单节点 Redis 再快,也会遇到三个问题:
- 单节点并发能力有上限。
- 单节点宕机会导致服务不可用。
- 单节点内存有限,无法承载海量数据。
Redis 的集群方案就是围绕这三个问题展开的:主从复制 解决读扩展,哨兵 解决自动故障恢复,分片集群解决海量数据和高并发写。
一、主从复制:读写分离
主从复制通常是一主多从。主节点负责写,从节点负责读,从而提高整体并发能力。
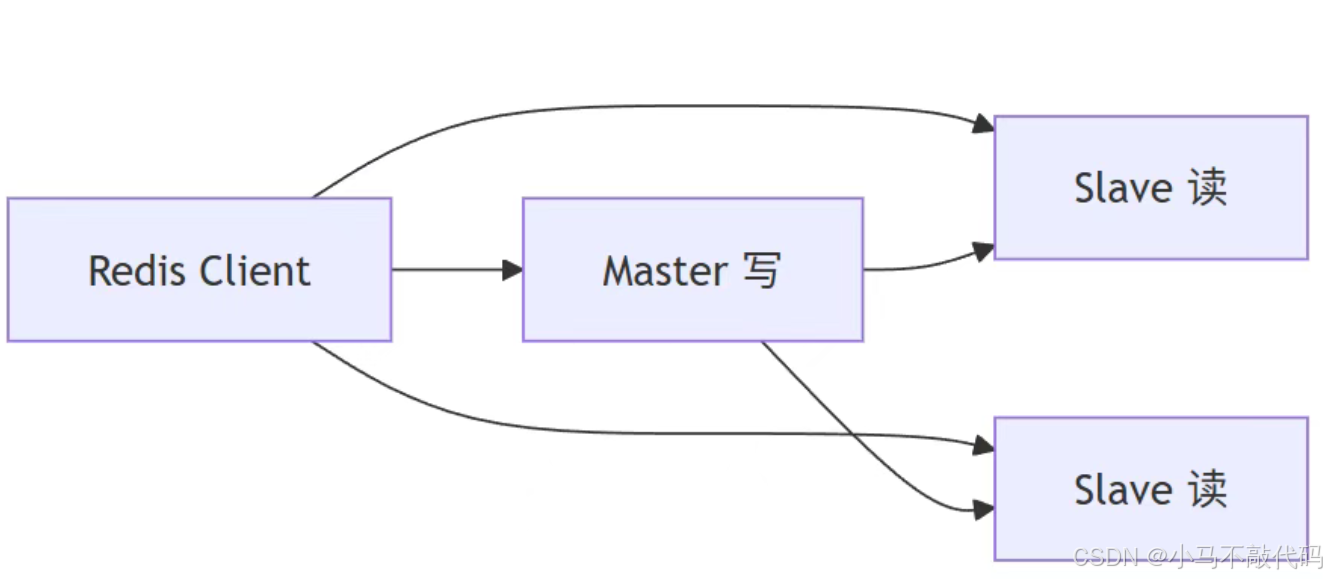
主从复制适合读多写少的场景。但它只解决读扩展,不解决 Master 宕机后的自动切换问题。
二、主从同步:全量同步和增量同步
第一次同步通常是全量同步:
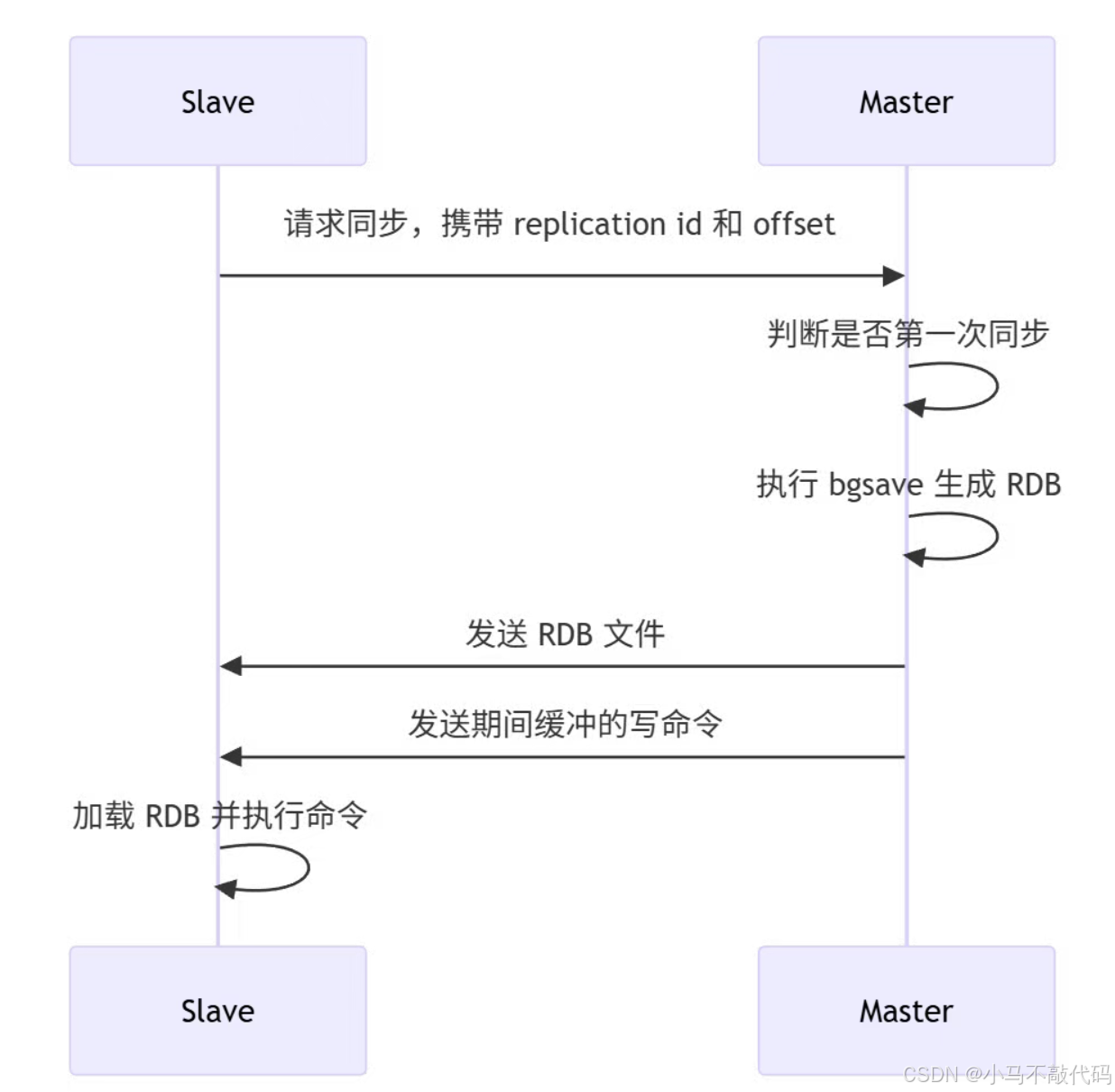
如果从节点短暂断开后重连,Master 会根据 offset 从 repl_backlog 中找到断开期间的命令,做增量同步。
三、哨兵:自动故障恢复
Sentinel 哨兵机制用于主从集群的自动故障恢复。它主要做三件事:
| 功能 | 说明 |
|---|---|
| 监控 | 定期 ping 主从节点,检查服务状态 |
| 自动故障恢复 | Master 宕机后,从 Slave 中选举新 Master |
| 通知 | 通知客户端新的 Master 地址 |
哨兵通过心跳判断节点状态:
| 状态 | 含义 |
|---|---|
| 主观下线 | 某个 Sentinel 认为节点不可用 |
| 客观下线 | 超过 quorum 数量的 Sentinel 都认为节点不可用 |
quorum 最好超过 Sentinel 实例数量的一半。
四、脑裂:为什么会出现两个 Master?
