Linux基础IO
一、前置知识
1.Linux下一切皆文件
在Linux系统中,几乎所有的资源都被抽象成"文件"来管理和访问,不仅仅是我们平时理解的文本文件、图片、程序文件,还包括:
- 普通文件(文本、二进制等)
- 目录(本质上也是一种特殊的文件)
- 硬件设备(如硬盘、串口、打印机等)
- 进程间通信(管道、套接字等)
- 系统信息(如/proc、/sys下的各种伪文件)
这是一个比较抽象的概念,需要在后面的学习中慢慢地去体会.
2.C\C++的文件操作(选看)
对于IO流的解释,我在C++的基本的输入输出流学习_c++输出基础学习-CSDN博客中有提到过.这里就不在过多的阐述.文件操作无非分为三步 :打开文件 -读写文件 -关闭文件.
!IMPORTANT
C 文件操作
1.打开文件
C
FILE *fp = fopen("test.txt", "r"); // 只读方式打开2.读写文件
C
// 读取
char buf[100];
fgets(buf, 100, fp); // 读取一行
// 写入
fprintf(fp, "Hello, world!\n");3.关闭文件
C
fclose(fp);其它函数:
-
fscanf() / fprintf():格式化读写 -
fread() / fwrite():二进制读写 -
fseek() / ftell():文件定位 -
feof() / ferror():检测文件结束/错误
C++ 文件操作
C++
#include <fstream>
// 写文件
std::ofstream ofs("test.txt");
ofs << "Hello, C++!" << std::endl;
ofs.close();
// 读文件
std::ifstream ifs("test.txt");
std::string line;
std::getline(ifs, line);
ifs.close();以上是语言层面的文件的操作案例,每个语言都有文件操作的接口,这里我就不再过多介绍了.
二、系统文件操作接口
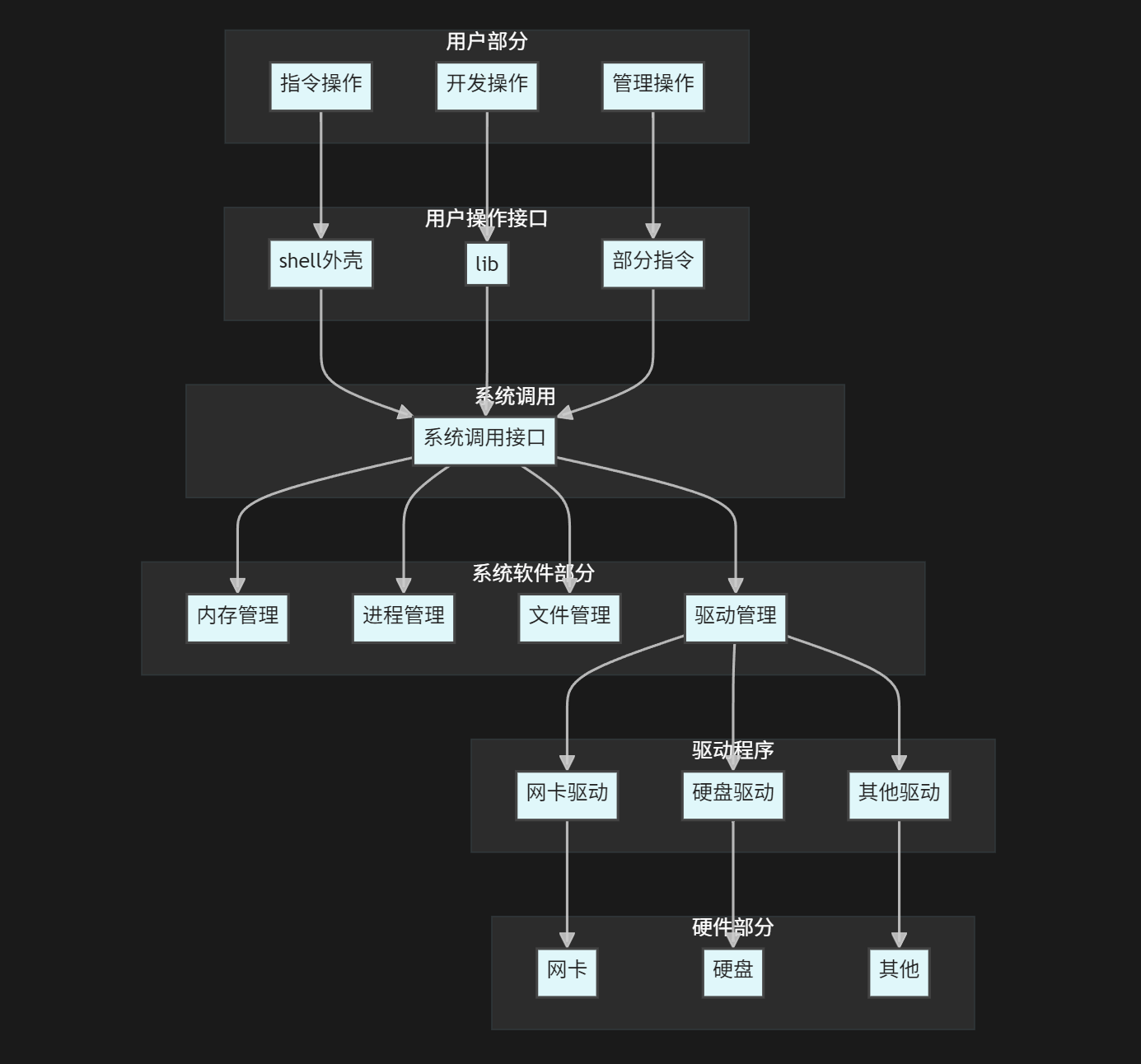
这是一张操作系统体系结构的分层模型图 ,其实想C语言中的fopen、fclose、fwrite、fread、fgets等称为库函数(libs),他们都是通过封装操作系统的系统接口而来的,用户使用起来更加的方便,但是如果我们需要进一步地了解操作系统如何进行IO的,我们就必须学习操作系统的接口.
文件操作-系统接口
open打开文件
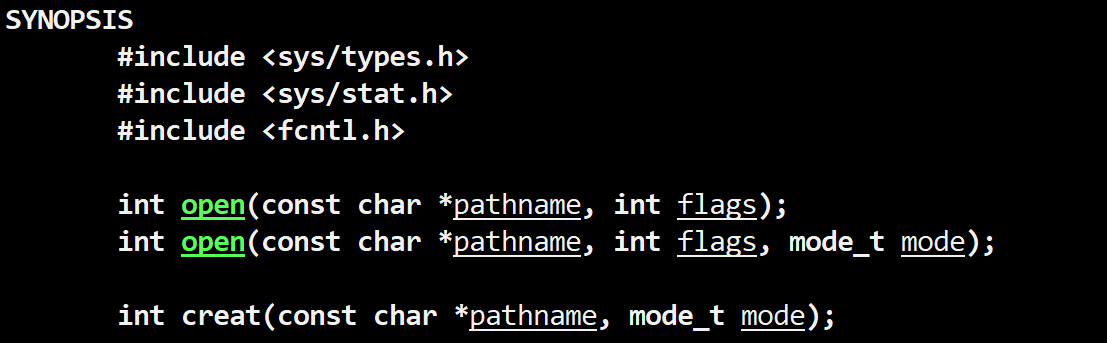
C
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char* pathname, int flags, mode_t mode);上面的Linux man手册中,open是有两个函数的,但是我们一般使用第二个.下面让我来说说函数的参数、返回值
-
返回值
int:文件描述符 (int类型,>=0),失败返回-1,文件描述符后面会有讲解. -
pathname:要打开的文件的路径. -
flags:打开方式和选项(如只读、只写、读写、创建等).使用比特位方式的标志位传递方式.O_RDONLY:只读打开
-
O_WRONLY:只写打开 -
O_RDWR:读写打开 -
O_CREAT:如果文件不存在则创建 -
O_EXCL:和O_CREAT一起用,文件已存在则出错 -
O_TRUNC:打开时清空文件内容 -
O_APPEND:每次写入都追加到文件末尾 -
O_NONBLOCK:非阻塞方式打开(常用于设备/管道) -
flags 可以用 | 组合,比如:
Copen("test.txt", O_RDWR | O_CREAT, 0644);
-
mode:新建文件时的权限(如 0644),只有在O_CREAT标志下才需要.
C
#include <stdio.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int main(){
int ret_fd = open("./test.txt", O_WRONLY | O_TRUNC | O_CREAT, 0644);
if(ret_fd < 0){printf("文件打开失败!\n");}
else{printf("文件打开成功!\n");}
return 0;
}[xj@iZbp1b3oqwxreih70m51j5Z test_7_7]$ ./myfile
文件打开成功!
[xj@iZbp1b3oqwxreih70m51j5Z test_7_7]$ ll
total 20
-rw-rw-r-- 1 xj xj 65 Jul 7 19:23 Makefile
-rwxrwxr-x 1 xj xj 8240 Jul 7 19:42 myfile
-rw-rw-r-- 1 xj xj 307 Jul 7 19:42 myfile.c
-rw-r--r-- 1 xj xj 0 Jul 7 19:42 test.txt以上代码所示,主要需要讲的就是O_WRONLY | O_TRUNC | O_CREAT,这里我选择了只写 、打开时清空文件内容 、没有文件时创建 .0644表示的是文件创建的权限:rw-r--r--.
close关闭文件
C
int close(int fd);- 返回值
int:成功关闭返回0,佛否则返回**-1**. - 参数
fd:所要关闭文件的描述符.
read读文件
C
ssize_t read(int fd, void *buf, size_t count);作用: 从文件描述符 fd 指定的文件中读取最多 count 字节到 buf 指向的内存中。
- 返回值
ssize_t:>0:实际读取的字节数.0:已到文件末尾(EOF).-1:出错(如无权限、fd无效等).
- 参数
fd:要读取的文件的操作符. - 参数
buf:缓冲区指针. - 参数
count:要读的字节数.
write写文件
ssize_t write(int fd, const void *buf, size_t count);-
功能: 将
buf指向的内存中的count字节数据写入到文件描述符fd指定的文件中。 -
返回值
ssize_t:>0:实际写入的字节数-1:出错
- 参数
fd:要读取的文件的操作符. - 参数
buf:缓冲区指针. - 参数
count:要写的字节数.
下面我们来一次综合的应用:
C
#include <stdio.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int main(){
char buf[1024] = {0};
int ret_fd = open("./read.txt", O_RDONLY);
if(ret_fd < 0){printf("文件打开失败!\n");}
else{printf("文件打开成功!\n");}
//读取文件内容
int ret_read = read(ret_fd, buf, sizeof(buf));
printf("读取文件成功!\n");
close(ret_fd);
//将读取到的内容写到文件里面
ret_fd = open("./write.txt", O_WRONLY | O_TRUNC | O_CREAT, 0644);
write(ret_fd, buf, sizeof(buf));
printf("写入文件成功!\n");
close(ret_fd);
return 0;
}[xj@iZbp1b3oqwxreih70m51j5Z test_7_7]$ ./myfile
文件打开成功!
读取文件成功!
写入文件成功!
[xj@iZbp1b3oqwxreih70m51j5Z test_7_7]$ cat write.txt
Hello World这里我提前在read.txt文件中写入了Hello World内容,如何再将它写入了write.txt文件中
三、文件操作的本质
在我们学习C\C++的时候,我们大多数只知道使用语言层面封装的函数来操作文件,那么在计算机系统层面,你打开一个文件会是什么样的呢?下面我们来初略讲一下:
1.什么是文件描述符(fd)
文件描述符(fd, File Descriptor)是操作系统内核为每一个被打开的文件 (或设备、管道、socket等)分配的一个非负整数 ,用来标识和管理这些"打开的文件"。同时,我们上面提到过,当我们使用open函数的时候,如果文件正常打开,我的将会得到这个打开的文件的文件描述符.
C
int ret_fd = open("./read.txt", O_RDONLY);//只读打开文件 ret_fd 为打开read.txt得到的文件描述符2.文件描述符可以干什么?
