扩散大语言模型的强化学习框架革新TraceRL:从理论推导到算法实现
目录
- [1. 引言](#1. 引言)
- [2. 预备知识](#2. 预备知识)
- [2.1 扩散概率模型的形式化定义](#2.1 扩散概率模型的形式化定义)
- [2.2 掩码扩散过程的数学描述](#2.2 掩码扩散过程的数学描述)
- [2.3 自回归与扩散生成的信息论对比](#2.3 自回归与扩散生成的信息论对比)
- [3. 背景与动机](#3. 背景与动机)
- [3.1 扩散语言模型的独特优势](#3.1 扩散语言模型的独特优势)
- [3.2 传统强化学习方法面临的挑战](#3.2 传统强化学习方法面临的挑战)
- [4. 核心方法:TraceRL 框架](#4. 核心方法:TraceRL 框架)
- [4.1 扩散语言模型的马尔可夫决策过程形式化](#4.1 扩散语言模型的马尔可夫决策过程形式化)
- [4.2 轨迹感知的密集奖励建模](#4.2 轨迹感知的密集奖励建模)
- [4.3 扩散基价值模型的理论分析与设计](#4.3 扩散基价值模型的理论分析与设计)
- [4.4 策略优化目标的数学推导](#4.4 策略优化目标的数学推导)
- [4.5 架构无关性的理论保证](#4.5 架构无关性的理论保证)
- [4.6 课程学习与长思维链推理的形式化分析](#4.6 课程学习与长思维链推理的形式化分析)
- [5. 实验设计与主要结果](#5. 实验设计与主要结果)
- [5.1 评估基准与数据集](#5.1 评估基准与数据集)
- [5.2 实现细节与超参数设置](#5.2 实现细节与超参数设置)
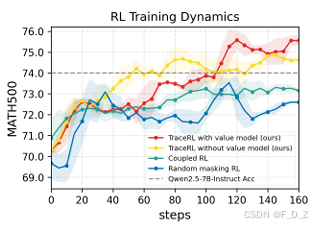
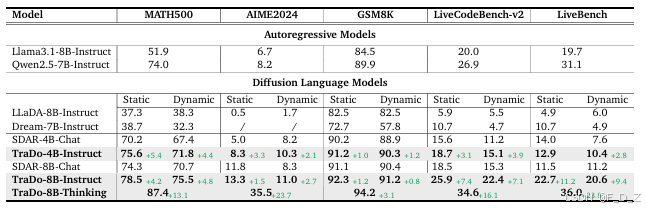
- [5.3 主实验结果与分析](#5.3 主实验结果与分析)
- [5.4 消融实验与敏感性分析](#5.4 消融实验与敏感性分析)
- [6. 局限性与未来研究方向](#6. 局限性与未来研究方向)
- [7. 一句话总结](#7. 一句话总结)
- [8. 论文基本信息](#8. 论文基本信息)
1. 引言
扩散概率模型在图像生成领域取得了显著成功,近年来研究者开始探索其在语言建模中的潜力。扩散大语言模型采用迭代去噪的生成机制,与传统的自回归模型形成本质区别。然而,如何有效地对扩散语言模型进行后训练,特别是引入强化学习以提升推理能力,仍然是一个开放性问题。
Wang 等人在 ICLR 2026 发表的论文《Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models》中,提出了名为 TraceRL 的新型强化学习框架。
2. 预备知识
2.1 扩散概率模型的形式化定义
扩散概率模型(Diffusion Probabilistic Model, DPM)定义了两个随机过程:前向扩散过程(forward diffusion)和反向去噪过程(reverse denoising)。
前向扩散过程 :设 q ( x 0 ) q(\mathbf{x}_0) q(x0) 为真实数据分布,其中 x 0 ∈ V L \mathbf{x}_0 \in \mathcal{V}^L x0∈VL 为长度为 L L L 的词元序列, V \mathcal{V} V 为词表。前向过程定义为一个马尔可夫链,逐步向数据中添加噪声:
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(\mathbf{x}_{1:T} | \mathbf{x}0) = \prod{t=1}^{T} q(\mathbf{x}t | \mathbf{x}{t-1}) q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
对于离散词元空间,掩码扩散(masked diffusion)采用如下转移核:
q ( x t ∣ x t − 1 ) = ∏ i = 1 L q ( x t ( i ) ∣ x t − 1 ( i ) ) q(\mathbf{x}t | \mathbf{x}{t-1}) = \prod_{i=1}^{L} q(x_t^{(i)} | x_{t-1}^{(i)}) q(xt∣xt−1)=i=1∏Lq(xt(i)∣xt−1(i))
其中每个词元独立地以概率 β t \beta_t βt 被替换为 MASK \\text{MASK} MASK 标记,以概率 1 − β t 1-\beta_t 1−βt 保持不变。记 m m m 为掩码标记,则单步转移可以写作:
q ( x t ( i ) ∣ x t − 1 ( i ) ) = { 1 − β t , x t ( i ) = x t − 1 ( i ) , x t − 1 ( i ) ≠ m β t , x t ( i ) = m , x t − 1 ( i ) ≠ m 1 , x t ( i ) = m , x t − 1 ( i ) = m 0 , 其他情况 q(x_t^{(i)} | x_{t-1}^{(i)}) = \begin{cases} 1 - \beta_t, & x_t^{(i)} = x_{t-1}^{(i)}, \quad x_{t-1}^{(i)} \neq m \\ \beta_t, & x_t^{(i)} = m, \quad x_{t-1}^{(i)} \neq m \\ 1, & x_t^{(i)} = m, \quad x_{t-1}^{(i)} = m \\ 0, & \text{其他情况} \end{cases} q(xt(i)∣xt−1(i))=⎩ ⎨ ⎧1−βt,βt,1,0,xt(i)=xt−1(i),xt−1(i)=mxt(i)=m,xt−1(i)=mxt(i)=m,xt−1(i)=m其他情况
即一旦词元被掩码,将永久保持掩码状态(吸收态假设)。经过 T T T 步后, x T \mathbf{x}_T xT 以高概率成为全掩码序列。
反向去噪过程 :反向过程学习逆转前向过程,从噪声分布 p ( x T ) p(\mathbf{x}_T) p(xT)(通常为全掩码分布)出发,逐步去噪生成数据:
p θ ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}{0:T}) = p(\mathbf{x}T) \prod{t=1}^{T} p\theta(\mathbf{x}_{t-1} | \mathbf{x}_t) pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)
其中 p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t) pθ(xt−1∣xt) 是由参数为 θ \theta θ 的神经网络参数化的去噪核。训练目标为变分下界(ELBO):
log p θ ( x 0 ) ≥ L ELBO = E q ( x 1 : T ∣ x 0 ) log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) \log p_\theta(\mathbf{x}0) \geq \mathcal{L}{\text{ELBO}} = \mathbb{E}{q(\mathbf{x}{1:T}|\mathbf{x}_0)} \left \\log \\frac{p_\\theta(\\mathbf{x}_{0:T})}{q(\\mathbf{x}_{1:T}\|\\mathbf{x}_0)} \\right logpθ(x0)≥LELBO=Eq(x1:T∣x0)logq(x1:T∣x0)pθ(x0:T)
展开后得到:
L ELBO = E q ( x 1 ∣ x 0 ) log p θ ( x 0 ∣ x 1 ) ⏟ 重构项 − ∑ t = 2 T D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ⏟ 去噪匹配项 − D KL ( q ( x T ∣ x 0 ) ∥ p ( x T ) ) ⏟ 先验匹配项 \mathcal{L}{\text{ELBO}} = \underbrace{\mathbb{E}{q(\mathbf{x}1|\mathbf{x}0)}\\log p_\\theta(\\mathbf{x}_0 \| \\mathbf{x}_1)}{\text{重构项}} - \sum{t=2}^{T} \underbrace{D_{\text{KL}}(q(\mathbf{x}{t-1}|\mathbf{x}t, \mathbf{x}0) \| p\theta(\mathbf{x}{t-1}|\mathbf{x}t))}{\text{去噪匹配项}} - \underbrace{D{\text{KL}}(q(\mathbf{x}_T|\mathbf{x}_0) \| p(\mathbf{x}T))}{\text{先验匹配项}} LELBO=重构项 Eq(x1∣x0)logpθ(x0∣x1)−t=2∑T去噪匹配项 DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−先验匹配项 DKL(q(xT∣x0)∥p(xT))
2.2 掩码扩散过程的数学描述
在掩码扩散模型中,后验分布 q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1} | \mathbf{x}_t, \mathbf{x}_0) q(xt−1∣xt,x0) 具有封闭形式。设 α ˉ t = ∏ s = 1 t ( 1 − β s ) \bar{\alpha}t = \prod{s=1}^t (1-\beta_s) αˉt=∏s=1t(1−βs) 为累积保留概率,则 t t t 时刻词元未被掩码的概率为 α ˉ t \bar{\alpha}_t αˉt。给定 x t \mathbf{x}_t xt 和 x 0 \mathbf{x}_0 x0,后验概率为:
q ( x t − 1 ( i ) = w ∣ x t ( i ) , x 0 ( i ) ) = { α ˉ t − 1 α ˉ t ⋅ I w = x 0 ( i ) , x t ( i ) = m , x 0 ( i ) ≠ m I w = x t ( i ) , x t ( i ) ≠ m q(x_{t-1}^{(i)} = w | x_t^{(i)}, x_0^{(i)}) = \begin{cases} \frac{\bar{\alpha}_{t-1}}{\bar{\alpha}_t} \cdot \mathbb{I}w = x_0\^{(i)}, & x_t^{(i)} = m, \quad x_0^{(i)} \neq m \\ \mathbb{I}w = x_t\^{(i)}, & x_t^{(i)} \neq m \end{cases} q(xt−1(i)=w∣xt(i),x0(i))={αˉtαˉt−1⋅Iw=x0(i),Iw=xt(i),xt(i)=m,x0(i)=mxt(i)=m
其中 w ∈ V w \in \mathcal{V} w∈V。该封闭形式使得我们可以精确计算 KL 散度项,从而简化训练过程。
2.3 自回归与扩散生成的信息论对比
从信息论视角,两种生成范式存在本质差异。设序列 x \mathbf{x} x 的熵为 H ( x ) H(\mathbf{x}) H(x)。自回归生成将联合分布分解为条件概率的乘积:
H ( x ) = ∑ i = 1 L H ( x i ∣ x < i ) H(\mathbf{x}) = \sum_{i=1}^{L} H(x_i | \mathbf{x}_{<i}) H(x)=i=1∑LH(xi∣x<i)
生成过程按照固定的因果顺序逐位确定信息。扩散生成则采用迭代精化策略:每个生成步 t t t 揭示部分信息。定义互信息 I ( x 0 ; x t ) = H ( x 0 ) − H ( x 0 ∣ x t ) I(\mathbf{x}_0; \mathbf{x}_t) = H(\mathbf{x}_0) - H(\mathbf{x}_0 | \mathbf{x}_t) I(x0;xt)=H(x0)−H(x0∣xt)。当 t t t 从 T T T 递减至 0 0 0 时,互信息逐渐增加,表明噪声逐步被移除。这种差异决定了强化学习方法的设计必须考虑不同的信息结构。
3. 背景与动机
