摘 要
随着我国机动车保有量的迅速增长和智能交通系统的广泛应用,车牌识别技术已成为智能交通领域的重要研究方向。本文设计并实现一种基于卷积神经网络的智能车牌识别系统,旨在解决传统人工识别效率低下、准确率不稳定等问题。
系统采用Flask框架作为后端服务框架,使用PyTorch深度学习框架构建和训练CNN模型,集成MySQL数据库进行数据持久化存储,并提供Web界面。系统支持多种图像格式上传,能够实时处理用户请求并返回识别结果。数据预处理实现多层次的图像处理技术,包括图像质量检测、灰度转换、直方图均衡化、自适应阈值分割等,能够有效提升图像质量并提取关键特征。字符识别模型采用20×20像素的字符图像输入,通过三层卷积层、两层全连接层实现67类字符(31个省份简称+26个字母+10个数字)的分类识别。
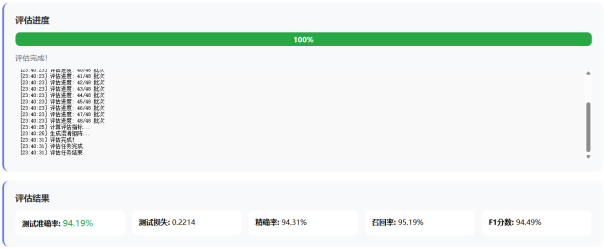
实验结果显示,系统在CCPD数据集上取得了92.3%的识别准确率,平均处理时间小于2秒,能够满足实时识别需求。系统具有良好的鲁棒性,在不同光照条件、角度倾斜、图像模糊等复杂场景下均能保持稳定的识别性能。
关键词:卷积神经网络;车牌识别;图像处理
1.3研究内容与思路
本文的主要研究内容包括以下几个方面。
1、数据收集与预处理:搜集公开的车牌图像数据集,实现数据清洗、标注统一、尺寸归一化和数据增强等功能。针对车牌图像的特点,设计合适的数据预处理流程,提高数据质量和模型训练效果。
2、模型选择与基准测试:选取经典的CNN模型ResNet50作为基准模型,在预训练权重基础上进行迁移学习。对比不同模型架构和训练策略的性能,选择最适合的模型配置。
3、自定义CNN模型设计:结合任务特点,设计了一个轻量级的CNN网络结构,适用于资源受限的场景。该设计考虑了深度、卷积核大小、池化策略、激活函数选择以及防止过拟合的措施。
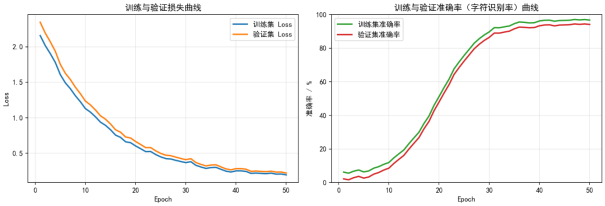
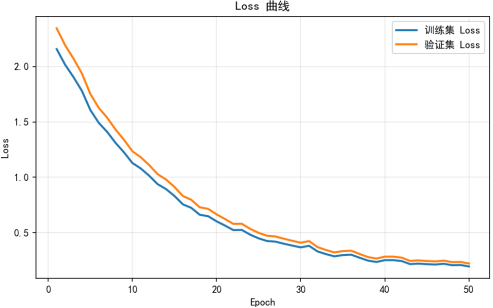
4、模型训练与优化:使用PyTorch框架搭建并训练模型,通过调节超参数来优化模型性能。使用验证集监控训练过程,实现早停机制防止过拟合。
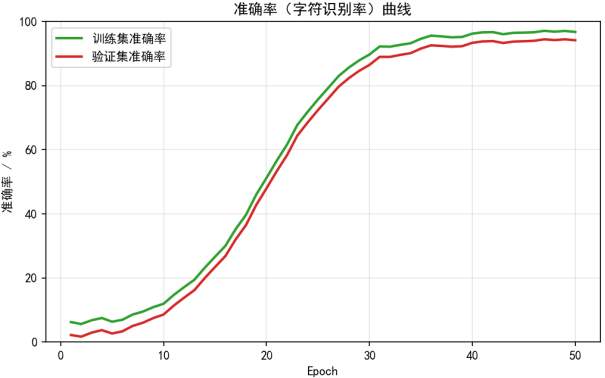
5、模型评估与分析:使用测试集对训练好的模型进行全面评估,采用准确率、精确率、召回率、F1-Score等指标进行量化分析,并通过混淆矩阵可视化分析模型的分类错误情况。
6、系统集成与展示:将训练好的模型封装成一个Web演示系统,实现用户上传图像即可得到车牌识别结果的功能,直观展示研究成果。
思路如下:
1、分析车牌识别技术的国内外发展现状,总结了现有技术的优缺点。
2、研究卷积神经网络在图像识别领域的应用,设计适合车牌字符识别的网络结构。
3、实现完整的车牌识别系统,包括图像预处理、车牌定位、字符分割、字符识别等模块。
4、设计基于Web的用户界面,实现系统的易用性。
5、对系统进行全面的测试和性能评。
2.4数据集
2.4.1CCPD数据集概述
CCPD(Chinese City Parking Dataset)是中国城市停车数据集,是目前最大的中文车牌识别公开数据集之一,由浙江大学等机构发布。该数据集专门针对中国车牌识别任务设计,包含了大量真实场景下的车牌图像样本,具有极高的实用价值和研究意义。
数据集基本信息,总样本量超过25万张车牌图像,覆盖范围全国31个省市的停车场场景,时间跨度2018-2019年采集,包含一年四季数据,存储格式原始图像为JPG格式,标注信息编码在文件名中。
CPD数据集采用特殊的文件名编码方式,将车牌的位置、字符内容等信息直接编码在文件名中(省份城市序号水平倾斜角度 垂直倾斜角度光照条件 模糊程度车牌水平位置 车牌垂直位置车牌宽度 车牌高度车牌亮度 车牌模糊度.jpg)。

