文章目录
- 一.前言
- 二.核心技术&知识
-
- 1.PyQt5
- 2.YOLOv8
- 3.DeepSeek
- 4.Sqlite3
- 5.多线程
- 6.淋巴细胞
- 7.淋巴细胞检测的意义和应用场景
-
- [1. 医院病理诊断与辅助阅片](#1. 医院病理诊断与辅助阅片)
- 2.肿瘤免疫微环境研究
- [3. 医学教学与实验培训](#3. 医学教学与实验培训)
- [4. 医学检验与血液细胞分析](#4. 医学检验与血液细胞分析)
- [5. 生物医学科研与药物研发](#5. 生物医学科研与药物研发)
- 三.核心功能
- 四.数据集
- 五.问题统一回答
-
- 1.数据库
-
- 1.users用户信息表
- [2.detect_history 检测历史表](#2.detect_history 检测历史表)
- 2.如何修改文案
- 3.如何修改图片资源
- [4.如何更换API Key](#4.如何更换API Key)
- 5.运行最佳分辨率
- 6.如何隐藏部分功能
- 7.软件系统架构图
- 六.关于项目
- 七.总结
本系统功能强大!支持对输入数据源的淋巴细胞情况进行检测,支持多种数据数据源输入并且接入了AI实现了对当前分析结果的评估,欢迎了解!
@项目名称:基于PyQt+YOLO+DeepSeek的的淋巴细胞检测系统
@仓库名称:yolov8-lymphocyte-detect
@作者:懷淰メ
@主页地址:https://blog.csdn.net/a1397852386
@定制:A1397852386
@开发日期:2026年5月
关键字:
一.前言
随着数字病理学和医学影像分析的发展,淋巴细胞的精准检测在肿瘤免疫研究和疾病诊断中扮演着关键角色。传统的人工显微镜观察不仅耗时耗力,而且受主观经验影响,容易出现漏检或误检现象。因此,开发一种高效、智能化的淋巴细胞检测系统具有重要的临床价值。该项目基于PyQt构建友好的图形用户界面,结合YOLO(You Only Look Once)目标检测算法实现对图像、视频及实时视频流中淋巴细胞的快速识别与定位,同时融入DeepSeek深度特征检索技术,支持对细胞形态和特征的精准检索与分类。通过这一系统,用户不仅可以对单张病理图像进行批量分析,还能实时监控实验样本的动态变化,实现从图像采集到结果输出的全流程智能化管理。项目的意义在于:一方面大幅提高病理分析的效率和准确性,减轻病理学家的工作负担;另一方面为免疫微环境研究、肿瘤评估及临床诊疗提供可量化、可追溯的数据支撑,为精准医疗和数字病理的发展奠定技术基础。该系统的集成化设计和深度学习能力使其在科研和临床应用中均具有广阔的推广前景。
二.核心技术&知识
在这章我将要介绍本系统的核心技术。
1.PyQt5
PyQt5 是一套用于创建跨平台桌面应用程序的 Python GUI 工具包,它是 Qt 应用框架的 Python 绑定。通过 PyQt5,开发者可以使用 Python 编写具有现代图形界面的应用程序,支持丰富的控件、信号与槽机制、窗口管理、事件处理等功能。它兼容主流操作系统(如 Windows、macOS 和 Linux),适用于开发各种规模的桌面软件,常与 Qt Designer 配合使用以加快开发效率。

2.YOLOv8
YOLOv8(You Only Look Once version 8)是由 Ultralytics 推出的最新一代实时目标检测模型,属于 YOLO 系列的改进版本。相比前代模型,YOLOv8 在精度、速度和灵活性上都有显著提升,支持目标检测、图像分割、姿态估计等多任务处理。它采用了更加高效的网络结构和训练策略,并提供开箱即用的 Python 接口和命令行工具,适用于边缘设备和云端部署,广泛应用于安防监控、自动驾驶、工业检测等场景。

3.DeepSeek
DeepSeek是由深度求索公司开发的AI大模型助手,作为纯文本模型,我擅长自然语言处理、文档分析和智能对话。当与YOLO(You Only Look Once)实时目标检测系统结合时,可以形成强大的多模态应用架构------YOLO系统负责实时视觉识别和目标检测,快速准确地识别图像或视频流中的物体;而我则对YOLO检测到的结果进行深度语义分析和上下文理解,提供物体属性的详细解读、场景描述、行为分析以及决策建议。这种结合使得计算机视觉的"看到"与AI的"理解"完美融合,可广泛应用于智能监控、自动驾驶、工业质检等领域,实现从视觉感知到智能决策的完整闭环。

4.Sqlite3
本系统使用Sqlite3进行数据的存储与管理。
SQLite3是一种轻量级的嵌入式关系型数据库管理系统,广泛应用于桌面软件、移动应用以及各类嵌入式设备中。与传统的客户端-服务器数据库(如MySQL、PostgreSQL)不同,SQLite3无需独立的数据库服务器进程,整个数据库以单一文件形式存储在本地,应用程序可直接通过库文件进行读写操作。这种架构使其具有部署简单、占用资源少、跨平台性强等显著优势。SQLite3遵循ACID事务特性,能够保证数据的一致性与可靠性,同时支持标准SQL语法,包括表的创建、查询、索引、触发器等常见功能,能够满足中小规模数据管理需求。在性能方面,SQLite3在读操作上表现高效,并通过锁机制实现多线程环境下的基本并发控制。由于其零配置特性和稳定性,SQLite3被广泛集成于Android、iOS等操作系统中,也常用于缓存数据存储、本地日志管理以及离线数据处理等场景。总体而言,SQLite3以其简洁高效的设计理念,在轻量级数据管理领域占据了重要地位。

5.多线程
QThread 是 PyQt5 提供的线程类,主要用于在图形界面程序中安全、高效地执行耗时任务,从而避免主线程阻塞导致界面卡顿或无响应的问题。在典型的GUI应用中,界面渲染与用户交互通常运行在主线程,一旦在该线程中直接执行诸如数据处理、深度学习模型推理、视频流分析或文件读写等耗时操作,就容易造成界面冻结,严重影响用户体验。QThread 的引入正是为了解决这一问题。
