
.
个人主页: 晓风飞
专栏: 数据结构|Linux|C语言
路漫漫其修远兮,吾将上下而求索
文章目录
- 脑图
- [你的 exit(1) 去哪了?------进程等待与程序替换](#你的 exit(1) 去哪了?——进程等待与程序替换)
-
- 为什么必须等
- 一个整数里的两张脸
- [waitpid 怎么拿到退出信息的?](#waitpid 怎么拿到退出信息的?)
- [李四和张三:阻塞 vs 非阻塞](#李四和张三:阻塞 vs 非阻塞)
- 一次创建多个子进程,一次等完
- exec:你的代码被换了
- [fork 之后 exec](#fork 之后 exec)
-
- [什么程序都能 exec](#什么程序都能 exec)
- [exec 家族的命名术](#exec 家族的命名术)
-
- [execl 里为什么程序名传了两遍?](#execl 里为什么程序名传了两遍?)
- 环境变量是怎么传进去的
-
- 默认继承
- 自定义环境变量(execle)
- 追加环境变量(putenv)
- [命令行参数也是通过 exec 传的](#命令行参数也是通过 exec 传的)
- 事情就是这样
脑图
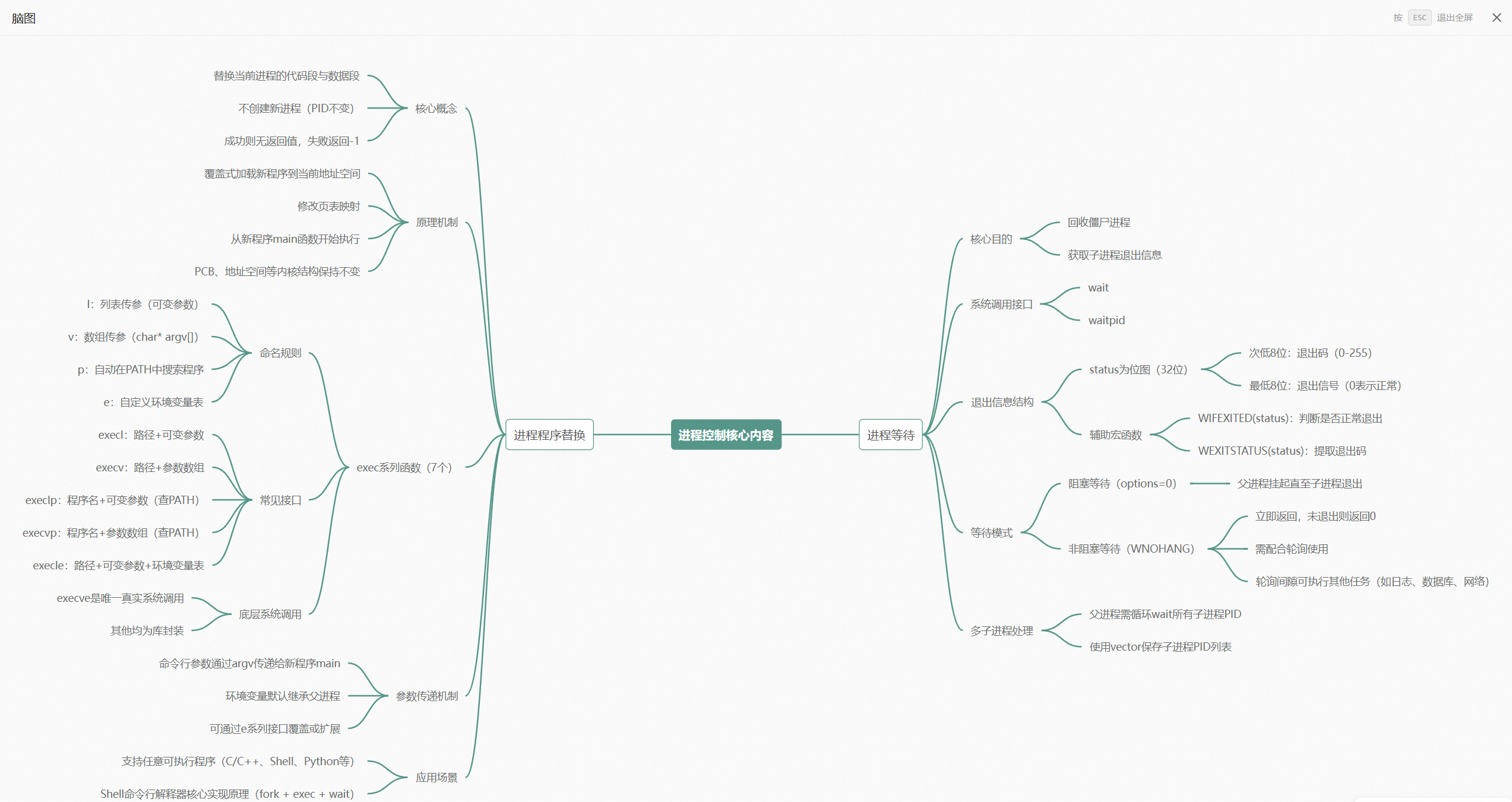
你的 exit(1) 去哪了?------进程等待与程序替换
c
// 子进程:我就退出,退出码设为 1
exit(1);
c
// 父进程:等到了!看看子进程的状态
pid_t rid = waitpid(id, &status, 0);
printf("wait success, pid = %d, status = %d\n", rid, status);wait success, pid = 114451, status = 256我明明写了 exit(1)。它给我的是 256。那个 1 藏到哪去了?
往下看。答案不复杂,但答案背后藏着整个进程等待的运作方式。
为什么必须等
先回到最基本的问题:父进程为什么要等子进程?
不是因为礼貌。是因为你不等就会有僵尸。
子进程退出时,它的尸体不会自己消失。内核必须保留它的 task_struct(PCB)------进程控制块------因为里面写着退出信息。如果父进程不来收尸,这块内存永远挂在进程表里。内存泄漏。这是刚需------必须解决。
第二个需求是获取子进程的退出信息。系统给你提供了接口,你可以拿,也可以不拿。但回收僵尸这件事不能不干。
waitpid 干两件事:回收僵尸,拿到退出信息。
现在我们来拆那个 256。
一个整数里的两张脸
status 是一个 32 位整数。但退出信息只用低 16 位,高 16 位直接不用。
高 16 位(不用) │ 次低 8 位(退出码) │ 低 8 位(退出信号 + core dump)低 8 位里,第 7 位是 core dump 标志(今天不讲,讲信号的时候再说),低 7 位是退出信号。如果进程正常结束------代码跑完了,没被 kill,没段错误------退出信号就是 0。