-
唯一标识 :fd 唯一标识当前进程打开的每一个文件.
-
操作凭证 :你不能直接操作文件名,必须先用
open得到fd,后续read、write、close都用fd. -
统一接口 :不仅仅是普通文件,设备、管道、socket等一切"流"都用
fd统一管理.
3.fd在系统中是如何表示的?或则说是系统的什么?
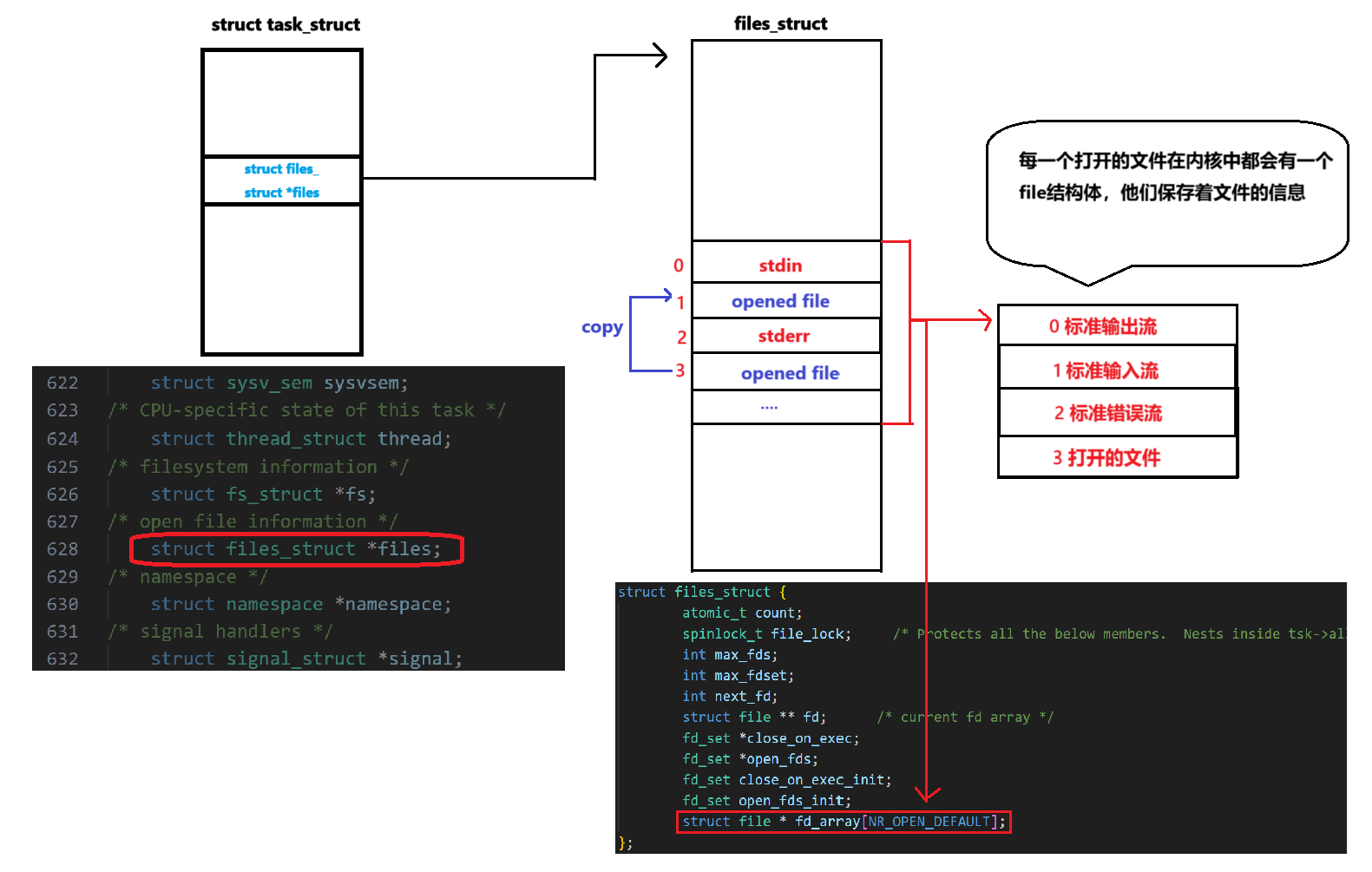
我们从open函数中可以得知,其实的fd只是一个整数,而且所谓的fd只是一个数组的下标 .我们之前讲过,每一个进程被创建的时候都有一个PCB 也就是task_struct,在我们每个程序的task_struct中都有一个struct files_struct *file指针,指向一个文件管理的结构体,在这个结构体里面我们可以发现一个打开文件的数组 struct file *fd_array[NR_OPEN_DEFAULT],里面存放的就是我们打开文件的file结构体的指针 .而!这些结构体指针对应的数组下标,就是我们的fd.
file结构体里面有什么?
-
文件的当前读写位置(偏移量)
-
文件的访问模式(只读、只写、读写等)
-
指向该文件
inode的指针(即文件的元数据) -
文件的引用计数
-
文件的操作函数表(如读、写、定位等操作的实现)
-
其他与文件相关的内核信息
同时,根据上图,我们可以发现一些细节,当我们进程创建的时候,我们就默认打开了三个文件 :stdin、stdout、stderr,而且他他们的**顺序是固定的!是固定的!固定的!这是系统默认为我们打开的,而且 往后系统都将fd = 1位置的文件认为是输出的文件!**无论你写什么数据,系统都会往fd = 1 的地方输出!
4.fd的分配问题
我们知道进程的PCB中存有一个数组来存放我的进程打开的文件,当我们的开一个文件后,进程会从小往大检索整个的数组 ,为什么我们找到最小的fd,随后将我们打开的文件的file结构体指针存入其中.同时,当我们关闭了文件后,对应的 fd 位置的 file* 将被置为NULL.
四、输出重定向
我相信我们在使用Linux系统时,我们都输入过下面这样的指令:
shell
echo "Hello World" >> test.txt我们会得到以下的结果:
shell
[xj@iZbp1b3oqwxreih70m51j5Z test_7_7]$ echo "Hello World" >> test.txt
[xj@iZbp1b3oqwxreih70m51j5Z test_7_7]$ cat test.txt
Hello World所以这句的代码的意思就是将"Hello World" 输出到了test.txt文件中,那么,我们之前说过我们系统都会将我们的输出的数据输出到fd = 1的文件中,bash也是一个进程,默认代开的fd = 1的文件也是stdout,那么为什么不是输出到屏幕,而是到了test.txt,其实这是因为我们的输出进行了重定向!
1.什么是输出重定向?
重定向就是把程序的输入或输出从默认的地方(通常是终端)"转向"到其他地方(如文件、设备、管道等)。
2.输出重定向的本质
-
每个进程启动时,标准输出(fd=1)默认指向终端(屏幕)。
-
程序里的
printf、puts、write(1, ...) 等,都会把内容输出到终端。
这里的fd指向的是数组的下标,如果我们将新打开文件的file 指针覆盖到数组下标为1的位置,我们的默认输出方向就成为了我们指定的位置了.如下图所示:
我们将opened file的file*覆盖到1中,当我们printf("Hello World"),Hello World会打印在opened file 这个文件中.
3.复制文件描述符的系统调用dup2
dup2 是 Linux/Unix 下用于复制文件描述符的系统调用。
它可以把一个文件描述符(如新打开的文件)重定向到另一个指定的文件描述符(如标准输出、标准输入等)。
C
#include <unistd.h>
int dup2(int oldfd, int newfd);- 返回值
int:成功返回 新的文件描述符 失败返回 -1 - 参数
oldfd:原有的文件描述符(已经打开的文件、设备、管道等) - 参数
newfd:你想让它指向的目标文件描述符(如0、1、2等)
下面我们模仿一下 ls "Hello World" > test.txt
C
int fd = open("out.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
dup2(fd, 1); // 让标准输出指向out.txt
printf("hello\n"); // 这行会写到out.txt
close(fd);
C
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(){
int ret_fd = open("./test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
dup2(ret_fd, 1);
printf("Hello World");
close(ret_fd);
return 0;
}这里我们将打开的test.txt文件的file*复制到了fd数组的1号位置,将输出重定向到了此文件,使用printf时,会输出到这个文件里面.
五、缓冲区
如果之前有学过编程语言的同学肯定都听说过缓冲区 这一个概念,但是我也相信很多人都跟我一样,一直学完了一门编程语言了,都没有正真的去理解缓冲区 .下面我结合系统来讲一下缓冲区究竟是什么!
1.什么是缓冲区?
缓冲区 就是一块临时存储数据的内存区域。
在文件操作中,缓冲区用于临时存放从文件读入或即将写入文件的数据,以减少磁盘I/O次数,提高效率。
2.为什么需要缓冲区?
-
磁盘I/O速度远慢于内存 ,频繁的读写磁盘会极大影响程序性能。缓冲区是在内存上的!
-
通过缓冲区,程序可以一次性读/写较大块数据,减少系统调用次数,提高整体效率。
-
缓冲区还能合并多次小的读写操作,减少磁盘寻道和机械延迟。
3.系统缓冲区与C语言缓冲区
下面我们来先写一段代码,展示一下效果!
C
#include <stdio.h>
#include <unistd.h>
int main(){
printf("Hello World!");
sleep(5);
return 0;
}这段代码是不会马上打印出Hello World的,因为当我们printf的内容会先存入缓冲区,当我们刷新缓冲区的时候,我的打印信息才会输出到输出文件中!
c
#include <stdio.h>
#include <unistd.h>
int main(){
char buf = "Hello World!";
write(1, buf, sizeof(buf));
sleep(5);
return 0;
}如果你在Linux上运行这些代码,你会发现,当程序走到write(1, buf, sizeof(buf));屏幕上马上显示出来我们的Hello World.这是因为write是直接写入了stdout中.
第一段代码写入的缓冲区是C语言的缓冲区! 但是我们同时可以猜测出来,C语言的printf接口是封装了write的,当合适的时候,printf调用write将数据写入终端的缓冲区.
C语言缓冲区
谈到C语言缓冲区,我们可以回想一下,我们使用的fopen函数:
C
FILE * fopen ( const char * filename, const char * mode );fopen函数给我们返回的是一个FILE*,那么FILE是什么呢?
FILE结构体是C语言标准库(stdio.h)中用于管理"文件流"的核心数据结构。它是实现fopen、fclose、fread、fwrite、fprintf等高级文件操作的基础。
-
FILE结构体是C标准库为每个打开的文件分配的一个"文件流对象"。
-
它封装了文件的缓冲区、状态、文件描述符等信息,让你可以用更高级、更方便的方式操作文件。
下面是一个简单的FILE封装
c
typedef struct _IO_FILE {
int _flags; // 文件状态标志
char* _IO_read_ptr; // 读缓冲区当前指针
char* _IO_read_end; // 读缓冲区末尾
char* _IO_write_base; // 写缓冲区起始
char* _IO_write_ptr; // 写缓冲区当前指针
char* _IO_write_end; // 写缓冲区末尾
char* _IO_buf_base; // 缓冲区起始
char* _IO_buf_end; // 缓冲区末尾
int _fileno; // 文件描述符fd
// ... 还有很多其他字段
} FILE;所以,我们可以总结,每一个FILE里面都有一个缓冲区!也就是说!每一个打开的文件都会有一个C语言提供的缓冲区!
内核缓冲区
1.什么是内核缓冲区?
-
内核缓冲区是指操作系统内核在内存中为文件I/O操作分配的一块缓存区域。
-
在Linux/Unix中,最典型的内核缓冲区就是页缓存(page cache),用于缓存磁盘文件的数据页。
2.内核缓冲区的作用
-
磁盘I/O速度远慢于内存,频繁直接读写磁盘会极大影响系统性能。
-
内核缓冲区可以合并、延迟、优化磁盘I/O,大幅提升文件操作效率。
-
多个进程读写同一文件时,可以直接在内存中交换数据,避免重复磁盘访问。
内核缓冲区最大的不同就是,内核缓冲区只有一个 ,它不同于C语言缓冲区,每个FILE结构体都有一个缓冲区,内核缓冲区只有一个 !它管理着系统的全部文件!而我们的write函数则是直接将内容写到内核缓冲区里面的!
