1. 问题:如何优化性能
从 Sidecar 项目开始,完成了 Python 后端, Go 控制层,rust 高性能处理 bpe 算法解耦后。出现了新的问题:经过压测,控制面的并发问题解决了,但 GPU 利用率的一般------请求处理完一批之后有明显的空档期,显存也没有被充分利用。
这两个问题指向同一个方向:
- 提高请求批处理效率:相同时间内处理更多请求,提升吞吐量
- 提高显存利用率:GPU 性能珍贵,在 AI 推理系统中是最重要的资源
就此,方向明确,如何提高系统批处理效率以及显存利用率。最好的办法就是参考现有的真实场景下的行业主流方案------vllm。不仅有效解决了如何高效利用显存,并从 token 层面解决了并发问题。
2. 现有方案:动态批处理 + VRAM Guard
Dynamic Batching
现在 Sidecar 中使用了动态批处理发送请求,设置了时间窗口以及最大容量,当到达最大容量或者到时间间隔时就一次性发送一批请求到达模型后端处理。
go
func (b *Batcher) Start() {
for {
batch := b.collectBatch() // ① 收集一个微批次
if len(batch) > 0 {
go b.flushBatch(batch) // ② 并发发送到后端
}
}
}
func (b *Batcher) collectBatch() []*Request {
var batch []*Request
deadline := time.After(b.dynamicWaitMs())
for {
select {
case req := <-b.queue:
batch = append(batch, req)
if len(batch) >= b.cfg.MaxBatchSize {
return batch // full batch --- flush immediately
}
case <-deadline:
return batch // time up --- flush whatever we have
}
}
}并通过监控 QPS 设置等待窗口,实现动态适应,针对不同情况设置不同条件
go
func (b *Batcher) dynamicWaitMs() time.Duration {
switch {
case qps > 100: return MaxWaitMs // 高负载:等满 50ms,收集更大批次
case qps > 50: return MaxWaitMs / 2 // 中负载:折中
default: return MaxWaitMs / 4 // 低负载:快速响应
}
}
func (b *Batcher) trackQPS() {
for range time.NewTicker(time.Second).C {
count := b.reqCount.Swap(0) // 原子读写,无锁
b.currentQPS.Store(count)
}
}VRAM Guard
显存管理则通过 NVML 直调,使用阈值熔断进行管理,当使用率到达 90%,显存压力大时便拒绝新请求,优先完成现有请求。
go
type Guard struct {
circuitOpen atomic.Bool // 熔断状态(atomic 保证无数据竞争)
UsedMB atomic.Value // 最新 VRAM 使用量
TotalMB atomic.Value // 最新 VRAM 总量
}熔断逻辑
go
pct := (used / total) * 100.0
if pct >= 90.0 {
if !g.circuitOpen.Load() { // 首次触发才打印日志
slog.Warn("VRAM guard OPEN")
g.circuitOpen.Store(true)
}
} else {
if g.circuitOpen.Load() {
slog.Info("VRAM guard CLOSED")
g.circuitOpen.Store(false)
}
}VRAM 下降后自动关闭熔断,无需人工介入。
局限
Dynamic Batching 是请求级别的,批次之间有空隙,GPU 可能空转。新请求必须等下一个时间窗口才能被发送到后端。VRAM Guard 是全局粗粒度的------超过 90% 就整体熔断,但实际上可能还有很多零散 block 可以用,算力被浪费。
3. vLLM 方案: Continuous Batching + PagedAttention
它解决的是同一层问题,但设计精度完全不同。
Continuous Batching
Continuous Batching 把调度下沉到 token 级:每生成一个 token,就重新跑一次 schedule(),决定下一轮谁进 batch。
调度器每轮都重新跑一次 schedule(),从 waiting 和 running 两个队列里选人,关键在于 waiting 和 running 可以同时被选入同一轮,不需要等上一批全部结束。------这是 Continuous Batching 和 Dynamic Batching 最本质的区别:
python
# 阶段 1: 从 waiting 队列拉新请求做 prefill
while self.waiting and len(scheduled_seqs) < self.max_num_seqs:
...
