论文标题:NetLLM: Adapting Large Language Models for Networking
会议:ACM SIGCOMM 2024
关键词:LLM、网络优化、多模态编码器、数据驱动 RL、参数高效微调
0. 写在前面
这篇论文是我在"基于大模型的意图驱动网络管理"研究方向上的第一篇深度精读。读完之后最大的感受是:顶会论文不仅技术扎实,叙事逻辑也极其清晰------从问题出发,拆解挑战,再逐一给出解决方案,最后用充分的实验证明效果。本文记录了我的完整阅读笔记,包括背景、挑战、方法设计、实验总结以及个人思考,希望能帮助同样对 LLM + Networking 感兴趣的同学。
1. 背景与动机
1.1 传统网络算法的演进
- 规则驱动算法(如 Copa、PANDA):依赖人工设计规则,工程成本高。
- 学习驱动算法(DL + DNN):通过监督学习(SL)或强化学习(RL)自动发现网络解决方案。
1.2 现有学习算法的两大痛点
- 高模型工程成本:每个任务需要手工设计专用 DNN,无法复用。
- 泛化能力差:在未见过的数据分布/环境中性能下降严重。
1.3 LLM 带来的新机遇
LLM(如 Llama2、OPT)具有预训练知识和涌现能力(规划、模式挖掘、推理),有潜力成为网络领域的 "基础模型" ,实现 "一个模型解决所有任务"。
1.4 将 LLM 直接用于网络管理的三大挑战
| 挑战 | 描述 |
|---|---|
