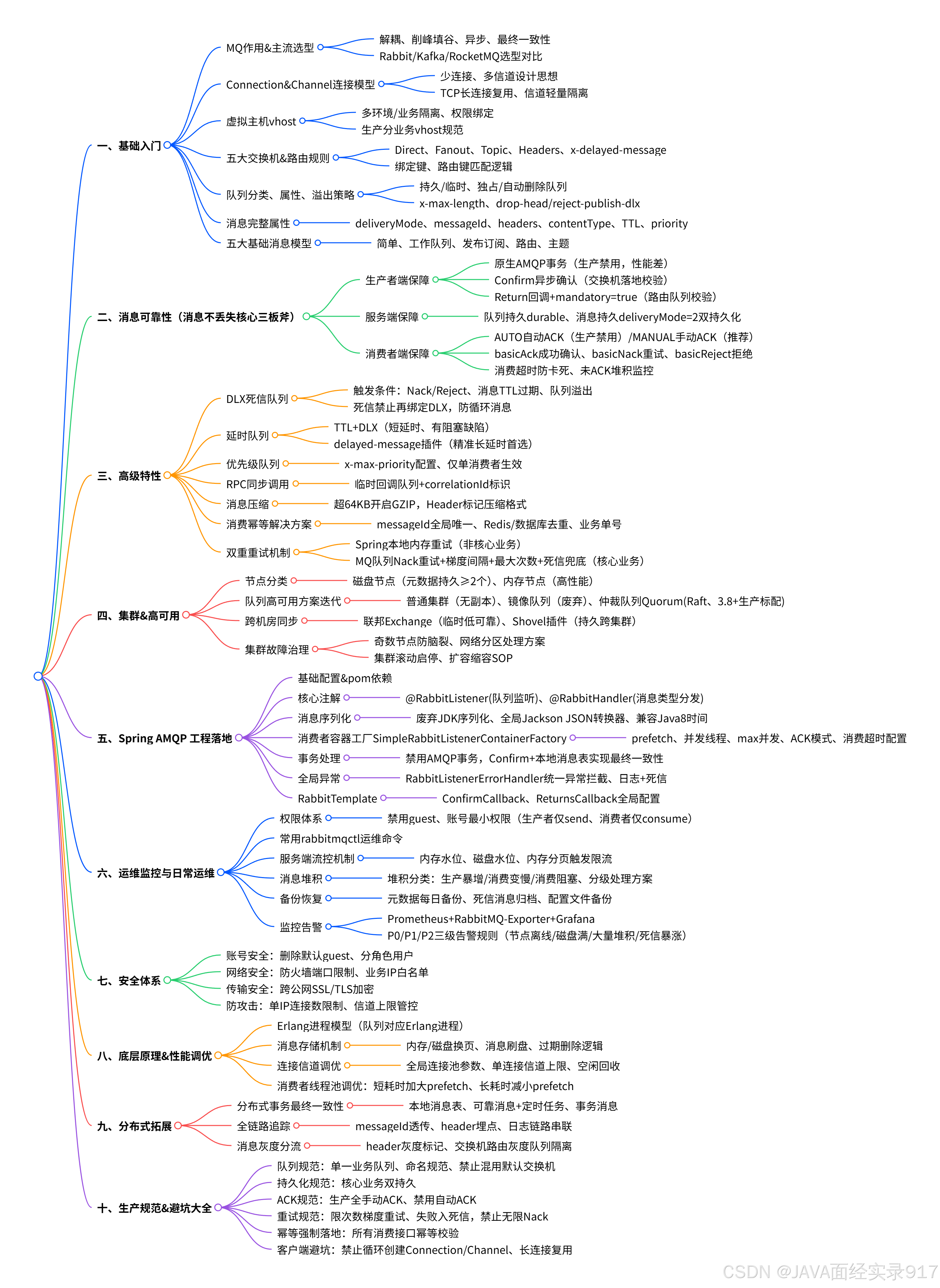
文档说明
RabbitMQ 全套学习文档(完整版 · 入门→实战→运维→面试)
本文档整合 RabbitMQ 基础、高阶特性、Spring 整合、集群高可用、运维监控、安全、底层原理、生产规范、巡检清单、面试考点,为一站式学习&上岗使用手册,覆盖开发、运维、架构全场景。
第一部分 整体学习路线与前置认知
1.1 MQ 通用概念
1.1.1 消息队列作用
-
业务解耦(核心):系统业务模块通过消息队列异步通信,无需直接接口调用,上下游业务独立开发、迭代、部署、扩容,修改单一业务不影响整体架构,大幅降低系统耦合度,提升项目可维护性与扩展性。
-
削峰填谷(高并发核心):瞬时大流量、秒杀、活动峰值流量可先缓存至消息队列,平稳分发至后端服务,避免突发流量直接冲击数据库和业务服务,防止系统雪崩;低谷时段匀速消费堆积消息,平衡服务器压力,最大化利用服务器资源。
-
异步提速(优化接口响应):将非核心、非实时业务(短信推送、日志记录、积分发放、订单通知等)异步化处理,主流程无需阻塞等待,大幅缩短接口响应时间,提升用户体验与系统吞吐量。
-
流量削控与限流:通过队列长度、预取值、溢出策略管控流量,限制后端最大处理压力,实现柔性限流,避免服务过载。
-
事件驱动架构支撑:基于消息事件实现业务联动,适配微服务架构,实现服务间解耦联动,适配复杂分布式业务场景。
-
消息缓冲与容错重试:消息持久化存储,业务消费失败可重试处理,避免瞬时服务抖动导致业务数据丢失,提升系统容错能力。
-
任务延时与定时调度:依托延时队列实现订单超时关闭、退款倒计时、定时提醒、延迟任务执行,替代传统定时任务,更加灵活可控。
-
流量广播与多消费分发:支持一对多消息分发,一条消息可被多个消费者消费,实现消息同步、多业务联动场景。
1.1.2 主流 MQ 选型对比
| 对比维度 | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|
| 开发语言 | Erlang | Scala/Java | Java |
| 核心定位 | 高可靠、功能完备的业务消息队列 | 超高吞吐、流式消息中间件 | 高吞吐+高可靠均衡型业务消息队列 |
| 吞吐量 | 中等(万级QPS),适合常规业务流量 | 极高(十万级QPS),支持海量数据堆积 | 高(数万级QPS),兼顾性能与稳定性 |
| 消息可靠性 | 极高,完整的确认、持久化、重试机制,几乎零丢消息 | 中等,默认异步刷盘,极端场景存在少量丢消息风险 | 极高,支持多副本、持久化、重试机制,可靠性接近RabbitMQ |
| 消息时序性 | 单队列严格有序 | 单分区严格有序,多分区无序 | 单队列严格有序,支持全局顺序消息 |
| 高级特性支持 | 齐全:死信、延时、优先级、重试、RPC、完整路由策略 | 匮乏:无原生死信、延时、优先级,仅基础收发能力 | 丰富:原生延时队列、死信、重试、事务消息、消息回溯 |
| 分布式事务 | 无原生支持,仅靠本地方案实现最终一致性 | 不支持事务,适用于无事务强依赖场景 | 原生支持半消息事务,适配分布式微服务事务场景 |
| 运维难度 | 低,自带可视化管理后台,运维简单友好 | 中,集群部署简单,监控生态完善 | 中,架构简洁,NameServer无选举复杂度,运维成本低 |
| 社区生态 | 全球开源社区成熟稳定,更新迭代平稳 | 生态最完善,大数据、流式计算适配性极强 | 国内生态活跃,适配国产微服务架构,海外生态偏弱 |
| 核心优势 | 可靠性拉满、功能全面、容错性强、适配复杂业务场景 | 零拷贝、批量读写、超高吞吐、海量数据处理能力强 | 吞吐与可靠均衡、事务能力强、原生高阶特性多 |
| 核心劣势 | 高吞吐场景性能瓶颈明显,不适合海量日志处理 | 消息可靠性弱,高阶功能缺失,不适合核心交易业务 | 跨语言支持弱,海外社区热度低于Kafka、RabbitMQ |
| 适用场景 | 金融、支付、电商交易、订单处理、通知推送、延时任务等强可靠核心业务 | 系统日志采集、用户行为上报、监控数据流、大数据流式计算等高吞吐非核心场景 | 互联网高并发业务、分布式事务场景、消息重试、定时任务、中小型微服务集群 |
1.1.2.1 MQ 终极选型口诀(面试/生产直接背诵)
-
强可靠、金融交易、复杂业务场景 → 首选 RabbitMQ
-
海量数据、日志流、高吞吐大数据场景 → 首选 Kafka
-
高并发互联网业务、需要分布式事务 → 首选 RocketMQ
1.1.3 基础角色定义
-
生产者(Producer):发送消息
-
消费者(Consumer):接收并处理消息
-
消息(Message):传输数据载体
-
交换机(Exchange):路由消息
-
队列(Queue):存储消息
-
绑定(Binding):交换机与队列的关联关系
1.2 整体学习顺序(推荐)
-
基础组件 + 5大交换机 + 消息模型(1~2天)
-
Java 原生客户端 + Spring Boot 整合(2~3天)
-
消息可靠性、死信、延时、幂等、重试(核心,3~4天)
-
集群、镜像队列、仲裁队列、跨机房方案(2天)
-
权限、安全、流控、监控、故障排查(2天)
-
底层原理、性能调优、生产规范、面试刷题(收尾)
第二部分 RabbitMQ 基础核心
2.1 整体架构与连接模型(超全完整版)
RabbitMQ 整体架构分为客户端层、网络连接层、服务端核心层、数据持久层、虚拟隔离层,整体遵循「生产者推送→交换机路由→队列存储→消费者拉取」的核心流转逻辑,所有消息交互均基于 TCP 连接完成,是理解所有 MQ 功能的底层基础。
2.1.1 完整整体架构组成
RabbitMQ 服务端核心五大组成组件,各司其职、互不耦合:
-
生产者(Producer):业务应用客户端,负责创建消息、指定路由规则,主动推送消息至 RabbitMQ 服务端,不直接操作队列。
-
交换机(Exchange):服务端核心路由组件,接收生产者消息,根据路由键和绑定规则,精准分发消息至对应队列,本身不存储消息。
-
绑定器(Binding):虚拟关联关系,唯一作用是建立「交换机 ↔ 队列」的映射,是消息路由的桥梁,无实体、不占用资源。
-
队列(Queue):消息唯一存储载体,负责持久化缓存消息、等待消费者消费,支持多消费者竞争消费,保证消息有序堆积。
-
消费者(Consumer):业务应用客户端,持续监听指定队列,获取并处理消息,处理完成后通过 ACK 机制告知服务端删除消息。
完整消息流转链路:生产者客户端 → TCP连接/信道 → 服务端交换机路由 → 绑定匹配 → 队列存储 → 消费者监听消费 → ACK 确认删除
2.1.2 Connection 与 Channel(核心面试必考)
RabbitMQ 采用「一个TCP物理连接 + 多个轻量逻辑信道」的设计模式,是高性能架构的核心设计,彻底避免频繁创建TCP连接的性能损耗。
1. Connection(TCP物理连接)
-
本质 :客户端与 RabbitMQ 服务端之间的原生 TCP 长连接,是所有通信的物理基础。
-
创建成本:极高,需要三次握手、认证授权、参数协商、资源初始化,耗时耗资源。
-
生命周期:项目启动时创建、项目销毁时关闭,全局复用,不随业务请求销毁。
-
数量限制:MQ 服务端对单节点连接数有上限,过多连接会触发流控、拒绝新连接。
-
独有特性:一个 Connection 独享一套TCP资源、网络缓冲区,连接断开则旗下所有信道全部失效。
2. Channel(逻辑信道/会话)
-
本质 :基于 Connection 虚拟出的轻量级逻辑通信通道,依附于TCP连接存在,无独立网络开销。
-
创建成本:极低,仅需内存初始化,无需网络握手,毫秒级创建。
-
作用:所有业务操作均通过信道完成:声明交换机、声明队列、发送消息、消费消息、ACK确认、绑定解绑等。
-
隔离性 :同一连接下多个信道相互隔离,单个信道异常、关闭,不会影响其他信道和物理连接。
-
数量:一个 Connection 可支持数十、上百个 Channel,无严格上限,受内存限制。
3. Connection 与 Channel 核心区别(面试简答版)
| 对比维度 | Connection(连接) | Channel(信道) |
|---|---|---|
| 底层本质 | 物理TCP长连接 | 虚拟逻辑会话,依附连接 |
| 创建销毁开销 | 极大,耗时耗资源 | 极小,几乎无性能损耗 |
| 相互影响 | 连接断开,所有信道全部失效 | 单信道故障,不影响其他信道和连接 |
| 资源占用 | 占用TCP端口、缓冲区、系统句柄 | 仅占用少量内存 |
| 业务使用 | 全局少量复用,不频繁操作 | 业务高频创建、复用、关闭 |
4. 生产核心最佳实践(避坑重点)
-
核心原则:多信道、少连接,绝对禁止「一条业务一个Connection」。
-
微服务项目统一配置全局连接池,维持2~4个长连接即可满足绝大多数业务。
-
业务操作复用信道,使用完毕正常关闭,杜绝信道泄漏(创建不关闭、连接不释放)。
-
禁止循环内创建Connection/Channel,会导致端口耗尽、服务雪崩。
2.1.3 虚拟主机 vhost(隔离层核心)
vhost 是 RabbitMQ 提供的多租户资源隔离机制,是架构层面的重要设计,完美解决多项目、多环境共用MQ集群的隔离问题。
-
核心作用 :每个 vhost 等价于一台独立的小型 RabbitMQ 实例,实现交换机、队列、权限、用户、数据完全隔离,不同vhost之间资源互不干扰、不可互通。
-
默认主机 :系统默认根路径
/,空项目默认使用,生产禁止核心业务使用默认vhost。 -
隔离粒度:支持按环境隔离(开发、测试、预发、生产)、按业务隔离(订单、支付、通知)、按项目隔离。
-
优势:无需搭建多套MQ集群,单集群可支撑多业务、多环境,大幅降低运维成本,同时保证业务隔离安全。
-
生产强制规范:所有正式业务必须独立配置专属vhost,禁止多业务共用同一个vhost,避免队列重名冲突、消息串流、权限混乱问题。
2.1.4 连接建立完整流程(底层原理)
-
TCP握手:客户端与MQ服务端完成三次握手,建立物理TCP连接。
-
协议协商:双方确认AMQP协议版本、通信参数、编码格式。
-
身份认证:客户端提交账号密码,服务端校验权限,认证通过则连接生效。
-
vhost 绑定:切换至指定虚拟主机,加载对应隔离资源。
-
创建信道:基于TCP连接创建多个逻辑信道,用于后续业务通信。
-
业务交互:通过信道完成队列声明、消息收发、路由匹配、消费确认等所有操作。
2.1.5 连接异常与重连机制(生产重点)
-
常见断连原因:网络抖动、服务端重启、端口封禁、流控触发、连接超时、防火墙策略。
-
断连影响:TCP连接断开后,所有信道立即失效,暂停消息收发;未持久化消息丢失,持久化消息等待重连后恢复消费。
-
生产最佳配置 :客户端开启自动重连机制,配置合理重连间隔、最大重试次数,避免断连后业务瘫痪。
2.2 五大交换机(核心必考 · 全网最全完整版)
交换机(Exchange)是 RabbitMQ 唯一的消息路由组件,生产者的消息只会发送给交换机,绝不直接投递队列。交换机根据「交换机类型 + 路由键 RoutingKey + 队列绑定键 BindingKey」完成消息分发。
核心前置概念
-
RoutingKey:生产者发送消息时携带的路由标识(消息往哪发)
-
BindingKey:队列绑定交换机时设置的匹配标识(队列收哪些消息)
-
匹配规则:不同交换机,匹配逻辑完全不同
-
共性特点 :交换机本身不存储消息,只负责路由;无匹配队列时消息直接丢失(未开启Return机制)
2.2.1 Direct 直连交换机(精准匹配 · 最常用)
匹配规则 :RoutingKey 必须与 BindingKey 完全相等,精准一对一匹配。
核心特性
-
一对一单播模式,一条消息只会被一个匹配队列接收
-
路由精准、无多余分发、性能损耗极低
-
支持多队列绑定同一个BindingKey,此时变为多消费者竞争消费
适用场景
-
点对点精准消息投递
-
订单单发、支付回调、单业务通知
-
需要精准路由、不允许消息乱投递的核心业务
优缺点
-
优点:精准可靠、路由效率高、业务可控
-
缺点:无模糊匹配能力,不适合批量广播、分类订阅场景
2.2.2 Topic 主题交换机(模糊匹配 · 最灵活)
匹配规则:基于通配符模糊匹配,支持层级路由,是业务最通用的交换机类型。
通配符详解(面试必背)
-
*(星号):匹配单个层级单词 ,只能匹配一个.分隔的字段 -
#(井号):匹配零个或多个层级单词,可匹配多级、空层级
示例演示
-
绑定键:
order.*→ 匹配:order.create、order.pay,不匹配:order.create.success -
绑定键:
order.#→ 匹配:order、order.create、order.pay.success 所有层级
核心特性
-
支持一对多、多维度订阅
-
可实现消息分类、分级路由、业务订阅隔离
-
规则灵活,适配绝大多数复杂业务场景
适用场景
-
消息分类订阅、业务模块解耦
-
日志分级收集、事件驱动、系统通知
-
多业务订阅同一类消息,按需过滤
2.2.3 Fanout 广播交换机(全网广播 · 最快)
匹配规则 :完全忽略 RoutingKey、BindingKey,无条件将消息分发到所有绑定的队列。
核心特性
-
纯广播模式,一对多全员接收
-
无需匹配计算,路由性能最高、速度最快
-
所有绑定队列都会收到完整消息
适用场景
-
系统全局通知、配置刷新、缓存刷新
-
多服务同步任务、集群节点同步
-
秒杀预热、活动公告、全员消息推送
优缺点 & 坑点
-
优点:性能极高、逻辑简单、适合批量同步
-
缺点:无法过滤消息,所有队列全量接收,易产生无效消息消费
2.2.4 Headers 头部交换机(极少使用)
匹配规则 :根据消息的 Header 头部参数 进行匹配,支持多参数复杂匹配。
核心特性
-
支持任意自定义参数匹配,规则最灵活
-
匹配需要遍历Header键值对,性能极差
-
支持 all/any 匹配模式(全部匹配/任意匹配)
现状与场景
-
生产环境几乎不用
-
仅用于极特殊的多维度复杂参数路由场景,可被Topic完全替代
2.2.5 Default 默认交换机(系统内置)
本质 :系统自动创建的匿名 Direct 直连交换机,全局唯一,无需手动声明。
核心机制
-
所有队列创建时,会自动绑定默认交换机
-
绑定键 = 队列名称
-
发送消息时,RoutingKey填队列名,可直接投递指定队列
使用场景
-
简单测试、临时消息投递
-
生产禁止核心业务使用,无管控、不易维护、无法统一路由管理
2.2.6 五大交换机 终极对比表(面试必背)
| 交换机类型 | 匹配规则 | 路由精度 | 性能 | 核心使用场景 |
|---|---|---|---|---|
| Direct | RoutingKey == BindingKey 完全一致 | 精准匹配 | 极高 | 点对点核心业务、订单、支付 |
| Topic | * 单层级 / # 多层级模糊匹配 | 灵活匹配 | 高 | 消息订阅、事件驱动、分类通知 |
| Fanout | 忽略所有key,全队列广播 | 无匹配 | 最高 | 全局通知、缓存刷新、多服务同步 |
| Headers | 根据消息Header键值对匹配 | 极灵活 | 极低 | 生产废弃,无使用场景 |
| Default | 默认Direct规则,绑定队列为key | 精准匹配 | 高 | 临时测试、简单demo |
2.2.7 面试高频坑点总结(必记)
-
坑1:交换机不存消息,只有队列存消息;无匹配队列消息直接丢失
-
坑2 :Topic中
*和#不能混用写错,多层级必须用 # -
坑3:Fanout 完全无视路由键,写了RoutingKey也无效
-
坑4:Headers交换机性能差,生产绝对不使用
-
坑5:生产禁止使用默认交换机,不利于业务解耦与维护
-
坑6:Direct多队列绑定同一个key,会触发消费者竞争消费,不是重复消费
2.2.8 选型口诀(一秒选型)
-
精准点对点 → Direct
-
订阅、分类、模糊路由 → Topic
-
全员广播、同步通知 → Fanout
-
复杂参数匹配 → 弃用Headers,改用Topic+业务字段
-
正式业务 → 禁用Default默认交换机
2.3 队列分类与配置(含完整可运行代码)
RabbitMQ 队列可按持久化特性、独占特性、自动删除特性、功能特性分为多类,结合 SpringBoot + SpringAMQP 可实现所有队列配置,以下为生产全套分类说明 + 完整实战代码。
2.3.1 队列核心基础属性(必懂)
所有队列均由三大核心属性组合,定义队列生命周期与存储特性:
-
durable(队列持久化):true=队列元数据持久到磁盘,服务重启队列不丢失;false=临时队列,重启销毁
-
exclusive(独占队列):true=仅当前创建连接可访问,连接断开队列自动销毁;false=多连接共享
-
autoDelete(自动删除队列):true=无任何消费者监听时,队列自动销毁;false=常驻队列
2.3.2 限制型队列(流量管控)
用于限流、防消息堆积溢出,适配秒杀、高并发场景,配置队列最大容量与溢出策略。
-
x-max-length:队列最大消息数量(消息条数限制) -
x-max-length-bytes:队列最大存储字节数(内存大小限制) -
**三大溢出策略(队列满时执行)**drop-head:默认策略,丢弃队列最头部旧消息,保留新消息
-
reject-publish:拒绝生产者新消息,返回投递失败,触发生产者异常
-
reject-publish-dlx:拒绝新消息,同时将溢出消息转入死信队列
2.3.3 临时队列
组合配置:exclusive=true + autoDelete=true + durable=false,生命周期跟随连接,多用于 RPC 远程调用临时回复队列、临时测试场景,无需手动维护。
2.3.4 功能型队列(高阶业务)
-
优先级队列:
x-max-priority,支持消息优先级消费(0~255) -
死信队列:绑定死信交换机,接收过期、拒绝、溢出消息
-
延时队列:基于TTL属性,结合死信实现延时消费
2.3.5 SpringBoot 完整配置代码(生产可直接用)
前置依赖:SpringBoot 整合 RabbitMQ 核心依赖,所有队列统一配置类声明,避免硬编码、重复创建。
java
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
/**
* RabbitMQ 队列全套配置类
* 包含:普通队列、持久队列、独占队列、自动删除队列、限制队列、优先级队列
*/
@Configuration
public class RabbitQueueConfig {
// ===================== 1. 基础持久队列(生产核心业务首选)=====================
/**
* 持久化业务队列:durable=true、非独占、常驻不自动删除
* 适配:订单、支付、通知等核心业务
*/
@Bean
public Queue orderBusinessQueue() {
// 参数:队列名、持久化、非独占、不自动删除
return new Queue("order.business.queue", true, false, false);
}
// ===================== 2. 临时队列(测试/RPC场景)=====================
/**
* 临时队列:非持久、独占、无消费者自动删除
* 适配:RPC调用临时回复队列、临时测试消息
*/
@Bean
public Queue tempExclusiveQueue() {
// 临时队列标准组合:durable=false + exclusive=true + autoDelete=true
return new Queue("temp.exclusive.queue", false, true, true);
}
// ===================== 3. 限制型队列(高并发限流)=====================
/**
* 限流队列:限制最大消息数+溢出策略
* 适配:秒杀、活动流量,防止消息无限堆积
*/
@Bean
public Queue limitTrafficQueue() {
Map<String, Object> args = new HashMap<>();
// 设置队列最大消息条数1000
args.put("x-max-length", 1000);
// 溢出策略:丢弃队首旧消息(默认)
args.put("x-overflow", "drop-head");
// 也可配置:reject-publish / reject-publish-dlx
return new Queue("limit.traffic.queue", true, false, false, args);
}
// ===================== 4. 字节限制队列(大消息限流)=====================
/**
* 按字节限制队列:限制队列最大存储大小
*/
@Bean
public Queue byteLimitQueue() {
Map<String, Object> args = new HashMap<>();
// 最大存储10MB
args.put("x-max-length-bytes", 10 * 1024 * 1024);
// 溢出消息转入死信队列
args.put("x-overflow", "reject-publish-dlx");
return new Queue("byte.limit.queue", true, false, false, args);
}
// ===================== 5. 优先级队列(高阶业务)=====================
/**
* 优先级队列:支持0-255优先级,数值越大优先级越高
* 注意:仅单消费者模式生效
*/
@Bean
public Queue priorityQueue() {
Map<String, Object> args = new HashMap<>();
// 设置最大优先级255
args.put("x-max-priority", 255);
return new Queue("message.priority.queue", true, false, false, args);
}
// ===================== 6. TTL延时队列(无插件延时方案)=====================
/**
* 队列级TTL延时队列:统一设置消息过期时间
*/
@Bean
public Queue ttlDelayQueue() {
Map<String, Object> args = new HashMap<>();
// 消息过期时间30秒(单位毫秒)
args.put("x-message-ttl", 30000);
// 绑定死信交换机,过期消息转入死信队列实现延时消费
args.put("x-dead-letter-exchange", "dlx.direct.exchange");
args.put("x-dead-letter-routing-key", "dlx.order.key");
return new Queue("ttl.delay.queue", true, false, false, args);
}
}2.3.6 队列配置核心参数详解(代码对应)
|---------------------------|---------|-----------------------|
| 队列构造参数 | 参数含义 | 生产配置规范 |
| String name | 队列名称 | 业务语义化命名,统一规范 |
| boolean durable | 是否队列持久化 | 核心业务true,临时业务false |
| boolean exclusive | 是否独占队列 | 业务队列false,临时RPC队列true |
| boolean autoDelete | 是否自动删除 | 常驻业务false,临时队列true |
| Map<String,Object> args | 队列拓展参数 | 限流、优先级、TTL、死信配置 |
2.3.7 生产队列选型口诀(代码落地版)
-
核心交易业务:持久化 + 共享 + 常驻(durable=true)
-
临时测试/RPC:非持久 + 独占 + 自动删除
-
高并发限流场景:配置max-length + 合理溢出策略
-
加急业务消息:使用优先级队列,单消费者消费
-
定时延时场景:TTL队列绑定死信交换机
2.4 消息完整属性(超全详解 + 生产代码 + 面试必背)
RabbitMQ 消息是完整的结构化数据载体,并非单纯的业务字符串。一条完整的 AMQP 消息由 消息头属性(Headers)+ 基础元属性 + 消息体(Body) 三部分组成。所有属性直接决定消息的持久化、生命周期、路由规则、消费逻辑、重试机制,是保证消息可靠性、幂等性、高阶特性的核心基础。
2.4.1 消息核心结构
标准 AMQP 消息三层结构:
-
基本属性(BasicProperties):MQ 原生内置元数据,控制消息路由、持久化、优先级、过期时间等核心能力
-
自定义消息头(Headers):开发者自定义 KV 键值对,用于灰度路由、业务标记、链路追踪
-
消息体(Body):真实业务数据(JSON/字符串/二进制),业务核心传输内容
2.4.2 原生内置核心属性(面试+生产必考)
| 属性字段 | 含义说明 | 生产作用 & 配置规范 |
|---|---|---|
| deliveryMode | 消息持久化模式 | 1:非持久化(重启丢失);2:持久化(落盘存储)生产规范:核心业务必须设置为2 |
| priority | 消息优先级 | 取值 0~255,数值越大优先级越高;仅优先级队列、单消费者模式生效 |
| contentType | 消息体数据格式 | 常用:application/json、text/plain;统一序列化格式,避免反序列化异常 |
| contentEncoding | 消息压缩编码 | 支持 GZIP/LZ4,大消息场景开启压缩,减少传输与存储开销 |
| messageId | 消息唯一ID | 全局唯一字符串,用于消息幂等、链路追踪、异常溯源,生产必须手动生成 |
| timestamp | 消息生产时间戳 | 记录消息生成时间,用于消息时效判断、过期过滤、日志排序 |
| expiration | 消息级TTL过期时间 | 单位毫秒,单条消息独立过期时间,优先级高于队列全局TTL |
| replyTo | RPC回复队列名称 | RPC同步调用专用,指定消费者处理完成后结果返回的临时队列 |
| correlationId | RPC关联ID | 关联请求与响应消息,保证RPC调用结果不乱序、不匹配错误 |
| userId | 发送用户标识 | 校验消息发送权限,可用于消息溯源、权限校验 |
| appId | 应用标识 | 标记消息所属服务,多服务场景区分消息来源,方便问题排查 |
2.4.3 自定义 Header 属性(生产高阶用法)
原生属性无法满足复杂业务时,可自定义 Header KV 参数,多用于灰度发布、流量路由、业务标记、链路追踪:
-
traceId/spanId:全链路追踪,贯穿生产、路由、消费全流程,快速定位消息异常
-
grayFlag:灰度标记,区分正式消息、测试消息,实现灰度流量分流
-
retryCount:消息重试次数,手动记录重试次数,避免无限重试
-
businessType:业务类型标记,多业务共用队列时区分消息类型
-
createTime:业务生成时间,辅助判断消息时效性
2.4.4 关键属性优先级与避坑(面试高频)
1. TTL 过期优先级
消息级 expiration > 队列级 x-message-ttl
同时配置时,以更小的时间为准;仅队列TTL会出现队尾消息延时不准的问题,单条动态延时优先用消息级TTL。
2. 持久化优先级规范
RabbitMQ 无单独消息持久化开关,必须队列持久化(durable=true) + 消息持久化(deliveryMode=2)双配置,缺一必丢消息。
3. 优先级失效场景(必考坑点)
-
未声明优先级队列(未配置x-max-priority)
-
多消费者并行消费
-
开启prefetch预取值缓存消息
-
以上场景优先级全部失效
2.4.5 SpringBoot 完整实操代码(配置所有消息属性)
可直接复制运行,包含持久化、TTL、优先级、消息ID、自定义Header、序列化规范,生产标准模板。
java
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessageBuilder;
import org.springframework.amqp.core.MessageProperties;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.UUID;
/**
* 消息属性完整配置实操
* 包含:持久化、TTL、优先级、唯一ID、自定义Header、压缩、链路追踪
*/
@Component
public class MessagePropertyProducer {
@Resource
private RabbitTemplate rabbitTemplate;
public void sendFullPropertyMessage() {
// 1. 构建完整消息属性
MessageProperties properties = new MessageProperties();
// 消息持久化:2-持久化 1-非持久化
properties.setDeliveryMode(MessageDeliveryMode.PERSISTENT);
// 消息优先级:0-255
properties.setPriority(10);
// 单条消息TTL:30秒过期
properties.setExpiration("30000");
// 全局唯一消息ID(幂等核心)
String messageId = UUID.randomUUID().toString().replace("-", "");
properties.setMessageId(messageId);
// 消息生产时间戳
properties.setTimestamp(System.currentTimeMillis());
// 数据格式为JSON
properties.setContentType("application/json");
// 2. 自定义Header高阶参数
properties.setHeader("traceId", "TRACE_" + messageId);
properties.setHeader("retryCount", 0);
properties.setHeader("grayFlag", "false");
properties.setHeader("businessType", "ORDER_PAY");
// 3. 构建消息体
String businessData = "{\"orderId\":\"20260601001\",\"payStatus\":1}";
Message message = MessageBuilder.withBody(businessData.getBytes())
.andProperties(properties)
.build();
// 4. 发送消息
rabbitTemplate.convertAndSend("order.topic.exchange", "order.pay.success", message);
}
}2.4.6 生产强制规范(必遵守)
-
所有核心业务消息必须开启持久化:deliveryMode=2
-
每条消息必须携带唯一messageId,杜绝重复消费
-
统一contentType为json,避免序列化乱码、解析异常
-
延时场景优先使用消息级TTL,适配动态过期时间需求
-
所有消息追加traceId,实现全链路问题溯源
-
重试消息通过header记录retryCount,限制最大重试次数,防止死循环
2.4.7 面试极简背诵总结
-
消息三要素:属性+Header+消息体
-
防丢消息核心:双持久化(队列持久+消息持久)
-
TTL优先级:单条消息 > 队列全局
-
幂等核心:messageId全局唯一
-
RPC核心:replyTo + correlationId
-
优先级仅单消费者+优先级队列生效
-
基础属性:routingKey、消息 ID、时间戳、优先级
-
持久化:
deliveryMode=2消息持久化;1非持久 -
拓展属性:TTL 过期时间、
reply-to(RPC 回复队列)、消息 Header、生产者标识
2.5 基础消息模型(五大核心模型 · 全原理+代码+场景完整版)
RabbitMQ 所有业务消息交互,均基于官方五大基础消息模型衍生拓展,是掌握高阶特性、排查消息异常的底层核心。五大模型分别为:简单队列模型、工作队列模型、发布订阅模型、路由模型、主题模型。下文全覆盖模型原理、流转流程、核心特点、生产场景、完整可运行代码、面试坑点。
2.5.1 简单队列模型(Simple Queue)
1. 核心原理
最基础的一对一消息模型,结构为:单个生产者 → 单个队列 → 单个消费者。生产者发送消息至指定队列,唯一消费者监听队列、逐条消费消息,全程无消息分发竞争、无广播分流,逻辑最简单。
2. 核心特点
-
一对一单点收发,消息唯一消费一次
-
消息有序,发送顺序与消费顺序完全一致
-
无复杂路由规则,基于默认交换机即可实现
-
性能有限,仅适配低并发、单消费场景
3. 适用场景
简单单业务通知、少量数据同步、测试调试、低频次点对点消息推送。
4. 核心坑点
-
仅单消费者,无法横向扩容提升消费速度
-
消费者宕机则消息堆积,业务暂停消费
5. 极简代码实操
java
// 生产者:发送消息至指定队列(默认交换机)
rabbitTemplate.convertAndSend("simple.biz.queue", "简单队列测试消息");
// 消费者:监听单队列单消费
@RabbitListener(queues = "simple.biz.queue")
public void consumeSimpleMsg(String msg) {
System.out.println("简单队列消费消息:" + msg);
}2.5.2 工作队列模型(Work Queue)
1. 核心原理
模型结构:单个生产者 → 单个队列 → 多个消费者 。多个消费者监听同一个队列,消息进入队列后,由多个消费者竞争消费 ,一条消息仅会被一个消费者处理,核心用于分担消费压力、解决消息堆积。
2. 两种分发模式(面试必考)
(1)轮询分发(默认模式)
MQ 均匀将消息依次分发到每个消费者,不区分消费者处理速度,无论消费者是否处理完毕,按顺序轮流推送消息。
-
特点:平均分配、简单粗暴
-
问题:容易出现忙闲不均,处理快的消费者空闲,处理慢的消费者堆积消息
(2)公平分发(生产推荐)
通过配置 prefetch 预取值 实现,MQ 仅在消费者处理完当前消息、手动ACK后,才会推送下一条消息,按需分发,适配消费者处理能力不均的场景。
-
核心配置:prefetch=1(一次只预推1条未确认消息)
-
特点:能者多劳,最大化利用消费资源,杜绝忙闲不均
-
生产规范:高并发业务必须开启公平分发
3. 核心特点
-
多条消息并行消费,大幅提升消费吞吐量
-
消息唯一消费,不会重复消费
-
支持横向扩容消费者节点,解决消息堆积
4. 适用场景
高并发任务处理、订单批量处理、日志解析、数据同步、需要提升消费速度的业务场景。
5. 核心坑点
-
默认轮询模式会导致消费不均衡,生产禁止直接使用
-
prefetch设置过大,会导致消费者本地消息堆积,故障易丢数据
-
多消费者场景下,队列消息仍保持有序,但单节点消费无序
6. 核心配置代码(公平分发)
java
// 配置消费者容器工厂,开启公平分发
@Bean
public SimpleRabbitListenerContainerFactory fairListenerFactory(SimpleRabbitListenerContainerFactoryConfigurer configurer, ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
configurer.configure(factory, connectionFactory);
// 关闭自动ACK,开启手动ACK
factory.setAcknowledgeMode(AcknowledgeMode.MANUAL);
// 核心:预取值1,实现公平分发
factory.setPrefetch(1);
// 开启多消费者并发
factory.setConcurrent(3);
return factory;
}2.5.3 发布订阅模型(Publish/Subscribe)
1. 核心原理
基于 Fanout 广播交换机 实现,模型结构:生产者→Fanout交换机→多个绑定队列→每个队列对应消费者 。生产者发送一条消息,交换机会无条件将消息广播到所有绑定的队列,实现一条消息、多服务同时消费。
2. 核心特点
-
完全忽略 RoutingKey、BindingKey,无路由匹配逻辑
-
一对多全员广播,所有绑定队列均可接收完整消息
-
路由性能极高,无匹配计算开销
-
天然支持多业务、多服务同步处理
3. 适用场景
系统配置刷新、全局缓存更新、集群节点同步、活动公告推送、多服务状态同步、日志全量采集。
4. 核心坑点
-
无法过滤消息,所有订阅服务全量接收,易产生无效消费
-
消息无针对性,不适合精准业务路由场景
5. 模型配置代码
java
// 声明Fanout广播交换机
@Bean
public FanoutExchange fanoutExchange() {
return ExchangeBuilder.fanoutExchange("system.fanout.exchange").durable(true).build();
}
// 绑定队列1
@Bean
public Queue cacheRefreshQueue() {
return new Queue("cache.refresh.queue", true);
}
@Bean
public Binding cacheBinding(FanoutExchange fanoutExchange, Queue cacheRefreshQueue) {
return BindingBuilder.bind(cacheRefreshQueue).to(fanoutExchange);
}
// 绑定队列2
@Bean
public Queue configRefreshQueue() {
return new Queue("config.refresh.queue", true);
}
@Bean
public Binding configBinding(FanoutExchange fanoutExchange, Queue configRefreshQueue) {
return BindingBuilder.bind(configRefreshQueue).to(fanoutExchange);
}2.5.4 路由模型(Routing)
1. 核心原理
基于 Direct 直连交换机 实现精准路由,模型结构:生产者→Direct交换机→按Key精准匹配队列→对应消费者消费 。通过 RoutingKey 与 BindingKey 完全相等匹配,实现消息定向投递、精准分发。
2. 核心特点
-
精准一对一、一对多匹配,路由无误差
-
可实现消息分类定向投递,按需分发
-
性能损耗极低,适配核心业务
-
多队列绑定同一个Key时,触发工作队列竞争消费模式
3. 适用场景
订单精准投递、支付回调分发、业务分级通知、异常消息定向推送、需要精准路由的核心交易场景。
4. 核心坑点
-
必须严格匹配Key,字符不一致则消息丢失
-
无模糊匹配能力,复杂多维度订阅场景不适用
2.5.5 主题模型(Topic)
1. 核心原理
基于 Topic 主题交换机 实现模糊层级路由,是业务最通用、最灵活的消息模型。通过 *、# 通配符实现多层级模糊匹配,支持消息分类订阅、动态路由。
2. 通配符核心规则(必背)
-
*:匹配单个层级的单词(仅匹配一个 . 分隔字段) -
#:匹配零个或多个层级的单词(适配多级路由)
3. 核心特点
-
路由规则灵活,支持精准匹配+模糊匹配
-
支持多服务差异化订阅同一类消息
-
可实现业务解耦、消息分级、灰度路由
-
完全覆盖Direct、Fanout大部分业务场景
4. 适用场景
消息分类订阅、事件驱动架构、日志分级收集、多模块业务解耦、灰度流量分发、复杂业务路由场景。
5. 经典匹配示例
-
绑定键:
order.*→ 匹配:order.create、order.pay | 不匹配:order.create.success -
绑定键:
order.#→ 匹配:order、order.create、order.pay.success、order.refund.all -
绑定键:
#.error→ 匹配所有结尾为error的异常日志消息
2.5.6 五大消息模型终极对比(面试速记表)
|------|-------------|-------------|-----------|----------------|
| 消息模型 | 依赖交换机 | 核心能力 | 消费模式 | 核心场景 |
| 简单队列 | 默认交换机 | 一对一单点收发 | 单消费者独占消费 | 简单测试、低频次通知 |
| 工作队列 | 默认/Direct | 多消费者分担压力 | 多消费者竞争消费 | 高并发任务、防消息堆积 |
| 发布订阅 | Fanout广播交换机 | 一对多全员广播 | 多队列独立全量消费 | 缓存刷新、集群同步 |
| 路由模型 | Direct直连交换机 | 精准Key匹配路由 | 定向队列消费 | 核心交易、精准投递 |
| 主题模型 | Topic主题交换机 | 模糊层级路由、灵活订阅 | 按需订阅差异化消费 | 复杂业务、事件驱动、消息订阅 |
2.5.7 面试高频总结+生产选型口诀
-
单点简单业务:简单队列模型
-
消息堆积、需扩容消费:工作队列模型(开启prefetch公平分发)
-
多服务同步、全局通知:发布订阅广播模型
-
核心交易、精准定向投递:Direct路由模型
-
复杂订阅、分类路由、解耦架构:优先Topic主题模型(业务万能模型)
终极结论 :生产环境中,Topic主题模型+工作队列消费模式组合,可覆盖95%以上的业务场景。
-
简单队列:一对一收发
-
工作队列:多个消费者竞争消费
-
轮询分发:默认模式
-
公平分发:配置 prefetch,按需推送,避免忙闲不均
-
-
发布订阅:Fanout 交换机实现广播
-
路由模式:Direct 交换机精准分发
-
主题模式:Topic 交换机模糊路由
第三部分 消息可靠性(重中之重,生产&面试核心)
3.1 生产者端防消息丢失(完整落地版)
生产者端消息丢失是业务最常见的消息异常场景,核心成因:消息未成功投递到交换机、路由失败无匹配队列、网络抖动导致投递中断、生产者异常退出。RabbitMQ 提供三套成熟的防丢失方案,包含事务机制、发布确认机制、消息退回机制,生产环境以「Confirm异步确认 + Return消息退回」为黄金组合,彻底杜绝生产者端消息丢失。
3.1.1 Channel 事务机制(同步方案,生产废弃)
1. 核心原理
RabbitMQ 支持原生 Channel 事务,通过事务的提交与回滚机制保证消息投递原子性:开启事务后,生产者发送的消息不会立即投递,仅暂存于本地事务缓存,只有执行事务提交,消息才会正式发送至MQ服务端;若投递过程出现异常,执行事务回滚,丢弃本次所有待发送消息,避免消息半投递、丢失问题。
2. 事务核心API
-
channel.txSelect():开启事务 -
channel.txCommit():提交事务,正式投递消息 -
channel.txRollback():回滚事务,丢弃缓存消息
3. 完整代码示例
java
// 1. 获取信道、开启事务
Channel channel = rabbitTemplate.getConnectionFactory().createConnection().createChannel(false);
channel.txSelect();
try {
// 2. 发送消息
channel.basicPublish("order.direct.exchange", "order.pay.key", null, "事务消息测试".getBytes(StandardCharsets.UTF_8));
// 3. 业务逻辑执行成功,提交事务
channel.txCommit();
} catch (Exception e) {
// 4. 出现异常,回滚事务,消息不投递
channel.txRollback();
e.printStackTrace();
} finally {
channel.close();
}4. 优缺点与生产选型
-
优点:实现简单,保证单会话消息投递原子性,无消息丢失风险
-
致命缺点:同步阻塞执行,每次投递都需等待事务确认,吞吐量极低(相比Confirm模式性能下降90%以上),不支持高并发场景
生产结论 :仅适用于极低频次、低并发的小众场景,互联网生产环境完全废弃,统一使用Publisher Confirm机制替代。
3.1.2 Publisher Confirm 发布确认(生产主流核心方案)
Confirm发布确认是RabbitMQ官方推荐的生产者消息可靠投递方案,核心逻辑:生产者发送消息后,MQ服务端接收消息并持久化成功后,主动回调告知生产者投递结果,生产者可根据确认结果做重试、日志记录、异常兜底,彻底解决投递丢失问题。
1. 三种确认模式(面试必背+生产选型)
-
NONE(默认关闭):关闭发布确认,发送消息后无需等待服务端响应,性能最高,但无法感知投递结果,存在消息丢失风险,生产核心业务禁用。
-
SIMPLE(单条同步确认):每发送一条消息,阻塞等待服务端ACK确认,成功后再发送下一条。安全性高,性能低,适用于少量核心消息投递。
-
CORRELATED(异步回调确认·企业首选):异步非阻塞模式,发送消息不阻塞业务线程,服务端确认后通过回调函数返回结果,性能与安全性兼顾,适配99%生产高并发场景。
2. 核心机制说明
服务端会返回两种确认结果:
-
ACK:消息成功接收、路由、持久化,投递成功
-
NACK:消息投递失败(服务端异常、内存溢出、磁盘满、路由异常),生产者需重试或兜底处理
3. SpringBoot 完整配置+落地代码(可直接上线)
第一步:配置文件开启异步确认
XML
spring:
rabbitmq:
# 开启发布确认-异步回调模式
publisher-confirm-type: correlated
# 开启消息退回机制
publisher-returns: true
# 开启 mandatory 强制路由,路由失败触发Return回调
template:
mandatory: true第二步:全局配置确认回调(统一处理成功/失败)
java
import org.springframework.amqp.core.ReturnedMessage;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.Resource;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
@Configuration
public class RabbitConfirmConfig {
@Resource
private ConnectionFactory connectionFactory;
// 缓存未确认消息,用于失败重试(生产核心兜底)
public static final Map<String, String> UN_CONFIRM_MSG_CACHE = new ConcurrentHashMap<>();
@Bean
public RabbitTemplate rabbitTemplate() {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
// 1. 发布确认回调(Confirm)
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
// 获取消息唯一ID
String msgId = correlationData != null ? correlationData.getId() : null;
if (ack) {
// 投递成功:清除缓存消息
UN_CONFIRM_MSG_CACHE.remove(msgId);
System.out.println("消息投递成功,消息ID:" + msgId);
} else {
// 投递失败:记录日志、重试投递、告警通知
String msgBody = UN_CONFIRM_MSG_CACHE.get(msgId);
System.err.println("消息投递失败,消息ID:" + msgId + ",失败原因:" + cause + ",消息内容:" + msgBody);
// 此处可拓展:定时重试、入库兜底、企业微信告警
}
});
return rabbitTemplate;
}
}第三步:生产者发送消息携带唯一ID
java
import org.springframework.amqp.core.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.UUID;
@Service
public class OrderMsgProducer {
@Resource
private RabbitTemplate rabbitTemplate;
public void sendOrderMsg(String msgContent) {
// 1. 生成全局唯一消息ID
String msgId = UUID.randomUUID().toString().replace("-", "");
CorrelationData correlationData = new CorrelationData(msgId);
// 2. 缓存待投递消息(兜底核心)
RabbitConfirmConfig.UN_CONFIRM_MSG_CACHE.put(msgId, msgContent);
// 3. 发送消息(指定交换机、路由键、消息体、确认ID)