次低 8 位是退出码 。你写的 exit(1) 就是把 1 写进这里。
现在看 256 怎么来的:
退出码 1,二进制 00000001。放在次低 8 位,也就是 00000001 后面跟 8 个零。
一个 1 后面跟 8 个 0------1 00000000------等于多少?1 << 8 = 256。退出信号是 0。所以 status = 256 + 0 = 256。
拆开来看:2^8 = 2^7 × 2 = 128 × 2 = 256。
代码跑完了,退出码为 1。至于 1 是什么意思------你自己在写代码的时候定。你可以让 0 代表成功,1 代表参数错误,2 代表文件找不到,随便你定义。
反过来,如果 kill -9 杀掉了子进程:退出信号变成 9,退出码无意义(设为 0)。status = 0 + 9 = 9。
如果子进程里写了个除零:信号 8(SIGFPE,Floating Point Exception)。status = 0 + 8 = 8。
如果野指针写空地址(int *p = NULL; *p = 100;):操作系统不准你往空地址写入,信号 11(SIGSEGV,Segmentation Fault)。status = 0 + 11 = 11。
所以父进程通过两个数字判断子进程的命运:退出码告诉你结果是什么(正常时),退出信号告诉你它是怎么死的(异常时)。 退出信号没有编号 0------0 表示运行过程中没有出错,非 0 表示运行过程中进程出问题了。
手动提取退出码和退出信号
c
int exit_code = (status >> 8) & 0xFF; // 右移 8 位,取低 8 位
int exit_signal = status & 0x7F; // 0x7F = 01111111,取低 7 位有人问:对 status 做 >> 8,status 本身的值会变吗?不会。只有写 status = status >> 8 才会改变它。你没有赋值,status 还是原来的值,右移操作只是产生了一个临时结果。
退出码只有 8 位,取值范围 0--255。别写 exit(256)------它会被截断。任何进程退出最多 256 种情况(0--255 共 256 个数字)。
用宏提取
每次手动位移不现实。系统给了宏:
c
if (WIFEXITED(status)) {
// 正常退出:退出信号为 0
printf("子进程正常退出,退出码 = %d\n", WEXITSTATUS(status));
} else {
// 异常退出:退出信号非 0
printf("子进程出异常了,请注意\n");
}WIFEXITED 就是检查退出信号是不是 0------底层做的事和你手动 status & 0x7F == 0 一模一样。WEXITSTATUS 帮你把次低 8 位移回来------底层就是 (status >> 8) & 0xFF。宏的存在不是为了魔法,只是让你不用每次自己写位操作。
waitpid 怎么拿到退出信息的?