脑裂通常发生在网络分区时。老 Master 和 Sentinel 失去联系,Sentinel 认为 Master 下线,于是把某个 Slave 提升为新 Master。但客户端可能仍然能连接老 Master,并继续写入数据。
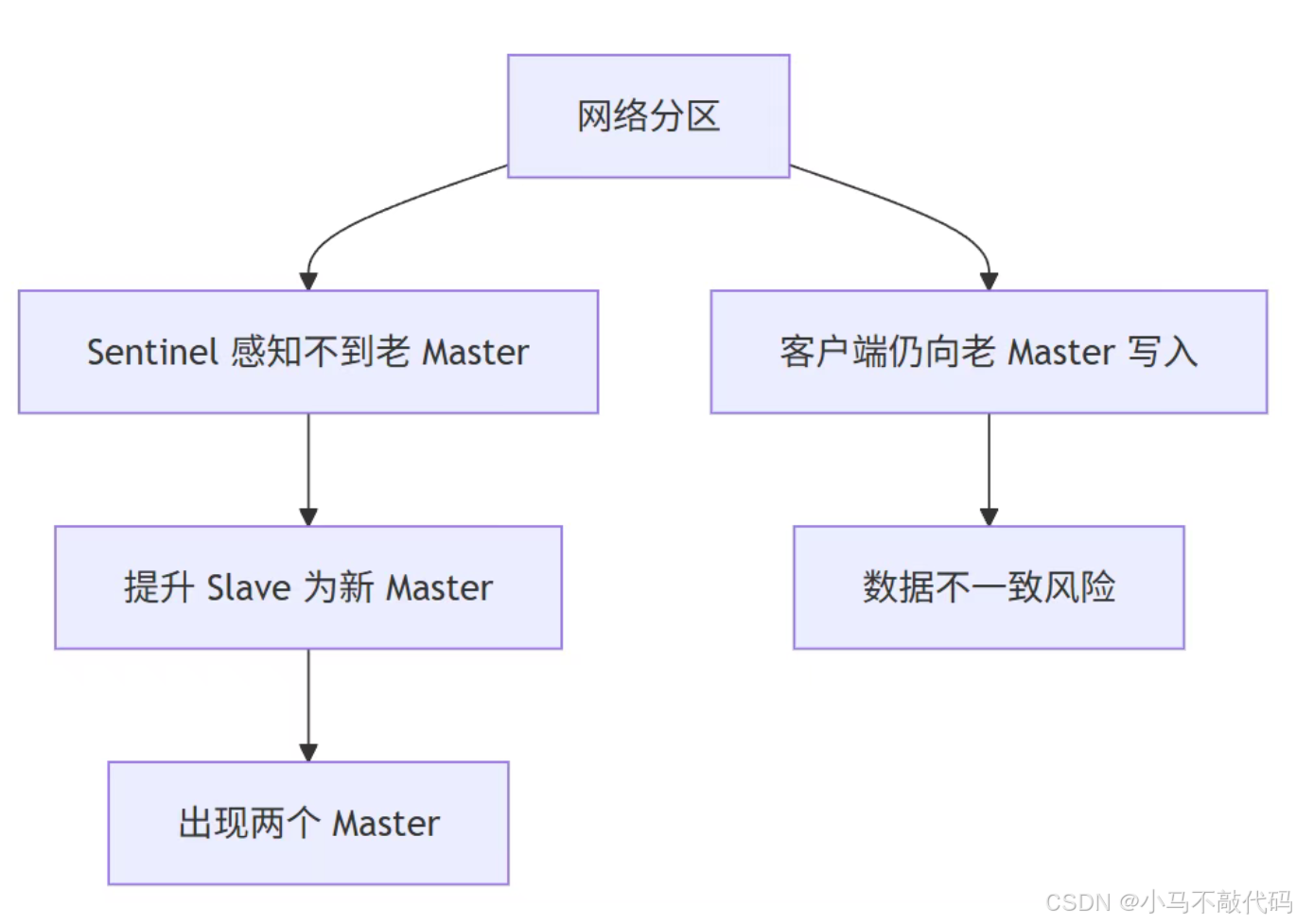
课件里给了两个配置来降低脑裂风险:
min-replicas-to-write 1min-replicas-max-lag 5
