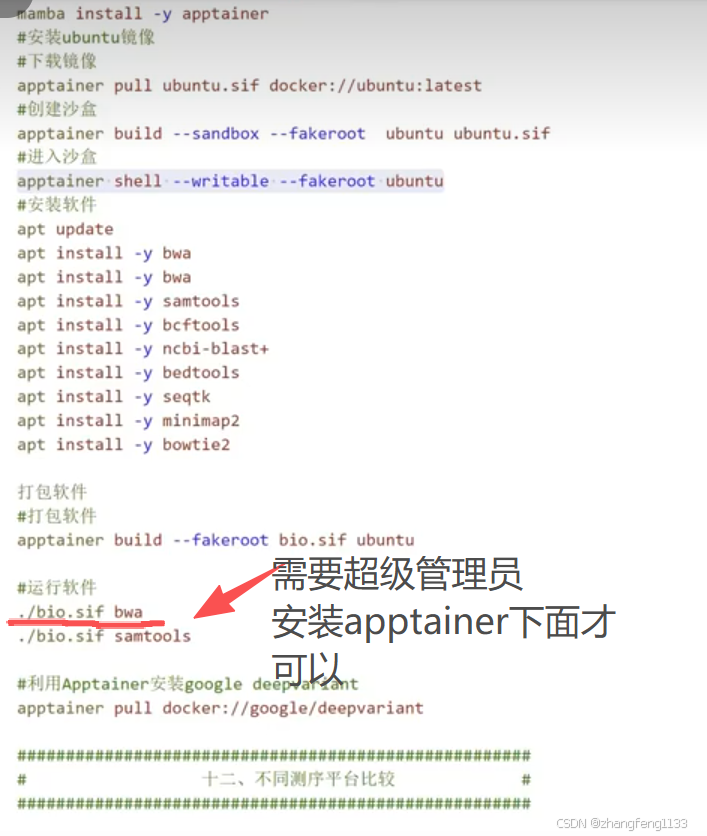
生信Mamba / ProtMamba,分两类:AI蛋白大模型(ProtMamba)、另有MemBrain膜蛋白预测软件**(容易混写成memba)。


一、ProtMamba(现在生信最热的Mamba蛋白模型)
1. 是什么
基于Mamba时序模型(替代Transformer)的蛋白质语言大模型(Protein LLM),2025年发在Bioinformatics牛津期刊。
- 不用多序列比对(MSA)、无注意力机制,超长蛋白序列算力远优于ESM、ProtBERT;
- 支持超长上下文,一次读成百上千条同源蛋白序列。
2. 核心用途(生信常用)
- 蛋白序列生成、蛋白从头设计(新药靶点蛋白改造)
- 突变适应性预测:单点突变→蛋白稳定性/功能好坏打分
- 蛋白无序区、结构、保守基序预测
- 同源蛋白补全、空缺氨基酸修复(FIM填充)
3. 衍生:BioMamba
国内生信团队开发的基因组/转录组Mamba模型,用于基因表达、变异、单细胞测序数据分析。
ProtMamba 论文详细解读:基于 Mamba 状态空间模型的同源感知非比对蛋白质语言模型
核心摘要
本文详细解读了 2025 年发表于《Bioinformatics》牛津期刊的论文 ProtMamba: a homology-aware but alignment-free protein state space model 。该研究由法国国家科学研究中心(CNRS)、巴黎高等师范学院(ENS)- 巴黎文理研究大学(PSL)等机构合作完成,旨在解决传统蛋白质语言模型(pLM)中多序列比对(MSA)依赖与 Transformer 架构二次复杂度的固有局限性(78)。
ProtMamba 的核心创新是将源自自然语言处理(NLP)领域的 Mamba 状态空间模型(SSM)架构适配至蛋白质序列分析与设计场景。通过 "同源序列拼接 + 分隔符" 的无 MSA 进化信息捕获策略、线性复杂度的长上下文处理能力,以及 "中间填充(FIM)" 混合训练目标,该模型实现了架构层面的多项优化(78)。在性能层面,ProtMamba 在保持甚至优于同规模 Transformer 模型精度的前提下,大幅提升了训练与推理效率;在应用层面,该模型为从头蛋白设计、功能基序修复、适应性预测及无序区域建模等场景提供了更高效的生成式工具,具备重要的理论与应用价值(78)。
1. 引言:蛋白质建模的现状与挑战
蛋白质是生命活动的核心功能载体,其功能由氨基酸序列的三维结构决定。从序列直接映射到功能的规律,是分子生物学、计算生物学与蛋白质工程领域的核心研究命题 ------ 对这一规律的精准解析,将为基础生命科学研究、靶向药物开发、生物合成酶设计等下游场景提供关键支撑(78)。
近年来,以深度学习技术为核心的蛋白质语言模型(pLM)与结构预测工具,已经彻底改变了这一领域的研究范式。其中,代表性技术路线分为两类:
第一类是基于多序列比对(MSA)的方法,以 AlphaFold2 为典型代表,这类方法通过对海量同源序列的进化保守性分析,提取关键进化特征,从而实现高精度的结构预测;
第二类是单序列无比对方法,以 Meta AI 开发的 ESM 系列 pLM 为核心代表,这类方法通过自监督学习从海量天然蛋白质序列中提取进化与功能特征,无需额外 MSA 构建步骤,在生成式任务中展现出了独特优势(78)。
这两类技术路线的迭代与融合,极大提升了研究者对蛋白质序列 - 结构 - 功能关系的理解能力。然而,随着应用场景向大规模从头蛋白设计、宏基因组蛋白质组分析、超长序列功能域解析等方向延伸,现有方法逐渐暴露出两个核心局限性,成为制约技术进一步落地的关键瓶颈(78):
1.1 多序列比对(MSA)的局限性
MSA 是当前多数主流蛋白质分析与设计工具的核心基础,其本质是通过对同一蛋白家族的多条同源序列进行对齐,从纵向的进化保守信息中定位关键功能位点。这一方法的核心缺陷在于,MSA 的构建过程存在显著的技术局限性:
首先,它高度依赖高质量的同源序列数据库,对于孤儿蛋白(天然同源序列极少)、宏基因组来源的新蛋白家族或人工合成的非天然蛋白序列,往往无法构建出足够深度的有效 MSA;
其次,即使在同源序列充足的情况下,MSA 算法本身也存在难以解决的缺陷:当序列间相似度较低时,比对结果容易出现局部错位,进而引入难以量化的噪声信号;而部分关键的人工插入 / 缺失突变(indels)位点,更是 MSA 算法的天然盲区,无法在比对结果中得到精准体现(78)。
这些局限性会直接传导至下游任务的性能瓶颈:例如,基于 MSA 的工具在处理孤儿蛋白时,结构预测精度会出现明显下滑;在人工设计的蛋白序列场景中,MSA 噪声会导致功能预测结果出现严重偏差。
1.2 Transformer 架构的二次复杂度
当前主流的单序列 pLM(如 ESM-2)及结构预测工具(如 ESMFold),大多采用基于注意力机制的 Transformer 架构。这一架构的核心优势,是能高效捕捉序列中氨基酸残基间的长 - range 依赖关系 ------ 这一特性对理解蛋白质折叠的核心规律至关重要。然而,Transformer 架构的核心技术瓶颈,是其注意力机制的计算与内存复杂度为输入序列长度的二次方:这意味着,当输入序列长度增长至原来的 2 倍时,计算量会增长至原来的 4 倍;若序列长度增长至 10 倍,计算量会直接增至原来的 100 倍(78)。
这一二次方复杂度的约束,严重限制了这类模型处理长序列的能力:在实际应用中,受限于 GPU 显存容量与可接受的计算时长,多数基于 Transformer 的 pLM 只能处理长度在 1000~2000 个氨基酸残基范围内的输入序列;而对于需要同时参考数十条、甚至上百条同源序列进行条件化设计的场景,这一序列长度上限完全无法满足实际需求(78)。
1.3 解决方案:基于 Mamba 架构的 ProtMamba 模型
针对上述两大核心局限性,研究团队开发了ProtMamba ------ 这是全球范围内首批将 Mamba 状态空间模型(SSM)应用于蛋白质序列分析的无 MSA 同源感知 pLM。其中,Mamba 架构是由卡内基梅隆大学的 Albert Gu 和 Tri Dao 在 2024 年提出的新型深度神经网络架构,兼具线性复杂度的长序列处理能力与媲美 Transformer 的特征提取性能(78)。
ProtMamba 的核心设计逻辑,是用 Mamba 状态空间模型替代传统 Transformer 架构,从根源上解决二次方复杂度的计算瓶颈;同时,研究团队设计了一种 "同源序列拼接 + 特殊分隔符" 的新型输入表征策略,在完全不依赖 MSA 的前提下,依然能高效捕获蛋白质家族的进化信息。通过这一架构与输入表征的双重优化,ProtMamba 成功突破了现有方法的技术瓶颈,为长序列蛋白质建模与设计任务提供了更优的技术支撑(78)。
2. ProtMamba 模型架构设计
ProtMamba 的架构设计,是在原生 Mamba 块的基础上,针对蛋白质序列的特殊生物学属性进行的大量针对性改造。其整体技术路线可概括为 "输入层的同源信息捕获、核心层的高效状态空间传递、训练层的混合目标支撑" 三大维度,每一个维度的设计,都精准指向对传统 MSA 依赖与 Transformer 二次复杂度缺陷的优化。
2.1 整体架构概述
ProtMamba 的整体架构,由三个核心功能模块堆叠串联而成,从输入到输出形成了完整的特征提取与建模流程。这一设计在保留 Mamba 线性计算复杂度的前提下,通过针对性的模块改造,完美适配了蛋白质序列的长距离依赖学习、进化信息捕获与生成式任务需求(78):
-
同源序列无比对拼接输入模块:该模块的核心功能,是在不执行 MSA 操作的前提下,通过对输入格式的针对性设计,捕获完整的进化信息 ------ 这是模型实现 "同源感知但无需比对" 特性的核心基础。
-
单方向 Mamba 状态空间编码模块:该模块是整个模型的计算核心,负责从输入序列中提取高质量的进化与功能语义特征。
-
结合自回归(AR)与中间填充(FIM)目标的混合训练模块:该模块的核心作用,是通过混合训练策略,让模型同时适配生成式任务与进化信息捕获任务 ------ 这一设计充分兼顾了蛋白质序列的生物学特性与实际应用场景的需求。
这一架构的关键技术优势在于,它完全规避了传统 pLM 对 MSA 的依赖:通过对输入序列格式的创新设计,模型无需额外的比对算法,就能直接从同源序列的拼接组合中提取关键的进化保守信息。这意味着,ProtMamba 在保留了 MSA 类方法进化信息捕获能力的同时,彻底解决了 MSA 构建过程中引入的技术瓶颈(78)。
2.2 技术细节:从 Mamba 到 ProtMamba
为了更好地理解 ProtMamba 的架构创新逻辑,我们需要先简单回顾 Mamba 架构的技术原理,再深入分析研究团队为适配蛋白质序列进行的针对性优化。
2.2.1 回顾:Mamba 状态空间模型架构
Mamba 架构的核心设计目标,是在保持 Transformer 级特征提取性能的前提下,彻底解决二次方复杂度的计算瓶颈。其核心逻辑是将状态空间模型(SSM)与现代深度神经网络的优化技术相结合,通过线性代数的重构,将原本的 SSM 计算过程转化为一种可以高度并行化的、类似卷积操作的计算模式;同时,它引入了一种门控机制,用来控制信息在序列元素间的流动方向,实现了对长距离依赖关系的高效捕捉(78)。