C语言缓冲区、内核缓冲区的数据传递图示
C
printf/fprintf/fwrite
↓
[C库缓冲区]
↓
write系统调用
↓
[内核缓冲区]
↓
终端/文件/设备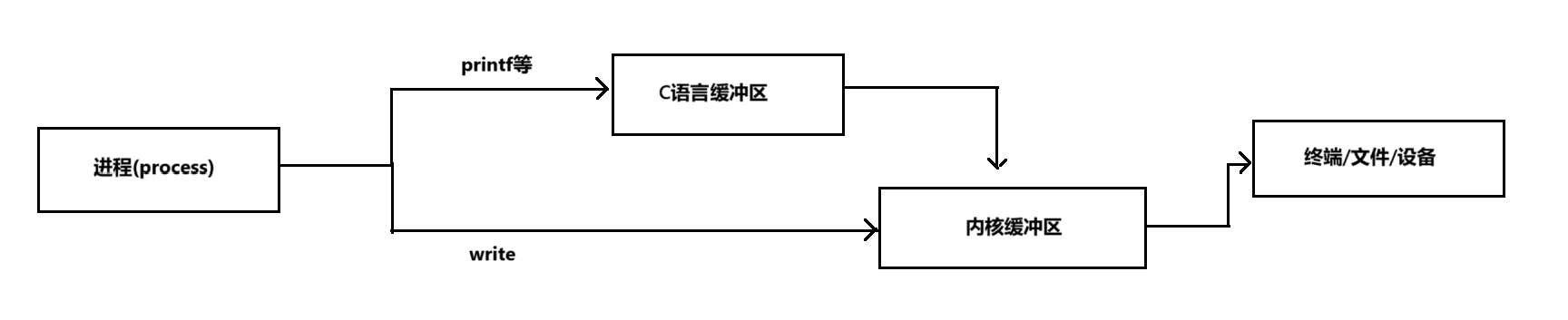
4.缓冲区的刷新模式
这里我们主要讲解的是C语言的缓冲区的刷新模式
C语言的缓冲区分为三种模式:全缓冲、行缓冲、无缓冲
- 全缓冲(Fully Buffered)
-
刷新时机:只有当缓冲区满 、
fflush、fclose或程序结束时,才会把数据写入内核。 -
应用场景:普通文件。
-
优点:效率最高,减少系统调用次数。
- 行缓冲(Line Buffered)
-
刷新时机:遇到换行符
\n、缓冲区满 、fflush、fclose或程序结束时刷新。 -
应用场景:终端(
stdout)等交互式设备。 -
优点:适合逐行输出,用户体验好。
C
printf("Hello World!\n");//这里,Hello World! 将会马上刷新出来- 无缓冲(Unbuffered)
-
刷新时机:每次写操作都立即写入内核,不经过缓冲区。
-
应用场景:标准错误(
stderr)、某些特殊设备。 -
优点:实时性最高,但效率最低。
上面的三种缓冲中,系统默认的是行缓冲,同时我们也可以通过以下的命令修改**特定的FILE**的缓冲刷新模式:
C
setvbuf(fp, NULL, _IONBF, 0); // 无缓冲
setvbuf(fp, NULL, _IOLBF, 0); // 行缓冲
setvbuf(fp, NULL, _IOFBF, 1024); // 全缓冲,1KB六、文件系统(Ext2)
1.前置知识
下面我们补充一些文件存储介质的基础知识
我们知道,当我们进程打开一个文件的时候,我们会将文件一部分或全部内容加载到内存中,那么,我们没有打开我的文件我们会存放到那里呢?没错,就是存放在磁盘中,现在我们就聊一聊机械磁盘.

我们的一个机械磁盘有着如上的结构,数据存放在我们的盘片中,使用磁头来读写数据.我们的一个盘片上面布满了磁道,一个个磁道被划分为许多的扇区,每个扇区大概512kb大小.
现在我们将磁盘内存抽象成线性结构,如图所示:

这样,我们的所有的扇区被划分为一个个小的区块,称为一条线性的储存结构,其实机械磁盘中的内存排布就是如此.那么那么多的扇区,我们的机械硬盘如何快速找到我们的扇区呢?其实每个扇区都有自己的编号,比如我们有一个标号编号为30001的扇区 要读写数据,这个磁盘每一个盘面有40000个扇区 ,一个盘面有20个磁道 ,一个磁道有2000个扇区.我们通过计算获取到位置
30000 / 40000 = 0 在 编号为 0 的盘面,其实就是第一个
30001 / 2000 = 15 ... 1 在编号为 15 的磁道的第 1 个扇区磁盘分区
我们知道,在window系统下,我们都会给磁盘分为不同的分区,方便我们储存数据,下面我们假设我们给磁盘分了一个200G的区.
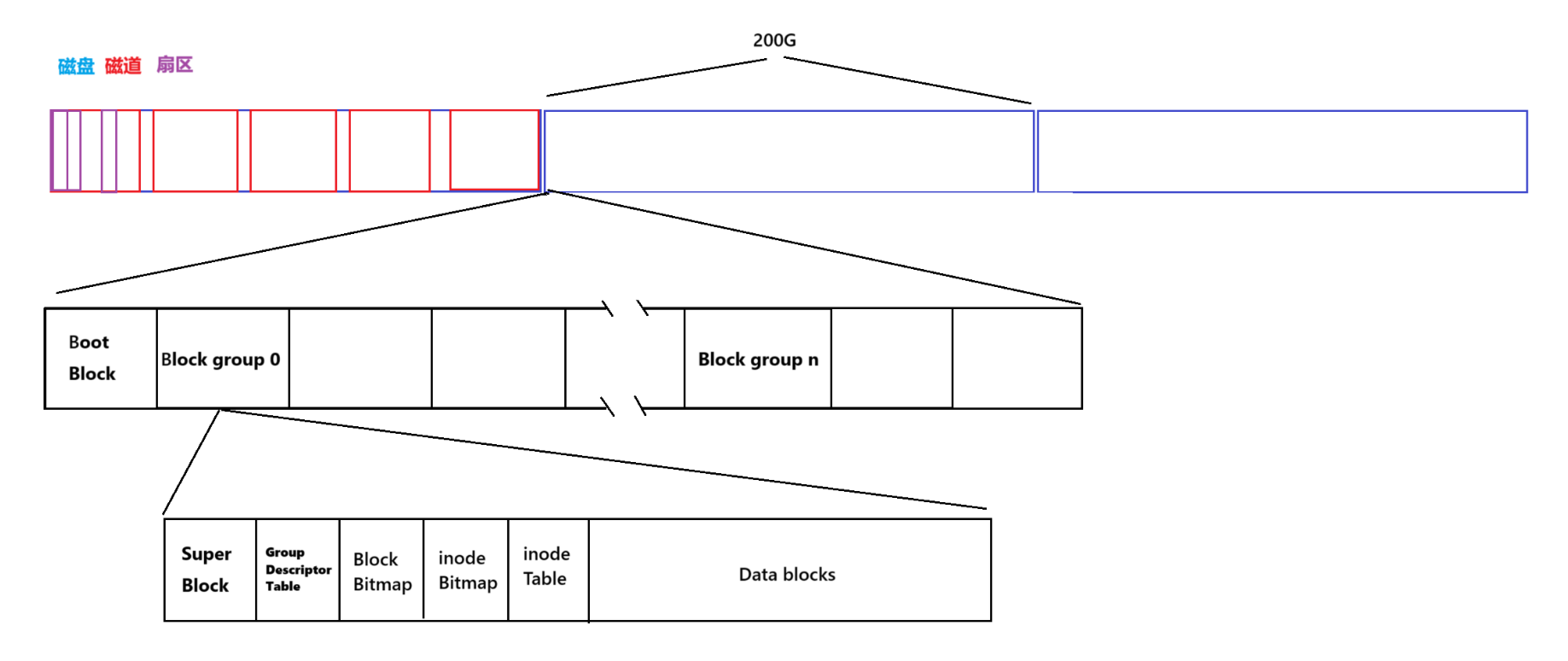
在我们的Linux文件系统下,一个分区被分为许多的块组,而这些**块组中都存放着块组的管理信息与数据.**一个块组由多个扇区组成.
-
进一步放大一个块组,可以看到块组内部的详细结构。包含如下部分(从左到右):
-
Boot Block :引导块,通常是第一个块组
-
Super Block :超级块,记录文件系统的全局信息(只有几个块组有,不是全部的块组都存在)
-
Group Descriptor Table:块组描述符表
-
Block Bitmap:标记哪些数据块被占用
-
inode Bitmap:标记哪些inode被占用
-
inode Table:存储所有inode(文件元数据)
-
Data blocks:实际存储文件内容的数据块
2.什么是inode?
inode(索引节点,index node)是Linux/Unix类文件系统(如ext2/ext3/ext4)中用于描述文件元数据的核心数据结构。
每个文件或目录在磁盘上都有一个唯一的inode,记录了文件的所有元信息和数据块位置 ,但不包含文件名。
!NOTE
Linux系统不认可文件名,所以Linux系统寻找文件都是通过inode寻找的.
3.inode包含哪些信息?
-
文件类型(普通文件、目录、符号链接等)
-
权限信息(rwx,属主、属组、其他用户的读写执行权限)
-
所有者UID、GID
-
文件大小
-
文件的创建、访问、修改时间戳(ctime、atime、mtime)
-
硬链接计数(有多少个目录项指向这个inode)
-
数据块指针(指向实际存储文件内容的数据块的地址)
-
其他元数据(如标志、版本号等)
4.inode与磁盘的关联
一般在Ext2文件系统下,inode结构体中都会定义这样的一个数字数组,这个数字数组存放得编号为我们得数据块的编号,inode把自己存放数据的数据块编号存放在里面.