含义是:至少要有 1 个从节点,并且复制延迟不能超过 5 秒,否则 Master 拒绝写入。这样老 Master 如果和从节点失联,就不会继续接收写请求。
五、分片集群:解决海量数据和高并发写
主从和哨兵解决了高可用和高并发读,但没有解决两个问题:
- 海量数据存储。
- 高并发写。
分片集群中会有多个 Master,每个 Master 保存不同的数据,每个 Master 又可以有多个 Slave。
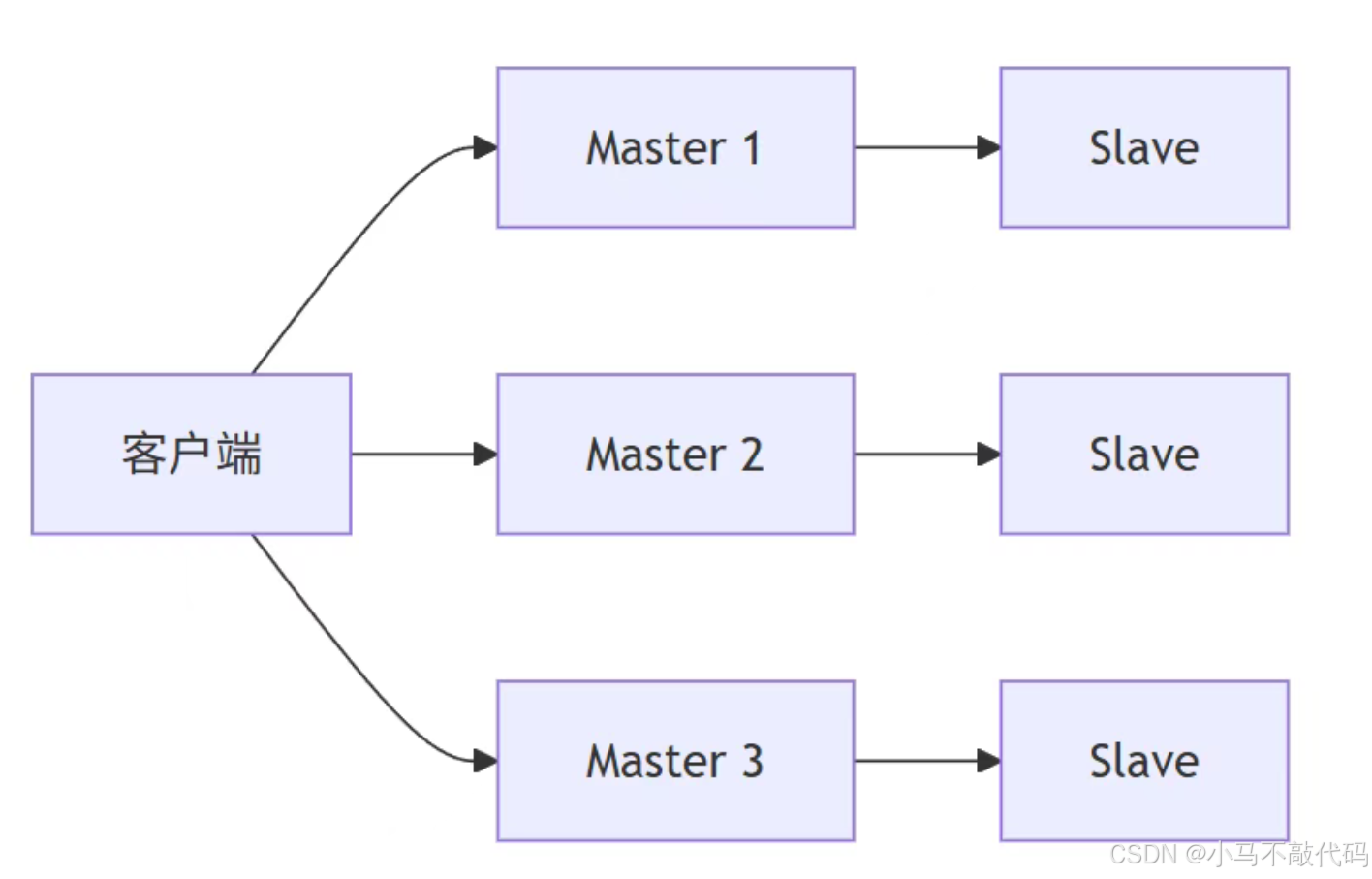
客户端可以访问集群任意节点,最终请求会被转发到正确节点。
六、哈希槽:key 到底存在哪个节点?