通过 QThread,开发者可以将这些计算密集型或IO密集型任务封装到子线程中独立运行,使主线程专注于界面更新与交互响应。同时,QThread 提供了基于信号与槽机制的线程间通信方式,能够在不同线程之间安全地传递数据与状态信息。例如,子线程在完成检测或处理任务后,可以通过发送信号将结果传递给主线程,由主线程负责更新界面控件,从而避免直接跨线程操作UI带来的风险。
此外,QThread 还支持线程的生命周期管理,包括启动、暂停、退出以及资源回收等,使得多线程程序结构更加清晰可控。合理使用 QThread 不仅可以显著提升应用程序的响应速度和运行效率,还能增强系统的稳定性与扩展能力。在涉及实时数据处理、视频监控或智能分析等复杂桌面应用开发场景中,QThread 已成为不可或缺的重要工具。
6.淋巴细胞
淋巴细胞是人体免疫系统的核心卫士,堪称一支高度专业的"精英部队"。它们起源于骨髓,主要定居在淋巴器官和循环系统中,时刻警惕着入侵的病原体和异常细胞。
这支部队分为两大主力:B细胞和T细胞。B细胞如同"情报专家",负责生产抗体------一种能精准识别并标记入侵者的蛋白质。一旦标记,其他免疫细胞便会迅速清除敌人。而T细胞则更为多样:辅助T细胞是"指挥官",协调整个免疫应答;杀伤T细胞是"特种兵",直接摧毁被病毒感染的细胞或癌细胞。
淋巴细胞的过人之处在于其"免疫记忆"。当首次遭遇某种病原体后,部分淋巴细胞会转化为记忆细胞,长期存活。若同一种病原体再次来袭,它们能迅速增殖并发动攻击,常常在症状出现前就清除了威胁------这正是疫苗接种的原理。
没有淋巴细胞,人体将暴露于无尽的感染与疾病中。它们是守护健康的无声力量,每天都在上演着精妙的防御战。珍惜这些微小而强大的细胞,就是珍视生命本身。
7.淋巴细胞检测的意义和应用场景
1. 医院病理诊断与辅助阅片
在医院病理科的日常工作中,淋巴细胞数量、分布特征以及形态变化往往是判断炎症反应、免疫状态和肿瘤微环境的重要依据。传统检测方式主要依赖病理医生通过显微镜进行人工观察和计数,不仅需要投入大量时间,而且在面对大批量病理切片时容易受到疲劳、经验差异等因素影响。基于PyQt+YOLO+DeepSeek的淋巴细胞检测系统能够自动对数字病理图像进行分析,快速定位淋巴细胞区域并完成目标检测、统计和结果可视化展示。医生只需导入病理切片图像,即可获得细胞数量、位置坐标和检测置信度等信息,从而显著提升阅片效率。同时,系统支持对检测结果进行人工校正和二次审核,实现"人工+智能"的协同诊断模式。对于肿瘤病理诊断而言,淋巴细胞浸润程度是评价患者免疫反应和预后的重要指标,系统能够快速统计肿瘤组织中的淋巴细胞密度,为医生制定治疗方案提供客观参考依据。该应用场景不仅能够提高诊断效率和准确率,还能够推动数字病理和智慧医疗的发展,为医院实现病理诊断标准化和智能化提供有力支撑。
2.肿瘤免疫微环境研究
在肿瘤学研究领域,淋巴细胞是免疫系统识别和攻击肿瘤细胞的重要组成部分,其分布情况与肿瘤发展、转移以及患者预后密切相关。研究人员通常需要分析大量组织切片,以评估不同区域内淋巴细胞的浸润程度和空间分布规律。然而,传统人工标注方式工作量巨大,尤其是在大规模科研项目中,往往需要投入大量的人力和时间成本。基于PyQt+YOLO+DeepSeek的淋巴细胞检测系统能够自动识别病理切片中的淋巴细胞,并对其进行批量统计和空间位置分析,为肿瘤免疫微环境研究提供高效的数据处理工具。系统支持图像和视频数据分析,可以针对不同实验组进行自动化比较,生成细胞密度热力图、数量统计图以及分布趋势分析结果。借助DeepSeek特征分析能力,研究人员还能够对不同形态特征的淋巴细胞进行筛选和检索,探索细胞异质性与疾病发展的关系。该系统能够大幅缩短数据处理周期,提高科研数据的一致性和可重复性,为肿瘤免疫治疗机制研究、免疫治疗效果评估以及新型抗肿瘤药物研发提供重要的技术支持。
3. 医学教学与实验培训
医学教育过程中,血液学、病理学以及细胞生物学课程通常需要学生掌握淋巴细胞的识别方法和形态学特征。传统教学主要依赖教师讲解和显微镜观察,但由于细胞种类繁多、样本差异较大,学生往往难以在短时间内准确掌握相关知识。基于PyQt+YOLO+DeepSeek的淋巴细胞检测系统可以作为智能教学平台应用于医学院校和实验培训机构。教师能够利用系统导入大量标准病理图像和显微镜视频,通过实时检测结果帮助学生理解淋巴细胞的典型特征和识别依据。系统能够自动标注淋巴细胞位置,并显示检测框和类别信息,使抽象的理论知识转化为直观的视觉内容。此外,系统还支持实时摄像头视频流分析,学生可以通过连接数字显微镜观察实验样本,实时查看AI检测结果,从而增强实践操作能力。对于实验考核场景,系统还可以统计学生标注结果与标准答案之间的差异,辅助教师进行客观评价。通过人工智能技术与医学教学的深度融合,该系统能够提高教学效率,降低学习门槛,帮助学生更快掌握病理图像分析技能,为培养高水平医学人才提供新的教学手段。
4. 医学检验与血液细胞分析
在临床医学检验领域,血液样本中的淋巴细胞数量和比例是评估人体免疫功能的重要指标,广泛应用于感染性疾病、血液系统疾病以及免疫系统疾病的诊断和监测。传统检验流程通常需要检验人员对血液涂片进行显微镜观察和人工计数,面对大量样本时工作强度较高。基于PyQt+YOLO+DeepSeek的淋巴细胞检测系统可以与数字显微镜设备相结合,实现血液图像的自动分析。系统能够快速检测视野中的淋巴细胞目标,自动完成计数、分类和结果统计,并生成检测报告。对于实验室连续采集的视频流数据,系统还能够实时跟踪和分析细胞变化情况,提高检测效率和数据准确性。DeepSeek模块可以进一步提取细胞特征信息,对异常淋巴细胞进行筛查和检索,辅助发现潜在病变细胞。该系统能够有效减少人工计数误差,提高检验结果的一致性和客观性。同时,自动化检测能力有助于缩短样本处理时间,提高实验室整体工作效率。随着智慧医疗和自动化检验技术的发展,该系统在基层医院、第三方医学检验机构以及大型医学中心均具有良好的应用价值和推广前景。
5. 生物医学科研与药物研发