| 输入模态不对齐 | 网络数据是多模态的(时序、图像、标量、图结构),LLM 只认文本 |
| 生成效率低且不可靠 | 自回归生成延迟高,且可能出现幻觉(生成无效答案) |
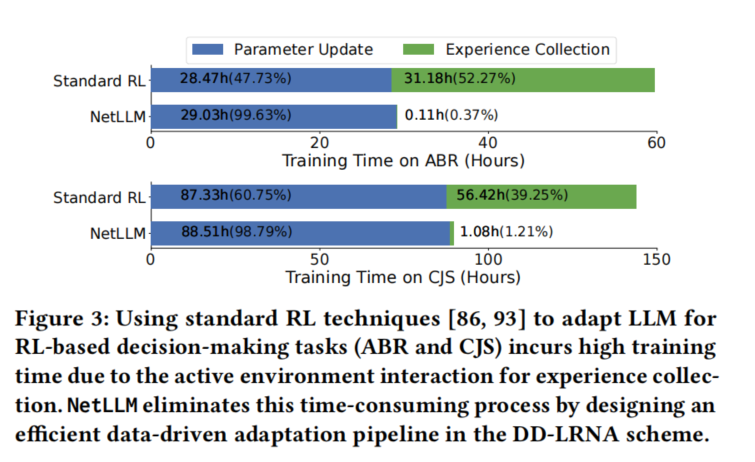
| 微调成本极高 | 尤其是 RL 决策任务,在线交互时间不可接受;全参数微调显存占用大 |
2. NetLLM 框架总览
NetLLM 是一个 "冻结 LLM 主体 + 适配外围模块" 的通用框架,三个核心模块分别对应上面三个挑战。
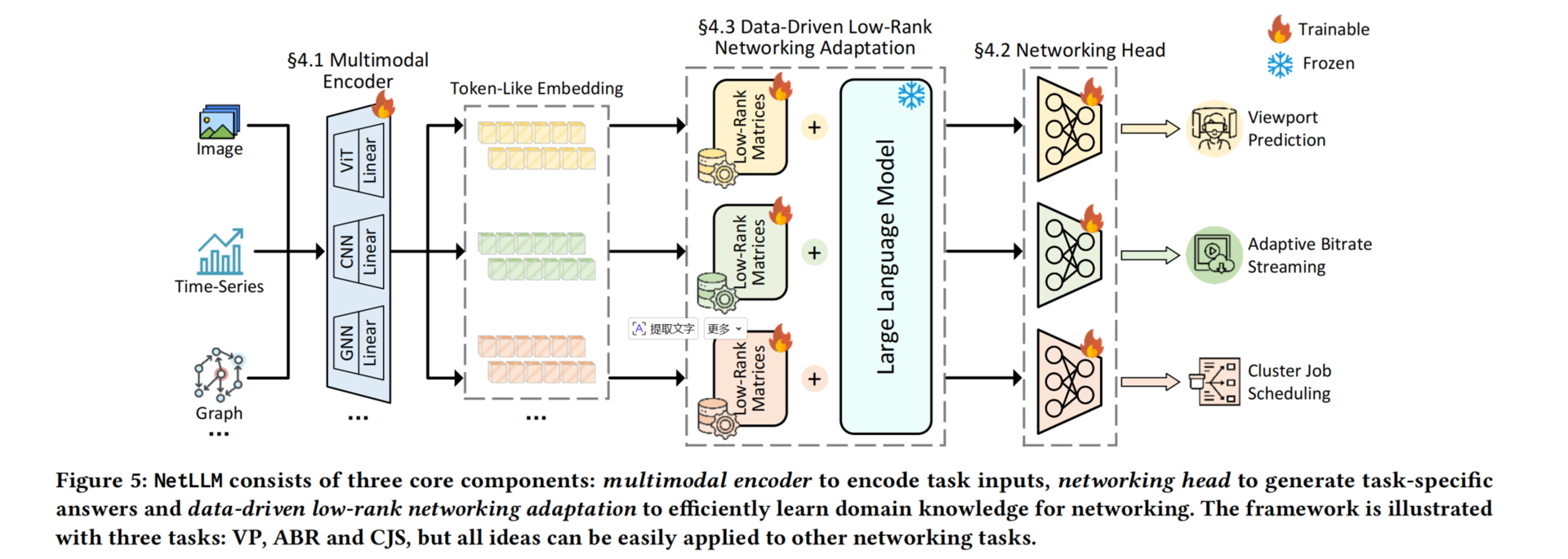
3. 三大核心模块详解
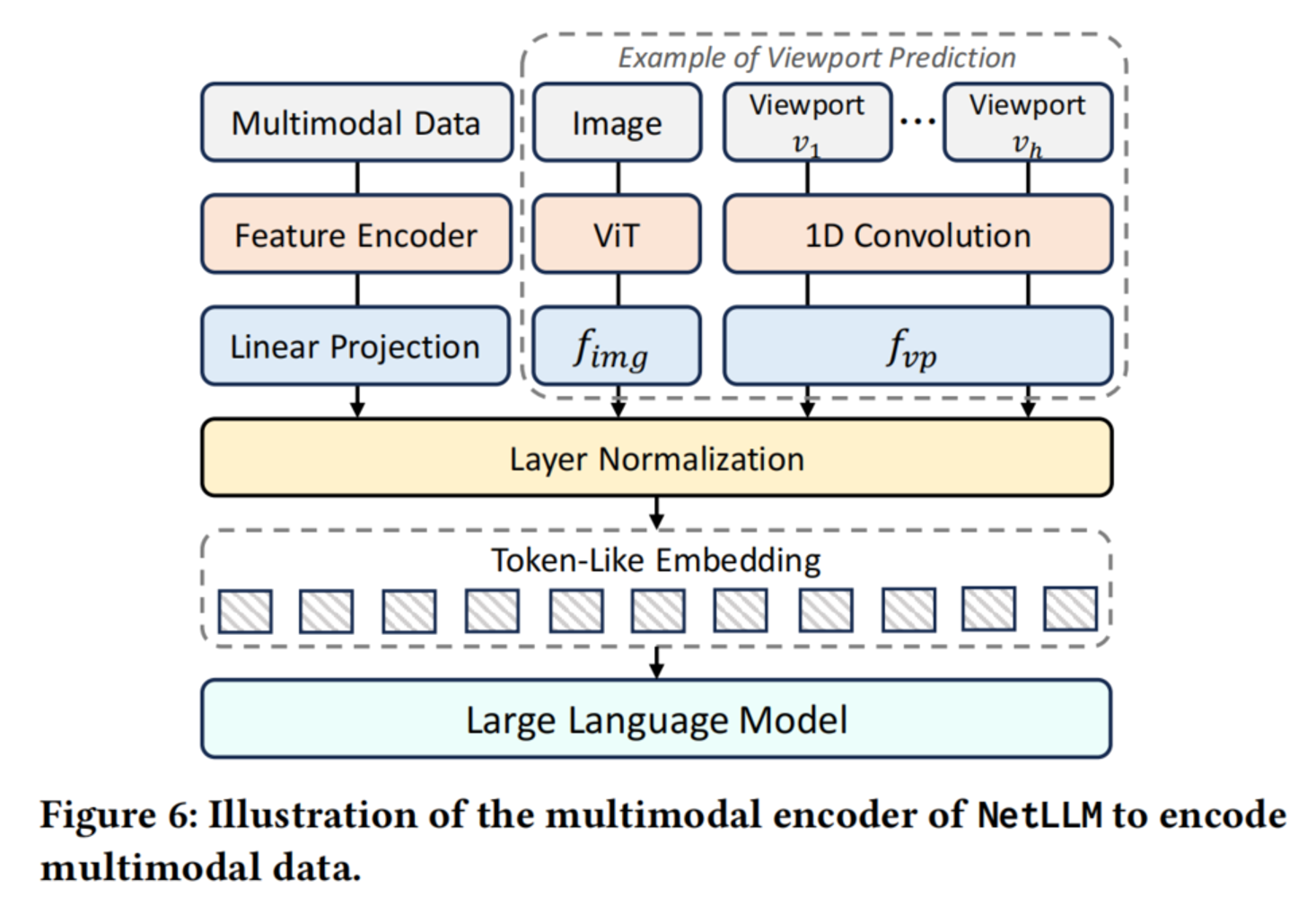
3.1 多模态编码器(解决输入不对齐)
设计思想:就像用"充电线+转接插头"把不同设备接到同一个电源。
- 特征编码器 (各类充电线):复用现有优秀编码器
- ViT → 图像
- 1D-CNN → 时序/序列
- 全连接层 → 标量
- GNN → 图(DAG)
- 线性投影 + LayerNorm(转接插头):将不同维度的特征统一映射到 LLM 的 token 空间。
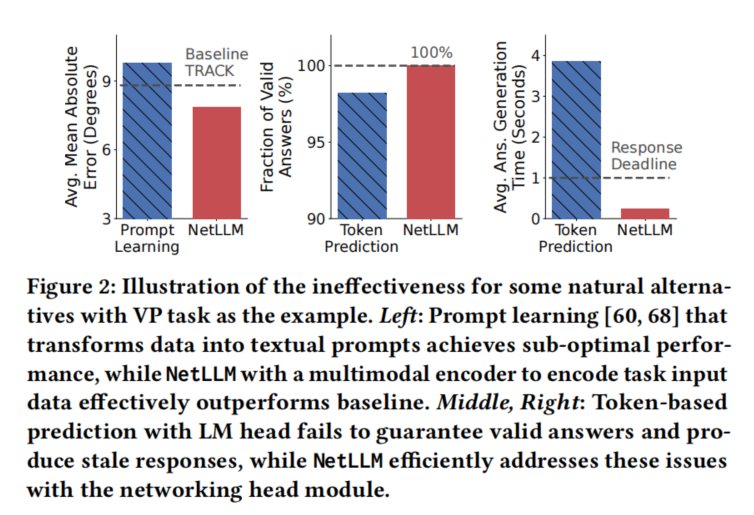
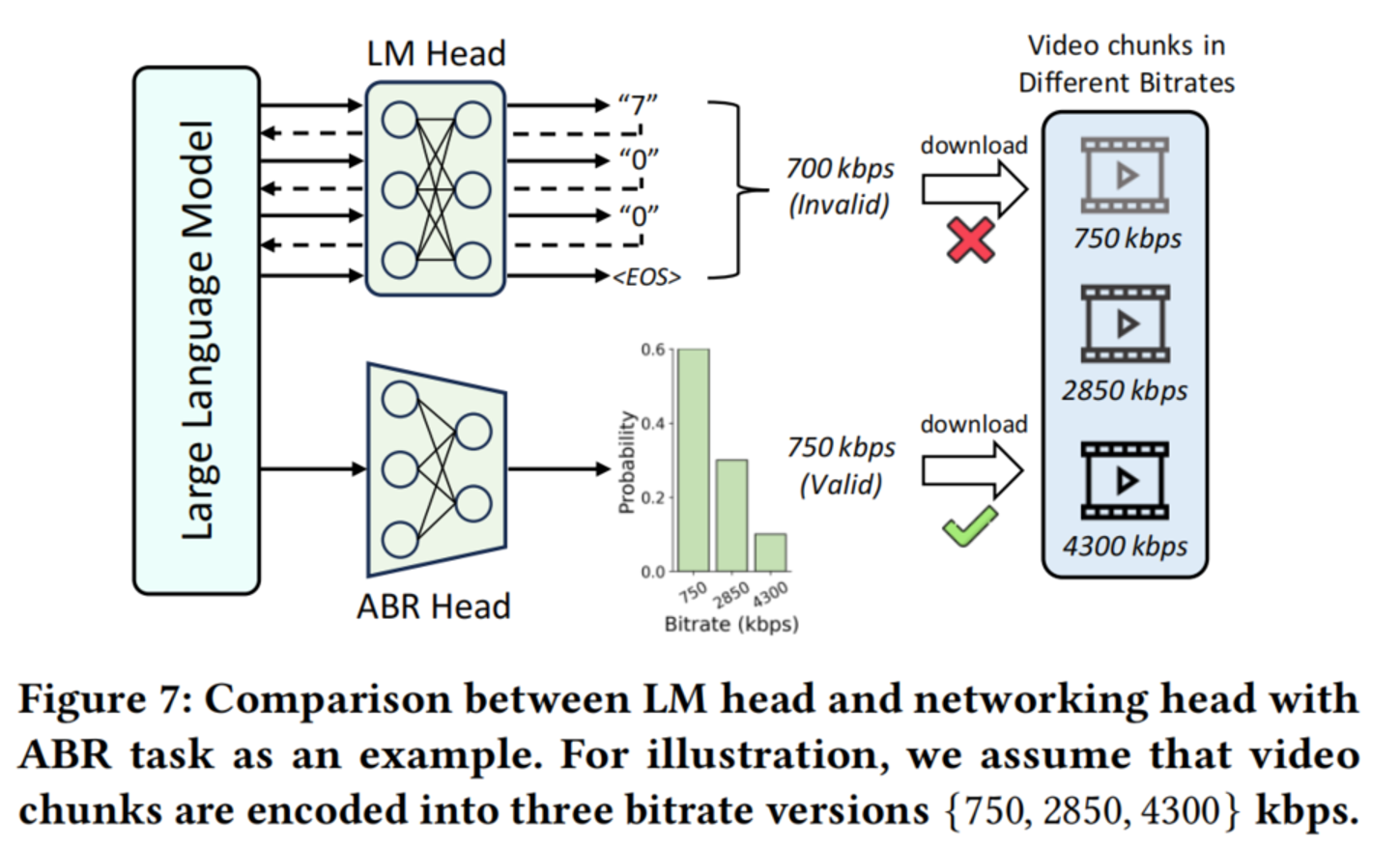
3.2 网络头(解决生成效率与可靠性)
- 移除原始的 LM 头(逐 token 自回归)。