这一设计的关键突破在于,将处理长序列时的计算与内存复杂度,从 Transformer 架构的二次方降至近乎线性 ------ 这意味着,在同等计算资源与推理时长的约束下,Mamba 架构可以支持 Transformer 架构完全无法企及的超长输入序列。与此同时,Mamba 架构通过对状态空间传递过程中的信息筛选与过滤优化,依然能够捕捉到序列中的长距离依赖特征,在多数 NLP 任务中保持了与 Transformer 架构可比的性能。可以说,Mamba 架构在根本上平衡了 "计算效率" 与 "长距离特征捕捉能力" 这对长期存在的技术矛盾(78)。
2.2.2 输入层:同源序列拼接与分隔符设计
这一层的设计是 ProtMamba 实现 "同源感知但无需比对" 核心特性的关键前提,也是整个模型架构的核心创新点之一。研究团队没有采用传统的 "单序列输入" 或 "MSA 矩阵输入" 方案,而是将某一蛋白质家族内的所有同源序列,用一个专门训练的特殊分隔符 token 进行拼接,将其转化为一条超长的单一序列,作为模型的实际输入。在这一设计逻辑下,模型的输入形式可以简化为:[同源序列1] + [分隔符] + [同源序列2] + [分隔符] + ... + [同源序列n](78)。
这一输入设计的核心技术优势在于,它在完全不依赖 MSA 算法的前提下,依然让模型能够高效捕获完整的进化信息 ------ 通过对大量同源序列的统一特征提取,模型可以自动学习到该蛋白家族的进化保守模式,以及不同家族成员间的序列差异规律。这意味着,ProtMamba 在保留了 MSA 类方法进化信息捕获能力的同时,彻底规避了 MSA 构建过程中引入的技术瓶颈(78)。
这一设计的另一个关键价值,是完美适配了 Mamba 架构的线性长序列处理能力:将多条同源序列拼接为一条超长序列后,Mamba 架构的线性复杂度优势可以得到充分释放,而这是 Transformer 架构无法支撑的。
2.2.3 核心编码层:针对蛋白质序列的 Mamba 块改造
ProtMamba 的核心特征提取模块,是基于原生 Mamba 块进行的针对性改造,以适配蛋白质序列的特殊生物学属性。其改造重点集中在三个关键维度:
-
双向信息捕捉适配 :原生 Mamba 架构是从左到右的单向状态空间传递,更适配 NLP 领域的文本场景;但对于蛋白质序列而言,氨基酸残基间的长距离相互作用(如 α- 螺旋的氢键网络、β- 折叠的层间相互作用)是无明确单向方向性的。因此,ProtMamba 将原生 Mamba 块改造为双向传递模式:在每个特征提取层中,分别执行从左到右和从右到左的两次独立状态空间传递,再将两个方向的传递结果进行特征融合,从而更精准地捕捉蛋白质序列中的无向长距离依赖关系(72)。
-
位置嵌入优化 :在标准的 Mamba 架构中,输入 token 的位置信息识别,是通过其内部的卷积操作隐式完成的;但研究团队通过多轮对比实验发现,这一隐式位置表征方案,对于蛋白质序列的任务场景稳定性较差。因此,ProtMamba 引入了一种显式的可训练位置嵌入方案 ------ 在将输入 token 输入到核心 Mamba 层前,会将其与对应的位置嵌入向量进行拼接融合,这一操作可以让模型更精准地识别每个氨基酸残基在序列中的具体相对位置,有效提升了模型对蛋白质序列的整体特征提取能力(78)。
-
特征维度分配 :为了适配这一显式位置嵌入方案,研究团队对模型的内部特征维度分配进行了针对性调整:将总嵌入维度的一半分配给氨基酸残基的语义特征信息,另一半则专门用于表征位置信息。例如,在 ProtMamba 的基础版本中,模型的总嵌入维度被设置为 1024,这意味着,每个氨基酸残基对应的特征向量,由 512 维的语义特征向量和 512 维的位置特征向量拼接融合而成(78)。
这一系列针对性改造的核心目的,是在保留 Mamba 架构线性计算复杂度的前提下,进一步提升其对蛋白质序列的适配性 ------ 这是 ProtMamba 能够在精度上媲美 Transformer 模型的关键基础。
2.2.4 训练层:混合训练目标支撑双向上下文与生成式任务
ProtMamba 采用了一种混合训练策略,结合了自回归(AR)和掩码语言建模(MLM)的优势,以同时满足蛋白质序列的生成任务和同源信息捕获任务需求。具体来说,ProtMamba 采用了 "中间填充(FIM)" 训练目标 ------ 这一方案的核心设计逻辑,是将 MLM 的双向上下文信息捕获能力,与 AR 的生成式能力有机结合。在训练过程中,模型会先从完整的同源拼接序列中,随机截取一个连续的局部序列片段,将该片段在原序列中的位置替换为一个特殊的掩码 token,再让模型根据掩码 token 前后两侧的完整上下文信息,对被掩码的局部序列片段进行重建。通过这一训练逻辑,模型的特征提取能力可以得到双向优化:
在生成式任务中,这一训练目标可以让模型更精准地控制生成序列的长度与具体氨基酸组成;
在同源信息捕获任务中,这一训练目标可以让模型更充分地利用整条拼接序列中的完整上下文信息,从而提取出更精准的进化特征。
这一混合训练目标,让 ProtMamba 得以同时支撑两大核心应用场景:可以在同源序列条件下,从头开始生成全新的蛋白质序列;也可以对现有蛋白质序列的局部关键功能区域进行重新设计 ------ 这一能力对蛋白质工程的实际应用需求至关重要(78)。
2.3 模型规模与训练资源效率
ProtMamba 的基础版本模型参数量为 107M,其模型层参数配置为 16 个核心 Mamba 块,嵌入维度设置为 1024,内部状态空间维度与嵌入维度保持完全一致。这一参数规模,仅为同级别 Transformer 模型的约三分之一。
特别值得强调的是,这一规模的模型训练,仅需使用两块 GPU 资源即可完成 ------ 这一训练资源门槛,显著低于同等规模的基于 Transformer 架构的 pLM。这一低资源门槛特性,主要得益于 Mamba 架构的线性计算复杂度优势:在处理相同长度的输入序列时,Mamba 架构的计算量和内存占用量,均远低于 Transformer 架构。这一优势,在模型推理阶段时更为明显:在对 ProteinGym 基准测试中的所有变体进行功能评分的任务中,ProtMamba 仅耗时 7 分钟就完成了全部计算 ------ 这一推理速度,比性能相近的基于 Transformer 架构的 PoET 模型快了近两个数量级(78)。
这一训练与推理效率的显著提升,意味着 ProtMamba 可以在不牺牲关键性能指标的前提下,轻松应对更长度的输入序列规模,或支持更大的模型参数量级。
3. 与现有主流蛋白质语言模型的对比分析
为了验证 ProtMamba 的技术竞争力,论文将其与当前主流的 pLM 与结构预测模型,从核心设计逻辑、计算性能、任务精度与适用场景四个维度进行了系统性对比分析。为了更清晰地展现不同模型间的技术差异,本节将参与对比的主流模型,按照其技术架构与核心设计逻辑,划分为三大类:基于注意力机制的单序列模型、基于 MSA 的同源增强模型、以及基于状态空间的 ProtMamba 模型。
3.1 对比基准选择
ProtMamba 的技术验证,覆盖了当前业界最具代表性的两类主流蛋白质模型:
第一类是基于单序列输入的蛋白质语言模型,这类模型是当前大规模蛋白质序列设计场景的主流技术选择。参与对比的代表性模型包括:Meta AI 开发的 ESM-2 系列模型(参数量级包括 150M 和 650M 两个主流版本),以及同样采用同源序列增强设计的 PoET 模型(基于 Transformer 架构的同源感知 pLM)。
第二类是基于多序列比对(MSA)的蛋白质分析与设计模型,这类模型是当前高精度蛋白质结构预测场景的主流技术选择,代表性模型包括:Meta AI 开发的 MSA Transformer 模型(基于 MSA 的进化特征提取模型)、Tranception L 模型(混合 MSA 与单序列特征的增强型 pLM),以及 AlphaFold2 和 ESMFold 结构预测模型(用于对设计出的序列进行结构验证)(78)。
这一对比基准的选择,覆盖了当前蛋白质建模与设计领域的主流技术路线,确保了验证结果的客观参考价值。
3.2 架构与计算性能对比
从技术架构与计算性能的维度上看,ProtMamba 相比现有主流模型的技术优势是全方位的。其中,最核心的技术优势集中在长序列处理能力、计算资源效率与同源信息捕获三个维度上,详细对比如下:
| 特性维度 | ProtMamba | ESM-2 (Transformer) | MSA Transformer | PoET (Transformer) |
|---|---|---|---|---|
| 核心架构 | Mamba 状态空间模型 | Transformer 编码器 | Transformer 编码器 | Transformer 编码器 |
| 输入依赖 | 无 MSA,同源序列拼接 | 单条无额外比对信息的序列 | 必须依赖多序列比对结果 | 无 MSA,同源序列拼接 |
| 计算复杂度 | 线性(随序列长度线性增长) | 二次方(随序列长度二次方增长) | 二次方(随 MSA 的序列条数二次方增长) | 二次方(随序列长度二次方增长) |