3.1 扩散语言模型的独特优势
扩散语言模型相较于自回归模型具有以下潜在优势:
- 双向上下文建模:在每步去噪过程中,模型可以同时利用当前位置左右两侧的上下文信息进行预测。
- 可控生成能力:通过在去噪过程中注入约束条件,可以灵活地引导生成方向。
- 并行生成潜力:理论上可以在比序列长度更少的步数内完成生成。
3.2 传统强化学习方法面临的挑战
传统强化学习算法,如近端策略优化(PPO),在应用于自回归语言模型时,高度依赖生成过程概率的链式分解:
p AR ( x ) = ∏ t = 1 L p ( x t ∣ x < t ) p_{\text{AR}}(\mathbf{x}) = \prod_{t=1}^{L} p(x_t | \mathbf{x}_{<t}) pAR(x)=t=1∏Lp(xt∣x<t)
在此框架下,策略梯度具有简洁形式:
∇ θ J ( θ ) = E τ ∼ p θ ∑ t = 1 L ∇ θ log p θ ( x t ∣ x \< t ) ⋅ R ( τ ) \nabla_\theta J(\theta) = \mathbb{E}{\tau \sim p\theta} \left \\sum_{t=1}\^{L} \\nabla_\\theta \\log p_\\theta(x_t \| \\mathbf{x}_{\
然而,扩散语言模型的生成概率无法分解为因果链式结构。其逆向去噪轨迹 x T → x T − 1 → ⋯ → x 0 \mathbf{x}T \rightarrow \mathbf{x}{T-1} \rightarrow \cdots \rightarrow \mathbf{x}_0 xT→xT−1→⋯→x0 中,每个时间步对所有位置进行联合更新,位置间的依赖性呈全局耦合状态。因此,直接将传统强化学习方法应用于扩散语言模型存在根本性的不匹配问题。
4. 核心方法:TraceRL 框架
TraceRL 框架将整个去噪过程视为一条完整的推理轨迹,并在此基础上引入轨迹感知的强化学习机制。
4.1 扩散语言模型的马尔可夫决策过程形式化
将逆向去噪过程建模为马尔可夫决策过程(MDP)。定义元组 ( S , A , P , R , γ ) (\mathcal{S}, \mathcal{A}, P, R, \gamma) (S,A,P,R,γ):
-
状态空间 S \mathcal{S} S :所有部分掩码序列的集合, S = ( V ∪ { m } ) L \mathcal{S} = (\mathcal{V} \cup \{m\})^L S=(V∪{m})L。状态 s t = x t s_t = \mathbf{x}_t st=xt 表示 t t t 时刻的序列状态。
-
动作空间 A \mathcal{A} A :去噪动作,对应于从当前状态预测并填充掩码位置。记 M ( x t ) = { i : x t ( i ) = m } \mathcal{M}(\mathbf{x}_t) = \{i: x_t^{(i)} = m\} M(xt)={i:xt(i)=m} 为掩码位置集合。动作 a t a_t at 定义为一个映射 a t : M ( x t ) → V a_t: \mathcal{M}(\mathbf{x}_t) \rightarrow \mathcal{V} at:M(xt)→V。在实际实现中,动作由策略网络输出的概率分布采样得到。
-
转移函数 P P P :确定性转移。给定状态 x t \mathbf{x}t xt 和动作 a t a_t at,新状态 x t − 1 \mathbf{x}{t-1} xt−1 由下式确定:
x t − 1 ( i ) = { a t ( i ) , i ∈ M ( x t ) x t ( i ) , i ∉ M ( x t ) x_{t-1}^{(i)} = \begin{cases} a_t(i), & i \in \mathcal{M}(\mathbf{x}_t) \\ x_t^{(i)}, & i \notin \mathcal{M}(\mathbf{x}_t) \end{cases} xt−1(i)={at(i),xt(i),i∈M(xt)i∈/M(xt)