Redis Cluster 引入了哈希槽。整个集群有 16384 个槽,每个 key 通过 CRC16 校验后对 16384 取模,得到槽位。
slot = CRC16(key) % 16384每个 Master 负责一部分槽。例如:
| 节点 | 负责槽位 |
|---|---|
| Master 1 | 0 - 5460 |
| Master 2 | 5461 - 10922 |
| Master 3 | 10923 - 16383 |
如果 key 中有大括号,Redis 会使用大括号里的内容作为有效部分计算槽位:
user:{1001}:name
order:{1001}:list这样可以让相关 key 落到同一个槽,便于执行某些多 key 操作。
七、深入实践:Java 客户端连接与代码示例
理解了 Redis 集群的原理后,我们来看看如何在 Java 应用中实际使用这些集群方案。这里以 Jedis 和 Lettuce 两个主流客户端为例。
7.1 连接主从+哨兵集群
当使用主从+哨兵方案时,客户端需要连接哨兵节点来获取当前可用的 Master 地址。
使用 Jedis 连接哨兵集群:
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisSentinelPool;
import java.util.HashSet;
import java.util.Set;
public class SentinelExample {
public static void main(String[] args) {
// 1. 配置哨兵节点
Set<String> sentinels = new HashSet<>();
sentinels.add("192.168.1.101:26379");
sentinels.add("192.168.1.102:26379");
sentinels.add("192.168.1.103:26379");
// 2. 主节点名称(在哨兵配置中定义的 master name)
String masterName = "mymaster";
// 3. 创建哨兵连接池
JedisSentinelPool pool = new JedisSentinelPool(masterName, sentinels);
try (Jedis jedis = pool.getResource()) {
// 4. 执行操作(会自动连接到当前 Master)
jedis.set("key1", "value1");
String value = jedis.get("key1");
System.out.println("获取的值: " + value);
// 5. 模拟故障转移
// 当 Master 宕机时,哨兵会选举新的 Master
// JedisSentinelPool 会自动检测并切换到新的 Master
} finally {
pool.close();
}
}
}使用 Lettuce 连接哨兵集群:
java
import io.lettuce.core.RedisClient;
import io.lettuce.core.RedisURI;
import io.lettuce.core.api.StatefulRedisConnection;
import io.lettuce.core.api.sync.RedisCommands;
import io.lettuce.core.sentinel.api.StatefulRedisSentinelConnection;
import io.lettuce.core.sentinel.api.sync.RedisSentinelCommands;
public class LettuceSentinelExample {
public static void main(String[] args) {
// 1. 构建哨兵连接 URI
RedisURI sentinelUri = RedisURI.Builder
.sentinel("192.168.1.101", 26379, "mymaster")
.withSentinel("192.168.1.102", 26379)
.withSentinel("192.168.1.103", 26379)
.build();
// 2. 创建客户端
RedisClient client = RedisClient.create(sentinelUri);
try (StatefulRedisConnection<String, String> connection = client.connect()) {
RedisCommands<String, String> commands = connection.sync();
// 3. 执行操作
commands.set("counter", "100");
String result = commands.get("counter");
System.out.println("计数器值: " + result);
// 4. 发布订阅示例(哨兵模式下)
commands.publish("channel:updates", "系统状态更新");
} finally {
client.shutdown();
}
}
}7.2 连接 Redis Cluster 分片集群
对于分片集群,客户端需要知道所有节点地址,并自动处理哈希槽的映射和重定向。
使用 Jedis 连接 Redis Cluster:
java
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPoolConfig;
import java.util.HashSet;
import java.util.Set;
public class ClusterExample {
public static void main(String[] args) {
// 1. 配置连接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(100);
poolConfig.setMaxIdle(20);
poolConfig.setMinIdle(5);
// 2. 添加集群节点(至少一个,客户端会自动发现其他节点)
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.1.101", 7001));
nodes.add(new HostAndPort("192.168.1.102", 7002));
nodes.add(new HostAndPort("192.168.1.103", 7003));
// 3. 创建集群客户端
try (JedisCluster jedisCluster = new JedisCluster(nodes, poolConfig)) {
// 4. 基本操作(自动路由到正确的节点)
jedisCluster.set("user:1001:name", "张三");
jedisCluster.set("user:1001:age", "25");
// 5. 使用哈希标签确保相关 key 在同一个槽
jedisCluster.set("{user:1001}:profile", "{\"city\":\"北京\",\"job\":\"工程师\"}");
jedisCluster.set("{user:1001}:settings", "{\"theme\":\"dark\",\"lang\":\"zh\"}");
// 6. 批量操作(相同哈希标签的 key 可以批量操作)
String profile = jedisCluster.get("{user:1001}:profile");
System.out.println("用户资料: " + profile);
// 7. 集群信息查询
System.out.println("集群槽位分布: " + jedisCluster.clusterSlots());
} catch (Exception e) {
e.printStackTrace();
}
}
}使用 Lettuce 连接 Redis Cluster:
java