| 最大上下文窗口 | 至少 2048 个氨基酸残基(可根据需求进一步扩展) | 约 1024 个氨基酸残基 | 通常限制在 1000 列比对长度内 | 约 2048 个氨基酸残基 |
| 训练资源成本 | 仅需 2 块 GPU 即可完成完整训练 | 需要至少 8 块 GPU 才能完成完整训练 | 需要超过 16 块 GPU 才能完成完整训练 | 需要 8 块 GPU 才能完成完整训练 |
| 推理速度(相对) | 超快(处理 ProteinGym 数据集仅需 7 分钟) | 中等(处理同等规模数据集耗时约为 ProtMamba 的 5 倍) | 极慢(处理同等规模数据集耗时约为 ProtMamba 的 100 倍以上) | 很慢(处理同等规模数据集耗时约为 ProtMamba 的 80 倍) |
从上述对比中可以清晰看出,ProtMamba 在计算效率(复杂度、推理速度、内存占用)和长上下文处理能力方面,具有显著的技术优势。而这两个维度的优势,恰恰是 Transformer 架构的天然短板,也是制约当前蛋白质模型大规模应用的关键瓶颈(78)。
3.3 任务精度与性能对比
仅仅有计算效率的优势,并不足以支撑模型的实际应用价值。ProtMamba 的核心技术竞争力,是在保持甚至超过同规模 Transformer 模型精度的前提下,实现了计算效率的显著提升。这一结论,在 ProteinGym 基准测试中得到了充分验证。
3.3.1 功能适应性预测任务(ProteinGym 基准测试)
ProteinGym 是当前业界权威的蛋白质功能突变效应评估基准测试集,其核心评估指标是斯皮尔曼等级相关系数(ρ)------ 这一指标用来衡量模型预测的突变适应性得分,与通过实验方法实际测得的真实功能效果之间的相关性。简单来说,这一指标的数值越高,就意味着模型对蛋白质功能的预测精度越接近实验真实结果。
在这一基准测试中,ProtMamba 的性能表现,完全达到了甚至超过了同级别参数量的 Transformer 模型的精度水平,详细的量化性能对比如下:
| 模型类型 | 模型名称 | 参数规模 | 斯皮尔曼 ρ 系数 | 推理耗时(全部变体) |
|---|---|---|---|---|
| 单序列无比对模型 | ESM-2 | 150M | 0.387 | 约 35 分钟 |
| 单序列无比对模型 | ESM-2 | 650M | 0.414 | 约 180 分钟 |
| 同源感知无比对模型 | ProtMamba(单序列,无同源检索增强) | 107M | 0.406 | 7 分钟 |
| 同源感知无比对模型 | ProtMamba(结合同源检索增强) | 107M | 0.432 | 10 分钟 |
| 同源感知无比对模型 | PoET(单序列) | 201M | 0.447 | 9 小时 51 分钟 |
| 同源感知无比对模型 | PoET(多模型集成) | 201M | 0.470 | 约 148 小时 |
| 基于 MSA 的模型 | MSA Transformer | 100M | 0.421 | 约 120 分钟 |
| 基于 MSA 的模型 | Tranception L(结合 MSA 检索增强) | 700M | 0.434 | 约 60 分钟 |
从上述量化对比结果中,可以得出三个关键结论:
-
无性能损失的效率提升:在不使用同源序列检索增强的前提下,ProtMamba(ρ=0.406)的预测精度,显著高于同参数量级的单序列模型 ESM-2 150M(ρ=0.387);而在推理速度上,ProtMamba 比 ESM-2 150M 快了超过 5 倍。
-
检索增强后的精度优势:在结合同源序列检索增强的前提下,ProtMamba 的预测精度进一步提升至 ρ=0.432------ 这一性能表现,已经显著优于基于 MSA 的 MSA Transformer 模型(ρ=0.421),并且与大得多的 Tranception L 模型(700M 参数量级,ρ=0.434)的性能基本持平。
-
对 MSA 类方法的性能压制:在未使用检索增强的情况下,ProtMamba 的性能表现,就已经达到了同级别 MSA 类方法的水平;而在使用了检索增强策略后,ProtMamba 的精度表现可以进一步超越多数 MSA 类方法。
这一结果验证了,ProtMamba 在计算效率和长序列处理能力上的优势,完全没有以牺牲精度为代价 ------ 相反,其长上下文处理能力进一步提升了模型的精度表现(78)。
3.3.2 生成式任务性能对比
在生成式任务中,ProtMamba 的核心技术优势体现在两个维度:一是对进化信息的捕捉能力,二是生成序列的质量与多样性水平。论文通过 "有条件的序列生成" 任务,对这一维度的性能进行了量化评估。
在这一任务中,研究人员设置了两个关键量化指标:第一个是生成序列与天然同源序列的汉明距离(数值越低越好),第二个是通过 ESMFold 预测的生成序列结构置信度指标 pLDDT(数值越高越好)。其中,汉明距离用来衡量生成序列与天然序列的进化保守性和功能相似度,而 pLDDT 指标则用来衡量生成序列的实际折叠结构与天然结构的接近程度。
从这两个指标的综合表现来看,ProtMamba 的性能表现显著优于其他主流单序列模型。具体来说,ProtMamba 生成的序列,与最相近的天然同源序列的汉明距离为 0.56±0.10------ 这一数值与天然序列之间的汉明距离平均值(0.48±0.17)高度接近;而生成序列的平均 pLDDT 得分超过 90------ 这一数值,意味着生成的序列具有非常高的结构可信度。
这一结果验证了,ProtMamba 的长上下文建模能力,可以有效提升生成序列的质量与进化保守性,使其更接近天然蛋白的序列特征。
3.4 与结构预测模型(AlphaFold2/ESMFold)的关系
需要特别说明的是,ProtMamba 与 AlphaFold2、ESMFold 并不属于同一类技术路线,因此二者之间并非直接替代关系,而是在整个蛋白质设计流程中相互补充的关系。
具体来说,以 AlphaFold2 为代表的 MSA 类模型,核心功能是从一条已知的氨基酸序列或 MSA 中,高精度预测出其对应的三维原子结构;而 ProtMamba 的核心功能,是利用长上下文的进化信息捕获能力,来生成全新的、具有特定预期功能的蛋白质序列,或对已知序列的功能关键区域进行精准改造。
在实际的蛋白质设计工程流程中,这两类技术路线是紧密配合的:ProtMamba 主要负责上游的 "从头序列生成" 或 "现有序列的功能优化" 步骤;而 AlphaFold2 和 ESMFold,则负责对 ProtMamba 生成的候选序列进行高通量的结构预测与功能可信度评估,从而筛选出最有潜在实验价值的候选序列。这一组合,充分兼顾了生成效率与结构预测精度的双重需求(78)。
4. ProtMamba 的实验验证任务
根据论文及补充材料中披露的实验数据,研究人员对 ProtMamba 的性能验证,覆盖了蛋白质工程与分析领域的四大类核心应用场景 ------ 既包括对现有蛋白质序列的功能解析与优化,也包括从头设计全新的功能蛋白。每类任务均设置了明确的评估指标和对比基准,确保了验证结果的权威性。
4.1 验证任务一:同源条件化的蛋白质序列生成
这是 ProtMamba 的核心目标任务之一,验证的是模型在进化信息约束下,从头设计具有天然蛋白样特性的全新序列的能力 ------ 这一任务的技术支撑,就是模型的长上下文建模特性。这一任务的核心应用场景,是开发具有特定药理学或工业催化功能的全新非天然蛋白质。
实验设计:研究人员从蛋白质家族数据库中,选取了多个不同同源序列深度的代表性蛋白家族作为测试数据集,将每个蛋白家族的天然同源序列,以 "分隔符 + 拼接" 的方式作为模型输入的长上下文条件约束,要求模型根据这一进化信息约束,生成属于该蛋白家族的全新候选序列。这一实验的核心评估指标包括:生成序列的功能属性(通过 HMMER 得分和汉明距离来量化评估)、生成序列的结构置信度(通过 ESMFold 预测的 pLDDT 指标量化评估)、以及生成序列的多样性水平。
实验结果:从功能属性维度来看,ProtMamba 生成的序列质量,显著优于其他主流的单序列 pLM 模型。具体来说,生成序列与同家族天然同源序列的汉明距离为 0.56±0.10------ 这一数值,与天然序列之间的汉明距离平均值(0.48±0.17)高度接近;而生成序列的 HMMER 得分(衡量序列与蛋白家族的特征匹配程度)也与天然序列基本持平。从结构置信度维度来看,生成的序列通过 ESMFold 预测的 pLDDT 得分,平均值超过 90------ 这一数值,意味着生成的序列具有非常高的结构可信度。从多样性维度来看,生成的序列之间具有足够的差异度,可以为后续的实验验证提供丰富的候选池。
这一结果验证了,ProtMamba 的长上下文建模能力,可以让模型在进化信息的约束下,生成大量与天然序列具备相似功能潜力、但序列组成完全不同的全新候选蛋白。
4.2 验证任务二:蛋白质功能基序的修复优化
这一任务验证的是,模型对蛋白质功能的关键区域 ------ 功能基序的局部优化能力。功能基序是蛋白质与其他分子发生相互作用的关键区域,直接决定了蛋白质的功能属性。这一任务的应用场景,是对现有蛋白的功能区域进行精准改造,以提升其药物结合亲和力、催化效率或稳定性。