在生物医学科研和新药研发过程中,研究人员经常需要观察药物对免疫细胞行为的影响,例如细胞增殖、迁移、聚集以及凋亡等过程。传统分析方式需要研究人员逐帧观察显微镜图像或视频,不仅耗时,而且难以处理大规模实验数据。基于PyQt+YOLO+DeepSeek的淋巴细胞检测系统能够对实验产生的图像、视频以及实时视频流进行自动分析,实现淋巴细胞的精准识别和动态监测。研究人员可以利用系统自动统计不同时间点的细胞数量变化情况,并结合实验参数分析药物作用机制。对于长时间培养实验,系统能够持续跟踪细胞运动轨迹,记录细胞增殖和迁移行为,为药效评价提供量化数据支持。同时,DeepSeek特征分析功能能够帮助研究人员发现不同药物处理条件下细胞形态的细微变化,提高实验结果分析的深度和精度。通过自动化检测与智能分析技术的结合,系统不仅能够降低科研人员的数据处理负担,还能够提高实验结果的客观性和重复性,加速药物筛选、免疫治疗研究以及细胞生物学研究的开展,为生命科学领域的创新发展提供重要技术支撑。
三.核心功能
1.登录注册
1.登录
软件启动后首先进入登录页面,用户需要输入正确的用户名和密码,经过系统验证后方可使用本系统的正式功能。登录页面整体采用垂直布局,使信息层次清晰、结构简洁,同时在局部区域辅以水平布局,以提升界面的灵活性与可读性。整体设计风格遵循"简约而不简单"的原则,在保证视觉美观的同时,也兼顾操作的直观性与易用性。
在功能实现方面,登录模块的后端采用sqlite3文件型数据库来存储用户信息,包括用户名、密码及相关基础数据。每次用户发起登录请求时,系统都会通过查询数据库进行身份校验,确保输入信息的准确性与安全性,从而实现规范化、标准化的登录流程。
同时,我们设计了统一风格的登录与注册界面,用于展示系统与用户交互所需的全部组件。界面顶部以醒目的标题形式展示系统名称,增强整体识别度与专业性。通过合理布局输入框、按钮及提示信息,使用户在使用过程中能够快速理解操作步骤,从而提升整体使用体验。
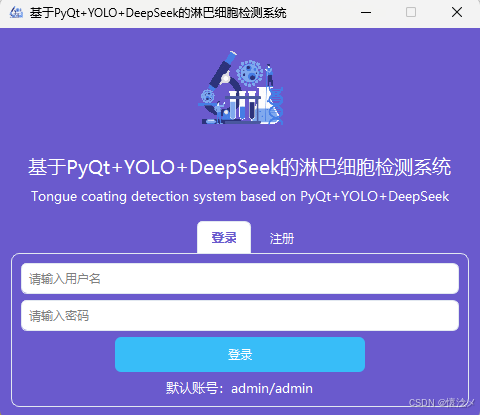
2.注册
对于尚未拥有账号的用户,需要先完成注册操作后才能使用系统功能。整体注册流程设计得较为简洁直观,用户只需在登录界面点击"注册"按钮,即可快速跳转至注册窗口,无需复杂的页面切换或额外步骤。在注册界面中,用户需要填写自定义的用户名,并输入两次一致的密码以完成身份信息的确认。这种双重密码输入机制可以有效避免因输入错误而导致的登录失败问题,从而提升系统的可靠性与用户体验。
在用户成功完成注册后,系统还提供了一项便捷的优化设计:自动将刚刚注册的用户名和密码填充到登录界面中。用户无需再次手动输入信息,即可直接进行登录操作。这一设计在一定程度上简化了登录流程路径,减少了重复操作,提高了整体使用效率。同时,该功能也体现了系统在交互细节上的人性化考虑,使用户在首次使用时能够获得更加顺畅和友好的体验。
2.主界面
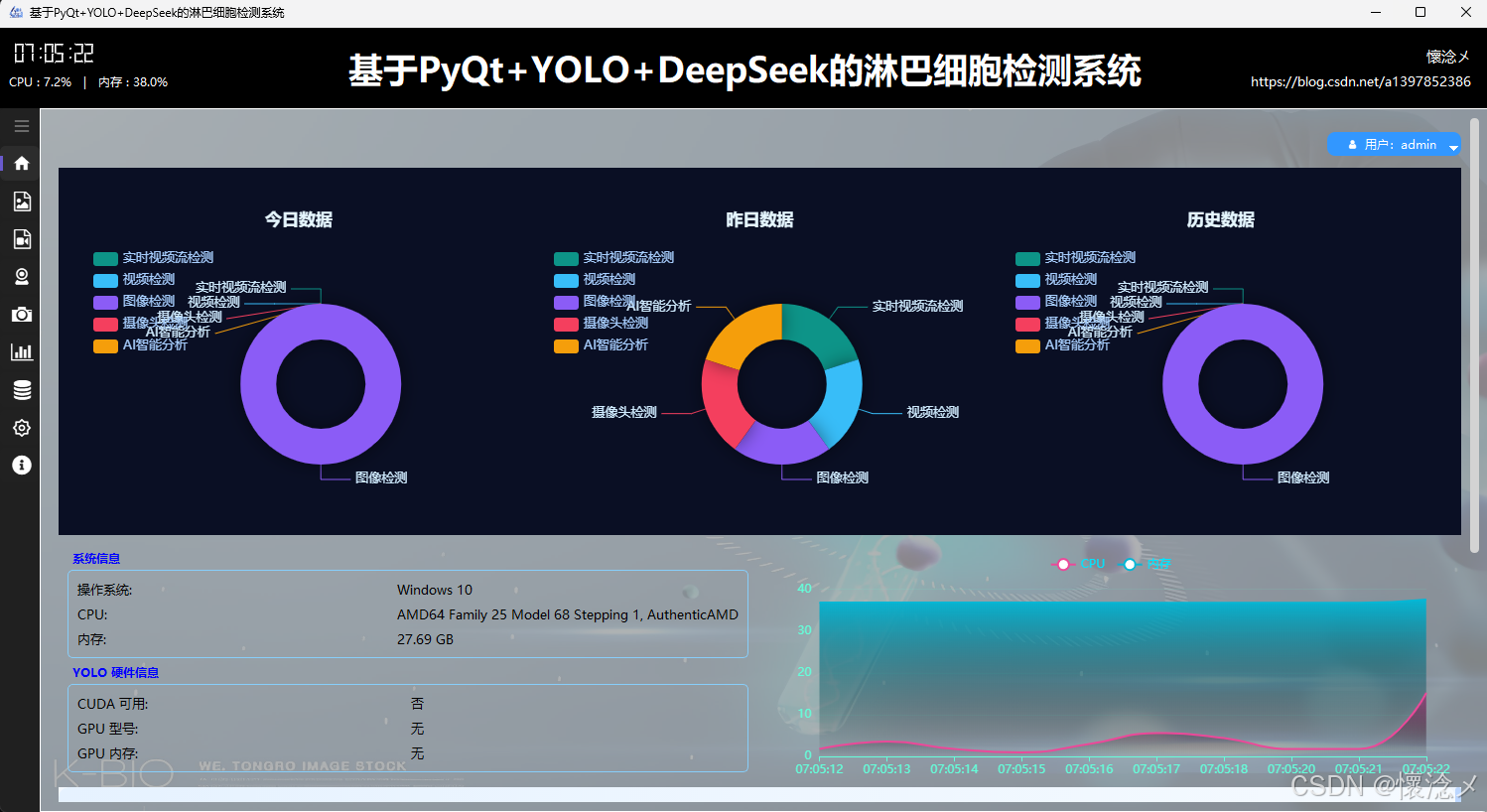
用户通过输入自己的用户名和密码登录到本系统后进入主界面,主界面内容十分丰富,我来一一介绍:首先软件整体是垂直布局,顶部是系统的标题,从左到右依次展示了系统的作者信息、系统名称、当前时间以及CPU内存占用情况,下方为水平布局,左侧是系统的导航区域,我们设计了windows风格支持展开与收缩的内容导航区域,右侧是内容核心区域,通过点击导航按钮切换展示内容,主界面主要展示了以日期为维度统计的数据、用户信息操作按钮、系统信息、系统环境信息以及实时CPU、内存可视化折线图
3.图像检测界面
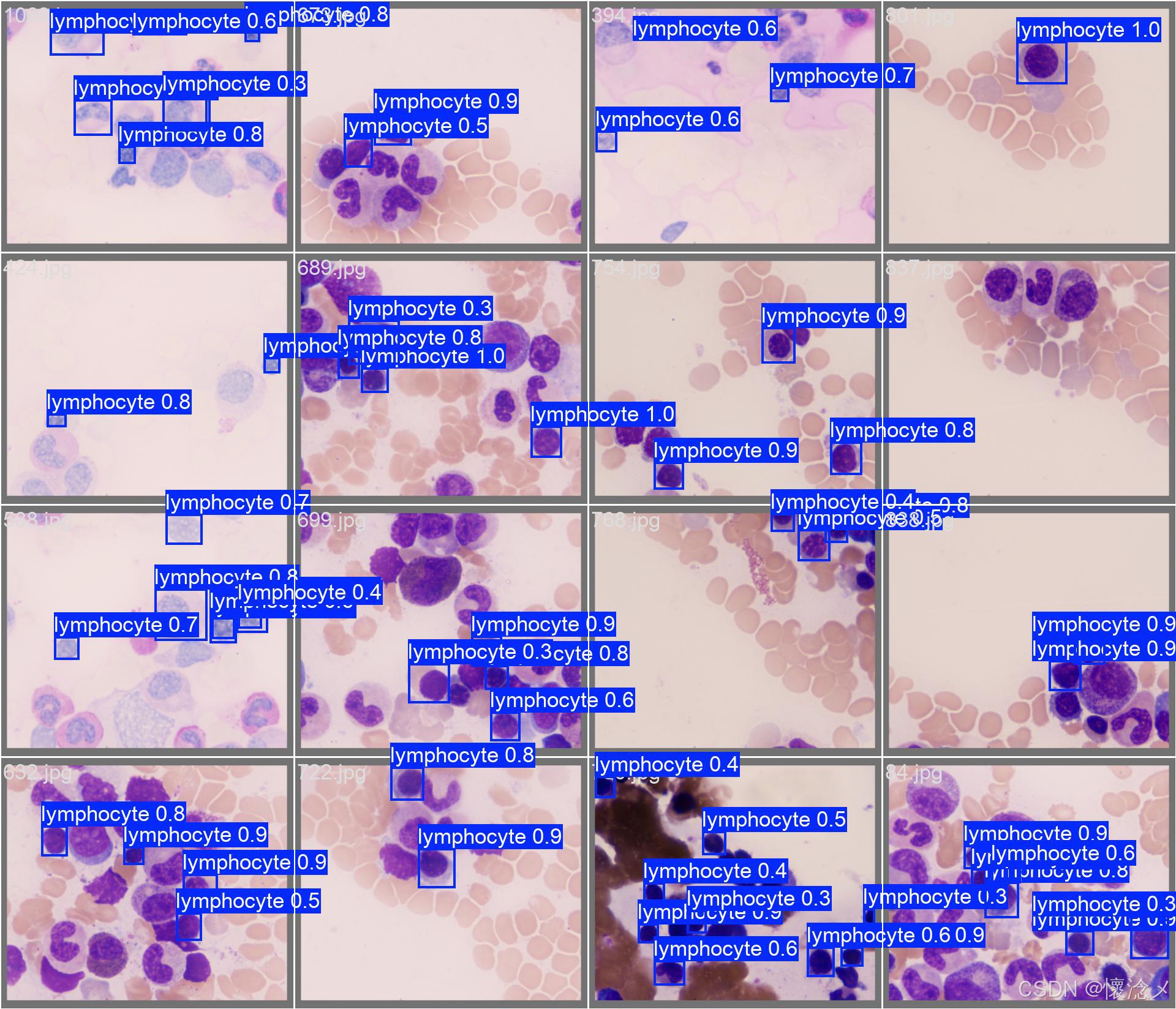
1.检测结果展示
用户通过点击左侧导航栏按钮切换到图像检测界面,在此界面支持选择图像进行输入,用户选择完之后被选择的图像会展示在左侧并且展示图像绝对路径信息,用户可以通过点击右侧的"进行检测"按钮对输入的图像数据进行检测,系统会自动调用YOLOv8相关算法根据指定的参数对输入图像内容进行检测,最后将检测结果展示到右侧,这样用户可以通过比对左右图像的区别得到直观的检测结果,系统自动使用红色边框框选出目标区域并且使用红色文字展示出目标类别以及它的置信度,这些参数和展示效果都可以在设置页面进行详细设置。

2.导出检测结果
我们在界面中专门设置了检测结果展示区域,用于集中呈现系统输出的信息。该区域不仅包含检测目标数量的统计展示,还提供了结构清晰的详细检测结果表格。通过这种方式,用户可以直观地查看每一条检测数据,包括目标类别、置信度以及对应位置信息等内容,从而更全面地了解检测情况。整体布局兼顾信息密度与可读性,使数据展示既完整又不显杂乱。
此外,在检测任务完成之后,界面右侧的三个功能按钮会自动由不可用状态切换为可点击状态,避免用户在未生成结果前进行误操作。这三个按钮分别承担不同的功能,其中"导出结果"按钮允许用户将检测数据保存到本地。系统支持多种导出格式,包括Excel、CSV以及TXT,用户可以根据实际需求灵活选择合适的文件类型,以便后续分析或归档使用。以Excel格式为例,导出的文件通常采用表格结构,对应字段清晰排列,便于用户进一步查看与处理数据。
3.可视化展示
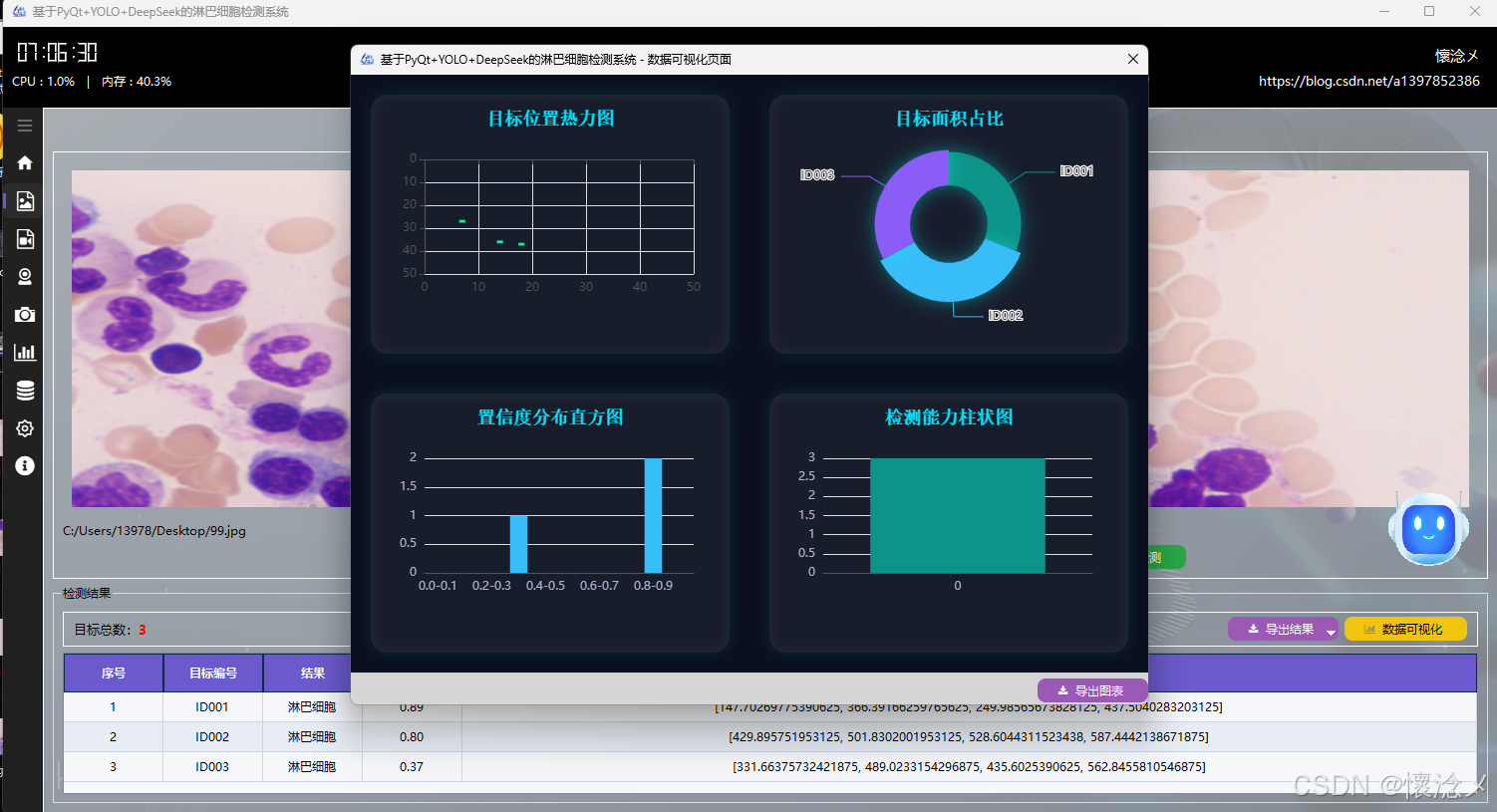
然后就是可视化展示,用户可以点击进行可视化按钮,查看对于本次检测的可视化效果,系统内置了四种可视化效果:分别是:目标位置热力图、目标面积占比、置信度分布直方图、检测能力柱状图,这些图标通过不同维度对当前数据进行了可视化展示,更便于用户理解,这里指的一体的是,支持可视化图表进行导出操作,用户可以点击紫色的导出按钮,对当前的可视化效果图表进行导出,生成一张本地的PNG图像文件。
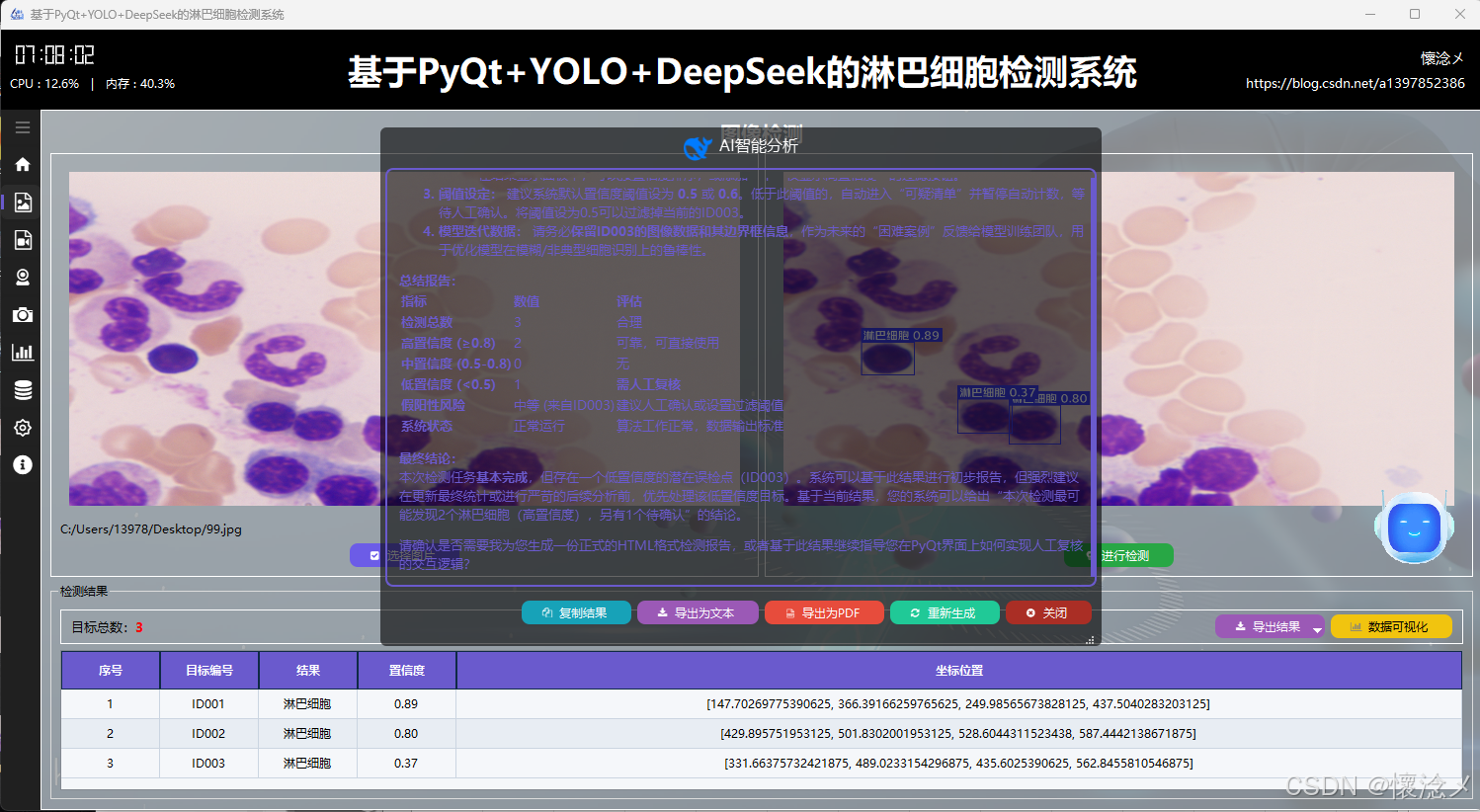
4.AI(DeepSeek)智能分析
在每次检测任务完成并展示检测结果之后,系统为用户提供了一种便捷且智能的交互方式:用户只需点击界面右下角悬浮的机器人图标,即可触发对当前检测结果的深度AI分析功能。系统会自动将本次检测所得到的所有关键信息------包括检测到的目标类别、置信度分数、目标位置坐标、数量统计以及可能存在的异常或遮挡情况等------完整地作为输入传递给后端AI大模型。AI模型接收到这些数据后,会基于其强大的语义理解与逻辑推理能力,对本次检测结果进行多维度的智能评估。评估内容可以包括:检测结果的准确性与可靠性判断、识别结果中可能存在的误检或漏检风险提示、针对当前场景的优化建议、对异常情况的详细解释。这一设计不仅使用户无需手动复制或整理检测数据就能获得即时的专业分析反馈,更重要的是,它实现了一种通用化的AI能力接入机制:检测模块与分析模块实现了解耦,任何检测结果都可以以统一格式传递给AI进行分析,而AI的具体分析逻辑可以根据需要灵活替换、升级或定制。这使得系统在未来可以轻松扩展更多智能功能,例如接入不同的大模型、增加多模态分析能力、实现检测策略的自适应调整等,极大地提升了整个系统的可扩展性与智能化水平。