- 添加 任务特定的线性层:直接输出有效答案(如比特率分类、坐标回归)。
- 优点:单次推理、输出天然有效、无幻觉、低延迟。
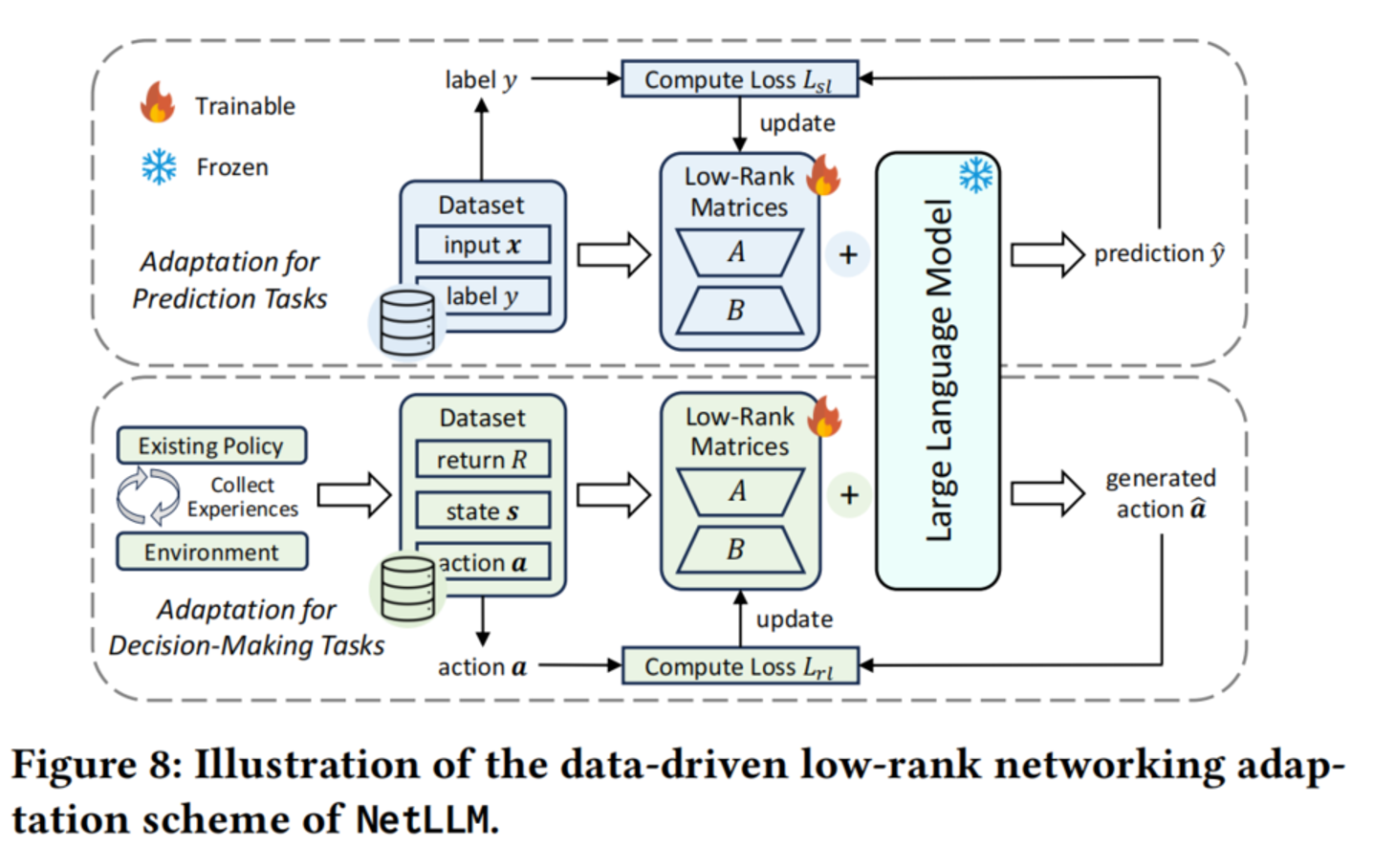
3.3 数据驱动低秩适配(DD-LRNA)(降低微调成本)
-
数据驱动网络适配(Data-Driven Networking Adaptation):包含两种学习范式的适配方式。
- 监督学习(SL)适配 :用于预测类任务(如 VP)。直接使用带标签的数据集 Dsl={X,Y}\mathcal{D}{sl} = \{\mathcal{X}, \mathcal{Y}\}Dsl={X,Y},计算预测值 y^\hat{y}y^ 与真实标签 yyy 之间的损失 Lsl=Fsl(y,y^)L{sl} = F_{sl}(y, \hat{y})Lsl=Fsl(y,y^)(如 MSE 或交叉熵),通过反向传播更新参数。
- 强化学习(RL)适配 :用于决策类任务(如 ABR、CJS)。采用 离线 RL(数据驱动) 方式,避免 LLM 与环境在线交互。用已有非 LLM 算法(如 GENET、Decima)预先收集经验数据集 Drl\mathcal{D}_{rl}Drl,然后像监督学习一样训练 LLM 预测动作。
-
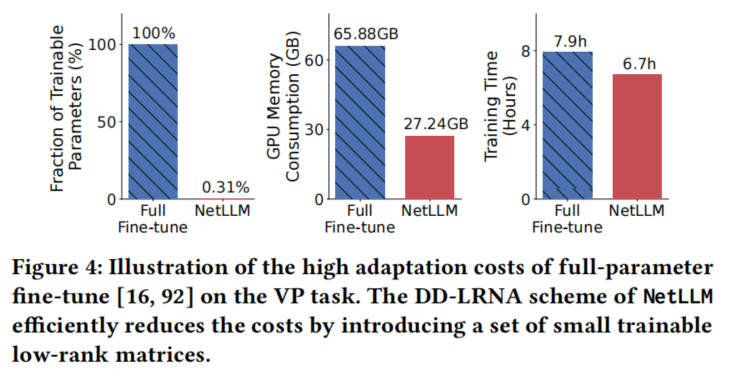