-
奖励函数 R R R :定义在状态转移上。通常仅在最终状态提供奖励:
R ( x t , x t − 1 ) = { r ( x 0 ) , t = 0 0 , t > 0 R(\mathbf{x}t, \mathbf{x}{t-1}) = \begin{cases} r(\mathbf{x}_0), & t = 0 \\ 0, & t > 0 \end{cases} R(xt,xt−1)={r(x0),0,t=0t>0
其中 r ( x 0 ) r(\mathbf{x}_0) r(x0) 是任务相关的奖励信号。
-
折扣因子 γ ∈ [ 0 , 1 ) \gamma \in [0,1) γ∈[0,1):控制未来奖励的权重。
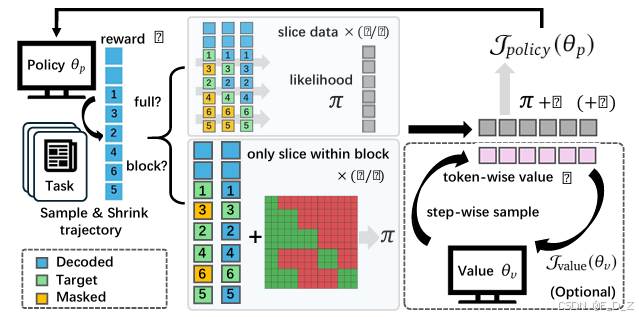
4.2 轨迹感知的密集奖励建模
稀疏奖励(仅在最终步提供)导致信用分配问题。为缓解此问题,TraceRL 引入轨迹级别的奖励建模。设完整的逆向轨迹为 τ = ( x T , x T − 1 , ... , x 0 ) \tau = (\mathbf{x}T, \mathbf{x}{T-1}, \dots, \mathbf{x}_0) τ=(xT,xT−1,...,x0)。定义中间状态的质量评估函数 ϕ : S → R \phi: \mathcal{S} \rightarrow \mathbb{R} ϕ:S→R,轨迹奖励可写为:
R total ( τ ) = r ( x 0 ) + λ ∑ t = 0 T − 1 γ t ⋅ ϕ ( x t ) R_{\text{total}}(\tau) = r(\mathbf{x}0) + \lambda \sum{t=0}^{T-1} \gamma^t \cdot \phi(\mathbf{x}_t) Rtotal(τ)=r(x0)+λt=0∑T−1γt⋅ϕ(xt)
其中 λ ≥ 0 \lambda \geq 0 λ≥0 为平衡系数。相应地,每一步的即时奖励可定义为:
R t = R ( x t , x t − 1 ) = { r ( x 0 ) + λ ϕ ( x 0 ) , t = 0 λ ϕ ( x t ) , t > 0 R_t = R(\mathbf{x}t, \mathbf{x}{t-1}) = \begin{cases} r(\mathbf{x}_0) + \lambda \phi(\mathbf{x}_0), & t = 0 \\ \lambda \phi(\mathbf{x}_t), & t > 0 \end{cases} Rt=R(xt,xt−1)={r(x0)+λϕ(x0),λϕ(xt),t=0t>0
通过中间状态奖励的引入,模型在每一个去噪步骤均可获得反馈信号,从而形成密集的奖励分布。
4.3 扩散基价值模型的理论分析与设计
为了实现价值估计,研究团队提出了扩散基价值模型 V ψ ( x t ) V_\psi(\mathbf{x}_t) Vψ(xt)。该模型以当前的去噪状态为输入,输出期望累积奖励:
V ψ ( x t ) = E p θ ( x t − 1 , ... , x 0 ∣ x t ) ∑ k = 0 t γ k R ( x k , x k − 1 ) V_\psi(\mathbf{x}t) = \mathbb{E}{p_\theta(\mathbf{x}_{t-1}, \dots, \mathbf{x}_0 | \mathbf{x}_t)} \left \\sum_{k=0}\^{t} \\gamma\^k R(\\mathbf{x}_k, \\mathbf{x}_{k-1}) \\right Vψ(xt)=Epθ(xt−1,...,x0∣xt)k=0∑tγkR(xk,xk−1)
价值网络采用与策略网络共享底层表示的架构。时序差分(TD)误差定义为:
δ t = R ( x t , x t − 1 ) + γ V ψ ( x t − 1 ) − V ψ ( x t ) \delta_t = R(\mathbf{x}t, \mathbf{x}{t-1}) + \gamma V_\psi(\mathbf{x}{t-1}) - V\psi(\mathbf{x}_t) δt=R(xt,xt−1)+γVψ(xt−1)−Vψ(xt)