这里是软件的另外一个核心:AI智能分析,我们的目标检测系统接入了DeepSeek大模型,支持对当前检测结果数据进行AI分析,AI会通过不同维度对当前检测结果进行多角度分析,最后生成检测结果分析报告,用户可以根据这个结果对系统进行调整,不断完善系统功能和目标检测准确度!
在AI分析结束后下方会展示一些按钮,用户可以方便地复制结果、导出文本内容、生成PDF报告、重新生成以及关闭,多重的操作方式给于用户了多种选择!

4.视频检测界面
1.视频文件检测
我们的系统具备对视频内容中淋巴细胞情况的智能检测能力,能够适配多种输入来源,包括本地视频文件、实时视频流以及各类摄像头设备,满足不同应用场景下的使用需求。系统通过对视频画面逐帧解析,利用先进的图像识别算法对画面中的目标进行精准检测,并实时完成标注与可视化展示,使用户能够直观了解检测效果。在性能方面,系统引入了灵活的帧率控制机制,在保证检测精度的同时有效提升视频播放的流畅性,避免出现卡顿或延迟问题,从而提升整体使用体验。
此外,系统界面设计注重用户交互体验,支持左右画面对比显示,用户可以通过肉眼直观对比原始画面与检测结果,快速评估算法表现与准确性。这种对比方式不仅便于结果验证,也有助于进一步优化检测参数。值得一提的是,视频检测界面在功能设计上与图像检测界面保持高度一致,操作逻辑统一,用户无需额外学习成本即可快速上手使用,包括基本的播放控制、暂停、逐帧查看以及检测结果开关等功能。因此,在保证功能完整性的同时,也兼顾了系统的易用性与扩展性。
2.摄像头内容检测
当用户点击"进行检测"按钮后,系统会自动调用本地摄像头设备并完成初始化,随即在界面中实时展示摄像头采集到的画面内容。在视频流持续输入的过程中,系统会同步启动目标检测算法,对当前画面中的目标进行实时识别与标注处理,确保检测结果能够及时反馈给用户。同时,界面采用左右分屏的展示方式,一侧显示原始画面,另一侧显示叠加检测结果的画面,用户可以通过直观对比快速判断检测效果与准确性。这种设计不仅提升了交互体验,也便于用户观察算法在不同场景下的表现情况。至于摄像头画面中是否出现本人,这里就暂时保持低调,不做展示了。
5.模型指标评估
在这个页面中我们通过三个tab展示了模型训练结果评估,分别是:训练结果图、训练结果详情、整体评估,所有的训练结果文件(夹)以及相关作用可见下面图标:
| 文件/文件夹名 | 类型 | 作用说明 |
|---|---|---|
weights/ |
文件夹 | 存放训练得到的模型权重 |
├─ best.pt |
文件 | 在验证集上表现最好的模型(推荐用于推理/部署) |
├─ last.pt |
文件 | 最后一轮训练结束时的模型(包含最新状态) |
results.csv |
文件 | 每个 epoch 的训练与验证指标(loss、mAP、precision 等) |
results.png |
图片 | 训练过程中各类指标变化曲线(loss、mAP 等可视化) |
confusion_matrix.png |
图片 | 混淆矩阵,展示类别预测情况 |
confusion_matrix_normalized.png |
图片 | 归一化后的混淆矩阵 |
PR_curve.png |
图片 | Precision-Recall 曲线 |
P_curve.png |
图片 | Precision 曲线 |
R_curve.png |
图片 | Recall 曲线 |
F1_curve.png |
图片 | F1-score 曲线 |
labels.jpg |
图片 | 数据集中标签分布(类别统计) |
labels_correlogram.jpg |
图片 | 标签相关性图(用于分析数据分布) |
train_batch*.jpg |
图片 | 训练批次样本可视化(带标注框) |
val_batch*.jpg |
图片 | 验证批次样本可视化 |
args.yaml |
文件 | 本次训练的完整参数配置(超参数、路径等) |
hyp.yaml(部分版本) |
文件 | 超参数配置(学习率、增强策略等) |
opt.yaml(旧版本可能有) |
文件 | 训练选项记录(已逐渐被 args.yaml 替代) |
events.out.tfevents.* |
文件 | TensorBoard 日志文件(用于可视化训练过程) |
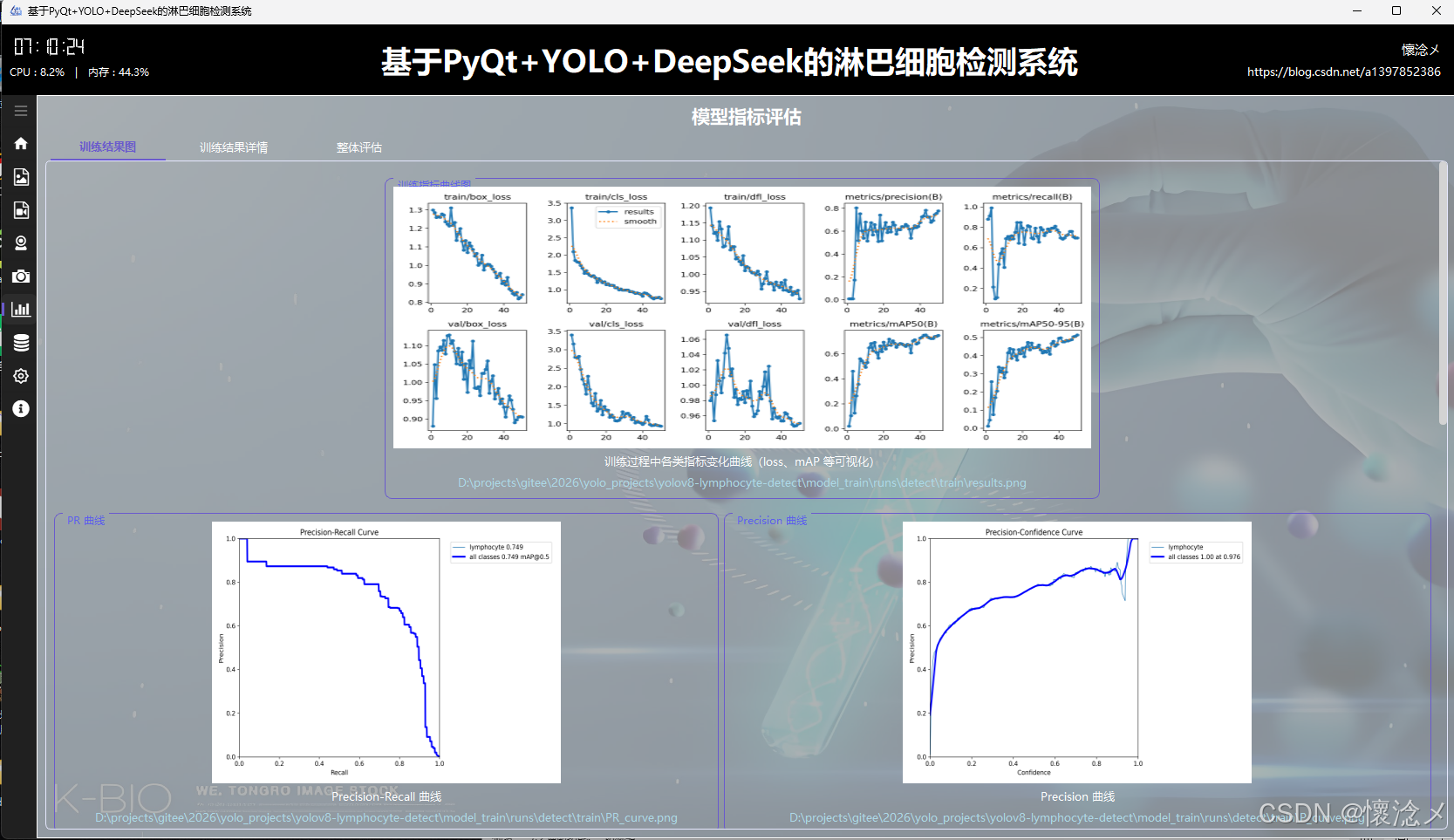
1.训练结果图tab
本系统基于 PyQt5 + YOLOv8 + DeepSeek 构建,实现对淋巴细胞的智能检测与可视化分析。在结果展示模块的该 tab 页面中,集中呈现模型训练与评估阶段生成的多维度指标图像,包括训练损失与性能指标曲线图、PR 曲线、Precision 曲线、Recall 曲线、F1 曲线,以及混淆矩阵与归一化混淆矩阵。同时还提供标签分布图与标签相关性图,用于分析数据集结构与类别关系。
这些图像以直观的方式嵌入界面中,用户无需额外操作即可快速浏览模型整体表现。例如,PR 曲线可反映模型在不同阈值下的查准率与召回率平衡,F1 曲线用于综合衡量模型性能,而混淆矩阵则清晰展示分类正确与误判情况。标签分布与相关性图则有助于判断数据是否均衡及类别间的潜在关联。
在交互设计上,用户可通过点击图像本身,或点击底部提供的图像路径,调用系统默认图像查看工具进行放大查看,提升细节分析能力。每张图像下方均附有简明且专业的说明文案,帮助用户理解其评估意义及应用价值,从而更全面地掌握模型训练效果与优化方向。
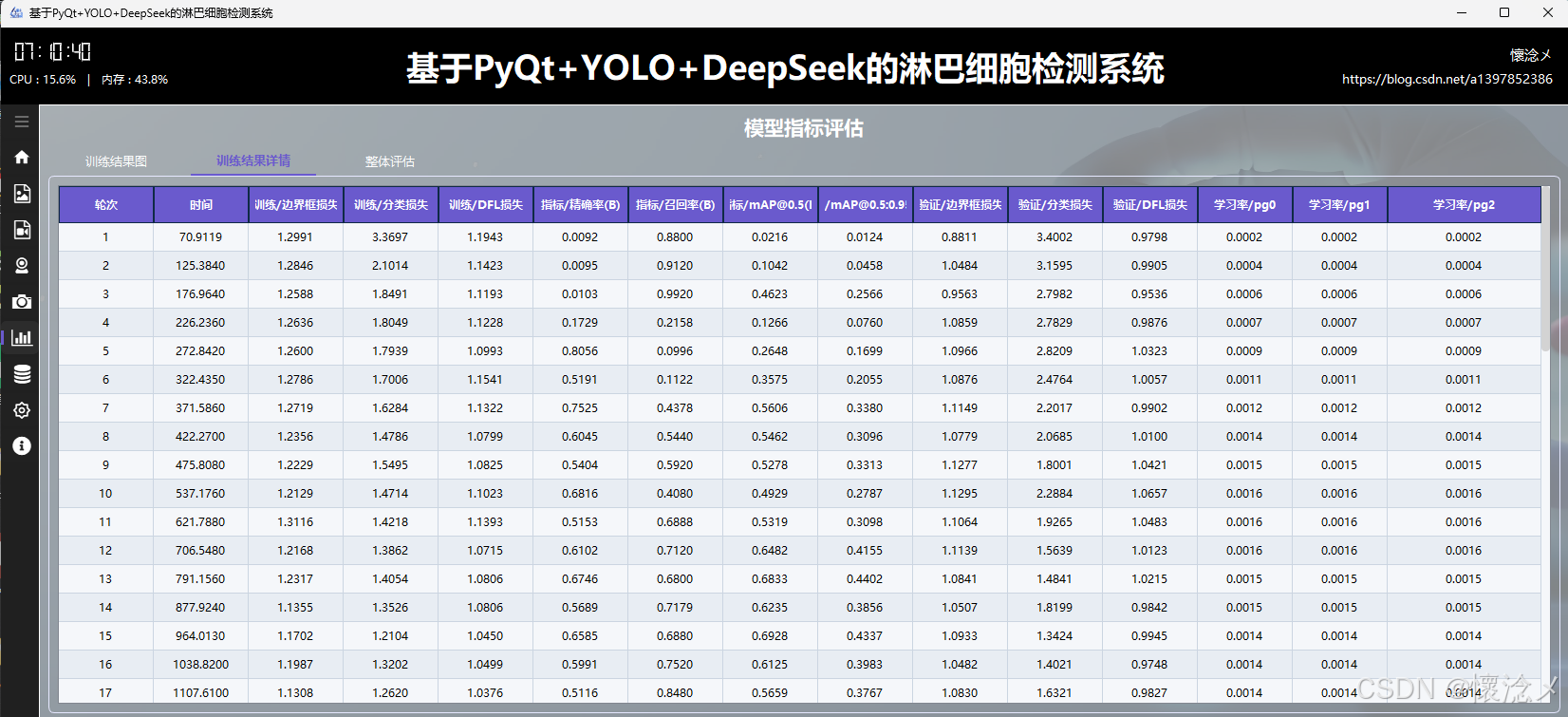
2.训练结果详情tab