# 阶段 2: 从 running 队列拉正在生成的请求做 decode
while self.running and len(scheduled_seqs) < self.max_num_seqs:
...
# 关键:如果 waiting 和 running 都有请求,prefill 优先,
# 但 running 的请求不会被迫等待------下一轮如果 waiting 空了马上轮到它们postprocess() 请求结束立刻退出,占用的 slot 和显存立刻释放,下一轮 schedule() 就能把新请求补进来------这是 GPU 利用率接近 100% 的根本原因:
python
if ... token_id == self.eos or seq.num_completion_tokens == seq.max_tokens:
seq.status = SequenceStatus.FINISHED
self.block_manager.deallocate(seq) # 回收 KV Cache block
self.running.remove(seq) # ← 立刻从 running 移除!step() 无限循环直到请求全部完成
python
while not self.is_finished():
seqs, is_prefill = self.scheduler.schedule() # 重新选人
token_ids = self.model_runner.call("run", ...) # GPU 计算
self.scheduler.postprocess(...) # 收尾(移除完成的)schedule() 实现了每轮动态选择,postprocess() 实现了做完就走,step() 循环实现了永不停歇。
对比 Sidecar,最大差异是调度时机------Sidecar 是时间驱动,vLLM 是事件驱动
PagedAttention
VRAM Guard 是粗粒度的------超过 90% 就整体熔断,不管还有多少零散 block 可以用。PagedAttention 核心上借鉴 OS 分页思想,通过逻辑表,物理块管理。将KV Cache 按 Block 按需分配,从逻辑块到物理块完成映射。
【传统方法】显存布局(灰色=有效数据,空=碎片浪费)
────────────────────────────────────────────────────────────────
│████████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░│ 请求A(预分配2048,只用512)
│████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░│ 请求B(预分配512,只用256)
│░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░│ 碎片(无法利用)
────────────────────────────────────────────────────────────────
碎片率:~70-80% 无法容纳新请求
【vLLM 分页】显存布局(固定大小块,无碎片)
────────────────────────────────────────────────────────────────
│████│████│████│██░░│████│████│████│████│████│████│████│████│ 块大小=16 tokens
└────┴────┴────┴────┴────┴────┴────┴────┴────┴────┴────┴────┘
A0 A1 A2 空闲 B0 B1 C0 A3 B2 D0 D1 ...
页表:
请求A: 物理块0,1,2,7 ← 分散但逻辑连续
请求B: 物理块4,5,8
请求C: 物理块3
阶段 1:分配
新请求进入,先检查显存够不够,再按需分配物理 block
python
num_cached_blocks = self.block_manager.can_allocate(seq) # 检查显存 + Prefix Caching
self.block_manager.allocate(seq, num_cached_blocks) # 分配物理块allocate() 之后,seq 拿到一个 block_table,记录它的 KV 存在哪些物理块里。和传统预分配最本质的区别:传统方式按最大长度预留一块连续显存,PagedAttention 用多少分多少,物理上可以不连续:
python
# 给 seq 分配物理 block,写入 seq.block_table(页表)
seq.block_table = [7, 12, 3] # ← 这就是页表!KV 存在 block 7, 12, 3 中
# ↑ ↑ ↑
# 物理块编号。物理上不连续,但逻辑上按顺序使用阶段 2:映射
分配了 block_table 后,每次 GPU 计算时需要告诉三件事:
- 新算出的 K/V 写到哪(slot_mapping)
- 历史 K/V 从哪读(block_tables)
- 每个序列的 KV 有多长(cu_seqlens_k)
python