C
unsigned int i_block[15]; // 直接、间接、双重间接、三重间接数据块指针-
i_block15 这个数组的每个元素,存放的都是一个数据块的"块号"。
-
这些块号指向了实际存储文件内容的data block(数据块)。
结构说明
-
前12个元素(i_block0 ~ i_block11):直接块指针,每个指向一个数据块。
-
第13个元素(i_block12):一级间接块指针,指向一个"间接块",这个间接块里存放更多数据块的块号。
-
第14个元素(i_block13):二级间接块指针,指向一个"二级间接块",里面存放一级间接块的块号。
-
第15个元素(i_block14):三级间接块指针,指向一个"三级间接块",以此类推。
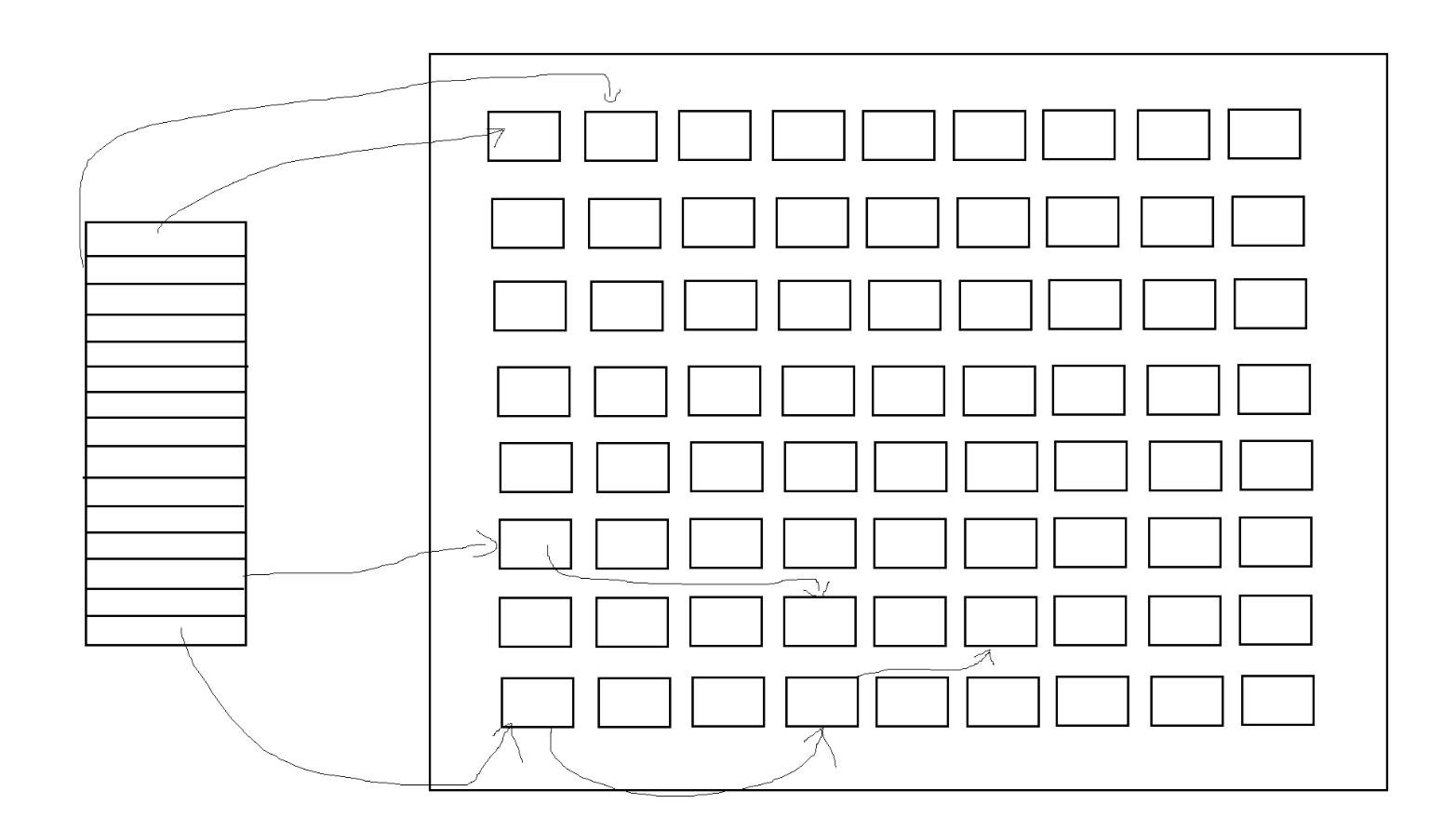
文件的创建
当我们创建一个文件时,文件会携带有一个inode编号,此时文件所在的块组 中的inode Table会加入这个inode,同时位图indoe Bitmap中inode映射的位置会被标记为使用 (一般置为1),并且检索文件数据所在的内存块,位图Block Bitmap将使用到的内存块的标号映射的位置标记为使用(一般置为1).
我们可以发现,文件的属性与内容时分开存储的.
文件的删除
当我们删除一个文件时,此时文件所在的块组 中的inode Table会空闲这个inode,同时位图indoe Bitmap中inode映射的位置会被标记为空闲 (一般置为0),并且检索文件数据所在的内存块,位图Block Bitmap将使用到的内存块的标号映射的位置标记为空闲(一般置为0).
文件的查找
从根目录 或当前目录 开始,逐级查找目录项,找到目标文件名对应的inode号。读取inode表,获取该文件的inode结构体 。通过inode的i_block数组,定位到文件内容实际存储的数据块 .返回文件的元数据和内容.
文件的修改
查找文件名,获取inode号,读取inode结构体。根据修改的位置和大小,分配新的数据块或覆盖原有数据块。更新inode的i_block数组,指向新的或修改后的数据块。更新inode的元数据(如文件大小、修改时间等)。更新相关bitmap(如有新分配的数据块)。
5.Linux目录的本质
Linux/Unix 下用于显示文件或文件系统详细状态信息的命令stat。它可以帮助你查看文件的各种元数据(即inode中的内容)
shell
stat 文件名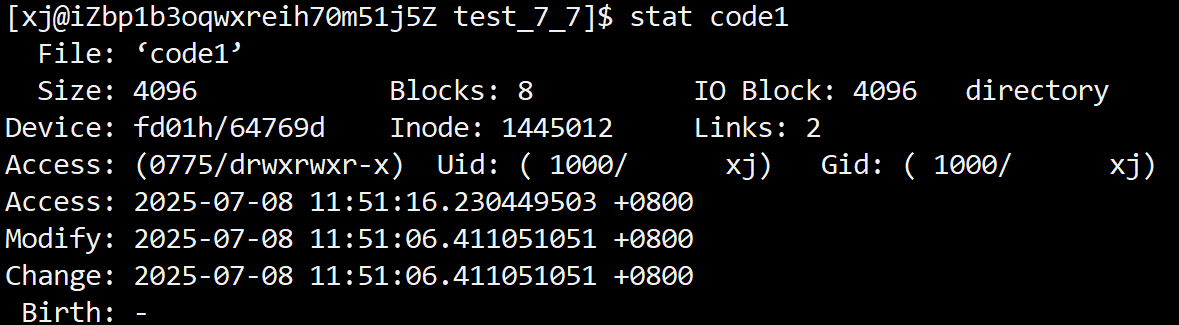
我们可以发现,其实在Linux中目录也是一个文件,它也有着inode,但是在Linux中目录本质上就是一种特殊类型的文件 .目录的数据块中存放着的时"目录项(directory entry) "的列表,其实就是文件名与inode的映射,其形式如下:
/home/user/ 目录的数据块内容:
---------------------------------
| 文件名 | inode号 |
|-------------|-----------------|
| . | 12345 |
| .. | 2 |
| file1.txt | 23456 |
| dir1 | 34567 |
---------------------------------所以,当我们在这个目录上访问一个文件的时候,我们需要通过文件名来寻找到它的inode编号,再通过inode编号找到它的inode结构体,才能对其进行操作.同时我们可以解答一下下面的问题:
-
为什么同一目录下无法存在同名的文件?
一个文件名对应着特定的indoe,同名的文件会用同样的inode,系统寻找时会出现错误.
七、软链接与硬链接
1. 硬链接(Hard Link)
原理
-
硬链接是为同一个文件分配多个文件名,这些文件名都指向同一个inode.
-
也就是说,多个目录项(文件名)指向同一个inode号,它们完全平等,没有主次之分.
特点
-
删除任意一个硬链接,文件内容不会丢失,只有所有硬链接都删除后,文件数据才会被释放.
-
硬链接只能在同一个分区内创建,不能跨分区.
-
不能对目录创建硬链接(防止形成环).
-
ls -l下,硬链接的文件有相同的inode号.
硬链接创建方式:
ln 源文件名 目标文件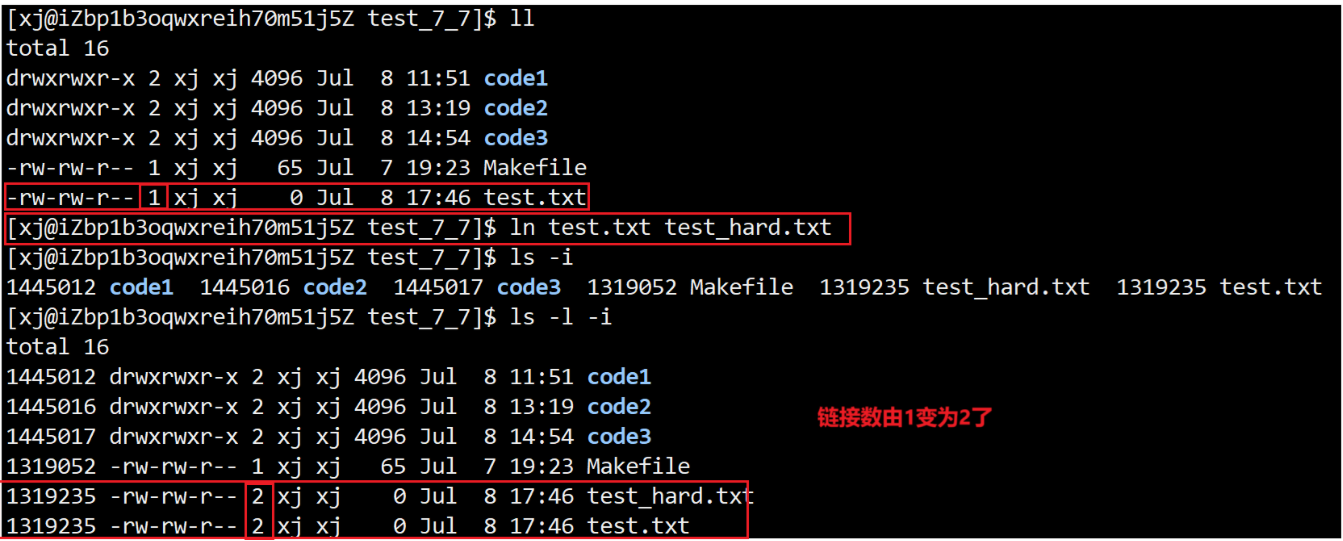
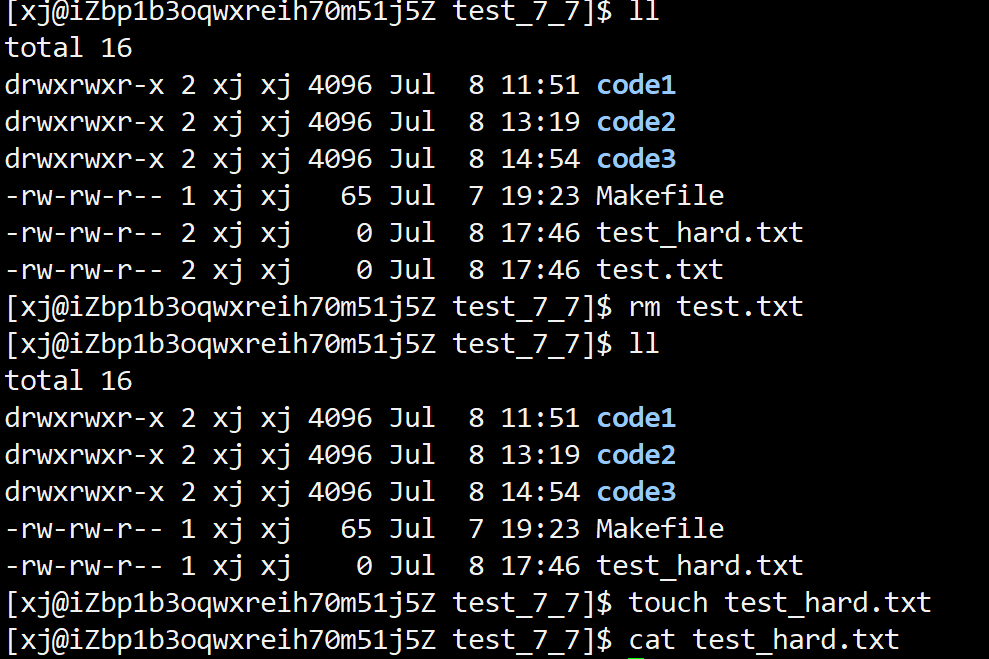
所以,硬链接就是文件的一个别名,当我们创建硬链接后,我们可以删除源文件,我们原有的文件也不会被删除,还是可以访问的.
2. 软链接(符号链接,Symbolic Link)
原理
-
软链接是一个特殊的文件,里面保存着另一个文件的路径名(字符串),有点像Windows的"快捷方式".
-
软链接有自己的
inode和数据块,内容是目标文件的路径.
特点
-
可以跨分区、跨文件系统创建.
-
可以对目录创建软链接.
-
如果原文件被删除,软链接会"失效"(变成死链).
-
ls -l下,软链接文件类型为l,并显示箭头指向目标路径. -
软链接本身有独立的inode号.