在该子 tab 页面中,系统进一步对训练过程中的 results.csv 数据进行了结构化展示。通过将原始训练日志解析为二维表格,完整呈现模型在每一轮(epoch)中的关键指标变化情况,使用户能够以更加清晰、系统化的方式回顾训练全过程。界面设计上采用了简洁清新的视觉风格,并结合横向渐变配色对不同数值区间进行区分,使数据变化趋势更加直观,重点指标一目了然。
表格中包含了完整的字段信息,例如"轮次"和"时间"用于标识训练进度;"训练/边界框损失""训练/分类损失""训练/DFL损失"反映模型在训练阶段的收敛情况;"指标/精确率(B)""指标/召回率(B)"以及"指标/mAP@0.5(B)"和"指标/mAP@0.5:0.95(B)"用于综合评估模型检测性能;对应的"验证/边界框损失""验证/分类损失""验证/DFL损失"则用于判断模型的泛化能力与是否存在过拟合现象。此外,"学习率/pg0""学习率/pg1""学习率/pg2"展示了不同参数组在训练过程中的学习率动态变化,有助于分析优化策略的效果。
在交互体验方面,表格支持滚动浏览与高亮显示,用户可以快速定位关键轮次的数据变化。同时结合渐变色视觉编码,能够快速识别性能提升或波动区间。通过这一模块,用户不仅可以精确掌握模型训练的细节,还能够为后续参数调优与模型改进提供可靠的数据支撑,实现从"可视化观察"到"数据驱动优化"的有效过渡。
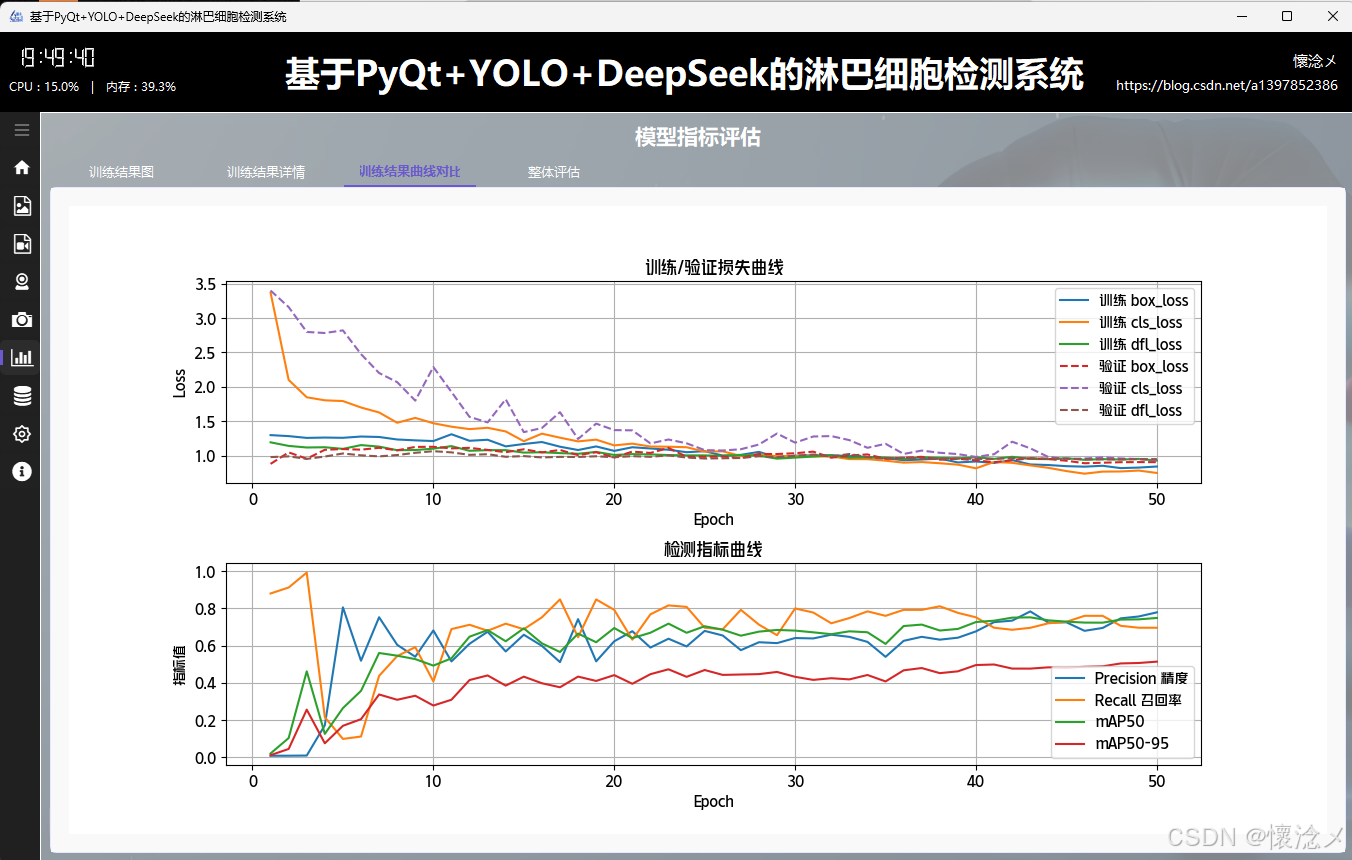
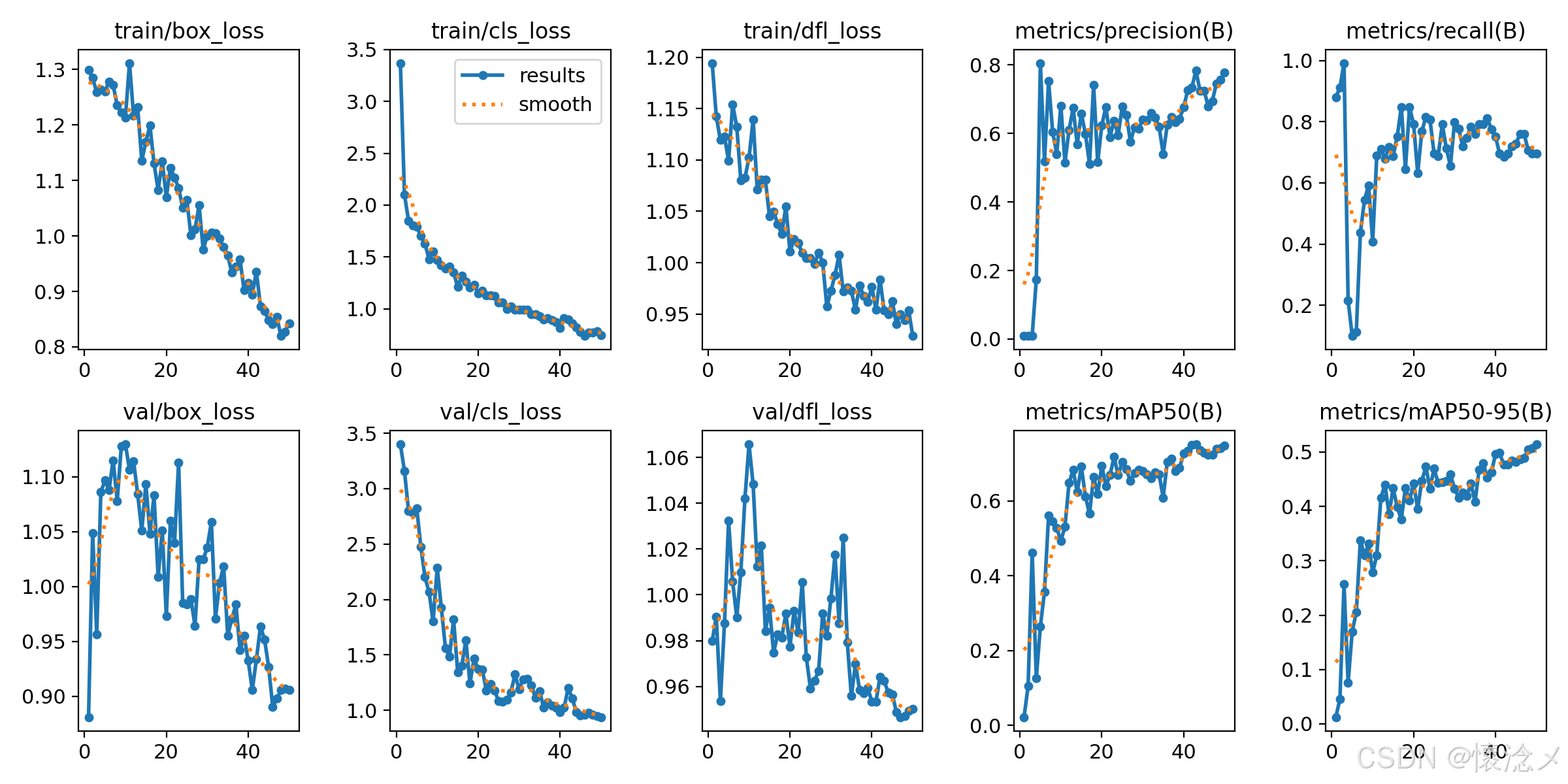
3.训练结果曲线对比tab
这是 YOLOv8 训练流程中用于可视化结果分析的核心界面模块。它的主要内容是自动读取训练生成的 results.csv 文件,并通过 Matplotlib 绘制两组关键曲线:上方子图展示训练/验证过程中的六条损失曲线(包括 box_loss、cls_loss、dfl_loss),下方子图展示精度、召回率、mAP50 和 mAP50-95 四项检测指标的变化趋势。在作用方面,该组件为开发者提供了直观的模型训练监控手段------通过观察损失曲线是否收敛且无严重震荡,可以判断模型是否欠拟合或过拟合;通过观察 mAP 等指标曲线的上升趋势,可以评估模型性能的改善情况。这使得用户无需手动解析 CSV 数据,即可快速完成模型调参、早停判断和训练效果对比,显著提升了 YOLOv8 模型开发的效率。
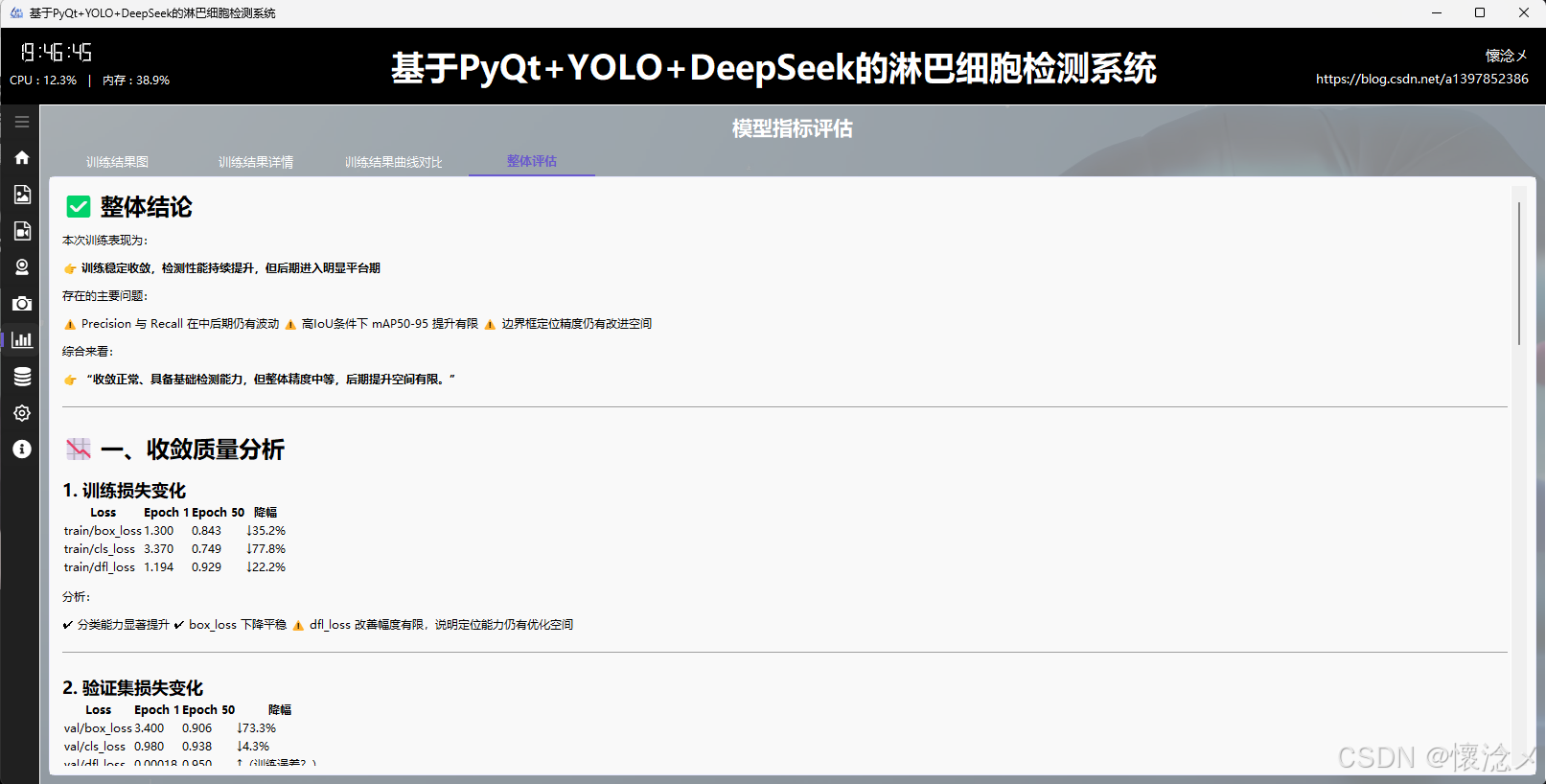
4.整体评估tab
在该页面中,系统对模型训练结果进行了更高层次的综合评估与总结分析。通过对关键指标进行统一整理与可视化表达,结合细致的颜色编码机制,将不同阶段的性能变化趋势清晰呈现出来,使用户能够从整体上把握模型训练的动态过程,而不仅仅停留在单一指标的观察。
在评估维度上,系统重点围绕多个核心方面展开。首先是收敛质量 ,通过训练与验证损失曲线的变化趋势,判断模型是否稳定收敛以及是否存在震荡或过早收敛的问题;其次是检测性能 ,结合 Precision、Recall 以及 F1 等指标,分析模型在目标检测任务中的准确性与覆盖能力;在泛化能力 方面,通过对比训练集与验证集指标差异,评估模型是否存在过拟合或欠拟合现象;同时利用 mAP 综合表现 (包括 mAP@0.5 与 mAP@0.5:0.95)对模型整体检测能力进行量化衡量,从多阈值角度反映检测精度的稳定性。
此外,系统还对学习率调度策略 进行了分析,通过展示不同参数组学习率随训练轮次的变化情况,帮助用户判断当前优化策略是否合理,以及是否需要进一步调整以提升训练效率或稳定性。所有评估结果均通过分层颜色与趋势变化进行突出展示,使关键结论更加直观易读。
在页面的最后部分,系统基于上述多维度分析结果,自动生成整体评估结论,并从工程应用视角给出总结性判断。例如模型是否已达到可部署标准、是否需要继续训练或优化数据集、以及在实际口罩检测场景中的预期表现。这种从数据到结论的完整闭环设计,有助于用户快速完成模型质量评估,并为后续系统部署与迭代提供明确依据。
6.数据查看界面
"历史数据"页面是系统中用于集中查看与管理过往记录的重要模块,整体设计清晰直观,通过两个独立的 Tab 实现不同维度数据的分类展示,方便用户快速切换与定位信息。
总体而言,"历史数据"页面通过清晰的结构划分与完善的功能设计,实现了检测记录与用户信息的高效管理与展示,为系统的运维与决策提供了有力支持。
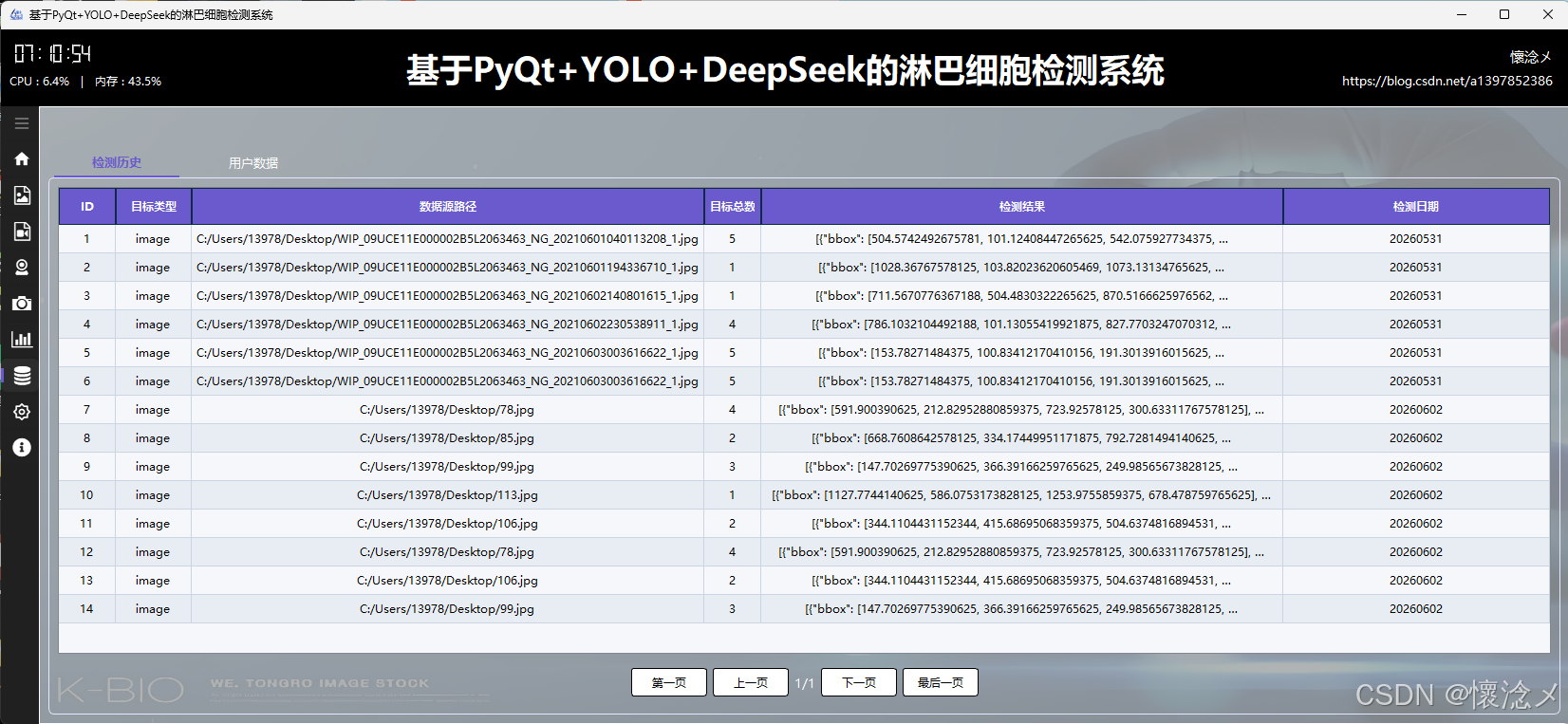
1.历史数据tab
在"检测历史数据"Tab中,页面以结构化表格的形式呈现所有检测相关记录。每一条数据都包含关键字段:数据库ID用于唯一标识记录,目标类型用于说明检测对象的类别,检测结果用于反馈检测结论,检测日期则记录具体的时间信息。该模块不仅实现了数据的完整展示,还特别强化了可用性与交互体验------支持分页浏览功能,用户可以根据数据量分批查看内容,同时提供"跳转到第一页"、"上一页"、"下一页"以及"最后一页"等操作按钮,便于在大量数据中高效导航。这种分页机制有效避免了数据过载带来的性能问题,同时也提升了界面的响应速度和用户体验。
2.用户数据tab
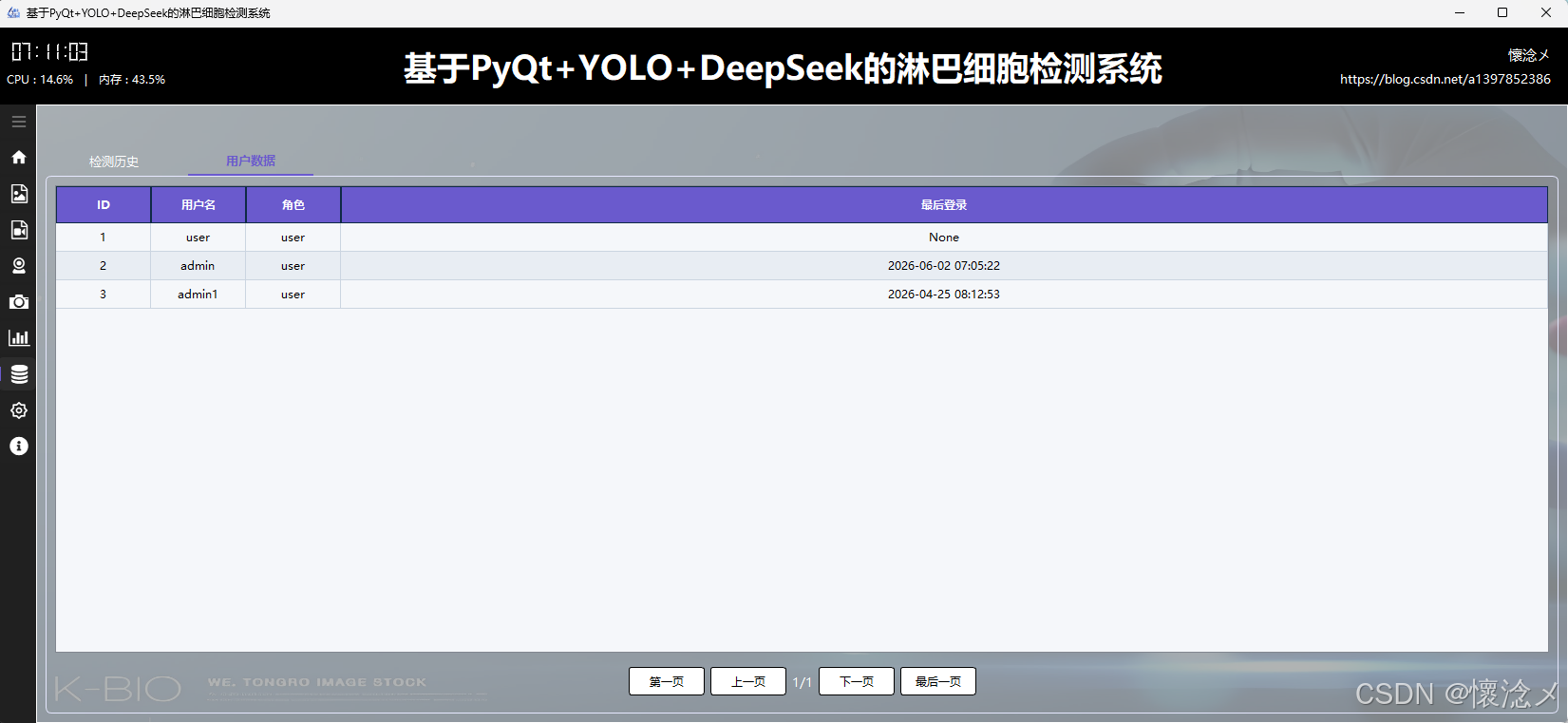
其次,在"用户数据"Tab中,系统汇总展示了所有已注册用户的信息,是一个用于用户管理与审计的重要视图。页面同样采用表格形式,列出了数据库ID、用户名、用户角色以及最后登录日期时间等核心字段。通过这些信息,管理员可以快速了解系统用户的基本情况及活跃状态,例如判断某些用户是否长期未登录,从而进行进一步管理操作。该部分数据覆盖范围全面,确保系统管理者能够掌握整体用户分布与使用情况。
6.系统设置界面
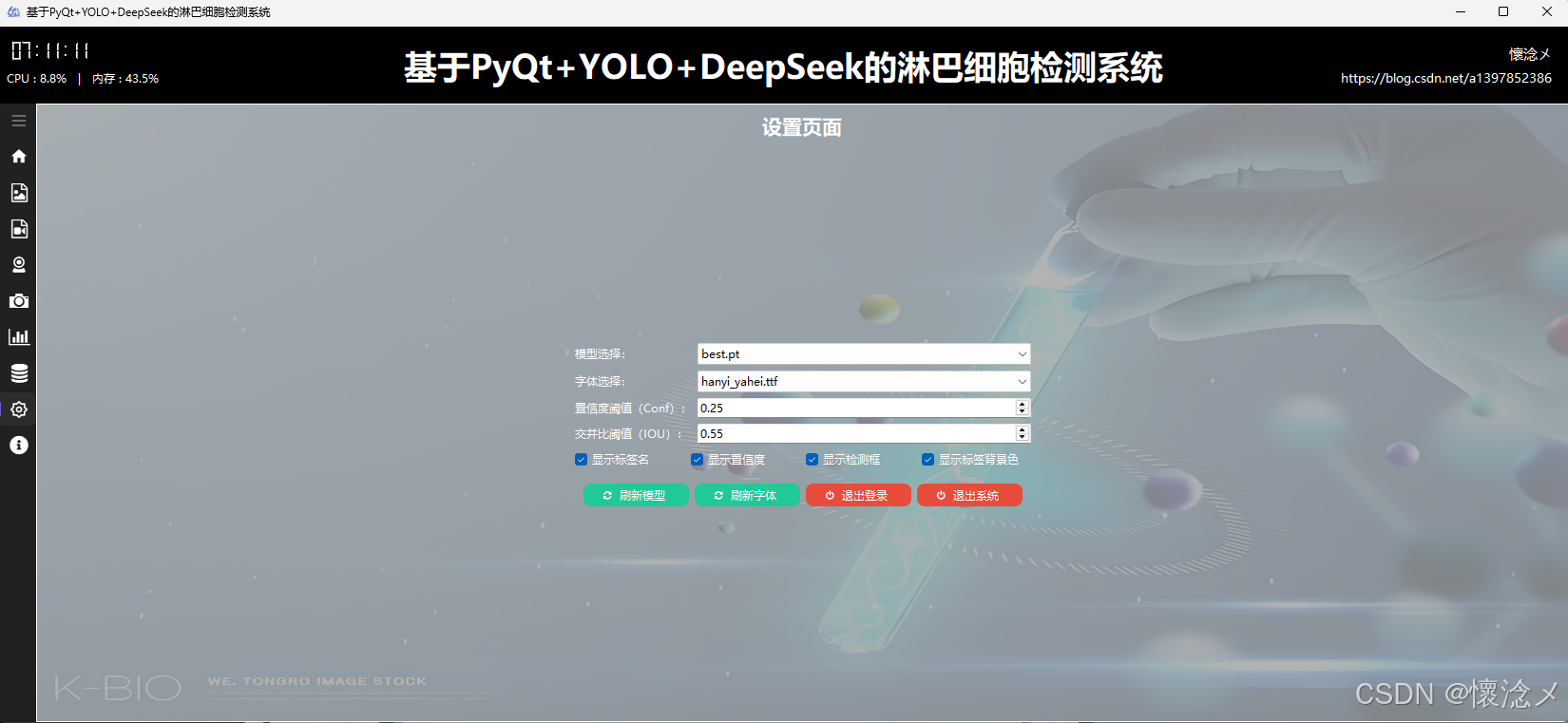
我们的系统是支持简单的参数设置的,具体可以设置目标检测模型、置信度阈值(Conf)、交并比阈值(IOU)、还有一些检测结果控制参数,比如检测框展示、目标类别展示、目标置信度展示,用户可以点击绿色的刷新按钮刷新可用模型,亦可通过点击退出按钮退出系统或者退出登录,本设置页面实现了目标检测参数的灵活配置!