# ────── 映射 1: slot_mapping(写入位置)──────
# 序列有 700 个 token,前 500 个已被 Prefix Caching 缓存
# 本轮要算第 501~700 这 200 个
# block_table = [7, 12, 3]
# 第 501~512 token → block 7 的第 244~255 slot
# slot = 7 * 256 + 244 = 2036 ... 7 * 256 + 255 = 2047
# 第 513~700 token → block 12 和 block 3
# slot = 12 * 256 + 0 = 3072 ... 12 * 256 + 127 = 3199
# slot = 3 * 256 + 0 = 768 ... 3 * 256 + 59 = 827
slot_mapping = [2036, 2037, ..., 2047, 3072, ..., 3199, 768, ..., 827]
# ↑ 写到 block7 ↑ 写到 block12 ↑ 写到 block3
# ────── 映射 2: block_tables(读取位置)──────
block_tables = prepare_block_tables(seqs)
# tensor([[7, 12, 3, -1, -1],
# [5, -1, -1, -1, -1]]) ← 每行是一个 seq 的页表
# FlashAttention 内核: 需要读 seq0 的第 0 个 block → 去物理块 7 读
# 需要读 seq0 的第 1 个 block → 去物理块 12 读
# ────── 映射 3: cu_seqlens_k(KV 总长度)──────
cu_seqlens_k = [0, 700] # seq 的 K 总长 = 700(已缓存的 500 + 新算的 200)
cu_seqlens_q = [0, 200] # seq 的 Q 只有 200(只需算新 token 的 attention)
# K 比 Q 长 → Prefix Caching 生效!阶段 3:读取
python
# 1. 先把新 K/V 写进 KV Cache
store_kvcache(k, v, k_cache, v_cache, context.slot_mapping)
# ↑ 根据 slot_mapping 把 K/V 写入物理 block 的对应位置
# 2. FlashAttention 从物理 block 读 KV
o = flash_attn_varlen_func(
q, k, v,
cu_seqlens_q=context.cu_seqlens_q, # Q 的边界在哪
cu_seqlens_k=context.cu_seqlens_k, # K 的边界在哪(更长 = prefix cache)
block_table=context.block_tables, # ← 页表!内核根据它跳转到物理地址
...
)根据 block_tables 跳转到对应物理地址读 KV,忽略物理块不连续。
Prefix Caching
从 token 层面,相同前缀的请求只算一次 KV,后续直接复用,完成 cache 匹配。
阶段 1:注册哈希
prefill 完成后,对每个 block 的 token 序列算链式哈希,注册到全局哈希表。链式哈希保证只有前缀完全一致才算命中
python
for seq, token_id in zip(seqs, token_ids):
self.block_manager.hash_blocks(seq) # ← 注册!hash_blocks():
python
# prefill 完了一个 block,把它注册到全局哈希表
start = seq.num_cached_tokens // self.block_size # 从哪个 block 开始注册
end = (seq.num_cached_tokens + seq.num_scheduled_tokens) // self.block_size
h = self.blocks[seq.block_table[start - 1]].hash if start > 0 else -1
for i in range(start, end):
block = self.blocks[seq.block_table[i]]
token_ids = seq.block(i)
h = self.compute_hash(token_ids, h) # 链式哈希
block.update(h, token_ids) # 块上记录哈希
self.hash_to_block_id[h] = block.block_id # 注册到全局哈希表!阶段 2:查找命中
新请求进来,逐块算哈希,查全局表,统计能复用几个 block:
python
if not seq.block_table:
num_cached_blocks = self.block_manager.can_allocate(seq)
# num_cached_blocks = 2 → "前 2 个 block 的 KV 已经有人算过了!"can_allocate():
python
h = -1
num_cached_blocks = 0
num_new_blocks = seq.num_blocks # 总共需要几个 block
for i in range(seq.num_blocks - 1): # 最后一块不查(可能不完整)
token_ids = seq.block(i)
h = self.compute_hash(token_ids, h) # 链式哈希
block_id = self.hash_to_block_id.get(h, -1) # 查全局哈希表
if block_id == -1 or self.blocks[block_id].token_ids != token_ids:
break # 未命中 → 停止!后面的 block 也不可能命中(链式哈希)
num_cached_blocks += 1 # 命中!