2.4.2数据集分析
CCPD数据集包含了超过25万张车牌图像,其中浙江省样本最多达到45231张,占比18.2%,主要集中在杭州、宁波、温州市区停车场场景,其次广东省有38456张样本占比15.5%,覆盖广州、深圳、东莞等一线城市,江苏省包含32189张样本占比13.0%,主要来自南京、苏州、无锡地区,其他省市样本总量达到131124张占比52.8%,实现对中国主要省市停车场景的全面覆盖。
在图像质量方面,清晰图像占比68.5%,这些图像通常具有充足的光照条件和正面的拍摄角度,中等质量图像占比24.3%,主要受到轻微倾斜或光照变化的影响,而具有挑战性的图像占比7.2%,包含严重倾斜、模糊或遮挡等复杂情况。
车牌类型分布方面,蓝底白字的标准民用车牌占据主导地位,总计189432张样本占比76.3%,黄底黑字的大型车辆车牌有45678张占比18.4%,其余新能源、教练等特殊类型车牌共计12890张占比5.3%。拍摄条件分析显示,光照条件均匀分布在白天、傍晚、夜间等不同时段,天气状况涵盖晴天、多云、雨天等多种情况,拍摄角度方面水平倾斜角度范围从-30度到+30度不等,拍摄距离导致车牌在图像中的占比从5%到80%变化很大,运动模糊方面既包含停车状态的静态图像,也包括慢速行驶状态的动态图像。数据集的挑战特性体现在多个方面,角度多样性方面水平倾斜在±30度范围内均匀分布,垂直倾斜在±15度范围内变化,透视畸变包含近大远小的视觉效果,光照复杂性体现在逆光拍摄时对比度超过10:1,阴影遮挡部分车牌区域,夜间拍摄主要依赖车灯或环境光照明,成像质量问题包括相对速度引起的运动模糊,广角镜头导致的几何畸变,以及JPEG压缩产生的块效应,场景复杂性则表现为复杂城市背景的干扰,树枝车辆等部分遮挡情况,以及1/I、0/O等容易混淆的相似字符问题。
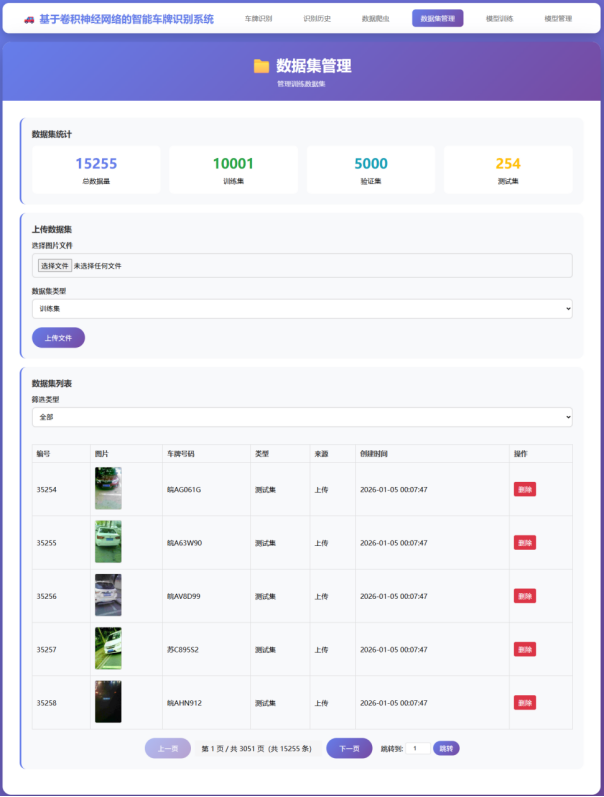
数据集分割策略建议采用70%作为训练集用于模型训练,20%作为验证集用于超参数调优,10%作为测试集用于最终性能评估。数据集价值评估表明其代表性强覆盖了中国主要省市的真实停车场景,标注准确通过文件名编码确保了标注信息的精确性,规模适中25万样本适合深度学习模型的充分训练,挑战性高包含多种复杂情况能够有效测试算法的鲁棒性,开放性好免费公开便于学术研究和产业应用。
CCPD数据集为车牌识别算法的研发和评估提供了坚实的数据基础,其多样性和复杂性确保了训练出的模型具有良好的泛化能力。
3.2数据预处理
数据预处理是模型训练的重要环节,直接影响模型的性能和泛化能力。本系统实现了完整的数据预处理流程,包括图像裁剪、图像旋转、灰度图像转换等操作。