低秩矩阵适配(Low-Rank Adaptation) :在冻结的 LLM 权重旁加入可训练的 low-rank 矩阵(类似 LoRA),仅更新约 0.31%0.31\%0.31% 的参数。相比全参数微调,显存占用减少 60.9%60.9\%60.9%,训练时间减少 15.1%15.1\%15.1%。
数据驱动 RL 的训练流程(关键理解点)
- 收集轨迹 (s,a,r)(s, a, r)(s,a,r),将即时奖励 rtr_trt 替换为累积回报 Rt=∑i=tTriR_t = \sum_{i=t}^{T} r_iRt=∑i=tTri。这样模型学习的是:"从当前状态开始,为了获得剩余总回报 RtR_tRt,应该采取什么动作"。
- 将状态和动作拆分为子项:st={st1,...,stn}s_t = \{s_t^1, \dots, s_t^n\}st={st1,...,stn},at={at1,...,atm}a_t = \{a_t^1, \dots, a_t^m\}at={at1,...,atm},以适应复合动作/状态的任务。
- 采样长度为 www 的连续窗口作为输入序列 d={Ri,si1,...,sin,ai1,...,aim}i=t−w+1td = \{R_i, s_i^1, \dots, s_i^n, a_i^1, \dots, a_i^m\}_{i=t-w+1}^{t}d={Ri,si1,...,sin,ai1,...,aim}i=t−w+1t。