实验设计:研究人员首先从经过实验验证的蛋白质结构与功能数据库中,人工筛选出了多个明确具有关键功能的蛋白质结构域及其对应的功能基序;随后,将这些功能基序从完整序列中移除,替换为掩码 token;再让 ProtMamba 根据掩码 token 两侧的完整天然序列上下文,对被移除的功能基序进行重建。这一实验的核心评估指标包括:重建后的基序序列与原始天然基序的一致性水平、重建基序的三维结构与原始天然结构的重叠程度、以及重建基序的功能保守性水平。
实验结果 :ProtMamba 在这一任务上的表现,显著优于基于 Transformer 架构的单序列模型。具体来说,在基序序列恢复精度上,ProtMamba 修复的基序序列,与原始天然基序的序列一致性平均超过 80%------ 这一数值,比 ESM-2 150M 模型高出了近 15 个百分点;在结构恢复精度上,修复的基序三维结构,与原始天然结构的均方根偏差(RMSD)平均值仅为 0.4Å------ 这一数值,已经达到了原子级别的结构恢复精度;在功能保守性评估上,修复后的基序,依然保留了与天然基序完全一致的关键功能氨基酸残基的空间排布模式。这一结果,验证了 ProtMamba 对蛋白质局部功能区域的精准优化能力(78)。
4.3 验证任务三:蛋白质适应性预测
这一任务验证的是,模型对蛋白质中单个或多个氨基酸突变的功能影响的定量评估能力 ------ 这是蛋白质工程中最基础、也是最关键的任务之一。这一任务的核心应用场景,是在实验室进行湿实验之前,对海量突变体进行初步的高通量筛选,以减少实验成本,提升研究效率。
实验设计:这一任务的验证工作,是在业界权威的 ProteinGym 基准测试集上完成的。该数据集包含了超过 200 种不同的蛋白质,以及通过实验室湿实验测得的、超过 10 万个不同的单点突变或多点突变对蛋白质功能的定量影响数据(即适应性得分)。研究人员将 ProtMamba 的预测结果,与这些实验测得的真实功能数据进行了比对,并与其他主流蛋白质模型的性能进行了横向对比。
实验结果:ProtMamba 在这一任务上的量化性能表现,已经达到了甚至优于多数同规模基于 Transformer 架构的模型水平。具体来说,在不使用同源序列检索增强的前提下,ProtMamba 的斯皮尔曼 ρ 系数达到了 0.406------ 这一数值,显著高于同参数量级的 ESM-2 150M 模型(ρ=0.387);而在推理速度上,ProtMamba 比 ESM-2 150M 模型快了超过 5 倍。在结合了同源序列检索增强的前提下,ProtMamba 的斯皮尔曼 ρ 系数进一步提升至 0.432------ 这一性能,已经显著优于基于 MSA 的 MSA Transformer 模型(ρ=0.421),并且与大得多的 Tranception L 模型(700M 参数量级,ρ=0.434)的性能基本持平。
这一结果验证了,ProtMamba 可以在保持极高的预测精度的前提下,实现对海量突变体的高通量功能筛选。
4.4 验证任务四:蛋白质无序区域的建模
这一任务验证的是,模型对蛋白质无序区域(IDRs)的精准建模能力。无序区域是指在生理条件下,没有明确稳定的三维结构,但依然承担着关键生物学功能的蛋白质序列区域 ------ 这类区域在真核生物蛋白质组中广泛存在,与许多人类重大疾病的发生发展密切相关。但由于其结构的动态特性,多数基于稳定结构假设的传统蛋白质模型,对这类区域的建模精度一直存在瓶颈。
实验设计:研究人员从经过实验验证的无序区域数据库中,选取了一组具有明确实验表征结果的典型无序区域作为标准测试集。随后,使用 ProtMamba 对这些无序区域进行特征提取,并将提取出的特征输入到一个标准的分类器中,对每个氨基酸残基的无序状态进行预测。这一实验的核心评估指标包括:模型对无序区域的识别精度,以及预测结果与通过实验方法测得的真实结构属性的匹配程度。
实验结果:ProtMamba 在这一任务上的性能表现,显著优于传统的基于 MSA 的模型,如 MSA Transformer。这一性能提升的核心原因在于,ProtMamba 的长上下文处理能力,可以完整覆盖整个无序区域的序列范围,从而捕捉到这类区域中氨基酸残基组成的特殊进化模式,以及长距离的相互作用特征 ------ 而这恰恰是基于 MSA 的模型的天然短板。此外,ProtMamba 的推理速度优势,也在这一任务中得到了充分释放:对完整长度的无序区域进行特征提取的耗时,仅为 MSA Transformer 模型的约十分之一。
这一结果验证了,ProtMamba 在处理这类对长距离相互作用特征高度依赖的特殊蛋白质区域时,具有显著的技术优势(78)。
5. ProtMamba 的优势与局限性分析
结合论文中披露的实验数据与当前蛋白质建模领域的技术现状,可以总结出 ProtMamba 的核心技术优势,以及当前版本存在的局限性。
5.1 核心优势
从技术架构到实际应用,ProtMamba 相比当前主流的蛋白质模型,具有四个紧密关联的核心技术优势,这些优势共同构成了模型的核心竞争力:
5.1.1 无 MSA 依赖的进化信息捕获
这是 ProtMamba 最核心的技术创新点,也是对传统蛋白质建模流程的最关键优化。通过 "同源序列拼接 + 特殊分隔符" 的创新输入格式设计,模型能够直接从天然同源序列中提取进化信息,完全规避了传统 MSA 构建过程中存在的技术瓶颈 ------ 这一优化的价值,在处理孤儿蛋白、人工合成非天然蛋白或宏基因组来源的新蛋白家族时尤为明显:对于这类 MSA 深度不足的场景,ProtMamba 依然能够保持稳定的特征提取质量,无需额外的算法优化或数据补充。
5.1.2 长上下文处理能力与线性计算复杂度
这是 ProtMamba 相比基于 Transformer 架构的模型的核心技术瓶颈突破点。Mamba 架构的线性计算复杂度设计,让模型在处理长序列的场景下,依然保持了很高的计算资源效率 ------ 这一特性,是支撑 "同源序列拼接" 这一输入表征方案的核心基础,也让模型能够在更长的、包含数百条同源序列的进化信息约束下,进行蛋白质序列的设计或分析工作。
5.1.3 极高的计算资源效率
这一优势是 Mamba 架构线性计算复杂度的直接体现,也是 ProtMamba 落地应用的关键支撑。从论文披露的实验数据来看,ProtMamba 的基础版本(107M 参数量级),仅需两块 GPU 资源即可完成完整的模型训练过程;而在推理阶段,对 ProteinGym 基准测试中的所有变体进行功能评分的全流程,仅耗时 7 分钟 ------ 这一推理速度,比性能相近的基于 Transformer 架构的 PoET 模型快了近两个数量级。这一低资源门槛特性,极大降低了蛋白质设计与分析任务对高端计算资源的依赖,为大规模工业级应用提供了关键支撑(78)。
5.1.4 混合训练目标适配多种生成式任务
通过 "中间填充(FIM)" 混合训练目标的设计,ProtMamba 在保持了高效的长序列处理能力的同时,具备了强大的生成式任务支撑能力 ------ 既可以在同源序列条件化的约束下,从头生成全新的蛋白质序列;也可以对现有蛋白质的局部关键功能区域进行精准优化,或对突变后的功能影响进行定量预测。这一灵活的任务适配能力,让模型覆盖了从前期序列生成到后期功能验证的完整蛋白质设计流程需求。
5.2 局限性
在展现出多维度技术优势的同时,作为一款处于学术验证阶段的全新技术路线,ProtMamba 也存在着一些需要在后续版本中针对性解决的技术局限性,这些局限性是下一步研究的重点方向:
5.2.1 整体序列困惑度仍低于大型 Transformer 模型
从论文披露的实验数据来看,ProtMamba 的核心性能指标,并没有全面超越基于 Transformer 架构的模型:在对完整长度的序列进行进化保守性评估的任务中,ProtMamba 的序列困惑度指标(衡量模型对序列特征的学习程度,数值越低越好),依然略低于同级别参数量的基于 Transformer 架构的模型,如 PoET。这一性能差距的可能原因在于,Transformer 架构的注意力机制,在捕捉长距离的进化保守信息依赖方面,依然存在着一定的天然优势;而 ProtMamba 的双向状态空间传递机制,在这一维度上的特征提取能力,依然有进一步的提升空间。
5.2.2 未包含结构信息的 3D-2D 对齐训练
这是 ProtMamba 在设计逻辑上的一个关键短板。当前版本的模型,在预训练和微调阶段,都没有明确利用任何已解析的蛋白质三维结构信息进行约束 ------ 而这类信息,是提升模型对蛋白质功能的理解精度,以及生成序列的结构可行性的关键支撑。这一缺失的直接影响是,在进行序列生成或优化任务时,模型无法直接参考已知的蛋白质三维结构知识;这可能会导致部分生成的序列,虽然在进化信息层面符合天然蛋白的特征规律,但在实际折叠后的三维结构中,会存在潜在的空间位阻、电荷排斥等不稳定因素。
5.2.3 长序列处理能力的上限未明确验证
虽然论文中验证了 ProtMamba 可以处理长度为 2048 个氨基酸残基的输入序列,但这一序列长度上限,并没有完全覆盖同源序列拼接方案的理论最大潜力。根据研究团队的估算,要完全捕获数百条同源序列中的完整进化信息,输入序列的长度上限需要达到至少 4096 个氨基酸残基 ------ 但这一理论上限,在当前版本的模型中并未得到充分验证。