子进程退出时,会把退出信息写在自己的 task_struct 里,同时把自己设为 Z 状态(僵尸)。
打开内核源码,看 task_struct:
c
struct task_struct {
// ...
int exit_code;
int exit_signal;
// ...
};子进程退出时,退出码和退出信号就存在这。waitpid 的本质是什么?你去检查自己的子进程列表,看子进程的 task_struct 状态是不是 Z。如果是 Z,就把 task_struct 里的退出信息拷贝到用户空间的 status 变量里。和 getpid()、getppid() 一样------从内核数据结构拷贝数据到用户空间。
如果子进程还没退(不是 Z 状态),那就看你传入的第三个参数:0 就阻塞等,WNOHANG 就立刻返回 0。
重点:子进程的退出信息只能通过 waitpid 拿,不能通过全局变量。 因为有写时拷贝------子进程和父进程的地址空间是隔离的,子进程改不了父进程的全局变量。
李四和张三:阻塞 vs 非阻塞
现在我们知道怎么取退出信息了。但等的方式不止一种。
第一幕:阻塞等待------电话不准挂
快考试了。李四听说张三笔记做得好。李四跑到张三楼下打电话。
"张三,下来帮我复习 C 语言,我请你吃饭。"
张三说:"行,但我还在看书,大概十分钟后下来。你等我。"
李四说:"张三,别挂电话。 电话放旁边,你去看书。我就在楼下听着。你下楼了告诉我,再挂。"
然后李四就站在楼下,耳朵贴在手机上,什么也不干。张三不下楼,李四不动。全心全意地听电话那头的一举一动。
这就是阻塞等待 。waitpid(id, &status, 0)------第三个参数是 0。函数不返回,直到子进程退出。父进程卡在那,形同石化。
第二幕:非阻塞轮询------打一次挂一次
第一种等法太蠢了------谁愿意傻站着什么都不干?
李四换了个策略。打完第一个电话,张三说"等我十分钟",李四说"好的",把电话挂了。然后他在楼下刷手机、翻翻书、看看别人打球。过一会儿,又打一个:"好了没?""还没呢。""行。"挂掉。再过一会儿,又打。如此反复。最后张三说:"好了,我正在下楼,已经看到你了------你在树底下穿了个红色上衣。"
(其实李四穿的是蓝色上衣------电话沟通总有误差,但这不重要。)
这就是非阻塞轮询 。waitpid(id, &status, WNOHANG)------WNOHANG 的意思是"别 hang 住"。"hang" 就是你程序卡住了,动不了。子进程还没退?函数立刻返回 0,不卡。打一次电话(一次系统调用),问一次状态,没好就立刻返回。过一会儿再打。打很多次------这叫轮询。每次打完电话到打下一次电话之间,李四可以做自己的事。
c
while (1) {
pid_t rid = waitpid(id, &status, WNOHANG);
if (rid > 0) {
// 等到了
printf("wait success, pid = %d\n", rid);
break;
} else if (rid == 0) {
// 子进程还没退,立刻返回
printf("子进程还没退,继续轮询......\n");
usleep(10000); // 歇 10 毫秒再问
} else {
// 出错了 (rid == -1)
printf("wait failed\n");
break;
}
}注意:因为 CentOS 上进程调度的行为有时候比较奇怪,不加 usleep 的话父进程可能忙等太久,加一点延迟让子进程有机会跑。
WNOHANG 让 waitpid 的返回值变成了三种:
| 返回值 | 含义 |
|---|---|
| > 0 | 等待成功,返回子进程 PID |
| 0 | 子进程还没退,立刻返回(非阻塞特有) |
| -1 | 出错了(比如等的 PID 根本不存在) |
如果没有 WNOHANG,返回值只有 > 0 和 -1------阻塞等待不等到结果不回来,不可能返回 0。
间隙里塞任务
两次非阻塞检测之间,父进程是自由的。你不会真的在楼下发呆------你做点别的事。
c
typedef void (*task_t)();
void print_log() { printf("我要打印日志\n"); }
void sync_db() { printf("我要访问数据库\n"); }
void download() { printf("我要下载核心数据\n"); }
task_t tasks[] = {print_log, sync_db, download};
// 在轮询循环里,每次检测返回 0 的时候:
for (int i = 0; i < 3; i++) {
tasks[i]();
}打印日志、同步数据库、下载数据------每次 wait 返回 0(子进程没好),父进程就把三个任务跑一圈,然后再去问一次。李四打完电话、挂掉、玩会儿手机、翻会儿书、再打------一模一样。
有些同学会说:你不是可以放一个 while 循环直接在外面一直调这些任务吗?对,但那和这里想表达的不是一回事。这里的重点是:非阻塞轮询给了你在等子进程的间隙做其他工作的能力。 你不需要专门为了做任务而做任务,你是在"等"的过程中顺手把事干了。
最佳实践:后续写代码,如果不加特殊说明,统一用阻塞等待就够了。非阻塞轮询虽然灵活,但多数场景不需要。不过你得知道它存在------因为 Bash 这种交互式程序底层就在非阻塞地做事,它不能卡住,还得响应你的键盘输入。
第三幕:阻塞的回归
考完 C 语言,有惊无险刚好 60 分。李四正在洋洋得意,突然听到旁边同学说:"明天还要考操作系统。" 李四傻了。
他又火急火燎跑到张三楼下。这次他选择了阻塞------"张三,电话不准挂,我就听着。"因为他知道张三一定会下来,而且他很急,不想分心,就想第一时间知道张三下楼了。
阻塞和非阻塞没有绝对的优劣。看场景。阻塞简单省心,非阻塞灵活但要多写循环。后面写代码默认用阻塞,需要的时候再切非阻塞。
一次创建多个子进程,一次等完
到目前为止都是创建一个等一个。实际场景里你可能会一次性创建一批子进程,然后逐个回收。
cpp
#include <iostream>
#include <vector>
#include <unistd.h>
#include <sys/wait.h>
const int g_num = 5; // 创建 5 个子进程
void work() {
int cnt = 5;
while (cnt > 0) {
printf("我是子进程 pid=%d, cnt=%d, 工作中......\n", getpid(), cnt);
sleep(1);
cnt--;
}
}
int main() {
std::vector<pid_t> subs;
for (int i = 0; i < g_num; i++) {
pid_t id = fork();
if (id < 0) {
// 创建失败,父进程直接退出
exit(1);
} else if (id == 0) {
// 子进程:干活,干完立刻退出,绝不往后走
work();
exit(0);
} else {
// 父进程:记下这个子进程的 PID
subs.push_back(id);
}
}
// 只有父进程会走到这里------所有子进程在 work() 之后直接退出了
// 父进程必须把所有子进程全部等完
for (auto &sub : subs) {
int status;
pid_t rid = waitpid(sub, &status, 0); // 阻塞等待每一个
if (rid > 0) {
if (WIFEXITED(status)) {
printf("子进程 %d 正常退出, exit code = %d\n",
rid, WEXITSTATUS(status));
} else {
printf("子进程 %d 异常退出\n", rid);
}
}
}
return 0;
}关键细节:
fork之后代码共享,子进程走到work()之后必须exit(0)直接退出,否则它会继续跑for循环------子进程再去fork就乱套了。进来时只有一个父进程在跑for循环,走到fork时只有父进程继续循环,子进程被分流去干活。- 父进程用
vector<pid_t>保存所有子进程的 PID。把子进程管理起来------对 vector 的增删查改就是对子进程的管理。后面甚至可以封装成类。 - 如果 5 个子进程里 4 个退了 1 个没退?父进程就在
waitpid那里阻塞等着------必须把全部子进程等完,父进程才能退出。 - C++ 调用 C 的系统调用是混编:
fork、waitpid这些函数是 C 的,返回值用pid_t是 C 的类型。C++ 里用vector管理它们就是 C++ 自己的事。后面字符串处理会比较恶心------比如exec的参数传递------但先打个预防针。
exec:你的代码被换了
上面所有的代码有一个共同的假设:子进程跑的是和父进程同一份代码 。fork 之后父子共享代码段,靠 if (id == 0) 分岔走不同分支。
但如果子进程想跑一个完全不同 的程序呢?比如 ls?比如 top?比如你自己写的另一个可执行文件?