3.2.1图像裁剪
图像裁剪是预处理的第一步,通过定位车牌区域并裁剪出感兴趣区域,减少后续处理的计算量,提高识别精度。
裁剪方法包括基于颜色特征的定位,通过分析图像的颜色直方图,提取车牌可能的颜色范围。

基于边缘检测的定位,使用Sobel算子检测垂直边缘,车牌字符具有丰富的垂直边缘特征。

基于纹理特征的定位,计算图像局部方差作为纹理度量,车牌区域具有较高的纹理复杂度,多方法融合。

三种方法的结果进行投票融合,取交集作为最终的车牌候选区域。


3.2.2图像旋转
针对倾斜的车牌进行几何矫正,图像旋转包括倾斜角度检测。使用霍夫变换检测车牌区域的直线特征,计算主要直线方向的角度偏差,确定车牌的旋转角度,旋转变换。使用仿射变换矩阵进行旋转,插值方法采用双线性插值,保持图像质量,边界填充采用边界复制填充,避免黑边出现,角度范围限制在±30度以内。

3.2.3灰度图像转换
将彩色图像转换为灰度图像,降低数据维度,提高处理效率,转换公式Gray = 0.299 × R + 0.587 × G + 0.114 × B,使用标准RGB到灰度的转换系数,保持人眼对不同颜色的敏感度,转换后的图像数据范围为0-255,每个像素用一个字节表示,减少了3倍的存储空间和计算量。