rabbitTemplate.convertAndSend("order.direct.exchange", "order.pay.key", msgContent, correlationData);
}
}4. 生产核心规范
-
所有核心业务必须开启correlated异步确认模式
-
每条消息必须携带全局唯一ID,用于溯源、重试、幂等
-
未确认消息需内存缓存+持久化兜底,避免重试丢失
-
NACK失败消息禁止无限重试,需设置最大重试次数,超限入库人工处理
3.1.3 Publisher Return 消息退回机制(兜底防丢)
Confirm机制只能确认「消息是否到达交换机」,无法解决「交换机路由失败、无匹配队列」导致的消息丢失。Return消息退回机制专门兜底路由异常场景,是生产者端防丢失的最后一道防线。
1. 核心原理
配合 mandatory=true 参数使用:生产者发送消息时开启强制路由,若消息抵达交换机后,无匹配的队列(BindingKey不匹配、无绑定队列),消息不会直接丢弃,而是原路退回生产者,触发Return回调,由生产者自主处理重试、告警、保存兜底。
2. 核心参数说明
-
mandatory=true:开启强制路由,路由失败消息退回生产者
-
mandatory=false(默认):路由失败直接丢弃消息,生产核心业务禁用
-
immediate标志:3.0版本后已废弃,无需使用,不做兼容
3. 完整Return回调配置(接续上面Confirm配置)
java
// 在RabbitTemplate配置类中新增Return回调
rabbitTemplate.setReturnsCallback(returnedMessage -> {
// 获取退回消息详情
String exchange = returnedMessage.getExchange();
String routingKey = returnedMessage.getRoutingKey();
String msgBody = new String(returnedMessage.getMessage().getBody());
int replyCode = returnedMessage.getReplyCode();
String replyText = returnedMessage.getReplyText();
// 路由失败兜底处理:记录日志、入库、告警、手动重试
System.err.println("消息路由失败被退回!");
System.err.println("交换机:" + exchange + ",路由键:" + routingKey);
System.err.println("失败码:" + replyCode + ",失败原因:" + replyText);
System.err.println("消息内容:" + msgBody);
// 拓展:路由异常告警、消息入库保存、定时重试补偿
});3.1.4 生产者端防丢失终极黄金组合(生产100%落地)
单一机制无法彻底杜绝消息丢失,生产环境必须组合使用,实现全链路无死角防护:
-
基础保障:消息持久化(deliveryMode=2)+ 队列持久化,服务端落地存储
-
投递保障:开启Confirm异步确认,确保消息成功抵达交换机
-
路由保障:开启mandatory+Return回调,兜底路由失败消息
-
兜底保障:消息发送前本地缓存/入库,失败自动重试,超限人工介入
3.1.5 面试高频考点+坑点总结
-
坑1:Confirm只能确认到交换机,不能确认消息是否投递到队列、是否被消费
-
坑2:仅开Confirm不开Return,路由失败依然会丢消息
-
坑3:事务机制性能极差,高并发项目禁止使用
-
坑4:mandatory默认false,必须手动开启才能触发消息退回
-
面试简答:生产者防丢=异步Confirm确认+Return路由兜底+消息持久化+本地缓存重试
3.1.1 Channel 事务
- 支持事务提交/回滚,性能极低,生产基本废弃。
3.1.2 Publisher Confirm 发布确认(主流)
三种模式:
-
NONE:关闭确认
-
SIMPLE:单条同步确认
-
CORRELATED:异步回调确认(企业首选)
- 分类:单条确认、批量确认、异步监听确认。
3.1.3 Publisher Return 消息退回
-
配合
mandatory=true使用 -
场景:消息路由失败(无匹配队列),消息退回生产者
-
immediate标志:3.0 版本后已废弃,无需使用。
3.2 服务端防丢失
-
队列持久化:
durable = true -
消息持久化:
deliveryMode = 2 -
生产强制要求:队列+消息双持久化
3.3 消费者端防消息丢失、防重复消费(超全生产落地版)
3.3.1 消费者端消息丢失成因(核心根源)
消费者端消息丢失全部由ACK机制使用不当导致,生产高频3大丢失场景:
-
自动ACK机制丢消息:消费者接收消息、未执行业务逻辑,MQ已标记消息消费成功并删除,一旦程序报错、宕机,消息永久丢失。
-
手动ACK异常中断:业务代码执行报错,未执行Nack/Reject,也未执行ACK,会话断开后消息异常丢失。
-
消费超时被动ACK:业务处理耗时过长,超过consumer_timeout阈值,服务端自动判定消费失败、回收消息,极端场景触发消息丢失。
生产核心结论 :自动ACK是消费者消息丢失的最大元凶,核心业务强制禁用自动ACK。
3.3.2 ACK确认机制全解析(生产标准)
RabbitMQ消费者ACK分为自动ACK 和手动ACK两种模式,生产环境严格区分使用场景。
1. 自动ACK(AUTO)
-
机制 :MQ将消息推送给消费者后,立即标记消息消费成功并删除,无需等待业务执行结果。
-
优点:性能高、无需手动编码确认逻辑。
-
致命缺陷:无任何可靠性保障,业务未执行、程序宕机、代码报错都会导致消息永久丢失。
-
适用场景:日志上报、非核心统计、可丢失的弱一致性业务。
-
生产规范 :订单、支付、交易等核心业务绝对禁用。
2. 手动ACK(MANUAL·生产唯一推荐)
核心逻辑:业务执行成功才确认,业务失败拒绝消息,全程由开发者掌控消息生命周期,彻底杜绝消费者端丢消息。
手动ACK提供三大核心API,精准适配不同异常场景:
-
basicAck(正常确认):业务处理完全成功,告知MQ删除消息。 参数multiple:false=只确认当前单条;true=确认当前及之前所有未确认消息(批量确认)。
-
basicReject(单条拒绝):单条消息处理失败,仅拒绝当前消息。 参数requeue:true=消息重回队列重试;false=消息丢弃/进入死信队列。
-
basicNack(批量拒绝·生产首选):支持批量拒绝多条消息,适配批量消费异常场景,功能覆盖Reject,生产优先使用。 参数requeue:true=重回队列;false=丢弃/进死信。
3. 批量ACK风险与生产禁忌
开启multiple=true批量确认时,若中间某条消息消费失败,会导致前置正常消息重复消费、后置消息丢失,消息顺序错乱、数据异常。
生产规范 :核心交易、强一致性业务,禁止使用批量ACK,一律单条确认。
3.3.3 消费超时机制与避坑方案
1. 机制原理
RabbitMQ默认consumer_timeout=180000ms(3分钟),消费者获取消息后,若超过超时时间未执行任何ACK操作,服务端会自动回收消息、重新入队。
2. 生产风险
-
业务耗时过长(大文件处理、远程调用超时),触发被动重发,导致消息重复消费。
-
死循环代码阻塞消费,反复触发超时重试,造成消息无限循环堆积。
3. 解决方案
-
长耗时业务单独调大超时阈值,适配业务处理时长。
-
所有消费逻辑添加超时熔断,避免线程阻塞。
-
搭配死信队列,拦截超时重试超限的异常消息。
3.3.4 消费者防消息丢失 完整落地方案(黄金标准)
组合以下4点,实现消费者端零消息丢失,生产直接落地:
-
强制开启手动ACK,全局禁用自动ACK,掌控消息确认权。
-
业务成功才Ack:所有数据库操作、业务逻辑执行完毕、数据落库成功后,再执行手动确认。
-
异常精准Nack:代码异常、业务失败时,执行Nack拒绝,临时异常重回队列,永久异常转入死信。
-
禁止空消费、空拦截:所有异常必须主动处理,禁止捕获异常后不做ACK/Nack操作。
SpringBoot 完整手动ACK落地代码(生产可用)
java
import com.rabbitmq.client.Channel;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Service;
@Service
public class OrderConsumer {
/**
* 手动ACK消费者(生产核心模板)
* 监听业务队列,手动控制消息确认与重试
*/
@RabbitListener(queues = "order.business.queue")
public void consume(String msgBody, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag) {
try {
// 1. 执行业务核心逻辑(订单处理、数据落库、状态更新)
doBusiness(msgBody);
// 2. 业务执行成功,手动ACK确认,删除消息
// multiple=false:仅确认当前单条消息(核心业务禁止批量确认)
channel.basicAck(tag, false);
} catch (Exception e) {
// 3. 业务异常,拒绝消息,根据异常类型处理
e.printStackTrace();
// 临时异常(网络抖动、接口超时):重回队列重试
// 永久异常(数据非法、参数错误):requeue=false,进入死信队列
channel.basicNack(tag, false, false);
}
}
/**
* 模拟核心业务处理逻辑
*/
private void doBusiness(String msgBody) {
// 订单解析、数据校验、数据库操作、业务流转
}
}全局手动ACK配置(yml)
XML
spring:
rabbitmq:
listener:
simple:
# 全局开启手动ACK(生产强制配置)
acknowledge-mode: manual
# 合理配置预取值,避免消息堆积与重复消费
prefetch: 10
# 消费超时适配长耗时业务
consumer-timeout: 3000003.3.5 消息重复消费成因(生产高频)
MQ本身不保证消息唯一消费,仅保证至少一次消费(At-Least-Once),重复消费100%由以下场景导致:
-
ACK超时未返回:业务执行成功,但ACK响应超时、网络抖动未送达MQ,服务端重新推送消息。
-
手动重试触发:业务异常Nack重回队列,重试消费导致重复执行。
-
集群故障切换:主节点宕机、主从切换,未确认消息被从节点重新推送。
-
生产者重试机制:生产者Confirm超时、投递失败重试,生成重复消息。
-
批量消费异常:批量ACK参数使用不当,导致消息回溯重发。
核心结论 :生产环境必须做消费幂等,否则100%出现数据重复、数据错乱、对账异常问题。
3.3.6 消费者防重复消费(幂等)全套生产方案
按业务优先级从「低成本→高可靠」排序,覆盖所有生产场景,可直接选型落地。
方案一:全局唯一ID判重(通用万能方案)
原理
生产者每条消息携带全局唯一MessageID,消费者消费前先查询是否已消费,已消费则直接拦截,未消费则执行业务+记录消费记录。
落地实现(Redis分布式锁+去重,高性能)
java
@Service
public class IdempotentConsumer {
@Resource
private RedisTemplate<String, String> redisTemplate;
// 消息消费记录过期时间(适配业务数据有效期)
private static final Long MSG_EXPIRE_TIME = 24 * 3600L;
@RabbitListener(queues = "order.business.queue")
public void consume(String msgBody, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag, @Header("messageId") String messageId) {
try {
// 1. 幂等校验:判断消息是否已消费
String key = "mq:consume:" + messageId;
Boolean isFirst = redisTemplate.opsForValue().setIfAbsent(key, "1", MSG_EXPIRE_TIME, TimeUnit.SECONDS);
if (!Boolean.TRUE.equals(isFirst)) {
// 重复消息,直接确认丢弃,不执行业务
channel.basicAck(tag, false);
return;
}
// 2. 首次消费,执行业务逻辑
doBusiness(msgBody);
// 3. 业务成功确认
channel.basicAck(tag, false);
} catch (Exception e) {
e.printStackTrace();
// 异常消息转入死信队列
try {
channel.basicNack(tag, false, false);
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
private void doBusiness(String msgBody) {
// 核心业务处理
}
}方案二:业务唯一主键幂等(数据库场景首选)
原理
依托业务天然唯一标识(订单号、支付流水号、用户单号),数据库添加唯一索引,重复消费插入/更新直接报错拦截,无额外缓存开销。
适用场景
订单创建、支付记录、交易流水、积分发放等有唯一业务单号的场景。
核心优势
数据级兜底,杜绝任何重复写入,一致性最高,无需依赖Redis,无缓存失效问题。
方案三:业务状态机幂等(复杂业务首选)
原理
业务数据自带状态(待处理、已处理、处理中、失败),消费前判断状态,已完成状态直接拦截,仅处理待处理状态。
场景适配
订单状态流转、退款流程、多级审批等有明确状态流转的复杂业务。
示例逻辑
-
消息消费→查询订单状态
-
状态=已支付/已处理:直接ACK拦截,不重复执行
-
状态=待处理:执行业务+更新状态
方案四:本地重试幂等兜底(轻量场景)
结合Spring Retry本地重试,重试过程中通过内存缓存+业务状态拦截重复执行,适配低并发、简单业务场景。
3.3.7 重试机制防重复、防死循环规范
1. 重试分级策略(生产标准)
-
临时异常(网络抖动、接口超时、数据库瞬时锁):允许有限次数重试(3~5次),间隔递增。
-
永久异常(参数错误、数据不存在、格式非法):禁止重试,直接转入死信队列。
2. 无限重试坑点规避
无限制重试会导致消息无限堆积、服务卡死,生产必须配置:最大重试次数+重试间隔+死信兜底。
3.3.8 消费者端终极防护总结(面试+生产背诵)
1. 防消息丢失四件套
手动ACK + 业务成功再确认 + 异常Nack兜底 + 超时机制优化
2. 防重复消费三板斧
消息唯一ID+Redis去重(通用) + 业务唯一索引(兜底) + 状态机拦截(复杂业务)
3. 面试高频简答
-
消费者丢消息原因:自动ACK、业务异常未确认、消费超时。
-
消费者重复原因:ACK超时、故障切换、生产者重试、异常重发。
-
核心解决方案:手动ACK保证可靠消费,多重幂等方案杜绝重复执行业务。
第四部分 高级特性(业务高阶场景)
4.1 死信队列 DLX(完整版·原理+配置+代码+重试模型+坑点)
4.1.1 死信队列核心概念
DLX(Dead Letter Exchange,死信交换机):并非特殊类型交换机,本质是一台普通交换机,专门用于接收「失效、异常、无法正常消费」的消息。
死信队列:绑定在死信交换机上的普通队列,用于存储死信消息,等待后续人工排查、定时重试或兜底处理。
死信消息:正常业务消息因各类条件不满足,被原队列判定为失效,自动转发至死信队列的消息。
4.1.2 消息成为死信的三大核心条件(必考)
满足以下任意一种条件,队列中的消息会自动变为死信,触发转发机制:
-
消费拒绝且不重试 :消费者执行
basicNack/basicReject,且requeue=false,消息不重回原队列 -
消息TTL过期:消息单独设置过期时间 或 队列统一TTL,消息超时未被消费
-
队列容量溢出:队列达到最大消息长度(x-max-length),新增消息挤压旧消息,溢出消息变为死信
4.1.3 死信转发核心规则(生产必避坑)
-
路由键继承 :死信消息转发时,会沿用原消息的
routingKey,不会自动变更,需提前匹配死信队列绑定规则 -
TTL优先级规则:消息级TTL(x-message-ttl)> 队列级TTL,同时配置时,以更小的过期时间为准
-
禁止循环死信 :死信队列绝对不能配置DLX,否则消息会在原队列和死信队列之间无限循环,造成消息雪崩
-
交换机无消息存储:死信仅能被转发至绑定队列,若无匹配死信队列,死信消息直接丢失
-
仅队列内消息可转为死信:未路由到队列、直接被丢弃的消息,无法进入死信队列
-
死信路由键沿用原消息 routingKey
-
TTL 优先级:消息TTL > 队列TTL,同时设置取最小值
-
避坑:禁止死信队列再配置 DLX,防止循环转发
4.1.4 死信队列核心应用场景(生产全覆盖)
-
异常消息兜底隔离:拦截参数错误、业务非法、重试失败的异常消息,避免无效消息堆积正常业务队列
-
实现延时任务:TTL过期+死信转发,低成本实现订单超时关闭、退款倒计时、活动到期结束等延时场景
-
消息重试降级:本地重试耗尽后,异常消息转入死信队列,人工排查+定时任务补偿重试
-
业务故障溯源:归档所有消费失败消息,用于线上问题排查、数据对账、业务异常复盘
-
队列限流兜底:高并发场景队列溢出时,保存溢出消息,避免直接丢失核心业务数据
4.1.5 完整搭建流程(标准生产架构)
死信队列架构由「业务队列+业务交换机+死信交换机+死信队列」四部分组成,标准搭建步骤:
-
创建死信交换机(普通Direct/Topic交换机,推荐Direct精准路由)
-
创建死信队列(独立队列,专门存储异常消息)
-
绑定死信交换机与死信队列,配置固定路由键
-
声明业务队列,配置队列参数:绑定死信交换机、指定死信路由键
-
业务交换机绑定业务队列,完成整体链路搭建
完整消息流转链路:生产者→业务交换机→业务队列→消费异常/超时/溢出→转发至死信交换机→死信队列→人工/定时补偿消费
4.2 延时队列(完整版·原理+双方案+生产代码+坑点+面试必背)
延时队列核心定义 :延时队列是一种消息发送后不立即消费,等待指定时长后自动触发消费 的高阶业务队列,核心用于处理定时、延迟执行的业务场景,是互联网项目刚需功能。
核心业务场景(生产高频):订单超时自动关闭、支付超时取消、退款倒计时、活动到期结束、用户未操作提醒、定时任务触发、超时未跟进工单处理。
RabbitMQ 无原生正统延时队列,行业通用两套落地方案:TTL+死信队列(无插件通用方案) 、延时交换机插件(高精度企业方案),以下为两套方案完整落地教程、优缺点对比、生产避坑。
4.2.1 方案一:TTL + 死信队列 延时方案(零插件、通用)
该方案依托 RabbitMQ 原生 TTL 过期机制 + 死信转发机制实现延时效果,无需安装任何第三方插件,开箱即用,适配中小延时、低精度业务场景。
1. 核心原理
创建普通业务延时队列,为队列/消息设置过期时间,消息在队列中等待过期;超时未消费的消息自动变为死信,被转发至死信交换机,最终路由到死信队列,消费者监听死信队列实现延时消费。
2. 两种TTL过期配置方式
-
队列级TTL(全局统一过期时间) :通过
x-message-ttl给队列所有消息设置统一过期时长,队列内所有消息延时时间一致,配置简单、性能高。 -
消息级TTL(单消息自定义过期):生产者发送消息时单独设置过期时间,不同消息可配置不同延时时长,灵活性更高。
TTL优先级铁律(面试必考):消息级TTL > 队列级TTL,同时配置时,以消息更小的过期时间为准。
3. 完整架构链路
生产者发送延时消息 → 业务延时队列(等待TTL过期)→ 消息超时变为死信 → 死信交换机路由 → 死信队列 → 消费者监听执行延时业务
4. SpringBoot 完整可运行配置代码
java
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
/**
* TTL+死信 延时队列配置
* 无插件通用延时方案,适配订单超时、定时提醒
*/
@Configuration
public class TtlDelayQueueConfig {
// ===================== 死信交换机、死信队列配置 =====================
@Bean
public DirectExchange delayDlxExchange() {
return ExchangeBuilder.directExchange("delay.dlx.direct.exchange")
.durable(true)
.build();
}
@Bean
public Queue delayDlxQueue() {
return QueueBuilder.durable("delay.dlx.queue").build();
}
@Bean
public Binding delayDlxBinding() {
return BindingBuilder.bind(delayDlxQueue())
.to(delayDlxExchange())
.with("delay.dlx.routing.key");
}
// ===================== 业务延时队列配置(队列级TTL:统一30秒延时) =====================
@Bean
public Queue orderTtlDelayQueue() {
Map<String, Object> args = new HashMap<>();
// 队列统一TTL:30秒过期
args.put("x-message-ttl", 30000);
// 绑定死信交换机
args.put("x-dead-letter-exchange", "delay.dlx.direct.exchange");
args.put("x-dead-letter-routing-key", "delay.dlx.routing.key");
return new Queue("order.ttl.delay.queue", true, false, false, args);
}
@Bean
public DirectExchange orderDelayExchange() {
return ExchangeBuilder.directExchange("order.delay.exchange")
.durable(true)
.build();
}
@Bean
public Binding orderDelayBinding() {
return BindingBuilder.bind(orderTtlDelayQueue())
.to(orderDelayExchange())
.with("order.delay.routing.key");
}
}5. 生产者发送消息(支持消息级自定义延时)
java
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessagePostProcessor;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class DelayMessageProducer {
@Resource
private RabbitTemplate rabbitTemplate;
/**
* 发送自定义延时消息(消息级TTL,灵活适配不同延时场景)
* @param msg 业务消息
* @param delayTime 延时时间(毫秒)
*/
public void sendCustomDelayMsg(String msg, long delayTime) {
// 消息后置处理器,设置单消息过期时间
MessagePostProcessor postProcessor = message -> {
// 设置消息TTL,自定义延时时长
message.getMessageProperties().setExpiration(String.valueOf(delayTime));
return message;
};
rabbitTemplate.convertAndSend("order.delay.exchange", "order.delay.routing.key", msg, postProcessor);
}
}6. 核心优缺点 & 生产坑点(必避)
优点
-
零插件依赖、原生支持、兼容性极强,所有RabbitMQ版本通用
-
配置简单、运维成本低、无额外部署风险
-
适配低精度延时场景(误差1~3秒可接受)
致命缺点(生产最大坑)
-
延时不准、存在消息阻塞问题 :RabbitMQ 仅校验队首消息是否过期,若队首消息延时10分钟、队尾消息延时30秒,队尾消息必须等待队首消息过期后才能触发转发,导致短延时消息严重超时。
-
不支持动态无序延时,队列内消息必须按顺序过期
-
消息堆积场景下,延时误差成倍放大
适用场景
延时时长固定、允许轻微误差、低并发的延时业务,如普通订单超时关闭、简单定时提醒。
4.2.2 方案二:延时交换机插件 rabbitmq_delayed_message_exchange(高精度方案)
该方案是企业生产主流高精度延时方案,通过官方延时插件实现,突破原生TTL队列的顺序阻塞问题,支持任意时长、无序、精准延时,是高要求延时业务首选。
1. 插件核心介绍
-
插件名称:
rabbitmq_delayed_message_exchange -
交换机专属类型:
x-delayed-message -
核心原理:消息发送至延时交换机后,交换机层面暂存消息,不立即推入队列,等待设定延时时间结束后,再路由分发至对应业务队列,彻底规避队列顺序阻塞问题。
2. 插件部署步骤(生产落地)
-
下载与RabbitMQ版本匹配的插件包(.ez格式)
-
将插件放入MQ插件目录
plugins -
执行启用命令:
rabbitmq-plugins enable rabbitmq_delayed_message_exchange -
重启RabbitMQ服务,控制台可看到新增延时交换机类型
3. 完整架构链路
生产者发送带延时参数消息 → 延时交换机(暂存消息、倒计时)→ 延时结束 → 交换机路由消息至业务队列 → 消费者即时消费
4. SpringBoot 生产级配置代码
java
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
/**
* 延时插件交换机配置(高精度延时方案·生产首选)
*/
@Configuration
public class DelayedExchangeConfig {
// 自定义延时交换机
@Bean
public CustomExchange preciseDelayExchange() {
Map<String, Object> args = new HashMap<>();
// 指定交换机类型为延时交换机,底层基于direct路由
args.put("x-delayed-type", "direct");
// 声明延时交换机
return new CustomExchange("precise.delay.exchange", "x-delayed-message", true, false, args);
}
// 延时业务队列
@Bean
public Queue preciseDelayQueue() {
return QueueBuilder.durable("precise.delay.queue").build();
}
// 绑定交换机与队列
@Bean
public Binding preciseDelayBinding() {
return BindingBuilder.bind(preciseDelayQueue())
.to(preciseDelayExchange())
.with("precise.delay.routing.key")
.noargs();
}
}5. 生产者发送高精度延时消息
java
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessagePostProcessor;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class PreciseDelayMsgProducer {
@Resource
private RabbitTemplate rabbitTemplate;
/**
* 发送高精度延时消息
* @param content 业务消息内容
* @param delayTime 延时时间(毫秒)
*/
public void sendPreciseDelayMsg(String content, long delayTime) {
MessagePostProcessor processor = message -> {
// 设置消息延时时长,交换机层面倒计时
message.getMessageProperties().setHeader("x-delay", delayTime);
return message;
};
// 发送消息至延时交换机
rabbitTemplate.convertAndSend("precise.delay.exchange", "precise.delay.routing.key", content, processor);
}
}6. 核心优缺点
优点
-
延时精准、无顺序阻塞:交换机层面倒计时,无序消息互不影响,支持任意时长延时
-
适配高并发、多延时混合场景,性能稳定
-
配置简洁,无需维护多余死信队列,链路更简单
缺点
-
需要额外安装插件,低版本MQ可能不兼容
-
延时消息会占用交换机内存,超大批量延时消息会轻微消耗服务性能
适用场景
订单超时、支付倒计时、精准定时任务、高并发延时、多混合延时时长的核心业务场景(生产主流选型)。
4.2.3 两种延时方案 终极对比表(面试必背)
|--------|---------------|-----------------|
| 对比维度 | TTL+死信队列方案 | 延时交换机插件方案 |
| 插件依赖 | 无、原生支持 | 需安装延时插件 |
| 延时精度 | 低,队列阻塞导致误差大 | 极高,无顺序阻塞 |
| 消息处理层级 | 队列层面过期转发 | 交换机层面倒计时 |
| 无序延时支持 | 不支持,必须按队列顺序过期 | 完美支持任意无序延时 |
| 架构复杂度 | 高,需维护两套队列+交换机 | 低,单交换机+单队列 |
| 并发性能 | 低,堆积场景极易出问题 | 高,适配生产高并发 |
| 生产选型 | 测试环境、低精度非核心业务 | 正式生产、核心延时业务(首选) |
4.2.4 延时队列生产终极避坑指南
-
坑1:TTL+死信方案绝对不能用于混合延时场景,长短延时消息共存必然导致短延时消息超时失效
-
坑2:延时插件消息依赖内存缓存,MQ重启后,未过期的延时消息会丢失,核心业务需搭配消息持久化
-
坑3:延时时间不能设置过长,超大时长延时消息长期占用内存,影响服务性能
-
坑4:禁止给死信队列配置TTL和DLX,避免延时消息循环转发、无限堆积
-
坑5:消息级TTL优先级高于队列级,混用会导致延时时间不生效,需统一配置规则
4.2.5 延时队列面试高频简答
-
1、TTL延时队列为什么延时不准? 原生队列仅校验队首消息是否过期,队首长延时消息会阻塞队尾短延时消息,导致延时失效、误差增大。
-
2、两种延时方案如何选型? 无插件、低精度、测试场景用TTL+死信;生产核心、高精度、高并发场景必用延时交换机插件。
-
3、延时插件原理是什么? 自定义延时交换机暂存消息,内部倒计时,延时结束后再路由至业务队列消费,规避队列顺序阻塞问题。
4.3 优先级队列(完整版·原理+代码+限制+生产避坑+面试必背)
4.3.1 优先级队列核心定义
RabbitMQ 优先级队列是一种支持消息权重排序消费的特殊功能队列,允许为不同消息设置不同优先级,高优先级消息优先被消费者消费,低优先级消息延后消费,适用于业务加急、紧急工单、VIP用户优先处理等差异化业务场景。
核心本质:队列在服务端内部维护消息优先级排序,打破默认的「先进先出(FIFO)」规则,实现权重优先、插队消费。
4.3.2 核心参数与优先级规则
-
队列核心参数 :通过队列拓展参数
x-max-priority开启优先级队列,指定当前队列支持的最大优先级数值 -
优先级取值范围 :0 ~ 255(整数),数值越大,优先级越高
-
默认优先级:未单独设置优先级的消息,默认优先级为 0(最低优先级)
-
排序规则:队列内消息按优先级倒序排列,同优先级消息遵循先进先出规则
4.3.3 严格生效条件(生产最核心必考限制)
优先级队列并非随时生效,存在严格使用限制,不满足条件则优先级完全失效,是生产高频踩坑点:
- 核心条件1:仅单消费者模式生效若队列配置多个消费者,RabbitMQ 会开启消费者轮询分发机制,消息提前预分发至各个消费者缓存,服务端无法重新排序,优先级彻底失效
核心条件2:消费者 prefetch 不能过度堆积prefetch 预取值过大,会导致大量消息提前推送到消费者本地缓存,服务端队列无剩余消息,无法触发优先级排序
核心条件3:消息堆积状态下优先级才会体现队列无消息堆积、消息即发即消时,高优先级消息无法插队,优先级特性无实际意义
4.3.4 SpringBoot 完整生产配置代码
包含优先级队列声明、交换机绑定、高/低优先级消息发送完整代码,可直接复制落地。
java
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
/**
* 优先级队列完整配置类
* 适用:加急业务、VIP优先、紧急工单场景
*/
@Configuration
public class PriorityQueueConfig {
// 1. 声明优先级专属直连交换机
@Bean
public DirectExchange priorityExchange() {
return ExchangeBuilder.directExchange("business.priority.exchange")
.durable(true)
.build();
}
// 2. 声明优先级队列,设置最大优先级255
@Bean
public Queue businessPriorityQueue() {
Map<String, Object> args = new HashMap<>();
// 开启优先级队列,最大优先级255
args.put("x-max-priority", 255);
// 生产规范:持久化、非独占、常驻队列
return new Queue("business.priority.queue", true, false, false, args);
}
// 3. 绑定交换机与优先级队列
@Bean
public Binding priorityQueueBinding() {
return BindingBuilder.bind(businessPriorityQueue())
.to(priorityExchange())
.with("business.priority.routing.key");
}
}4.3.5 消息发送:自定义优先级代码
java
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class PriorityMessageProducer {
@Resource
private RabbitTemplate rabbitTemplate;
/**
* 发送优先级消息
* @param content 业务消息内容
* @param priority 优先级 0-255,数值越大优先级越高
*/
public void sendPriorityMsg(String content, Integer priority) {
rabbitTemplate.convertAndSend("business.priority.exchange",
"business.priority.routing.key",
content,
message -> {
// 设置消息优先级
message.getMessageProperties().setPriority(priority);
return message;
});
}
// 快捷方法:发送高优先级紧急消息
public void sendHighPriorityMsg(String content) {
sendPriorityMsg(content, 200);
}
// 快捷方法:发送普通优先级消息(默认0)
public void sendNormalPriorityMsg(String content) {
sendPriorityMsg(content, 0);
}
}4.3.6 生产核心坑点(必避)
-
坑1:多消费者场景优先级失效 优先级队列必须配置单个消费者,多消费者轮询消费会导致插队机制完全失效,生产加急业务务必单消费者部署
-
坑2:x-max-priority 配置后不可修改队列创建后,最大优先级数值无法修改,如需调整必须删除重建队列,上线前需提前确定优先级区间
-
坑3:优先级数值超限报错消息优先级超出 0~255 范围,消息会被直接丢弃,无任何异常提示
-
坑4:prefetch 值过大导致优先级失效消费者预取值过大,大量消息被提前拉取到本地,服务端无法排序,建议优先级队列 prefetch 设置为1~10(小预取值)
-
坑5:无堆积场景无优先级意义 队列实时消费、无消息积压时,高低优先级消息无先后区别,优先级队列仅适用于存在消息堆积的业务场景
4.3.7 适用业务场景
-
VIP用户订单优先处理、付费业务插队执行
-
系统紧急告警、故障应急消息优先推送
-
紧急工单、加急任务优先消费处理
-
核心业务消息优先于普通日志、通知类消息消费
4.3.8 生产最佳实践
-
优先级队列强制单消费者部署,关闭多实例负载均衡消费
-
合理设置 prefetch 预取值,避免消费者本地消息堆积
-
统一业务优先级规范:0-50普通业务、51-150加急业务、151-255紧急业务
-
优先级队列独立部署、独立配置,不与普通业务队列混用
-
核心紧急消息搭配消息持久化+手动ACK,保证高可靠
4.3.9 面试高频简答
-
**1、优先级队列优先级一定生效吗?**不一定,仅单消费者、小prefetch、队列存在消息堆积三个条件同时满足才会生效,多消费者场景完全失效。
-
**2、优先级取值范围和规则?**0~255,数值越大优先级越高,未设置默认0,超出范围消息丢失。
-
**3、优先级队列为什么不适合多消费者?**多消费者采用轮询分发,消息提前预加载至消费者本地,服务端无法重新排序,插队逻辑失效。
4.4 RPC 同步调用模式(完整版·原理+代码+坑点+生产实践)
RabbitMQ 并非专为 RPC(远程过程调用)设计,但可通过临时回复队列+消息关联标识 实现同步调用效果,满足跨服务同步查询、远程方法调用场景,是微服务简单同步通信的轻量化解决方案。区别于MQ主流的异步解耦模式,RPC模式核心是发消息后阻塞等待消费结果返回。
4.4.1 核心核心组成与原理
RPC同步调用依托两个核心消息属性实现请求与响应精准匹配,彻底解决多请求响应错乱问题:
-
correlationId(关联ID):全局唯一消息ID,每次RPC请求生成唯一值,用于绑定「请求消息+响应结果」,防止多请求结果错乱匹配
-
replyTo(回复队列) :生产者指定的临时回调队列,消费者处理完业务后,将执行结果发送至该队列,实现结果回传
核心原理:生产者发送带唯一ID和回调队列的请求消息 → 消费者处理业务 → 消费者根据消息属性,将结果回调至指定队列 → 生产者监听回调队列,匹配对应ID获取结果,完成同步调用。
4.4.2 完整RPC调用流程(标准6步)
-
生产者初始化临时队列:创建独占、自动删除、非持久化的临时回调队列,用于接收响应结果
-
生成唯一关联ID:为本次RPC请求生成全局唯一correlationId,绑定请求与响应
-
发送RPC请求消息:消息携带correlationId、replyTo(回调队列名)、业务请求参数,发送至服务端请求队列
-
消费者处理业务:监听请求队列,接收消息、执行业务逻辑、生成返回结果
-
消费者回调结果:通过消息的replyTo属性获取回调队列,将结果+原correlationId发送至回调队列
-
生产者接收结果:监听临时回调队列,匹配correlationId,获取对应结果,结束阻塞,完成同步调用
4.4.3 SpringBoot 生产完整实战代码
包含:RPC请求队列配置、生产者同步调用(阻塞等待)、消费者业务处理、结果回调全套可运行代码。
1. RPC队列配置类
java
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* RabbitMQ RPC同步调用队列配置
*/
@Configuration
public class RpcQueueConfig {
// RPC业务请求队列(常驻队列,消费者持续监听)
@Bean
public Queue rpcRequestQueue() {
return QueueBuilder.durable("rpc.request.queue").build();
}
// RPC请求直连交换机
@Bean
public DirectExchange rpcRequestExchange() {
return ExchangeBuilder.directExchange("rpc.request.exchange")
.durable(true)
.build();
}
// 绑定交换机与请求队列
@Bean
public Binding rpcRequestBinding() {
return BindingBuilder.bind(rpcRequestQueue())
.to(rpcRequestExchange())
.with("rpc.request.routing.key");
}
}2. RPC生产者(同步阻塞调用)
java
import org.springframework.amqp.core.*;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer;
import org.springframework.stereotype.Service;
import java.util.UUID;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
@Service
public class RpcProducerService {
private final RabbitTemplate rabbitTemplate;
private final ConnectionFactory connectionFactory;
public RpcProducerService(RabbitTemplate rabbitTemplate, ConnectionFactory connectionFactory) {
this.rabbitTemplate = rabbitTemplate;
this.connectionFactory = connectionFactory;
}
/**
* RPC同步调用核心方法
* @param requestParam 业务请求参数
* @return 消费者返回的业务结果
* @throws InterruptedException 超时异常
*/
public String rpcSyncCall(String requestParam) throws InterruptedException {
// 1. 生成全局唯一关联ID
String correlationId = UUID.randomUUID().toString();
// 2. 创建临时回调队列:独占、自动删除、非持久化
Queue tempReplyQueue = new Queue(UUID.randomUUID().toString(), false, true, true);
// 3. 定义计数器,阻塞主线程,等待结果返回
CountDownLatch latch = new CountDownLatch(1);
final String[] result = {null};
// 4. 初始化监听容器,监听临时回调队列
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer(connectionFactory);
container.setQueueNames(tempReplyQueue.getName());
container.setAutoStartup(true);
// 手动ACK,保证结果可靠接收
container.setAcknowledgeMode(AcknowledgeMode.MANUAL);
// 5. 消息监听处理
container.setMessageListener((message, channel) -> {
// 匹配关联ID,防止结果错乱
String msgCorrelationId = message.getMessageProperties().getCorrelationId();
if (correlationId.equals(msgCorrelationId)) {
// 获取回调结果
result[0] = new String(message.getBody());
latch.countDown();
}
// 手动ACK确认消息
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
});
container.start();
// 6. 构建消息属性,绑定关联ID和回调队列
MessageProperties properties = new MessageProperties();
properties.setCorrelationId(correlationId);
// 指定结果回调队列
properties.setReplyTo(tempReplyQueue.getName());
Message msg = new Message(requestParam.getBytes(), properties);
// 7. 发送RPC请求消息
rabbitTemplate.send("rpc.request.exchange", "rpc.request.routing.key", msg);
// 8. 阻塞等待结果(设置30秒超时,防止无限阻塞)
boolean await = latch.await(30, TimeUnit.SECONDS);
// 停止监听容器,释放资源
container.stop();
if (!await) {
throw new RuntimeException("RPC同步调用超时,请求参数:" + requestParam);
}
return result[0];
}
}}
3. RPC消费者(业务处理+结果回调)
java
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class RpcConsumerService {
@Resource
private RabbitTemplate rabbitTemplate;
/**
* 监听RPC请求队列,处理同步请求并回调结果
*/
@RabbitListener(queues = "rpc.request.queue")
public void handleRpcRequest(Message message) {
// 1. 获取消息核心属性
String correlationId = message.getMessageProperties().getCorrelationId();
String replyToQueue = message.getMessageProperties().getReplyTo();
// 解析业务请求参数
String requestParam = new String(message.getBody());
// 2. 执行业务逻辑(模拟远程方法调用)
String responseResult = handleBusinessLogic(requestParam);
// 3. 将结果回调至生产者指定的临时队列
rabbitTemplate.convertAndSend(replyToQueue, responseResult, msg -> {
// 绑定相同关联ID,保证精准匹配
msg.getMessageProperties().setCorrelationId(correlationId);
return msg;
});
}
/**
* 模拟远程业务处理逻辑
*/
private String handleBusinessLogic(String requestParam) {
// 自定义业务处理,如查询数据、远程计算等
return "RPC调用成功,入参:" + requestParam + ",处理时间:" + System.currentTimeMillis();
}
}4.4.4 核心特性与优势
-
轻量化无依赖:无需集成Dubbo、Feign等RPC框架,基于原生RabbitMQ实现同步调用
-
跨服务适配性强:支持跨语言、跨微服务同步通信,适配异构服务架构
-
资源自动回收:临时回调队列独占+自动删除,调用结束、连接断开后自动销毁,无资源残留
-
请求精准匹配:通过唯一correlationId彻底解决多并发RPC请求结果错乱问题
4.4.5 生产致命坑点(必避)
-
坑1:无超时机制导致线程阻塞:生产者未设置超时时间,消费者宕机、消息丢失时,主线程永久阻塞,引发服务线程池耗尽
-
坑2:未使用唯一correlationId导致结果错乱:高并发多RPC请求场景,无唯一ID绑定会出现请求与结果不匹配的严重问题
-