if block_id in self.used_block_ids:
num_new_blocks -= 1 # 正在被用 → 可以直接共享,不需要新分配
# 如果 block 不在 used 里(之前用过但已回收,哈希还在)
# → 需要重新分配物理块,但 KV 内容不用重算(等 allocate 时分配空块)
return num_cached_blocks # 返回可复用几个 block阶段 3:复用
命中的 block 直接加引用计数,不重新分配,多个请求共享同一份物理内存:
python
self.block_manager.allocate(seq, num_cached_blocks)allocate():
python
h = -1
# 前 num_cached_blocks 块:复用缓存的
for i in range(num_cached_blocks):
token_ids = seq.block(i)
h = self.compute_hash(token_ids, h)
block_id = self.hash_to_block_id[h]
block = self.blocks[block_id]
if block_id in self.used_block_ids:
block.ref_count += 1 # 已经被别的 seq 在用 → 只加引用计数
else:
block.ref_count = 1 # 空闲的 → 标记为使用
self.free_block_ids.remove(block_id)
self.used_block_ids.add(block_id)
seq.block_table.append(block_id)
# 后面的块:正常分配
for i in range(num_cached_blocks, seq.num_blocks):
seq.block_table.append(self._allocate_block())
seq.num_cached_tokens = num_cached_blocks * self.block_size
# 已经有 KV Cache 了,model_runner 会跳过这部分 token阶段 4:跳过计算
只取未缓存的 token,已有 KV Cache 的部分直接从物理块读,不重新计算 prefill
python
for seq in seqs:
start = seq.num_cached_tokens # = 2 * 256 = 512(前两个 block 已缓存)
end = start + seq.num_scheduled_tokens # = 512 + 200 = 712
input_ids.extend(seq[start:end]) # 只取 [512:712],跳过前 512!
positions.extend(range(start, end)) # 位置从 512 开始
cu_seqlens_q = [0, 200] # Q 只有 200 个新 token
cu_seqlens_k = [0, 712] # K 有 712 个(512 缓存 + 200 新)
# K 比 Q 长 → 需要 block_tables 让 FlashAttention 读缓存的 KV
if cu_seqlens_k[-1] > cu_seqlens_q[-1]:
block_tables = self.prepare_block_tables(seqs)
ini
