 根据图像和状态预测一段动作,再放回 MuJoCo 里 rollout。Task04 没有换方向,我继续留在操作模型与世界模型这条线上,选了 LeWorldModel 做进阶复现。原因也很直接:ACT 解决的是"现在该怎么动",LeWM 多看了一步,先学"执行某个动作以后环境会变成什么",再用这个预测结果去选动作。
这次主要参考项目里的两份材料:
Task03-分支A操作模型与世界模型-MuJoCo_ACT复现教程.md17-具身世界模型/Leworldmodel分析解读与实验复现/Leworldmodel分析解读与实验复现.md
这次复现抓住的点
LeWM 的结构比我预期的简单。它把当前图像 o_t 编码成潜在向量 z_t,再把 z_t 和动作 a_t 丢给 predictor,预测下一时刻的潜在表示 z_{t+1}。代码层面主要盯住两项 loss:
python
pred_loss = (pred_emb - tgt_emb).pow(2).mean()
loss = pred_loss + lambd * sigreg_loss这里 pred_loss 管未来状态预测,SIGReg 管特征分布别塌掉。表征崩溃这件事在世界模型里很现实:如果 encoder 把所有图像都压成同一个向量,预测误差可以被做得很低,但这个模型已经分不清房间、方块和目标位置了。LeWM 的处理办法是把高维特征随机投到多个一维方向上,再做一维正态性约束。论文里用 Cramer-Wold 定理兜底,我觉得少绕一层 teacher-student 和 EMA,也不用堆 7 个辅助 loss,直接用一个分布约束逼 encoder 保留信息。
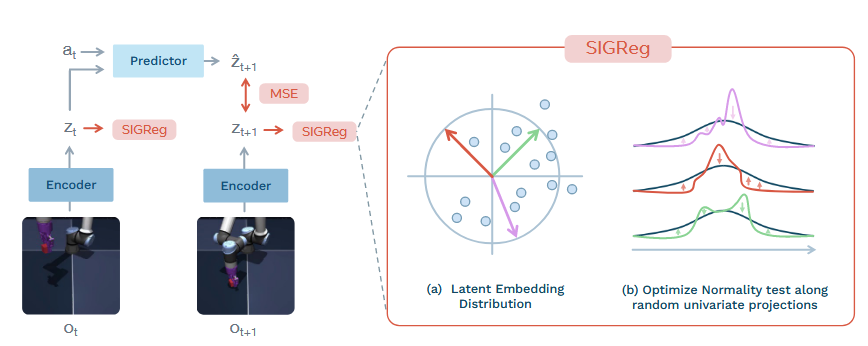
训练好的 LeWM 像一个小型"仿真器"。先把当前图像和目标图像编码成两个 latent,然后采样一批未来动作序列,用 predictor 在 latent 空间里往前滚 H 步,最后挑出离目标 latent 最近的那组动作。实际执行时只走第一步,下一帧再重新规划。这个 receding horizon 的做法能缓解长序列自回归误差,长 rollout 一次走到底我觉得风险会很大。
复现步骤
环境按 LeWM 文档走,Python 版本用 3.10:
bash
conda create -n lewm python=3.10
conda activate lewm
pip install stable-worldmodel[train,env]数据和权重按任务分目录放。tworoom 的结构是:
text
lewm/
└── tworoom/
└── tworoom/
├── lewm_object.ckpt
└── tworoom.h5cube 的数据多一层 ogbench:
text
lewm/
└── cube/
├── ogbench/
│ └── cube_single_expert.h5
└── cube/
└── lewm_object.ckpt路径这里要小心,STABLEWM_HOME 需要指到任务外层目录。比如 tworoom:
bash
export STABLEWM_HOME=/home/your-user/lewm/tworoom
python train.py data=tworoom
python eval.py --config-name=tworoom.yaml policy=tworoom/lewm我这次没把所有任务都铺开,重点看了 tworoom 和 cube。tworoom 更像导航预测问题,cube 更接近机械臂操作,能和 Task03 的 ACT 对上。
结果记录
tworoom 结果:
text
success_rate: 98.0
evaluation_time: 179.3897 seconds
episodes: 50这个结果说明 LeWM 在简单二维房间任务上能稳定用 latent 预测支撑规划。50 个 episode 里只有 1 个失败,失败样本值得后面单独看轨迹,不然只看 98% 会把问题遮住。


cube 结果:
text
success_rate: 64.0
evaluation_time: 191.0677 seconds
episodes: 50cube 的 64% 我不打算直接当成"机械臂操作已经做得不错"。这里有两个折扣:一是 cube 权重只训练了 12 轮,二是成功判定只看方块位置和目标位置的欧氏距离是否小于等于 0.04 m,没有检查夹爪姿态、接触过程和最终稳定性。方块到了目标点就算成功,机械臂有没有用一个像样的操作过程完成,指标没有完全约束住。


遇到的问题
官方 Google Drive 权重不方便下载,改用 Hugging Face 上的 Datawhale 权重更省事。还有一个小坑:Hugging Face 下到的 .pt 和 eval 期望的 .ckpt 不完全是一回事,直接混用会卡在加载阶段。我最后按文档把对应任务的权重重命名成 lewm_object.ckpt,放到任务目录里。
路径也容易踩。STABLEWM_HOME 如果只指到 lewm/,模型权重会散在根目录下面,训练和评估再切任务时很乱。我这次把它指到 lewm/tworoom 或 lewm/cube,后面排查日志方便很多。
我对 cube 的成功率还存疑。0.04 m 的距离阈值适合快速评估目标到达,但机械臂任务最好再补一个过程指标,比如夹爪是否完成稳定抓取、方块到目标后是否保持若干帧、末端执行器是否离开目标区域。否则会出现"指标成功,视频看着勉强"的情况。
和 Task03 的关系
Task03 的 ACT 是 imitation policy,训练目标贴着动作数据走;LeWM 是 model-based planning,先学环境转移,再通过目标 latent 反过来挑动作。两者没有谁替代谁的问题,算是同一条操作链路里的两种接口。
如果后面继续做,我会先做一个小对比表:ACT 看单步或 action chunk 的动作误差,LeWM 看 latent 预测误差和规划成功率。再往后可以试 cube 的完整 99 轮训练,重新测 50 个 episode,并把成功判定改得严格一点。这个方向继续挖下去,比较有意思的是把 LeWM 的未来预测接到 ACT/VLA 的动作候选上,让策略模型提动作,世界模型负责提前筛掉明显会失败的动作序列。