软链接创建方式:
ln -s 源文件名 目标文件名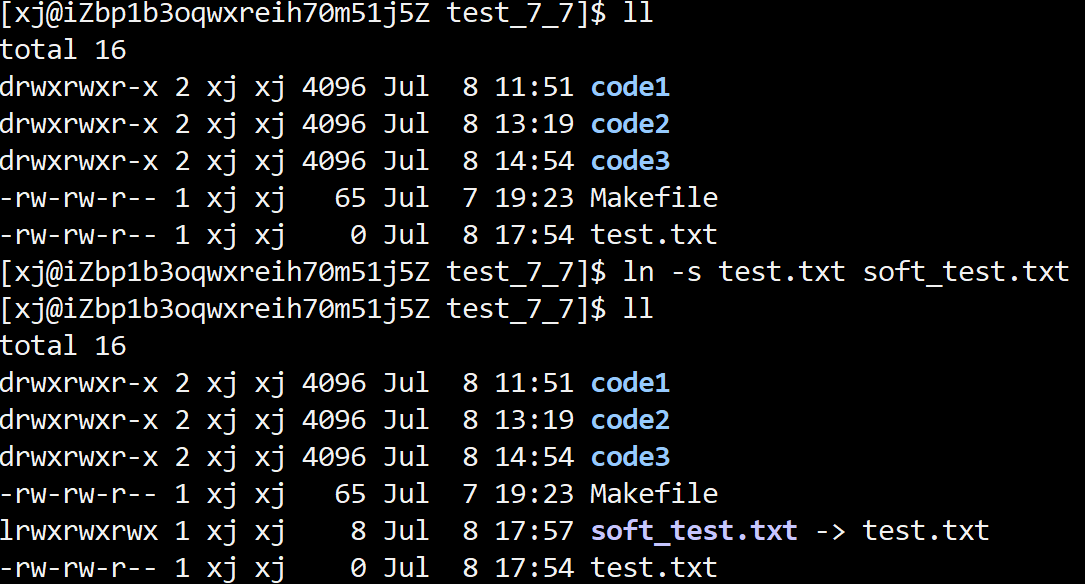
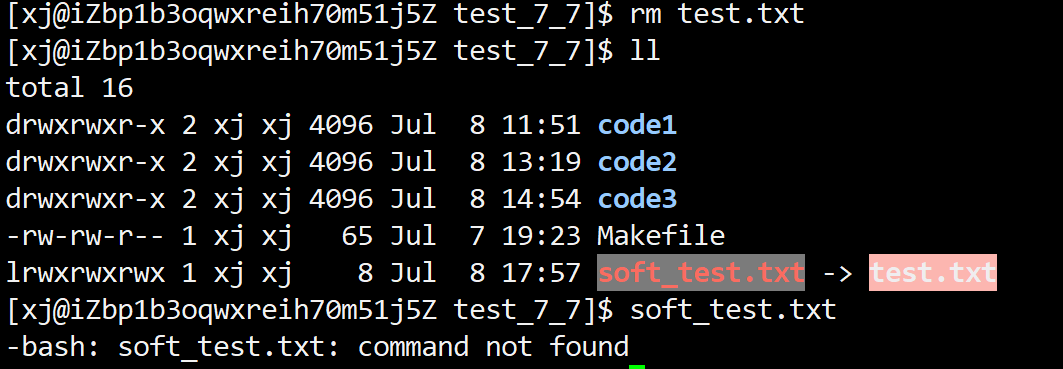
若是我们删除了软链接的源文件,我们将不能通过软链接去访问这个文件.所以软链就相当于windows下的快捷方式
3.目录上的软硬链接
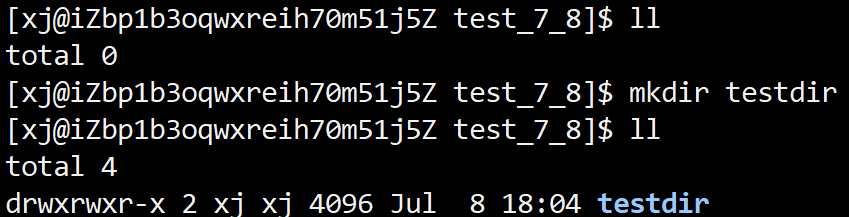
若是我们创建一个新的目录,我们会发现新的目录是有着两个硬链接的,这是为什么呢?

如图,当我们进入到我们的目录中时,我们会看到有一个.这代表着当前的目录 ,也就是说,当我们创建新目录的时候,我们目录下会创建一个硬链接. ,这个.就代表着当前的目录的硬链接,这也是为什么新的目录是有两个硬链接.同时我们会发现..有着三个硬链接,如何解释也是一样的.
软硬链接的对比
| 特点 | 硬链接 | 软链接 |
|---|---|---|
| inode号 | 相同 | 不同 |
| 跨分区 | 不支持 | 支持 |
| 对目录 | 不支持 | 支持 |
| 原文件删除 | 不影响其他链接 | 链接失效 |
| 占用空间 | 很小 | 很小 |
| 命令 | ln | ln -s |
八、Linux文件系统与内存管理核心原理
1.Linux物理内存管理:精细的"仓库"艺术
Linux操作系统对我们的进程、文件都有着对应的管理,同样的Linux操作系统也会对我们的内存进行同样的管理工作,那么下面我们来讲讲Linux操作系统是如何管理我们的物理内存的.
首先,Linux会将物理内存 抽象成一个巨型的仓库 ,为了更好的管理仓库,Linux会将我们的物理内存 分为一个个细小的单元(4KB),如图:
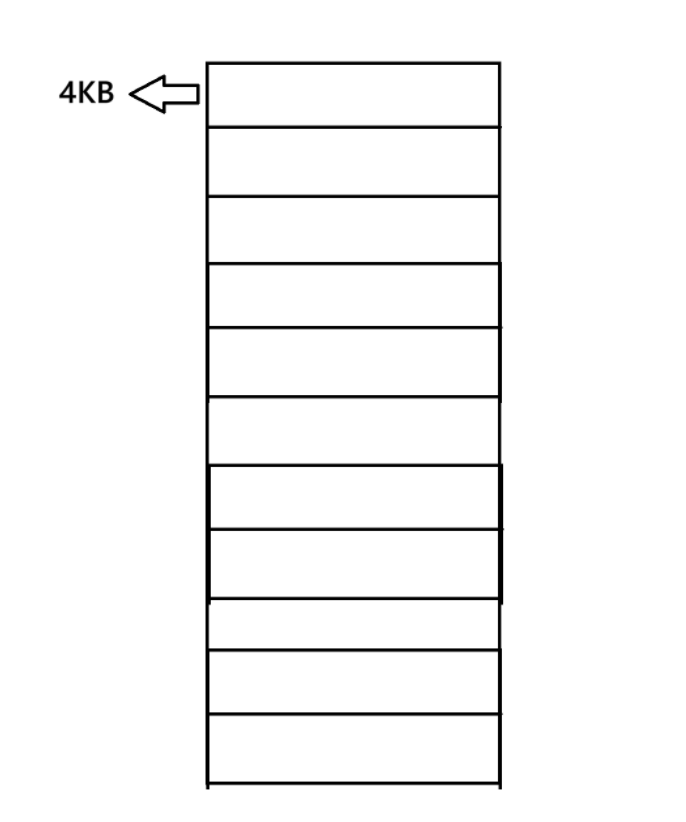
依旧是先描述再组织 ,就像是进程管理一样,Linux将每一个内存块分配给一个struct page管理 ,而在操作系统的内部有着一个struct page的数组 struct page mem_array\[\],用来管理这些struct page从而管理我们的物理内存.
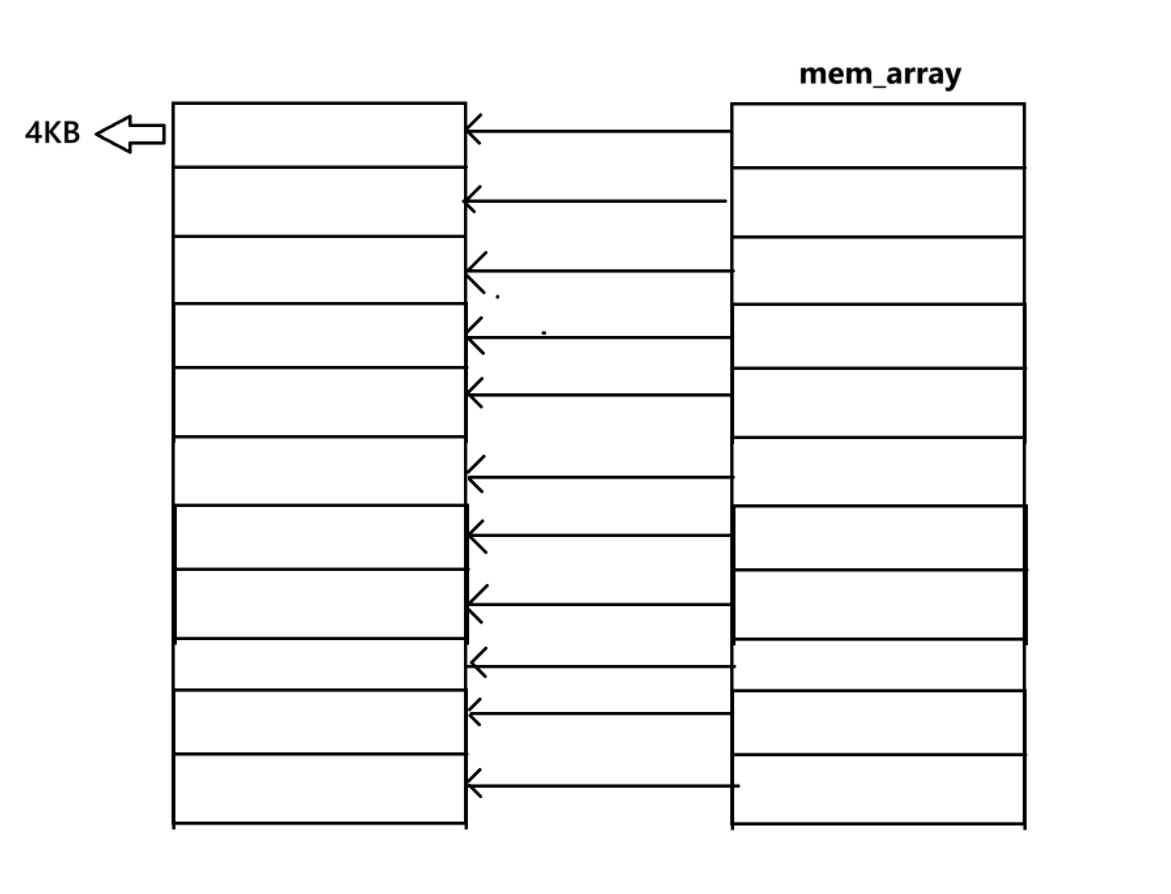
那么struct page如何找到对应的物理内存的呢? 下面我们来说说:
struct page数组个数的计算 :假设我的电脑有着4GB 的物理内存,4GB = 4 * 1024 * 1024 KB ,总页帧数 = (4 * 1024 * 1024 KB) / 4 KB= 1,048,576 个 (也就是 2^20) ,那么,struct page数组的长度就是 1,048,576,它的有效下标范围就是 0 到 1,048,575.
通过地址找到对应的struct page,从而找到对应的内存单元 :假设我得到一个一个虚拟地址通过MMU得到了映射的物理地址0x00123ABC,内核首先需要知道这个地址位于第几个物理页帧上,进行一个简单的除法:0x00123ABC / 0x1000(4KB) = 0x0012,所以这个**地址对应的物理内存页是第0x0012(十进制:1,179,648),也就是 **``struct page mem_array[1,179,648].
!IMPORTANT
内存与磁盘都是被划分为这样的最小单元存储的,当被调用的时候,操作系统会以最小单元来取存数据,哪怕你需要的是1KB的数据,也会拿出4KB的内存.