- 将 ddd 送入 LLM,预测动作 a^ij\hat{a}i^ja^ij,计算损失 Lrl=1w∑i=1w∑j=1mFrl(aij,a^ij)L{rl} = \frac{1}{w}\sum_{i=1}^{w}\sum_{j=1}^{m} F_{rl}(a_i^j, \hat{a}_i^j)Lrl=w1∑i=1w∑j=1mFrl(aij,a^ij)(分类任务用交叉熵,回归任务用 MSE)。
- 推理时 :设定高目标回报 R1R_1R1(如最大可能 QoE),自回归生成动作序列,每执行一步后更新 Rt+1=Rt−rtR_{t+1} = R_t - r_tRt+1=Rt−rt。
4. 实验评估
4.1 实验设置
- 硬件:NVIDIA A100 (80GB)
- 基础 LLM:Llama2-7B(也对比了 OPT、Mistral、LLaVa)
- 任务:VP(视口预测)、ABR(自适应比特率)、CJS(集群作业调度)
- 基线:每种任务均包含 SOTA 学习型(TRACK/GENET/Decima)和传统规则型(LR/BBA/FIFO 等)
4.2 总体性能(训练环境与测试环境相同)
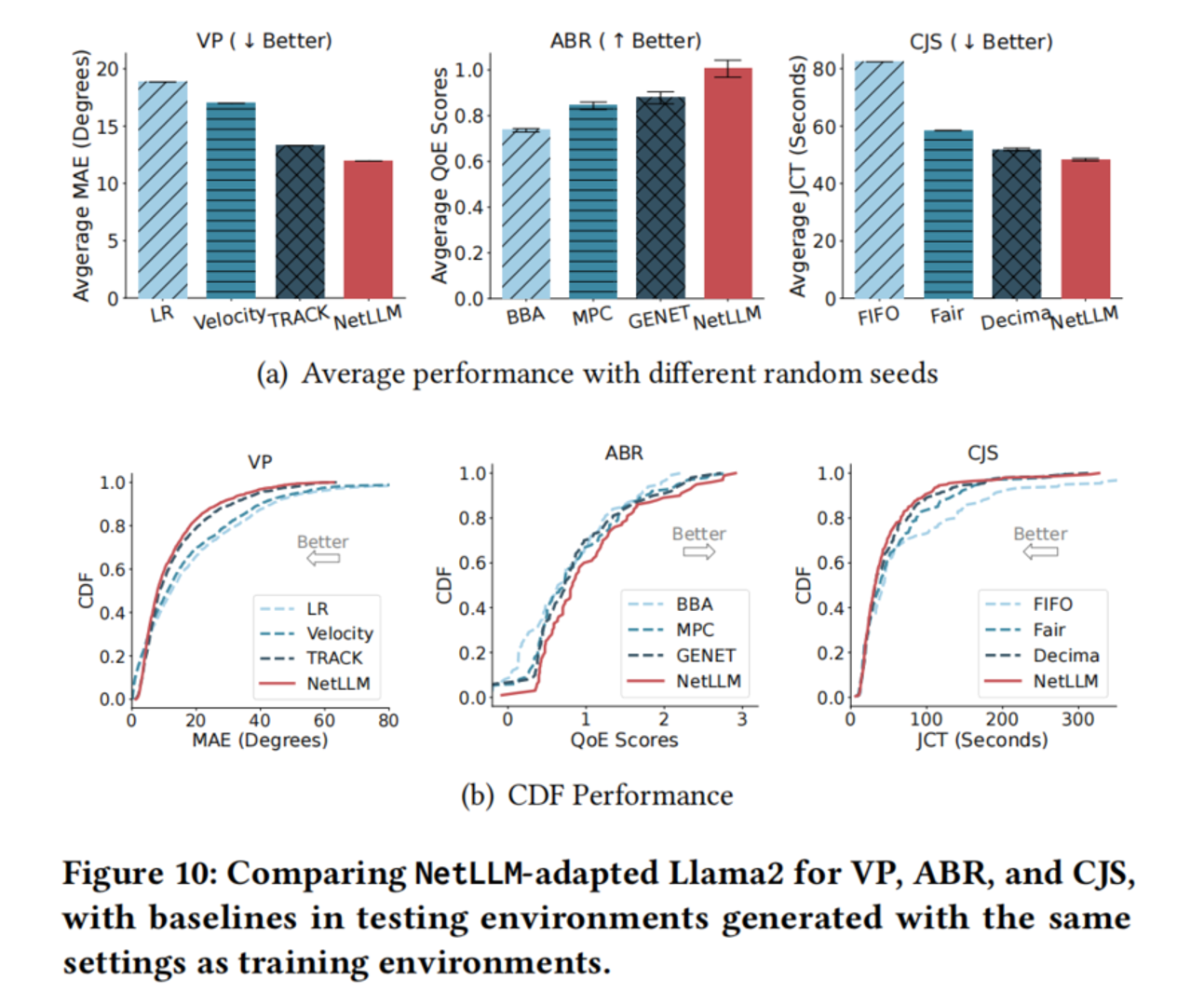
- VP :NetLLM 比 TRACK 降低 MAE 10.1%--36.6%
- ABR :比 GENET 提升 QoE 14.5%--36.6%
- CJS :比 Decima 降低 JCT 6.8%--41.3%
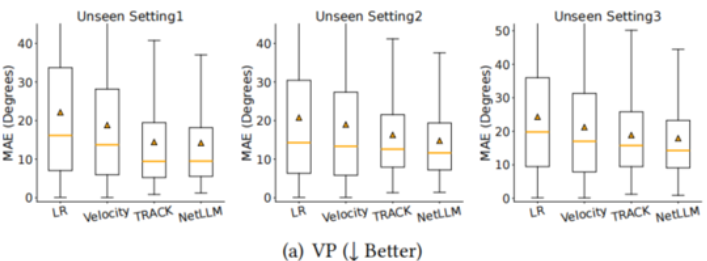
4.3 泛化性能(测试环境与训练环境不同)