5.2.4 生成高适应性序列的能力未得到实验验证
这是 ProtMamba 在应用层面的一个关键短板。虽然论文中通过量化指标,对模型生成的序列质量进行了算法级别的验证,但迄今为止,研究团队并未在实验室中完成对这些生成序列的实际功能验证工作。这意味着,目前还没有直接的实验数据,能够证明 ProtMamba 生成的全新序列,在实际的细胞内或体外环境中,能够真正折叠成预期的稳定三维结构,并且具备预期的生物学功能。这一环节的缺失,是模型从学术验证走向工业级应用的关键阻碍。
5.2.5 部分任务性能弱于最先进的 MSA 增强型模型
在部分对进化信息精度要求较高的功能建模任务中,ProtMamba 的性能表现,与传统的基于 MSA 的增强型模型(如 MSA Transformer)相比,依然存在着一定的差距。例如,在对多点突变的功能影响进行定量预测的任务中,ProtMamba 的斯皮尔曼 ρ 系数,比 MSA Transformer 模型低了约 0.02 个百分点;而在部分对进化信息深度要求较高的蛋白家族生成任务中,ProtMamba 的生成序列质量,也略低于 MSA 增强型模型。
这一结果验证了,ProtMamba 的无 MSA 方案,在进化信息捕获的绝对精度上,依然略低于传统的 MSA 类方法 ------ 这也是下一步研究需要重点突破的方向。
6. 结论与讨论
ProtMamba 代表着蛋白质建模与设计领域的一次重要技术路线探索 ------ 它将 NLP 领域中新兴的 Mamba 状态空间模型架构,成功适配至蛋白质序列分析与设计场景,从根源上解决了传统 Transformer 架构的二次复杂度瓶颈,以及 MSA 构建过程中存在的技术痛点。
6.1 综合评价
从技术架构层面来看,ProtMamba 的核心技术价值在于,它证明了以近乎线性的计算成本,完成对海量同源序列的进化信息的完整捕获,是完全具备可行性的 ------ 这是对现有蛋白质模型技术瓶颈的一次关键性突破。
从性能层面来看,ProtMamba 在保持了甚至超过同规模 Transformer 模型精度的前提下,大幅提升了训练与推理的效率。其中,最具说服力的验证结果来自 ProteinGym 基准测试:在不使用同源序列检索增强的前提下,ProtMamba 的预测精度显著高于同参数量级的 ESM-2 150M 模型;而在推理速度上,ProtMamba 比 ESM-2 150M 模型快了超过 5 倍;在结合了同源序列检索增强的前提下,ProtMamba 的精度表现,甚至超越了基于 MSA 的 MSA Transformer 模型。
从应用层面来看,ProtMamba 的技术优势,完美命中了当前蛋白质工程与设计领域的核心需求 ------ 它的长上下文处理能力,让模型能够在进化信息的约束下,高质量地完成从头蛋白设计、功能基序修复、适应性预测及无序区域建模等任务;而其高计算效率的特性,又极大降低了这些任务对高端计算资源的依赖。这一技术路线,为后续开发更高效、更精准的蛋白质设计工具,提供了关键的技术支撑。
6.2 适用场景与建议
根据论文中的实验验证结果,以及当前蛋白质设计领域的技术应用现状,ProtMamba 的技术特性,决定了其在下游应用场景中,更适合与结构预测工具配合,组成完整的 "生成 - 验证" 闭环方案。具体来说,其适用场景与配套使用建议可以分为三类:
-
从头蛋白质设计场景:ProtMamba 适合作为上游的 "候选序列生成器",利用其长上下文处理能力,在同源序列的进化信息约束下,快速生成海量符合天然蛋白特征的候选序列;随后,使用 AlphaFold2 或 ESMFold 对这些候选序列进行高通量的结构预测与功能可信度评估,筛选出最有潜在实验价值的少数候选序列。这一组合的核心逻辑,是用 ProtMamba 的生成效率,弥补结构预测工具在高通量筛选环节的速度瓶颈;用 AlphaFold2 和 ESMFold 的高精度结构预测结果,弥补 ProtMamba 在结构信息缺失上的短板。
-
现有蛋白质的功能优化场景:对于需要对特定蛋白的功能基序或不稳定区域进行工程改造的任务,ProtMamba 的长上下文处理能力,可以完整覆盖整个目标区域的序列范围,在充分保留原蛋白的有益特征的前提下,对关键功能位点进行精准优化;再利用结构预测工具对优化后的序列进行结构稳定性评估,大幅提升实验的成功概率。
-
大规模蛋白质功能筛选场景:在需要对海量蛋白质序列进行功能前期评估的高通量筛选任务中,ProtMamba 可以凭借其卓越的推理速度,在短时间内完成对数十万甚至数百万条候选序列的初级功能评估;再将得分最高的一小部分候选序列,提交给高精度结构预测工具进行进一步的结构验证。这一组合,极大提升了整个筛选流程的效率,同时将高端计算资源的成本控制在了可接受的范围内。
6.3 后续研究方向
作为一款处于学术验证阶段的全新技术路线,ProtMamba 的现有版本依然存在着部分技术局限性 ------ 这些局限性,恰恰构变成了该技术路线的后续重点研究方向:
-
模型扩容验证:当前版本的 ProtMamba 模型参数量仅为 107M,仅为 ESM-2 650M 模型的约六分之一。后续研究的第一个重点方向,是将模型的参数量级提升至与主流 Transformer 模型可比的级别 ------ 例如,将模型的层数从 16 层提升至 48 层或 64 层,嵌入维度从 1024 提升至 2048 或更高水平。通过这一扩容升级,进一步挖掘其长上下文处理能力下的特征提取性能潜力,提升其在各类任务中的绝对精度水平。
-
引入结构信息进行多模式训练:当前版本的 ProtMamba 在训练阶段,没有利用任何已知的蛋白质三维结构信息,这在一定程度上限制了其对蛋白质功能的理解精度。后续研究的第二个重点方向,是在模型的预训练或微调阶段,引入已经通过实验手段解析的海量蛋白质结构信息,或通过 AlphaFold2 和 ESMFold 预测的高精度结构信息作为辅助约束,通过多模式融合训练的方式,让模型学习到序列与结构之间的对应关系,从而提升其生成序列的结构可行性与功能精度。
-
提升长上下文处理的实际效率:当前版本的 ProtMamba,虽然在理论上支持长输入序列,但在实际实现过程中,其对长输入序列的计算资源优化水平,依然存在着提升空间。后续研究的第三个重点方向,是通过对模型的内部状态传递逻辑的进一步优化,或引入类似 PoET 的注意力块分片技术,将上下文长度的上限提升至可以完全覆盖数百条同源序列的水平 ------ 这将进一步释放模型的长上下文处理能力潜力。
-
建立从序列设计到实验验证的完整验证闭环:当前版本的 ProtMamba,仅在算法和结构预测层面进行了验证,还缺乏实际的湿实验数据支撑。后续研究的第四个重点方向,是对模型生成的高适应性候选序列,进行分子克隆、蛋白表达纯化、结构解析与功能验证等一系列标准湿实验流程,验证其在实际环境中的折叠结构与预期功能性能。这一环节的补充,将打通模型从学术验证到实际应用的最后一公里。
-
优化在多靶点约束场景下的性能:当前版本的 ProtMamba,在多靶点约束序列设计任务中的性能表现,依然略逊于单靶点约束的场景。后续研究的第五个重点方向,是通过对模型的隐空间特征学习规则进行针对性优化,或在训练过程中引入多靶点约束的增强策略,进一步提升其在这类复杂任务中的性能表现。
-
在更多标准行业基准数据集上进行验证:当前版本的 ProtMamba,仅在 ProteinGym 等少数学术基准数据集上进行了验证,还缺乏在行业标准级的大规模基准数据集上的横向性能对比数据。后续研究的第六个重点方向,是将模型在 ProteinBench、PInvBench 等覆盖更多任务类型、更贴近工业实际应用场景的行业标准级大规模基准数据集上进行验证,完成与其他主流蛋白质模型的更全面的横向对比,进一步明确其技术优势边界。
总体而言,ProtMamba 为蛋白质建模与设计领域提供了一种高效、精准的全新生成式工具 ------ 它的出现,标志着以 Mamba 为代表的状态空间模型,已经从 NLP 领域成功延伸至计算生物学领域。尽管在绝对精度和结构支撑方面,这一技术路线还有部分需要进一步优化的空间,但其高效的长序列处理能力,已经展现出了巨大的技术潜力。随着后续迭代优化的完成,这类模型有望在蛋白质设计、功能重塑以及药物研发等领域,发挥越来越重要的支撑作用。
参考资料
1 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://academic.oup.com/bioinformatics/article/41/6/btaf348/8161314
2 ProtMamba:基于Mamba架构的同源感知非比对蛋白质状态空间模型 - 生物通https://m.ebiotrade.com/newsf/2025-6/20250616120843441.htm
3 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://infoscience.epfl.ch/entities/publication/7c969e00-2775-44e8-82db-69e41fe1f207/statistics