坑3:频繁创建临时队列引发性能损耗:高频RPC调用频繁创建销毁临时队列、监听容器,会消耗大量内存与CPU资源
-
坑4:不支持批量调用:单队列单请求匹配,批量同步调用效率极低
-
坑5:MQ原生异步设计,同步调用违背设计初衷:无法发挥MQ削峰、异步解耦核心优势,高并发场景吞吐量极低
4.4.6 生产最佳实践与选型规范
适用场景(仅低并发、简单同步场景)
-
低频跨服务简单查询、轻量远程方法调用
-
临时同步通信需求,不想引入额外RPC框架
-
异构系统简单同步交互场景
禁止使用场景
-
高并发、高吞吐同步业务
-
核心交易、高性能要求的远程调用
-
频繁、批量的跨服务通信
生产优化方案
-
强制配置超时时间:所有RPC调用必须设置超时阈值,避免线程阻塞
-
复用回调队列:高并发场景放弃临时队列,复用固定回调队列,减少资源创建销毁开销
-
优先专业RPC框架:正式生产同步调用优先使用 Dubbo、gRPC、OpenFeign,RabbitMQ RPC仅做临时兜底方案
-
异常兜底处理:捕获超时、消息丢失、消费异常,返回统一失败结果,避免业务报错
4.4.7 面试高频简答(必背)
-
**1、RabbitMQ RPC模式核心原理?**通过correlationId唯一关联请求与响应,replyTo指定临时回调队列,生产者阻塞监听回调队列,消费者处理完业务后回传结果,实现同步调用。
-
**2、为什么不推荐生产高并发场景用MQ的RPC模式?**MQ是异步消息中间件,同步调用会阻塞线程、吞吐量低、频繁创建临时队列损耗性能,且存在线程阻塞风险,专业同步场景优先使用RPC框架。
-
**3、RPC模式如何解决多请求结果错乱问题?**依靠全局唯一的correlationId关联每一次请求和响应,消费者回调时携带相同ID,生产者精准匹配对应结果。
-
**4、RPC临时队列的特性?**独占、非持久、自动删除,仅当前生产者连接可访问,连接断开后队列自动销毁,无需手动维护。
4.5 消息压缩(生产大消息优化核心)
RabbitMQ 消息默认以原生二进制或JSON格式传输存储,当消息体过大(超过10KB)时,会出现网络传输慢、磁盘占用高、IO压力大、集群同步延迟等问题。消息压缩是生产环境优化大消息场景的核心手段,通过GZIP、LZ4等压缩算法对消息体编码压缩,大幅缩减消息体积,兼顾传输性能与存储成本。
4.5.1 消息压缩核心原理
消息压缩全程对业务无侵入,核心流程:
-
生产者压缩:消息发送前,对JSON/字符串业务消息体进行算法压缩,同时在消息Header中标记压缩格式;
-
传输存储:压缩后的小体积消息在网络传输、磁盘持久化,降低资源开销;
-
消费者解压:消费消息时读取Header压缩标识,自动对应算法解压,还原原始业务数据;
核心特点:仅压缩消息Body体,不修改消息元属性,不影响路由、ACK、持久化等原有机制。
4.5.2 主流压缩算法选型对比(生产必选)
|-------------|--------------|------------|------------------------|
| 压缩算法 | 压缩率 | 压缩/解压速度 | 生产适用场景 |
| LZ4 | 中等(50%~60%) | 极快,内存开销小 | 高并发、实时性要求高的大消息场景(生产首选) |
| GZIP | 高(70%~80%) | 较慢,CPU消耗略高 | 非实时、超大消息、追求极致存储压缩比场景 |
| Deflate | 中高 | 中等 | 通用兼容场景,无特殊性能要求 |
生产选型口诀:高并发实时选LZ4,超大文件归档选GZIP。
4.5.3 SpringBoot 全局消息压缩配置(可直接落地)
Spring AMQP 原生支持消息压缩,无需手动编码压缩解压,全局配置后自动对所有消息生效,支持GZIP/LZ4。
1. 引入压缩依赖
XML
<!-- LZ4高性能压缩依赖(推荐) -->
<dependency>
<groupId>org.lz4</groupId>
<artifactId>lz4-java</artifactId>
<version>1.8.0</version>
</dependency>2. 全局压缩配置类
java
import org.springframework.amqp.core.MessageProperties;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* RabbitMQ 消息压缩全局配置
* 适配大消息场景,自动压缩解压、业务无侵入
*/
@Configuration
public class RabbitCompressConfig {
@Bean
public RabbitTemplate rabbitTemplate(RabbitTemplate rabbitTemplate) {
// 设置JSON序列化转换器
rabbitTemplate.setMessageConverter(new Jackson2JsonMessageConverter());
// 开启全局消息压缩:LZ4算法,阈值10KB(超过自动压缩)
rabbitTemplate.setCompressorType(MessageProperties.CompressorType.LZ4);
// 压缩阈值:消息体大于10240字节(10KB)自动触发压缩,小消息无需压缩避免性能损耗
rabbitTemplate.setCompressionThreshold(10240);
return rabbitTemplate;
}
}4.5.4 手动动态压缩代码(特殊场景适配)
针对部分超大消息、特殊业务场景,可手动指定消息压缩,灵活适配个性化需求。
java
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessageProperties;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class CompressMessageProducer {
@Resource
private RabbitTemplate rabbitTemplate;
/**
* 手动发送GZIP压缩大消息
*/
public void sendCompressBigMessage(String exchange, String routingKey, String bigContent) {
rabbitTemplate.convertAndSend(exchange, routingKey, bigContent, message -> {
// 手动指定GZIP压缩
message.getMessageProperties().setCompressorType(MessageProperties.CompressorType.GZIP);
return message;
});
}
}4.5.5 消息压缩生产适用与禁用场景
✅ 必须开启压缩场景
-
单条消息体大于10KB的大消息(批量数据、报表、日志、详情数据)
-
高吞吐海量消息场景,需减少网络带宽占用
-
集群多节点同步、跨机房传输消息场景
-
磁盘存储空间紧张,需降低消息存储成本的业务
❌ 禁止开启压缩场景
-
小于10KB的短小消息(订单通知、简单状态推送),压缩开销大于收益
-
极致低延迟、超高实时性的极小消息业务
4.5.6 生产核心避坑指南
-
坑1:全量消息无脑压缩 小消息压缩会增加CPU开销、延长响应时间,必须配置压缩阈值,仅大消息触发压缩
-
坑2:生产者消费者压缩算法不一致 两端必须统一使用同一种压缩算法,否则会出现解压失败、消息乱码、消费异常
-
坑3:过度追求高压缩率 GZIP压缩率高但速度慢,高并发场景优先LZ4,避免CPU瓶颈
-
坑4:未兼容旧消息 线上开启压缩需灰度升级,存量未压缩消息与新增压缩消息需兼容处理,避免消费报错
-
坑5:压缩后消息丢失Header标识 禁止手动修改压缩消息的Header属性,否则消费者无法识别压缩格式,导致解压失败
4.5.7 面试高频简答
-
1、消息压缩的核心作用? 大幅缩减大消息体积,降低网络传输带宽、磁盘存储占用、集群同步IO压力,提升高并发场景吞吐量。
-
2、LZ4和GZIP如何选型? 高并发实时业务用LZ4(速度快、开销低);超大消息、归档存储、追求高压缩比场景用GZIP。
-
3、为什么要设置压缩阈值? 小消息压缩的CPU开销大于体积优化收益,阈值过滤可避免无效压缩,平衡性能与资源开销。
-
4、消息压缩会影响消息可靠性吗? 不会,压缩仅修改消息体内容,不改变消息持久化、ACK、路由等核心机制,对业务无侵入。
4.6 消息幂等性(防重复消费·生产全方案)
在 RabbitMQ 消息消费场景中,重复消费是生产高频问题 ,若业务无幂等设计,重复消费会造成订单重复创建、积分重复发放、金额重复扣款、数据重复写入、业务状态错乱等严重故障。消息幂等性核心定义:同一条消息,无论被消费1次还是N次,最终业务结果完全一致,无副作用、无数据异常。
4.6.1 重复消费核心成因(必懂根源)
重复消费并非生产者重复发送消息,99%场景由消费端与网络机制导致,核心4大成因:
-
消费端ACK超时未确认:消费者成功处理业务,但因网络卡顿、服务卡顿,未及时发送ACK确认指令,MQ服务端超时后判定消息未消费,重新投递消息。
-
服务重启/宕机重试:消息消费中,业务逻辑执行完成、未ACK时,消费者进程重启、机器宕机,MQ重启后重新推送未确认消息。
-
网络ACK丢失:消费者正常发送ACK,但网络链路异常导致ACK指令丢失,MQ未收到确认,触发消息重投。
-
手动重试/死信重试机制:业务主动Nack重试、本地重试、死信队列重试,导致同一条消息多次消费。
核心结论:重复消费是MQ机制的正常现象,无法彻底杜绝,只能通过幂等设计规避业务异常。
4.6.2 幂等设计核心原则
-
先查询、后执行:消费消息前先校验业务是否已处理,避免重复执行
-
唯一标识绑定:每条消息绑定全局唯一业务标识,作为判重依据
-
状态幂等:通过业务状态机控制,已完成任务直接拦截,不重复执行
-
原子性保障:判重+执行业务+标记完成,保证操作原子性,避免并发重复
4.6.3 生产五大落地解决方案(附完整代码+场景选型)
方案一:全局唯一ID + Redis 分布式判重(通用首选)
核心原理:生产者为每条消息生成全局唯一ID(messageId),消费端消费前先查询Redis;不存在则执行业务并写入Redis,已存在则直接跳过消费,实现幂等。
适用场景:绝大多数通用业务、无数据库唯一索引场景、高并发消息场景。
优势:性能极高、无数据库压力、适配所有消息类型、支持过期自动清理。
java
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
/**
* Redis+MessageId 实现消息幂等(通用方案)
*/
@Service
public class MqIdempotentRedisConsumer {
@Resource
private RedisTemplate<String, Object> redisTemplate;
// 幂等Key前缀
private static final String MQ_IDEMPOTENT_PREFIX = "mq:idempotent:";
// 幂等缓存过期时间(大于业务消息最大留存时间,此处设为24小时)
private static final long EXPIRE_TIME = 24 * 60 * 60;
@RabbitListener(queues = "order.business.queue")
public void consume(Message message) {
// 1. 获取消息唯一ID(生产者全局生成)
String messageId = message.getMessageProperties().getMessageId();
String idempotentKey = MQ_IDEMPOTENT_PREFIX + messageId;
// 2. 幂等判断:存在则直接跳过,保证原子性(setIfAbsent 原子操作)
Boolean success = redisTemplate.opsForValue().setIfAbsent(idempotentKey, "1", EXPIRE_TIME, TimeUnit.SECONDS);
if (!Boolean.TRUE.equals(success)) {
// 消息已消费,直接返回,避免重复执行业务
return;
}
try {
// 3. 执行正常业务逻辑
doBusinessLogic(message);
} catch (Exception e) {
// 4. 业务异常,删除幂等标识,允许重试消费
redisTemplate.delete(idempotentKey);
throw e;
}
}
/**
* 模拟业务处理逻辑
*/
private void doBusinessLogic(Message message) {
String body = new String(message.getBody());
System.out.println("执行业务逻辑,消息内容:" + body);
}
}方案二:业务唯一主键 + 数据库唯一索引(核心交易首选)
核心原理 :依托业务天然唯一标识(订单号、支付流水号、用户唯一单号),在数据库表建立唯一索引,重复插入/更新时数据库直接拦截,抛出唯一冲突异常,实现天然幂等。
适用场景:订单、支付、退款、交易等核心金融业务,数据落地数据库场景。
优势:数据零丢失、强一致性、无需额外缓存依赖,生产核心业务首选。
java
/**
* 业务唯一单号+数据库唯一索引 幂等方案
* 数据库表字段:order_no 建立 UNIQUE 唯一索引
*/
@Service
public class OrderIdempotentConsumer {
@Resource
private OrderMapper orderMapper;
@RabbitListener(queues = "order.pay.queue")
public void consumePayMessage(String orderNo) {
// 无需手动判重,数据库唯一索引自动拦截重复订单
try {
// 新增/更新订单业务数据
Order order = new Order();
order.setOrderNo(orderNo);
order.setStatus(1);
orderMapper.insert(order);
} catch (DuplicateKeyException e) {
// 唯一索引冲突,说明消息已消费,直接忽略,无需报错
System.out.println("订单已处理,重复消息拦截:" + orderNo);
}
}
}方案三:业务状态机控制幂等(状态流转业务首选)
核心原理 :针对有明确状态流转的业务(订单:待支付→已支付→已完成),消费前校验业务状态,已完成/终态数据直接拦截,仅处理初始状态数据。
适用场景:订单流程、退款流程、审批流程、状态递进式业务。
java
/**
* 业务状态机幂等方案
*/
@Service
public class OrderStatusIdempotentConsumer {
@Resource
private OrderMapper orderMapper;
@RabbitListener(queues = "order.status.queue")
public void consumeOrderStatus(String orderNo) {
// 1. 查询当前订单状态
Order order = orderMapper.selectByOrderNo(orderNo);
if (order == null) {
return;
}
// 2. 终态直接拦截,防止重复消费
Integer status = order.getStatus();
if (status == 1 || status == 2) {
// 1=已支付、2=已完成,终态无需重复处理
System.out.println("订单已处理,拦截重复消费:" + orderNo);
return;
}
// 3. 仅处理初始状态业务
updateOrderStatus(orderNo);
}
private void updateOrderStatus(String orderNo) {
// 执行业务状态更新逻辑
}
}方案四:本地消息表幂等(分布式最终一致性)
核心原理:创建消息记录表,存储消息ID、业务类型、消费状态、创建时间,消费前查询记录表,已消费则跳过,未消费则执行业务+记录状态,保证幂等。
适用场景:分布式事务场景、需严格记录消息消费日志、无Redis依赖的本地化场景。
方案五:MQ消费幂等+全局去重拦截(网关层预处理)
高并发场景可在网关/生产者层做前置去重,统一过滤重复消息,从源头减少重复消费压力,配合消费端幂等实现双重保障。
4.6.4 五大方案生产场景选型口诀
-
通用业务、高并发、非强事务 → Redis+MessageId 方案(首选)
-
订单、支付、金融核心交易 → 数据库唯一索引方案
-
状态流转类业务(订单/审批) → 状态机拦截方案
-
分布式事务、需溯源日志 → 本地消息表方案
4.6.5 生产致命坑点(必避)
-
坑1:先执行业务后标记幂等:顺序颠倒会导致并发重复消费,必须先判重、后执行、最后标记
-
坑2:Redis幂等无过期时间:永久存储会导致Redis数据堆积,内存溢出,需根据业务生命周期设置过期时间
-
坑3:幂等判断非原子性:先查询再写入存在并发漏洞,必须使用setIfAbsent、insert唯一索引等原子操作
-
坑4:业务异常不删除幂等标识:临时异常导致业务失败,幂等标识已存在,后续重试直接拦截,导致消息永久丢失
-
坑5:使用随机临时ID做幂等:必须使用生产者全局唯一MessageId/业务单号,消费者本地生成ID无法去重
4.6.6 面试高频简答(必背)
-
1、MQ重复消费的根本原因? 核心是ACK超时、网络丢包、服务宕机重启导致MQ未收到消费确认,触发消息重投,并非生产者重复发消息。
-
2、最常用的MQ幂等方案? 通用场景用Redis+全局MessageId原子去重,核心交易场景用数据库唯一索引兜底,状态业务用状态机拦截。
-
3、幂等设计核心关键点? 原子判重、先查后执、异常回滚幂等标识、适配业务生命周期、避免数据堆积。
-
4、Redis幂等为什么要用setIfAbsent? 保证多消费者并发消费时,只有一个线程执行业务,彻底解决并发重复消费问题,普通查询+写入非原子,存在漏洞。
4.7 消息重试体系(完整落地版·本地重试+死信重试+多级补偿)
在RabbitMQ消费场景中,业务异常、网络抖动、第三方接口超时、数据库瞬时故障等问题会导致消息消费失败。若直接丢弃消息会造成业务数据缺失,若无限重试会拖垮服务、引发消息堆积。标准化消息重试体系核心思想:本地有限重试解决瞬时临时异常,死信队列兜底解决永久异常,区分异常类型精准重试,杜绝无效重试与消息丢失,是生产环境必备的容错方案。
4.7.1 消息重试核心分类
生产环境统一分为两级重试,分层治理、各司其职,完全覆盖所有消费异常场景:
-
第一级:本地内存重试(Spring Retry):针对瞬时、临时可恢复异常,短时间内快速重试,无需入队,效率高、延迟低
-
第二级:队列死信重试(DLX兜底):针对本地重试耗尽仍失败的永久异常、业务异常,转入死信队列,支持定时重试、人工干预、故障复盘
核心执行链路:消息消费失败 → 本地指数退避重试(有限次数) → 重试成功结束流程 → 重试全部失败 → Nack拒绝消息 → 消息进入死信队列 → 定时补偿/人工修复重试
4.7.2 第一级:本地重试(Spring Retry 完整配置+落地代码)
本地重试基于Spring Retry实现,在消费者内存中完成重试,不经过MQ服务端,速度快、无网络开销,专门解决网络超时、数据库瞬时卡顿、第三方接口抖动等临时异常。
1. 核心特性与重试策略
-
重试触发条件:仅捕获可重试瞬时异常(超时异常、IO异常、临时连接异常),主动忽略业务参数错误、数据不存在等不可重试异常
-
重试策略:指数退避重试(最优生产策略),逐步拉长重试间隔,避免高频重试压垮服务
-
有限次数:禁止无限重试,默认配置3-5次重试,耗尽后直接转入死信队列
-
执行范围:仅作用于当前消费者线程,重试期间消息不释放、不重新入队
2. 全局完整配置(生产直接可用)
java
import org.springframework.amqp.rabbit.config.SimpleRabbitListenerContainerFactory;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.retry.backoff.ExponentialBackOffPolicy;
import org.springframework.retry.policy.SimpleRetryPolicy;
import org.springframework.retry.support.RetryTemplate;
import java.util.HashMap;
import java.util.Map;
/**
* RabbitMQ 本地重试全局配置
* 指数退避重试 + 区分可重试/不可重试异常 + 有限次数重试
*/
@Configuration
public class RabbitRetryConfig {
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
// 开启手动ACK(生产强制)
factory.setAcknowledgeMode(org.springframework.amqp.rabbit.connection.AcknowledgeMode.MANUAL);
// 配置重试模板
factory.setRetryTemplate(retryTemplate());
// 重试失败后的恢复回调:手动Nack,消息入死信队列
factory.setRecoveryCallback(context -> {
throw new RuntimeException("本地重试耗尽,消息转入死信队列");
});
return factory;
}
/**
* 自定义重试模板:指数退避 + 异常精准匹配
*/
private RetryTemplate retryTemplate() {
RetryTemplate retryTemplate = new RetryTemplate();
// 1. 指数退避策略:初始间隔1s、最大间隔10s、倍率2(1s→2s→4s→8s)
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(1000);
backOffPolicy.setMaxInterval(10000);
backOffPolicy.setMultiplier(2);
retryTemplate.setBackOffPolicy(backOffPolicy);
// 2. 自定义可重试异常:仅瞬时异常重试,业务异常不重试
Map<Class<? extends Throwable>, Boolean> retryExceptionMap = new HashMap<>();
// 可重试异常:网络超时、IO异常、数据库连接异常
retryExceptionMap.put(java.net.SocketTimeoutException.class, true);
retryExceptionMap.put(java.io.IOException.class, true);
retryExceptionMap.put(org.springframework.dao.TransientDataAccessException.class, true);
// 不可重试异常:参数错误、数据不存在、业务校验失败
retryExceptionMap.put(IllegalArgumentException.class, false);
retryExceptionMap.put(NullPointerException.class, false);
// 3. 最大重试次数:4次本地重试
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy(4, retryExceptionMap, true);
retryTemplate.setRetryPolicy(retryPolicy);
return retryTemplate;
}
}3. 本地重试核心优势与坑点
-
优势:重试速度快、无MQ消息流转开销、瞬时异常快速恢复、不产生无效死信消息
-
坑1:本地重试期间线程阻塞,会占用消费者线程,重试过多会降低消费吞吐量
-
坑2:未区分异常类型,所有异常都重试,会导致参数错误等永久异常无效重试
-
坑3:重试次数过多、间隔过短,会加剧服务压力,引发雪崩
4.7.3 第二级:队列死信重试(DLX 兜底重试)
当本地重试全部耗尽仍消费失败,说明异常为永久不可恢复(数据异常、业务逻辑bug、第三方服务宕机),此时禁止无限本地重试,通过手动Nack将消息投递至死信队列,实现兜底重试与人工干预。
1. 消息进入死信队列的三大条件(必考)
-
消费者手动Nack拒绝消息,且不重新入队(requeue=false)
-
消息/队列达到TTL过期时间,未被消费
-
队列消息数量达到上限,触发溢出策略,消息溢出
2. 死信重试完整架构
业务队列 → 本地重试失败 → Nack入死信队列 → 配置死信消费者/定时任务 → 定时重试消费 + 人工排查修复 → 消费成功/归档废弃消息
3. 死信队列标准配置代码(衔接前文队列配置)
java
// 死信交换机
@Bean
public DirectExchange dlxDirectExchange() {
return ExchangeBuilder.directExchange("dlx.direct.exchange")
.durable(true)
.build();
}
// 死信队列
@Bean
public Queue dlxBusinessQueue() {
return QueueBuilder.durable("dlx.business.queue")
.build();
}
// 死信交换机与死信队列绑定
@Bean
public Binding dlxBinding() {
return BindingBuilder.bind(dlxBusinessQueue())
.to(dlxDirectExchange())
.with("dlx.order.key");
}4. 死信重试消费逻辑
java
/**
* 死信队列兜底重试消费者
* 处理本地重试失败的异常消息,支持人工修复后重试
*/
@RabbitListener(queues = "dlx.business.queue")
public void dlxConsume(Message message, Channel channel) throws Exception {
try {
// 重新执行业务逻辑
doBusinessLogic(message);
// 消费成功,手动ACK
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
// 死信队列二次消费失败:不再重试,记录日志、归档消息,等待人工排查
log.error("死信消息消费失败,消息已归档,messageId:{}", message.getMessageProperties().getMessageId(), e);
// 放弃消息,不重新入队,避免循环重试
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, false);
// 可拓展:异常消息入库归档,方便后续复盘
}
}4.7.4 高级方案:延时阶梯重试(生产高阶优化)
针对部分需要延时重试的业务(第三方服务宕机、库存释放、接口限流),可基于TTL+DLX实现阶梯式延时重试,替代无脑重试,适配不同故障恢复周期。
-
1次失败:延时10s重试
-
2次失败:延时30s重试
-
3次失败:延时60s重试
-
多次失败:转入永久死信队列,人工干预
4.7.5 生产最优重试组合规范(强制落地)
标准架构:本地指数退避重试(瞬时异常) + 死信队列兜底(永久异常) + 死信人工复盘(最终保障)
-
优先开启本地重试,配置3-4次指数退避,解决90%瞬时抖动异常
-
区分异常类型,不可重试异常直接跳过本地重试,直接入死信
-
本地重试耗尽后,统一进入死信队列,禁止消息丢失、禁止无限重投
-
死信队列单独消费,不与正常业务队列混用,避免影响主业务
-
每日定时归档死信消息,统计异常类型,优化业务代码
4.7.6 生产致命坑点(必避)
-
坑1:开启自动ACK+无限本地重试:自动ACK会导致消息消费失败后直接删除,重试无意义,且丢失数据
-
坑2:死信队列再次配置DLX:导致消息循环重试、无限堆积,拖垮MQ服务
-
坑3:所有异常统一重试:参数错误、数据缺失等业务异常重试无效,浪费系统资源
-
坑4:本地重试未限制次数:无限重试阻塞消费者线程,导致业务消息堆积、服务雪崩
-
坑5:重试消息未做幂等:重试触发重复消费,引发数据错乱、重复扣款等问题
4.7.7 面试高频简答(必背)
-
1、RabbitMQ重试体系分为哪两层?各自作用? 本地Spring Retry重试解决网络、接口瞬时抖动异常,效率高、速度快;死信队列重试兜底处理本地重试失败的永久异常,支持人工干预,杜绝消息丢失。
-
2、为什么不建议无限本地重试? 无限重试会阻塞消费者线程、占用系统资源,导致正常消息无法消费,引发消息堆积与服务雪崩,且业务永久异常重试无意义。
-
3、死信队列消息为什么禁止再次配置死信交换机? 会形成消息循环消费、无限重试,造成消息永久堆积,耗尽MQ磁盘与内存资源。
-
4、指数退避重试的优势? 逐步拉长重试间隔,既能快速恢复瞬时异常,又能避免高频重试压垮故障服务,平衡容错与服务稳定性。
-
5、如何避免重试导致的重复消费? 所有重试消息必须基于messageId实现幂等,重试前先判重,保证多次重试结果一致。
第五部分 集群、高可用与跨机房部署
5.1 节点类型
-
磁盘节点:存储元数据(队列、交换机、用户、权限),集群至少 2 个
-
内存节点 :元数据存内存,性能高,不能独立部署
5.2 四大集群模式(完整落地版+原理+优缺点+选型)
RabbitMQ 主流四大集群模式:普通集群、镜像队列集群、仲裁队列集群、分片队列集群 ,适配不同可用性、并发、数据一致性场景,其中 3.8+ 版本官方主推仲裁队列,逐步淘汰传统镜像队列,以下为全维度对比详解。
5.2.1 普通集群(基础集群模式)
普通集群是最基础的集群部署方式,集群内所有节点共享交换机、vhost、用户、权限等元数据 ,但队列数据仅存储在创建队列的当前节点,不会同步到其他节点。
核心原理
-
元数据全局同步:所有节点拥有完整集群元数据,可正常路由消息、处理连接请求
-
队列数据本地化:队列实体与消息数据仅存在于创建节点,其他节点仅保留路由索引
-
跨节点转发机制:客户端连接非队列所在节点时,该节点会将请求转发至队列主节点,完成消息收发
核心优缺点
-
优点:部署简单、无数据同步开销、集群性能损耗极低、资源占用少
-
缺点:无高可用能力,存在单点故障;队列所在节点宕机后,队列彻底不可读写,未消费消息堆积丢失,集群可用性极差
适用场景
仅适用于测试环境、本地开发、非核心临时业务,生产核心业务禁止使用,无故障容错能力。
生产坑点
普通集群仅实现负载均衡,未实现数据高可用,切勿误以为集群部署即可容错,单节点故障直接导致对应业务瘫痪。
5.2.2 镜像队列集群(传统高可用模式)
镜像队列是 RabbitMQ 传统高可用方案,基于普通集群升级,通过配置镜像策略,将单个队列的元数据+消息数据同步到集群多个节点,形成主从镜像架构,解决普通集群单点故障问题。
核心原理
-
角色划分:集群内队列分为主节点(Master) 和镜像节点(Mirror)
-
读写规则:所有消息读写操作仅在主节点执行,镜像节点异步同步主节点数据副本
-
故障切换:主节点宕机后,集群自动从镜像节点中选举新主节点,接管队列读写服务
-
同步机制:消息写入主节点成功后,异步同步至所有镜像节点,保证数据多副本留存
核心优缺点
-
优点:实现队列高可用、节点故障不丢消息、业务不中断、适配旧版本 RabbitMQ
-
缺点 :异步同步存在数据一致性风险;极易产生脑裂问题;同步大量消息时网络开销大、性能损耗高;新版本逐步被官方废弃
适用场景
RabbitMQ 3.8 以下旧版本生产集群、对可用性有基础要求、暂未升级新版本的存量业务。
生产坑点
网络抖动引发集群脑裂后,会出现多主节点并行工作、数据同步错乱、消息重复、队列异常等严重问题,人工修复成本极高。
5.2.3 仲裁队列 Quorum Queue(3.8+ 官方主推·金融级高可用)
仲裁队列是 RabbitMQ 3.8 版本推出的新一代高可用队列,基于标准 Raft 分布式一致性算法实现,替代传统镜像队列,解决镜像队列脑裂、数据不一致、稳定性差的核心问题,是目前生产最优高可用方案。
核心原理
-
Raft 选举机制:集群节点分为 Leader(主节点)、Follower(从节点),采用多数派选举策略(节点数建议奇数:3/5个)
-
强一致性:消息写入需得到多数节点确认才算写入成功,杜绝异步同步的数据丢失风险
-
故障容错:少数节点宕机不影响集群整体可用性,无需人工干预,自动完成选举切换
-
无脑裂特性:依托一致性算法,从底层杜绝集群脑裂问题,稳定性远超镜像队列
核心优缺点
-
优点:金融级数据零丢失、无脑裂风险、自动故障转移、集群稳定性极强、适配高可靠核心业务、官方长期维护迭代
-
缺点:不支持临时队列、不支持消息优先级、不支持队列溢出策略;同步确认机制存在轻微性能损耗
适用场景
生产所有核心业务(订单、支付、交易、金融业务)、要求消息零丢失、高可用、高稳定性的场景,新版本集群强制首选。
生产强制规范
仲裁队列副本数必须配置奇数(3/5),保证多数派选举生效,偶数节点无法发挥 Raft 算法容错优势。
5.2.4 分片队列 Sharded Queue(高并发海量消息模式)
分片队列是面向超高并发、海量消息堆积场景的专项优化模式,核心是将一个大逻辑队列,按指定规则拆分多个物理子队列,分散到集群不同节点存储消费,突破单队列性能瓶颈。
核心原理
-
分片拆分:自定义分片规则(消息Key、路由键、哈希算法),将消息均匀分发至多个物理分片队列
-
分布式存储:多个分片队列分散在集群不同节点,分摊单节点存储与读写压力
-
并行消费:多节点、多消费者同时消费分片队列,大幅提升整体消费吞吐量
核心优缺点
-
优点:彻底突破单队列性能上限、海量消息无堆积、并发吞吐能力拉满、集群资源利用率最大化
-
缺点:无法保证全局消息有序、运维复杂度提升、不适合强时序业务、分片规则需合理设计
适用场景
海量日志上报、用户行为追踪、高并发活动流量、超大批量消息处理等高吞吐、弱时序业务场景。
5.2.5 四大集群模式终极选型口诀(面试+生产必背)
-
测试环境、临时业务 → 普通集群
-
旧版本存量业务、基础高可用 → 镜像队列集群
-
核心交易、金融业务、零丢失要求 → 仲裁队列(首选)
-
海量消息、超高吞吐、弱时序业务 → 分片队列
5.2.6 四大集群模式核心对比表
|------|----------------|-------|------|------|------------|
| 集群模式 | 数据同步方式 | 高可用能力 | 脑裂风险 | 吞吐性能 | 生产推荐度 |
| 普通集群 | 仅同步元数据,队列数据本地化 | 无 | 低 | 高 | ❌ 禁止生产核心使用 |
| 镜像队列 | 主节点异步同步副本 | 中 | 极高 | 中 | ⚠️ 旧版本过渡使用 |
| 仲裁队列 | Raft多数派强同步 | 极高 | 无 | 中高 | ✅ 新版生产首选 |
| 分片队列 | 分片分布式存储,独立同步 | 高 | 低 | 极高 | ✅ 高吞吐场景专用 |
5.3 跨集群/跨机房高可用互通方案
RabbitMQ 原生不支持跨机房自动集群同步,常规集群模式要求节点同机房、低延迟、高可靠内网互通,无法适配跨公网、跨机房、异地多活场景。行业生产主流两套跨集群/跨机房解决方案:Federation(联邦) 、Shovel 插件,均无需组建全局集群、无需节点同网段,实现低耦合、弱网络适配的异地消息同步,支撑多机房容灾、业务互通、数据双向同步场景。
5.3.1 Federation 联邦机制(轻量跨机房互通)
联邦是RabbitMQ官方原生轻量跨集群方案,核心是不组建完整集群、不同步元数据、仅按需同步消息,实现独立MQ集群之间的消息互通,节点无需互通内网,适配跨机房、跨网段、弱网络环境。
1. 核心原理
-
架构隔离:上下游MQ集群完全独立,无集群主从关系、不共享元数据、不触发集群脑裂
-
按需拉取:下游联邦交换机/队列主动向上游集群拉取消息,而非被动同步,网络开销极低
-
单向/双向同步:支持一对一、一对多消息转发,可实现多机房消息联动
-
容错重连:网络中断后自动重试连接,恢复后继续同步消息,不丢失数据
2. 两大核心组件
-
Federation Exchange(联邦交换机):核心用于消息路由同步,上游交换机消息可同步至下游联邦交换机,适配广播、事件订阅场景,支持多集群消息分发
-
Federation Queue(联邦队列):下游队列直接绑定上游集群队列,跨集群竞争消费消息,实现异地负载均衡消费
3. 生产配置核心步骤
-
所有集群节点开启联邦插件:
rabbitmq-plugins enable rabbitmq_federation rabbitmq_federation_management -
上下游集群配置互通链接、账号权限,放开MQ端口白名单
-
下游定义联邦上游节点(关联上游集群地址、账号)
-
创建联邦交换机/队列,绑定上游资源,自动建立同步链路
4. 核心优缺点
-
优点:部署轻量化、无集群耦合、适配弱网络、几乎无脑裂风险、资源开销小、支持动态扩缩容
-
缺点:仅同步消息、不同步队列元数据;不支持消息事务;高堆积场景同步效率一般
5. 适用场景
-
多机房业务消息互通、异地多活轻量同步
-
总部-分支架构,分支集群订阅总部消息
-
跨网段、跨云厂商MQ集群低耦合通信
-
事件驱动、通知类、广播类非强一致消息同步
5.3.2 Shovel 插件(持久化跨机房数据同步)
Shovel 是RabbitMQ官方主推的高可靠跨集群消息转发方案,专门解决异地灾备、数据持久化同步、弱网络稳定传输问题,可实现两个完全独立MQ实例/集群之间的消息定向转发,是生产异地容灾首选方案。
1. 核心原理
-
独立转发代理:Shovel可理解为独立的消息转发引擎,部署在本地集群,主动连接远端MQ集群
-
持久化转发:转发过程支持消息临时持久化,网络中断、服务重启后,恢复未完成转发任务,杜绝消息丢失
-
精准定向:支持指定源队列/交换机、目标队列/交换机,单向/双向精准转发
-
自动容错:内置重连机制、失败重试、异常熔断,适配公网、弱网络波动场景
2. 两种工作模式
-
queue-shovel(队列转发):最常用,从上游指定队列拉取消息,转发至下游目标队列,适配业务消息同步、异地灾备
-
exchange-shovel(交换机转发):监听上游交换机路由消息,转发至下游交换机,适配批量消息路由、广播同步
3. 生产核心优势(对比联邦)
-
可靠性更高:转发全程可追溯、支持断点续传,适配核心交易消息同步
-
配置更灵活:支持自定义转发规则、消息过滤、异常丢弃、重试次数
-
运维更友好:管理后台可视化监控转发状态、堆积数量、异常日志
-
适配性更强:支持跨公网、跨云、弱网络长期稳定运行
4. 适用场景
-
核心业务异地灾备、消息数据跨机房备份
-
生产-测试环境消息同步、数据复刻
-
跨云厂商MQ集群数据互通、弱网络环境同步
-
需要高可靠、零丢失的异地消息同步场景
5.3.3 两大跨机房方案终极对比(生产+面试必背)
|------|------------------|------------------|
| 对比维度 | Federation 联邦 | Shovel 插件 |
| 可靠级别 | 中等,轻量同步,无断点续传 | 极高,支持断点续传、持久化转发 |
| 网络适配 | 内网、低延迟网络最优 | 公网、弱网络、跨云适配 |
| 核心场景 | 轻量业务互通、事件广播、多活订阅 | 核心业务灾备、数据备份、精准同步 |
| 性能开销 | 极低,轻量化运行 | 中等,需占用转发线程与内存 |
| 运维难度 | 低,配置简单 | 中,支持精细化监控运维 |
5.3.4 生产选型口诀(一秒落地)
-
轻量互通、事件订阅、低延迟内网 → 优先联邦 Federation
-
异地灾备、核心数据同步、公网弱网络 → 优先 Shovel 插件
-
非核心业务多活联动 → 联邦;核心交易异地备份 → Shovel
5.3.5 生产致命坑点(必避)
-
坑1:跨机房方案混用集群模式:跨公网绝对不能使用原生集群,网络延迟高、极易触发脑裂、数据错乱
-
坑2:联邦同步核心交易消息:联邦无断点续传,网络抖动易丢失少量消息,禁止用于支付、订单等核心业务
-
坑3:Shovel未配置重连策略:弱网络下转发中断后无法自动恢复,导致同步中断、数据堆积
-
坑4:双向同步未做消息去重:双向转发会形成消息循环同步,引发无限消息堆积,必须基于messageId做幂等过滤
-
坑5:未配置同步限流:跨机房同步大流量消息会占用公网带宽,拖垮业务网络,需配置转发速率限流
5.3.6 面试高频简答(必背)
-
1、为什么跨机房不建议用原生RabbitMQ集群? 原生集群要求节点低延迟内网互通,跨公网网络延迟高、抖动频繁,极易触发集群脑裂、数据同步失败、消息错乱,稳定性极差。
-
2、联邦和Shovel的核心区别? 联邦轻量化、适合轻量业务互通,无持久化转发;Shovel高可靠、支持断点续传,是异地灾备、核心数据同步首选。
-
3、跨机房消息同步如何保证不丢数据? 选用Shovel插件、开启断点续传、配置自动重连、消息全局幂等、同步失败告警、定时校验数据一致性。
-
4、双向同步如何避免消息循环? 基于消息唯一MessageId做幂等过滤,消费/转发前判重,同时配置消息来源标记,拦截循环转发消息。
5.4 集群常见问题与完整解决方案(生产高频)
本节汇总RabbitMQ集群运维全场景高频故障,包含脑裂、节点离线、队列异常、消息同步失败、集群重启异常、数据不一致等核心问题,配套成因、故障现象、紧急处理方案、长期预防规范,可直接落地运维排查。
5.4.1 集群脑裂(最核心故障)
集群脑裂是RabbitMQ集群最致命的生产故障,高发于镜像队列集群,仲裁队列可从底层规避该问题。
1、故障成因
-
网络分区:机房网络抖动、交换机故障、防火墙拦截,导致集群节点间内网互通中断,整体集群分裂为多个独立子集群
-
节点超时判定:RabbitMQ节点默认心跳超时,失联节点自动判定对方宕机,各自独立选举主节点
-
偶数节点集群:偶数节点无绝对多数派,极易触发多主节点分裂,加剧脑裂风险
-
人工运维不当:未规范停机顺序、强制单节点重启、批量操作集群节点
2、核心故障现象
-
管理后台显示集群节点状态不一致,部分节点正常、部分节点异常
-
同一队列出现多个主节点,消息双向同步错乱
-
消息重复消费、消息丢失、队列消息数量不一致
-
生产者发送消息随机报错,消费者频繁断连重连
-
集群日志持续打印network partition(网络分区)异常
3、紧急处理方案
-
暂停业务:临时关停生产者、消费者服务,避免故障扩大,产生脏数据
-
判定主集群:保留消息数据最全、节点数量最多的正常子集群
-
重置异常节点 :对分裂的异常节点执行
rabbitmqctl reset重置集群状态 -
重新加入集群:将重置后的节点重新加入主集群,同步全局元数据
-
数据校验修复:对比各节点队列消息数量,补全丢失消息,清理重复消息
-
恢复业务:集群状态稳定、数据一致后,重启生产消费服务
4、长期预防规范
-
生产核心集群强制使用奇数节点(3/5个),杜绝偶数节点部署
-
3.8+版本全面替换为仲裁队列,依托Raft算法无脑裂风险
-
优化机房网络,降低网络抖动,保障集群节点低延迟内网互通
-
配置网络分区自动恢复策略,开启集群状态监控告警
-
规范运维操作,禁止强制断电、单节点强制重启、无序启停集群
5.4.2 集群节点离线故障
1、常见成因
-
服务器宕机、重启、系统资源耗尽(CPU/内存爆满)
-
集群端口(25672)被防火墙拦截、端口占用
-
节点磁盘满、内存触发MQ流控,服务进程挂起
-
Erlang进程异常崩溃、MQ进程意外退出
2、故障现象
-
管理后台节点状态显示 down,集群节点数量缺失
-
普通集群:离线节点的队列彻底不可读写,消息堆积
-
镜像/仲裁集群:自动触发主从切换,业务短暂抖动后恢复
-
客户端出现短暂断连重连,少量消息发送超时
3、处理方案
-
排查服务器状态:重启宕机节点、清理磁盘/内存资源、释放端口
-
检查防火墙、安全组规则,放行集群通信端口
-
重启MQ服务,等待节点自动重新加入集群
-
核对队列主节点状态,确认消息同步正常、无数据丢失
-
监控业务消息生产消费速率,确认业务恢复正常
5.4.3 集群消息同步失败、数据不一致
1、成因
-
镜像队列异步同步延迟,主节点宕机前数据未同步至从节点
-
集群节点时间不同步,导致消息同步校验异常
-
网络延迟过高,跨节点消息同步超时
-
手动修改单节点队列配置,导致集群配置不一致
2、现象
-
同一队列在不同节点的消息数量、未消费条数不一致
-
部分消息消费后未同步,重启节点后消息重复出现
-
集群日志打印消息同步超时、同步失败异常
3、解决方案
-
统一所有集群节点服务器时间,开启时间同步服务
-
优化集群内网网络,降低延迟与丢包率
-
禁止单节点单独修改配置,所有队列、交换机配置统一集群同步
-
镜像队列升级为仲裁队列,通过强一致性算法保障数据一致
-
定时巡检集群各节点数据,自动校验消息数量一致性
5.4.4 集群启停异常故障
1、错误启停导致的问题
-
先停磁盘节点、后停内存节点,导致元数据丢失、队列销毁
-
无序重启节点,引发集群选举异常、临时脑裂
-
未停止业务直接重启集群,导致大量消息发送失败、连接异常
2、标准集群启停规范(生产强制遵守)
停机顺序(从业务到服务)
-
暂停所有生产者、消费者业务服务,停止消息收发
-
依次停止内存节点MQ服务
-
最后停止磁盘节点MQ服务(保留元数据)
启动顺序(从底层到业务)
-
优先启动所有磁盘节点,等待集群元数据加载完成
-
依次启动内存节点,自动加入集群同步数据
-
等待集群所有节点状态正常、数据同步完成
-
分批启动消费者、生产者业务服务,恢复消息收发
5.4.5 集群队列漂移故障
1、故障成因
集群节点频繁上下线、主节点反复切换,导致队列主节点在集群节点间频繁漂移。
2、危害
-
每次漂移触发消息重新同步,占用大量网络、磁盘IO资源
-
业务频繁断连重连,接口抖动、消息消费延迟
-
极端场景引发消息重复、短暂堆积
3、解决与预防
-
稳定集群节点状态,减少节点重启、运维操作频次
-
仲裁队列集群合理配置选举超时时间,避免频繁重选主节点
-
核心业务队列固定优先主节点,减少随机漂移
5.4.6 面试高频简答(集群故障必背)
-
1、如何彻底解决RabbitMQ集群脑裂问题? 放弃镜像队列,升级为3.8+版本仲裁队列,依托Raft多数派一致性算法底层杜绝脑裂;集群部署奇数节点,规范网络与运维操作,从根源规避故障。
-
2、集群节点宕机后,消息会丢失吗? 普通集群:宕机节点本地队列消息丢失;镜像队列:异步同步可能丢失未同步消息;仲裁队列:多数节点存活时数据零丢失,高可用最强。
-
3、集群数据不一致的核心原因?怎么解决? 核心原因是镜像队列异步同步、网络延迟、节点时间不同步、运维操作不规范;解决方案是升级仲裁队列、统一节点时间、优化内网网络、规范集群配置与运维。
-
4、为什么集群必须优先启动磁盘节点? 磁盘节点存储集群元数据(队列、交换机、权限等),先启动磁盘节点可保障集群初始化时加载完整元数据,避免内存节点启动后无元数据、集群初始化失败、队列丢失等问题。
第六部分 Spring Boot / Spring AMQP 整合(企业主流)
6.1 基础整合(从零落地完整流程)
本节提供Spring Boot 整合 RabbitMQ 全套可落地基础代码,包含依赖引入、配置文件、全局配置、基础生产者/消费者demo,适配SpringBoot2.x、SpringBoot3.x主流版本,生产项目可直接复用。
6.1.1 核心Maven依赖(SpringBoot2.x / 3.x通用)
Spring整合RabbitMQ核心依赖为spring-boot-starter-amqp,自动封装连接池、信道管理、消息收发、自动重连等核心能力,无需手动原生API操作。
XML
<!-- SpringBoot 整合 RabbitMQ 核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<!-- 可选:JSON序列化依赖,保证消息统一序列化 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>6.1.2 全局YAML配置(生产级完整配置)
包含服务连接、虚拟主机、账号权限、连接池、自动重连、消息确认、超时控制等全套基础配置,规避基础环境坑点。
XML
spring:
# RabbitMQ 全局配置
rabbitmq:
# 服务端地址
host: 127.0.0.1
# 客户端通信端口(默认5672,集群端口25672、管理端口15672)
port: 5672
# 专属虚拟主机,禁止使用默认/
virtual-host: /business
# 生产专属账号(禁止guest)
username: mq_business_user
password: Mq@Business123456
# 连接池配置(核心优化:多信道、少连接)
connection-pool:
# 最小空闲连接数
min-idle: 2
# 最大空闲连接数
max-idle: 4
# 最大连接数(生产无需过大,2-4个长连接足够)
max-active: 4
# 连接空闲超时,自动回收闲置连接
idle-timeout: 30000
# 消息确认配置(生产必备)
publisher-confirm-type: correlated # 开启生产者异步确认
publisher-returns: true # 开启路由失败返回机制
# 消费者基础配置
listener:
simple:
acknowledge-mode: manual # 手动ACK(生产强制)
prefetch: 10 # 预取值,均衡消费压力
retry:
enabled: true # 开启本地重试
initial-interval: 1000 # 首次重试间隔1s
max-attempts: 3 # 最大重试3次
multiplier: 2 # 重试间隔倍率