先看效果,再讲原理
c
#include <unistd.h>
#include <stdio.h>
int main() {
printf("我是进程,pid = %d\n", getpid());
execl("/usr/bin/ls", "ls", "-a", "-l", NULL);
printf("我要退出了......\n");
return 0;
}编译,运行:
我是进程,pid = 23626
total 32
drwxr-xr-x 2 user user 4096 Jun 3 10:00 .
drwxr-xr-x 10 user user 4096 Jun 3 09:50 ..
-rw-r--r-- 1 user user 1024 Jun 3 10:00 my_exec.c"我要退出了......" 去哪了?
没了。 execl 成功的那一瞬间,当前进程的代码段和数据段被 ls 的代码和数据全部覆盖 了。execl 后面的 printf 是旧程序的代码------它在新程序的地址空间里根本不存在,所以永远不会执行。
exit() 也没有返回值------因为进程一旦终止就不会往后运行了。execl 也一样:调用成功就不返回,失败了才会返回 -1。这是一个正确的代码写法:
c
execl("/usr/bin/ls", "ls", "-a", "-l", NULL);
exit(1); // 只有 execl 失败才会走到这里如果你想让 execl 失败一次看看效果,把程序名写错:
c
execl("/usr/bin/lssss", "lssss", "-a", "-l", NULL); // 这个程序不存在运行后"我要退出了"就打印出来了------因为替换失败,execl 返回 -1,程序继续往下走。
替换原理
这就是进程程序替换。同一个进程壳子------task_struct 不变,地址空间结构不变------但代码段和数据段被换成了另一个程序的。修改页表映射,然后把 CPU 的指令指针指向新程序的入口(main 函数),从头开始跑。
如果要画图:磁盘上有一个 ls 的二进制文件。execl 把它加载进内存,覆盖当前进程的代码、数据、堆、栈,修改页表里虚拟地址到物理地址的映射关系,然后进程从新程序的 main 处重新开始执行。
不创建新进程。 怎么证明?你在 execl 前面打 getpid(),替换进去的程序里也打 getpid()------两个 PID 一模一样。后面马上证明。
先有 PCB 还是先有代码?
一个反直觉的结论:操作系统创建一个进程时,先创建内核数据结构(task_struct、地址空间、页表),后面再按需加载代码和数据。 就像你高考被录取之后,人还没到学校,档案已经提走了------在暑假期间你已经是那个大学的学生了。
今天 exec 的存在恰好证明了这一点:进程(PCB + 地址空间 + 页表)已经在那了,代码和数据没加载的时候,exec 可以随时换上新的。如果先有代码才有进程,就不可能发生"替换"这种事。
fork 之后 exec
单进程自己替换自己没什么实际用处------你把自己换成了 ls,原来的程序就没了。真正有价值的是 fork + exec:
c
pid_t id = fork();
if (id == 0) {
// 子进程
printf("子进程 pid = %d,即将替换为 ls\n", getpid());
sleep(1); // 让你看清楚
execl("/usr/bin/ls", "ls", "-a", "-l", NULL);
exit(1); // 只有 execl 失败才会走到这里
}
// 只有父进程走到这里
int status;
pid_t rid = waitpid(id, &status, 0);
if (rid > 0) {
printf("wait child success\n");
}fork 之后子进程和父进程共享代码和数据。但一旦子进程调用 execl,要加载全新的程序------这时候写时拷贝全面触发。代码段、数据段全部和父进程分离,子进程从头建立自己的页表映射。父进程完全感知不到------进程独立性。
这,就是 Bash 的核心逻辑。
你在命令行敲 ls -a -l。Bash 做了什么?