价值网络的损失函数为:
L V ( ψ ) = E ( x t , x t − 1 ) ∼ D δ t 2 \mathcal{L}V(\psi) = \mathbb{E}{(\mathbf{x}t, \mathbf{x}{t-1}) \sim \mathcal{D}} \left \\delta_t\^2 \\right LV(ψ)=E(xt,xt−1)∼Dδt2
其中 D \mathcal{D} D 为经验回放缓冲区。
4.4 策略优化目标的数学推导
TraceRL 采用基于策略梯度的优化方法,目标函数为带 KL 约束的期望奖励最大化:
L RL ( θ ) = E τ ∼ p θ ∑ t = 0 T − 1 γ t A ψ ( x t , x t − 1 ) − β ⋅ D KL ( p θ ∥ p ref ) \mathcal{L}{\text{RL}}(\theta) = \mathbb{E}{\tau \sim p_\theta} \left \\sum_{t=0}\^{T-1} \\gamma\^t A_\\psi(\\mathbf{x}_t, \\mathbf{x}_{t-1}) \\right - \beta \cdot D_{\text{KL}}(p_\theta \| p_{\text{ref}}) LRL(θ)=Eτ∼pθt=0∑T−1γtAψ(xt,xt−1)−β⋅DKL(pθ∥pref)
其中:
- A ψ A_\psi Aψ 为优势函数,可通过广义优势估计(GAE)计算。
- p ref p_{\text{ref}} pref 为参考策略(通常是监督学习得到的初始策略)。
- β > 0 \beta > 0 β>0 为 KL 惩罚系数。
策略梯度可近似为:
∇ θ L RL ≈ E ∑ t = 0 T − 1 ∇ θ log p θ ( x t − 1 ∣ x t ) ⋅ A ψ ( x t , x t − 1 ) − β ∇ θ D KL ( p θ ∥ p ref ) \nabla_\theta \mathcal{L}{\text{RL}} \approx \mathbb{E} \left \\sum_{t=0}\^{T-1} \\nabla_\\theta \\log p_\\theta(\\mathbf{x}_{t-1} \| \\mathbf{x}_t) \\cdot A_\\psi(\\mathbf{x}_t, \\mathbf{x}_{t-1}) \\right - \beta \nabla\theta D_{\text{KL}}(p_\theta \| p_{\text{ref}}) ∇θLRL≈Et=0∑T−1∇θlogpθ(xt−1∣xt)⋅Aψ(xt,xt−1)−β∇θDKL(pθ∥pref)
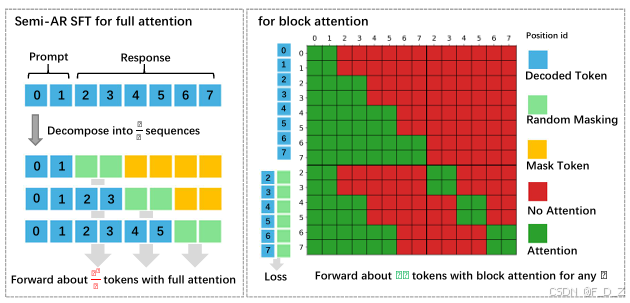
4.5 架构无关性的理论保证
TraceRL 框架的设计不依赖于特定的扩散注意力机制。设注意力机制抽象为一个函数 Attn : R L × d → R L × d \text{Attn}: \mathbb{R}^{L \times d} \rightarrow \mathbb{R}^{L \times d} Attn:RL×d→RL×d。策略网络的一般形式为:
p θ ( x t − 1 ∣ x t ) = ∏ i ∈ M ( x t ) Softmax ( W ⋅ Attn θ ( Emb ( x t ) ) i + b ) p_\theta(\mathbf{x}_{t-1} | \mathbf{x}t) = \prod{i \in \mathcal{M}(\mathbf{x}t)} \text{Softmax}\left( W \cdot \text{Attn}\theta(\text{Emb}(\mathbf{x}_t))_i + b \right) pθ(xt−1∣xt)=i∈M(xt)∏Softmax(W⋅Attnθ(Emb(xt))i+b)