7.关于软件界面
我们使用富文本html的形式展示了软件相关的信息,包括系统用到的相关技术,对于二维的数据使用二维表进行了展示,最底部放置了四个按钮,分别是:关于YOLO、关于软件、关于作者、关于QT,点击之后都会弹出对应的信息提示框,这个页面的作用是让用户更多的了解软件和创作者信息,跨过技术的鸿沟!

四.数据集
本系统为"一款基于PyQt+YOLO+DeepSeek的淋巴细胞系统",用以检测输入数据源是否存在淋巴细胞。
本项目采用基于YOLO的深度学习目标检测模型,因此对数据图像的质量和规范性具有一定要求。系统支持JPEG、PNG、BMP、TIFF等常见图像格式,同时兼容MP4、AVI等视频文件以及摄像头实时视频流输入。为了保证淋巴细胞检测的准确性,采集图像应具有较高分辨率,建议不低于1024×1024像素,确保细胞核、胞质边缘及细胞形态特征清晰可见。图像应避免出现严重模糊、失焦、过曝、欠曝以及明显噪声干扰等问题,以减少误检和漏检现象。在病理切片场景下,建议采用统一的染色标准(如HE染色)和显微镜采集条件,保持样本间颜色、亮度和对比度的一致性,从而提高模型的泛化能力和检测稳定性。训练数据需要覆盖不同放大倍率、不同组织区域以及不同密度分布的淋巴细胞样本,并对每个目标进行准确标注,标注内容包括细胞位置边界框和类别信息,以保证模型能够学习到丰富的细胞特征。此外,数据集中应包含一定数量的复杂背景、细胞重叠及染色差异样本,以增强模型在实际应用环境中的鲁棒性和适应能力,为图像、视频及实时视频流中的淋巴细胞检测提供可靠的数据基础。
1.数据准备
本系统附带1438张不同图像和1438个数据标注文件,大家可以根据自己的情况自行训练数据自己的模型!
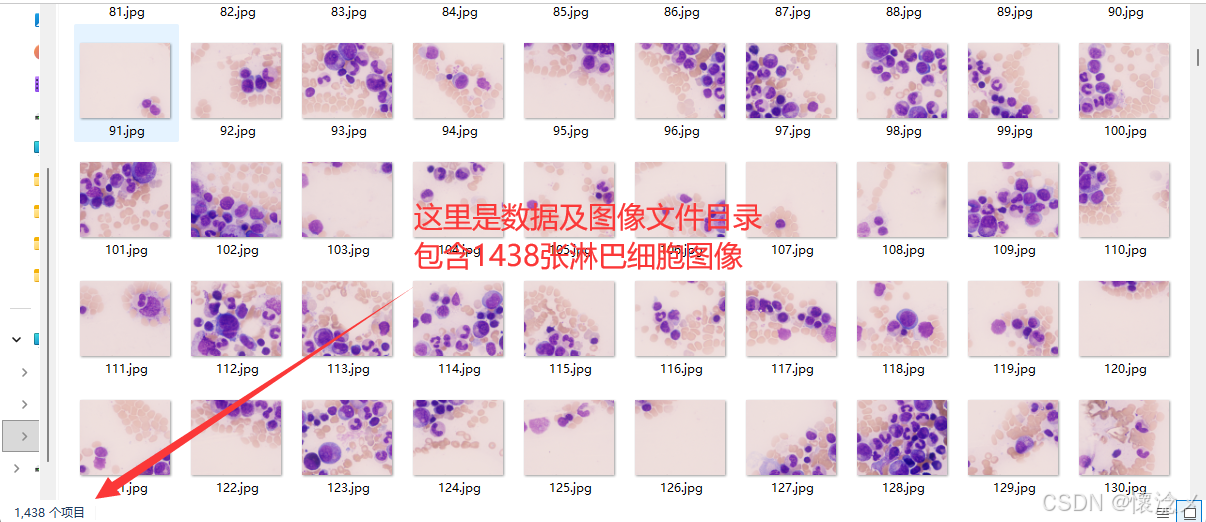
上图是数据标注文件,格式为txt,下面我们提供了相关脚本支持将xml转为YOLO的txt格式
我们使用TXT的格式存储数据标注文件,单数据标注文件内容如下:
bash
<annotation>
<folder>IMAGES</folder>
<filename>2.jpg</filename>
<path>D:\CELL\IMAGES\2.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>2448</width>
<height>2048</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>cell</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1774</xmin>
<ymin>287</ymin>
<xmax>1970</xmax>
<ymax>456</ymax>
</bndbox>
</object>
<object>
<name>cell</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>2053</xmin>
<ymin>117</ymin>
<xmax>2290</xmax>
<ymax>371</ymax>
</bndbox>
</object>
<object>
<name>cell</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>2151</xmin>
<ymin>1395</ymin>
<xmax>2324</xmax>
<ymax>1576</ymax>
</bndbox>
</object>
<object>
<name>cell</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>451</xmin>
<ymin>1126</ymin>
<xmax>694</xmax>
<ymax>1376</ymax>
</bndbox>
</object>
<object>
<name>cell</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>555</xmin>
<ymin>897</ymin>
<xmax>824</xmax>
<ymax>1119</ymax>
</bndbox>
</object>
</annotation>2.数据集处理
1.数据集标注文件类型转换
直接使用VOC格式的数据标注文件进行训练是不行的,需要我们将xml转成txt文件,
这段代码的作用是将指定文件夹中的 Pascal VOC 格式的 XML 标注文件批量转换为 YOLO 格式的 TXT 标注文件。它会先遍历所有 XML 自动统计有效类别并生成类别到 ID 的映射表,忽略类别名为 "not" 的标注,然后读取对应图片的尺寸,将 XML 中的边界框坐标转换为 YOLO 的归一化格式(class_id x_center y_center width height),最后将生成的 TXT 文件保存到指定目录中,便于直接用于 YOLO 训练。
大家首先执行step1_voc_to_txt.py
python
import os
import xml.etree.ElementTree as ET
from PIL import Image
from train_conf import BASE_DIR
# 原始路径
xml_dir = BASE_DIR + r"annotation"
img_dir = BASE_DIR + r"images"
# YOLO标签输出路径
yolo_txt_dir = BASE_DIR + r"labels"
os.makedirs(yolo_txt_dir, exist_ok=True)
# ===== 自动生成类别映射 =====
class_map = {}
next_class_id = 0
# 支持的图像扩展
img_exts = [".jpg", ".jpeg", ".png", ".bmp"]
# 遍历 XML 文件
for xml_file in os.listdir(xml_dir):
if not xml_file.endswith(".xml"):
continue
xml_path = os.path.join(xml_dir, xml_file)
tree = ET.parse(xml_path)
root = tree.getroot()
# --- 以 XML 文件名匹配图像 ---
base = os.path.splitext(xml_file)[0]
img_path = None
for ext in img_exts:
candidate = os.path.join(img_dir, base + ext)
if os.path.exists(candidate):
img_path = candidate
break
if img_path is None:
print(f"Warning: 图像文件与 {xml_file} 同名的图片不存在,跳过")
continue
# 获取图像尺寸
try:
with Image.open(img_path) as img:
w, h = img.size
except Exception as e:
print(f"无法打开图片 {img_path}: {e}")
continue
txt_lines = []
# 遍历目标
for obj in root.findall("object"):
name_node = obj.find("name")
if name_node is None:
continue
label = name_node.text.strip()
# === 自动分配 class_id ===
if label not in class_map:
class_map[label] = next_class_id
next_class_id += 1
class_id = class_map[label]
bndbox = obj.find("bndbox")
if bndbox is None:
continue
xmin = float(bndbox.find("xmin").text)
ymin = float(bndbox.find("ymin").text)
xmax = float(bndbox.find("xmax").text)
ymax = float(bndbox.find("ymax").text)
x_center = ((xmin + xmax) / 2) / w
y_center = ((ymin + ymax) / 2) / h
box_width = (xmax - xmin) / w
box_height = (ymax - ymin) / h
txt_lines.append(
f"{class_id} {x_center:.6f} {y_center:.6f} {box_width:.6f} {box_height:.6f}"
)
# 保存 YOLO txt
txt_file_path = os.path.join(yolo_txt_dir, base + ".txt")
with open(txt_file_path, "w") as f:
f.write("\n".join(txt_lines))
# ===== 输出类别映射 =====
print("\n类别映射 class_map:")
for k, v in class_map.items():
print(f"{v}: {k}")
print(f"\n转换完成!YOLO TXT 文件已保存在: {yolo_txt_dir}")2.数据集拆分