智能分配------管理员的高级存货策略
策略1:仓库分区------内存域(Zones)
管理员会根据硬件特性,把仓库分成几个大区(Zones),比如ZONE_DMA(特殊设备区)、ZONE_NORMAL(普通货区)等,以实现最高效的管理。
策略2:处理"大宗批发"------伙伴系统(Buddy System)
当程序需要一块连续的大内存时,管理员使用"伙伴系统"。它像切蛋糕一样,通过分裂和合并2的幂次方大小的内存块,来高效满足大内存请求,并能有效减少内存碎片。
策略3:处理"零售小件"------Slab分配器
当程序需要很多常用的小对象(比如几十个字节)时,伙伴系统就显得浪费了。此时,管理员会使用"Slab分配器",它像一个"零件收纳盒",预先把从伙伴系统批发来的大块内存切分成小格子,专门存放小对象,速度极快且没有浪费。
总结: 所有的内存申请动作,都是对struct page数组进行操作.
2.一个文件的"人生之旅":从打开到读写的Linux内核全景解析
我们之前讲过,每一个进程都有一个PCB,PCB里面有着一个struct files_struct *files,里面存放着一个struct file * fd_array[NR_OPEN_DEFAULT]数组,管理着此进程打开的文件.那么我们也说过,进程打开的文件会有一部分或者全部加载到内存中,那么进程如何去找到打开的这些文件的所在地呢?
这里我们要介绍一个文件的"内存缓存管理员" :address_space,address_space结构体存放file结构体中,结构如下:
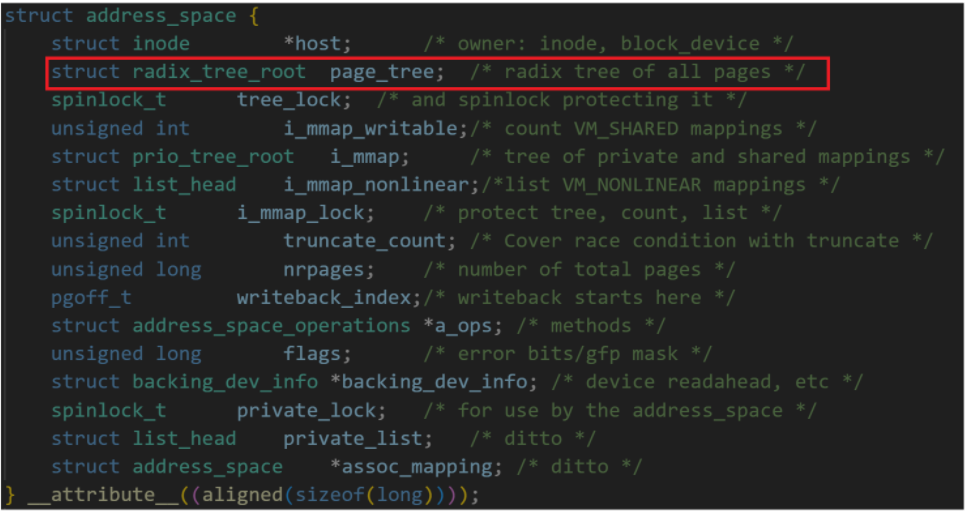
我们可以发现在address_space结构体下,有一个radix_tree_root结构体,这是一棵基树.我们进入其中.

我们进入radix_tree_root结构体中,发现存放着radix_tree_node节点,进入其中我们可以看到void *slots[RADIX_TREE_MAP_SIZE],其实这里指向的就是文件数据所在的内存块,也就是上面struct page的地址.
文件如何加载进进程?
第一步 :检查缓存 。 内核会在address_space的基数树中进行查找,判断需要的文件页是否已在页缓存(struct page)中.
情况一 :缓存未命中 。当进程调用read()时,若是内核 检查到文件没有加入到内存 中,启动IO调度,取磁盘的数据拷贝到物理内存中.
情况二 :缓存命中。 如果找到了,则直接进入下一步.
第二步: :拷贝到用户空间。 此时,数据已确保存在于页缓存中。内核会将该页帧中的数据,拷贝到进程提供的用户缓冲区中,从而完成整个读取操作.
九、静、动态库
1.GCC编译知识的复习
GCC编译有四个核心阶段:预处理 、编译 、汇编 、链接.下面我们分开详细说说.
预处理
C源码文件预处理后的文件应该由.c转化为.i
C
#include <stdio.h>
#define Test "Hello"
//Test
int main(){
printf("这是预处理测试:%s\n", Test);
return 0;
}GCC指令:
shell
# -E 选项让 GCC 在预处理结束后就停下来
# -o 指定输出文件名
gcc -E Pretreatmen.c -o Pretreatmen.i处理源代码中以 # 开头的"预处理指令".
-
宏定义展开:将 #define 定义的宏替换掉,例如将 Test 换成 "Hello"。
-
头文件包含:将 #include <stdio.h> 替换为 stdio.h 文件的实际内容。
-
条件编译:处理 #if, #ifdef, #endif 等指令。
-
删除注释:移除代码中所有的注释。
编译
将预处理后的C代码转换成汇编语言(Assembly Language)。汇编语言是与特定CPU架构相关的低级语言.
预处理文件编译后由.i文件转化为.o文件
GCC指令:
bash
# -S 选项让 GCC 在编译成汇编代码后就停下来
gcc -S Pretreatmen.i -o Pretreatmen.s
# 也可以从 .c 文件一步到位
# gcc -S Pretreatmen.c -o Pretreatmen.s汇编
将汇编代码转换成机器码(Machine Code),也就是CPU可以直接执行的二进制指令。这些指令被打包在一个叫做目标文件(Object File)的格式中.
GCC指令:
bash
# -c 选项是我们之前创建静态库时用到的,它的作用就是只编译到目标文件,不进行链接
gcc -c Pretreatmen.s -o Pretreatmen.o
# 也可以从 .c 文件一步到位
# gcc -c Pretreatmen.c -o Pretreatmen.o这个 Pretreatmen.o 文件是二进制格式的,你用文本编辑器打开会看到乱码。它包含了代码的机器码版本,但它还不是一个完整的程序。例如,它知道需要调用一个叫 printf 的函数,但它不知道 printf 的具体地址在哪里。
链接
这是最后也是最关键的一步。链接器(ld)将一个或多个目标文件(比如你的 main.o)与它们所需的库(比如我们之前做的 libmymath.a 或者系统自带的C标准库)连接起来,最终生成一个完整的可执行文件。
-
地址和符号解析:找到像 printf 这样的函数调用的实际地址,并将它们填入最终的程序中。
-
合并代码段:将所有 .o 文件中的相同部分(如代码段、数据段)合并在一起。
输入: 一个或多个目标文件 (.o) 和库文件 (.a, .so)
输出: 可执行文件 (在Windows上是 .exe,在Linux/macOS上通常没有扩展名)
今天我们要将的静、动态库就是讲的是这一步骤.
指令汇总
| 选项 | 作用 |
|---|---|
| -E | 只进行预处理。 |
| -S | 只进行预处理和编译,生成汇编代码。 |
| -c | 进行预处理、编译和汇编,生成目标文件 (.o)。 |
| -o | 指定输出文件的名称。 |
| -g | 在可执行文件中加入调试信息,用于 GDB 等调试器。 |
| -Wall | 开启大部分常用的编译警告,强烈推荐使用! |
| -I | 指定头文件 (.h) 的搜索目录。 |
| -L | 指定库文件 (.a, .so) 的搜索目录。 |
| -l | 链接指定的库,例如 -lm 表示链接数学库 libm.a。 |
2.库的命名
在Linux系统下,库的命名是有统一个格式的,这一格式在后面的程序链接库的部分尤其重要,如果库的命名不规范可能会影响库链接.
命名规则:
lib + 库名 + 后缀-
前缀 lib : 这是强制性的。所有的库文件名都必须以
lib开头。这是链接器识别库文件的一个信号. -
库的真实名称 : 这是你自己为库起的名字,比如我们之前的例子
mymath,或者像标准的数学库m、C标准库c. -
后缀(扩展名):
.a(Archive): 代表静态库..so(Shared Object): 代表动态库/共享库.(在 macOS 上,也常用 .dylib)
示例:
| 库的真实名称 | 静态库文件名 | 动态库文件名 |
|---|---|---|
| math | libmath.a | libmath.so |
| pthread | libpthread.a | libpthread.so |
| my_custom_lib | libmy_custom_lib.a | libmy_custom_lib.so |
3.静态库
1.什么是静态库?
静态库 (Static Library),在我的认知中,静态库就像是一个代码包,它包含了一系列预先编译好的目标文件(Object files),这些目标文件通常实现了一组相关的功能(比如数学计算、图形处理等).当我们在编程的时候,我们需要用到这个代码包里面的一些方法,变量,我们可以将这些需要的"工具"拷贝到我们的程序中,我们自然而然就可以用起来了.
静态库 (.a 文件)本质上就是一个或多个目标文件(.o 文件)的打包归档文件(Archive)。它本身不是可执行的,它只是一个"半成品"的原材料仓库,专门在链接阶段为链接器(Linker)提供代码。静态库中不含有main函数!
2.如何打包一个静态库?
我们上面说过,静态库.a其实就是多个.o汇编完的文件组合起来,下面我们进行模仿实现一个加减乘除的静态库.
第一步: 将我们的头文件mymath.h存入目录mylib/include.
C
//整数型加法
int add(int a, int b);
//整数型减法
int sub(int a, int b);
//整数型乘法
int mul(int a, int b);
//整数型除法
int div(int a, int b);第二步 :补充函数实现文件mymath.c存入目录mylib/lib
C
#include "mymath.h"
//整数型加法
int add(int a, int b){
return a + b;
}
//整数型减法
int sub(int a, int b){
return a - b;
}
//整数型乘法
int mul(int a, int b){
return a * b;
}
//整数型除法
int div(int a, int b){
if(b == 0){
return -1;
}
return a / b;
}好的,现在我们已经把我们写的方法的声明,已经方法的实现写好了,现在我们要开始把他们打包成一个静态库.首先我们使用Makefile来打包我们的静态库.
Makefile 位于mylib目录
makefile
#静态库名称
STATIC_NAME = libmymath.a
#obj文件名称
OBJ_NAME = mymath.o
.PHONY: all obj lib clean
all:$(STATIC_NAME)
#形成静态库
$(STATIC_NAME) : $(OBJ_NAME)
@echo "$(STATIC_NAME) making by $(OBJ_NAME)"
ar rc $(STATIC_NAME) $(OBJ_NAME)
#形成obj文件
$(OBJ_NAME): lib/mymath.c include/mymath.h
@echo "---> Compiling $< to $@"
# -c: 只编译,不链接
# -Iinclude: 指定头文件的搜索路径
gcc -c lib/mymath.c -o $(OBJ_NAME) -Iinclude
#清理文件
clean:
@ehco "cleaning ------->"
rm -f $(STATIC_NAME) $(OBJ_NAME)命令解释:
makefile
ar rc $(STATIC_NAME) $(OBJ_NAME)-
ar: 这是命令本身,是 "archiver"(归档器)的缩写。在 Linux/macOS 环境下,它被用来创建和管理静态库(也就是.a文件)。它的工作是把一堆目标文件(.o)像打包一样捆绑在一起。 -
rc: 这是传递给ar命令的两个选项(flags). -
r: 代表 "replace"(替换)。它告诉 ar,将后面列出的文件插入到归档文件中。如果归档文件中已经有了同名的文件,就用新的替换掉它. -
c: 代表 "create"(创建)。它告诉 ar,如果指定的归档文件不存在,就创建一个新的,并且不要显示警告信息. -
STATIC_NAME: 这部分是你用来指代静态库的名字libmymath.a. -
OBJ_NAME: 这是你希望添加到库里的文件。而这正是错误的关键所在。ar 工具不认识 C 语言源代码,它只认识已经被编译器处理过的二进制目标文件.
bash
[xj@iZbp1b3oqwxreih70m51j5Z mylib]$ make
---> Compiling lib/mymath.c to mymath.o
# -c: 只编译,不链接
# -Iinclude: 指定头文件的搜索路径
gcc -c lib/mymath.c -o mymath.o -Iinclude
libmymath.a making by mymath.o
ar rc libmymath.a mymath.o
[xj@iZbp1b3oqwxreih70m51j5Z mylib]$ ll
total 20
drwxrwxr-x 2 xj xj 4096 Jul 10 15:39 include
drwxrwxr-x 2 xj xj 4096 Jul 10 15:39 lib
-rw-rw-r-- 1 xj xj 1700 Jul 10 16:15 libmymath.a
-rw-rw-r-- 1 xj xj 550 Jul 10 16:15 Makefile
-rw-rw-r-- 1 xj xj 1536 Jul 10 16:15 mymath.o3.如何链接静态库
如上我们的静态库libmymath.a就创建出来了,但是我们应该如何使用他呢?下面我们先设置一个使用场景.创建main.c在目录mylib
C
#include "include/mymath.h"
#include <stdio.h>
int main(){
int a = 10;
int b = 5;
printf("a + b = %d\n", add(a, b));
printf("a - b = %d\n", sub(a, b));
printf("a * b = %d\n", mul(a, b));
printf("a / b = %d\n", div(a, b));
return 0;
}使用指令:
bash
gcc main.c -I ./include/ -L . -lmymath -o my_app命令解释:
main.c:告诉GCC我要编译的文件.