max-interval: 5000 # 最大重试间隔5s6.1.3 全局基础配置类(必配)
统一配置JSON消息转换器、全局超时、消息编码,解决默认二进制序列化乱码、泛型反序列化异常问题,生产项目全局唯一配置。
java
import com.fasterxml.jackson.annotation.JsonTypeInfo;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* RabbitMQ 全局基础配置
* 统一序列化、消息转换、全局回调、防乱码、防序列化异常
*/
@Configuration
public class RabbitBasicConfig {
/**
* 全局JSON消息转换器(替代默认二进制序列化)
* 解决乱码、对象序列化不一致、泛型反序列化失败问题
*/
@Bean
public MessageConverter jsonMessageConverter() {
ObjectMapper objectMapper = new ObjectMapper();
// 兼容多类型对象序列化,解决嵌套对象、泛型反序列化异常
objectMapper.activateDefaultTyping(
LaissezFaireSubTypeValidator.instance,
ObjectMapper.DefaultTyping.NON_FINAL,
JsonTypeInfo.As.PROPERTY
);
return new Jackson2JsonMessageConverter(objectMapper);
}
/**
* 全局RabbitTemplate配置
* 绑定消息转换器、开启全局回调
*/
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory, MessageConverter jsonMessageConverter) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
// 全局统一JSON序列化
rabbitTemplate.setMessageConverter(jsonMessageConverter);
// 强制开启mandatory,路由失败触发Return回调,不丢失消息
rabbitTemplate.setMandatory(true);
return rabbitTemplate;
}
}6.1.4 基础交换机&队列绑定配置
以常用Direct直连交换机为例,演示生产标准的交换机、队列、绑定关系声明方式,统一资源管理。
java
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 基础消息资源配置
* 声明交换机、队列、绑定关系,统一管理MQ资源
*/
@Configuration
public class RabbitResourceConfig {
// 1. 定义队列名称
public static final String ORDER_BUSINESS_QUEUE = "order.business.queue";
// 2. 定义交换机名称
public static final String ORDER_DIRECT_EXCHANGE = "order.direct.exchange";
// 3. 定义路由键
public static final String ORDER_ROUTING_KEY = "order.business.key";
/**
* 声明持久化业务队列(生产标准)
* 持久化、非独占、常驻不自动删除
*/
@Bean
public Queue orderBusinessQueue() {
return new Queue(ORDER_BUSINESS_QUEUE, true, false, false);
}
/**
* 声明直连交换机
*/
@Bean
public DirectExchange orderDirectExchange() {
// 参数:交换机名、持久化、不自动删除
return new DirectExchange(ORDER_DIRECT_EXCHANGE, true, false);
}
/**
* 绑定队列与交换机,关联路由键
*/
@Bean
public Binding orderQueueBinding(Queue orderBusinessQueue, DirectExchange orderDirectExchange) {
return BindingBuilder
.bind(orderBusinessQueue)
.to(orderDirectExchange)
.with(ORDER_ROUTING_KEY);
}
}6.1.5 基础生产者实战代码
封装通用消息发送工具类,支持普通消息发送、携带唯一消息ID、适配全局确认机制。
java
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.UUID;
/**
* 基础消息生产者工具类
* 通用消息发送、自带唯一消息ID、适配生产规范
*/
@Component
public class RabbitMsgProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 发送订单业务消息
* @param data 业务数据
*/
public void sendOrderMsg(Object data) {
// 生成全局唯一消息ID,用于幂等、溯源
String messageId = UUID.randomUUID().toString().replace("-", "");
// 发送消息:交换机、路由键、消息体、消息属性
rabbitTemplate.convertAndSend(
RabbitResourceConfig.ORDER_DIRECT_EXCHANGE,
RabbitResourceConfig.ORDER_ROUTING_KEY,
data,
message -> {
// 设置消息唯一ID、持久化模式
message.getMessageProperties().setMessageId(messageId);
message.getMessageProperties().setDeliveryMode(2); // 消息持久化
message.getMessageProperties().setContentType("application/json");
return message;
}
);
}
}6.1.6 基础消费者实战代码(生产标准)
采用手动ACK、异常捕获、日志溯源,完全贴合生产消费规范,杜绝消息丢失、无限重试问题。
java
import com.rabbitmq.client.Channel;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
/**
* 订单业务消费者
* 生产标准:手动ACK、异常处理、消息溯源、拒绝策略
*/
@Component
public class OrderMsgConsumer {
/**
* 监听订单业务队列
* @param data 消息体数据
* @param channel 信道
* @param deliveryTag 消息唯一标识
* @param messageId 消息唯一ID
*/
@RabbitListener(queues = RabbitResourceConfig.ORDER_BUSINESS_QUEUE)
public void consumeOrderMsg(Object data,
Channel channel,
@Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag,
@Header(AmqpHeaders.MESSAGE_ID) String messageId) {
try {
// 1. 业务消费逻辑(自定义业务处理)
System.out.println("收到订单消息,消息ID:" + messageId);
System.out.println("消息内容:" + data);
// 2. 手动ACK确认,告知MQ删除消息
// 参数:消息标识、是否批量确认(false=单条确认,精准可控)
channel.basicAck(deliveryTag, false);
} catch (Exception e) {
try {
// 3. 消费异常,拒绝消息,不重回队列(避免无限重试)
// 可根据业务改造:异常消息转入死信队列
channel.basicNack(deliveryTag, false, false);
System.err.println("订单消息消费异常,消息ID:" + messageId + ",异常信息:" + e.getMessage());
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
}6.1.7 基础整合核心总结
-
整合核心流程:引入依赖 → 配置连接与连接池 → 全局序列化配置 → 声明MQ资源 → 编写生产消费逻辑
-
生产强制规范:手动ACK、JSON序列化、消息持久化、全局唯一MessageId、关闭默认二进制序列化
-
基础避坑点:禁止频繁创建RabbitTemplate、禁止自动ACK、禁止缺失消息唯一ID、禁止默认序列化
6.2 核心注解(全套完整版·生产+面试必背)
Spring AMQP 提供全套注解简化RabbitMQ开发,替代原生繁琐API,核心分为消费者监听注解、消息分发注解、属性配置注解、事务/重试注解,以下为所有高频核心注解详解、属性用法、实战场景与避坑点。
6.2.1 @RabbitListener(核心消费者注解)
作用:声明方法为RabbitMQ消息监听方法,持续监听指定队列,是生产最核心的消费者注解,支持类级别+方法级别配置。
核心常用属性(生产必配)
-
queues:指定监听的队列名称(支持单队列/多队列数组),最常用属性
-
queuesToDeclare:直接声明并绑定队列,无需手动配置Bean,适合简单临时队列
-
exchanges:绑定交换机,可直接声明交换机、队列、路由键(零配置快速开发)
-
bindingKeys:交换机与队列绑定的路由键,配合exchanges使用
-
containerFactory:指定自定义监听器容器工厂,配置并发、重试、预取值
-
ackMode:局部ACK模式,优先级高于全局配置,支持手动/自动ACK切换
生产实战用法
java
// 基础用法:监听指定业务队列
@RabbitListener(queues = RabbitResourceConfig.ORDER_BUSINESS_QUEUE)
public void consumeOrderMsg(String msg){
// 业务消费逻辑
}
// 进阶用法:指定容器工厂、局部手动ACK
@RabbitListener(
queues = RabbitResourceConfig.PAY_BUSINESS_QUEUE,
containerFactory = "manualAckListenerFactory",
ackMode = "MANUAL"
)
public void consumePayMsg(String msg, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag){
// 手动ACK消费逻辑
}
// 零配置用法:直接声明队列+交换机+绑定关系
@RabbitListener(
exchanges = @Exchange(value = "test.topic.exchange", type = ExchangeTypes.TOPIC, durable = "true"),
queuesToDeclare = @Queue(value = "test.topic.queue", durable = "true"),
bindingKeys = "test.#"
)
public void consumeTestMsg(String msg){
// 临时测试消费逻辑
}核心坑点
-
类上注解
@RabbitListener+ 方法无注解:所有方法统一监听队列,极易引发消费混乱 -
多队列监听时,未做消息类型判断,导致不同业务消息消费异常
-
局部ackMode覆盖全局配置,容易出现ACK模式不统一的问题
6.2.2 @RabbitHandler(消息分发注解)
作用 :配合类上@RabbitListener使用,实现方法级消息分发,根据消息体类型、消息头参数自动匹配对应消费方法,解决多类型消息统一队列消费问题。
核心特性
-
仅可标注在方法上,必须配合类级别的
@RabbitListener生效 -
支持根据参数类型精准分发不同消息
-
支持根据消息Header、RoutingKey自定义分发规则
-
完美适配单队列多业务类型消费场景,无需手动if判断消息类型
生产实战用法
java
// 类级别统一监听队列
@Component
@RabbitListener(queues = RabbitResourceConfig.BUSINESS_MULTI_QUEUE)
public class MultiMsgConsumer {
// 处理订单消息
@RabbitHandler
public void consumeOrderMsg(OrderDTO orderDTO, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag) {
// 订单业务消费逻辑
}
// 处理支付消息
@RabbitHandler
public void consumePayMsg(PayDTO payDTO, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag) {
// 支付业务消费逻辑
}
// 处理通用文本消息
@RabbitHandler
public void consumeCommonMsg(String msg) {
// 通用消息处理逻辑
}
}核心坑点
-
无匹配方法时,消息直接丢弃,无任何报错日志
-
子类、父类消息类型会出现匹配优先级问题,需保证参数类型精准
-
单独使用无效,必须搭配类上
@RabbitListener
6.2.3 @Exchange(交换机声明注解)
作用 :快速声明交换机,搭配@RabbitListener实现零Bean配置,支持五大交换机类型。
核心属性
-
value:交换机名称
-
type:交换机类型,支持DIRECT/TOPIC/FANOUT/HEADERS
-
durable:是否持久化,生产默认true
-
autoDelete:是否自动删除,生产常驻交换机默认false
-
internal:是否内置私有交换机,业务默认false
6.2.4 @Queue(队列声明注解)
作用:快速声明队列属性,替代Java Bean配置,支持队列持久化、独占、自动删除、拓展参数配置。
核心属性
-
value:队列名称
-
durable:队列是否持久化
-
exclusive:是否独占队列
-
autoDelete:是否自动删除
-
arguments:队列拓展参数(TTL、死信、限流、优先级等)
6.2.5 @Header(消息头获取注解)
作用:消费方法参数注解,用于获取消息内置/自定义Header属性,实现消息溯源、幂等、链路追踪。
高频内置Header参数(面试必背)
-
AmqpHeaders.DELIVERY_TAG:消息投递标识,用于ACK确认 -
AmqpHeaders.MESSAGE_ID:消息唯一ID,幂等核心依据 -
AmqpHeaders.ROUTING_KEY:消息路由键 -
AmqpHeaders.EXCHANGE:消息投递交换机 -
AmqpHeaders.REDELIVERED:是否为重投消息
6.2.6 @Retryable + @Recover(消息重试注解)
作用:实现方法级本地重试,替代全局配置,精准控制单队列消息重试策略。
-
@Retryable:开启重试,配置重试次数、间隔、重试异常类型
-
@Recover:重试失败兜底方法,重试耗尽后执行,可转发死信队列
实战示例
java
// 开启重试:最大3次,间隔1s,仅业务异常重试
@Retryable(value = BusinessException.class, maxAttempts = 3, backoff = @Backoff(delay = 1000))
public void consumeBusinessMsg(String msg){
// 业务消费逻辑
}
// 重试失败兜底
@Recover
public void recoverConsumeFail(BusinessException e, String msg){
// 记录异常日志、推送告警、转发死信
}6.2.7 @Transactional(MQ事务注解)
作用 :开启Spring本地事务,实现数据库+MQ消息本地事务一致性。
核心限制(面试高频)
-
仅支持单机本地事务,不支持分布式事务
-
事务生效范围:数据库操作 + MQ消息发送
-
异常自动回滚消息发送,避免数据库成功、消息发送失败
6.2.8 核心注解面试简答(必背)
-
@RabbitListener和@RabbitHandler区别? @RabbitListener用于监听队列、绑定资源;@RabbitHandler用于方法级消息分发,根据消息类型精准匹配消费方法,必须配合前者使用。
-
如何实现单队列多类型消息消费? 类上加@RabbitListener监听队列,多个消费方法加@RabbitHandler,通过参数类型自动分发。
-
消息重试兜底怎么实现? 使用@Retryable配置重试策略,@Recover注解实现重试失败兜底处理。
-
如何获取消息唯一标识做幂等? 通过@Header(AmqpHeaders.MESSAGE_ID)获取全局消息ID,作为幂等判断依据。
6.3 消息转换器(生产核心·深度完整版)
Spring AMQP 消息转换器是消息序列化与反序列化的核心组件,负责将Java对象转为网络传输字节流(生产者)、将字节流还原为Java对象(消费者)。默认转换器存在乱码、类型异常等诸多生产坑点,生产环境必须手动配置全局JSON转换器,是项目整合的必改核心配置。
6.3.1 原生默认转换器缺陷(必须替换)
Spring AMQP 默认使用 SimpleMessageConverter 简单转换器,底层基于JDK原生二进制序列化,存在大量生产致命问题:
-
中文乱码:字符串、中文对象传输极易出现编码错乱,无法正常解析
-
兼容性极差:仅支持JDK原生对象,跨服务、跨版本序列化极易失败
-
可读性为0:二进制格式无法直接查看消息内容,排查问题极其困难
-
泛型/嵌套对象异常:复杂DTO、嵌套实体、泛型对象反序列化直接报错
-
无统一格式规范:不同服务默认序列化规则不一致,导致消息互通失败
6.3.2 生产主流转换器选型
|----------------------------------|----------------|-------------------|-------------|
| 转换器类型 | 底层原理 | 优缺点 | 适用场景 |
| SimpleMessageConverter(默认) | JDK二进制序列化 | 简单无依赖、乱码多、兼容性差 | 仅测试使用,生产禁用 |
| Jackson2JsonMessageConverter | JSON格式化序列化 | 可读性强、跨语言兼容、支持复杂对象 | 全场景生产首选 |
| MappingJackson2MessageConverter | 定制化JSON序列化 | 可自定义日期、空值、字段过滤规则 | 特殊格式定制业务 |
| ProtoBufMessageConverter | Protobuf二进制序列化 | 体积小、速度快、可读性差 | 超高吞吐、海量消息场景 |
6.3.3 生产标准JSON转换器完整配置(已避坑)
该配置解决泛型反序列化、嵌套对象、日期格式化、乱码、类型不匹配等所有常见问题,可直接复用。
java
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonTypeInfo;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
import com.fasterxml.jackson.databind.ser.std.DateSerializer;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalDateTimeSerializer;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Date;
/**
* RabbitMQ 全局消息转换器配置
* 统一JSON序列化、解决所有序列化异常、日期乱码、泛型解析失败问题
*/
@Configuration
public class RabbitMessageConverterConfig {
/**
* 全局唯一JSON消息转换器(生产标准)
*/
@Bean
public MessageConverter jsonMessageConverter() {
ObjectMapper objectMapper = new ObjectMapper();
// 1. 注册Java8时间模块,解决LocalDateTime序列化异常
JavaTimeModule javaTimeModule = new JavaTimeModule();
// 自定义时间格式化
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
javaTimeModule.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(dateTimeFormatter));
objectMapper.registerModule(javaTimeModule);
// 2. 序列化规则配置:忽略空值、统一格式
objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
// 3. 核心:开启类型序列化,解决泛型、嵌套对象、多类型消息反序列化失败
objectMapper.activateDefaultTyping(
LaissezFaireSubTypeValidator.instance,
ObjectMapper.DefaultTyping.NON_FINAL,
JsonTypeInfo.As.PROPERTY
);
// 4. 禁用默认日期时间戳序列化,统一格式化
objectMapper.disable(com.fasterxml.jackson.databind.SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
return new Jackson2JsonMessageConverter(objectMapper);
}
}6.3.4 核心配置原理详解
-
activateDefaultTyping 核心作用 :序列化时自动追加对象类型信息,消费者可精准识别消息对象类型,彻底解决泛型DTO、多态对象、嵌套复杂对象反序列化失败问题,是生产最关键配置。
-
JavaTimeModule 适配:原生Jackson不支持Java8+时间类(LocalDateTime/LocalDate),手动注册模块避免时间类序列化报错。
-
忽略空值序列化:减少消息体体积,避免无效空字段传输,提升消息传输效率。
6.3.5 常见序列化异常与解决方案
-
异常1:泛型消息反序列化失败 原因:默认转换器无类型识别;解决方案:开启
activateDefaultTyping类型序列化。 -
异常2:LocalDateTime 序列化报错/变成时间戳 原因:缺少Java8时间模块适配;解决方案:注册
JavaTimeModule自定义格式化。 -
异常3:中文乱码 原因:二进制序列化编码不统一;解决方案:全局替换为JSON转换器,默认UTF-8编码。
-
异常4:子类字段丢失、多态对象解析不全 原因:未记录对象真实类型;解决方案:开启全局类型留存配置。
-
异常5:消息体过大、序列化冗余 解决方案:开启忽略空值序列化,精简消息体内容。
6.3.6 生产强制规范
-
所有SpringBoot整合RabbitMQ项目,必须全局配置Jackson2JsonMessageConverter,禁止使用默认转换器。
-
禁止局部自定义转换器,全局统一序列化规则,避免多服务消息互通异常。
-
所有业务消息统一使用
application/json格式,规范消息头ContentType。 -
复杂对象、泛型DTO、时间类字段,必须适配对应的序列化规则。
-
严禁在业务代码中手动序列化/反序列化,统一交由全局转换器处理。
6.3.7 面试高频问答(必背)
-
为什么要替换默认消息转换器? 默认JDK二进制序列化存在中文乱码、兼容性差、可读性低、复杂对象反序列化失败等问题,无法适配生产跨服务、复杂业务场景,JSON转换器更通用、稳定、易排查问题。
-
Jackson转换器开启类型序列化的作用? 序列化时记录对象真实类型,解决泛型、多态、嵌套对象的反序列化匹配问题,是复杂业务消息正常消费的核心保障。
-
消息序列化失败一般怎么排查? 优先检查全局转换器配置、时间类适配、类型序列化开关、消息体格式是否统一,90%异常均为转换器配置缺失导致。
6.4 监听器容器工厂(生产调优核心+面试必考)
Spring AMQP 核心容器工厂用于统一管控消费者监听容器 ,所有 @RabbitListener 消费者最终都由容器工厂创建、初始化、运行和销毁。容器工厂决定消费者的并发模型、ACK模式、预取值、重试策略、线程池、异常处理,是RabbitMQ消费性能调优、生产稳定性管控的核心组件。
6.4.1 两大核心容器类型(生产必须区分)
Spring AMQP 提供两种主流监听容器,适配不同业务场景,核心差异在并发模型、线程调度、资源占用:
1、SimpleRabbitListenerContainerFactory(简单容器·生产首选)
-
核心特性:固定线程并发模型,启动后线程数稳定,支持动态预取值、批量消费、自动重试
-
运行机制:为每个队列分配固定消费线程,线程常驻运行,持续监听队列消息
-
优势:稳定性极强、资源可控、无频繁线程创建销毁、适配绝大多数生产业务
-
适用场景:核心业务消费、长连接监听、流量稳定的常规业务(90%生产场景首选)
2、DirectRabbitListenerContainerFactory(直接容器·小众场景)
-
核心特性:动态线程模型,消息到来时临时创建线程消费,消费完成后回收线程
-
运行机制:无常驻监听线程,基于任务驱动模式消费消息
-
劣势:线程频繁创建销毁,高并发下性能损耗大,不支持部分高级特性
-
适用场景:低频次、间歇性消息消费、临时测试、低优先级非核心业务
6.4.2 核心全量参数详解(生产调优核心)
所有参数直接决定消费吞吐量、稳定性、容错性,是生产调优的关键,每个参数均标注生产规范:
-
concurrency(并发消费者数) 含义:单队列常驻消费线程数量,控制消费并发能力 生产规范:低并发业务2~4,中高并发10~20,超大流量可梯度扩容,禁止盲目超大并发导致服务过载
-
prefetch(预取值) 含义:消费者单次从服务端预拉取的消息条数,未消费确认前,服务端不再推送新消息 生产规范:核心业务10~20,均衡流量;高吞吐业务50~100;禁止设置0(无限预拉取),会导致消息堆积失衡、消费者过载
-
ackMode(ACK确认模式) 可选值:MANUAL(手动)、AUTO(自动)、NONE(无确认) 生产规范:核心业务强制MANUAL,非核心低可靠业务可AUTO,生产禁用NONE
-
batchSize(批量消费条数) 含义:累积指定条数消息后统一消费、批量ACK,提升吞吐量 生产规范:高吞吐非核心业务设置20~50,核心交易业务禁止批量消费,保证精准可控
-
receiveTimeout(消费超时时间) 含义:消费者空闲超时时间,超时无消息则释放资源 生产规范:默认适配即可,长轮询场景可适当调大,避免无效重连
-
shutdownTimeout(容器关闭超时) 含义:服务停机时,容器等待剩余消息消费完成的最大时长 生产规范:设置30000~60000ms,保证停机不丢失正在消费的消息
-
maxAttempts(本地重试最大次数) 含义:消费异常本地重试次数,配合重试策略生效 生产规范:核心业务3次,非核心业务2次,禁止无限重试
-
retryInterval(重试间隔) 含义:消费失败后下次重试间隔时间,支持梯度倍率 生产规范:基础间隔1s,梯度倍率2,避免瞬时重试导致频繁报错
-
globalRetry(全局重试开关) 含义:是否开启全局消费重试,关闭则仅局部注解重试生效
6.4.3 生产完整可落地配置(双容器适配)
配置两套容器工厂:手动ACK核心容器(交易业务)+ 自动ACK轻量容器(通知业务),适配全场景业务,可直接复制使用。
java
import org.springframework.amqp.rabbit.config.SimpleRabbitListenerContainerFactory;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.retry.backoff.ExponentialBackOffPolicy;
import org.springframework.retry.policy.SimpleRetryPolicy;
import org.springframework.retry.support.RetryTemplate;
/**
* RabbitMQ 监听器容器工厂配置
* 区分核心业务/非核心业务双容器,适配不同消费场景
*/
@Configuration
@ConditionalOnClass(RabbitTemplate.class)
public class RabbitListenerContainerConfig {
/**
* 核心业务容器工厂:手动ACK、可靠重试、低并发、高稳定
* 适配:订单、支付、交易等核心可靠业务
*/
@Bean("manualAckListenerFactory")
public SimpleRabbitListenerContainerFactory manualAckListenerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
// 绑定全局连接工厂
factory.setConnectionFactory(connectionFactory);
// 1、并发配置:核心业务小并发,保证稳定
factory.setConcurrentConsumers(5);
// 最大并发,突发流量扩容上限
factory.setMaxConcurrentConsumers(10);
// 2、预取值配置,均衡消费压力
factory.setPrefetch(15);
// 3、手动ACK模式(核心业务强制)
factory.setAckMode(AmqpHeaders.AckMode.MANUAL);
// 4、关闭批量消费,保证单条消息精准处理
factory.setBatchSize(1);
// 5、配置重试策略:3次重试,梯度间隔
RetryTemplate retryTemplate = new RetryTemplate();
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy();
retryPolicy.setMaxAttempts(3);
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(1000); // 首次重试1s
backOffPolicy.setMultiplier(2); // 倍率2倍
backOffPolicy.setMaxInterval(5000); // 最大间隔5s
retryTemplate.setRetryPolicy(retryPolicy);
retryTemplate.setBackOffPolicy(backOffPolicy);
factory.setRetryTemplate(retryTemplate);
// 6、停机超时配置,保障消息不丢失
factory.setShutdownTimeout(30000);
return factory;
}
/**
* 非核心业务容器工厂:自动ACK、高并发、高吞吐
* 适配:通知、日志、统计、非核心推送业务
*/
@Bean("autoAckListenerFactory")
public SimpleRabbitListenerContainerFactory autoAckListenerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
// 高并发适配
factory.setConcurrentConsumers(10);
factory.setMaxConcurrentConsumers(20);
// 大预取值提升吞吐
factory.setPrefetch(50);
// 自动ACK提升消费效率
factory.setAckMode(AmqpHeaders.AckMode.AUTO);
// 批量消费提升吞吐量
factory.setBatchSize(20);
// 精简重试,非核心业务无需强重试
factory.setRetryTemplate(null);
return factory;
}
}6.4.4 容器工厂生产最佳实践
-
场景隔离原则:核心交易、高可靠业务使用手动ACK容器;日志、通知、统计类非核心业务使用自动ACK高吞吐容器,严格区分不混用
-
并发配比原则:并发数与prefetch联动调优,并发越大,预取值可适度增大,避免消费饥饿
-
重试隔离原则:核心容器开启可控重试,非核心容器关闭重试,避免无效重试占用资源
-
禁止全局统一容器:所有业务共用一个容器会导致高低优先级消息互相影响,引发堆积、超时问题
-
线程池管控:禁止无限扩容并发数,根据服务器CPU、内存设置最大并发上限,防止服务线程打爆
6.4.5 高频坑点与解决方案(面试+生产)
-
坑1:prefetch设置为0 问题:消费者一次性拉取所有消息,内存溢出、负载极度不均 解决:生产必须设置固定合理预取值
-
坑2:核心业务使用自动ACK 问题:消费过程服务宕机,未执行完的消息直接丢失 解决:核心业务强制手动ACK,手动控制消息删除
-
坑3:并发数盲目开大 问题:大量线程抢占资源,CPU飙升、消费效率下降 解决:梯度扩容,结合服务器配置压测调优
-
坑4:开启批量消费处理核心消息 问题:单条消息异常导致批量消息重审,引发批量重复消费 解决:核心业务禁用批量消费
-
坑5:不区分容器,所有业务共用一个配置 问题:低优先级消息阻塞高优先级消息,业务响应延迟解决:按业务优先级拆分多套容器工厂
6.4.6 面试高频简答(必背)
-
Simple和Direct容器区别? Simple为常驻固定线程,稳定高性能,适配绝大多数生产场景;Direct为动态临时线程,低负载可用,高并发性能差,生产极少使用。
-
prefetch作用是什么?为什么不能设为0? prefetch用于控制消费者预拉取消息数量,实现消费负载均衡;设为0会一次性拉取全量消息,导致消费者内存过载、负载失衡。
-
为什么核心业务必须手动ACK容器? 自动ACK消息投递后立即标记删除,消费宕机会丢失消息;手动ACK可在业务执行成功后再确认删除,保证消息绝对可靠。
-
多容器工厂的意义? 实现业务隔离,区分核心/非核心业务的并发、重试、ACK策略,避免高低优先级业务互相影响,提升整体架构稳定性。
6.5 事务支持(原生+Spring+分布式 全量完整版)
RabbitMQ 事务分为服务端原生AMQP事务 、Spring本地整合事务 、分布式最终一致性事务三类,核心解决「业务执行与消息发送/消费的一致性问题」,彻底避免数据库操作与MQ消息不同步、消息丢失、消息多发等生产问题,是金融、交易类业务的核心保障方案。
6.5.1 RabbitMQ 原生AMQP事务(底层原理)
RabbitMQ 原生支持单信道事务,仅针对消息发送、确认操作做事务管控,不关联数据库事务,是最基础的事务机制。
1. 核心事务指令
-
channel.txSelect():开启事务,当前信道进入事务模式,所有消息发送、绑定、声明操作暂存,不真实提交
-
channel.txCommit():提交事务,批量执行所有暂存操作,消息正式入队列
-
channel.txRollback():回滚事务,清空所有暂存操作,消息全部丢弃
2. 原生事务执行流程
-
信道开启事务(txSelect)
-
执行消息发送、队列绑定等操作(操作暂存,未落地)
-
业务逻辑正常执行无异常 → txCommit 批量提交,消息持久落地
-
业务抛出异常 → txRollback 回滚,所有操作作废,无消息产生
3. 原生事务致命缺陷(生产禁用)
-
性能极差:事务模式下所有操作批量提交,无法批量收发,吞吐量断崖式下跌,仅支持单条事务提交
-
无法关联数据库:仅管控MQ操作,数据库事务与MQ事务相互独立,无法保证整体一致性
-
阻塞严重:事务未提交前,当前信道阻塞,无法执行其他操作
-
功能局限:仅支持发送事务,消费ACK无法参与事务管控
生产规范:严禁使用RabbitMQ原生tx事务,仅作底层原理了解,无任何落地场景。
6.5.2 Spring AMQP 本地事务(生产单机首选)
Spring 整合后的声明式事务 ,可实现 数据库事务 + MQ消息发送事务 联动,是单机微服务最常用的一致性方案,依托Spring事务管理器实现原子性。
1. 核心生效条件
-
项目同时引入Spring事务、Mybatis/JPA数据库事务、RabbitMQ依赖
-
开启事务注解
@EnableTransactionManagement -
方法标注
@Transactional注解,事务传播机制默认REQUIRED -
RabbitTemplate 开启事务适配(默认自动适配Spring事务)
2. 事务执行原子性
-
业务正常执行:数据库提交 + MQ消息正常发送,全部生效
-
业务抛出异常:数据库事务回滚 + MQ消息发送作废,全部失效
-
完全原子性:杜绝「数据库成功、消息未发送」或「消息发送成功、数据库回滚」的不一致问题
3. 生产实战代码(可直接复用)
java
import org.springframework.transaction.annotation.Transactional;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
/**
* Spring本地事务+MQ联动 实战示例
* 实现数据库操作与MQ消息发送原子一致性
*/
@Service
public class OrderTransactionService {
@Resource
private RabbitTemplate rabbitTemplate;
@Resource
private OrderMapper orderMapper;
// 开启Spring声明式事务
@Transactional(rollbackFor = Exception.class)
public void createOrderAndSendMsg(Order order) {
// 1. 数据库新增订单
orderMapper.insert(order);
// 2. 发送订单消息(事务管控中)
// 若后续代码报错,数据库会回滚,此消息不会发送
rabbitTemplate.convertAndSend("order.topic.exchange", "order.create", order);
// 模拟业务异常,测试事务回滚
// int i = 1 / 0;
}
}4. 核心限制与坑点
-
仅支持单机本地事务:仅当前服务的数据库+MQ操作一致性,跨服务、跨节点无效
-
不支持消费事务回滚 :仅管控消息发送,消费阶段异常无法通过Spring事务回滚
-
事务失效场景通用:方法内部调用、非public方法、异常被捕获、传播机制错误,都会导致事务失效
-
不支持分布式事务:多服务、多库场景下无法保证全局一致性
6.5.3 消息确认机制替代事务(生产高吞吐方案)
对于高吞吐、低延迟业务,事务会严重拖累性能,生产普遍采用「可靠投递机制」替代事务,实现最终一致性,兼顾性能与可靠性。
核心组合方案
-
生产者端:Confirm确认机制 + Return退回机制 + 消息持久化
-
服务端:队列+消息双持久化
-
消费者端:手动ACK + 死信队列兜底 + 消息幂等
该方案无事务性能损耗,通过补偿机制实现最终一致性,适配90%高并发生产场景。
6.5.4 分布式事务最终一致性方案(跨服务核心)
RabbitMQ 无原生分布式事务支持,跨服务、跨库场景必须通过行业通用最终一致性方案解决,以下为三种落地主流方案。
1. 本地消息表方案(最经典、零依赖)
核心原理
业务库新增消息事务表,将「业务数据入库」和「消息记录入库」放在同一个本地事务中,实现原子性,再通过定时任务扫描未发送消息,补偿投递。
执行流程
-
开启本地事务,新增业务数据 + 新增消息待发送记录(同一事务)
-
事务提交,数据库数据落地
-
异步发送MQ消息,发送成功更新消息状态为已发送
-
定时任务扫描超时未发送、发送失败的消息,重试投递
-
消费者消费成功后,回调更新消息状态,完成闭环
优缺点
-
优点:零中间件依赖、稳定可靠、适配所有微服务场景
-
缺点:需维护额外数据表、定时任务,存在少量代码侵入
2. 事务状态表+补偿任务方案(轻量化)
简化本地消息表,仅记录事务状态,不存储完整消息体,通过业务ID关联消息,减少数据库存储压力,适配高吞吐场景。
3. Seata+RabbitMQ整合方案(框架化)
依托Seata AT模式,实现跨服务分布式事务,MQ消息参与全局事务,事务失败自动回滚消息投递,适配大型微服务集群。
6.5.5 生产事务选型规范(落地口诀)
-
单机核心交易、低并发:优先 Spring 本地事务(@Transactional),简单可靠
-
单机高并发、高吞吐:放弃事务,使用 Confirm+ACK 可靠投递+兜底补偿
-
跨服务分布式场景:本地消息表 / Seata 最终一致性方案
-
所有场景:禁止使用 RabbitMQ 原生 tx 事务
6.5.6 面试高频必背问答
-
RabbitMQ原生事务和Spring事务的区别? 原生事务仅管控MQ信道操作,性能极差、无法关联数据库,生产禁用;Spring事务联动数据库+MQ发送操作,实现单机原子一致性,是单机业务首选。
-
为什么高并发场景不推荐用MQ事务? 事务会阻塞信道、批量提交无并发能力,严重降低吞吐量,高吞吐场景用可靠投递+补偿方案替代事务,兼顾性能与一致性。
-
RabbitMQ如何解决分布式事务问题? 本身不支持分布式事务,行业通过本地消息表、事务补偿、Seata框架等最终一致性方案实现,无强一致性分布式事务能力。
-
Spring MQ事务的失效场景有哪些? 非public方法、内部调用、异常被捕获、事务传播机制不匹配、未开启事务注解,均会导致事务失效,出现数据不一致问题。
6.6 异常处理(生产全方案 · 零无限重试 · 闭环兜底)
RabbitMQ消费异常是生产最常见故障点,核心痛点集中在异常消息无限重试、消息丢失、重复消费、队列堆积、业务脏数据。本章节整合生产闭环异常处理方案,包含异常分类、全局捕获、重试策略、死信兜底、兜底补偿、代码落地、避坑规范,实现消费异常100%可控闭环。
6.6.1 消费异常分类(精准区分,差异化处理)
生产环境所有MQ消费异常可分为两大类,处理逻辑完全不同,禁止统一重试处理:
-
瞬时异常(可重试异常):临时故障,重试可恢复,无需兜底丢弃 常见场景:网络短暂抖动、数据库连接超时、第三方接口临时不可用、服务器资源瞬时不足
-
业务致命异常(不可重试异常):消息本身数据错误,重试永远失败,必须立即终止重试、转入死信 常见场景:消息体格式错乱、字段缺失/非法、参数校验失败、业务逻辑不合法、数据不存在、重复操作
6.6.2 核心异常处理原则(生产强制规范)
-
禁止无限重试:所有消费异常必须限制最大重试次数,避免无效重试导致队列堆积、CPU飙升
-
异常分级处理:瞬时异常可控重试,业务异常直接终止重试、进入死信队列
-
异常不丢消息:禁止直接丢弃异常消息,所有失败消息必须有兜底存储、可追溯、可人工补偿
-
全局统一捕获:杜绝消费代码裸奔无try-catch,统一异常拦截,避免消费者宕机
-
异常可监控告警:异常消费、死信入队实时日志记录、触发告警,及时发现业务故障
6.6.3 Spring AMQP 全局异常处理器(核心兜底)
Spring AMQP 提供全局异常拦截接口,可统一捕获所有消费者消费异常,替代分散的业务try-catch,实现全局异常统一处理、日志打印、重试判定、死信路由,是生产标准化方案。
完整可落地全局异常配置代码
java
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.listener.api.RabbitListenerErrorHandler;
import org.springframework.amqp.rabbit.support.ListenerExecutionFailedException;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* RabbitMQ 全局消费异常处理器
* 统一捕获所有@RabbitListener消费异常,实现异常分级处理、日志兜底
*/
@Slf4j
@Configuration
public class RabbitGlobalExceptionConfig {
/**
* 全局异常处理器,所有消费异常统一进入该方法处理
*/
@Bean("rabbitListenerErrorHandler")
public RabbitListenerErrorHandler rabbitListenerErrorHandler() {
return (message, channel, exception) -> {
// 1. 获取消息唯一标识、消息体、异常信息
String messageId = message.getMessageProperties().getMessageId();
String body = new String(message.getBody());
log.error("MQ消费异常,消息ID:{},消息体:{},异常信息:{}",
messageId, body, exception.getMessage(), exception);
// 2. 区分异常类型,差异化处理
if (isBusinessException(exception)) {
// 业务致命异常:终止重试,自动入死信队列
log.error("【业务异常】消息数据非法,终止重试,转入死信队列,消息ID:{}", messageId);
// 抛出异常触发死信路由(手动ACK模式下需自行处理NACK)
throw new RuntimeException("消息消费失败,业务数据异常,转入死信队列");
} else {
// 瞬时异常:交由本地重试策略重试,重试耗尽后入死信
log.warn("【瞬时异常】消息消费临时失败,等待重试恢复,消息ID:{}", messageId);
throw exception;
}
};
}
/**
* 判定是否为业务不可重试异常
* 可根据项目自定义异常拓展匹配规则
*/
private boolean isBusinessException(Throwable exception) {
String errMsg = exception.getMessage();
if (errMsg == null) {
return false;
}
// 匹配数据非法、参数错误、数据不存在等不可重试场景
return errMsg.contains("参数校验失败")
|| errMsg.contains("数据不存在")
|| errMsg.contains("消息体格式错误")
|| errMsg.contains("重复操作")
|| errMsg.contains("业务逻辑校验不通过");
}
}6.6.4 异常重试完整闭环机制(杜绝无限重试)
结合前文容器工厂的重试策略,搭配异常分级,实现瞬时重试→重试耗尽→死信兜底的完整闭环,彻底解决无限重试问题。
1. 重试执行流程
-
消费抛出瞬时异常 → 本地梯度重试(1s、2s、4s)
-
3次重试全部失败 → 终止本地重试,触发NACK,不重回原队列
-
消息自动路由至死信队列,完成异常闭环
-
业务异常直接跳过重试,立即进入死信队列
2. 生产重试禁忌(高频坑点)
-
禁止代码手写while循环重试,无次数限制,极易引发服务雪崩
-
禁止对业务异常重试,无效重试只会占用服务资源
-
禁止重试无间隔、无梯度,瞬时高频重试会加重服务压力
6.6.5 手动ACK模式下异常精准处理方案
生产核心业务均为手动ACK模式,需手动控制消息确认、拒绝、重回队列、死信路由,精准管控异常消息生命周期。
完整手动消费异常处理代码
java
import com.rabbitmq.client.Channel;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Service;
/**
* 手动ACK消费异常标准处理示例
* 实现:正常ACK、瞬时异常重试、业务异常死信兜底
*/
@Slf4j
@Service
public class RabbitConsumerExceptionService {
/**
* 监听核心业务队列,使用手动ACK、核心容器工厂
*/
@RabbitListener(queues = "order.business.queue", containerFactory = "manualAckListenerFactory")
public void consumeOrderMsg(Message message, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag) {
String messageId = message.getMessageProperties().getMessageId();
try {
// 1. 解析消息、执行业务消费逻辑
String body = new String(message.getBody());
// 业务消费逻辑...