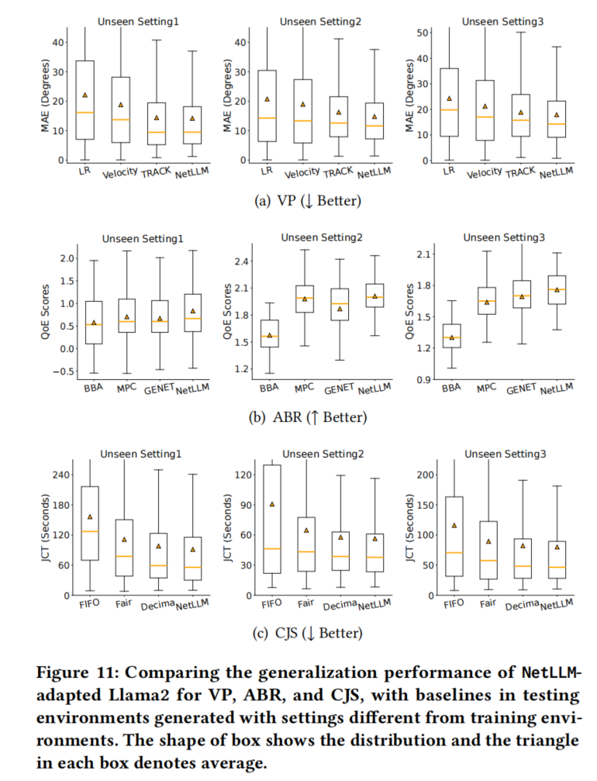

- NetLLM 在所有泛化设置中均优于基线,且性能波动更小(箱体更紧凑)。
- 传统学习型算法在某些未见环境中甚至不如规则型,而 NetLLM 保持领先。
4.4 深入分析
4.4.1 预训练知识与领域知识的重要性
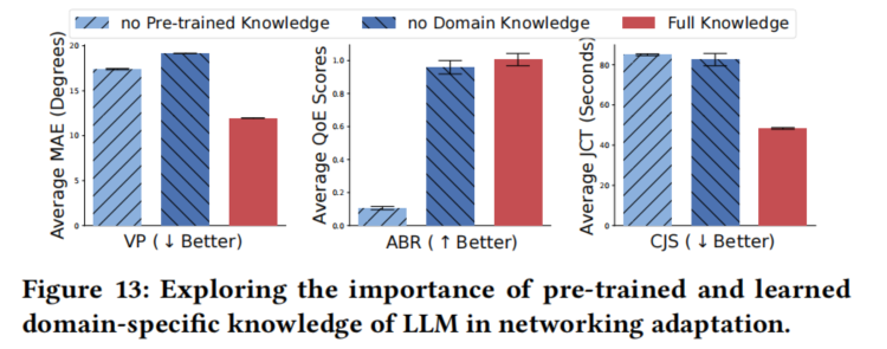
- 随机初始化 LLM → 性能崩溃
- 冻结预训练权重但不加低秩矩阵 → 性能大幅下降
结论:两者缺一不可。
4.4.2 不同 LLM 类型的影响
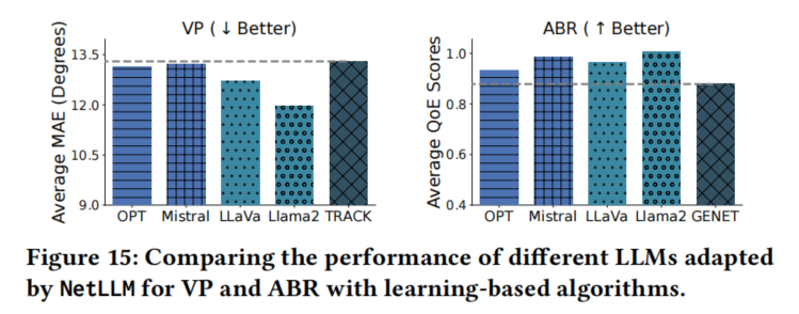
- 所有 7B 模型经过 NetLLM 适配后均超过 SOTA。
- 多模态 LLaVa 略差于纯文本 Llama2,说明跨模态预训练知识对网络任务不一定直接有用。
4.4.3 不同 LLM 大小的影响
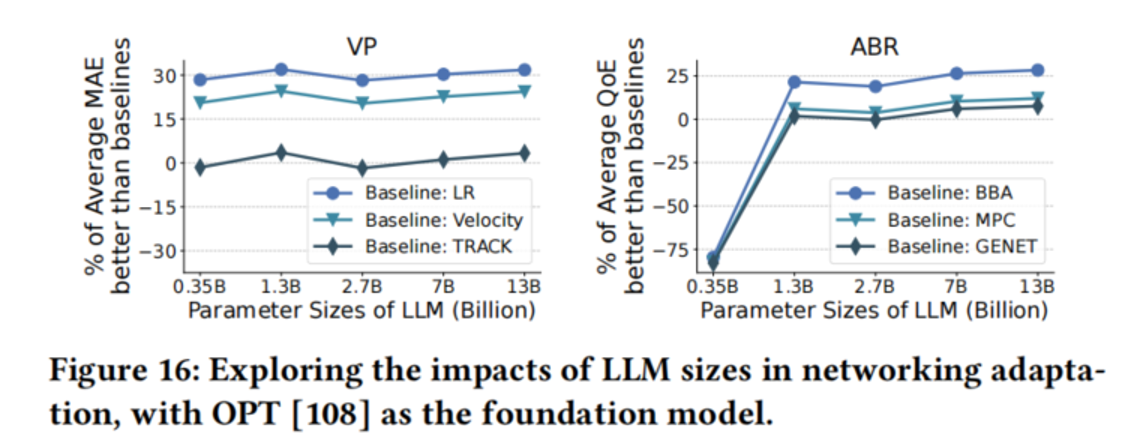
- 参数量 < 1B(如 OPT-0.35B)性能甚至不如规则型基线。
- 参数量 ≥ 1.3B 即可超越 SOTA 学习型算法。
- 为实际部署提供了"最小可用规模"的参考。
5. 讨论
论文通过 Q&A 形式回应了四个潜在质疑:
| 问题 | 核心回答 |
|---|---|
| Q1: 还需要人工设计吗? | 需要少量(设计网络头、选择现成编码器),成本很低 |