YOLO 推荐训练集和测试集按 8:2 划分,主要是因为目标检测对样本量非常依赖,需要尽可能多的训练数据来学习特征,同时又必须保留足够的独立测试数据来评估模型的真实泛化能力。8:2 被证明在"训练数据够多"与"测试评估足够稳定"之间取得了较好平衡,因此成为默认且通用的实践比例。
这个脚本的作用是从已有的图片和 YOLO 标注文件中随机抽取 200 张图片,并将它们按照训练集和验证集的比例进行划分,然后将对应的图片和 TXT 标注文件复制到新的数据集目录中,方便直接用于训练 YOLO 模型。脚本会先创建训练集和验证集的图片、标签子目录,然后随机选择 指定数量的张图片,其中 五分之一作为验证集,其余 五分之四作为训练集,复制过程中会保证每张图片对应的标注文件也被同步复制,如果标注文件不存在,会生成一个空的 TXT 文件,以保持文件结构完整。运行完成后,新的数据集就整理好了,可以直接用于训练和验证。。最终会在目标目录下生成:

执行脚本step2_auto_part.py
bash
import os
import random
import shutil
from train_conf import BASE_DIR
# 原始数据路径
img_dir = BASE_DIR + "images"
label_dir = BASE_DIR + "labels"
# 新数据集路径
dataset_dir = BASE_DIR + "dataset"
MAX_IMAGE_COUNT = 200
SP_COUNT = int(MAX_IMAGE_COUNT * 0.2)
train_img_dir = os.path.join(dataset_dir, "train", "images")
train_label_dir = os.path.join(dataset_dir, "train", "labels")
val_img_dir = os.path.join(dataset_dir, "val", "images")
val_label_dir = os.path.join(dataset_dir, "val", "labels")
# 创建目录
for dir_path in [train_img_dir, train_label_dir, val_img_dir, val_label_dir]:
os.makedirs(dir_path, exist_ok=True)
# 获取所有图片文件
all_images = [f for f in os.listdir(img_dir) if f.lower().endswith((".jpg", ".png", ".jpeg"))]
# 随机抽取MAX_IMAGE_COUNT张
if len(all_images) < MAX_IMAGE_COUNT:
raise ValueError(f"图片数量不足MAX_IMAGE_COUNT张,当前数量: {len(all_images)}")
selected_images = random.sample(all_images, MAX_IMAGE_COUNT)
# 分割训练集和验证集
random.shuffle(selected_images)
val_images = selected_images[:SP_COUNT]
train_images = selected_images[SP_COUNT:]
def copy_files(image_list, target_img_dir, target_label_dir):
for img_file in image_list:
# 复制图片
src_img_path = os.path.join(img_dir, img_file)
dst_img_path = os.path.join(target_img_dir, img_file)
shutil.copy(src_img_path, dst_img_path)
# 对应的txt
label_file = os.path.splitext(img_file)[0] + ".txt"
src_label_path = os.path.join(label_dir, label_file)
if os.path.exists(src_label_path):
dst_label_path = os.path.join(target_label_dir, label_file)
shutil.copy(src_label_path, dst_label_path)
else:
# 如果没有对应txt文件,创建一个空文件
open(os.path.join(target_label_dir, label_file), "w").close()
# 复制训练集
copy_files(train_images, train_img_dir, train_label_dir)
# 复制验证集
copy_files(val_images, val_img_dir, val_label_dir)
print(f"随机抽取完成!训练集: {len(train_images)} 张,验证集: {len(val_images)} 张")
print(f"数据集路径: {dataset_dir}")3.模型训练
数据集准备好之后就可以开始模型训练了,我们首先准备一个训练的配置文件,比如说是data.yaml
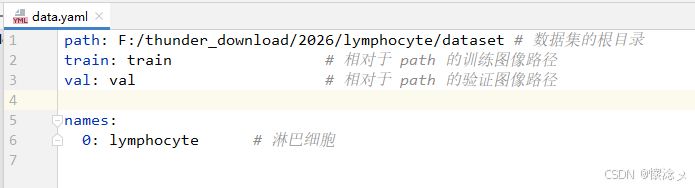
然后就可以开始模型训练了,直接执行我们准备好的train.bat文件,内容就是下面的内容
bash
yolo task=detect mode=train model=../data/model/yolov8n.pt data=./data.yaml epochs=30 imgsz=640 batch=16 lr0=0.01用户亦可执行step3_train_model.py脚本进行模型训练
python
from ultralytics import YOLO
def main():
# 加载模型
model = YOLO("../data/model/yolov8n.pt")
# 开始训练
model.train(
data="./data.yaml", # 数据集配置
epochs=50, # 训练轮数
imgsz=640, # 输入尺寸
batch=16, # batch size
lr0=0.01, # 初始学习率
task="detect" # 任务类型
)
if __name__ == "__main__":
main()然后模型就开始训练了
这里我贴一些训练验证结果截图
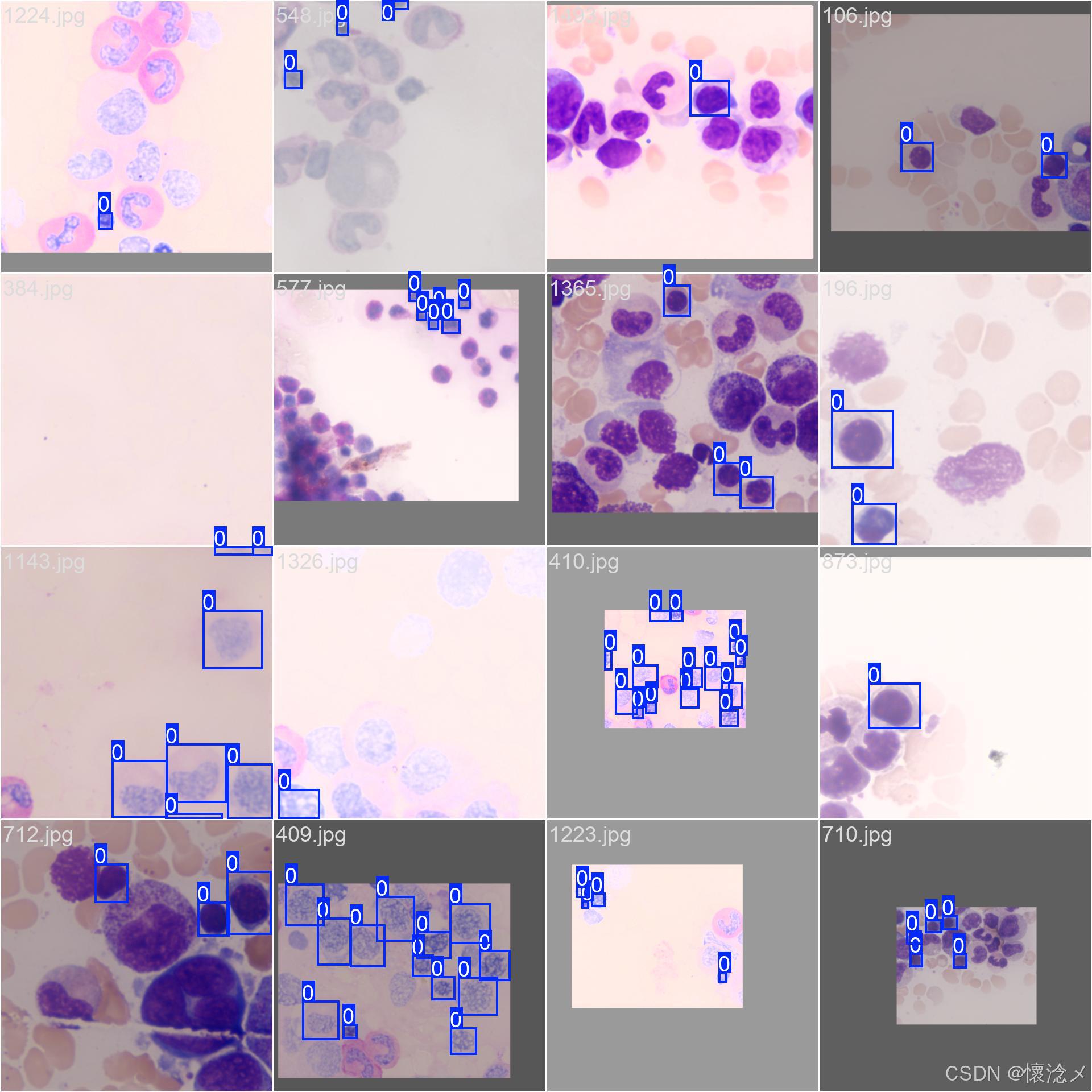

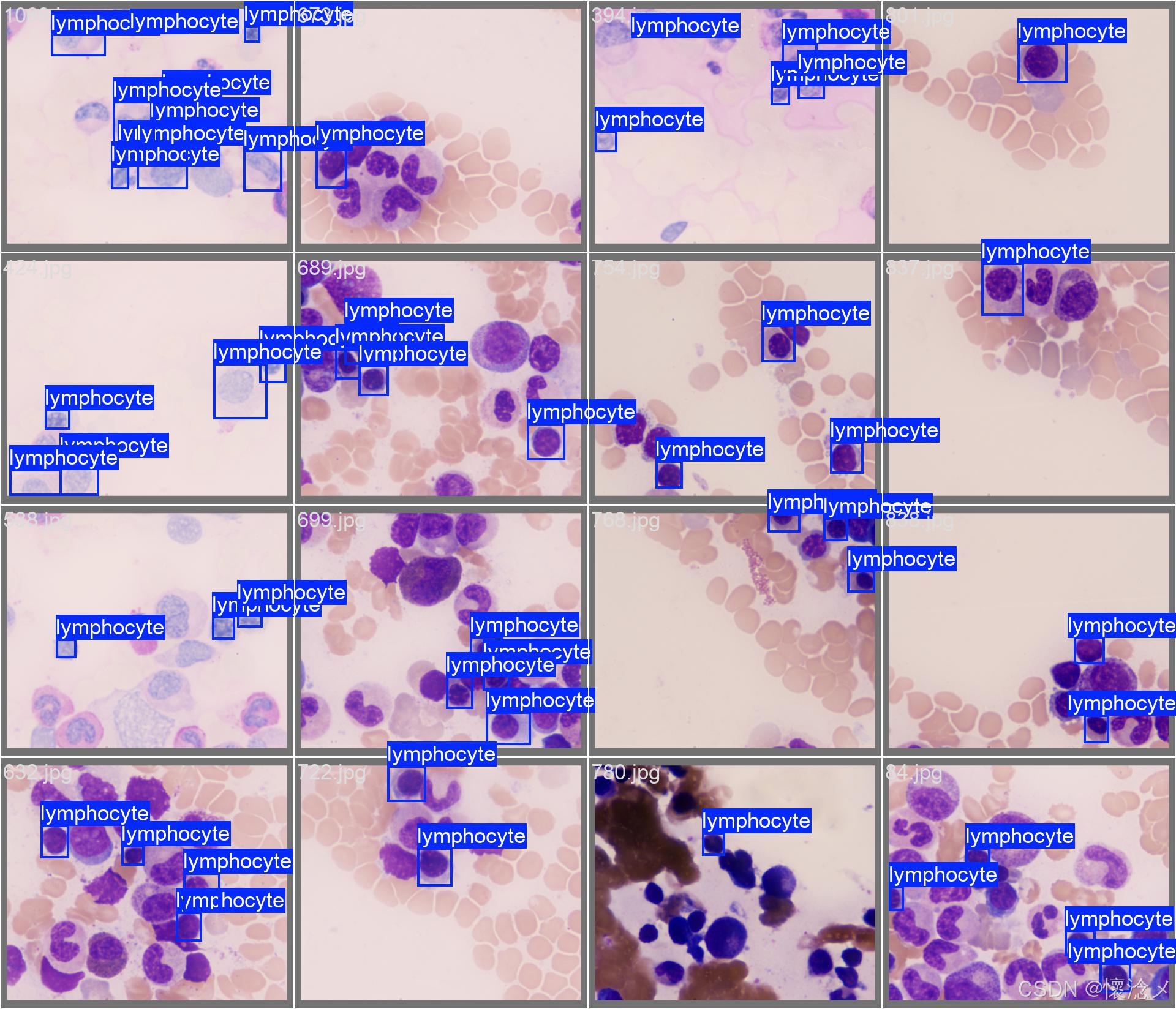
最后的results.png见下图,训练效果还是可以的!
bash
# 🚀 一、整体表现亮点
👉 本次训练整体呈现出:
> **稳定收敛 + 持续学习 + 无明显训练异常**
说明模型训练过程是健康的。
---
# 📉 二、Loss表现优秀
## ✅ 1. Train Loss稳定下降
| 指标 | 下降幅度 |
| -------- | ----- |
| box_loss | ↓约41% |
| cls_loss | ↓约64% |
| dfl_loss | ↓约38% |
✔ 分类学习能力持续增强
✔ 回归能力持续优化
✔ 没有震荡或发散
---
## ✅ 2. 验证集Loss同步优化
| 指标 | 表现 |
| ------------ | ---- |
| val_cls_loss | 明显下降 |
| val_box_loss | 整体稳定 |
| val_dfl_loss | 保持平稳 |
✔ 训练与验证趋势一致
✔ 无明显过拟合迹象
✔ 泛化学习是有效的
---
# 🚀 三、检测能力持续提升
## 📈 mAP50(核心指标)
* 从接近 0 → 稳定提升至 ~0.08+
* 训练过程中持续增长
✔ 模型成功学习目标特征
✔ 检测能力逐步建立
✔ 存在明确有效学习信号
---
## 📈 mAP50-95
* 从接近 0 → 提升至 ~0.027+
✔ 高IoU条件下仍有提升
✔ 框定位能力在逐步形成
✔ 复杂检测能力正在建立中
---
# 🎯 四、Precision / Recall 正向趋势
✔ Precision逐步提升至 ~0.19
✔ Recall逐步提升至 ~0.17
✔ 二者保持同步增长趋势
说明:
* ✔ 模型开始具备识别能力
* ✔ 检测与漏检问题在持续改善
* ✔ 分类边界逐步清晰
---
# ⚙️ 五、训练过程非常稳定
✔ 学习率策略正常
✔ 无训练崩溃或震荡
✔ loss曲线平滑下降
✔ 各指标逐步改善
👉 说明训练配置是合理的
---
# 🧠 六、学习能力总结
本次模型展现出:
✔ 良好的特征学习能力
✔ 稳定的收敛过程
✔ 持续的性能提升趋势
✔ 正向的检测能力演化
---
# 🏁 最终总结(只看优点)
👉 本次训练的核心优点是:
* ✔ 训练过程稳定可靠
* ✔ Loss持续显著下降
* ✔ mAP从0逐步提升
* ✔ Precision/Recall持续增长
* ✔ 无明显过拟合
* ✔ 模型具备持续优化潜力五.问题统一回答
在这个章节我将统一回答朋友们比较关心的问题
1.数据库
我们使用sqlite3作为数据存储数据库,数据库中包含两个数据表,用于存储我们的核心数据
1.users用户信息表
数据表结构
sql
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT NOT NULL UNIQUE,
password TEXT NOT NULL,
last_login TEXT,
role TEXT NOT NULL
)| 字段名 | 类型 | 作用 |
|---|---|---|