// 2. 消费成功,手动ACK确认,删除消息
channel.basicAck(tag, false);
} catch (Exception e) {
// 3. 异常分级处理
if (isBusinessError(e)) {
// 业务异常:拒绝消息,不重回队列,自动进入死信队列
log.error("订单消息业务异常,转入死信队列,消息ID:{}", messageId, e);
channel.basicNack(tag, false, false);
} else {
// 瞬时异常:重试耗尽后拒绝,避免无限重试
log.warn("订单消息瞬时消费异常,等待重试,消息ID:{}", messageId, e);
channel.basicNack(tag, false, false);
}
}
}
/**
* 业务异常判定
*/
private boolean isBusinessError(Exception e) {
String msg = e.getMessage();
return msg != null && (msg.contains("参数非法") || msg.contains("数据不存在"));
}
}
6.6.6 死信队列异常兜底规范(闭环核心)
所有消费异常消息最终兜底方案,禁止丢弃任何业务消息,保证异常消息可追溯、可人工修复重投。
1. 死信消息来源(仅三种)
-
消费异常:业务/瞬时异常重试耗尽,NACK拒绝不重回队列
-
消息过期:队列TTL超时未消费
-
队列溢出:队列达到最大长度,溢出消息转入死信
2. 死信队列生产强制规范
-
死信队列禁止配置二次死信交换机,避免消息循环路由、死信风暴
-
死信队列单独拆分,按业务维度隔离(订单死信、通知死信分开)
-
死信消息必须保留完整消息体、异常日志、时间戳、消息ID
-
死信队列配置监控告警,消息入队立即通知运维排查
-
建立死信消息处理机制:定期复盘、人工修复、批量重投工具
6.6.7 异常消息重复消费解决方案
消费异常重试、消息重投极易引发重复消费,配合异常处理必须实现消费幂等,核心方案:
-
全局唯一MessageId作为幂等键,消费前优先查询消费记录
-
数据库唯一索引约束,杜绝重复数据入库
-
消费状态记录表,标记消息未消费、消费成功、消费失败状态
-
重复消费直接ACK跳过,不执行业务逻辑
6.6.8 生产异常处理完整流程总结
-
消息消费触发异常 → 全局异常处理器捕获、日志留存、告警
-
判定异常类型:业务异常直接终止重试,瞬时异常梯度重试
-
重试成功 → 手动ACK,消息正常销毁
-
重试耗尽仍失败 → NACK拒绝消息,不重回原队列
-
消息自动路由至死信队列,完成闭环
-
运维监控感知死信消息,人工排查修复、批量重投
6.6.9 面试高频必背问答
-
消费异常为什么不能无限重试? 无限重试会持续占用CPU、线程资源,导致队列消息堆积、服务响应变慢,严重时引发服务雪崩;同时无效重试会放大瞬时异常影响范围。
-
业务异常和瞬时异常处理区别? 瞬时异常可短时间梯度重试,大概率自动恢复;业务异常为消息数据本身错误,重试永远失败,必须直接转入死信队列,禁止重试。
-
手动ACK模式下basicNack第三个参数作用? 第三个参数为requeue,true则消息重回原队列触发无限重试,false则消息不重回队列,进入死信队列,生产异常处理必须设为false。
-
如何实现消费异常完全闭环不丢消息? 全局异常捕获+分级重试+重试耗尽死信兜底+消息幂等+死信人工重投,五重保障实现异常消息零丢失、零无限重试。
第七部分 运维、监控、故障排查
7.1 权限体系(完整落地版)
7.1.1 权限核心原理与三大权限维度
RabbitMQ的权限是基于vhost维度的细粒度RBAC权限模型,所有权限绑定虚拟主机,不同vhost权限完全隔离,核心分为三大基础权限,覆盖所有服务操作,无超级权限兜底,严格遵循最小权限原则。
-
配置权限(Configure):管控交换机、队列的创建、删除、修改、绑定/解绑等元数据操作,是最高权限。 授权范围:允许用户声明、删除交换机/队列,修改队列参数、绑定关系、TTL、死信配置等所有资源配置操作。
-
写权限(Write):管控消息写入、路由转发相关操作。 授权范围:允许生产者向指定交换机推送消息、触发消息路由、消息投递等写操作。
-
读权限(Read):管控消息消费、查询相关操作。 授权范围:允许消费者监听队列、消费消息、消息ACK/NACK、查询队列消息数据、查看路由信息等读操作。
权限匹配规则:RabbitMQ权限支持正则匹配,可精准管控指定名称的交换机、队列,实现精细化资源隔离,权限优先级:精准匹配 > 正则匹配 > 全局匹配。
- 配置权限、写权限、读权限
7.1.2 生产标准用户角色与权限划分(落地规范)
生产环境禁止统一使用管理员账号,需按职能拆分5类标准角色,每类角色权限最小化、各司其职,杜绝权限溢出,适配开发、运维、监控全场景。
-
超级管理员(administrator) 权限范围:拥有所有vhost的配置、读、写全部权限,可管理用户、权限、集群、插件 使用场景:仅运维核心人员使用,日常业务禁止使用 生产规范:账号密码严格保密,禁止业务代码接入
-
业务生产者账号(producer) 权限范围:仅拥有指定业务vhost、指定交换机的【写权限】,无配置、无读权限 权限正则:仅匹配业务专属交换机,禁止操作队列、其他交换机 使用场景:微服务生产者发送消息专用,只能发消息,不能消费、不能修改资源
-
业务消费者账号(consumer) 权限范围:仅拥有指定业务vhost、指定队列的【读权限】,无配置、无写权限 权限正则:仅匹配业务专属队列,无法创建、修改任何资源 使用场景:微服务消费者消费消息专用,只能消费,不能发送、修改资源
-
业务全权限账号(business-admin) 权限范围:当前业务vhost内完整的配置、读、写权限,无其他vhost权限 使用场景:业务测试、临时排查、本地开发调试,仅限对应业务vhost生效
-
监控只读账号(monitor) 权限范围:全局只读权限,仅可查询集群状态、队列数据、连接信息、日志统计,无任何修改、读写权限 使用场景:Prometheus、Grafana监控接入、运维日常查看,禁止任何业务操作
-
生产原则:最小权限分配,不滥用管理员权限。
7.1.3 权限正则匹配语法(精准管控核心)
RabbitMQ权限依托正则表达式实现精细化管控,默认 .* 代表匹配所有资源,生产需严格限制正则范围,避免权限过大。
-
全局匹配:
.*匹配当前vhost下所有交换机、队列 -
精准匹配:
order.*仅匹配order前缀的交换机/队列 -
固定匹配:
pay.direct.exchange仅匹配指定单一资源 -
排除匹配:通过正则反向匹配,禁止操作系统内置资源
生产最优配置 :生产者仅授权业务交换机写权限,消费者仅授权业务队列读权限,严格缩小正则匹配范围,杜绝全局.* 权限。
7.1.4 常用权限实操命令(可直接复制执行)
基于rabbitmqctl命令,涵盖用户创建、权限绑定、权限查询、账号禁用全流程,生产运维直接复用。
XML
# 1. 创建自定义用户(生产禁止使用guest)
rabbitmqctl add_user business_prod Xxxx@123456
# 2. 为用户设置角色(区分管理员/普通用户)
# 设置为超级管理员
rabbitmqctl set_user_tags business_admin administrator
# 设置为普通业务用户(无管理员权限)
rabbitmqctl set_user_tags business_prod consumer
# 3. 精细化权限授权(核心生产配置)
# 语法:set_permissions [-p vhost] 用户名 配置权限正则 写权限正则 读权限正则
# 订单生产者权限:仅订单交换机可写,无配置、无读权限
rabbitmqctl set_permissions -p /business_order business_prod "^order.*" "^order.*" ""
# 订单消费者权限:仅订单队列可读,无配置、无写权限
rabbitmqctl set_permissions -p /business_order business_consumer "" "" "^order.*"
# 业务管理员权限:当前vhost全权限
rabbitmqctl set_permissions -p /business_order business_admin ".*" ".*" ".*"
# 4. 查询所有用户及权限
rabbitmqctl list_users
rabbitmqctl list_permissions -p /business_order
# 5. 清空用户权限
rabbitmqctl clear_permissions -p /business_order 用户名
# 6. 禁用/启用用户
rabbitmqctl set_user_tags 用户名 disabled
rabbitmqctl set_user_tags 用户名 consumer
# 7. 删除无用用户
rabbitmqctl delete_user 用户名7.1.5 生产权限强制规范 & 高频坑点
生产强制规范
-
严禁使用默认guest账号,必须删除/禁用,杜绝外网、内网直接访问
-
严格按vhost隔离权限,不同业务vhost账号独立,禁止跨vhost授权
-
业务账号禁止授予全局配置权限,避免随意删除队列、交换机导致业务故障
-
所有业务账号密码必须满足强复杂度(字母+数字+特殊符号),90天定期轮换
-
定期清理僵尸账号、无用权限,每月做一次权限巡检
-
监控账号仅保留只读权限,禁止任何读写、配置权限
高频坑点与解决方案
-
坑1:业务账号授予全局.*权限 风险:账号可操作所有队列、交换机,误删资源直接导致业务瘫痪 解决方案:按业务前缀正则精准授权,禁止全局权限
-
坑2:生产者账号开启读权限、消费者开启写权限 风险:权限混乱,易出现恶意消费、非法推送脏消息 解决方案:严格权责分离,生产者只写、消费者只读
-
坑3:多业务共用同一账号权限 风险:业务权限串通,A业务可操作B业务消息,数据安全失控 解决方案:一业务一账号、一vhost一权限隔离
-
坑4:测试/生产环境共用账号 风险:测试消息污染生产队列,引发生产数据异常 解决方案:环境隔离,账号、vhost完全独立
- 内存流控:内存达到阈值(默认物理内存 40%),停止接收新消息
7.1.6 面试高频必背问答
-
RabbitMQ三大权限分别是什么?作用是什么? 分为配置权限、写权限、读权限。配置权限管控交换机/队列的创建删除修改;写权限管控消息推送路由;读权限管控消息消费查询,三者相互独立,实现精细化权限管控。
-
为什么生产禁止业务账号使用全局.*权限? 全局权限可操作当前vhost所有资源,易出现误删队列、篡改配置、跨业务操作等风险,违反最小权限原则,存在极大生产安全隐患。
-
生产者和消费者权限如何区分配置? 生产者仅配置对应交换机的写权限,无配置、读权限;消费者仅配置对应队列的读权限,无配置、写权限,权责完全隔离。
-
vhost和权限的关系? 权限完全绑定vhost,不同vhost权限相互隔离,同一用户在不同vhost可配置不同权限,是多业务、多环境隔离的核心支撑。
7.2 常用命令 rabbitmqctl
本节整理生产最全 rabbitmqctl 常用命令,分类涵盖服务启停、集群管理、用户权限、vhost操作、队列/交换机运维、消息排查、故障修复、状态查询,所有命令均适配生产环境,附带详细注释与使用场景,可直接复制执行,替代零散百度命令,适配日常运维、上线排查、故障应急全场景。
7.2.1 服务启停与状态查看(基础运维)
适配单机/集群节点启停、状态校验、开机自启配置,生产禁止暴力杀进程
XML
# 1. 启动RabbitMQ服务
systemctl start rabbitmq-server
# 2. 停止RabbitMQ服务(优雅停机,优先消费完存量消息)
systemctl stop rabbitmq-server
# 3. 重启服务(生产谨慎使用,避开业务高峰期)
systemctl restart rabbitmq-server
# 4. 查看服务运行状态
systemctl status rabbitmq-server
# 5. 设置开机自启
systemctl enable rabbitmq-server
# 6. 关闭开机自启
systemctl disable rabbitmq-server
# 7. 前台启动(测试/调试使用,生产不用)
rabbitmq-server
# 8. 后台守护进程启动
rabbitmq-server -detached7.2.2 集群状态核心命令(集群运维必用)
用于集群节点校验、主从状态查看、脑裂排查、节点管理
XML
# 1. 查看集群整体状态(核心命令,查看节点、角色、磁盘类型、运行状态)
rabbitmqctl cluster_status
# 2. 将当前节点加入指定集群(集群搭建核心)
rabbitmqctl join_cluster rabbit@节点主机名
# 3. 以内存节点身份加入集群(节省节点资源)
rabbitmqctl join_cluster --ram rabbit@节点主机名
# 4. 退出集群(单节点剥离集群)
rabbitmqctl reset
# 5. 强制重置节点(节点异常、脑裂修复使用,谨慎操作)
rabbitmqctl force_reset
# 6. 修改节点类型:磁盘节点 / 内存节点
rabbitmqctl change_cluster_node_type disc
rabbitmqctl change_cluster_node_type ram
# 7. 移除集群指定故障节点
rabbitmqctl forget_cluster_node rabbit@故障节点主机名
# 8. 设置集群节点自动同步、恢复策略
rabbitmqctl update_cluster_nodes rabbit@正常节点主机名7.2.3 用户与权限命令(生产安全核心)
承接前文权限体系,完整覆盖用户增删改查、角色绑定、精细化授权
XML
# 1. 新增用户(用户名、密码)
rabbitmqctl add_user 用户名 密码
# 2. 删除用户
rabbitmqctl delete_user 用户名
# 3. 修改用户密码
rabbitmqctl change_password 用户名 新密码
# 4. 清空用户密码(禁止登录)
rabbitmqctl clear_password 用户名
# 5. 查询所有用户列表
rabbitmqctl list_users
# 6. 给用户绑定角色(administrator/monitor/consumer/producer)
rabbitmqctl set_user_tags 用户名 角色名
# 7. 精细化权限授权(语法:vhost 配置权限 写权限 读权限)
rabbitmqctl set_permissions -p /自定义vhost 用户名 "交换机/队列正则" "交换机/队列正则" "交换机/队列正则"
# 8. 清空用户指定vhost权限
rabbitmqctl clear_permissions -p /自定义vhost 用户名
# 9. 查询指定vhost下所有权限
rabbitmqctl list_permissions -p /自定义vhost
# 10. 查询指定用户的所有权限
rabbitmqctl list_user_permissions 用户名
# 11. 禁用用户(临时封禁,无需删除)
rabbitmqctl set_user_tags 用户名 disabled7.2.4 虚拟主机vhost操作命令(环境隔离)
多环境、多业务隔离必备,实现vhost增删改查、权限批量绑定
XML
# 1. 创建自定义vhost(生产禁止使用默认/)
rabbitmqctl add_vhost /business_order
rabbitmqctl add_vhost /business_pay
# 2. 删除无用vhost(谨慎操作,会清空所有队列、交换机数据)
rabbitmqctl delete_vhost /废弃vhost名
# 3. 查询所有vhost列表
rabbitmqctl list_vhosts
# 4. 查看vhost详细信息(状态、资源数)
rabbitmqctl list_vhosts name tracing
# 5. 复制vhost权限(环境迁移、批量授权)
rabbitmqctl copy_vhost_permissions 源vhost 目标vhost7.2.5 交换机运维命令(路由资源管理)
用于交换机查询、创建、删除、绑定关系排查,适配线上资源排查
XML
# 1. 查询指定vhost下所有交换机(名称、类型、持久化、状态)
rabbitmqctl list_exchanges -p /自定义vhost
# 2. 手动创建交换机(direct/topic/fanout/headers)
# 语法:declare_exchange vhost 交换机名 类型 持久化(true/false) 自动删除
rabbitmqctl declare_exchange -p /business_order order.direct.exchange direct true false
# 3. 删除指定交换机(谨慎操作,解绑所有队列绑定关系)
rabbitmqctl delete_exchange -p /business_order 交换机名
# 4. 查询交换机绑定关系
rabbitmqctl list_bindings -p /自定义vhost7.2.6 队列核心运维命令(生产高频使用)
队列排查、消息堆积统计、队列清空、队列删除、镜像/仲裁队列管理
XML
# 1. 查询所有队列核心信息(名称、消息数、消费者数、持久化、内存占用)
rabbitmqctl list_queues -p /自定义vhost
# 2. 精准查询:消息数、消费者、队列状态、持久化、优先级、TTL配置
rabbitmqctl list_queues -p /自定义vhost name messages consumers durable arguments
# 3. 手动创建队列
rabbitmqctl declare_queue -p /business_order order.business.queue true false false
# 4. 清空队列所有消息(保留队列,仅删除消息,生产常用)
rabbitmqctl purge_queue 队列名 -p /自定义vhost
# 5. 删除队列(清空消息+删除队列本身,谨慎操作)
rabbitmqctl delete_queue 队列名 -p /自定义vhost
# 6. 查看队列绑定的交换机、路由键
rabbitmqctl list_bindings -p /自定义vhost | grep 队列名
# 7. 查看队列镜像/仲裁配置状态
rabbitmqctl list_queue_configs -p /自定义vhost7.2.7 连接与信道排查命令(线上故障必查)
排查连接泄漏、信道堆积、异常连接、客户端非法接入
XML
# 1. 查看所有客户端连接(IP、端口、用户、vhost、连接状态、内存占用)
rabbitmqctl list_connections
# 2. 筛选异常连接(空闲连接、长时间挂起连接)
rabbitmqctl list_connections pid user host port idle
# 3. 强制关闭异常连接(解决连接泄漏、非法接入)
rabbitmqctl close_connection 连接PID "连接异常,手动强制关闭"
# 4. 查看所有信道(归属连接、状态、是否泄漏、操作记录)
rabbitmqctl list_channels
# 5. 筛选空闲、异常信道
rabbitmqctl list_channels pid connection_id idle state7.2.8 消息与消费状态排查命令
排查消息堆积、未确认消息、死信消息、消费异常
XML
# 1. 查看队列未消费消息、待确认消息、总消息数
rabbitmqctl list_queues messages messages_unacknowledged messages_ready
# 2. 查看消费者详情(消费队列、IP、预取值、消费状态)
rabbitmqctl list_consumers -p /自定义vhost
# 3. 统计全局消息生产、消费速率
rabbitmqctl status | grep message7.2.9 数据备份与恢复命令(生产兜底)
元数据定期备份、故障恢复、集群数据迁移必备
XML
# 1. 备份集群所有元数据(交换机、队列、用户、权限、绑定关系)
rabbitmqctl backup /备份路径/backup-file
# 2. 恢复元数据(节点故障重建、集群迁移使用)
rabbitmqctl restore /备份路径/backup-file
# 3. 导出指定vhost配置
rabbitmqctl export_definitions /导出路径/vhost-def.json -p /自定义vhost
# 4. 导入vhost配置(新环境快速搭建)
rabbitmqctl import_definitions /导出路径/vhost-def.json -p /自定义vhost7.2.10 性能与流控排查命令
排查内存、磁盘、流控触发、节点性能瓶颈
XML
# 1. 查看节点全局状态(内存、磁盘、CPU、进程数、流控状态)
rabbitmqctl status
# 2. 查看内存使用详情、内存水位线配置
rabbitmqctl eval 'rabbit_memory:status().'
# 3. 查看磁盘使用、磁盘水位线配置
rabbitmqctl eval 'rabbit_disk_monitor:get_disk_free_space().'
# 4. 查看当前是否触发流控
rabbitmqctl list_nodes | grep flow7.2.11 日志与插件管理命令
插件启停(延时队列、监控、联邦插件)、日志路径查看
XML
# 1. 查看所有已安装插件
rabbitmq-plugins list
# 2. 启用延时队列插件(生产高频)
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
# 3. 启用管理后台插件
rabbitmq-plugins enable rabbitmq_management
# 4. 启用跨机房联邦插件、Shovel插件
rabbitmq-plugins enable rabbitmq_federation
rabbitmq-plugins enable rabbitmq_shovel
# 5. 禁用插件
rabbitmq-plugins disable 插件名
# 6. 查看日志存储路径
rabbitmqctl environment | grep log7.2.12 生产命令使用规范与禁忌
-
禁止高危命令随意执行:reset、force_reset、delete_vhost、delete_queue 必须确认业务,避开高峰期
-
优先使用优雅操作:清空消息用 purge_queue,禁止直接删队列重建
-
集群操作规范:集群启停、节点移除必须先查看 cluster_status,避免脑裂
-
权限操作规范:所有账号授权必须使用正则精准匹配,禁止全局 .* 授权
-
排查优先原则:消息堆积、消费异常,先查 list_queues、list_connections、list_consumers 定位问题
7.3 流控机制 Flow Control(重点故障点 · 生产高频故障)
RabbitMQ 流控(Flow Control)是服务端自我保护机制,核心作用是当节点内存、磁盘、进程负载达到阈值时,限制生产者消息推送速率,避免服务过载、内存溢出、磁盘打满、节点宕机,是生产环境最常见的故障诱因之一。流控触发后会直接导致生产者阻塞、业务接口超时、消息堆积,必须熟练掌握排查与根治方案。
7.3.1 流控核心分类与完整触发原理
RabbitMQ 流控分为客户端级流控 和节点级流控,节点级流控又包含内存流控、磁盘流控两类,所有流控均为主动拦截消息写入,保护服务稳定性。
1. 内存流控(最常见)
核心原理:RabbitMQ 基于物理内存占比判定阈值,默认当节点内存占用达到物理内存40%(默认阈值),立即触发全局内存流控。
-
触发逻辑:内存占用 > vm_memory_high_watermark 阈值 → 暂停接收所有生产者新消息 → 阻塞客户端连接/信道
-
恢复逻辑:内存占用回落至阈值的50%(默认回水位),自动解除流控,恢复消息接收
-
核心危害:触发后生产者发送消息直接阻塞,业务接口超时、重试风暴、消息大批量堆积
2. 磁盘流控(致命故障)
核心原理:检测节点剩余磁盘空间,当空闲磁盘低于预设水位线,触发磁盘流控,彻底禁止消息写入。
-
默认阈值:剩余磁盘空间 < 50MB(可自定义配置)
-
触发逻辑:磁盘剩余空间不足 → 拒绝所有新消息投递、禁止消息持久化落盘
-
特殊场景:磁盘满后不仅拦截生产,还会停止消息刷盘、集群同步,引发集群同步失败、节点异常
3. 客户端信道流控(精细化流控)
区别于全局节点流控,针对单个信道/连接限流,不影响整个节点其他业务,优先级低于节点流控。当单个客户端信道消息推送速率过快、服务端消费处理跟不上,触发单信道流控,精准限制异常客户端,避免单业务拖垮全局集群。
7.3.2 核心配套机制:内存分页 Page Out(性能杀手)
内存流控前置高危机制,是生产性能暴跌的核心诱因,优先级高于流控。
-
触发条件:内存占用达到阈值后,继续推送消息,内存持续溢出
-
机制原理:RabbitMQ 将内存中未消费的消息强制分页写入磁盘(Page Out),释放内存空间
-
致命危害:磁盘IO速度远低于内存,消息读写速度断崖式下跌,QPS骤降90%以上,引发大规模消息堆积、业务超时,生产绝对禁止触发内存分页
-
核心区别:流控是阻止新消息进入 ,分页是内存消息落地磁盘,分页比流控危害更大
7.3.3 流控完整配置参数(生产自定义调优)
所有参数可在 rabbitmq.conf 配置文件自定义,适配不同服务器配置与业务流量,生产禁止使用默认参数。
XML
# 1. 内存高水位阈值(默认0.4=40%物理内存)
vm_memory_high_watermark = 0.5
# 内存回落水位(阈值占比,默认0.5),内存降至 总内存*0.5*0.5 解除流控
vm_memory_high_watermark_relative = 0.5
# 2. 磁盘最低水位阈值(默认50MB,单位bytes)
disk_free_limit = 104857600
# 3. 关闭内存分页(生产强制配置,杜绝性能暴跌)
vm_memory_page_out_threshold = 07.3.4 流控触发核心现象(快速识别故障)
1. 服务端现象
-
管理后台节点状态显示 flow control 流控标记
-
节点内存/磁盘占用持续高位,无法释放
-
集群消息同步延迟、节点数据不一致
-
无新消息入队,队列消息只增不减
2. 客户端业务现象
-
生产者发送消息超时、接口响应卡顿、大量报错
-
客户端连接阻塞、信道卡死,无消息投递成功日志
-
消息堆积持续上涨,消费速率远低于生产速率
-
微服务调用超时、重试,引发连锁业务故障
7.3.5 流控故障完整排查步骤(生产落地)
-
确认流控状态 :执行
rabbitmqctl list_nodes | grep flow,查看节点是否处于流控状态 -
定位流控类型 :执行
rabbitmqctl status,查看内存、磁盘占用,区分内存/磁盘流控 -
排查堆积根源:查看队列消息数、消费者在线数、消费速率,确认是消费停滞还是流量突增
-
检查客户端状态:排查连接、信道是否泄漏,是否存在异常客户端高频推送消息
-
校验配置参数:核对内存、磁盘水位阈值是否合理,是否存在配置过小问题
7.3.6 分级解决方案(紧急处理+根治方案)
1. 紧急止血方案(故障爆发时立即执行)
-
临时限流:关闭非核心业务消息生产,仅保留核心交易业务,减少流量输入
-
扩容消费能力:临时增加消费者实例、调大消费者并发数,快速消费堆积消息
-
清理无效消息:清空过期、无效堆积消息,快速释放内存磁盘资源(谨慎操作核心业务)
-
重启异常节点:针对内存泄漏、卡死节点,优雅重启恢复资源
2. 长期根治方案(生产规范落地)
-
优化阈值配置:根据服务器配置调大内存水位(40%→50%),合理设置磁盘阈值,避免误触发流控
-
杜绝内存分页:关闭自动分页机制,从根源避免性能断崖下跌
-
流量削峰:核心业务队列配置最大长度+溢出策略,避免消息无限堆积占满资源
-
客户端治理:限制单IP连接数、单信道推送速率,杜绝异常客户端打爆服务
-
监控前置告警:内存、磁盘占用达到80%阈值提前告警,不等流控触发再处理
-
业务拆分:大流量队列拆分分片,分散节点压力,避免单节点过载
7.3.7 生产高频坑点总结
-
坑1:误以为流控是MQ故障,实际是MQ的自我保护机制,根源是业务流量过载/消费能力不足
-
坑2:内存分页触发后只重启服务,不解决堆积根源,重启后瞬间再次触发流控
-
坑3:默认阈值适配小服务器,高配服务器不修改阈值,资源浪费、频繁误流控
-
坑4:流控期间频繁重启客户端,导致连接风暴、加重集群压力
-
坑5:未区分节点流控和单信道流控,盲目扩容全集群,无法解决单业务异常问题
7.3.8 面试高频必背问答
-
RabbitMQ流控的作用是什么? 流控是MQ自我保护机制,当节点内存、磁盘资源达到阈值时,限制消息写入速率,防止服务过载、内存溢出、磁盘打满、节点宕机,保障集群基础稳定性。
-
内存流控和磁盘流控哪个危害更大? 磁盘流控危害更大,直接禁止所有消息写入,导致业务完全中断;内存流控仅阻塞生产,资源回落可自动恢复。而内存分页是比流控更严重的性能故障。
-
流控和内存分页的区别? 流控是拦截新消息进入,保护服务不崩溃;内存分页是将内存存量消息写入磁盘,导致性能暴跌、堆积加剧,生产必须杜绝分页触发。
-
触发流控后如何快速恢复业务? 优先扩容消费者提升消费能力、清理无效堆积消息释放资源,临时限流非核心流量,资源回落自动解除流控,后续优化阈值与业务流量架构根治问题。
7.4 消息堆积(生产最高频故障 · 全场景解决方案)
7.4.1 消息堆积核心定义与危害
消息堆积指RabbitMQ队列中未被消费的消息持续累积、只增不减,生产速率长期大于消费速率的异常现象,是MQ最核心的生产故障。
核心生产危害
-
业务延迟:实时业务、通知、订单任务延迟执行,用户体验受损,超时任务大面积失效
-
服务雪崩:海量消息堆积占用磁盘、内存资源,触发MQ内存/磁盘流控,阻塞生产者,导致上游业务接口超时、重试风暴
-
消息丢失风险:队列堆满触发溢出策略,旧消息被丢弃;长时间堆积导致消息过期失效
-
性能暴跌:海量消息持久化引发频繁磁盘IO,MQ整体吞吐量断崖式下降
-
数据不一致:订单、支付等核心业务消息堆积,导致业务状态同步滞后,引发数据错乱
7.4.2 消息堆积完整分类(精准定位问题根源)
1. 瞬时峰值堆积(良性临时堆积)
成因:秒杀、活动促销、流量突发、定时任务集中触发,短时间流量远超日常均值,消费者正常运行但瞬时处理不过来。
特征:消费者在线正常消费、消费速率稳定,流量回落後堆积可自动清零,无业务异常日志,属于正常流量削峰现象。
判定标准:堆积量随流量波动,峰值上涨、低谷持续下降,无持续递增趋势。
2. 持续递增堆积(恶性核心故障)
成因:消费能力永久性不足、消费者故障、消费阻塞,生产速率持续大于消费速率,堆积量只增不减。
特征:队列消息数持续上涨、消费者在线数正常/异常、消费速率极低甚至为0,长期无法自动恢复。
核心诱因:业务代码Bug、消费阻塞、并发配置过低、服务资源瓶颈。
3. 假堆积(最易误判)
成因:消费者进程存活、端口监听正常、后台显示在线,但实际消费逻辑卡死、线程阻塞、循环等待,无真实消费动作。
特征:消费者进程存活、连接信道正常、无消费报错日志,但消息始终堆积、ready消息只增不减。
常见场景:消费逻辑死循环、外部接口阻塞无超时、分布式锁卡死、数据库连接耗尽。
4. 死信堆积(特殊异常堆积)
成因:消息重试耗尽、消息过期、消费拒绝,大量异常消息涌入死信队列,死信队列无消费者处理,持续堆积。
危害:掩盖真实业务故障,长期堆积占用MQ资源,遗漏异常业务数据。
7.4.3 消息堆积全维度成因(生产全覆盖)
1. 消费者侧核心成因(90%堆积根源)
-
消费阻塞卡死:消费逻辑调用第三方接口、数据库、缓存无超时配置,线程无限阻塞
-
代码业务Bug:消费代码报错、空指针、参数异常,频繁重试失败,消息无法消费
-
消费并发不足:prefetch取值过小、消费者线程数过低、实例数太少,消费能力跟不上生产
-
手动ACK未提交:业务逻辑异常未执行ACK/NACK,消息一直处于未确认状态,重复堆积
-
消费者宕机/重启频繁:服务熔断、OOM、部署重启,导致消费中断
-
幂等逻辑卡死:重复消息触发幂等判断死循环、锁等待超时
2. 生产者侧成因
-
流量突发暴涨:秒杀、活动、批量任务导致瞬时流量峰值超出预估
-
无效消息刷屏:代码异常重复投递、循环发送消息,产生海量无效数据
-
消息批量推送:批量同步数据、历史数据重投,瞬间涌入大量消息
3. MQ服务端成因
-
触发流控机制:内存/磁盘达到阈值触发流控,消息生产受阻、消费卡顿
-
集群节点异常:主节点宕机、集群同步失败、脑裂问题,消息无法正常路由消费
-
队列配置不合理:无溢出策略、无消息过期时间,异常消息无限堆积
-
内存分页触发:消息过多内存落盘,IO性能暴跌,消费速率骤降
4. 环境与资源成因
-
服务器CPU、内存、磁盘IO打满,消费者进程被限流、卡顿
-
网络抖动、延迟过高,消息收发不稳定
-
数据库连接池耗尽、缓存服务宕机,导致消费逻辑无法执行
7.4.4 五步极速排查流程(生产落地版)
第一步:确认堆积类型
执行命令查看队列核心数据:rabbitmqctl list_queues -p /对应vhost name messages_ready messages_unacknowledged consumers
-
messages_ready>0、消费者正常:未消费堆积
-
messages_unacknowledged>0:消费阻塞、未ACK堆积
-
消费者数为0:消费者全部宕机离线
第二步:排查消费者状态
查看消费者在线数、连接信道状态,确认是否为假堆积;查看服务日志,排查报错、阻塞、超时、死循环问题
第三步:校验消费配置参数
核对prefetch预取值、消费者并发数、超时时间、重试策略,判断是否存在并发不足、重试无限叠加问题
第四步:检查MQ服务端状态
查看节点是否触发流控、内存磁盘占用、集群状态、同步情况,排除服务端性能与集群故障
第五步:溯源流量来源
排查生产者日志,确认是否存在流量突增、重复投递、无效消息刷屏问题
7.4.5 分级处理解决方案(紧急止血+根治)
1. 紧急止血方案(5分钟快速恢复业务)
-
处理阻塞堆积:重启卡死的消费者服务,释放阻塞线程,恢复消费能力
-
临时扩容消费:快速增加消费者实例数、调大prefetch并发、提升线程数,快速消化存量消息
-
隔离异常消息:暂停生产异常消息,将报错堆积消息转入死信队列,避免持续阻塞
-
释放资源:清理无效堆积消息、释放MQ内存磁盘,解除流控限制
2. 中期优化方案(解决持续堆积)
-
修复消费Bug:修复代码报错、死循环、接口无超时、锁等待等核心问题
-
优化消费配置:合理配置prefetch、消费超时、重试次数,避免无限重试堆积
-
队列拆分分流:大流量队列拆分分片,分散消费压力,避免单队列过载
-
流量限流管控:队列配置最大长度+溢出策略,限制消息无限堆积
3. 长期根治方案(生产规范落地)
-
全链路超时控制:消费逻辑所有外部调用(接口、DB、缓存)强制配置超时时间,杜绝线程阻塞
-
完善异常兜底:全局异常捕获,所有消费异常自动NACK、转入死信队列,禁止无效重试
-
精准流量预估:基于历史峰值配置弹性扩容策略,适配流量波动
-
完善监控告警:堆积量、消费速率、未确认消息数实时告警,提前干预
-
消息规范约束:统一消息格式、大小限制,杜绝超大消息、无效消息刷屏
7.4.6 特殊场景处理:海量历史堆积消息
针对百万级、千万级海量消息堆积,禁止直接重启服务、批量消费,避免CPU/IO打满引发故障,标准处理流程:
-
临时新增消费者集群,单独承担存量消息消费,不影响实时业务
-
关闭存量消息重试机制,避免重复消费耗时
-
批量消费、分批ACK,降低单次IO压力
-
过期无效消息直接批量清空,减少消费压力
-
存量消息消费完毕后,恢复正常消费策略
7.4.7 生产高频坑点总结
-
坑1:只扩容消费者不修复代码Bug,治标不治本,扩容后依旧持续堆积
-
坑2:消费阻塞不处理,盲目重启MQ服务,重启后消息重新堆积,故障复现
-
坑3:无限重试未配置次数,异常消息反复消费,持续占用线程资源
-
坑4:忽略假堆积场景,误以为消费者未启动,盲目排查部署问题
-
坑5:超大消息未拆分,单消息消费耗时过长,导致整体消费速率极低
-
坑6:未配置死信队列,异常消息滞留原队列,持续阻塞正常消息消费
7.4.8 面试高频必背问答
-
如何快速区分真堆积和假堆积? 真堆积是流量大、消费能力不足,消费者正常消费、速率稳定;假堆积是消费者进程存活但线程阻塞、逻辑卡死,无真实消费行为,unack消息持续堆积,无日志输出。
-
消息堆积最核心的原因是什么? 90%场景为消费者问题:消费代码异常、线程阻塞、并发配置不足、未手动ACK、无限重试;其次是流量突增和MQ服务端流控、集群故障。
-
海量消息堆积为什么不能直接重启服务? 重启后所有未ACK消息重新入队,瞬间引发大批量重复消费,CPU、IO飙升,直接导致服务雪崩,加重故障。
-
如何预防消息堆积? 代码层加超时、异常兜底、死信队列;配置层优化并发与重试策略;监控层提前告警;架构层队列拆分、流量限流,全链路预防。
-
unack消息堆积如何处理? 排查消费阻塞代码,修复Bug后重启消费者,手动触发NACK,让未确认消息重新消费,同时优化超时与重试配置,避免再次阻塞。
7.5 日志体系
-
日志分级、日志切割、定时归档
-
核心排查日志:连接日志、路由日志、集群日志、异常日志
7.6 数据备份与恢复(生产全流程落地版)
RabbitMQ 生产数据分为元数据 和业务消息数据两类,元数据包含交换机、队列、绑定关系、用户权限、参数配置等集群核心资源;消息数据为队列中存储的业务存量消息。生产故障、集群重建、环境迁移、误操作删除都会导致数据丢失,因此必须建立标准化的备份、定时归档、故障恢复、数据迁移全流程规范,保障集群数据安全。
7.6.1 核心备份分类与优先级
根据业务重要性划分备份等级,适配不同生产场景,避免过度备份或备份缺失:
-
一级核心(必备):集群元数据,所有环境强制定时备份,丢失会导致集群资源全部失效,业务无法收发消息
-
二级核心(按需备):核心业务消息数据,金融、支付、订单等不可丢失业务,需额外做消息数据兜底备份
-
三级非核心(可选):日志、监控数据,用于故障溯源,无需高频备份,按需归档即可
7.6.2 元数据完整备份方案(生产强制落地)
元数据是集群运行的基础,支持单vhost精准备份和全局集群备份,适配环境迁移、故障重建、误操作恢复场景。
1. 单虚拟主机备份(推荐生产用法)
按业务vhost独立备份,隔离性强,恢复精准,不会覆盖其他业务配置,是日常运维首选方案。
XML
# 语法:rabbitmqctl export_definitions 备份文件路径 -p 目标vhost
# 示例:备份订单业务vhost元数据
rabbitmqctl export_definitions /data/rabbitmq/backup/order_vhost_def_$(date +%Y%m%d).json -p /business_order
# 示例:备份支付业务vhost元数据
rabbitmqctl export_definitions /data/rabbitmq/backup/pay_vhost_def_$(date +%Y%m%d).json -p /business_pay2. 全局集群元数据备份
备份整个集群所有vhost、用户、权限、交换机、队列、绑定关系全量数据,适用于集群整体迁移、整机故障兜底。
XML
# 全局全量元数据备份(无-p参数代表备份所有vhost) rabbitmqctl export_definitions /data/rabbitmq/backup/cluster_all_def_$(date +%Y%m%d).json3. 原生集群快照备份(完整兜底)
rabbitmqctl backup 为官方原生快照备份,可备份集群完整运行状态、节点配置、持久化元数据,适配节点彻底损坏场景。
XML
# 集群快照备份
rabbitmqctl backup /data/rabbitmq/backup/cluster_backup_$(date +%Y%m%d)4. 定时自动备份规范(生产标准)
通过Linux定时任务配置自动备份,杜绝人工遗漏,配套过期清理策略,避免磁盘占用过高:
-
备份频率:核心业务vhost 每日凌晨自动备份,集群全量备份每周1次
-
文件命名:统一携带日期后缀,区分备份版本
-
过期清理:自动删除7天前的日常备份、30天前的全量备份
-
备份存储:独立磁盘存储,禁止和MQ数据同盘,避免磁盘故障连带丢失备份
XML
# 定时任务示例(crontab -e):每日凌晨2点备份订单vhost元数据
0 2 * * * rabbitmqctl export_definitions /data/rabbitmq/backup/order_vhost_def_$(date +\%Y\%m\%d).json -p /business_order >> /data/rabbitmq/backup/backup_log.log 2>&1
# 每日凌晨3点清理7天前备份文件
0 3 * * * find /data/rabbitmq/backup/ -name "*.json" -mtime +7 -delete7.6.3 元数据恢复标准流程(故障应急)
适用于误删队列/交换机、权限丢失、vhost配置异常、节点重建后配置恢复场景,严格遵循以下步骤避免二次故障。
1. 前置准备(必做)
-
停止生产者服务,暂停消息投递,避免恢复期间消息异常丢失、路由错乱
-
确认目标vhost已存在,不存在则先创建对应虚拟主机
-
备份当前异常配置,防止恢复失败可回滚
2. 单vhost精准恢复
XML
# 恢复指定vhost元数据(覆盖当前配置)
rabbitmqctl import_definitions /data/rabbitmq/backup/order_vhost_def_20260601.json -p /business_order3. 全局集群恢复
XML
# 恢复集群全量元数据
rabbitmqctl import_definitions /data/rabbitmq/backup/cluster_all_def_20260601.json4. 快照整体恢复
XML
# 从集群快照恢复完整数据
rabbitmqctl restore /data/rabbitmq/backup/cluster_backup_202606015. 恢复后校验步骤
-
查看交换机、队列是否全部恢复:
rabbitmqctl list_exchanges / list_queues -
校验队列与交换机绑定关系、路由键是否正常
-
核对用户权限、vhost配置是否生效
-
启动测试生产者,验证消息收发正常后恢复业务
7.6.4 业务消息数据备份与恢复(核心业务专属)
元数据备份仅恢复集群配置,无法恢复已堆积的业务消息,针对金融、支付、订单等零丢失核心业务,需单独做消息数据兜底方案。
1. 消息备份方案
-
消费落地备份:消费者消费消息后,同步将完整消息体入库存储(MySQL/ES),作为永久数据兜底
-
队列镜像兜底:核心队列开启仲裁队列/镜像队列,集群多节点实时同步消息,单节点故障不丢失数据
-
定时迁移备份:针对长期堆积的重要消息,定时批量迁移至备份队列归档
2. 丢失消息恢复方案
-
日志溯源重投:通过生产端唯一MessageId、链路日志,定位丢失消息,批量重新投递
-
数据库兜底重推:基于业务库订单/支付数据,批量补发缺失消息
-
备份队列恢复:从归档备份队列迁移消息至业务队列,恢复消费
7.6.5 集群迁移完整方案(跨环境/跨机器迁移)
适用于服务器换代、机房迁移、集群扩容重构场景,零停机、零数据丢失迁移流程:
-
新集群部署:搭建同版本、同配置新RabbitMQ集群,保证环境一致性
-
元数据迁移:旧集群导出全量元数据,导入新集群,还原所有vhost、队列、交换机、权限
-
消息数据迁移:通过Shovel插件/消费转发,将旧集群存量消息同步至新集群
-
流量灰度切换:先切换测试流量,验证消息收发正常后,全量切换业务流量
-
旧集群兜底保留:流量切换完成后,保留旧集群7天,无业务异常再下线
7.6.6 生产备份恢复禁忌与坑点(必避)
-
坑1:仅备份元数据,不做消息兜底,集群故障后存量消息全部丢失
-
坑2:跨版本恢复元数据,高低版本配置不兼容,导致队列、交换机失效
-
坑3:恢复操作未暂停业务,引发消息重复投递、路由错乱、数据重复
-
坑4:备份文件与MQ同盘存储,磁盘故障导致备份、数据全部丢失
-
坑5:长期不校验备份文件,备份损坏无法使用,故障时无兜底方案
-
坑6:全局元数据恢复会覆盖现有权限、配置,生产需优先使用单vhost精准恢复
7.6.7 日常巡检备份规范
-
每日校验自动备份文件是否生成、文件大小是否正常,杜绝空备份
-
每周随机抽取1份备份文件,在测试环境模拟恢复,验证备份可用性
-
每月清理过期备份,优化磁盘存储,保证备份资源可控
-
集群版本升级、配置大幅修改前,必须手动备份一次全量数据
7.7 监控与告警
7.7.1 监控方案
Prometheus + Grafana 接入,采集核心指标: 生产速率、消费速率、消息堆积、连接数、信道数、内存、磁盘、节点状态。
7.7.2 必配告警规则
-
消息堆积超限告警
-
集群节点离线、主从切换告警
-
内存/磁盘临近水位告警
-
流控触发、连接数突增告警
第八部分 生产安全体系
8.1 账号安全
-
禁用默认 guest 账号,外网绝对禁止使用
-
密码强复杂度,定期轮换
-
清理无用账号,关闭匿名访问
8.2 网络安全
-
防火墙限制端口:
-
5672:客户端通信端口
-
15672:Web 管理后台
-
25672:集群通信端口
-
-
配置 IP 白名单,仅业务服务器访问
-
外网/跨机房开启 SSL/TLS 加密传输,防窃听、篡改
8.3 防攻击体系(生产全维度防护)
RabbitMQ 开源默认配置较为宽松,公网/内网暴露场景易遭遇端口扫描、恶意连接、消息轰炸、DOS/DDOS攻击、资源耗尽攻击,导致集群瘫痪、业务中断、数据异常。以下为生产环境全套可落地的防攻击配置、防护策略与避坑规范,覆盖连接、流量、资源、权限全维度防护。
8.3.1 常见攻击类型与危害
-
恶意连接攻击:单机高频创建大量无效Connection/Channel,耗尽MQ服务端连接数、端口资源,导致正常业务无法建连。
-
消息轰炸攻击:高频推送海量无效消息、超大消息,打满队列、磁盘与内存,触发流控、节点宕机。
-
端口扫描攻击:扫描5672、15672、25672端口,暴力破解账号密码,窃取或篡改业务数据。
-
DOS资源耗尽攻击:创建大量独占队列、临时队列不销毁,占用集群资源,导致正常业务队列无法创建。
-
恶意消费攻击:非法消费者抢占队列消费权限,批量NACK消息引发无限重试,造成消息堆积、服务卡顿。
8.3.2 核心防护配置(生产强制落地)
1. 连接数限流(防恶意建连)
通过配置文件限制单IP最大连接数、全局最大连接数,杜绝单IP恶意刷屏建连,防止端口与文件句柄耗尽。
XML
# rabbitmq.conf 核心限流配置
# 全局最大连接数(根据服务器配置调整,常规集群设置2000-5000)
max_connections = 3000
# 单IP最大连接数(限制恶意单机批量建连)
per_ip_max_connections = 50
# 空闲连接超时自动断开(清理僵尸无效连接,单位毫秒)
connection_timeout = 600002. 消息流量限流(防消息轰炸)
从消息条数、消息大小、推送速率三维度限流,防止海量无效消息、超大消息击穿集群。
XML
# 单信道最大未确认消息数,防止单客户端霸占消费资源
consumer_prefetch_limit = 100
# 单客户端最大消息推送速率(条/秒),抑制高频轰炸
publisher_rate_limit = 1000
# 全局单消息最大限制(10MB),拦截超大消息
max_message_size = 104857603. 僵尸资源自动清理(防资源耗尽)
自动清理长时间空闲的连接、信道、临时队列,避免恶意创建无效资源占用集群内存与磁盘。
XML
# 空闲信道超时自动关闭(30秒)
channel_idle_timeout = 30000
# 临时队列空闲超时自动销毁,防止恶意堆积无效队列
temp_queue_idle_timeout = 600008.3.3 权限与访问防护(防越权攻击)
-
最小权限原则:严格区分账号权限,生产者仅赋予发送权限、消费者仅赋予消费权限,禁止普通业务账号拥有队列删除、权限修改、集群配置权限。
-
禁止全局权限 :所有账号授权禁止使用
.*全局正则,仅授权业务所需vhost、队列、交换机。 -
账号风控:开启登录失败限流,连续5次密码错误封禁IP,防止暴力破解。
-
定期巡检账号:自动检测无用账号、异常登录IP、异地登录记录,及时清理风险账号。
8.3.4 网络层防护(基础兜底)
-
端口严格封禁:外网防火墙彻底禁用5672、15672、25672端口,仅内网白名单IP开放。
-
白名单机制:仅业务服务、运维服务器IP可访问MQ集群,拒绝所有陌生IP连接请求。
-
传输加密:内网核心业务可选SSL加密,外网/跨机房通信强制开启TLS加密,防止消息窃听、篡改、劫持。
-
屏蔽端口扫描:防火墙配置拦截高频端口探测、异常报文请求,规避扫描攻击。
8.3.5 客户端防攻击规范
-
业务客户端统一使用连接池,禁止循环创建Connection/Channel,杜绝人为引发的连接风暴。
-
所有消息必须携带唯一MessageId,服务端可拦截重复消息、无效异常消息。
-
生产者开启Confirm、Return回调,拦截非法路由、异常投递请求。
-
消费端配置超时与重试上限,避免恶意消息引发无限重试、线程阻塞。
8.3.6 攻击应急排查与处置命令
XML