| Q2: 为何不用 RAG? | 网络知识隐式、动态,难以文本化;微调更适合 |
| Q3: LLM 开销太大怎么办? | 可用模型压缩(剪枝、量化、蒸馏),已有成熟方案 |
| Q4: LLM 为什么能用于网络? | 预训练知识带来涌现能力;可解释性有待未来研究 |
给我的启发:Discussion 就像审稿人"预答辩",提前堵住质疑,同时拔高论文格局。
6. 个人总结与思考
方法借鉴
-
"冻结主体 + 适配外围"的通用范式:NetLLM 的核心思想是保留 LLM 的预训练权重不变(冻结),只在输入、输出和少量参数上添加可训练模块。这种范式不仅适用于网络管理,也可以用于我自己的意图驱动网络(IDN)项目------不必重新训练大模型,而是为特定任务设计轻量适配层。
-
多模态输入的通用处理流水线 :面对网络中的各种异构数据(时序、图像、标量、图结构),论文没有从零设计特征提取器,而是直接复用已有成熟编码器(ViT、1D-CNN、GNN等),再通过可训练的线性投影层统一映射到 LLM 的 token 空间。这启示我:遇到新模态时,优先找现成的预训练编码器,而不是自己造轮子。
-
输出端的"直接映射"取代"自回归生成":对于有明确输出空间的任务(如分类、回归),可以完全放弃 LLM 原生的 token 预测头,换成简单的线性层直接输出结果。这一设计既消除了幻觉风险,又大幅降低了推理延迟。
-