import io.lettuce.core.RedisURI;
import io.lettuce.core.cluster.RedisClusterClient;
import io.lettuce.core.cluster.api.StatefulRedisClusterConnection;
import io.lettuce.core.cluster.api.sync.RedisAdvancedClusterCommands;
import java.util.Arrays;
import java.util.List;
public class LettuceClusterExample {
public static void main(String[] args) {
// 1. 构建集群节点 URI
List<RedisURI> nodes = Arrays.asList(
RedisURI.create("redis://192.168.1.101:7001"),
RedisURI.create("redis://192.168.1.102:7002"),
RedisURI.create("redis://192.168.1.103:7003")
);
// 2. 创建集群客户端
RedisClusterClient clusterClient = RedisClusterClient.create(nodes);
try (StatefulRedisClusterConnection<String, String> connection =
clusterClient.connect()) {
RedisAdvancedClusterCommands<String, String> commands = connection.sync();
// 3. 执行跨节点操作
commands.set("product:1001:name", "iPhone 15");
commands.set("product:1001:price", "6999");
// 4. 管道操作示例(提升批量操作性能)
commands.setAutoFlushCommands(false);
commands.set("order:2024001", "pending");
commands.incr("global:order:count");
commands.expire("order:2024001", 3600);
commands.flushCommands(); // 一次性发送
// 5. 事务操作(相同哈希槽的 key)
commands.multi();
commands.set("{account:1001}:balance", "5000");
commands.decrBy("{account:1001}:balance", "1000");
commands.exec();
// 6. 集群状态监控
System.out.println("集群节点信息:");
commands.clusterNodes().forEach(System.out::println);
} finally {
clusterClient.shutdown();
}
}
}7.3 生产环境最佳实践
- 连接池配置优化
java
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(200); // 最大连接数
config.setMaxIdle(50); // 最大空闲连接
config.setMinIdle(10); // 最小空闲连接
config.setMaxWaitMillis(5000); // 获取连接最大等待时间
config.setTestOnBorrow(true); // 借出时测试连接
config.setTestWhileIdle(true); // 空闲时测试连接- 重试机制与故障处理
java
public class ResilientRedisClient {
private static final int MAX_RETRIES = 3;
public String getWithRetry(JedisCluster cluster, String key) {
int retries = 0;
while (retries < MAX_RETRIES) {
try {
return cluster.get(key);
} catch (Exception e) {
retries++;
if (retries == MAX_RETRIES) {
throw new RuntimeException("获取数据失败,重试次数耗尽", e);
}
try {
Thread.sleep(100 * retries); // 指数退避
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
}
}
return null;
}
}- 监控与告警集成
java
// 使用 Micrometer 或类似框架监控 Redis 指标
public class RedisMetrics {
private final MeterRegistry registry;
private final JedisCluster cluster;
public void recordOperation(String operation, long duration) {
Timer.builder("redis.operation.duration")
.tag("operation", operation)
.register(registry)
.record(duration, TimeUnit.MILLISECONDS);
}
public void checkClusterHealth() {
try {
String clusterInfo = cluster.clusterInfo();
// 解析集群状态,触发告警
if (clusterInfo.contains("cluster_state:fail")) {
sendAlert("Redis 集群状态异常");
}
} catch (Exception e) {
sendAlert("Redis 集群健康检查失败: " + e.getMessage());
}
}
}7.4 性能对比与选型建议
| 客户端 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Jedis | 1. API 简单直观 2. 社区成熟,文档丰富 3. 同步阻塞式,符合传统习惯 | 1. 连接非线程安全 2. 高并发需要连接池 3. 集群模式下重连逻辑较简单 | 传统 Spring 项目,中小规模并发 |
| Lettuce | 1. 基于 Netty,性能更高 2. 支持异步/响应式编程 3. 连接线程安全 4. 自动重连和拓扑刷新 | 1. 学习曲线稍陡 2. 内存占用相对较高 | 高并发微服务,Spring Boot 2.x+,需要响应式支持 |
| Redisson | 1. 分布式对象和服务丰富 2. 支持分布式锁、队列等 3. 与 Java 数据结构无缝集成 | 1. 功能复杂,较重 2. 配置相对繁琐 | 需要高级分布式功能,如分布式锁、延迟队列等 |
选型建议:
- 新项目推荐使用 Lettuce,特别是 Spring Boot 2.x 以上版本
- 老项目维护或简单场景可用 Jedis
- 需要复杂分布式数据结构时考虑 Redisson
七、怎么选集群方案?
| 场景 | 推荐方案 |
|---|---|
| 小型项目,Redis 压力不大 | 单机或一主一从 |
| 需要自动故障恢复 | 主从 + 哨兵 |
| 数据量大,写压力高 | Redis Cluster 分片集群 |
| 单节点内存超过 10G | 优先考虑拆分服务或分片 |
面试可以这样说:
Redis 集群方案主要有主从复制、哨兵和分片集群。主从复制通过读写分离提升读并发;哨兵在主从基础上增加监控、自动故障转移和通知能力;分片集群通过多个 Master 分摊数据和写压力,并通过 16384 个哈希槽决定 key 的存储位置。脑裂可以通过限制最少从节点数量和最大复制延迟来降低风险。