# 1. 查看异常连接、高频连接IP(快速定位攻击源)
rabbitmqctl list_connections host peer_port state
# 2. 强制踢出恶意IP所有连接
rabbitmqctl close_all_connections host=恶意IP
# 3. 查看异常消费、未确认消息堆积
rabbitmqctl list_queues messages_unacknowledged consumers
# 4. 清理无效临时队列、僵尸资源
rabbitmqctl purge_queue 无效队列名
rabbitmqctl delete_queue 废弃临时队列名8.3.7 生产高频坑点总结
-
坑1:默认不开启连接限流,内网一台服务异常即可打爆全局连接数,导致集群瘫痪。
-
坑2:未限制单消息大小,恶意超大消息引发磁盘IO飙升、集群卡顿。
-
坑3:账号全局授权,一旦账号泄露,攻击者可随意删除队列、篡改配置。
-
坑4:未清理僵尸连接、临时队列,长期堆积导致资源缓慢耗尽。
-
坑5:外网开放管理端口,无白名单防护,极易被扫描爆破入侵。
8.3.8 面试高频必背问答
-
RabbitMQ如何防止DOS攻击? 通过四层防护:网络层IP白名单+端口封禁、服务端连接/消息限流、权限最小化、客户端规范管控,同时自动清理僵尸资源,拦截恶意建连、消息轰炸、越权操作等攻击行为。
-
发现MQ被恶意攻击如何紧急处理? 先通过命令定位攻击IP,强制踢出恶意连接,临时封禁攻击IP;清理无效堆积消息、僵尸队列;检查账号权限是否泄露,修改密码、收紧权限;最后补全限流配置,根治攻击风险。
-
为什么要限制单IP连接数? 防止单机异常或恶意程序批量创建连接,耗尽MQ全局连接数、系统端口与文件句柄,导致正常业务无法建立连接,引发整体业务瘫痪。
第九部分 底层原理与性能调优
9.1 Erlang 底层模型(深度完整版·RabbitMQ核心基石)
RabbitMQ 核心基于 Erlang/OTP 并发编程模型 开发,Erlang 是一门专为高并发、高可用、分布式、容错性设计的函数式语言,其原生特性完美适配消息中间件的核心诉求,也是 RabbitMQ 具备高稳定、低延迟、集群强一致性的底层根本。区别于Java、Go等通用语言,Erlang的轻量进程、隔离机制、容错设计,是RabbitMQ区别于其他MQ的核心底层优势。
9.1.1 核心核心:轻量级进程模型(区别于系统线程)
Erlang 最核心的设计是用户态轻量进程(Lightweight Process),完全独立于操作系统内核线程,是Erlang高并发的核心支撑,也是RabbitMQ队列隔离运行的底层基础。
1. 轻量进程核心特性
-
极低资源占用 :单个Erlang进程仅占用几百字节~几KB内存,无内核线程栈内存开销,一台普通服务器可支撑数十万、上百万个进程并发运行,远超操作系统线程上限。
-
完全独立隔离 :每个进程拥有独立的栈内存、进程状态、消息队列,进程间内存完全隔离,无共享内存、无需锁竞争,从底层杜绝并发锁冲突、死锁问题。
-
调度高效无阻塞:由Erlang虚拟机(BEAM)自主调度,采用抢占式调度机制,无需操作系统内核参与,调度开销极低,响应延迟稳定在微秒级。
-
生命周期灵活:进程创建、销毁、切换成本极低,支持高频启停,适配MQ动态创建队列、动态扩容消费的场景。
2. 与操作系统线程/进程核心对比
|-------|-------------|-----------------|--------------|
| 对比维度 | Erlang轻量进程 | OS系统线程 | OS系统进程 |
| 内存开销 | KB级,极致轻量化 | MB级,默认栈内存占用大 | 数十MB级,资源开销极高 |
| 最大并发数 | 单机数十万~百万级 | 单机数千~万级 | 单机数百级 |
| 隔离性 | 完全隔离,无共享内存 | 共享进程内存,存在线程安全问题 | 完全隔离,内核级隔离 |
| 调度主体 | BEAM虚拟机自主调度 | 操作系统内核调度 | 操作系统内核调度 |
| 锁机制 | 无共享锁,天然并发安全 | 依赖锁、CAS保证线程安全 | 无需锁,隔离性极强 |
9.1.2 RabbitMQ 进程绑定机制(核心落地)
RabbitMQ 基于Erlang进程模型,实现了一队列一进程的核心架构,是其稳定性的核心保障,也是生产故障隔离的底层支撑。
-
队列独立进程绑定:每创建一个RabbitMQ队列,BEAM虚拟机就会单独启动一个专属Erlang轻量进程,全权负责该队列的消息接收、存储、路由、消费、持久化、过期清理等所有逻辑。
-
绝对故障隔离 :单个队列进程出现异常(卡死、报错、堆积过载),仅当前队列失效,不会影响集群内其他队列、交换机、连接进程,彻底避免单点故障全局扩散。
-
资源精准管控:每个队列进程独立占用少量内存、CPU资源,MQ可精准监控每个队列的运行状态、资源消耗,实现精细化运维。
-
动态弹性伸缩:队列删除时,对应Erlang进程立即销毁,释放全部资源,无内存泄漏、资源残留问题。
9.1.3 Erlang 消息传递机制(无锁并发核心)
Erlang 进程间不共享任何内存 ,所有进程通信完全依赖消息传递机制,这也是RabbitMQ无锁高并发的底层原理。
-
进程专属信箱:每个Erlang进程自带独立消息信箱,生产者、交换机、队列、消费者之间的所有交互,均通过进程间异步消息投递完成。
-
数据拷贝传递:进程间通信采用值拷贝方式,而非引用传递,彻底杜绝多线程并发修改、数据竞争问题,天然线程安全。
-
异步非阻塞通信:消息投递为异步操作,发送方无需等待接收方处理完成,极大提升MQ整体吞吐量。
9.1.4 OTP 容错设计(高可用底层支撑)
OTP(开放电信平台)是Erlang配套的高可用组件库,内置进程监控树、自动重启、故障自愈机制,是RabbitMQ集群高可用、7*24小时稳定运行的核心保障。
-
监控树机制(Supervisor):所有RabbitMQ核心进程(队列进程、集群进程、连接进程)均被监控进程统一托管,形成层级监控树。
-
故障自动自愈:当某个队列进程、通信进程异常退出、卡死、崩溃时,监控进程会实时感知,根据预设策略自动重启进程,无需人工干预。
-
可控重启策略:支持配置重启次数、重启间隔,避免进程频繁崩溃重启引发的震荡,保障集群稳定性。
-
故障隔离兜底:进程重启失败达到阈值后,会被标记为异常进程,不再反复重启,避免占用系统资源。
9.1.5 热更新机制(生产零停机升级)
Erlang 原生支持代码热更新,无需重启服务、无需中断业务,即可完成代码升级、补丁修复,这是RabbitMQ生产环境零停机运维的核心优势。
-
升级过程不终止进程、不中断消息收发,业务无感知;
-
支持灰度更新单个进程逻辑,风险可控;
-
区别于Java、Go服务,升级必须重启进程,会导致业务短暂中断、消息堆积。
9.1.6 底层模型生产优缺点总结
核心优势(RabbitMQ核心竞争力)
-
超高稳定性:进程完全隔离,单队列故障不扩散,集群整体稳定性极强;
-
天然无锁并发:消息传递通信,无锁竞争、无死锁,并发性能稳定;
-
极致容错自愈:OTP监控自愈,适配7*24小时不间断运行的生产场景;
-
低延迟可控:虚拟机自主调度,延迟波动极小,适合核心业务;
-
零停机运维:支持热更新,生产升级无需停服。
底层短板(生产选型避坑)
-
高吞吐短板:进程隔离、消息拷贝机制会产生微小开销,海量日志、超高吞吐场景性能弱于Kafka;
-
生态小众:Erlang语言小众,运维排障、二次开发成本高于Java系MQ;
-
内存开销累积:海量队列并发场景,大量轻量进程会累积占用内存,需合理管控队列数量。
9.1.7 面试高频必背问答
-
RabbitMQ 为什么稳定性远超其他MQ? 底层基于Erlang轻量进程模型,一队列一独立进程,进程完全隔离,单队列故障不影响全局;依托OTP监控自愈机制,支持进程自动重启、故障自愈,无锁并发设计避免并发故障,整体稳定性极强。
-
Erlang轻量进程和普通线程的核心区别? Erlang进程为虚拟机用户态进程,资源开销极低、单机并发量极大,进程间内存完全隔离、无共享锁,通过消息传递通信,天然并发安全;系统线程依赖内核调度、资源开销大、存在共享内存竞争,易出现线程安全与死锁问题。
-
RabbitMQ 单队列故障为什么不会拖垮集群? 每个队列对应独立的Erlang轻量进程,进程相互隔离、独立运行,单个队列进程异常、崩溃、卡死,仅影响当前队列,不会占用其他进程资源,也不会影响集群中其他队列、交换机的正常运行。
9.2 消息存储机制(底层全量详解)
核心存储架构 :RabbitMQ 基于 Erlang 内存+磁盘混合存储模型,区分热数据(内存) 与冷数据(磁盘),兼顾高性能与高可靠。所有队列数据独立存储,队列间数据隔离,单队列存储异常不影响全局集群。
(1) 三大核心存储文件组成(持久化生效)
消息日志文件(.dq):核心数据文件,存储完整的持久化消息体、消息属性、路由信息,是消息落地的核心载体,采用顺序写入机制,极大提升磁盘IO性能。文件采用分段存储,单文件达到阈值后自动新建日志文件,避免单文件过大导致的读写卡顿。
索引文件(.idx):存储消息偏移量、消息状态、队列关联关系等索引数据,记录每条消息在日志文件中的存储位置。消费者消费消息时,先查询索引文件定位消息位置,再读取日志文件数据,实现快速检索,避免全文件遍历。
元数据文件:存储队列、交换机、绑定关系、vhost、权限等集群元数据,服务重启后优先加载该文件,恢复集群架构资源,不丢失业务配置。
( 2 )冷热数据交换机制(核心底层逻辑)
热数据:新投递、待消费、高频访问的消息,优先存储在内存中,支持高速读写,保障消费吞吐量。
冷数据:长时间未被消费、堆积的存量消息,当内存占用达到内存水位阈值或单队列内存占用超限,会自动触发内存分页,将内存中存量消息批量落盘至磁盘,释放内存资源。
数据回迁:磁盘中的冷数据即将被消费时,会重新加载回内存,转为热数据供消费者读取,实现动态冷热切换。
( 3 )两大刷盘策略(生产核心选型)
同步刷盘(持久化高可靠):生产者投递持久化消息后,MQ 必须等待消息完整写入磁盘、落盘成功后,才返回投递成功响应。
特性:数据零丢失、安全性最高;
缺点:磁盘IO频繁,吞吐量较低,适合金融、支付等核心交易业务。
异步刷盘(高性能):消息先写入内存缓冲区,立即返回投递成功,后台线程异步批量将缓冲区消息刷入磁盘。
特性:批量刷盘、IO开销小、吞吐量极高;
缺点:极端场景(服务宕机、磁盘故障)会丢失缓冲区未刷盘消息,适合非核心、高吞吐业务。
( 4 )消息删除机制(延迟删除,优化IO)
常规认知误区:消费者ACK确认消息后,不会立即删除磁盘数据。
真实机制:消息消费成功后,仅在索引文件中标记消息为已删除状态,逻辑上失效,不再被消费者读取。后台独立线程定期执行「日志合并清理」操作,批量清除已标记删除的无效数据,回收磁盘空间。
设计优势:避免单条消息频繁删除引发的随机磁盘IO,通过批量清理大幅提升磁盘读写性能,适配高并发场景。
( 5 )消息过期存储逻辑
设置TTL过期的消息,不会主动扫描删除,仅在消息即将被消费、或队列触发清理时校验过期状态。
过期消息自动被判定为无效消息,根据队列配置转入死信队列或直接丢弃,不占用有效消费资源。
( 6 )集群存储差异
普通集群:消息仅存储在队列主节点,从节点仅同步元数据,不同步消息数据,主节点故障则存量消息无法访问。
镜像/仲裁队列:消息在集群多节点同步存储,实现多副本备份,单节点故障不丢失消息,保障高可用。
( 7 )生产高频坑点与优化
坑1:异步刷盘场景,未开启消息确认机制,宕机导致缓冲区消息丢失。
坑2:海量消息堆积触发大量内存分页,冷热数据频繁切换,磁盘IO飙升、性能暴跌。
坑3:单日志文件过大,导致后台批量清理卡顿,短暂影响队列吞吐量。
优化:核心业务同步刷盘+多副本存储,高吞吐业务异步刷盘+消息限流,避免无限堆积。
9.3 镜像队列同步原理(完整版·生产+面试)
镜像队列是 RabbitMQ 3.8版本之前主流的高可用队列方案 ,核心解决普通集群「仅主节点存消息、从节点只同步元数据」的消息丢失问题。通过集群多节点实时同步队列数据与消息,实现队列多副本存储,主节点故障后从节点可无缝升级为主节点,保障消息不丢失、业务不中断。3.8版本后官方推荐仲裁队列替代镜像队列,但镜像队列的底层原理仍是面试核心考点,且老旧生产集群大量沿用。
9.3.1 镜像队列核心架构
镜像队列集群中,每个队列分为两类节点角色,角色动态切换,由集群选举机制管控:
-
主节点(Master):队列的核心读写节点,唯一处理生产者消息投递、消费者消息消费、消息ACK、过期清理、持久化落地的节点,所有业务请求统一由主节点处理,保证消息读写唯一性,避免数据错乱。
-
镜像节点(Slave):队列的副本备份节点,不处理任何读写业务,仅实时同步主节点的队列元数据、消息数据、消息状态,作为主节点的热备节点。
-
非镜像节点:未加入当前队列镜像组的集群节点,不存储该队列任何数据,也不参与同步。
核心架构特点:一个队列全局仅有一个主节点,可拥有多个镜像从节点,副本数量可自定义配置,适配不同高可用等级需求。
9.3.2 镜像同步完整流程
1. 队列初始化同步(启动同步)
当镜像队列创建、新节点加入集群、集群重启恢复时,会触发全量初始化同步:
-
集群选举生成队列主节点,初始化队列元数据与存储结构;
-
主节点向所有镜像从节点同步队列基础配置(队列名、持久化属性、TTL、死信配置等);
-
从节点初始化与主节点一致的队列结构,完成队列搭建同步,等待消息数据同步。
2. 消息实时增量同步(核心运行机制)
队列正常运行期间,所有消息的新增、消费、删除、过期操作,均会实时同步至所有镜像节点,全程异步无阻塞:
-
生产同步:生产者投递消息至主节点,主节点完成消息校验、持久化落盘后,异步将完整消息体、消息属性、路由信息推送至所有镜像从节点,从节点同步落地存储,保证副本数据一致;
-
消费同步:消费者在主节点消费消息、执行ACK确认后,主节点同步消息删除/已消费标记至镜像节点,从节点同步更新消息状态,避免副本数据与主数据不一致;
-
状态同步:队列消息过期、被拒绝、溢出删除等所有状态变更,均会实时同步至所有镜像副本。
3. 故障切换同步(主节点宕机)
-
当队列主节点宕机、网络失联、进程异常时,集群立即感知主节点状态异常;
-
集群从当前存活的镜像从节点中,选举出新的队列主节点;
-
新主节点接管所有读写业务,基于已同步的完整消息副本继续提供服务,无消息丢失、无业务中断;
-
原主节点恢复后,自动降级为镜像从节点,同步当前最新队列数据,回归副本角色。
9.3.3 三大同步模式(生产可配置)
RabbitMQ 支持三种镜像同步策略,适配不同性能与可用性场景,可全局配置或单队列配置:
(1)all 模式(全节点镜像):集群所有节点均为队列镜像节点,数据全节点同步。
优势:可用性最高,任意节点故障均不影响队列;
劣势:同步开销最大,节点越多同步延迟、IO开销越高;
适用:核心零丢失业务、小规模集群(3节点)。
(2)exactly 模式(指定数量镜像):自定义固定副本节点数量(生产推荐3节点集群配置2个副本)。 优势:平衡可用性与性能,避免全节点同步冗余开销;
劣势:需合理配置副本数,数量过少降低容错能力;
适用:绝大多数生产高可用场景,官方推荐主流方案。
(3)nodes 模式(指定节点镜像):手动指定固定节点作为镜像副本节点。
优势:可精准控制副本存储节点,适配机房节点隔离场景;
劣势:节点固定,灵活性差,手动维护成本高;
适用:跨机房固定节点容灾场景。
9.3.4 同步核心特性与机制细节
-
异步同步机制:主节点完成本地数据写入后立即响应生产者,同步从节点操作异步执行,不阻塞主流程,保证读写性能;极端场景下,主节点写入成功、副本未同步完成时宕机,会产生极短暂数据不一致。
-
顺序同步保障:所有同步操作严格按照主节点执行顺序同步,从节点复刻主节点所有操作时序,保证副本数据与主数据完全一致,不打乱消息顺序。
-
只同步队列数据 :镜像队列仅同步队列+消息数据,交换机、绑定关系、vhost元数据为集群全局同步,不属于镜像同步范畴。
-
读写单点约束:无论多少镜像副本,始终只有主节点处理读写请求,从节点仅做数据备份,不分担读写压力,无法实现读写分离。
9.3.5 镜像队列优缺点(生产选型核心)
核心优点
-
消息高可用:多节点副本存储,主节点故障不丢失存量消息,彻底解决普通集群数据单点问题;
-
业务无缝切换:主节点宕机后自动选举新主节点,业务无需手动切换,无感知恢复;
-
适配老旧集群:3.8之前版本唯一成熟的队列高可用方案,兼容性极强。
核心缺点(生产高频坑点)
-
同步性能损耗:消息需要多节点同步存储,IO、网络开销远大于普通队列,高吞吐场景性能下降明显;
-
集群脑裂风险高:网络分区(脑裂)场景下,多节点可能各自选举主节点,导致队列分裂、消息重复、数据错乱;
-
无读写分流:从节点仅备份不读写,集群资源无法充分利用;
-
重启同步风暴:集群整体重启时,所有队列全量同步数据,瞬间引发大规模IO、网络暴涨,导致集群卡顿;
-
数据一致性弱:异步同步机制,极端宕机场景存在短暂数据不一致风险。
9.3.6 镜像队列 VS 仲裁队列(新版替代核心对比)
RabbitMQ 3.8+ 推出仲裁队列(Quorum Queue),彻底替代镜像队列,核心优化同步机制与容错能力:
-
镜像队列:异步同步、最终一致性、脑裂风险高、性能损耗大;
-
仲裁队列:基于Raft一致性算法,同步同步、强一致性、脑裂容错强、性能更优;
-
生产规范:新集群一律使用仲裁队列,老旧集群逐步淘汰镜像队列。
9.3.7 面试高频必背问答
-
镜像队列同步是同步还是异步? 默认异步同步,主节点本地落盘成功即返回成功,异步同步至从节点,性能高但极端场景存在短暂数据不一致,无法做到强一致性。
-
镜像队列主从节点数据一定一致吗? 正常运行最终一致,主节点刚写入、未完成副本同步时宕机,会出现短暂数据不一致,丢失未同步消息。
-
镜像队列为什么会产生同步风暴? 集群重启、节点恢复时,所有镜像队列会一次性全量同步历史消息,海量数据同步会打满磁盘IO和网络带宽,引发集群卡顿。
-
镜像队列和普通队列的核心区别? 普通队列仅主节点存消息,从节点只同步元数据,主节点故障丢失存量消息;镜像队列多节点同步消息副本,主节点故障可无缝切换,保障消息不丢失。
9.4 性能调优参数(生产全量可落地参数)
本节整理RabbitMQ服务端、客户端、内存、磁盘、网络、消费生产全套性能调优参数,所有参数均适配生产集群,包含参数释义、推荐值、调优场景与底层原理,可直接写入配置文件落地,同时适配面试高频考点。
9.4.1 基础全局核心参数(rabbitmq.conf)
全局通用配置,控制集群基础运行状态、资源上限,是性能调优的前置核心配置。
|------------------------|----------------|----------------|-------------------------------|
| 参数名称 | 参数释义 | 生产推荐值 | 调优说明 |
| max_connections | 集群全局最大TCP连接数 | 3000~5000 | 防止连接数耗尽,中小型集群推荐3000,高并发集群5000 |
| per_ip_max_connections | 单IP最大连接数限制 | 50~100 | 防单机恶意建连、连接风暴,杜绝单IP霸占全部连接资源 |
| connection_timeout | 空闲连接超时时间(ms) | 60000 | 自动清理僵尸空闲连接,释放端口与句柄资源 |
| channel_idle_timeout | 空闲信道超时关闭时间(ms) | 30000 | 清理无效空闲信道,避免内存累积泄漏 |
| max_message_size | 单消息最大限制字节数 | 10485760(10MB) | 拦截超大消息,防止磁盘IO飙升、内存溢出,业务大消息需拆分 |
9.4.2 内存与流控调优(核心防雪崩)
控制MQ内存使用阈值、内存分页、流控触发条件,解决内存溢出、集群卡顿、消息堆积问题,是高并发场景核心调优项。
|--------------------------|------------------|-----------|----------------------------|
| 参数名称 | 参数释义 | 生产推荐值 | 调优说明 |
| vm_memory_high_watermark | 内存高水位阈值(占系统内存比例) | 0.6 | 内存占用达60%触发流控,停止接收新消息,防止OOM |
| vm_memory_low_watermark | 内存低水位阈值 | 0.4 | 内存回落至40%解除流控,恢复正常消息收发 |
| memory_paging_threshold | 内存分页触发阈值 | 默认适配,无需修改 | 控制内存冷数据落盘频率,避免频繁分页导致性能暴跌 |
| credit_flow_default | 信贷流控开关 | true | 默认开启,精准控制单连接消息推送速率,防止客户端过载 |
9.4.3 磁盘IO与持久化调优(兼顾性能与可靠)
管控消息刷盘策略、日志分段、磁盘水位,解决磁盘IO瓶颈、刷盘卡顿、磁盘溢出问题,区分核心业务与高吞吐业务配置。
|---------------------------------|-------------|---------|----------------------------|
| 参数名称 | 参数释义 | 生产推荐值 | 调优说明 |
| disk_free_limit.relative | 磁盘剩余空间相对阈值 | 1.0 | 剩余磁盘空间小于1倍内存时触发磁盘流控,保护集群 |
| queue_index_max_journal_entries | 索引日志最大条目数 | 100000 | 达到阈值触发日志合并清理,避免索引文件过大、检索卡顿 |
| msg_store_file_size_limit | 消息日志单文件最大大小 | 1GB | 单文件阈值达标自动新建日志,优化磁盘读写效率 |
| 异步刷盘批量大小 | 批量刷盘消息条数 | 50~100 | 高吞吐业务调大,核心小流量业务调小,平衡IO与可靠性 |
9.4.4 生产端限流调优参数
管控生产者消息推送速率、信道承载上限,防止消息轰炸、队列无限堆积,实现生产端柔性限流。
|----------------------|-----------------|------------|-------------------------|
| 参数名称 | 参数释义 | 生产推荐值 | 调优说明 |
| publisher_rate_limit | 单客户端消息推送速率(条/秒) | 1000~5000 | 根据业务峰值调整,防止单客户端高频轰炸打满集群 |
| channel_max | 单连接最大信道数 | 200 | 限制单连接信道上限,避免信道过多导致内存碎片化 |
9.4.5 消费端核心调优参数(Spring AMQP)
客户端消费参数是性能调优关键,直接决定消费吞吐量、负载均衡、消息堆积速度,为生产高频调优重点。
|------------------|------------|---------------------|---------------------------|
| 参数名称 | 参数释义 | 生产推荐值 | 调优说明 |
| prefetch | 单消费者预取消息条数 | 普通业务:20 高吞吐:50~100 | 过小浪费性能,过大导致消费不均、消息堆积、超时重试 |
| concurrency | 消费者初始并发数 | 5~20 | 根据业务消费耗时调整,耗时短调大、耗时长调小 |
| max-concurrency | 消费者最大并发数 | 20~50 | 动态扩容消费线程,应对流量峰值,避免消费能力瓶颈 |
| batch-size | 批量消费消息数 | 10~20 | 高吞吐非核心业务开启,核心交易业务禁止批量消费 |
| consumer-timeout | 消费超时时间(ms) | 30000 | 超时未ACK自动重发,防止线程卡死导致消息永久阻塞 |
9.4.6 集群高可用调优参数
适配仲裁队列、镜像队列集群,优化同步效率、脑裂防护、故障切换速度。
|----------------------------|-----------|----------------|------------------------|
| 参数名称 | 参数释义 | 生产推荐值 | 调优说明 |
| quorum_cluster_size | 仲裁队列集群节点数 | 3(奇数) | 奇数节点规避脑裂,保障Raft算法选举有效 |
| cluster_partition_handling | 集群分区处理策略 | pause_minority | 分区后少数节点暂停服务,彻底杜绝脑裂数据错乱 |
| sync_batch_count | 队列同步批量条数 | 100 | 批量同步副本消息,降低集群同步网络IO开销 |
9.4.7 生产调优核心原则(口诀+场景选型)
-
核心交易业务(金融/支付):低并发、高可靠 → 同步刷盘+双持久化+低prefetch+单消费者有序消费,牺牲性能保数据零丢失
-
高吞吐业务(日志/通知):高并发、低可靠要求 → 异步批量刷盘+调高prefetch+批量消费+动态并发,牺牲极致可靠性换吞吐量
-
流量波动业务:配置队列最大长度+溢出策略+动态消费者并发,实现流量削峰与柔性限流
-
集群通用原则:奇数节点、磁盘内存节点搭配、开启流控与超时清理、禁止无限制资源占用
9.4.8 面试高频调优问答
-
prefetch为什么不能设置过大? prefetch过大会导致单个消费者抢占大量消息,造成消费负载不均;同时消息长期未消费易触发超时重试,引发重复消费与消息堆积。
-
内存高水位如何合理配置? 根据服务器内存大小调整,常规服务器设置60%高水位、40%低水位,既避免内存溢出,又减少频繁流控影响业务吞吐。
-
异步刷盘和同步刷盘怎么选型? 核心交易、资金类业务强制同步刷盘保证零丢失;日志、推送、统计类非核心业务使用异步刷盘提升吞吐量。
-
消息堆积如何通过参数调优解决? 调大消费者并发数、合理调高prefetch、开启批量消费、优化消费逻辑耗时,同时限制队列最大长度防止无限堆积。
9.5 连接&信道治理(生产核心落地规范)
连接(Connection)与信道(Channel)是RabbitMQ客户端与服务端通信的核心载体,连接、信道混乱是生产环境端口耗尽、连接风暴、内存泄漏、集群流控、消息堆积的高频诱因。本节系统性补全生产治理规范、常见问题、排查方案、配置最佳实践与避坑细则,为线上运维必备准则。
9.5.1 核心治理总原则(生产铁律)
遵循官方最优设计:少连接、多信道、全局复用、杜绝频繁创建销毁
-
禁止单业务、单请求新建Connection(TCP连接创建成本极高,三次握手+认证极其耗资源)
-
信道可高频复用、合理创建,用完规范关闭,杜绝信道泄漏
-
全局统一连接池管控,所有微服务统一连接配置,不个性化乱配
-
空闲资源定时回收,僵尸连接、无效信道自动清理,避免资源累积占用
9.5.2 连接治理规范(Connection)
1. 生产连接池标准配置
中小型微服务集群、常规业务场景,单服务实例维持2~4个全局长连接即可支撑万级QPS,无需过多创建。
-
长连接生命周期:项目启动初始化、项目销毁关闭,全程全局复用
-
禁止代码内动态new Connection、循环创建连接
-
单IP连接数严格限流,配合服务端per_ip_max_connections参数,防止单机连接打爆集群
2. 异常连接分类与处理
-
僵尸连接:客户端已下线、进程退出,但服务端未感知,连接残留占用端口与句柄 解决方案:服务端配置空闲连接超时(connection_timeout),自动清理60s以上空闲僵尸连接
-
失效重连连接 :网络抖动断连后,客户端频繁重试建连,产生大量无效连接 解决方案:客户端配置指数退避重连策略(初始1s、最大30s间隔),禁止固定频率疯狂重连
-
超限连接:连接数打满服务端max_connections阈值,新业务无法建连 解决方案:监控连接数阈值告警,提前扩容节点、排查异常客户端连接泄漏
3. 连接故障核心影响
-
单连接断开:旗下所有信道全部失效,瞬时暂停消息收发
-
连接数过载:服务端触发全局流控,拒绝新连接、新消息投递
-
大量僵尸连接:占用系统端口、文件句柄,严重时导致服务器端口耗尽、服务宕机
9.5.3 信道治理规范(Channel)
1. 信道使用标准规范
-
单Connection合理承载信道数:50~200个,不超限、不空闲堆积
-
业务信道按需创建、复用、关闭,禁止长期闲置大量空信道
-
核心业务、不同业务队列信道隔离,单一信道故障不影响其他业务
-
禁止在for循环、定时任务高频逻辑内创建Channel,极易引发信道泄漏
2. 信道泄漏(生产最高频坑点)
泄漏定义:代码创建Channel后,未执行close关闭,导致信道持续占用内存、连接资源,无法释放,长期累积引发内存泄漏、信道超限。
泄漏常见场景:
-
消息发送异常、抛出异常,未执行finally关闭信道
-
自定义信道工具类,只创建不回收
-
定时任务频繁新建信道,无统一销毁逻辑
-
使用原生API操作信道,未使用SpringAMQP自动复用机制
泄漏解决方案:
-
所有手动创建信道代码,必须在finally代码块执行channel.close()
-
生产优先使用SpringAMQP自动信道复用,摒弃原生手动创建方式
-
开启服务端空闲信道超时清理(channel_idle_timeout=30s),自动回收无效信道
3. 信道异常隔离机制
-
RabbitMQ信道天然隔离:单信道异常、关闭、报错,不影响所属连接和其他信道
-
利用该特性,不同业务拆分独立信道,实现业务故障隔离
-
禁止单一信道承载过多不同类型业务,避免单点异常批量影响
9.5.4 SpringAMQP 自动治理配置(生产直接可用)
SpringAMQP已封装连接池与信道复用机制,生产只需规范配置,即可杜绝90%的连接、信道问题。
XML
# SpringBoot RabbitMQ 连接&信道治理最优配置
spring:
rabbitmq:
# 连接池配置:少连接、多信道
connection-pool:
min-idle: 2 # 最小空闲长连接
max-idle: 4 # 最大空闲长连接
max-active: 4 # 最大活跃连接(禁止超量)
idle-timeout: 60000 # 空闲连接超时回收
# 信道空闲超时
channel-idle-timeout: 30000
# 开启自动重连+指数退避
retry:
enabled: true
initial-interval: 1000 # 初始重连1s
max-interval: 30000 # 最大重连30s
multiplier: 1.5 # 指数退避倍率9.5.5 线上问题排查方案(落地可执行)
1. 连接数过高排查
-
MQ管理后台查看【Connections】列表,统计活跃连接、僵尸连接数量
-
按IP维度聚合,定位异常高频建连的服务节点
-
排查业务代码是否存在循环创建Connection、短连接频繁销毁重建
2. 信道泄漏排查
-
后台查看【Channels】数量,持续上涨不回落即为泄漏
-
检索项目原生Channel创建代码,补充finally关闭逻辑
-
临时解决方案:重启服务释放累积信道资源,长期需代码修复
3. 频繁断连重连排查
-
检查服务器防火墙、端口策略、网络抖动情况
-
核对服务端内存、磁盘水位,是否触发流控导致主动断连
-
检查客户端重连配置,是否存在频繁重连风暴
9.5.6 面试高频必背问答
-
为什么不能频繁创建TCP连接,信道可以复用创建? Connection是物理TCP长连接,创建需三次握手、身份认证、资源初始化,开销极大;Channel是虚拟机内部逻辑信道,依附连接存在,创建销毁几乎无开销,适合业务高频复用。
-
信道泄漏会导致什么线上问题? 无效信道持续占用内存资源,信道数量持续堆积超限,引发新信道创建失败、消息收发异常、内存缓慢泄漏,严重时触发集群流控。
-
单信道故障会影响整个连接吗? 不会,RabbitMQ设计信道完全隔离,单信道报错、关闭、异常,仅影响当前信道业务,不会中断TCP连接、不影响其他信道正常通信。
-
生产连接池为什么只配置2~4个长连接? 长连接创建成本高、无需多开,少量长连接可通过数百个信道承载海量业务,过多连接会占用端口、内存资源,反而降低集群性能。
9.5.7 连接&信道治理终极口诀
-
连接要少、全局复用,杜绝新建、杜绝频繁
-
信道够用、用完即关,隔离业务、防止泄漏
-
空闲定时、自动回收,重连退避、杜绝风暴
-
池化管理、统一配置,监控告警、提前防控
-
杜绝信道泄漏(创建不关闭)
-
客户端开启自动重连,配置合理重连间隔。
第十部分 分布式拓展
10.1 分布式事务(最终一致性方案 · 原理+完整代码)
RabbitMQ 不支持原生分布式事务 ,无法像RocketMQ一样通过半消息实现强事务一致性。行业生产统一采用最终一致性方案 ,核心思想:本地事务落库+可靠消息投递+失败定时补偿,保证上下游业务数据最终一致,无数据偏差、无事务悬挂。
本节整理四大主流落地方案,按「生产使用率从高到低」排序,附带全套可运行SpringBoot代码、踩坑点、选型标准,适配微服务跨服务事务场景。
10.1.1 方案一:本地消息表(最经典、无框架依赖、零侵入)
1. 核心原理
基于本地事务+消息记录表实现事务一致性,是最通用、最稳定的MQ分布式事务方案,无第三方框架依赖,适配所有微服务场景。
-
业务服务新建本地消息事务表,存储消息状态(待发送、已发送、消费成功、消费失败);
-
开启本地事务:执行业务SQL + 新增消息记录,二者原子落库;
-
事务提交成功后,异步投递MQ消息,投递成功更新消息状态为「已发送」;
-
消费者消费成功后,回调更新消息状态为「消费成功」;
-
定时任务扫描待发送/发送超时的消息,重试投递,解决消息丢失、投递失败问题,实现最终一致。
2. 数据库表结构(直接执行)
sql
CREATE TABLE `mq_local_transaction` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`message_id` varchar(64) NOT NULL COMMENT '消息唯一ID',
`exchange` varchar(64) NOT NULL COMMENT '交换机名称',
`routing_key` varchar(64) NOT NULL COMMENT '路由键',
`message_body` text NOT NULL COMMENT '消息体内容',
`message_status` tinyint NOT NULL DEFAULT '0' COMMENT '消息状态:0-待发送 1-已发送 2-消费成功 3-发送失败',
`retry_count` int NOT NULL DEFAULT '0' COMMENT '重试次数',
`max_retry` int NOT NULL DEFAULT '3' COMMENT '最大重试次数',
`next_retry_time` datetime DEFAULT NULL COMMENT '下次重试时间',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_message_id` (`message_id`),
KEY `idx_status_retry` (`message_status`,`next_retry_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='MQ本地事务消息表';3. 核心业务代码(生产者端)
java
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessageProperties;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.UUID;
/**
* 本地消息表-分布式事务生产者服务
* 核心:业务操作 + 消息入库 原子执行
*/
@Service
public class OrderTransactionService {
@Resource
private RabbitTemplate rabbitTemplate;
@Resource
private MqLocalTransactionMapper transactionMapper;
// 业务交换机、路由键
private static final String ORDER_EXCHANGE = "order.topic.exchange";
private static final String ORDER_ROUTING_KEY = "order.create.success";
/**
* 下单分布式事务方法
*/
@Transactional(rollbackFor = Exception.class)
public void createOrderWithTransaction(Order order) {
// 1. 执行业务数据库操作(创建订单)
orderMapper.insert(order);
// 2. 生成全局唯一消息ID(保证幂等)
String messageId = UUID.randomUUID().toString().replace("-", "");
// 3. 封装消息,存入本地事务表(和订单操作同事务,原子性保障)
MqLocalTransaction transaction = new MqLocalTransaction();
transaction.setMessageId(messageId);
transaction.setExchange(ORDER_EXCHANGE);
transaction.setRoutingKey(ORDER_ROUTING_KEY);
transaction.setMessageBody(JSON.toJSONString(order));
transaction.setMessageStatus(0); // 待发送
transaction.setRetryCount(0);
transaction.setMaxRetry(3);
transaction.setNextRetryTime(LocalDateTime.now());
transactionMapper.insert(transaction);
// 4. 投递MQ消息(异步投递,失败由定时任务补偿)
sendMqMessage(transaction);
}
/**
* MQ消息投递方法
*/
private void sendMqMessage(MqLocalTransaction transaction) {
try {
// 封装消息属性
MessageProperties properties = new MessageProperties();
properties.setMessageId(transaction.getMessageId());
properties.setContentType("application/json");
Message message = new Message(transaction.getMessageBody().getBytes(), properties);
// 发送消息,绑定消息ID用于确认回调
CorrelationData correlationData = new CorrelationData(transaction.getMessageId());
rabbitTemplate.convertAndSend(transaction.getExchange(), transaction.getRoutingKey(), message, correlationData);
} catch (Exception e) {
// 投递异常不抛事务异常,由定时任务后续重试补偿
log.error("消息投递临时失败,等待重试,messageId:{}", transaction.getMessageId(), e);
}
}
}4. 消息确认回调+状态更新代码
java
/**
* MQ消息投递确认回调配置
* 投递成功更新状态,投递失败等待重试
*/
@Component
public class RabbitConfirmCallback implements RabbitTemplate.ConfirmCallback {
@Resource
private MqLocalTransactionMapper transactionMapper;
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
if (correlationData == null || StringUtils.isEmpty(correlationData.getId())) {
return;
}
String messageId = correlationData.getId();
// 消息投递成功,更新状态为已发送
if (ack) {
transactionMapper.updateStatus(messageId, 1);
} else {
// 投递失败,更新重试次数、下次重试时间
transactionMapper.updateRetryInfo(messageId);
}
}
}5. 定时补偿任务(核心兜底)
java
/**
* 定时重试任务:补偿投递失败、超时未发送的消息
* 生产建议:每30秒执行一次
*/
@Component
@EnableScheduling
public class MqTransactionCompensateTask {
@Resource
private MqLocalTransactionMapper transactionMapper;
@Resource
private OrderTransactionService transactionService;
@Scheduled(fixedRate = 30000)
public void compensateFailedMessage() {
// 查询:待发送、未超过最大重试次数、到达重试时间的消息
List<MqLocalTransaction> failMessages = transactionMapper.selectNeedRetryMessage();
for (MqLocalTransaction message : failMessages) {
// 超过最大重试次数,标记为失败,人工排查
if (message.getRetryCount() >= message.getMaxRetry()) {
transactionMapper.updateStatus(message.getMessageId(), 3);
continue;
}
// 重新投递消息
transactionService.sendMqMessage(message);
// 重试次数+1
transactionMapper.increaseRetryCount(message.getMessageId());
}
}
}6. 消费者回调更新状态代码
java
/**
* 订单消息消费者
* 消费成功回调更新事务状态,完成最终一致性闭环
*/
@RabbitListener(queues = "order.success.queue")
@Component
public class OrderMessageConsumer {
@Resource
private MqLocalTransactionMapper transactionMapper;
@RabbitHandler
public void consume(Message message, Channel channel) {
String messageId = message.getMessageProperties().getMessageId();
try {
// 1. 解析消息、执行业务消费逻辑
String body = new String(message.getBody());
Order order = JSON.parseObject(body, Order.class);
// 执行业务:订单后续处理、通知、积分发放等
handleOrderBusiness(order);
// 2. 消费成功,更新事务状态为完成
transactionMapper.updateStatus(messageId, 2);
// 3. 手动ACK确认
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
// 消费异常,拒绝消息,等待重试/人工处理
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, false);
log.error("订单消息消费失败,messageId:{}", messageId, e);
}
}
}7. 方案优缺点与适用场景
-
优点:无框架依赖、兼容性强、稳定性极高、数据零丢失、适配所有RabbitMQ版本
-
缺点:需要额外建表、少量代码侵入、需维护定时补偿任务
-
适用场景:金融、支付、电商核心交易(生产90%场景首选)
10.1.2 方案二:事务状态表+定时补偿(简化版)
针对简单业务场景,简化本地消息表逻辑,不存储完整消息体,仅存储事务状态与消息标识,减少数据库存储压力,核心逻辑与本地消息表一致,适合轻量化业务。
核心简化点:消息体无需入库,仅记录messageId、事务状态、业务主键,投递失败后通过业务主键重新查询数据组装消息,降低数据库IO开销。
10.1.3 方案三:RabbitMQ Confirm+Return 可靠投递(轻量无表方案)
1. 核心原理
无需新建数据库表,依托RabbitMQ原生Confirm确认机制+Return回退机制,结合本地业务日志、Redis缓存记录消息状态,实现轻量最终一致性。
-
业务事务执行成功后,投递MQ消息;
-
通过Confirm监听交换机接收状态,Return监听队列路由状态;
-
Redis缓存消息投递状态(过期时间72小时),记录未投递成功消息;
-
定时任务扫描Redis异常消息,触发重试投递。
2. 核心配置与代码
yml开启可靠投递配置:
XML
spring:
rabbitmq:
# 开启消息投递确认
publisher-confirm-type: correlated
# 开启路由失败返回
publisher-returns: true
# 路由失败不丢弃消息
template:
mandatory: true3. 优缺点与适用场景
-
优点:无需建表、代码轻量化、无数据库冗余存储
-
缺点:依赖Redis、极端缓存失效可能丢消息、可靠性低于本地消息表
-
适用场景:非核心业务、通知类、日志类、低可靠性要求场景
10.1.4 方案四:Seata+RabbitMQ 框架整合方案
1. 核心原理
整合Seata分布式事务框架,基于TCC/AT模式,结合RabbitMQ实现跨服务事务最终一致,框架自动管理事务状态,减少手动编码。
2. 优缺点与适用场景
-
优点:代码侵入极低、框架自动化管理、适配复杂微服务集群
-
缺点:依赖第三方框架、学习成本高、存在框架版本兼容问题、底层仍为最终一致性
-
适用场景:已接入Seata的大型微服务集群、多服务联动复杂事务场景
10.1.5 四大方案生产终极选型口诀
-
核心交易、零丢失要求 → 本地消息表(首选)
-
轻量业务、不想建表 → Redis+Confirm轻量方案
-
已接入Seata框架、多服务联动 → Seata整合方案
-
简单通知、非核心业务 → 简化定时补偿方案
10.1.6 面试高频必背问答
-
RabbitMQ能不能实现强一致性分布式事务? 不能,RabbitMQ无原生事务消息机制,所有方案均为最终一致性,无法实现RocketMQ、Kafka的事务半消息强一致性。
-
本地消息表核心难点是什么? 幂等性保障、定时重试防死循环、消息状态精准流转、避免重复投递与重复消费。
-
如何解决消息重试导致的重复消费? 全局唯一messageId做幂等校验、消费者业务接口幂等设计、状态机控制消费状态。
-
Confirm机制和本地消息表的区别? Confirm仅能确认消息是否到达交换机,无法保证队列接收、消费成功;本地消息表全程闭环,兜底能力更强。
10.2 全链路追踪(生产完整版 · 原理+代码+排查)
RabbitMQ消息异步通信的核心痛点是链路断裂、调用无上下文、问题难溯源 ,传统接口日志无法串联生产者、MQ服务端、消费者全流程。全链路追踪可实现消息从「生产→路由→堆积→消费→异常重试」的全生命周期监控,是微服务MQ场景问题排查、故障定位、性能分析的核心能力。本文整合SkyWalking、Pinpoint、Spring Cloud Sleuth主流方案,提供生产落地规范与可运行代码。
10.2.1 核心追踪原理
基于分布式追踪上下文透传机制,全程依托消息Header传递链路标识,打通跨服务异步链路:
-
生成链路根标识 :生产者发起业务时,生成全局唯一 TraceId (全链路唯一)+ SpanId(单步骤唯一);
-
上下文透传:将TraceId、SpanId、调用服务名、时间戳等追踪信息,写入RabbitMQ消息自定义Header;
-
服务端链路记录:MQ服务端记录消息接收时间、路由交换机、队列、堆积时长,关联TraceId;
-
消费者承接上下文:消费者消费消息时,从消息Header解析TraceId、SpanId,延续链路上下文,生成子Span;
-
全链路日志聚合:所有服务日志、MQ操作日志、异常日志携带统一TraceId,通过追踪平台聚合串联全流程。
核心追踪字段(生产统一规范)
-
TraceId:全局唯一链路ID,贯穿生产、路由、消费全流程
-
SpanId:单节点操作ID,区分生产者、MQ、消费者不同步骤
-
ParentSpanId:父节点ID,构建层级调用关系
-
ProducerService:生产者服务名称
-
ProduceTime:消息生产时间戳
-
QueueName/ExchangeName:消息路由队列、交换机标识
-
ConsumeTime:消息消费开始时间戳
10.2.2 主流框架选型对比(生产首选)
|-------------------|------------------------|-------------------------|---------------------|
| 追踪框架 | 核心优势 | 劣势 | 生产选型建议 |
| SkyWalking | 无侵入、轻量、性能损耗极低、原生支持MQ追踪 | 自定义链路拓展稍复杂 | 中小型微服务首选(主流方案) |