数据驱动 RL(离线 RL)的应用:对于决策类任务,不需要让 LLM 在真实环境中试错,而是用已有的传统算法提前收集经验数据集,把 RL 问题转化为监督学习问题。这个思路可以推广到任何"交互成本高"的决策场景。
-
低秩参数更新(LoRA 风格):即使需要更新 LLM 的部分参数,也只需引入少量的低秩矩阵(仅占总参数的 0.31%)。这极大降低了显存和训练时间,同时保留了 LLM 的预训练知识。
写作借鉴
-
挑战 → 解决方案的一一对应:论文在1.2提出三个挑战,第4章就用三个模块分别回应,结构清晰得像一张表。我以后写论文也可以先列出问题清单,再逐条回答。
-
主动"拆掉"显而易见的方法:作者在动机部分(第3节)亲自测试了 prompt learning、token 预测等"显然可以试试"的方法,并展示它们失败的结果。这比直接说"现有方法不好"有说服力得多。
-
Discussion 作为"预答辩":第6章用 Q&A 形式主动回应了审稿人可能质疑的四个问题(为何不用 RAG?开销太大怎么办?等等)。这种写法既展示了作者的深度思考,也避免了被审稿人"挖坑"。
-
CDF 图(累积分布函数) :CDF 的纵轴是"累积比例",CDF 图直观刻画随机变量累积概率随变量取值逐步上升的变化趋势,它比只给平均值更能揭示算法的稳定性和长尾表现。
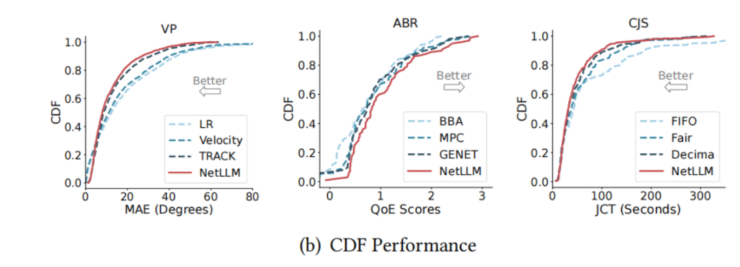
-
箱线图 :箱线图箱体上下沿为上下四分位数、箱内横线是中位数,首尾须线为数据正常范围极值,须外圆点是异常值,用来简明展示数据分布与离群情况。