-I ./include/:告诉GCC去./include/里面找头文件.
-L .:告诉GCC库在.目录下.
-lmymath.h:告诉GCC去找一个叫mymath的静态库,也就是libmymath.a.
-o my_app:告诉GCC生成文件的名字叫my_app.
bash
[xj@iZbp1b3oqwxreih70m51j5Z mylib]$ gcc main.c -I ./include/ -L . -lmymath -o my_app
[xj@iZbp1b3oqwxreih70m51j5Z mylib]$ ll
total 36
drwxrwxr-x 2 xj xj 4096 Jul 10 15:39 include
drwxrwxr-x 2 xj xj 4096 Jul 10 15:39 lib
-rw-rw-r-- 1 xj xj 1700 Jul 10 16:15 libmymath.a
-rw-rw-r-- 1 xj xj 262 Jul 10 16:30 main.c
-rw-rw-r-- 1 xj xj 550 Jul 10 16:15 Makefile
-rwxrwxr-x 1 xj xj 8336 Jul 10 16:31 my_app
-rw-rw-r-- 1 xj xj 1536 Jul 10 16:15 mymath.o
[xj@iZbp1b3oqwxreih70m51j5Z mylib]$ ./my_app
a + b = 15
a - b = 5
a * b = 50
a / b = 2这样,我们的程序就连接上静态库了.
4.如何多个静态库一起链接?
mylib/include中加入mylog.h
C
//日志打印
void Log(char* msg);mylib/lib中加入mylog.c
C
#include "mylog.h"
#include <stdio.h>
//日志打印
void Log(char *msg){
printf("Log:%s\n", msg);
}更新Makefile
makefile
#静态库名称
STATIC_NAME_ONE = libmymath.a
STATIC_NAME_SECOND = libmylog.a
#obj文件名称
OBJ_FILE_ONE = mymath.o
OBJ_FILE_SECOND = mylog.o
.PHONY: all obj lib clean
all:$(STATIC_NAME_ONE) $(STATIC_NAME_SECOND)
#形成静态库libmymath.a
$(STATIC_NAME_ONE) : $(OBJ_FILE_ONE)
@echo "$(STATIC_NAME_ONE) making by $(OBJ_FILE_ONE)"
ar rc $(STATIC_NAME_ONE) $(OBJ_FILE_ONE)
#形成静态库libmylog.a
$(STATIC_NAME_SECOND) : $(OBJ_FILE_SECOND)
@echo "$(STATIC_NAME_SECOND) making by $(OBJ_FILE_SECOND)"
ar rc $(STATIC_NAME_SECOND) $(OBJ_FILE_SECOND)
#形成mymath obj文件
$(OBJ_FILE_ONE): lib/mymath.c include/mymath.h
@echo "---> Compiling $< to $@"
# -c: 只编译,不链接
# -Iinclude: 指定头文件的搜索路径
gcc -c lib/mymath.c -o $(OBJ_FILE_ONE) -Iinclude
#形成mylog obj文件
$(OBJ_FILE_SECOND) : lib/mylog.c include/mylog.h
@echo "---> Compiling $< to $@"
# -c: 只编译,不链接
# -Iinclude: 指定头文件的搜索路径
gcc -c lib/mylog.c -o $(OBJ_FILE_SECOND) -Iinclude
#清理文件
clean:
@echo "cleaning ------->"
rm -f *.o *.a此时我们会拥有libmymath.a、libmylog.a这两个库,下面我们写一下main.c
C
#include <stdio.h>
#include "include/mymath.h"
#include "include/mylog.h"
int main(){
int a = 10;
int b = 5;
printf("a + b = %d\n", add(a, b));
printf("a - b = %d\n", sub(a, b));
printf("a * b = %d\n", mul(a, b));
printf("a / b = %d\n", div(a, b));
Log("这是一个测试");
return 0;
}下面我们进行两个库的链接
bash
gcc main.c -I ./include -L . -lmymath -lmylog -o my_app
bash
[xj@iZbp1b3oqwxreih70m51j5Z mylib]$ ./my_app
a + b = 15
a - b = 5
a * b = 50
a / b = 2
Log:这是一个测试这里有一个更简便的Makefile,留给给位朋友研究啦~
Makefile
# 自动查找 lib 目录下的所有 .c 源文件
SRC_FILES = $(wildcard lib/*.c)
# 根据源文件自动推导 .o 目标文件列表
OBJ_FILES = $(patsubst lib/%.c,%.o,$(SRC_FILES))
# 根据源文件自动推导 .a 库文件列表
LIB_FILES = $(patsubst lib/%.c,lib%.a,$(SRC_FILES))
.PHONY: all clean
# 默认目标:构建所有找到的库文件
all: $(LIB_FILES)
# 模式规则:如何从对应的 .o 文件构建 .a 库文件
# $@ 代表目标 (如 libmymath.a),$^ 代表所有依赖 (如 mymath.o)
lib%.a: %.o
@echo "==> Archiving $@ from $^..."
ar rcs $@ $^
# 模式规则:如何从 lib/ 目录下的 .c 文件构建 .o 文件
# $< 代表第一个依赖 (如 lib/mymath.c)
%.o: lib/%.c
@echo "==> Compiling $< to $@..."
gcc -c $< -o $@ -Iinclude
# 清理规则:删除所有生成的文件
clean:
@echo "==> Cleaning up..."
rm -f *.o *.a my_app 使用到的命令总结:
1.库源文件编译成.o文件
bash
gcc -c 源文件2.打包静态库
bash
ar rc 库名字 .o文件3.静态库使用
bash
gcc 源文件 -I 头文件目录 -L 静态库目录 -l静态库名称 (链接多个库-l...) -o 编译出的文件名4.动态库
1.什么是动态库?
动态库 (Dynamic Library) 是一系列编译好的函数和变量的集合,它在程序运行时才被加载到内存中。它不像静态库那样在编译时就把代码完整地复制到最终的可执行文件中.在Linux中动态库的文件名后缀为.so.
2.动静态库的区别
- 链接的时间不同
- 静态库:静态库在程序编译的时候就跟程序链接了.
- 动态库 :程序编译的时候,会在内部记住使用到静态库的部分,在上面打一个标识,当使用到动态库里面的函数时,程序会跳转到共享区,运行动态库的代码.
- 文件大小
- 静态库: 由于静态库要把自己的函数、变量的代码加载进入程序中,所以静态链接的程序一般都比较大.
- 动态库:不需要加载代码到程序中,大小一般不大.
- 内存使用:
- 静态库:每个运行的程序都在内存中有自己的一份库代码的拷贝.
- 动态库:真正的"共享"体现在内存里。如果多个程序都用到了同一个动态库,内存中通常只需要加载一份这份库的代码,然后映射给所有需要的程序使用,极大地节省了内存.
3.如何打包一个动态库?
动态库的打包其实跟静态库差不多,但是也有细微的差别,我们在下面慢慢道来. 接下来的讲解,我们使用我们原本的mymath、mylog来讲解.对于动态库的多个链接也静态库一样,我下面就不说了.
第一步:形成.o文件
使用指令,mylib目录下进行:
bash
gcc -c ./lib/mymath.c -Iinclude -fPIC -o mymath.o这里我相信大家都认识这些命令是什么意思,但是唯一不认识 的可能就是 -fPIC ,下面我们在动态库如何链接的时候会讲到.
第二步:打包成动态库
使用指令,mylib目录下进行:
bash
gcc -shared mymath.o -o libmymath.so指令解释:
-
-shared: 告诉 GCC 生成一个共享库. -
-o libmymath.so: 输出文件名为 libmymath.so.
4.如何链接动态库?
使用指令,mylib目录下进行:
bash
gcc main.c -I ./include -L . -lmymath -o my_app**这里的指令与静态库链接的指令相同,我就不再多讲了.**通过下面的ldd指令我们可以看我们文件的链接状态
bash
[xj@iZbp1b3oqwxreih70m51j5Z mylib]$ ldd my_app
linux-vdso.so.1 => (0x00007ffe086a6000)
libmymath.so (0x00007f9643136000)
libc.so.6 => /lib64/libc.so.6 (0x00007f9642d68000)
/lib64/ld-linux-x86-64.so.2 (0x00007f9643338000)可以发现,我们已经连接上了我们的libmymath.so动态库.
5.生成的可执行文件无法运行问题解决
如果你直接运行 ./my_app,很可能会看到这个错误:
bash
./main: error while loading shared libraries: libmymath.so: cannot open shared object file: No such file or directory这是因为在编译时,-L. 只是告诉了编译器(ld) 在哪里找库。但是程序运行时,操作系统的动态链接器(ld.so) 并不知道去当前目录找 libmymath.so。注意:再版本高一点的编译器可能不会存在这个问题。
解决办法一: 库加入系统库目录
将我们的mymath.so库直接复制进入/usr/lib目录下,这是系统级库存放的地方,比如:libc.so,C语言的开发库,但是不建议这种,因为可能我们的库会对系统库进行污染。
解决办法二 :修改etc/ld.so.conf 配置文件
/etc/ld.so.conf 配置文件:这个文件包含了系统库路径的配置。你可以把你的库所在路径添加进去,然后运行 sudo ldconfig 来更新缓存。这是系统管理员安装新库的标准做法。
解决办法三: 修改LD_LIBRARY_PATH 环境变量
LD_LIBRARY_PATH 环境变量:一个由冒号分隔的路径列表,动态链接器会在此列表中的目录里查找。命令如下:
bash
export LD_LIBRARY_PATH=.:$LD_LIBRARY_PATH # 将当前目录临时加入查找路径
./main # 现在可以成功运行了这非常适合在开发和测试时临时指定库的位置,但不推荐在生产环境中使用。
解决办法四 :rpath 机制
rpath 机制:编译时硬编码在可执行文件中的路径。可以通过 -Wl,-rpath= 选项来指定。
bash
gcc main.c -o main -L. -lmymath -Wl,-rpath=.这样就把当前目录 . 硬编码到了 main 程序中,运行时它就知道来这里找库了。这种方法比较方便,适合分发独立的应用程序。
解决办法五:建立软链接
我们可以在系统库的目录下建立我们库的软链接,这样进程在系统库目录找库的时候直接找到我们的库.
6.动态库如何加载的?