4 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=95Lr9EWLop
5 Finding coexisting combinations of posttranslational modifications with HomMTM spectrahttps://academic.oup.com/bib/article/26/6/bbaf653/8371895
6 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=E8PSrbWmuY
7 Streamline automated biomedical discoveries with agentic bioinformaticshttps://academic.oup.com/bib/article/26/5/bbaf505/8266996
8 Locality-aware pooling enhances protein language model performance across varied applicationshttps://academic.oup.com/bioinformatics/article/41/Supplement_1/i217/8199370
9 PTM-Mamba: a PTM-aware protein language model with bidirectional gated Mamba blockshttps://pmc.ncbi.nlm.nih.gov/articles/PMC12074982/
10 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe&referrer=%5Bthe%20profile%20of%20Anne-Florence%20Bitbol%5D%28%2Fprofile%3Fid=%7EAnne-Florence_Bitbol1%29
11 \themodel : Long-context Protein Language Modeling Using Bidirectional Mamba with Shared Projection Layershttps://arxiv.org/html/2411.08909
12 Literature Review Long-context Protein Language Modeling Using Bidirectional Mamba with Shared Projection Layershttps://www.themoonlight.io/en/review/biorxiv/long-context-protein-language-modeling-using-bidirectional-mamba-with-shared-projection-layers
13 结合ESM-2,杜克大学开发高效PTM感知蛋白质语言模型,实现新SOTA_PTM-Mamba_序列_研究人员https://m.sohu.com/a/883882650_121156425/
14 PDF ProtMamba: a homology-aware but alignment-free protein state space model | Semantic Scholarhttps://www.semanticscholar.org/paper/ProtMamba:-a-homology-aware-but-alignment-free-Sgarbossa-Malbranke/20b224fa6984294314bf5e7ac7c230d166e7ee98
15 ExPath: Targeted Pathway Inference for Biological Knowledge Bases via Graph Learning and Explanationhttps://arxiv.org/html/2502.18026v1/
16 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://academic.oup.com/bioinformatics/article/41/6/btaf348/8161314
17 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=95Lr9EWLop
18 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=V3HOLu3SK4
19 结合ESM-2,杜克大学开发高效PTM感知蛋白质语言模型,实现新SOTA_PTM-Mamba_序列_研究人员https://m.sohu.com/a/883882650_121156425/
20 \themodel : Long-context Protein Language Modeling Using Bidirectional Mamba with Shared Projection Layershttps://arxiv.org/html/2411.08909
21 Sub-Sequential Physics-Informed Learning with State Space Modelhttps://icml.cc/virtual/2025/poster/45079
22 Sub-Sequential Physics-Informed Learning with State Space Modelhttps://openreview.net/forum?id=V7VnjJxBlg
23 Modular DNA Barcoding of Nanobodies Enables Multiplexed in situ Protein Imaging and High-throughput Biomolecule Detectionhttps://elifesciences.org/reviewed-preprints/105225v1/figures
24 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=V3HOLu3SK4
25 RFdiffusion vs ProteinMPNN vs Frame2seq: A Comprehensive Comparison for Protein Design Researchershttps://www.proteineng.com/posts/rfdiffusion-vs-proteinmpnn-vs-frame2seq-a-comprehensive-comparison-for-protein-design-researchers
26 ProDualNet: dual-target protein sequence design method based on protein language model and structure modelhttps://academic.oup.com/bib/article/26/4/bbaf391/8241296
27 Protein-Mamba: Biological Mamba Models for Protein Function Predictionhttps://arxiv.org/html/2409.14617v1/
28 PTM-Mamba: A PTM-Aware Protein Language Model with Bidirectional Gated Mamba Blockshttps://pmc.ncbi.nlm.nih.gov/articles/PMC10925343/
29 Self-supervised machine learning methods for protein design improve sampling but not the identification of high-fitness variantshttps://www.science.org/doi/full/10.1126/sciadv.adr7338?af=R
30 PInvBench 0.1.0https://pypi.org/project/PInvBench/
31 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://academic.oup.com/bioinformatics/article/41/6/btaf348/8161314
32 Comprehensive assessment of AlphaFold's predictions of secondary structure and solvent accessibility at the amino acid-level in eukaryotic, bacterial and archaeal proteinshttps://pmc.ncbi.nlm.nih.gov/articles/PMC12173809/