| Pinpoint | 可视化极强、链路细节最全、无需埋点 | 代理占用资源较高、启动稍慢 | 大型集群、精细化链路分析场景 |
| Sleuth+Zipkin | Spring生态原生适配、自定义灵活 | SpringCloud新版本已废弃、需手动维护 | 老旧SpringCloud项目兼容使用 |
10.2.3 SkyWalking 无侵入落地(生产最优方案)
SkyWalking 通过JavaAgent字节码增强实现零代码侵入,自动捕获RabbitMQ消息生产、路由、消费链路,是目前生产最通用的MQ追踪方案。
1. 环境部署核心配置
-
部署SkyWalking OAP服务 + UI可视化面板
-
业务服务启动挂载SkyWalking Agent,自动加载RabbitMQ追踪插件
-
开启消息Header自动透传,无需手动编码传递TraceId
2. 关键特性(适配RabbitMQ)
-
自动捕获生产者发送消息、交换机路由、队列堆积、消费者消费全链路
-
自动记录消息生产耗时、堆积时长、消费耗时、异常信息
-
支持MQ链路与HTTP、RPC、数据库链路串联,完整还原业务流程
-
异常消息自动标记,精准定位投递失败、消费失败、超时堆积问题
10.2.4 手动链路透传代码(无框架依赖、通用适配)
若未接入全链路追踪框架,可通过手动封装工具类实现TraceId透传,适配所有项目,零依赖、可直接落地。
1. 链路追踪工具类(全局通用)
java
import org.slf4j.MDC;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessageProperties;
import java.util.UUID;
/**
* MQ全链路追踪工具类
* 实现TraceId上下文生成、透传、解析
*/
public class MqTraceUtil {
// 链路追踪Header常量
public static final String TRACE_ID = "X-MQ-TRACE-ID";
public static final String SPAN_ID = "X-MQ-SPAN-ID";
public static final String PRODUCE_TIME = "X-MQ-PRODUCE-TIME";
public static final String PRODUCER_SERVICE = "X-MQ-PRODUCER-SERVICE";
/**
* 生成全局唯一TraceId
*/
public static String generateTraceId() {
return UUID.randomUUID().toString().replace("-", "");
}
/**
* 封装消息Header,透传链路上下文
*/
public static void buildTraceHeader(MessageProperties properties) {
// 优先获取当前线程上下文TraceId,无则新建
String traceId = MDC.get(TRACE_ID);
if (traceId == null || "".equals(traceId)) {
traceId = generateTraceId();
}
// 填充链路追踪信息
properties.setHeader(TRACE_ID, traceId);
properties.setHeader(SPAN_ID, generateTraceId());
properties.setHeader(PRODUCE_TIME, System.currentTimeMillis());
properties.setHeader(PRODUCER_SERVICE, "order-service");
// MDC绑定,日志自动打印TraceId
MDC.put(TRACE_ID, traceId);
}
/**
* 消费者解析链路上下文,还原追踪信息
*/
public static String parseTraceContext(Message message) {
MessageProperties properties = message.getMessageProperties();
String traceId = properties.getHeader(TRACE_ID);
// 绑定当前线程MDC,后续日志自动携带链路ID
MDC.put(TRACE_ID, traceId);
return traceId;
}
/**
* 清除链路上下文(防止线程池上下文污染)
*/
public static void clearTraceContext() {
MDC.remove(TRACE_ID);
}
}2. 生产者链路透传改造
java
// 发送消息前封装链路Header
MessageProperties properties = new MessageProperties();
// 填充全链路追踪上下文
MqTraceUtil.buildTraceHeader(properties);
// 构建消息
Message message = new Message(JSON.toJSONString(order).getBytes(), properties);
// 发送消息
rabbitTemplate.convertAndSend(ORDER_EXCHANGE, ORDER_ROUTING_KEY, message);3. 消费者链路承接改造
java
@RabbitListener(queues = "order.success.queue")
@Component
public class OrderMessageConsumer {
@RabbitHandler
public void consume(Message message, Channel channel) {
// 解析并绑定链路上下文
String traceId = MqTraceUtil.parseTraceContext(message);
try {
// 执行业务消费逻辑,所有日志自动携带TraceId
String body = new String(message.getBody());
Order order = JSON.parseObject(body, Order.class);
handleOrderBusiness(order);
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
// 异常日志携带TraceId,精准溯源
log.error("订单消息消费失败,traceId:{}", traceId, e);
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, false);
} finally {
// 清除上下文,避免线程复用污染
MqTraceUtil.clearTraceContext();
}
}
}10.2.5 日志规范与链路聚合(ELK落地)
配合ELK(Elasticsearch+Logstash+Kibana)实现日志聚合检索,通过TraceId精准串联全链路日志,是线上问题排查核心手段。
1. 统一日志格式规范
所有服务日志必须包含:时间戳 + 服务名 + TraceId + 日志级别 + 业务信息 + 异常堆栈
2. 核心检索场景
-
根据TraceId查询消息生产、投递、路由、消费全量日志
-
快速定位消息丢失、投递失败、消费超时、重复消费根因
-
统计消息平均堆积时长、消费耗时,优化业务性能
10.2.6 生产高频问题排查流程(链路追踪落地)
-
问题定位:获取异常消息的MessageId或业务单号,检索对应TraceId;
-
链路回溯:通过TraceId查看生产者是否成功投递、交换机是否路由成功、队列是否接收消息;
-
节点排查:判断故障节点(生产失败/路由失败/堆积超时/消费异常);
-
日志溯源:查看对应节点日志,定位异常堆栈、参数错误、超时原因;
-
问题修复:针对性修复代码、配置、网络问题,重试补偿异常消息。
10.2.7 面试高频必背问答
-
RabbitMQ异步消息如何实现全链路追踪? 通过消息Header透传TraceId、SpanId等链路上下文,生产者生成、消费者承接,结合MDC日志绑定、追踪平台聚合,实现异步跨服务链路串联。
-
为什么MQ场景必须手动透传链路上下文? MQ是异步解耦通信,生产者与消费者不在同一线程、同一请求链路,原生追踪框架无法自动串联,必须手动透传上下文保证链路完整。
-
链路追踪核心作用是什么? 解决异步消息链路断裂问题,快速定位消息丢失、消费异常、堆积超时根因,实现故障秒级排查,提升线上问题处理效率。
-
手动透传需要注意什么坑? 必须在消费完成后清除MDC上下文,避免线程池复用导致上下文污染;所有异常日志必须携带TraceId,保证溯源完整性。
10.3 消息灰度分流(生产全落地方案)
消息灰度分流是微服务迭代、版本升级、功能测试的核心生产能力 ,核心目标:在不影响全量线上业务的前提下,将少量测试流量/新功能流量分流至灰度消费者,实现灰度验证、无痛迭代、风险可控 ,避免新版本BUG导致全量业务故障。本节整理RabbitMQ生产主流的RoutingKey路由灰度、Header自定义灰度两种方案,附带完整实战代码、适配场景、避坑细则。
10.3.1 灰度分流核心原理
基于RabbitMQ Topic交换机模糊匹配、Header自定义标记的特性,通过流量标记+路由规则过滤,实现同一业务消息的流量拆分:
-
线上正式消费者:消费全量正式业务流量,保障核心业务稳定
-
灰度测试消费者:仅消费标记后的灰度流量,用于新版本功能验证、性能测试
-
核心优势:无需改造生产者核心逻辑、无需停机、流量配比可控、故障隔离,灰度异常不影响正式环境
生产灰度流量分级规范
-
小流量灰度:5%~10%流量,用于新版本功能验证、BUG测试
-
中流量灰度:30%~50%流量,用于性能压测、高并发验证
-
全量放量:灰度验证无问题后,切换100%流量至新版本服务
10.3.2 方案一:RoutingKey规则灰度(最简单、零侵入、生产首选)
1. 实现原理
依托Topic主题交换机通配符匹配规则,生产者根据流量策略,动态修改消息RoutingKey后缀,通过不同绑定规则区分正式队列与灰度队列,实现流量精准分流。
2. 队列与交换机绑定规则设计
-
公共交换机:业务通用Topic交换机(无需新增交换机,复用线上交换机)
-
正式队列:绑定路由键
order.#,接收所有正常业务消息 -
灰度队列:绑定路由键
order.#.gray,仅接收灰度标记消息
流量规则:正常消息RoutingKey为 order.create,灰度消息RoutingKey追加后缀为 order.create.gray,实现流量物理隔离。
3. SpringBoot完整配置代码
java
/**
* 消息灰度分流-队列&绑定配置
* 复用线上业务交换机,新增灰度队列做流量隔离
*/
@Configuration
public class MqGrayRouteConfig {
// 业务主题交换机(线上已有,直接复用)
public static final String ORDER_TOPIC_EXCHANGE = "order.topic.exchange";
// 正式队列、路由键
public static final String ORDER_NORMAL_QUEUE = "order.normal.queue";
public static final String ORDER_NORMAL_ROUTE = "order.#";
// 灰度队列、路由键
public static final String ORDER_GRAY_QUEUE = "order.gray.queue";
public static final String ORDER_GRAY_ROUTE = "order.#.gray";
/**
* 正式业务队列配置
*/
@Bean
public Queue orderNormalQueue() {
return new Queue(ORDER_NORMAL_QUEUE, true, false, false);
}
/**
* 灰度测试队列配置
*/
@Bean
public Queue orderGrayQueue() {
return new Queue(ORDER_GRAY_QUEUE, true, false, false);
}
/**
* 正式队列绑定交换机
*/
@Bean
public Binding normalQueueBinding() {
return BindingBuilder.bind(orderNormalQueue())
.to(new TopicExchange(ORDER_TOPIC_EXCHANGE))
.with(ORDER_NORMAL_ROUTE);
}
/**
* 灰度队列绑定交换机
*/
@Bean
public Binding grayQueueBinding() {
return BindingBuilder.bind(orderGrayQueue())
.to(new TopicExchange(ORDER_TOPIC_EXCHANGE))
.with(ORDER_GRAY_ROUTE);
}
}4. 生产者灰度流量分发代码(可控流量配比)
java
/**
* 灰度消息生产者工具类
* 支持自定义灰度流量比例、动态开关
*/
@Component
public class MqGrayMessageProducer {
@Resource
private RabbitTemplate rabbitTemplate;
// 灰度流量比例(0-100,生产可配置化,放入Nacos/Apollo配置中心)
@Value("${mq.gray.rate:10}")
private Integer grayRate;
// 灰度功能总开关
@Value("${mq.gray.enabled:false}")
private Boolean grayEnabled;
/**
* 发送订单消息(自动灰度分流)
*/
public void sendOrderMessage(Order order) {
String routingKey = "order.create";
// 灰度开关开启 & 命中灰度比例,追加灰度路由后缀
if (grayEnabled && isHitGrayRate()) {
routingKey = routingKey + ".gray";
}
// 发送消息
rabbitTemplate.convertAndSend(MqGrayRouteConfig.ORDER_TOPIC_EXCHANGE, routingKey, order);
}
/**
* 判断是否命中灰度流量比例
*/
private boolean isHitGrayRate() {
if (grayRate <= 0) {
return false;
}
if (grayRate >= 100) {
return true;
}
// 随机数匹配流量比例
int random = new Random().nextInt(100);
return random < grayRate;
}
}5. 消费者监听配置
java
/**
* 正式、灰度双消费者配置
* 正式服务只监听正式队列,灰度服务只监听灰度队列
*/
@Component
public class OrderGrayConsumer {
/**
* 正式环境消费者:只处理正常业务流量
*/
@RabbitListener(queues = MqGrayRouteConfig.ORDER_NORMAL_QUEUE)
public void consumeNormalMessage(Order order, Channel channel, Message message) {
try {
// 正式业务消费逻辑
handleOrderBusiness(order);
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, false);
}
}
/**
* 灰度环境消费者:只处理灰度测试流量
*/
@RabbitListener(queues = MqGrayRouteConfig.ORDER_GRAY_QUEUE)
public void consumeGrayMessage(Order order, Channel channel, Message message) {
try {
// 新版本灰度业务逻辑(与正式逻辑隔离)
handleGrayOrderBusiness(order);
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, false);
}
}
}6. 方案优缺点与适用场景
-
优点:零侵入原有业务、配置简单、流量物理隔离、无性能损耗、适配所有Topic业务场景
-
缺点:仅支持比例灰度,无法精准指定用户、订单等维度定向灰度
-
适用场景:版本迭代灰度、批量流量验证、性能压测、通用业务灰度
10.3.3 方案二:Header自定义标记灰度(精准定向灰度)
1. 实现原理
通过消息Header自定义灰度标记(灰度用户ID、灰度环境、版本号),结合Header交换机或消费者拦截过滤,实现精准定向灰度,支持指定用户、指定业务单号、指定版本流量灰度,适配精细化迭代场景。
2. 核心实现逻辑
-
生产者:根据业务规则(用户白名单、版本号),在消息Header中添加
gray=true、grayUserId=xxx标记 -
消费者:消费前拦截消息,校验Header灰度标识,正式服务过滤灰度消息,灰度服务接收灰度消息
-
优势:无需新增队列、无需修改路由规则,通过业务标记实现精准分流
3. 完整代码实现
java
/**
* Header精准灰度-消息发送工具
* 支持白名单用户、指定版本定向灰度
*/
@Component
public class MqHeaderGrayProducer {
@Resource
private RabbitTemplate rabbitTemplate;
// 灰度用户白名单(可配置化存入配置中心)
private static final Set<String> GRAY_USER_WHITE_LIST = new HashSet<>(Arrays.asList("10001","10002","10003"));
public void sendOrderGrayMessage(Order order) {
MessageProperties properties = new MessageProperties();
// 判断是否为灰度用户,添加灰度标记
if (GRAY_USER_WHITE_LIST.contains(order.getUserId())) {
properties.setHeader("isGray", true);
properties.setHeader("grayVersion", "2.0.0");
} else {
properties.setHeader("isGray", false);
}
// 构建消息
Message message = new Message(JSON.toJSONString(order).getBytes(), properties);
// 统一发送至业务队列
rabbitTemplate.convertAndSend("order.topic.exchange", "order.create", message);
}
}4. 消费者灰度拦截过滤逻辑
java
/**
* Header灰度消息消费者拦截器
* 实现正式/灰度服务流量隔离
*/
@Component
public class MqHeaderGrayConsumer {
// 当前服务部署版本:正式版/灰度版
@Value("${service.version:release}")
private String serviceVersion;
@RabbitListener(queues = "order.normal.queue")
public void consumeMessage(Message message, Channel channel) throws IOException {
MessageProperties properties = message.getMessageProperties();
// 获取灰度标记
Boolean isGray = properties.getHeader("isGray");
if (isGray == null) {
isGray = false;
}
// 正式服务:只消费非灰度消息,忽略灰度消息
if ("release".equals(serviceVersion) && isGray) {
channel.basicNack(properties.getDeliveryTag(), false, false);
return;
}
// 灰度服务:只消费灰度消息,忽略正式消息
if ("gray".equals(serviceVersion) && !isGray) {
channel.basicNack(properties.getDeliveryTag(), false, false);
return;
}
// 正常消费业务逻辑
String body = new String(message.getBody());
Order order = JSON.parseObject(body, Order.class);
handleBusiness(order);
channel.basicAck(properties.getDeliveryTag(), false);
}
}5. 方案优缺点与适用场景
-
优点:灰度精度极高、支持用户级/业务级定向灰度、无需新增队列、灵活可控
-
缺点:需要代码拦截过滤、有少量代码侵入、相比路由灰度多一层判断逻辑
-
适用场景:精准用户灰度、小范围定向测试、新版本功能内测、精细化流量管控
10.3.4 两种灰度方案生产终极选型
-
批量流量灰度、版本整体迭代 → 优先RoutingKey路由灰度(简单稳定、零侵入)
-
精准用户、白名单内测、定向流量 → 优先Header标记灰度(精度最高)
-
生产组合方案:初期Header精准灰度内测,验证无误后切换RoutingKey批量灰度放量
10.3.5 生产灰度落地规范与避坑点
-
流量隔离必做:灰度消息与正式消息物理隔离或逻辑隔离,禁止灰度BUG污染正式业务数据
-
灰度开关可配置:灰度比例、灰度状态必须接入配置中心,支持动态调整、一键关闭
-
幂等性兼容:灰度消息与正式消息共用同一幂等校验规则,避免重复消费、数据错乱
-
禁止长期灰度:灰度验证完成后,及时全量放量并下线灰度队列、灰度逻辑,减少代码冗余
-
灰度监控告警:单独监控灰度队列堆积、消费异常、报错率,灰度故障立即止损
-
消息溯源:灰度消息Header必须携带版本、灰度标记,方便问题排查溯源
10.3.6 面试高频必背问答
-
RabbitMQ消息灰度如何实现? 生产主流两种方案:1. RoutingKey后缀+Topic交换机匹配,实现批量流量灰度,零侵入、稳定性高;2. Header自定义灰度标记+消费者拦截过滤,实现用户级精准定向灰度,适配精细化迭代场景。
-
灰度消息会不会影响正式业务? 不会,路由灰度通过独立队列物理隔离流量,Header灰度通过消费者逻辑过滤隔离,灰度消息异常、消费失败仅影响灰度环境,完全不干扰线上正式业务。
-
灰度放量的标准流程是什么? 精准白名单灰度(小范围内测)→ 5%-10%批量流量灰度 → 30%-50%中流量验证 → 全量100%放量 → 下线灰度逻辑与资源。
-
两种灰度方案的核心区别? 路由灰度基于MQ路由规则隔离,无代码侵入、性能零损耗,适合批量流量;Header灰度基于业务标记过滤,精度更高、适配定向场景,存在少量代码侵入。
第十一部分 生产最佳实践(完整版·规范+原理+避坑落地)
一、基础架构与资源规范(核心避坑)
-
1. 队列单一职责,严格业务隔离:坚决杜绝一个队列承载多类不同业务消息,订单、支付、通知、日志、积分等业务必须拆分独立队列。多业务混用队列会导致故障耦合、消费阻塞牵连、消息类型混乱、排查难度激增,同时无法针对性配置限流、重试、死信策略。
-
2. 禁用系统默认交换机与默认队列:禁止生产业务使用匿名Default交换机,必须手动声明业务专属交换机、队列并绑定。默认交换机无统一路由管控、无业务标识、无法批量配置策略,后期迭代极易出现路由混乱、消息串流问题,完全不适合规范化运维。
-
3. 多环境多业务独立vhost隔离:开发、测试、预发、生产环境拆分独立vhost,不同核心业务线(订单、支付、用户)单独分配vhost。杜绝多环境、多业务共用vhost,避免队列重名冲突、消息跨业务串流、权限管控失效、故障互相影响。
-
4. 遵循「多信道、少连接」核心原则:严格禁止循环内创建Connection/Channel、单业务单连接等错误写法。TCP连接创建成本极高,项目全局维持2-4个长连接即可,信道按需复用、用完关闭,杜绝信道泄漏、端口耗尽、连接数打满引发的流控与断连问题。
-
5. 规范资源命名体系:交换机、队列、路由键统一采用「业务模块+功能+类型」语义化命名(如order.business.queue、pay.direct.exchange),禁止随意命名、拼音缩写、无规则命名,方便运维检索、故障定位、权限配置。
二、消息可靠性落地规范(零丢失核心)
-
1. 核心业务强制双持久化:所有交易、支付、订单类核心业务,必须同时开启「队列持久化(durable=true)+ 消息持久化(deliveryMode=2)」。仅队列持久化会导致服务重启后内存消息丢失,仅消息持久化无法保留队列元数据,双持久化是消息不丢失的基础保障。
-
2. 生产统一使用手动ACK,禁用自动ACK:自动ACK会出现消息未消费完成、程序异常退出但消息已删除的丢数据问题。手动ACK可精准控制消费状态,业务执行成功手动确认,异常时Nack重试或入死信,完全掌控消息生命周期。
-
3. 核心业务必开Confirm+Return双重确认:生产者必须开启Confirm投递确认、Return路由失败回调,搭配mandatory=true参数。Confirm校验消息是否抵达交换机,Return校验消息是否成功路由到队列,彻底解决消息投递静默丢失问题。
-
4. 每条消息强制携带全局唯一MessageId:所有业务消息必须手动生成唯一MessageId,用于幂等校验、链路追踪、异常溯源、重试去重。禁止依赖MQ自动生成ID,自动ID无法跨服务关联业务日志,排查问题效率极低。
-
5. 严格控制消息体大小,禁止超大消息:单条消息体建议控制在128KB以内,最大不超过512KB。超大消息会占用大量内存、降低传输效率、引发队列堆积、拖慢整体消费速度,大文件、大数据集需拆分传输或开启GZIP压缩。
三、消费端避坑与性能规范(防堆积、防重复)
-
1. 合理配置Prefetch预取值,杜绝消费不均:根据消费者单机处理能力配置prefetch(常规业务10-50,高并发轻量业务可适当调高,重型业务调低)。Prefetch过大导致单消费者堆积、负载失衡;过小导致频繁拉取消息、损耗性能。
-
2. 禁止无限重试,所有异常消息接入死信队列:消费异常必须设置最大重试次数(3-5次),重试失败后转入死信队列。无限重试会导致消息死循环、队列持续堆积、服务CPU打满,严重拖垮整个MQ服务。
-
3. 消费业务必须实现全局幂等:所有消费者接口、业务逻辑强制幂等设计,依托MessageId、业务单号做唯一校验。MQ重试、网络抖动、集群重试都会引发重复投递,无幂等会导致订单重复处理、积分重复发放、数据错乱。
-
4. 禁止消费端长耗时阻塞操作:消费逻辑中禁止嵌套大量IO、同步远程调用、复杂计算、睡眠等待。长耗时消费会导致队列堆积、ACK超时、消息重复投递,耗时业务需异步拆解、线程池异步处理。
-
5. 区分Reject与Nack,规范异常处理:无需重试的无效消息、脏数据使用basicReject直接丢弃;临时异常、可重试业务使用basicNack批量重试,禁止滥用Nack批量重试导致批量消息重复消费。
-
6. 关闭自动重试兜底,手动管控重试逻辑:禁用SpringAMQP默认自动重试机制,默认重试无次数限制、无间隔梯度、无法管控。统一使用自定义重试策略+死信队列,实现梯度重试、失败兜底。
四、高阶特性规范(死信/延时/优先级避坑)
-
1. 死信队列禁止嵌套DLX,杜绝循环消息 :死信队列仅作为异常消息兜底队列,绝对不能配置死信交换机。若死信队列再次绑定DLX,会导致过期消息、异常消息无限循环流转,造成队列永久堆积。
-
2. 延时队列优先插件方案,规避TTL坑点 :简单延时场景可使用TTL+DLX实现,精准、长延时场景必须使用RabbitMQ延时插件。原生TTL方案存在队列消息阻塞、前置消息未过期、后置消息无法优先执行的致命问题,精度极差。
-
3. 优先级队列仅限单消费者场景:优先级队列仅在单消费者模式下生效,多消费者竞争消费场景下优先级失效,生产切勿盲目使用,仅用于加急订单、紧急通知等特殊业务。
-
4. 限流队列必须配置合理溢出策略:秒杀、大促等高并发队列,必须配置x-max-length队列上限,根据业务场景选择drop-head、reject-publish、reject-publish-dlx溢出策略,杜绝消息无限堆积撑满磁盘。
五、集群高可用规范(防故障、防脑裂)
-
1. 新版本集群优先使用仲裁队列:RabbitMQ 3.8+版本全面废弃镜像队列,生产强制使用仲裁队列。仲裁队列基于Raft算法,解决镜像队列性能差、同步延迟、脑裂风险高的问题,集群稳定性大幅提升。
-
2. 集群节点采用奇数部署,规避脑裂:生产集群节点数≥3且为奇数,杜绝双节点集群。双节点集群极易出现网络分区脑裂,导致数据不一致、消息丢失、队列状态异常。
-
3. 集群保留至少2个磁盘节点:集群内必须部署2个及以上磁盘节点,禁止全内存节点部署。内存节点重启后元数据丢失,磁盘节点负责持久化集群元数据,是集群数据安全的核心保障。
-
4. 严格遵循集群启停、故障恢复流程:禁止暴力启停集群节点,故障节点恢复后等待集群自动同步完成再接入流量,手动处理网络分区、脑裂异常,避免强行恢复导致数据覆盖、消息丢失。
-
5. 跨机房通信优先Shovel,简单场景用联邦:跨机房、跨集群消息同步,稳定持久场景优先Shovel插件(支持重连、容错、持久同步),临时数据同步、低优先级场景使用联邦插件,规避跨机房消息丢失、重复问题。
六、安全与权限规范(生产刚需)
-
1. 强制禁用默认guest账号:生产环境必须删除或禁用guest默认账号,该账号权限全开、公开透明,极易被攻击窃取数据、篡改队列配置。
-
2. 权限最小化分配,分角色管控:拆分管理员、运维、生产者、消费者四类账号,生产者仅拥有发送权限、消费者仅拥有消费权限,禁止普通业务账号拥有队列删除、交换机修改、集群配置权限。
-
3. 端口防护+IP白名单双重隔离:防火墙限制核心端口(5672/15672/25672)外网访问,仅放行业务服务器IP白名单,杜绝外网非法连接、恶意攻击、队列刷数据。
-
4. 跨公网传输开启SSL/TLS加密:跨机房、公网传输消息必须开启加密,防止消息明文传输被窃取、篡改,保障业务数据传输安全。
七、运维监控与故障兜底规范
-
1. 全指标监控+全场景告警:必须接入Prometheus+Grafana监控,覆盖节点状态、连接数、信道数、队列堆积、消息吞吐、消费异常、内存磁盘使用率、流控状态,配置短信/钉钉告警,实现故障提前预警。
-
2. 定时备份集群元数据与消息数据:制定定时备份策略,定期备份交换机、队列、绑定关系等元数据,核心业务支持消息数据回溯恢复,应对误删除、故障数据丢失问题。
-
3. 日志规范化切割与归档:开启MQ服务日志、客户端日志切割,避免单日志文件过大,日志保留合理时长,方便故障溯源、问题复盘、安全审计。
-
4. 制定完整应急预案:针对消息堆积、节点离线、集群脑裂、流控触发、消息丢失、大量消费异常等场景,制定标准化应急处理流程,保障故障快速止损。
八、Spring AMQP 专属最佳实践
-
1. 全局统一配置JSON消息转换器:禁止默认序列化方式,全局配置Jackson消息转换器,统一消息序列化、反序列化规则,避免类型转换异常、数据格式错乱。
-
2. 合理配置消费者线程池参数:根据服务器性能配置核心线程数、最大线程数,避免线程过多导致上下文切换频繁、性能下降,线程过少导致消费能力不足、队列堆积。
-
3. 全局统一消费异常处理:封装全局异常处理器,统一捕获消费异常,自动记录日志、标记异常消息、转入死信队列,避免异常消息阻塞消费链路。
-
4. 彻底摒弃MQ原生事务:RabbitMQ原生事务性能极差、阻塞严重、无实际生产价值,分布式事务统一使用本地消息表、Confirm补偿等最终一致性方案,禁止使用原生事务。
-
5. 关闭不必要的自动创建资源机制:生产环境禁止客户端自动创建交换机、队列,所有MQ资源统一后台预创建、代码绑定,避免线上随意创建无效资源、造成资源混乱。
九、性能调优终极规范
-
1. 合理设置内存、磁盘水位阈值:根据服务器配置调整MQ内存阈值、磁盘水位,避免内存溢出、磁盘打满触发流控、暂停消息接收,保障集群稳定运行。
-
2. 限制单IP、单节点最大连接数:配置全局连接数限制、单IP连接数限制,防止恶意连接、异常服务占用全部连接资源,导致正常业务无法通信。
-
3. 定期清理无效资源:定时清理废弃队列、无效交换机、僵尸连接、闲置信道,释放服务器内存、端口资源,避免资源累积占用导致性能下降。
-
4. 高吞吐业务专项调优:海量非核心业务(日志、上报数据)可适当放宽持久化策略、调整批量收发参数,在可控范围内平衡可靠性与吞吐量。
简洁:
-
队列单一职责,一个队列对应一类业务,不混用
-
禁止使用默认交换机,手动声明交换机与队列
-
业务队列强制双持久化(队列+消息)
-
生产环境统一使用手动 ACK,禁用自动 ACK
-
合理配置 prefetch,保证消费负载均衡
-
消息体控制大小,大消息拆分或压缩
-
所有异常消息接入死信队列,禁止无限重试
-
每条消息携带全局唯一 ID,保证幂等
-
新版本集群优先使用仲裁队列,替代镜像队列
-
多环境/多项目使用独立 vhost 隔离
-
禁用 guest 账号,配置 IP 白名单与 SSL 加密
-
规范连接池,禁止频繁创建销毁连接、信道
-
全环境部署监控+告警,提前发现故障
-
制定集群启停、故障应急标准流程
第十二部分 文字版思维导图(可直接复习)
第十三部分 生产环境巡检清单(可落地检查)
一、账号与 vhost 检查
-
已禁用/修改默认 guest 账号,禁止外网访问
-
账号按角色划分:管理员、监控、生产者、消费者
-
密码复杂度达标,定期轮换
-
多环境/多业务使用独立 vhost 隔离
-
权限遵循最小分配原则
二、网络与传输安全
-
防火墙限制 5672/15672/25672 端口
-
配置业务服务器 IP 白名单
-
外网/跨机房已开启 SSL/TLS 加密
三、服务端集群配置(完整版·部署+参数+调优+故障落地)
本板块为RabbitMQ生产集群核心配置规范,覆盖集群部署架构、节点类型、队列模式、核心参数调优、集群约束、故障规避、生产禁用项,适配3.8+高版本,完全贴合企业生产落地标准,可直接用于集群巡检、搭建、整改。
3.1 集群基础架构部署规范
-
集群节点数量硬性规范 :生产集群必须部署3节点及以上奇数节点(3节点最优、5节点适配超大型集群),严格禁止2节点双节点集群、单节点集群上线生产。双节点集群极易触发网络分区(脑裂),导致队列状态不一致、消息丢失、重复消费;单节点无高可用,节点故障直接导致业务瘫痪。
-
节点角色配比规范 :集群内至少部署2个磁盘节点 ,剩余节点可配置为磁盘节点,严格禁止全内存节点集群。磁盘节点持久化集群元数据(交换机、队列、绑定关系、用户权限),内存节点仅缓存数据、读写性能更高,全内存节点重启后所有集群配置全部丢失。
-
节点部署隔离规范:集群节点需跨物理机、跨机架部署,核心业务集群建议跨机房容灾,禁止单机器、单机架部署所有节点,避免硬件故障、机架断电导致整个集群瘫痪。
-
集群同步机制规范:3.8+版本统一基于Raft算法实现集群数据同步,元数据自动同步、节点故障自动剔除,无需人工干预,替代旧版本手动同步机制。
3.2 队列模式选型与配置规范(核心)
-
默认强制使用仲裁队列(Quorum Queue) :RabbitMQ3.8+生产环境全面废弃镜像队列,所有业务队列必须设置为仲裁队列。仲裁队列基于Raft一致性算法,具备数据强一致、自动容灾、脑裂风险低、性能更优的特性,解决镜像队列同步延迟、性能卡顿、数据不一致的核心问题。
-
仲裁队列核心配置规范:队列副本数默认3副本(与集群节点数匹配),最小可用副本数2,保证单节点离线后队列仍可正常读写;禁止随意修改副本数为1,丧失集群高可用能力。
-
临时队列特殊适配:临时独占队列、测试队列可使用普通队列模式,无需配置仲裁副本,减少集群资源消耗。
-
彻底禁用镜像队列:生产环境关闭自动镜像策略,无任何业务队列使用镜像模式,规避旧架构兼容性故障。
3.3 核心阈值参数生产调优配置
-
内存水位阈值(防止内存溢出):默认内存阈值为系统内存40%,生产需根据服务器配置自定义调整,8G服务器设置2G阈值、16G服务器设置4-6G阈值;内存触发阈值后集群自动开启流控、停止接收新消息,防止OOM宕机。
-
磁盘水位阈值(防止磁盘打满):配置磁盘低水位警戒线,预留10%以上磁盘空间,磁盘使用率触发阈值后,集群暂停消息写入、拒绝生产者连接,避免磁盘100%占满导致服务卡死、日志无法写入。
-
全局连接数限制:配置集群最大总连接数、单节点最大连接数、单IP最大连接数,规避异常服务、恶意连接占用全部连接资源,导致正常业务无法建立通信。常规集群单节点最大连接数设置1000-2000。
-
信道数量限制:限制单连接最大信道数(默认无上限,生产配置200-500),防止单一连接创建过量信道,耗尽节点内存资源。
-
消息最大尺寸限制:全局限制单条消息最大大小(默认64MB,生产建议限制512KB),杜绝超大消息占用内存、拖慢集群整体吞吐。
3.4 集群网络与分区容错规范
-
网络超时参数配置:优化集群节点间心跳超时、故障判定超时参数,适配机房常规网络抖动,避免短暂网络波动误判节点离线。默认心跳间隔60s,生产可微调为30s,兼顾稳定性与容错性。
-
网络分区(脑裂)处理规范:开启集群自动分区恢复策略,奇数节点集群天然规避脑裂;若出现网络分区,自动保留节点数量最多的分区为主集群,自动剔除异常分区节点,无需人工介入。
-
禁止手动强制恢复分区:出现集群分区、节点分裂时,禁止手动重启节点、强制合并集群,避免数据覆盖、消息丢失,需等待网络恢复后集群自动同步修复。
3.5 集群启停与故障恢复标准流程
-
集群正常启停规范:停机顺序:先停止生产者、消费者业务流量 → 逐个优雅关停集群从节点 → 关停主节点;启动顺序:先启动磁盘主节点 → 等待节点初始化完成 → 逐个启动从节点 → 集群同步完成后再放行业务流量。禁止暴力kill进程、强制断电启停集群。
-
故障节点恢复规范:故障节点下线后,集群自动剔除、业务正常运行;节点恢复上线后,自动与集群同步元数据、队列数据,同步完成后自动接管流量,无需手动重建队列、交换机。
-
集群扩容/缩容规范:扩容新增节点后,自动加入集群、同步全量配置;缩容下线节点前,需清空节点消息、迁移队列,避免直接下线导致消息丢失。
3.6 集群生产禁用项(高危避坑)
-
禁止生产集群使用单节点部署、双节点集群部署
-
禁止全内存节点集群、仅单磁盘节点集群
-
禁止生产核心业务使用镜像队列、废弃旧架构队列模式
-
禁止随意修改集群副本数、心跳超时、水位阈值核心参数
-
禁止集群运行中直接删除节点、强制重置集群状态
-
禁止不同版本RabbitMQ节点混合组建集群(版本差异过大导致同步异常)
3.7 集群巡检专属校验项(新增落地清单)
-
集群节点数量为3/5奇数,无单节点、双节点生产集群
-
集群磁盘节点数量≥2,无全内存节点部署
-
所有核心业务队列均为仲裁队列,无镜像队列残留
-
内存、磁盘水位阈值已根据服务器配置优化,无默认参数上线
-
全局连接数、单IP连接数、信道数已做限流配置
-
集群心跳超时、分区恢复策略配置合理,无频繁节点离线
-
严格遵循集群启停、扩容缩容标准流程,无暴力操作记录
-
集群无历史脑裂、数据同步异常、节点分裂故障记录
四、队列与消息配置(全维度生产巡检补全)
本模块覆盖生产队列全属性配置、消息持久化、流量管控、死信兜底、TTL延时、消息规范、高危避坑等核心巡检项,所有校验标准均贴合前文生产最佳实践,可直接用于线上环境逐项核查、整改落地,杜绝队列配置不规范引发的消息丢失、堆积、重复消费、业务错乱问题。
4.1 队列基础属性巡检(核心必查)
-
所有核心业务队列已开启队列持久化(durable=true),无临时队列承载正式业务
-
核心交易、订单、支付类消息已开启消息持久化(deliveryMode=2),实现双持久化兜底
-
正式业务队列均为共享队列(exclusive=false),无独占队列用于常驻业务
-
常驻业务队列自动删除属性关闭(autoDelete=false),避免无消费者时队列自动销毁
-
所有队列遵循单一职责原则,无多类业务混用同一队列情况
-
队列命名规范统一(业务+功能+类型),无随意命名、拼音缩写、重名队列
-
生产环境无默认交换机绑定的匿名队列,所有队列均关联专属业务交换机
4.2 流量管控与溢出策略巡检(高并发专项)
-
秒杀、活动、高并发流量队列已配置x-max-length最大消息条数限制,防止无限堆积
-
大体积数据业务队列已配置x-max-length-bytes字节容量限制,避免磁盘内存溢出
-
队列溢出策略配置合理:核心业务采用reject-publish-dlx,普通业务采用drop-head,无未配置溢出策略的高并发队列
-
限流队列阈值贴合业务峰值流量,无阈值过大导致堆积、阈值过小拦截正常流量问题
4.3 死信队列(DLX)配置巡检(异常兜底核心)
-
所有核心业务队列已绑定专属死信交换机与死信队列,异常消息有兜底机制
-
死信队列未配置任何死信交换机(禁止DLX嵌套),彻底杜绝消息循环流转、永久堆积问题
-
死信队列独立隔离,不与正式业务队列混用,单独监控、单独清理、单独溯源
-
明确队列死信触发条件:消费Nack/reject、消息过期、队列溢出三类场景均能正常转入死信队列
-
死信队列配置合理的堆积告警,无长期堆积未处理的异常消息
4.4 TTL延时队列配置巡检(高阶业务专项)
-
短延时业务(30s内)TTL队列参数配置准确,消息过期时间贴合业务场景
-
精准、长延时业务已采用延时插件方案,未使用原生TTL+DLX规避消息阻塞坑点
-
TTL队列严格区分队列级TTL 与消息级TTL,无参数冲突导致延时失效问题
-
延时队列消息过期后可正常路由至目标业务队列,无路由失效、消息丢失问题
4.5 优先级队列配置巡检(加急业务专项)
-
加急、紧急通知类业务按需配置优先级队列,已设置x-max-priority最大优先级(0~255)
-
优先级队列均搭配单消费者模式,无多消费者竞争导致优先级失效问题
-
普通业务未滥用优先级队列,避免无效占用集群资源
4.6 消息规范与属性巡检(零丢失、可溯源核心)
-
消息体大小严格可控,单条消息≤128KB,最大不超过512KB,超大消息已拆分或开启GZIP压缩
-
所有业务消息强制携带全局唯一MessageId,用于幂等校验、链路溯源、异常排查
-
消息contentType统一为application/json,序列化格式统一,无反序列化异常隐患
-
大消息场景已开启压缩编码,传输与存储开销可控
-
消息自定义Header规范统一,链路追踪、灰度标记参数完整,无无效自定义参数冗余
4.7 队列生命周期与资源巡检(运维规范)
-
无僵尸队列、废弃队列长期占用集群资源,闲置队列已定期清理下线
-
临时队列仅用于RPC调用、测试场景,无临时队列承载线上正式业务
-
队列绑定关系准确,无无效绑定、重复绑定、错绑交换机问题
-
交换机类型与业务匹配,核心业务无使用Headers、Default废弃交换机
4.8 生产高危配置禁项(零故障兜底)
-
无核心业务队列关闭持久化、裸跑上线的情况
-
无死信队列嵌套DLX、延时队列混用多级TTL的高危配置
-
无超大消息、无格式乱序消息线上传输
-
无多业务混用同一队列、同一交换机导致的消息串流问题
-
业务队列全部开启队列持久化
五、消费者配置(完整版·参数+规范+代码+避坑)
消费者是RabbitMQ消息链路的最后一环,配置直接决定消费速度、消息重复性、堆积概率、业务稳定性。本章节补全生产全量消费者配置规范、核心参数、代码落地、异常处理及高频坑点,完全适配Spring AMQP生产环境。
5.1 核心基础配置规范(生产强制标准)
-
ACK机制强制规范 :生产环境彻底禁用自动ACK(AUTO),统一使用手动ACK(MANUAL)。自动ACK会在消息投递成功后立即删除消息,若消费过程程序异常、机器宕机、接口报错,会直接造成消息永久丢失;手动ACK可精准控制消费成功确认、异常重试、失败入死信,完全掌控消息生命周期。
-
全局关闭批量ACK:非超高吞吐非核心业务,禁止使用批量ACK。批量ACK一次性确认多条消息,存在中间消息消费失败、首尾消息正常却全部确认删除的隐患,极易引发数据不一致,仅日志、埋点等极低优先级业务可谨慎开启。
-
消息预取值Prefetch精准配置:prefetch为单消费者单次拉取的最大未确认消息数,是负载均衡、防堆积的核心参数。常规业务配置10~50,轻量快速消费业务配置50~100,耗时重型业务配置5~10;prefetch过大会导致单消费者消息堆积、集群负载不均,过小会引发频繁拉取、损耗网络与CPU性能。
-
消费超时合理配置:统一设置消费超时时间(默认30s,生产根据业务调整),避免消费线程卡死、长阻塞导致消息一直未ACK,队列消息持续挂起、无法轮转消费,最终引发队列堆积。超时未消费消息会自动触发重试机制,防止消息永久阻塞。
-
严格落实消费幂等:所有消费者业务逻辑必须实现全局幂等。MQ重试、网络抖动、集群多实例部署、消息重投都会导致消息重复投递,无幂等逻辑会造成订单重复创建、积分重复发放、数据重复入库、业务错乱等严重问题。
5.2 消费者线程池配置规范(性能核心)
-
核心线程数:根据服务器CPU核心数、业务耗时配置,常规配置5~20,保证常驻消费线程,避免频繁创建销毁线程损耗性能。
-
最大线程数:根据业务并发峰值扩容,核心业务不超过50,防止线程过多导致上下文切换频繁、服务器资源耗尽、服务卡顿。
-
队列容量:线程池任务队列不宜过大,避免消费任务堆积在本地JVM,脱离MQ管控,故障后无法回溯、重试。
-
线程超时回收:配置空闲线程超时时间,闲置线程自动回收,节省服务器资源,适配流量波动场景。
5.3 ACK、Nack、Reject 精准使用规范(避坑重点)
-
basicAck(成功确认) :仅在业务完全执行成功、数据落地无误后执行,参数multiple=false,单次精准确认单条消息,杜绝批量确认引发的数据风险。
-
basicNack(异常重试):用于临时可重试异常(网络抖动、数据库短暂超时、瞬时资源不足),可批量驳回消息;重试次数耗尽后禁止继续Nack重试,必须转入死信队列。
-
basicReject(直接拒绝):用于无效脏数据、参数错误、过期失效、无需重试的消息,单次拒绝单条消息,配合requeue=false直接丢弃,避免无效消息无限重试占用资源。
-
核心禁忌:禁止所有异常无脑Nack重试,禁止批量Nack滥用,禁止业务失败不做任何处理,导致消息永久挂起、队列死循环堆积。
5.4 重试机制生产规范(杜绝死循环)
-
禁用SpringAMQP默认重试:框架默认重试无次数限制、无时间梯度、无法管控,极易引发消息死循环、CPU打满、队列雪崩。
-
自定义梯度重试策略:统一配置3~5次最大重试次数,采用梯度间隔重试(1s、3s、5s、10s),避免频繁重试冲击业务服务与数据库。
-
重试失败兜底:所有达到最大重试次数的消息,必须转入专属死信队列,禁止丢弃、禁止继续重试,保留异常消息用于问题溯源与数据修复。
-
重试幂等强化:重试消息与首次消息共用同一幂等校验逻辑,避免重试引发重复业务处理。
5.5 消费业务代码强制约束(防堆积、防异常)
-
禁止长耗时阻塞操作:消费逻辑中禁止嵌套同步远程调用、大批量IO操作、复杂计算、睡眠等待、循环阻塞等耗时逻辑,长耗时消费会直接导致队列大量堆积、ACK超时、消息重复投递。
-
耗时业务异步拆解:复杂耗时业务拆解为轻量消费通知+线程池异步处理,MQ消费仅做消息接收与任务分发,保证消费链路快速响应、及时ACK。
-
禁止消费内部吞异常:消费逻辑必须捕获所有异常,统一日志记录、堆栈打印、异常标记,禁止try-catch空吞异常导致消息静默丢失、问题无法排查。
-
大消息专项处理:超大消息先解压、再解析、后消费,避免解析失败、内存溢出导致消费卡死。
5.6 消费者负载均衡机制规范
-
普通队列竞争消费:多消费者监听同一队列,默认竞争消费模式,消息均匀分发,配合合理prefetch实现负载均衡。
-
禁止消费者能力不均:同一队列的消费者实例配置统一线程池、prefetch参数,避免部分实例过载、部分实例闲置,负载失衡引发局部堆积。
-
灰度消费隔离:正式消费者与灰度消费者严格隔离,分别监听对应队列,禁止混听混消费,避免灰度脏数据污染正式业务。
5.7 SpringBoot 消费者完整配置代码(生产直接可用)
java
/**
* RabbitMQ 消费者全局配置
* 包含手动ACK、线程池、prefetch、重试、超时、异常兜底全套生产配置
*/
@Configuration
public class RabbitConsumerConfig {
/**
* 消费者容器工厂配置(全局统一)
*/
@Bean("rabbitListenerContainerFactory")
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
// 1. 全局开启手动ACK
factory.setAcknowledgeMode(AcknowledgeMode.MANUAL);
// 2. 预取值配置(适配常规业务)
factory.setPrefetch(20);
// 3. 消费超时时间30秒
factory.setReceiveTimeout(30000L);
// 4. 消息重试超时时间
factory.setRetryTemplate(retryTemplate());
// 5. 线程池配置