fork()一个子进程- 子进程
execl("/usr/bin/ls", "ls", "-a", "-l", NULL) - 父进程
waitpid()等子进程跑完,拿到退出信息 - 回到第 1 步,打印下一个提示符,等你输入
当然真正的 Bash 比你想象的多做了很多事------管道、重定向、信号处理、作业控制------但骨架就是 fork → exec → wait。下节课我们会自己搓一个简易 shell------几百行代码的事。
什么程序都能 exec
不是什么 C 语言特殊------在 Linux 上,任何跑起来的东西最终都是一个进程。
c
// 执行 top,每 1 秒刷新,共 3 次
execl("/usr/bin/top", "top", "-d", "1", "-n", "3", NULL);
// 执行 Python 脚本
execl("/usr/bin/python3", "python3", "test.py", NULL);
// 执行 Shell 脚本
execl("/usr/bin/bash", "bash", "test.sh", NULL);
// 执行你自己写的 C++ 程序
execl("./my_proc", "my_proc", "-a", "-b", NULL);每个语言最终要么被编译成二进制(C、C++、Rust、Go),要么被一个二进制解释器边读边跑(Python 的 python3、Bash 的 bash、Java 的 java)。解释器本身就是一个 C/C++ 写的进程。 你 exec 解释器进程,把脚本路径作为命令行参数传进去,解释器进程起来之后读脚本、解析、执行。所以你只要有一个二进制程序的路径,就能用 exec 让它跑起来。和语言无关。
exec 家族的命名术
execl 只是入口。一共七个函数,但有一个是真正的系统调用,其他六个全是库函数封装。命名规则就四个字母:
| 字母 | 含义 | 例子 |
|---|---|---|
| l (list) | 参数以可变参数列表传入,NULL 结尾 |
"ls", "-a", "-l", NULL |
| v (vector) | 参数以指针数组传入,数组最后必须是 NULL |
char *argv[] = {"ls", "-a", "-l", NULL} |
| p (path) | 自动在 PATH 环境变量里找可执行文件,不用写完整路径 | execlp("ls", ...) |
| e (environment) | 自己传环境变量表,不用系统默认的 | execle(..., env) |
排列组合就是五个库函数加一个系统调用:
c
// ===== 不带 p(需要完整路径),l 传参 =====
execl("/usr/bin/ls", "ls", "-a", "-l", NULL);
// ===== 不带 p,v 传参 =====
char *argv[] = {"ls", "-a", "-l", NULL};
execv("/usr/bin/ls", argv);
// ===== 带 p(自动找 PATH),l 传参 =====
execlp("ls", "ls", "-a", "-l", NULL);
// ===== 带 p,v 传参 =====
execvp("ls", argv);
// ===== 带 e(自定义环境变量),l 传参 =====
char *env[] = {"HOME=/myhome", "PATH=/usr/bin", NULL};
execle("/usr/bin/ls", "ls", "-a", "-l", NULL, env);
// ===== 带 e,v 传参:这才是真正的系统调用 =====
execve("/usr/bin/ls", argv, env);只有 execve 是系统调用。 它在 man 手册第 2 节。其他五个在 man 手册第 3 节------它们是 C 库函数的封装,底层全部调 execve。
为什么需要这么多封装?因为不同场景下参数来的形式不一样。有时候你的参数在一个数组里(比如解析命令行得到的 argv),就选 v。有时候程序在 PATH 里,就选 p------省掉路径。有时候你想从零搭建环境变量,就选 e。不传 e 的版本,底层自动把 extern char **environ 传给 execve。
execl 里为什么程序名传了两遍?