| id | INTEGER | 用户唯一ID(自增主键) |
| username | TEXT | 用户名(唯一) |
| password | TEXT | 用户密码 |
| last_login | TEXT | 最后登录时间 |
| role | TEXT | 用户角色(如:admin/user) |
users 表用途
这个表主要用于:
用户注册
用户登录认证
用户权限管理
登录时间记录
2.detect_history 检测历史表
表结构
sql
CREATE TABLE IF NOT EXISTS detect_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
type VARCHAR(50),
path TEXT,
total VARCHAR(50),
detail TEXT,
detect_date VARCHAR(50)
)| 函数名 | 作用 | 操作对象 |
|---|---|---|
__init__() |
初始化数据库对象 | 整体系统 |
check_check_and_create() |
创建数据库目录 | 文件系统 |
execute_sql() |
执行SQL语句 | 所有表 |
create_tables() |
创建数据库表 | users / detect_history |
register_user() |
用户注册 | users |
get_user_by_credentials() |
用户登录验证 | users |
init_default_user() |
初始化默认账号 | users |
insert_detect_history() |
插入检测历史 | detect_history |
query_users() |
分页查询用户 | users |
query_detect_history() |
分页查询检测记录 | detect_history |
clear_detect_history() |
清空检测历史 | detect_history |
这个表用于保存:
AI检测结果
图像检测历史
视频分析结果
文件识别记录
2.如何修改文案
全局搜索目标文案,如果搜不到就删减关键字直到搜索到目标关键字
这里以主界面右上角的作者信息来演示,去掉此文案
在线免直接进行字符串替换即可
3.如何修改图片资源
用户可能需要更换背景图或者登录界面logo图,这里以修改背景图为例:在src/resource/images找到对应文件,找到自己准备好的图片(最好是同样扩展名),最后执行script/create_qrc.py脚本,完成资源替换。
4.如何更换API Key
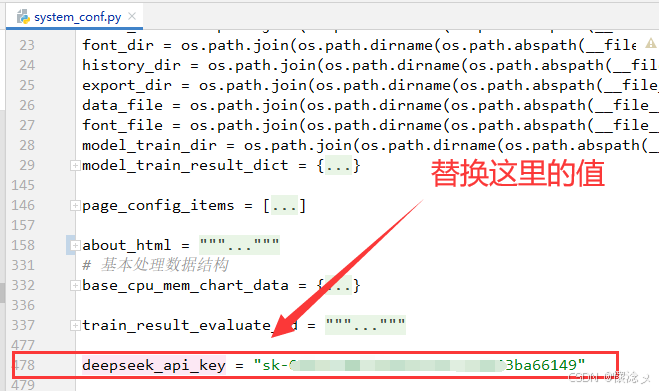
我们的系统是支持AI分析的,用户要更换API Key的话,可以找到src/conf/system_conf.py的deepseek_api_key ,替换此变量的值即可。
5.运行最佳分辨率
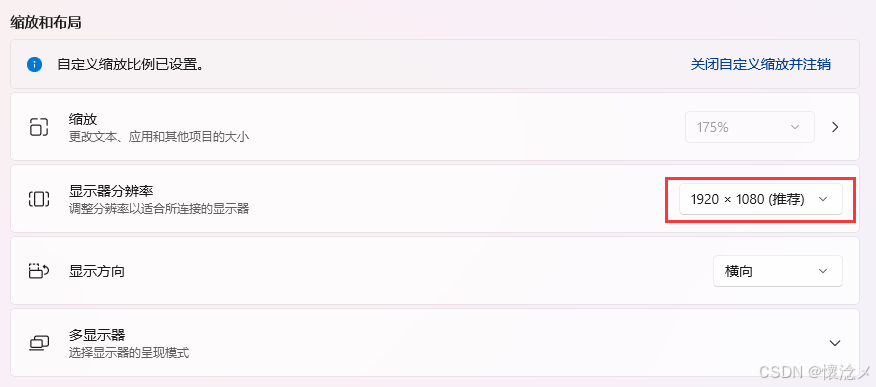
软件是在python3.8的windows环境下开发的,推荐的分辨率为1920X1080
6.如何隐藏部分功能
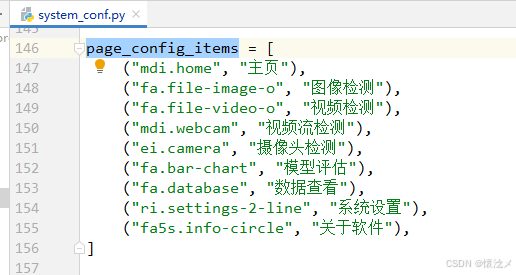
我们的软件包含多个界面,通过左侧导航栏控制右侧内容页面展示,用户如果需要隐藏功能,可以这样操作:
找到src/conf/system_conf.py的page_config_items 变量,按照情况注释或者删除,即可隐藏指定的页面
7.软件系统架构图
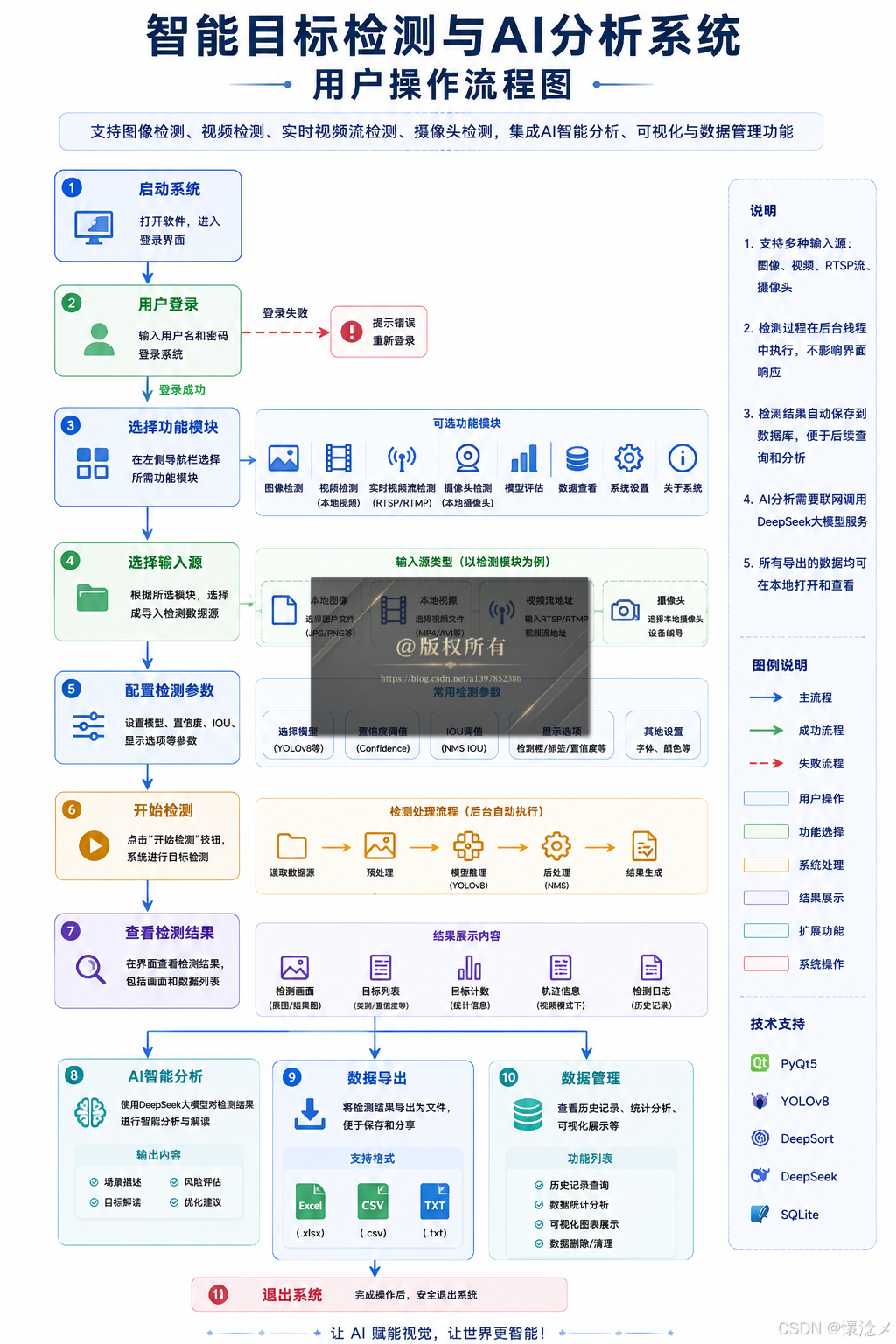
我们绘制了软件架构图,详细地展示了软件系统层级架构以及数据流转,拿到项目代码的朋友,可以免费获取无水印版本系统架构图哦~
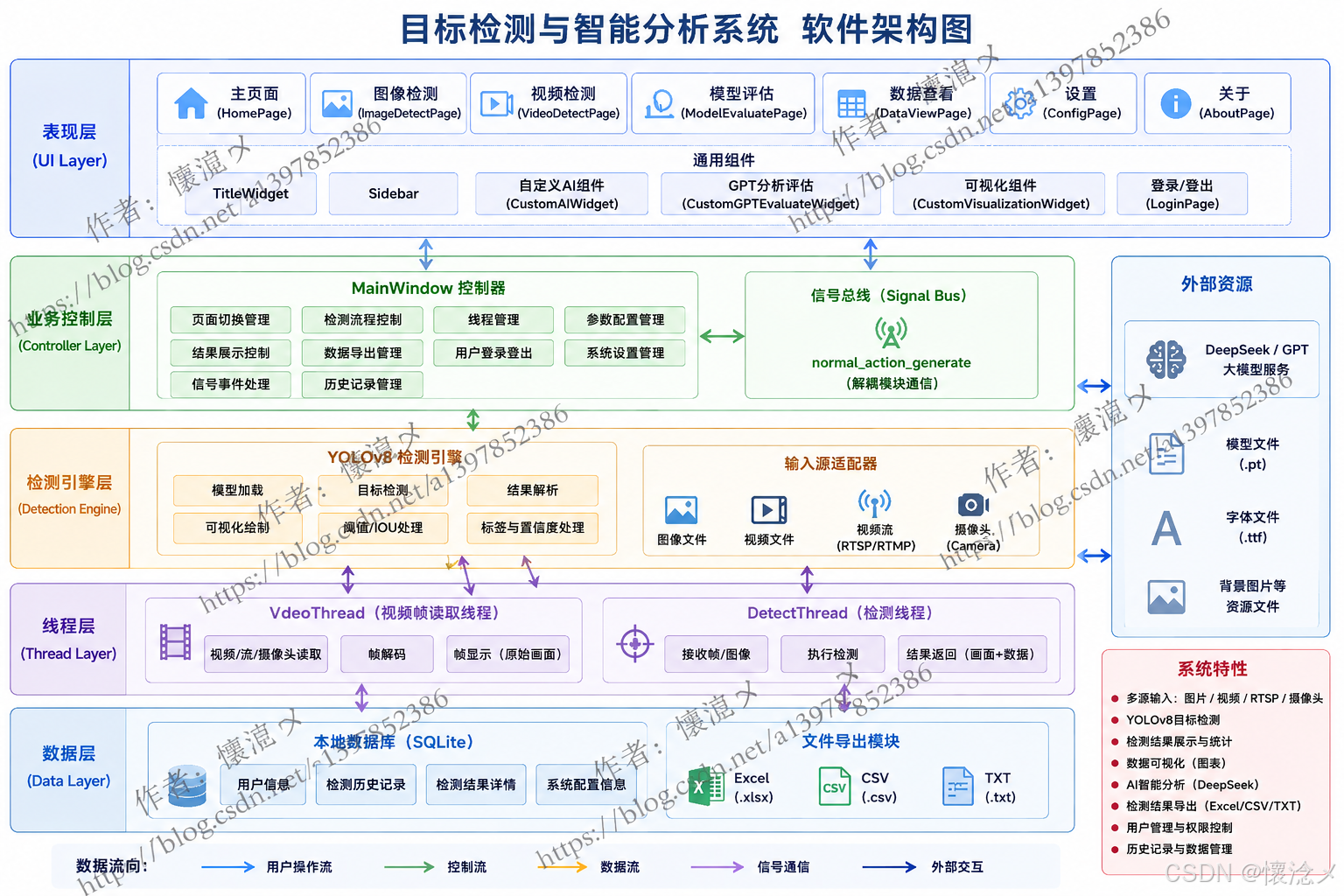
下图为本系统的功能模块图,直观地展示了系统的每个功能模块

下图为用户操作流程图,用户能够直观地看到系统每个具体的操作流程
六.关于项目
1.开发环境
本系统是在 Windows 11 操作系统上进行开发的,Python 环境采用的是 Python 3.8 版本,硬件方面使用的是 AMD 处理器 ,未配备独立显卡,开发工具为 *PyCharm 2021.3
- 版本。在整个开发与测试过程中,我们严格遵循了上述环境配置,确保了系统的稳定运行。在此特别建议所有使用者:为了避免出现因版本过新而导致的"不兼容"情况,请大家尽量不要使用过高的 Python 版本(如 Python 3.11 及以上),也不要使用最新的 PyCharm 或操作系统版本。因为较新的环境可能对部分依赖库或语法特性支持不佳,容易引发意外的报错或功能异常。遵循本项目所推荐的版本配置,能够最大程度地保证系统的顺利部署与稳定运行。
2.项目部署
1.项目依赖
博主是在Windows电脑上使用Python3.8开发的本系统,建议大家使用的Python版本别太高。
其中项目依赖为:
bash
PyQt5==5.15.11
QtAwesome==1.3.1
torch==2.4.1
torchvision==0.19.1
Pillow==9.3.0
pyqtgraph===0.13.3
PyQtWebEngine==5.15.5
opencv-python==4.10.0.82
ultralytics==8.3.234
Requests==2.32.5
pandas==2.0.3
numpy==1.24.4
Markdown==3.4.4我已经整理到了requirements.txt,大家直接使用命令
pip install -r requirements.txt
即可一键安装项目依赖,其中的torch和torchvision只要匹配即可,不一定非要和博主开发环境的版本一致。
2.项目结构
很多小伙伴担心拿到代码后项目看不懂,这个大家不必担心,我们采用文件+类名对相关功能进行了模块化定义,大家见名知意。
下图博主采用tree命令生成了文件、目录树
bash
tree "D:\projects\gitee\2026\yolo_projects\yolov8-colorectal-polyps-detect" /f /a
bash
D:\PROJECTS\GITEE\2026\YOLO_PROJECTS\yolov8-colorectal-polyps-detect
| main.py
| record.txt
| requirements.txt
|
+---data
| +---database
| | data.db
| |
| +---db
| | db.csv
| |
| +---font
| | hanyi_yahei.ttf
| |
| |
| \---model
| best.pt
| yolov8n.pt
+---script
| create_qrc.py
|
\---src
+---conf
| style_conf.py
| system_conf.py
| test_data.py
| __init__.py
|
+---engine
| engines.py
| __init__.py
|
+---resource
| | resource.qrc
| | resource_rc.py
| | __init__.py
| |
| +---imgs
| | ai.gif
| | ai.svg
| | bg.jpeg
| | login_gif.gif
| |
| \---js
| echarts.min.js
|
+---threads
| main_threads.py
| signal_bus.py
| __init__.py
|
+---utils
| custom_utils.py
| __init__.py
|
\---widgets
base_widgets.py
custom_pages.py
custom_widgets.py
main_page.py
unique_widgets.py
__init__.py
3.项目启动
本系统的项目启动十分简单:在安装好所有相关依赖之后,直接执行 main.py 文件,即可自动打开系统的登录注册页面。用户进入该页面后,通过输入匹配的用户名和密码完成登录操作。为方便初次体验,系统内置了一个默认账号,用户名为 admin,密码也为 admin,用户可以直接使用这组账号进行快速登录。当用户成功登录后,系统主界面会完整展示出来,而之前的登录注册页面则会自动隐藏,从而为用户提供清晰、流畅的操作体验。
4.往期优秀作品
七.总结
本项目开发了一款基于PyQt+YOLO+DeepSeek的淋巴细胞检测系统,旨在实现对图像、视频及实时视频流中淋巴细胞的高效、精准识别。系统以PyQt构建友好的图形界面,用户可方便地导入病理切片图像或实验视频,实时查看检测结果;YOLO目标检测模块负责快速定位和识别淋巴细胞,实现高精度的自动计数和标注;DeepSeek深度特征检索模块则支持对细胞形态和特征的智能筛选与分类,便于研究者对特殊细胞类型进行分析。该系统可应用于病理诊断辅助、肿瘤免疫微环境研究、医学教学、血液细胞分析及药物实验中,不仅显著提升检测效率,减少人工误差,还能为科研和临床提供可量化、可追溯的数据支撑。通过整合深度学习与可视化界面,该系统实现了从图像采集到结果输出的全流程智能化管理,为精准医疗和数字病理的发展提供了可靠技术平台。
本次给大家介绍了我使用PyQt5+YOLOv8+DeepSeek的淋巴细胞检测系统,本系统功能强大,支持多种数据源输入,包含多种用户交互按钮以及模式,内置数据可视化方案、大模型AI加持,是您学习、工作使用的不错选择!
需要代码的朋友可以点击箭头下方的二维码加我好友,欢迎您了解!
如需帮助请私聊博主!