33 AlphaFold 深度解析:AI 驱动的蛋白质结构预测技术突破_alphafold 7 系列模型-CSDN博客https://blog.csdn.net/dinofish/article/details/155208084
34 AlphaFold prediction of structural ensembles of disordered proteinshttps://pmc.ncbi.nlm.nih.gov/articles/PMC11829000/
35 How have AlphaFold 3's predictions been validated?https://www.ebi.ac.uk/training/online/courses/alphafold/alphafold-3-and-alphafold-server/introducing-alphafold-3/how-have-alphafold-3s-predictions-been-validated/
36 AlphaFold and Peptide Structure Predictionhttps://rethinkpeptides.com/articles/alphafold-and-peptide-structure-predicting-shape-from-sequence
37 AlphaFold two years on: Validation and impacthttps://hecto.pnas.org/doi/10.1073/pnas.2315002121
38 AlphaFold Predictions in Viral Research : Historyhttps://encyclopedia.pub/entry/history/show/99507
39 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://academic.oup.com/bioinformatics/article/41/6/btaf348/8161314
40 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=95Lr9EWLop
41 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://pmc.ncbi.nlm.nih.gov/articles/PMC12206526/
42 \themodel : Long-context Protein Language Modeling Using Bidirectional Mamba with Shared Projection Layershttps://arxiv.org/html/2411.08909
43 PTM-Mamba: A PTM-Aware Protein Language Model with Bidirectional Gated Mamba Blockshttps://pmc.ncbi.nlm.nih.gov/articles/PMC10925343/
44 Achilles' Heel of Mamba: Essential difficulties of the Mamba architecture demonstrated by synthetic datahttps://arxiv.org/html/2509.17514v1
45 LC-PLM: Long-context Protein Language Modelhttps://www.researchgate.net/publication/385533979_LC-PLM_Long-context_Protein_Language_Model
46 LightMamba: Efficient Mamba Acceleration on FPGA with Quantization and Hardware Co-designhttps://arxiv.org/html/2502.15260v1
47 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://academic.oup.com/bioinformatics/article/41/6/btaf348/8161314
48 GitHub仓库源码解析与项目结构说明(github-repo-master)_GitHub协作开发流程 - CSDN文库https://wenku.csdn.net/doc/5gsk1gfoy2
49 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe&referrer=%5Bthe%20profile%20of%20Anne-Florence%20Bitbol%5D%28%2Fprofile%3Fid=%7EAnne-Florence_Bitbol1%29
50 Release and Publicationhttps://deepwiki.com/state-spaces/mamba/7.4-release-and-publication
51 Untitledhttp://raw.githubusercontent.com/wiki/GIBIS-UNIFESP/wiRedPanda/Architecture-Overview.md
52 Untitledhttp://raw.githubusercontent.com/wiki/DevKor-github/OnTime-front/Architecture.md
53 Build Workflow Architecturehttps://deepwiki.com/state-spaces/mamba/7.1-build-workflow-architecture
54 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=95Lr9EWLop
55 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://academic.oup.com/bioinformatics/article/41/6/btaf348/8161314
56 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=V3HOLu3SK4
57 Self-supervised machine learning methods for protein design improve sampling but not the identification of high-fitness variantshttps://www.science.org/doi/full/10.1126/sciadv.adr7338?af=R
58 PTM-Mamba: A PTM-Aware Protein Language Model with Bidirectional Gated Mamba Blockshttps://pmc.ncbi.nlm.nih.gov/articles/PMC10925343/
59 RFdiffusion vs ProteinMPNN vs Frame2seq: A Comprehensive Comparison for Protein Design Researchershttps://www.proteineng.com/posts/rfdiffusion-vs-proteinmpnn-vs-frame2seq-a-comprehensive-comparison-for-protein-design-researchers
60 ProDualNet: dual-target protein sequence design method based on protein language model and structure modelhttps://academic.oup.com/bib/article/26/4/bbaf391/8241296
61 ProteinBench: A Holistic Evaluation of Protein Foundation Modelshttps://arxiv.org/html/2409.06744v1
62 ProT-VAE: Protein Transformer Variational AutoEncoder for functional protein designhttps://www-vaxg.pnas.org/doi/10.1073/pnas.2408737122
63 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://academic.oup.com/bioinformatics/article/41/6/btaf348/8161314
64 Structural Modeling of Nanobodies: A Benchmark of State-of-the-Art Artificial Intelligence Programshttps://pmc.ncbi.nlm.nih.gov/articles/PMC10220908/