我们把一个故事分为三幕:
- 第一幕:舞台的搭建 - 虚拟内存
- 第二幕:共享的道具 - 动态库的加载
- 第三幕:灵活的演员 - 位置无关代码 (PIC)
第一幕:舞台的搭建 - 虚拟内存
想象一下,我们写的任何一个程序(比如 my_app),在运行之前,都只是磁盘上一个静态的文件。它对自己将来会在计算机的哪个角落运行一无所知。
这时,操作系统这位伟大的"舞台总监"登场了。当我们要运行 my_app 时,总监做了件神奇的事:它不直接把程序扔到真实的物理内存(内存条)里,而是为它创建了一个私有的、独立的、巨大的"虚拟舞台" ,这个舞台在技术上被称为虚拟地址空间。
这个虚拟舞台有几个特点:
- 巨大且标准:在32位系统上,它的大小总是4GB(从地址0到0xFFFFFFFF)。无论你的物理内存多大,每个进程都拥有这么大的一个专属舞台。
- 私有:进程A的舞台和进程B的舞台是完全隔离的。A在自己的舞台上做什么,都不会影响到B。
- 虚幻 :这个舞台上的地址(虚拟地址)都不是真实的。CPU和我们的程序,从始至终都只工作在这个虚拟舞台上,使用虚拟地址。
那真实的物理内存在哪里呢?它就像是后台真正的仓库。操作系统手里拿着一个叫做页表 (Page Table) 的"剧本",这个剧本上精确地记录着:
"A号演员在舞台(虚拟地址)的X位置" -> "对应后台仓库(物理内存)的Y号储物格"。
通过这个剧本(页表),CPU每次需要访问一个虚拟地址时,都能被精确地引导到正确的物理内存位置。
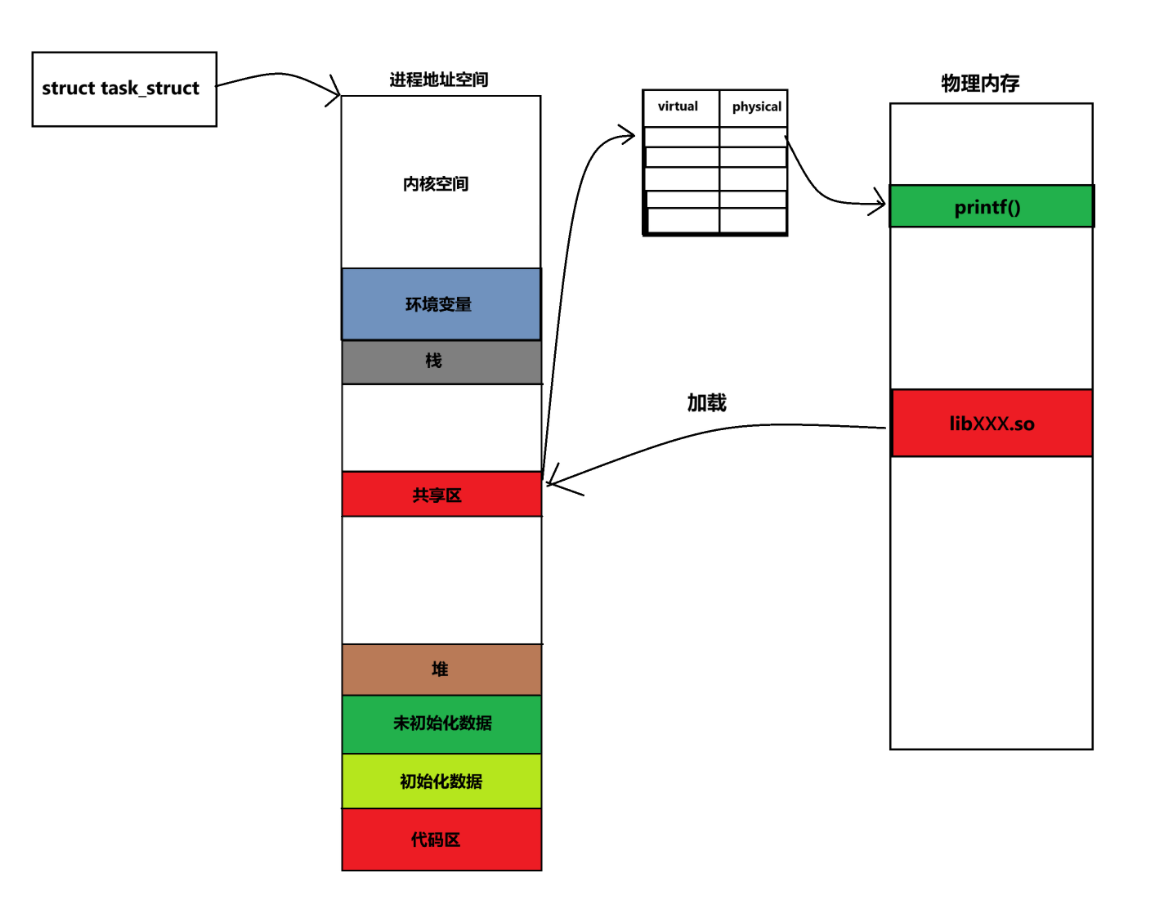
第二幕:共享的道具 - 动态库的加载
现在,舞台(虚拟地址空间)已经搭好了。我们的主角 my_app 登台了。但它发现自己需要一个常见的道具,比如一个叫 printf 的函数,这个函数存放在一个叫 libc.so 的"公共道具库"(动态库)里。
这时,如果系统里有10个程序都在运行,并且都需要 printf,难道操作系统要在物理内存这个"后台仓库"里,准备10份一模一样的 libc.so 吗?当然不,那样太浪费了。
操作系统的聪明之处在于:
- 只加载一份 :它只在物理内存 中加载一份
libc.so的实体。 - 分别映射 :然后,它修改每个进程的"剧本"(页表)。
- 在进程A的剧本里写上:将你虚拟舞台的
0xB7000000这个区域,指向物理内存里那份唯一的libc.so。 - 在进程B的剧本里写上:将你虚拟舞台的
0xB8F00000这个区域,也指向物理内存里那份唯一的libc.so。
- 在进程A的剧本里写上:将你虚拟舞台的
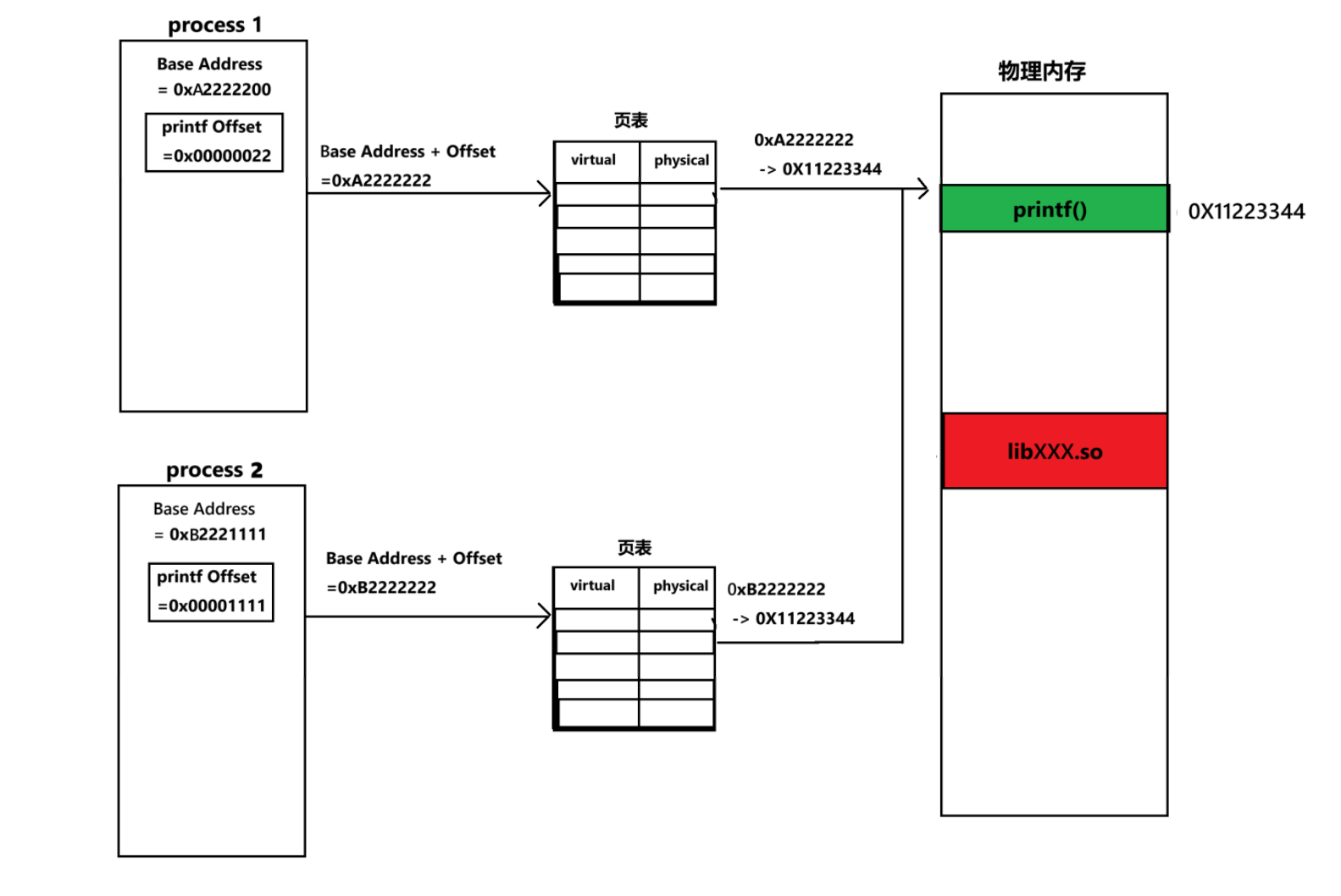
如您的第一张图所示,这就实现了内存共享 :多个进程在各自的虚拟舞台上,都以为自己独占了 libc.so,但实际上它们都被映射到了同一块物理内存。这极大地节省了系统资源。
第三幕:灵活的演员 - 位置无关代码 (PIC)
第二幕引出了一个致命的问题,这也是您第二张笔记的核心:libc.so 这个演员,在进程A的舞台上,它的起始位置是 0xB7000000;在进程B的舞台上,它的起始位置是 0xB8F00000。位置是不固定、不可预测的!
如果 libc.so 内部的代码是写死的,比如它内部一个函数调用另一个函数,指令是 jmp 0xB7001234(跳转到绝对地址)。那么这段代码在进程A中能跑,但把它原封不动地搬到进程B中就会立刻崩溃,因为进程B的 0xB7001234 地址处根本不是它要找的函数!
为了解决这个问题,我们需要一个"灵活的演员",这就是位置无关代码 (Position-Independent Code, PIC)。
PIC 的工作原理,正如您第二张图画的那样,是基于 "基地址 + 偏移量" 的思想:
- 偏移量 (Offset) :在编译
libc.so时(使用gcc -fPIC),编译器就已经算好了,库中任何一个函数或变量,相对于库文件开头的距离(偏移量)是固定不变的 。例如,printf的偏移量永远是0x1122。 - 基地址 (Base Address) :当操作系统把
libc.so加载到某个进程的虚拟地址空间时,会确定一个起始地址 ,这就是基地址。这个地址是动态变化的。
所以,无论 libc.so 被加载到哪里,当它内部需要调用 printf 时,指令不再是"跳转到某个绝对地址",而是"跳转到当前基地址 + 0x1122的位置"。
这样一来,libc.so 内部的所有代码都只关心相对位置,不关心自己的绝对坐标。它就像一个自带GPS的演员,无论被放在舞台的哪个角落,都能精准地找到自己的同伴。这就是"位置无关"的精髓。
总结:静态库为何不同?
最后,我们回头看静态库,就能瞬间明白它的不同之处了:
静态库不是一个在运行时登台的独立演员。它是在编译时 就被"肢解",然后把需要的代码片段直接缝合 到 my_app 这个主角身上了。它成为了主角的一部分。因此,它没有"被加载到不同位置"的烦恼,自然也就不需要"位置无关"这项特殊技能了。