if context.block_tables is not None:
k, v = k_cache, v_cache # ← 从 Cache 读完整 KV(含缓存的 512 个)
flash_attn_varlen_func(
q, k, v,
cu_seqlens_q=[0, 200], # Q 只有 200
cu_seqlens_k=[0, 712], # K 有 712
block_table=block_tables, # 页表
)
# Q[0..199] 对 K[0..711] 做 attention
# 其中 K[0..511] 是直接从 Cache 读的,没重算 ← 这就是 Prefix Caching 省掉的部分!4. 对比
两套方案解决的是同一个问题,但设计粒度和适用场景不同:
| 维度 | Sidecar(Dynamic Batching + VRAM Guard) | nano-vLLM(Continuous Batching + PagedAttention) |
|---|---|---|
| 调度粒度 | 请求级(时间窗口触发) | Token 迭代级(每个 token 后重新调度) |
| 显存管理 | 粗粒度阈值熔断(>90% 整体拒绝) | Block 级精细分配,精确到每个 token |
| 新请求插入 | 等下一个时间窗口 | 当前 token 生成完立即可插入 |
| TTFT(首字延迟) | 可控,低负载响应快 | 高负载下可能抖动 |
| GPU 吞吐 | 批次间有空隙,利用率中等 | 几乎无空闲,利用率接近 100% |
| Prefix 复用 | 不支持 | 链式哈希命中,跳过 prefill |
| 实现复杂度 | 低,易维护 | 高,需要完整调度器和内存管理器 |
| 适用场景 | 中小规模,延迟敏感,快速上线 | 大规模并发,吞吐优先 |
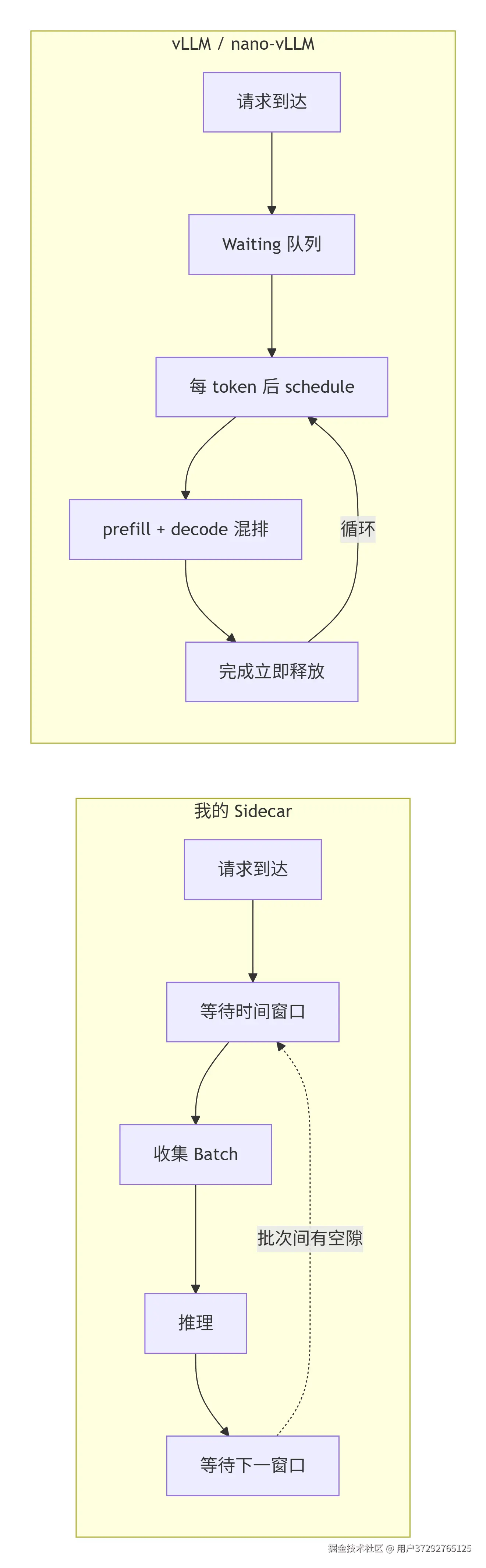
Sidecar 的简单换来了低延迟和易维护;vLLM 的复杂换来了极致的 GPU 利用率。
5. 如何改进
显存管理从粗粒度到 Block 级
从阈值熔断改为物理块级的精细管理,可以在根本上节省并利用显存资源。阈值熔断的问题在于它是全局的------显存超 90% 就拒绝所有新请求,但实际上可能还有很多零散的 block 可以用。Block 级管理能精确知道还剩多少可用 slot,做到"还能放 3 个请求就放 3 个",不浪费算力。
调度粒度从请求级下沉到迭代级
其次,优化系统处理请求。将调度级别从请求级升级到迭代级,达到每生成一个 token 就重新调度,GPU 几乎没有空闲时间。
但实现这些操作将大大提高代码复杂程度,要完整的调度器状态机、显存感知的准入控制、以及迭代级的请求生命周期管理。必须针对真实场景进行选择。
6. 总结
系统设计没有全局最优解,必须根据真实场景选择最合适的情况,是权衡利弊的结果,不是理所当然的结论。
Dynamic Batching 和 VRAM Guard 用最低的实现复杂度解决了并发调度问题。Continuous Batching 和 PagedAttention 用更高的工程复杂度换来了极致的 GPU 利用率,适合大规模高并发的生产环境。
欢迎提出意见:github.com/Li-PengShen...
vLLM 部分代码参考自 nano-vLLM,精简实现保留了 PagedAttention 和 Continuous Batching 的核心逻辑,适合学习使用。