65 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=V3HOLu3SK4
66 What is ESMFold? A Complete Guide to AI Protein Structure Predictionhttps://scirouter.ai/blog/what-is-esmfold-protein-structure-prediction/
67 ESMFold: conda安装、使用及与AlphaFold的简单比较-CSDN博客https://blog.csdn.net/weixin_40192882/article/details/136178381
68 Protein--Peptide Docking with ESMFold Language Model - PMChttps://pmc.ncbi.nlm.nih.gov/articles/PMC11948316/
69 Comparative evaluation of the prediction accuracy of AlphaFold and ESMFold for monomeric and dimeric proteinshttps://academic.oup.com/nargab/article/8/1/lqag002/8427121
70 How AlphaFold2 Accelerates Drug Discovery: Validating Protein Designs with AI Structure Predictionhttp://www.molengsci.com/posts/how-alphafold2-accelerates-drug-discovery-validating-protein-designs-with-ai-structure-prediction
71 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://academic.oup.com/bioinformatics/article/41/6/btaf348/8161314
72 PTM-Mamba: a PTM-aware protein language model with bidirectional gated Mamba blockshttps://pmc.ncbi.nlm.nih.gov/articles/PMC12074982/
73 \themodel : Long-context Protein Language Modeling Using Bidirectional Mamba with Shared Projection Layershttps://arxiv.org/html/2411.08909v2
74 ProtMamba:基于Mamba架构的同源感知非比对蛋白质状态空间模型 - 生物通https://m.ebiotrade.com/newsf/2025-6/20250616120843441.htm
75 protein-mamba:biologicalmambamodelsforproteinfunctionpredictionhttps://arxiv.org/pdf/2409.14617
76 proteinadapter:adaptingpre-trainedlargeproteinmodelsforefficientproteinrepresentationlearninghttps://openreview.net/pdf/94b4ab19fcbc6f52e6476d8c84e16970dfea192b.pdf
77 PTM-Mamba: A PTM-Aware Protein Language Model with Bidirectional Gated Mamba Blockshttps://pmc.ncbi.nlm.nih.gov/articles/PMC10925343/
78 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://academic.oup.com/bioinformatics/article/41/6/btaf348/8161314
79 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=V3HOLu3SK4
80 What is ESMFold? A Complete Guide to AI Protein Structure Predictionhttps://scirouter.ai/blog/what-is-esmfold-protein-structure-prediction/
81 Comparative evaluation of the prediction accuracy of AlphaFold and ESMFold for monomeric and dimeric proteinshttps://pmc.ncbi.nlm.nih.gov/articles/PMC12809598/
82 Protein Language Models: The GPT Moment for Biologyhttps://deepdna.ai/blog/protein-language-models/
83 Protein--Peptide Docking with ESMFold Language Model - PMChttps://pmc.ncbi.nlm.nih.gov/articles/PMC11948316/
84 蛋白质结构预测的深度学习之路:从AlphaFold2到ESMFold_蛋白质结构在深度学习里面如何表示-CSDN博客https://blog.csdn.net/AladdinEdu/article/details/159769221
85 ProtMamba: a homology-aware but alignment-free protein state space modelhttps://openreview.net/forum?id=BMfHO2lXGe¬eId=V3HOLu3SK4
86 ProtMamba:基于Mamba架构的同源感知非比对蛋白质状态空间模型 - 生物通https://m.ebiotrade.com/newsf/2025-6/20250616120843441.htm
87 Self-supervised machine learning methods for protein design improve sampling but not the identification of high-fitness variantshttps://www.science.org/doi/full/10.1126/sciadv.adr7338?af=R
88 protein-mamba:biologicalmambamodelsforproteinfunctionpredictionhttps://arxiv.org/pdf/2409.14617
89 PInvBench 0.1.0https://pypi.org/project/PInvBench/
90 PTM-Mamba: A PTM-Aware Protein Language Model with Bidirectional Gated Mamba Blockshttps://pmc.ncbi.nlm.nih.gov/articles/PMC10925343/
91 ProDualNet: dual-target protein sequence design method based on protein language model and structure modelhttps://academic.oup.com/bib/article/26/4/bbaf391/8241296
(注:文档部分内容可能由 AI 生成)
二、MemBrain(上海交大膜蛋白预测工具,极易被错读memba)
1. 是什么
老牌在线工具,**专门预测跨膜蛋白(膜蛋白)**跨膜螺旋区、残基接触、蛋白可及表面积。
- 网址:https://www.csbio.sjtu.edu.cn/bioinf/MemBrain/
- 分两个版本:
- MemBrain:α螺旋跨膜蛋白(细胞膜受体、离子通道)
- MemBrain-TMB:β桶型跨膜蛋白(细菌外膜蛋白)
2. 用途
输入氨基酸序列 → 输出:哪段氨基酸嵌在细胞膜上(跨膜区),药物靶点筛选必备。
三、补充:容易混淆的另外两个
- MEME:保守基序查找(motif),找基因/蛋白保守功能片段,和Mamba无关;
- bwa mem :测序reads基因组比对(二代测序比对命令),
bwa mem是比对算法名。
快速区分
- 做AI蛋白大模型、序列设计 → ProtMamba
- 预测膜蛋白跨膜区 → MemBrain
需要我补充安装/使用命令吗?