对于不同的注意力架构------全注意力、块注意力或稀疏注意力------只要注意力模块可微,策略梯度即可正确传播。因此,TraceRL 对任何可微分的注意力架构均适用。
4.6 课程学习与长思维链推理的形式化分析
为进一步提升复杂推理能力,研究团队引入课程学习策略。设任务难度由函数 d : X → 0 , 1 d: \mathcal{X} \rightarrow 0,1 d:X→0,1 度量。课程调度函数定义为:
C ( k ) = min ( 1 , max ( 0 , k − k warmup k anneal ) ) \mathcal{C}(k) = \min\left(1, \max\left(0, \frac{k - k_{\text{warmup}}}{k_{\text{anneal}}}\right)\right) C(k)=min(1,max(0,kannealk−kwarmup))
其中 k k k 为当前训练步数。在每个 epoch,只有满足 d ( T ) ≤ C ( k ) d(\mathcal{T}) \leq \mathcal{C}(k) d(T)≤C(k) 的任务 T \mathcal{T} T 被采样用于训练。该策略最终成功训练出首个支持长思维链推理的扩散语言模型。
5. 实验设计与主要结果
5.1 评估基准与数据集
评估基准包括:
- MATH500:包含 500 道数学竞赛题目,用于评估数学推理能力。
- LiveCodeBench-V2:用于评估代码生成与实际执行能力的基准。
对比模型选取主流的自回归大语言模型:Qwen2.5-7B、Llama3.1-8B 等。
5.2 实现细节与超参数设置
根据论文,关键超参数设置如下:
| 参数 | 值 |
|---|---|
| 扩散步数 T T T | 128 |
| 学习率 | 5 × 10 − 6 5 \times 10^{-6} 5×10−6 |
| 批次大小 | 64 |
| γ \gamma γ | 0.99 |
| λ GAE \lambda_{\text{GAE}} λGAE | 0.95 |
| β \beta β | 0.01 |
5.3 主实验结果
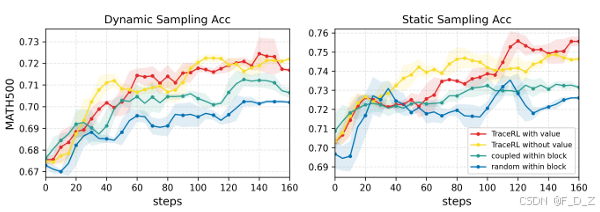
5.4 消融实验与敏感性分析
根据论文内容,消融实验验证了以下设计选择的有效性:
-
密集奖励的影响 :带有中间状态奖励( λ > 0 \lambda > 0 λ>0)的配置相比仅使用最终奖励( λ = 0 \lambda = 0 λ=0)在准确率和收敛速度上均有提升。
-
KL 约束的影响 :适中的 β \beta β 值(约 0.01)在防止策略崩塌和保持探索能力之间取得最佳平衡。
6. 局限性与未来研究方向
尽管 TraceRL 框架取得了突破性进展,仍存在若干有待完善之处:
-
训练计算成本 :扩散模型的多步去噪过程使得强化学习训练的计算资源显著高于自回归模型。对于 T = 128 T=128 T=128 步的设定,训练成本约为自回归模型的数倍。
-
理论基础统一:当前领域存在多个并行工作(DiFFPO、EGSPO、DCoLT 等),各自提出了不同的强化学习适配方案,尚未形成统一的数学框架。
-
超长上下文处理 :在超过 10 5 10^5 105 词元的上下文环境下的推理效率与质量仍需进一步验证。
-
多模态扩展:将 TraceRL 扩展至多模态扩散模型是一个具有前景的方向。
7. 一句话总结
TraceRL 框架通过轨迹感知的强化学习与扩散基价值模型,首次系统性地解决了扩散语言模型的后训练适配问题,使得小参数量扩散模型在复杂推理任务上能够与更大规模的自回归模型竞争甚至超越。
8. 论文基本信息
- 标题:Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models
- 作者:Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, Mengdi Wang
- 发表会议:ICLR 2026
- 预印本日期:2025 年 9 月 8 日
- 论文链接 :arXiv:2509.06949
- 开源代码 :https://github.com/Gen-Verse/dLLM-RL