简述:小数据集照片分类的模型训练
如:20 个分类 × 每类 500 张 = 总共 1 万张图,属于小数据集多分类。
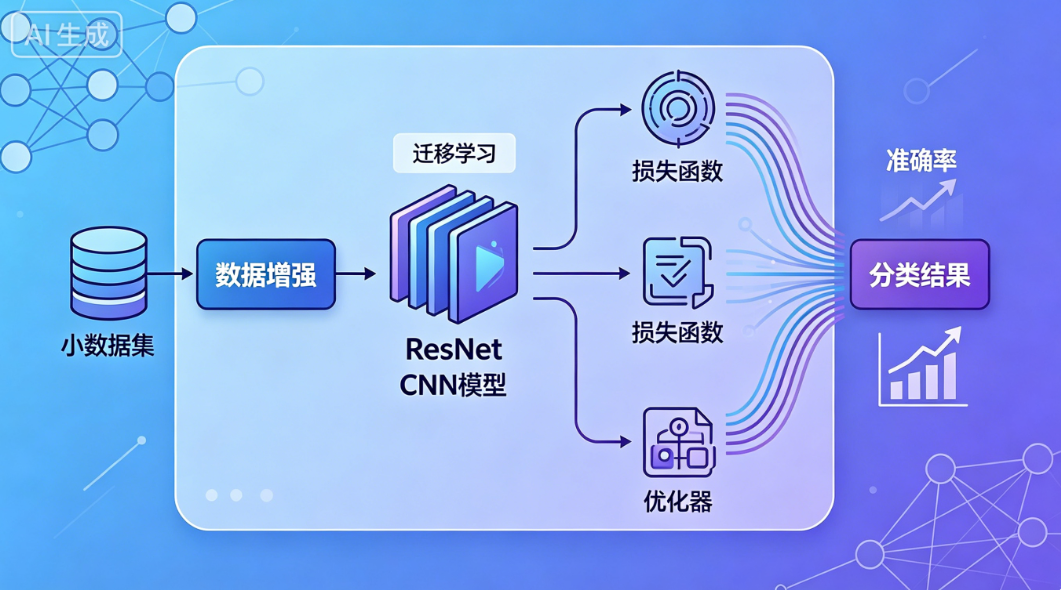
一、先确定:你该用什么模型?
直接选:MobileNetV2 或 ResNet34
理由:
适合小数据集(1 万张以内)
训练快、不容易过拟合
分类效果稳,20 类完全够用
你之前已经在用 ResNet,无缝衔接
二、训练前准备
- 文件夹结构(必须这样放)
bash
plaintext
dataset/
train/
类别1/
001.jpg
002.jpg
...
类别2/
...
类别20/
val/
类别1/
类别2/
...
类别20/- 数据划分规则(非常重要)
每类 500 张:
400 张 → train 训练
100 张 → val 验证
三、最简单训练方案(推荐你直接用)
核心技术:迁移学习(小数据集必用)
用ImageNet 预训练权重
只微调最后几层
训练速度快、准确率高
训练超参数(直接照抄)
输入尺寸:224×224
批次大小:16 或 32
学习率:1e-4
优化器:Adam
损失函数:CrossEntropyLoss(多分类标准)
训练轮数:30~50 轮
四、完整训练步骤(从 0 到 1)
第 1 步:安装环境(1 行命令)
bash
pip install torch torchvision pillow tqdm第 2 步:训练代码(复制直接运行)
python
import torch
import torch.nn as nn
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader
import os
# ====== 1. 配置 ======
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_classes = 20 # 你的分类数量
batch_size = 16
epochs = 30
lr = 1e-4
# ====== 2. 数据增强(小数据集必须加)======
data_transforms = {
'train': transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.RandomRotation(15), # 随机旋转
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406], [0.229,0.224,0.225])
]),
'val': transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406], [0.229,0.224,0.225])
])
}
# ====== 3. 加载数据 ======
data_dir = 'dataset' # 你的数据集路径
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
dataloaders = {x: DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=0) for x in ['train', 'val']}
# ====== 4. 模型:ResNet34 + 迁移学习 ======
model = models.resnet34(pretrained=True)
# 修改最后一层为20分类
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, num_classes)
model = model.to(device)
# ====== 5. 损失函数 & 优化器 ======
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# ====== 6. 开始训练 ======
for epoch in range(epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in dataloaders['train']:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
train_acc = 100 * correct / total
print(f'Epoch {epoch+1}/{epochs} | Loss: {running_loss:.4f} | Acc: {train_acc:.2f}%')
# 验证
model.eval()
val_correct = 0
val_total = 0
with torch.no_grad():
for inputs, labels in dataloaders['val']:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
val_total += labels.size(0)
val_correct += (predicted == labels).sum().item()
val_acc = 100 * val_correct / val_total
print(f'验证集准确率: {val_acc:.2f}%\n')
# 保存模型
torch.save(model.state_dict(), 'photo_classify_20classes.pth')
print("训练完成,模型已保存!")第 3 步:运行训练
把数据集放好,直接运行代码,30~60 分钟训练完成。
五、预测代码(训练完直接用)
python
import torch
from torchvision import models, transforms
from PIL import Image
# 加载模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = models.resnet34()
model.fc = torch.nn.Linear(model.fc.in_features, 20)
model.load_state_dict(torch.load('photo_classify_20classes.pth'))
model = model.to(device)
model.eval()
# 预处理
transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
# 预测一张图
def predict_image(img_path):
img = Image.open(img_path).convert('RGB')
img = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
output = model(img)
_, pred = torch.max(output, 1)
return pred.item()
# 使用
print(predict_image("test.jpg"))六、这个数据规模,预期效果
训练集准确率:95%~99%
验证集准确率:85%~92%
20 分类完全够用
每类 500 张属于刚刚好的小样本
七、总结最关键的 3 点
任务类型:图像分类模型(ResNet34),不是分割模型
数据:每类分 400 训练 + 100 验证,文件夹分类放好
训练:用迁移学习,30 轮,直接运行我给的代码