在分布式架构与多系统协同的业务场景下,定时任务已是后台系统不可或缺的功能,数据统计、日志清理、业务结算、服务监控等核心工作都依赖定时任务自动执行。但目前不少团队存在一个普遍问题:大量定时任务集中设置在整点触发。随着系统交互愈发频繁、服务依赖不断加深,定时任务扎堆整点运行,极易引发服务器资源拥堵、服务卡顿、任务执行失败等一系列故障。因此,规范定时任务执行时间、主动避开整点时段,成为保障整体系统平稳运行的关键举措。
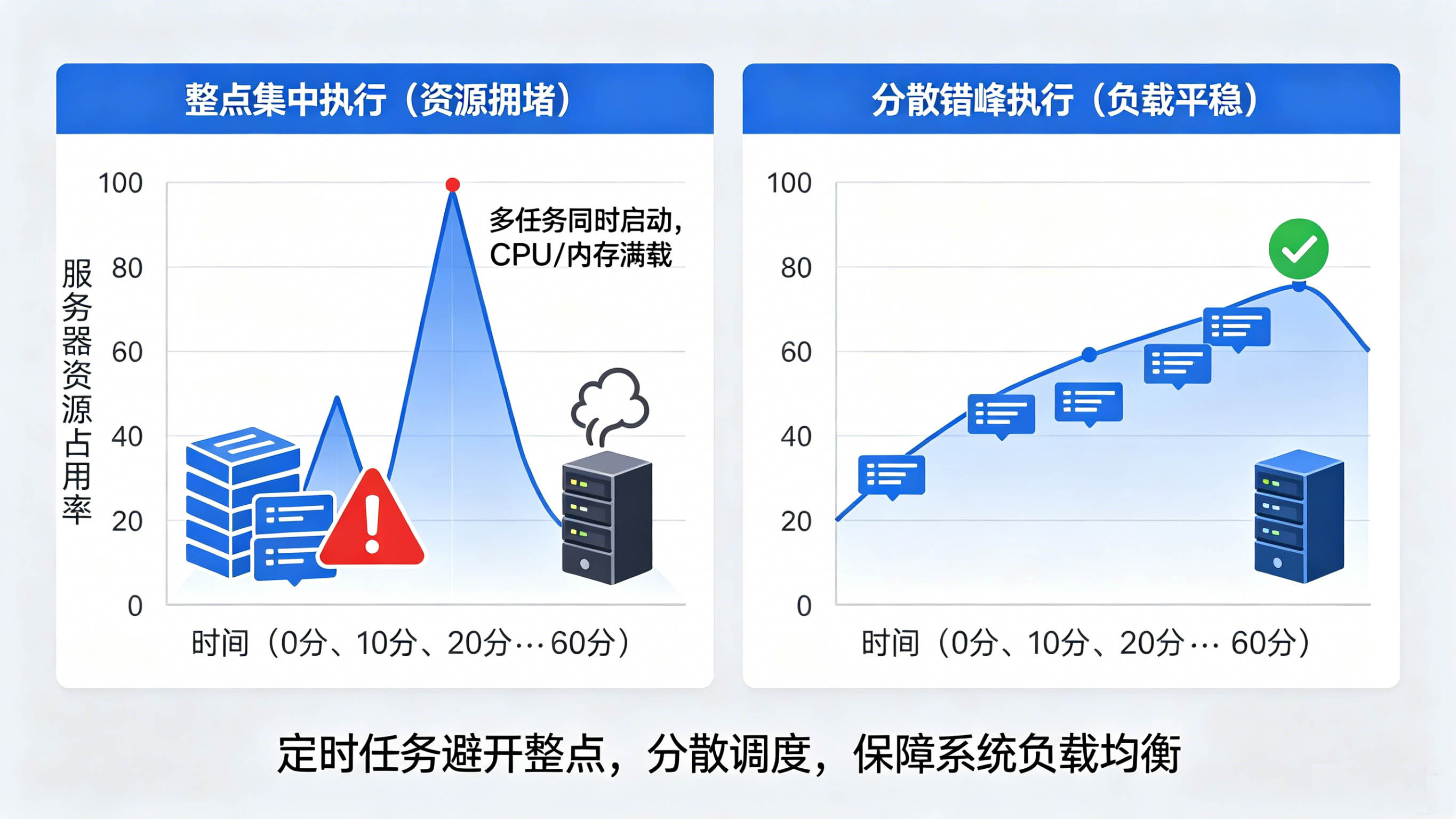
多数企业的业务服务器采用虚拟化部署模式,单台物理机往往会划分出多台虚拟机对外提供服务。出于硬件利用率与成本考量,物理资源普遍采用资源超卖策略,即分配给所有虚拟机的总资源,会超出物理机实际硬件配置。定时任务大多属于高资源消耗型操作,运行过程中会大量占用 CPU、内存、磁盘 IO 以及网络带宽。若多个业务系统的定时任务统一在 0 分、30 分等整点集中启动,海量计算、读写请求会瞬间涌向服务器,虚拟机之间相互抢占资源,直接造成服务器负载飙升、响应延迟,轻则正常业务请求处理变慢,重则出现任务中断、服务假死,影响全链路业务运转。
除了资源挤占问题,服务器运维动作也需和整点定时任务错峰。日常运维中,服务器会因版本更新、故障修复、安全补丁等需求执行自动重启、批量重启操作。若重启时间恰逢整点,一方面正在运行的定时任务会被强制终止,导致数据统计不全、业务流程中断,需要人工二次补跑任务,增加运维工作量;另一方面,服务器重启后刚完成服务初始化,系统资源尚未恢复平稳,整点大批量任务立刻启动,会让刚重启的服务器瞬间承压,大幅提升启动失败、服务异常的概率,给线上系统埋下安全隐患。
定时监控类任务是踩中整点高峰的重灾区。很多运维人员为了配置简便,会将巡检、状态监测、告警检测等任务设置为每 10 分钟执行一次,常用 Cron 表达式为
*/10 * * * * /path/to/your/command
该表达式代表每整 10 分钟触发一次,执行节点固定为 0 分、10 分、20 分、30 分、40 分、50 分。这类高频监控任务本身数量多、覆盖范围广,再叠加整点的结算、统计类任务,会让整点时段的服务器压力呈指数级增长。看似简单通用的配置方式,实则是系统稳定性的潜在风险点。
想要解决定时任务扎堆问题,核心思路就是错峰分配、分散执行。针对固定周期任务,可人为偏移执行时间,比如将原本整点执行的报表任务延后 3~8 分钟启动;对于每 10 分钟执行的监控任务,可调整 Cron 表达式,改为每 10 分钟从第 3 分钟开始执行,打破整点集中执行的惯例。同时,团队可统一梳理全平台定时任务清单,按照业务重要程度、资源消耗等级划分时段,将高消耗任务、高频监控任务、普通运维任务均匀分布在不同分钟区间,避免同一时间窗口内任务密集触发。
定时任务的时间配置看似是微小细节,却直接关系到整个服务集群的运行质量。摒弃 "默认整点执行" 的惯性思维,合理错峰调度,既能充分利用服务器资源,又能从源头规避资源瓶颈与运维风险,让各类自动化任务稳定、高效地运转,为业务系统筑牢底层保障。