c
execl("/usr/bin/ls", "ls", "-a", "-l", NULL);
// 第一个 ls↑ 第二个 ls↑第一个 "/usr/bin/ls" 代表的是:我想执行谁------在哪能找到它。 这是 path 参数,带路径的。
第二个 "ls" 代表的是:我想怎么执行------命令行上怎么写。 这是 argv0,和你敲命令一样。
它们逻辑上不重复。第一个解决"找到程序",第二个解决"告诉程序你叫什么名字"。有些程序会根据 argv[0] 的不同表现不同行为(比如 busybox)。你省略第二个或者写错它,有时候也能跑------因为 execl 内部的实现做了容错,能从 path 推出来。但不推荐省略,思路清楚最重要:想执行谁 + 想怎么执行。
环境变量是怎么传进去的
任何一个 C/C++ 程序的 main 函数除了能接命令行参数,还能接环境变量:
c
int main(int argc, char *argv[], char *env[]) {
// 打印命令行参数
for (int i = 0; i < argc; i++) {
printf("argv[%d] = %s\n", i, argv[i]);
}
// 打印环境变量
for (int i = 0; env[i]; i++) {
printf("env[%d] = %s\n", i, env[i]);
}
}默认继承
如果你用不带 e 的 exec(execl、execv、execlp、execvp),不传环境变量------子进程依然有环境变量。哪来的?
因为不带 e 的库函数在内部调用 execve 时,自动把全局变量 extern char **environ 传了进去。这个指针指向当前进程从 Bash 一路继承下来的环境变量表。
c
// 不需要显式声明这个变量,但你可以声明它来直接访问
extern char **environ;自定义环境变量(execle)
如果你用带 e 的版本(比如 execle),你自己传一张环境变量表:
c
char *my_env[] = {
"HAHA=hehe",
"HOME=/myhome",
"PATH=/usr/bin",
NULL // 表必须以 NULL 结尾
};
execle("./my_proc", "my_proc", "-a", "-b", NULL, my_env);传了这张表之后,系统默认的环境变量就完全不用了------全部替换。 这是"自定义",不是"追加"。子进程拿到的环境变量就是你这几张,原来的 HOME、USER、PATH 全没了(除非你自己写进去)。
追加环境变量(putenv)
如果你既想保留默认的,又想加几个新的:
c
#include <stdlib.h>
// putenv 把键值对写进 environ 指向的那张表
putenv("MY_KEY=my_value");
putenv("CLASS=118");
// 然后用不带 e 的 exec------新变量已在 environ 里了
execl("./my_proc", "my_proc", NULL);putenv 修改的是当前进程的 environ 表。之后即使不用带 e 的 exec,子进程也能拿到新增的变量。注意 putenv 的参数是 char *------环境变量可以被修改,正式写代码时应该用 malloc 或 new 分配空间,不要传字符串常量。
命令行参数也是通过 exec 传的
你在 execl 里写的 "-a", "-l" 这些选项,最终会通过操作系统内部机制传递给新程序的 main 函数的 argv。换句话说------你程序里 main 函数的 argc 和 argv 是哪来的?是 exec 系列函数传进来的,最终由操作系统的加载器在启动程序时填入。
事情就是这样
回到开头。exit(1) 变成 256 不是因为计算错误------是因为退出信息被压进了一个 16 位的位图。次低 8 位是退出码,低 7 位是退出信号。1 在次低 8 位,就是 256。这个设计不优雅,但它紧凑------一个整数装下了一个进程最后的全部信息:它是正常跑完的(退出码),还是被杀掉的(退出信号),还是自己崩溃的(退出信号)。
李四终于在楼下等到了张三。张三抱着笔记本下来了------阻塞等待结束。两个人去自习室复习。考完 C 语言 60 分压线及格。然后又听说要考操作系统------李四又跑回楼下,但这次他学聪明了,不傻等,打完电话就刷手机,非阻塞轮询。
你下次打开终端敲命令的时候,窗口后面发生的事情和楼下的一幕一模一样:Bash fork 一个子进程,子进程 exec 你的命令,Bash 等它跑完,拿到退出状态,然后打印下一个提示符。周而复始。
下次课我们就把这个循环写出来。几百行代码,一个能跑的命令行解释器。