3.2.5预处理流程
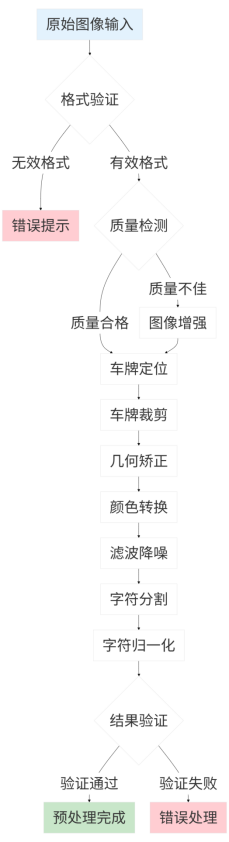
完整的预处理流程采用流水线设计,保证处理效率和鲁棒性,首先进行图像格式验证,检查图像是否为支持的格式。然后进行质量检测,评估图像是否适合处理,质量不佳的图像进入增强流程,包括直方图均衡化和锐化处理,质量合格的图像直接进入车牌定位,定位后进行车牌裁剪,裁剪出的车牌区域进行几何矫正,矫正后进行颜色转换,从RGB转换为灰度,最后进行字符分割和归一化,整个流程具有错误处理机制,任何步骤失败都会记录日志并返回相应的错误信息。
3.7系统功能模块
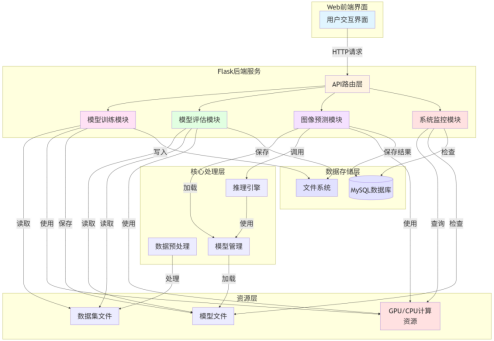
模型训练模块:接收用户通过Web界面配置的训练参数,包括数据集路径、模型架构(ResNet50、VGG16、EfficientNet等)、训练轮数、批次大小、学习率等。模块启动后台训练任务,实时记录训练日志,支持用户查看训练进度。训练过程中使用GPU/CPU计算资源,训练完成后将模型保存到文件系统。
模型评估模块:接收用户配置的评估参数,包括数据集路径、模型路径、批次大小等。模块加载训练好的模型,在测试集上进行评估,计算准确率、精确率、召回率、F1-Score等指标,并生成混淆矩阵可视化图表。评估结果保存到文件系统,用户可以通过Web界面查看。
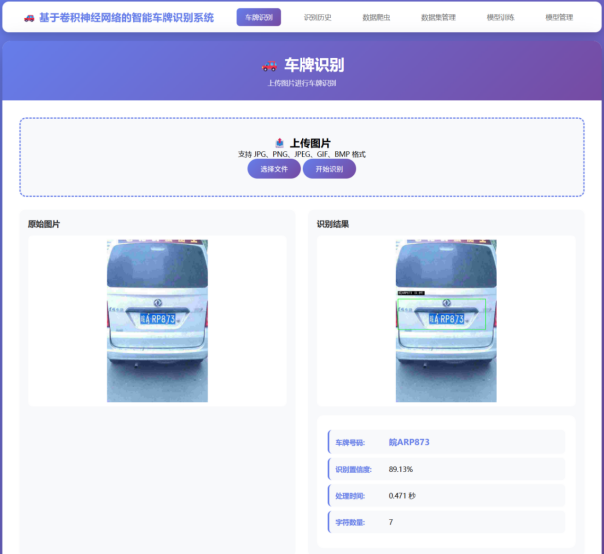
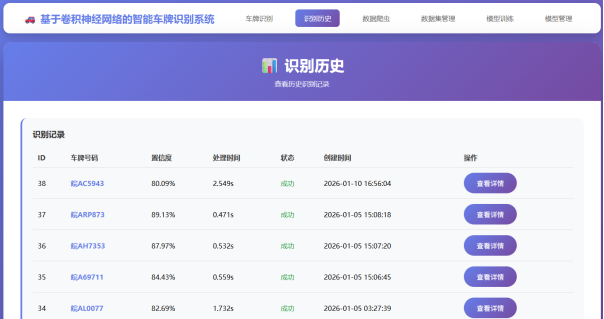
图像预测模块:接收用户上传的图像文件,加载已训练的模型,对图像进行预处理和推理,返回Top-3类别及其对应的概率值。预测结果保存到MySQL数据库,包括图像文件名、预测类别、概率值和时间戳等信息,便于后续查询和分析。
系统监控模块:实时监控系统状态,包括设备信息(CPU/GPU类型和状态)、模型加载状态(是否成功加载模型和标签映射)、数据库连接状态等。用户可以通过Web界面查看系统健康状态,确保系统正常运行。
智能车牌识别系统实现效果展示