factory.setConcurrentConsumers(10);
factory.setMaxConcurrentConsumers(30);
return factory;
}
/**
* 自定义梯度重试模板
* 最大重试4次,梯度间隔:1s、3s、5s、10s
*/
private RetryTemplate retryTemplate() {
RetryTemplate retryTemplate = new RetryTemplate();
// 最大重试次数
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy(4);
// 梯度重试间隔
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(1000);
backOffPolicy.setMultiplier(2.0);
backOffPolicy.setMaxInterval(10000);
retryTemplate.setRetryPolicy(retryPolicy);
retryTemplate.setBackOffPolicy(backOffPolicy);
// 重试失败后执行兜底策略
retryTemplate.registerListener(new RabbitRetryListener());
return retryTemplate;
}
}5.8 标准消费者业务模板(规范落地版)
java
/**
* 标准业务消费者模板
* 包含幂等校验、手动ACK、异常处理、重试兜底、死信兜底
*/
@Component
public class StandardBusinessConsumer {
@Resource
private BusinessService businessService;
@RabbitListener(queues = "order.business.queue")
public void consume(Message message, Channel channel) {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
String messageId = message.getMessageProperties().getMessageId();
String body = new String(message.getBody());
try {
// 1. 全局幂等校验(优先执行)
if (businessService.checkIdempotent(messageId)) {
// 已消费过,直接确认,避免重复处理
channel.basicAck(deliveryTag, false);
return;
}
// 2. 解析消息、执行业务逻辑
Order order = JSON.parseObject(body, Order.class);
businessService.handleOrderBusiness(order);
// 3. 消费成功,手动确认
channel.basicAck(deliveryTag, false);
} catch (Exception e) {
try {
// 4. 异常重试/死信兜底
Integer retryCount = message.getMessageProperties().getHeader("x-retry-count");
retryCount = retryCount == null ? 0 : retryCount;
if (retryCount <= 3) {
// 未达最大重试次数,重回队列重试
channel.basicNack(deliveryTag, false, true);
} else {
// 重试耗尽,拒绝消息,转入死信队列
channel.basicReject(deliveryTag, false);
}
} catch (IOException ex) {
log.error("消息消费异常、ACK处理失败", ex);
}
}
}
}5.9 消费者高频坑点汇总(生产必避)
-
坑1:自动ACK上线生产,宕机、异常导致消息静默丢失
-
坑2:prefetch配置不合理,引发负载不均、消息堆积、消费卡顿
-
坑3:消费内部嵌套长耗时、同步阻塞逻辑,导致ACK超时、重复消费
-
坑4:所有异常无脑Nack重试,无次数限制,引发消息死循环、CPU爆满
-
坑5:未实现幂等,重试、重复投递导致业务数据错乱
-
坑6:批量ACK滥用,中间消息异常无法精准回溯,造成数据丢失
-
坑7:消费异常空吞try-catch,不记录日志、不处理兜底,问题无法排查
-
坑8:多消费者实例参数不一致,导致集群负载严重失衡
5.10 消费者巡检清单(可直接勾选落地)
-
生产环境全部使用手动 ACK,彻底关闭自动ACK
-
批量 ACK 仅在非核心业务谨慎使用,核心业务禁用
-
prefetch 根据业务消费能力合理配置,无过大过小问题
-
消费超时参数适配业务耗时,无长期挂起未ACK消息
-
所有消费业务已实现全局幂等,支持重复投递无错乱
-
已关闭框架默认重试,自定义梯度重试+最大次数限制
-
重试耗尽消息正常转入死信队列,无无限重试堆积
-
消费逻辑无长耗时阻塞、同步远程调用嵌套问题
-
消费者线程池参数合理,无线程过载、资源浪费
六、生产者配置(完整版·规范+参数+代码+避坑+巡检)
生产者是消息链路的入口,其配置直接决定消息投递成功率、消息不丢失、路由可靠性、集群负载稳定性,是RabbitMQ生产稳定性的源头核心。本章节补全全套生产者生产规范、核心参数、SpringBoot落地代码、高频坑点及专属巡检清单,适配所有线上业务场景。
6.1 生产者核心强制规范(生产必守)
-
核心业务强制开启Confirm投递确认机制:所有订单、支付、交易类核心业务,必须开启异步Confirm确认,精准感知消息是否成功抵达交换机,彻底解决生产者投递静默丢失问题。禁用同步Confirm,同步确认阻塞严重、吞吐量极低,不适合线上高并发场景。
-
路由失败强制开启Return回调+mandatory=true:仅Confirm只能确认抵达交换机,无法校验是否成功路由到队列。开启mandatory参数+Return回调,无匹配队列、路由失败的消息会触发Return回调,可及时捕获异常、记录日志、补偿重发,杜绝路由失效导致的消息丢失。
-
核心业务消息强制双持久化:生产者发送消息时,必须手动设置消息持久化模式(deliveryMode=2),搭配队列持久化,实现消息+队列双持久化,服务重启、节点故障不丢失消息。非核心日志、埋点消息可按需关闭,换取更高吞吐量。
-
每条消息强制携带全局唯一MessageId:生产者统一生成UUID或业务单号作为MessageId,全局唯一,用于消费幂等校验、链路追踪、异常溯源、重试去重,禁止依赖MQ自动生成ID,避免跨服务日志无法关联。
-
禁止使用MQ原生事务:RabbitMQ原生事务性能极差、阻塞严重、吞吐量极低,生产彻底废弃。消息投递一致性统一使用Confirm+本地消息表实现最终一致性,适配所有分布式业务场景。
-
严格控制消息体大小:生产者封装消息时,严控单条消息体积,常规业务≤128KB,最大不超过512KB。超大消息拆分分片发送或开启GZIP压缩,避免占用过高内存、拖慢集群吞吐、引发队列堆积。
-
统一消息序列化格式:生产者统一使用JSON序列化,指定contentType为application/json,禁止随意使用JDK默认序列化、二进制乱序格式,避免消费端反序列化异常、数据错乱。
6.2 生产者核心参数详解(生产调优关键)
-
mandatory 参数:true=路由失败消息触发Return回调,不直接丢弃;false=路由失败消息直接丢失,无任何回调。生产核心业务必须设置为true,普通非核心业务可设为false提升性能。
-
deliveryMode 消息模式:1=非持久化(内存消息,重启丢失);2=持久化(落盘存储)。核心业务固定2,日志、监控、埋点等低优先级业务可使用1。
-
消息TTL属性:生产者可单独设置消息级过期时间,优先级高于队列级TTL,适配单条消息差异化延时、过期失效场景,避免统一队列TTL约束。
-
消息优先级参数:仅配合优先级队列生效,生产者发送消息时指定0~255优先级,加急业务设置高优先级,实现优先消费。
-
批量发送参数:高吞吐非核心业务可开启批量投递,积攒多条消息统一发送,减少网络IO次数,大幅提升吞吐量;核心交易业务禁止批量发送,保证单条消息精准可控。
6.3 SpringBoot 生产者全局配置(可直接上线)
java
/**
* RabbitMQ 生产者全局配置
* 包含Confirm确认、Return回调、消息持久化、序列化、重试兜底全套生产配置
*/
@Configuration
@Slf4j
public class RabbitProducerConfig {
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
// 1. 全局开启消息持久化(核心业务默认持久化)
rabbitTemplate.setMandatory(true);
// 2. 开启异步Confirm确认回调
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) {
log.info("消息投递交换机成功,消息ID:{}", correlationData != null ? correlationData.getId() : null);
} else {
log.error("消息投递交换机失败,消息ID:{},失败原因:{}", correlationData != null ? correlationData.getId() : null, cause);
// 可自定义失败补偿逻辑:重试、记录数据库、告警
}
});
// 3. 开启路由失败Return回调
rabbitTemplate.setReturnsCallback(returned -> {
log.error("消息路由队列失败,交换机:{},路由键:{},回复码:{},回复信息:{}",
returned.getExchange(), returned.getRoutingKey(), returned.getReplyCode(), returned.getReplyText());
// 路由失败兜底:消息落地存档、人工排查、重发补偿
});
// 4. 全局配置JSON消息转换器,统一序列化规则
rabbitTemplate.setMessageConverter(jsonMessageConverter());
return rabbitTemplate;
}
/**
* 全局JSON序列化转换器
* 替代默认JDK序列化,避免类型异常、数据兼容问题
*/
@Bean
public MessageConverter jsonMessageConverter() {
MappingJackson2MessageConverter converter = new MappingJackson2MessageConverter();
converter.setObjectMapper(new ObjectMapper().registerModule(new JavaTimeModule())
.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false));
return converter;
}
}6.4 标准生产者发送模板(规范落地版)
java
/**
* 标准业务生产者发送模板
* 包含唯一MessageId、持久化配置、Confirm关联、异常兜底
*/
@Service
@Slf4j
public class StandardBusinessProducer {
@Resource
private RabbitTemplate rabbitTemplate;
/**
* 发送核心业务消息(订单/支付/交易)
*/
public void sendOrderMessage(OrderDTO orderDTO) {
// 1. 生成全局唯一消息ID,用于幂等与溯源
String messageId = UUID.randomUUID().toString().replace("-", "");
// 2. 封装消息投递关联数据,绑定Confirm回调
CorrelationData correlationData = new CorrelationData(messageId);
// 3. 构建消息属性:持久化、JSON格式
MessageProperties messageProperties = new MessageProperties();
// 消息持久化
messageProperties.setDeliveryMode(MessageDeliveryMode.PERSISTENT);
// 统一JSON格式
messageProperties.setContentType(MediaType.APPLICATION_JSON_VALUE);
// 绑定唯一消息ID
messageProperties.setMessageId(messageId);
try {
// 4. 消息封装与发送
String msgBody = JSON.toJSONString(orderDTO);
Message message = new Message(msgBody.getBytes(StandardCharsets.UTF_8), messageProperties);
// 投递消息(指定交换机、路由键)
rabbitTemplate.send("order.topic.exchange", "order.create", message, correlationData);
log.info("订单消息投递成功,messageId:{},订单号:{}", messageId, orderDTO.getOrderNo());
} catch (Exception e) {
log.error("订单消息投递异常,messageId:{}", messageId, e);
// 投递失败兜底:入库记录、定时重试、告警通知
}
}
/**
* 发送非核心高吞吐消息(日志/埋点/上报)
* 轻量化配置,牺牲部分可靠性换取高吞吐
*/
public void sendLogMessage(LogDTO logDTO) {
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
// 非核心消息关闭持久化、提升吞吐量
MessageProperties messageProperties = new MessageProperties();
messageProperties.setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT);
messageProperties.setContentType(MediaType.APPLICATION_JSON_VALUE);
String msgBody = JSON.toJSONString(logDTO);
Message message = new Message(msgBody.getBytes(StandardCharsets.UTF_8), messageProperties);
rabbitTemplate.send("log.fanout.exchange", "log.report", message, correlationData);
}
}
6.5 生产者高级特性落地规范
-
消息批量发送规范:仅日志、用户行为上报、监控数据等高吞吐、低可靠场景使用批量发送;批量大小控制在100~500条,避免单次批量过大导致消息拥堵、投递超时。核心交易业务禁止批量发送,保证单条消息精准可控。
-
消息压缩传输规范:消息体超过64KB自动开启GZIP压缩,生产者压缩、消费者解压,大幅减少网络传输流量与磁盘存储占用,提升吞吐效率。压缩后需在Header标记压缩类型,保证消费端正常解析。
-
差异化TTL发送规范:统一延时场景使用队列TTL,单条消息差异化延时场景使用消息级TTL,优先级:消息TTL > 队列TTL,避免全局队列延时规则冲突。
-
灰度消息标记规范:灰度流量消息,生产者统一在Header中添加灰度版本、灰度比例、灰度标记,用于消费者精准过滤隔离,避免灰度消息污染正式业务。
6.6 生产者高频坑点汇总(生产必避)
-
坑1:仅开启队列持久化,未设置消息持久化,服务重启内存消息全部丢失。
-
坑2:只开Confirm、未开Return回调,路由失败消息静默丢失,无法溯源。
-
坑3:mandatory=false,无匹配队列时消息直接丢弃,无任何兜底机制。
-
坑4:使用同步Confirm或原生事务,高并发下严重阻塞接口、吞吐量暴跌。
-
坑5:未自定义MessageId,依赖MQ自动ID,无法做幂等与链路排查。
-
坑6:超大消息无压缩、无拆分,拖慢集群整体性能,极易引发堆积。
-
坑7:混用消息TTL与队列TTL,导致延时时间错乱、业务逻辑异常。
-
坑8:高并发场景频繁创建Connection/Channel,导致端口耗尽、连接打满。
6.7 生产者生产巡检清单(可直接勾选落地)
-
核心业务开启 Confirm 异步确认,无同步Confirm、无原生事务使用
-
路由失败场景开启 Return 回调 + mandatory=true,路由异常可捕获兜底
-
每条消息携带全局唯一 MessageId,支持幂等校验与链路溯源
-
核心业务消息开启持久化(deliveryMode=2),实现双持久化兜底
-
全局统一JSON消息转换器,无JDK默认序列化乱序问题
-
超大消息已拆分或开启GZIP压缩,消息体积合规可控
-
高吞吐非核心业务按需开启批量发送,核心业务禁止批量投递
-
灰度消息、延时消息、优先级消息参数配置规范,无参数冲突
-
消息投递异常有完整兜底策略(日志记录、重试、告警、入库存档)</checkbox id="4420" done="false">严格遵循多信道、少连接原则,无频繁创建销毁连接信道问题
七、客户端连接管理(完整版·原理+配置+调优+排错+落地规范)
客户端连接是RabbitMQ通信的基础,连接、信道的创建、复用、异常处理、资源回收直接决定MQ集群稳定性与业务可用性,绝大多数MQ线上故障(端口耗尽、连接打满、信道泄漏、频繁断连、消费卡顿)均由客户端连接不规范导致。本章节全方位补全生产级客户端连接管理规范,适配Spring AMQP全场景,可直接落地执行、巡检整改。
7.1 客户端连接核心设计原则(生产铁律)
-
多信道、少连接(核心准则):严格禁止业务频繁创建/销毁TCP物理连接,全局复用少量长连接,基于单连接创建多个轻量级信道完成业务通信,大幅降低TCP握手、资源初始化开销,避免端口与文件句柄耗尽。
-
长连接永久复用:客户端与MQ服务端全程维持长连接,项目启动初始化连接池,项目销毁统一关闭,不随单次接口请求、业务流程启停。
-
连接资源隔离:不同微服务、不同环境(开发/测试/生产)独立使用连接池,禁止跨服务、跨环境共用连接,避免连接混乱、相互影响。
-
资源闭环回收:所有信道、临时连接使用完毕必须主动关闭,杜绝信道泄漏、连接残留,防止长期运行资源累积占用导致服务卡顿。
7.2 连接与信道生产配置规范
7.2.1 全局连接池参数标准(适配所有微服务)
-
最小空闲连接数:2~4个,常驻维持基础通信,应对突发流量,避免流量洪峰时新建连接耗时阻塞。
-
最大连接数:8~16个,单服务无需过多物理连接,足够支撑数万级QPS业务,防止连接过多占用集群连接配额。
-
单连接最大信道数:200~500个,限制单连接信道上限,避免单连接创建过量信道耗尽内存资源,规避单连接雪崩风险。
-
连接空闲超时:关闭空闲连接自动销毁,生产长连接永久常驻,避免频繁断连重连引发消息重试、消费抖动。
-
连接超时时间:建立连接超时设置5~10s,防止网络阻塞导致线程长期挂起。
-
握手协商超时:3~5s,避免协议协商、身份认证超时卡死连接创建流程。
7.2.2 信道使用规范
-
信道复用优先:业务收发消息优先从连接池获取空闲信道,禁止每次业务新建信道。
-
短生命周期信道机制:临时信道使用完毕立即关闭,常驻业务信道统一池化复用。
-
信道故障隔离:单信道异常、关闭不影响所属TCP连接与其他信道,故障后自动新建信道替补,不中断整体业务通信。
-
禁止信道堆积:同一连接下空闲信道及时回收,避免无效信道占用内存资源。
7.3 自动重连与故障容错机制(生产必备)
-
开启全局自动重连:生产环境强制开启客户端自动重连机制,网络抖动、节点重启、短暂断连后自动恢复通信,无需人工介入重启服务。
-
梯度重连间隔配置:禁止固定间隔高频重连,采用梯度重试(2s→5s→10s→30s),最大重连间隔不超过30s,避免大量客户端同时重连冲击MQ集群。
-
最大重连次数限制:配置无上限重连,保障服务长期离线恢复后可自动恢复通信,适配集群滚动重启、机房维护场景。
-
重连失败告警:连续多次重连失败触发钉钉/短信告警,及时发现集群宕机、端口封禁、网络不通等故障。
-
断连期间消息兜底:生产者断连时缓存待发送消息(内存短时缓存+数据库持久兜底),重连成功后批量补发,避免消息丢失。
7.4 高频连接异常与故障解决方案(生产排错手册)
7.4.1 端口耗尽/连接数打满
故障成因:循环内频繁创建Connection/Channel、信道泄漏、连接不回收、多实例重复创建连接。
解决方案:启用连接池统一复用、禁止循环创建连接信道、新增资源回收拦截器、定时清理僵尸连接与闲置信道。
7.4.2 频繁断连重连
故障成因:服务器防火墙超时回收连接、MQ服务端流控、内存磁盘打满、网络不稳定、心跳参数配置不合理。
解决方案:优化客户端心跳间隔(30s)、调整服务端水位阈值、关闭防火墙空闲连接回收、优化重连梯度策略。
7.4.3 信道泄漏(核心隐形故障)
故障现象:服务长期运行后信道数持续上涨、内存占用逐步升高、无业务流量但信道不释放。
成因:手动创建信道后未关闭、异常场景未捕获导致信道未回收、第三方工具频繁创建临时信道。
解决方案:统一池化信道管理、全局拦截所有信道创建与销毁、异常finally代码块强制关闭信道、定时巡检清理无效信道。
7.4.4 连接被服务端强制断开
成因:单IP连接数超限、单节点连接数打满、触发服务端流控、磁盘/内存水位触发暂停接收连接。
解决方案:扩容集群连接配额、优化连接池参数、限制单IP最大连接数、清理无效连接释放资源。
7.5 SpringBoot 客户端连接池完整配置(可直接上线)
java
/**
* RabbitMQ 客户端连接池全局配置
* 解决连接频繁创建、信道泄漏、断连重连、资源耗尽问题
*/
@Configuration
@Slf4j
public class RabbitConnectionConfig {
@Bean
public CachingConnectionFactory connectionFactory() {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
// MQ集群地址、账号密码、vhost 自行配置
connectionFactory.setHost("127.0.0.1");
connectionFactory.setPort(5672);
connectionFactory.setUsername("prod-mq-user");
connectionFactory.setPassword("xxxxxx");
connectionFactory.setVirtualHost("/prod-business");
// 1. 连接池核心参数配置
// 最小空闲连接
connectionFactory.setCacheMode(CachingConnectionFactory.CacheMode.CONNECTION);
connectionFactory.setConnectionCacheSize(4);
// 单连接最大信道数
connectionFactory.setChannelCacheSize(300);
// 信道空闲超时回收(毫秒)
connectionFactory.setChannelCheckoutTimeout(10000);
// 2. 超时参数配置
connectionFactory.setConnectionTimeout(5000);
connectionFactory.setHandshakeTimeout(3000);
// 3. 自动重连配置
connectionFactory.getRabbitListenerContainerFactory();
connectionFactory.setAutomaticRecoveryEnabled(true);
// 初始重连间隔2s,最大30s
connectionFactory.setInitialRecoveryInterval(2000);
connectionFactory.setMaxRecoveryInterval(30000);
// 4. 开启连接、信道日志监控,便于排错
connectionFactory.setPublisherConfirmType(CacheConfirmType.CORRELATED);
return connectionFactory;
}
}7.6 客户端连接生产禁用项(高危避坑)
-
禁止在循环、定时任务、接口请求中手动新建 Connection、Channel
-
禁止关闭自动重连机制,避免网络抖动后业务彻底瘫痪
-
禁止无限创建信道、不做资源回收,杜绝信道内存泄漏
-
禁止单服务配置过多物理连接,占用集群连接配额
-
禁止开发、测试、生产环境共用同一连接与vhost,引发消息串流
-
禁止自定义短连接逻辑,所有通信统一基于连接池长连接复用
7.7 客户端连接完整巡检清单(落地可勾选)
-
使用长连接池复用机制,无频繁创建销毁 Connection 行为
-
所有 Channel 使用后正常关闭,无信道内存泄漏、残留闲置信道
-
客户端自动重连已开启,梯度重连参数配置合理,无暴力高频重连
-
连接池参数适配业务流量,连接数、信道数阈值合理无超限风险
-
已禁用循环创建连接/信道的高危代码,无端口耗尽隐患
-
断连、重连、连接失败场景有日志记录与告警机制,可快速排错
-
不同环境、不同业务独立连接隔离,无跨环境消息串流问题
-
长期运行服务无连接数、信道数持续上涨的资源泄漏问题
八、监控、告警与运维(生产完整版·落地手册)
监控与运维是保障RabbitMQ集群长期稳定运行的核心,完整的监控体系可提前预判流量异常、消息堆积、节点故障、资源溢出问题,配套告警与应急预案可实现故障秒级发现、分钟级处理。本章节整合监控指标、可视化搭建、告警规则、日常运维、故障排查、备份恢复、应急预案全套生产落地方案,适配线上集群全场景。
8.1 核心监控体系架构(生产标准)
生产统一采用 Prometheus + Grafana + RabbitMQ Exporter + 钉钉/短信告警 监控架构,实现指标采集、可视化展示、异常告警、数据留存全链路闭环,替代原生简陋监控,适配集群多节点、大流量场景。
-
RabbitMQ Exporter:部署在MQ集群节点,采集服务端核心指标、队列指标、连接信道指标、资源阈值指标
-
Prometheus:时序数据存储、指标聚合、规则计算,长期留存监控数据
-
Grafana:可视化大盘展示,支持节点、队列、流量、资源多维度视图
-
AlertManager:告警规则匹配、分级推送、告警收敛,避免轰炸式告警
-
告警渠道:钉钉机器人、企业微信、短信、邮件,分级触发不同告警方式
8.2 全维度核心监控指标(必监控·无遗漏)
8.2.1 集群节点资源指标(基础存活监控)
-
节点在线状态:集群节点在线数量、单节点离线状态,监控集群可用性
-
CPU使用率:节点CPU负载,长期高负载排查集群流量过载、日志打满问题
-
内存使用率:区分系统内存与MQ进程内存,监控内存水位阈值触发情况
-
磁盘使用率:磁盘空间占用、磁盘IO负载,防止磁盘打满、IO阻塞
-
文件句柄数:已使用/最大句柄占比,规避句柄耗尽导致连接创建失败
-
网络流量:节点入/出网络带宽、TCP连接数,监控流量洪峰与网络异常
8.2.2 流量吞吐指标(业务流量监控)
-
消息发送QPS:全局/单队列每秒投递消息数,监控业务流量峰值与波动
-
消息消费QPS:全局/单队列每秒消费消息数,判断消费能力是否匹配生产流量
-
消息吞吐总量:时段内累计收发消息数,统计业务流量规模
-
投递失败率:生产者投递失败、路由失败消息占比,排查配置与路由异常
-
消费失败率:消费异常、Nack、Reject消息占比,感知业务消费故障
8.2.3 队列核心指标(业务稳定性核心)
-
队列消息堆积数:待消费消息总量,区分正常堆积、异常持续堆积
-
队列就绪消息数:可正常消费的堆积消息数
-
未ACK消息数:消费中未确认消息数量,排查消费卡死、线程阻塞问题
-
死信队列堆积数:异常消息总量,感知业务异常、消息失效问题
-
队列消息过期数:TTL过期消息数量,判断延时业务是否异常
-
队列溢出消息数:队列超限溢出消息,排查流量限流配置合理性
8.2.4 连接与信道指标(连接稳定性监控)
-
全局连接总数:集群已建立TCP连接数,防止连接数打满
-
单IP连接数:监控异常IP大量创建连接,规避恶意访问、服务异常
-
信道总数:集群活跃信道数量,排查信道泄漏、资源残留问题
-
断连重连次数:时段内断连重连频次,判断网络抖动、节点不稳定问题
-
空闲连接/信道数量:闲置资源占比,优化连接池参数
8.2.5 集群高阶指标(高可用监控)
-
集群分区状态:是否存在脑裂、节点分区、集群分裂异常
-
仲裁队列副本状态:副本在线数量、同步状态,判断队列高可用有效性
-
流控触发次数:节点流控、内存流控触发频次,排查流量过载问题
-
消息持久化失败数:落盘失败消息数量,规避消息丢失风险
-
元数据同步状态:节点间交换机、队列配置同步一致性
8.3 生产分级告警规则(可直接配置上线)
所有告警分为**紧急告警(P0)、重要告警(P1)、一般告警(P2)**三级,不同级别对应不同推送渠道与响应时效,避免告警泛滥、核心故障被淹没。
8.3.1 P0紧急告警(5分钟内必须处理)
-
集群节点离线、半数以上节点异常,集群可用性下降
-
磁盘使用率≥90%,即将打满,存在服务卡死风险
-
集群出现脑裂、节点分区,数据同步异常
-
核心业务队列消费停滞、堆积持续暴涨,无消费进度
-
全局消息消费失败率≥20%,大面积业务异常
-
集群流控持续触发,业务消息无法正常投递
8.3.2 P1重要告警(30分钟内处理)
-
单节点CPU/内存使用率≥85%,资源负载过高
-
磁盘使用率≥80%,临近预警阈值
-
核心队列堆积量超平日峰值2倍,持续增长无回落
-
死信队列新增消息量突增,业务异常频发
-
连接数、信道数持续上涨,存在资源泄漏风险
-
节点频繁断连重连,网络或服务稳定性异常
8.3.3 P2一般告警(日常巡检处理)
-
非核心队列少量消息堆积
-
节点资源使用率小幅升高,无业务影响
-
少量消息投递失败、路由失败
-
闲置僵尸队列、无效连接长期存在
8.4 Grafana生产大盘配置(标准模板)
生产统一配置五大可视化面板,全覆盖运维观测场景:
-
集群总览面板:节点状态、在线数量、全局吞吐、连接总数、告警统计
-
资源监控面板:CPU、内存、磁盘、网络、文件句柄实时曲线
-
流量监控面板:收发QPS、失败率、流量峰值、时段流量统计
-
队列监控面板:各队列堆积数、未ACK数、死信数、过期消息数排行
-
连接信道面板:连接数、信道数、断连次数、资源占用趋势
8.5 日志运维规范(排查溯源核心)
8.5.1 日志分类与作用
-
服务日志:节点启动、集群同步、权限校验、流控触发、故障报错日志
-
消息日志:消息投递、路由、消费、ACK、异常重试、死信流转日志
-
连接日志:连接创建、销毁、断连、重连、信道异常日志
-
审计日志:队列/交换机创建删除、权限修改、配置变更操作日志
8.5.2 生产日志规范
-
开启日志分级输出(INFO/WARN/ERROR),关闭冗余DEBUG日志
-
配置日志切割:按天切割、单文件最大200MB,保留15天日志
-
异常日志完整打印堆栈、messageId、队列名、路由键,便于精准溯源
-
禁止日志输出敏感数据(账号密码、订单明文、用户信息)
-
日志接入ELK,支持全局检索、链路追踪、异常统计
8.6 数据备份与恢复(零数据丢失保障)
8.6.1 备份范围
-
元数据备份:交换机、队列、绑定关系、用户权限、vhost配置(核心必备)
-
消息数据备份:核心业务堆积消息、死信队列异常消息
-
配置文件备份:集群参数、水位阈值、限流、权限配置文件
8.6.2 备份周期规范
-
元数据:每日凌晨自动全量备份,保留30天备份文件
-
配置文件:变更后立即手动备份,留存版本记录
-
异常消息:死信队列定时导出归档,长期留存用于问题复盘
8.6.3 故障恢复流程
-
集群配置丢失:导入最新元数据备份,自动恢复交换机、队列、绑定关系
-
异常消息丢失:通过归档死信消息、业务日志进行数据补偿
-
配置误改:回滚历史配置备份,重启节点生效
8.7 日常运维标准操作(SOP手册)
8.7.1 日常巡检SOP(每日必做)
-
核查集群节点全部在线,无分区、无离线、无同步异常
-
检查磁盘、内存、CPU资源使用率,无超阈值预警
-
核对核心队列无持续堆积、消费正常、死信无新增异常
-
查看连接、信道数量正常,无资源泄漏、异常暴涨
-
核查告警记录,处理遗留异常、消除预警隐患
8.7.2 版本升级SOP
-
采用滚动升级:逐个下线节点→升级版本→重启加入集群→同步完成再升级下一个
-
升级前备份全量元数据与配置文件
-
禁止集群多节点同时下线升级,避免集群不可用
-
升级后校验队列同步、消息收发、集群状态正常
8.7.3 配置变更SOP
-
所有核心参数变更必须先测试环境验证,再灰度生产
-
变更前备份配置,记录变更内容、时间、责任人
-
变更后持续观测10~30分钟监控指标,确认无异常
-
高危参数变更避开业务高峰期,选择低峰期操作
8.8 高频故障排查手册(生产秒排)
8.8.1 消息持续堆积
排查步骤:1.查看消费QPS是否为0,判断消费是否停滞;2.检查未ACK消息数,排查消费卡死、线程阻塞;3.核对prefetch参数、消费者线程池配置;4.查看消费异常日志,定位业务报错;5.检查集群流控、资源过载情况。
解决方案:修复消费异常、优化耗时逻辑、调优线程池与prefetch、清理卡死消息、重启异常消费者。
8.8.2 消息频繁丢失
排查步骤:1.检查消息/队列双持久化是否开启;2.核查mandatory+Return回调、Confirm回调是否配置;3.排查路由失败、无匹配队列场景;4.查看是否队列溢出、过期自动删除;5.核对服务端重启、节点故障记录。
解决方案:补全持久化配置、开启投递与路由兜底、优化队列溢出策略、完善消息过期兜底。
8.8.3 集群频繁断连重连
排查步骤:1.查看服务器防火墙超时策略;2.检查MQ内存磁盘水位是否触发流控;3.核对心跳超时参数配置;4.排查网络抖动、端口拦截问题;5.检查客户端连接池配置是否合理。
解决方案:优化心跳参数、关闭防火墙空闲连接回收、调优资源阈值、规范客户端连接复用。
8.8.4 死信队列持续暴涨
排查步骤:1.解析死信消息Header,确认死信触发原因(过期/拒绝/溢出);2.查看消费报错日志,定位业务异常;3.核对消息参数合法性、队列TTL配置;4.排查重试策略是否失效。
解决方案:修复业务bug、调整重试次数、优化消息过期时间、清理无效脏数据消息。
8.8.5 集群脑裂/节点分区
排查原因:网络分区、节点心跳超时、奇数节点缺失、集群参数异常。
解决方案:等待网络自动恢复、禁止手动强制合并、异常节点重启重新加入集群、优化心跳与分区容错参数。
8.9 生产运维高危禁忌(绝对禁止)
-
禁止业务高峰期重启集群节点、修改核心配置、升级版本
-
禁止手动清空生产队列堆积消息,无备份直接删除数据
-
禁止集群脑裂时手动强制恢复、强制重置节点,避免数据覆盖丢失
-
禁止关闭监控告警、关闭日志输出,故障无溯源依据
-
禁止随意修改内存、磁盘水位、流控、副本数核心参数
-
禁止直接kill -9暴力关停MQ进程,导致消息未落地、元数据损坏
8.10 运维巡检落地清单(可直接勾选)
-
已完整搭建 Prometheus+Grafana 监控体系,核心指标全覆盖
-
P0/P1/P2三级告警规则配置齐全,告警渠道正常可用
-
日志切割、归档、脱敏配置完成,支持异常溯源检索
-
元数据、配置文件定时自动备份,备份文件可正常恢复
-
集群滚动升级、配置变更、故障处理SOP落地执行
-
无长期持续堆积、无频繁死信新增、无异常断连重连
-
集群资源阈值、流控参数、分区容错参数配置合理
-
运维高危操作严格管控,无违规变更、暴力启停记录
九、Spring AMQP 专项(完整版·配置+注解+源码+避坑+落地)
Spring AMQP 是 Spring 生态对接 RabbitMQ 的标准框架,屏蔽了原生 AMQP 协议的底层复杂 API,提供自动化配置、注解驱动、消息封装、异常兜底、重试机制等高阶能力,是企业级 SpringBoot 项目接入 RabbitMQ 的唯一主流方案。本章节补全生产所有核心知识点、配置细节、注解详解、源码核心逻辑、高频坑点,适配开发落地、面试问答双场景。
9.1 Spring AMQP 核心优势(对比原生 API)
-
自动化配置:基于 SpringBoot 自动装配,无需手动创建 Connection、Channel、交换机、队列,通过注解和配置类即可完成全量初始化。
-
注解驱动开发 :提供
@RabbitListener、@RabbitHandler等核心注解,极简实现消息监听与消费,代码可读性极强。 -
内置可靠机制:原生支持消息重试、手动ACK、死信转发、Confirm/Return回调、异常拦截,无需手动封装底层逻辑。
-
统一消息封装:标准化 Message 消息体、消息转换器,统一序列化/反序列化规则,规避原生API数据解析错乱问题。
-
池化资源管理:内置连接池、信道池自动复用,杜绝连接泄漏、端口耗尽等原生API高频问题。
-
无缝适配Spring生态:完美整合 Spring 事务、IOC容器、AOP、日志体系,适配微服务全场景开发。
9.2 核心自动配置原理(面试必问)
9.2.1 核心自动配置类
-
RabbitAutoConfiguration:Spring AMQP 核心自动配置入口,项目启动自动加载MQ相关配置。
-
RabbitProperties :MQ配置属性绑定类,对应
spring.rabbitmq全局配置参数。 -
RabbitTemplate:消息发送核心模板类,封装所有投递、回调、序列化逻辑。
-
SimpleRabbitListenerContainerFactory:消费者容器工厂,统一管控消费者线程、ACK、重试、预取值等参数。
9.2.2 自动装配核心流程
-
项目启动读取
application.yml/properties中RabbitMQ连接、账号、vhost等配置。 -
自动创建
CachingConnectionFactory连接工厂,初始化连接池、信道池。 -
自动注入
RabbitTemplate,加载默认消息转换器、回调机制。 -
扫描项目中
@RabbitListener注解,自动注册消费者监听容器。 -
自动初始化声明配置类中定义的交换机、队列、绑定关系。
-
完成服务端链路绑定,开启消息收发监听。
9.3 核心注解全解(生产开发必备)
9.3.1 @RabbitListener(核心监听注解)
作用:标记方法为消息消费者,监听指定队列消息,是项目最常用核心注解。
核心属性详解:
-
queues:指定监听的队列名称(最常用),支持单队列、多队列监听。 -
queuesToDeclare:直接声明并绑定队列,无需单独配置类,适合简单临时队列。 -
exchanges:绑定交换机,搭配路由键实现动态监听。 -
key:绑定路由键,指定消息匹配规则。 -
containerFactory:指定自定义消费者容器工厂,适配差异化消费配置。
生产规范 :核心业务统一使用配置类声明队列、交换机,@RabbitListener 仅做监听,不做声明,统一管控资源。
9.3.2 @RabbitHandler(消息分发注解)
作用:基于消息体类型、Header参数实现方法级消息分发,同一队列不同类型消息匹配不同消费方法。
适用场景:同一队列接收多种业务消息(订单创建、订单支付、订单取消),按需分发处理。
使用规范 :必须与 @RabbitListener 搭配使用,统一监听队列,多方法通过参数类型区分消费逻辑。
9.3.3 @Retryable / @Recover(重试兜底注解)
-
@Retryable:标记消费方法支持重试,配置重试次数、间隔、异常类型。 -
@Recover:重试耗尽后触发的兜底方法,替代死信逻辑,适合轻量级异常兜底。
生产禁忌:核心业务禁止依赖该注解重试,优先使用MQ原生重试+死信队列,注解重试无消息状态管控,易引发重复消费。
9.4 消息转换器核心配置(解决序列化坑)
Spring AMQP 默认使用 JDK序列化 ,存在兼容性差、可读性低、跨语言不支持、反序列化异常等问题,生产必须全局替换为JSON序列化。
9.4.1 标准JSON转换器配置(可直接上线)
java
/**
* 全局消息转换器配置
* 统一JSON序列化,适配时间格式、未知参数兼容、跨服务解析
*/
@Bean
public MessageConverter jsonMessageConverter() {
MappingJackson2MessageConverter converter = new MappingJackson2MessageConverter();
ObjectMapper objectMapper = new ObjectMapper();
// 适配Java8时间类
objectMapper.registerModule(new JavaTimeModule());
// 时间格式化
objectMapper.setDateFormat(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
// 忽略未知字段,避免版本迭代字段增减导致反序列化失败
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
// 空对象不报错
objectMapper.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
converter.setObjectMapper(objectMapper);
return converter;
}
/**
* 注入RabbitTemplate,绑定全局转换器
*/
@Bean
public RabbitTemplate rabbitTemplate(CachingConnectionFactory connectionFactory, MessageConverter jsonMessageConverter) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setMessageConverter(jsonMessageConverter);
return rabbitTemplate;
}9.4.2 序列化生产避坑点
-
禁止默认JDK序列化,仅支持Java项目,跨语言、跨版本解析报错。
-
必须兼容Java8时间类型,否则LocalDateTime、LocalDate序列化异常。
-
必须开启忽略未知字段,适配业务实体类迭代新增/删除字段。
-
全局统一转换器,禁止生产者、消费者使用不同序列化规则。
9.5 消费者容器核心参数详解(生产调优核心)
SimpleRabbitListenerContainerFactory 是消费者的核心容器,所有消费规则、线程模型、重试机制均由此配置,直接决定消费性能与稳定性。
9.5.1 核心参数生产配置规范
-
acknowledgeMode :ACK模式,生产强制
MANUAL手动确认,杜绝自动ACK丢消息。 -
prefetch:预取值,常规业务配置10~20,耗时业务配置5~10,极速业务配置30~50,防止负载失衡。
-
concurrentConsumers:初始消费者线程数,基础并发能力,常规配置10~15。
-
maxConcurrentConsumers:最大消费者线程数,峰值扩容上限,常规配置20~30。
-
receiveTimeout:消费超时时间,默认30s,超长耗时业务可适当调大,避免无故重连。
-
batchSize:批量消费条数,非核心业务可开启批量,核心业务禁用。
9.5.2 线程池调优口诀
短耗时、高吞吐:调高prefetch+加大并发线程 长耗时、低吞吐:降低prefetch+适中并发,避免线程阻塞堆积 核心交易业务:小prefetch、稳并发,优先保证可靠性
9.6 重试机制深度解析(Spring AMQP专属)
9.6.1 两种重试模式对比
-
框架本地重试(RetryTemplate):消费异常后本地重试,不重回队列,重试耗尽后可兜底,性能较高,适合临时业务抖动异常。
-
MQ队列重试(Nack重回队列):消费失败Nack重回队列,配合死信队列兜底,数据持久化,可靠性最高,适合核心交易业务。
9.6.2 生产重试规范
-
核心业务:关闭框架本地无限重试,使用梯度次数重试+死信兜底,避免本地重试阻塞线程。
-
非核心业务:开启轻量本地重试,减少队列消息堆积,提升消费效率。
-
所有重试必须限制最大次数,杜绝无限重试死循环。
-
重试间隔采用梯度递增,避免高频重试冲击数据库与业务服务。
9.7 消息确认机制(Spring AMQP落地版)
9.7.1 三种ACK模式
-
AUTO(自动确认):消费方法执行完毕自动ACK,异常自动Nack,生产核心业务禁用,易丢消息、重复消费。
-
MANUAL(手动确认):手动调用basicAck/basicNack/basicReject,精准控制消息状态,生产唯一推荐。
-
NONE:关闭ACK机制,消息投递即删除,极致性能,仅适用于日志、埋点等极低可靠场景。
9.7.2 手动ACK生产标准逻辑
-
消费成功、业务处理完成、幂等校验通过 → basicAck 确认删除。
-
临时异常、网络抖动、数据库超时 → basicNack 重回队列重试。
-
参数非法、数据脏数据、重试耗尽 → basicReject 拒绝,转入死信队列。
9.8 异常处理全局方案
9.8.1 全局异常拦截器
通过 RabbitListenerErrorHandler 实现全局消费异常统一拦截,避免每个消费者重复写try-catch。
9.8.2 异常兜底分层策略
-
可重试异常:超时、网络抖动、数据库锁等待,触发梯度重试。
-
不可重试异常:参数错误、业务规则不通过、数据不存在,直接转入死信。
-
未知异常:记录全量日志、告警、消息存档,人工排查修复。
9.9 Spring AMQP 事务适配规范
Spring AMQP 支持本地事务,但生产绝对禁用原生MQ事务。
9.9.1 MQ原生事务弊端
-
事务阻塞严重,吞吐量暴跌90%以上,无法适配高并发场景。
-
仅支持单一信道事务,不支持跨服务、跨队列分布式事务。
-
异常回滚机制死板,无灵活兜底策略。
9.9.2 生产最终一致性方案
统一使用 Confirm异步确认 + 本地消息表 + 定时补发 实现分布式事务最终一致性,替代原生MQ事务,兼顾性能与可靠性。
9.10 批量消息处理规范
9.10.1 批量消费开启条件
-
仅高吞吐、非核心、可容忍少量数据异常的场景(日志、上报、统计数据)。
-
核心交易、订单、支付业务禁止批量消费,无法精准定位单条异常消息。
9.10.2 批量消费配置参数
-
batchListener:开启批量监听模式。 -
batchSize:单次最大消费条数(100~500)。 -
batchTimeout:批量等待超时时间(50~100ms),超时不足条数也触发消费。
9.11 Spring AMQP 高频坑点汇总(生产必避)
-
坑1:未全局替换JSON转换器,默认JDK序列化导致跨服务解析失败。
-
坑2:使用自动ACK,业务异常、服务宕机引发消息丢失、重复消费。
-
坑3:prefetch配置过大,单消费者堆积过多消息,集群负载失衡。
-
坑4:本地重试与MQ重试混用,导致消息无限重试、CPU爆满。
-
坑5:消费方法嵌套长耗时同步逻辑,引发ACK超时、消息重复消费。
-
坑6:未配置消息唯一ID,无法做幂等与链路溯源。
-
坑7:核心业务使用批量消费,异常无法精准定位,数据兜底困难。
-
坑8:依赖Spring事务实现MQ消息一致性,性能极差且存在数据风险。
-
坑9:多消费者容器参数不一致,导致集群消费能力不均、局部堆积。
-
坑10:未关闭默认重试策略,重试次数无限制,引发死循环消费。
9.12 Spring AMQP 生产落地巡检清单
-
全局替换JSON消息转换器,兼容时间类型、未知字段,无序列化异常
-
所有核心消费者开启手动ACK,彻底禁用自动ACK、NONE模式
-
消费者线程池、prefetch参数适配业务场景,负载均衡合理
-
重试机制规范化,核心业务使用死信兜底,无无限重试问题
-
所有消费业务实现幂等,支持重复投递无数据错乱
-
禁用MQ原生事务,采用Confirm+本地消息表实现最终一致性
-
批量消费仅用于非核心高吞吐场景,核心业务单条精准消费
-
全局异常拦截生效,消费异常可日志溯源、告警兜底
-
Confirm、Return回调完整配置,无投递、路由消息丢失风险
第十四部分 高频面试考点(背诵版)
-
消息队列的作用、RabbitMQ 整体架构与五大交换机区别
-
如何保证消息不丢失(生产者、服务端、消费者三端)
-
如何保证消息不重复消费(幂等方案)
-
死信队列的产生条件、使用场景、配置方式
-
两种延时队列实现方案对比、优缺点
-
Connection 和 Channel 区别,为什么建议多信道少连接
-
ACK 几种模式、basicReject 与 basicNack 区别、批量 ACK 风险
-
Confirm 三种模式、Return 机制与 mandatory 作用
-
普通集群、镜像队列、仲裁队列区别,脑裂成因与解决
-
消息堆积的原因、分类、排查与解决方案
-
RabbitMQ 流控机制、内存分页触发条件与危害
-
跨机房通信:联邦与 Shovel 插件区别与选型
-
RabbitMQ 如何实现分布式事务?本身是否支持分布式事务?
-
临时队列、独占队列使用场景
-
消息TTL、队列TTL 优先级与坑点