21 Artificial Intelligence in the Oracle AI Database(21 Oracle AI 数据库中的 AI)
本章介绍 Oracle AI 数据库中提供的人工智能功能。
- Overview of Oracle AI Vector Search(Oracle AI 向量搜索概述)
Oracle AI 向量搜索专为人工智能 (AI) 工作负载而设计,允许您基于语义而非关键字来查询数据。 - Vector Distance Metrics(向量距离度量)
度量向量空间中的距离是识别给定查询向量最相关结果的核心。该过程与关系数据库领域中众所周知的关键字过滤截然不同。 - Overview of Hierarchical Navigable Small World Indexes(层次化可导航小世界索引概述)
使用这些示例了解如何为向量近似相似性搜索创建 HNSW 索引。 - Understand Inverted File Flat Vector Indexes(了解倒排文件扁平向量索引)
倒排文件扁平向量索引是一种旨在通过使用邻居分区或簇来缩小搜索区域从而提高搜索效率的技术。 - Performing Similarity Searches(执行相似性搜索)
本节介绍执行相似性搜索的方法。
Overview of Oracle AI Vector Search(Oracle AI 向量搜索概述)
Oracle AI 向量搜索专为人工智能 (AI) 工作负载而设计,允许您基于语义而非关键字来查询数据。
VECTOR Data Type(VECTOR 数据类型)
VECTOR 数据类型随 Oracle AI Database 26ai 的发布而引入,为在数据库中将向量嵌入与业务数据一起存储提供了基础。使用嵌入模型,您可以将非结构化数据转换为向量嵌入,然后用于对业务数据进行语义查询。为了使用 VECTOR 数据类型及其相关功能,COMPATIBLE 初始化参数必须设置为 23.4.0 或更高。有关该参数及其更改方法的更多信息,请参见《Oracle AI 数据库升级指南》。
请参见以下在表定义中使用 VECTOR 数据类型的基本示例:
sql
CREATE TABLE docs (doc_id INT, doc_text CLOB, doc_vector VECTOR );有关 VECTOR 数据类型以及如何在表中使用向量的更多信息,请参见使用 VECTOR 数据类型创建表。
由于 VECTOR 数据类型的数值特性,您可以将其用作机器学习算法(如分类、异常、回归、聚类和特征提取)的输入。有关在机器学习中使用 VECTOR 数据类型的更多详细信息,请参见向量数据类型支持。
注意
从 23.7 版本开始,所有版本均支持用于机器学习的
VECTOR数据类型。
Vector Embeddings(向量嵌入)
如果您曾经使用过语音助手、聊天机器人、语言翻译器、推荐系统、异常检测或视频搜索与识别等应用程序,那么您已经隐式地使用了向量嵌入功能。
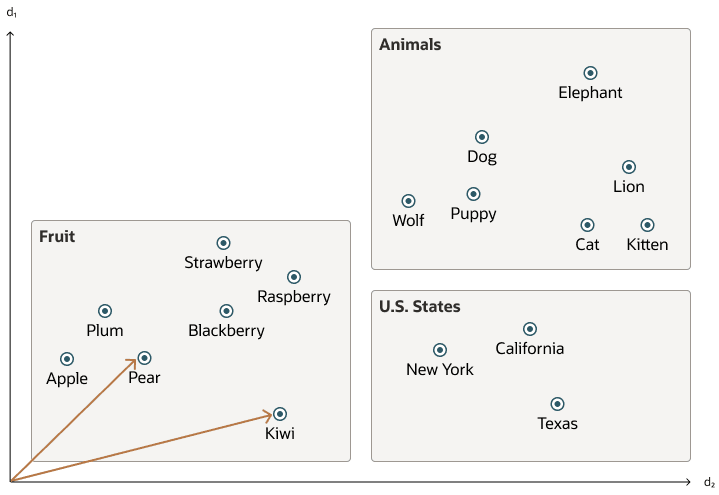
Oracle AI 向量搜索存储向量嵌入,即数据点的数学向量表示。这些向量嵌入描述了内容(如单词、文档、音轨或图像)背后的语义含义。例如,在进行基于文本的搜索时,向量搜索通常被认为优于关键字搜索,因为向量搜索基于单词背后的含义和上下文,而不是单词本身。这种向量表示将人类感知到的对象的语义相似性转化为数学向量空间中的邻近性。这个向量空间通常具有数百甚至数千个维度。换句话说,向量嵌入是一种将几乎任何类型的数据(例如文本、图像、视频、用户或音乐)表示为多维空间中的点的方法,这些点在空间中的位置以及与其他点的邻近性在语义上是有意义的。
此简化图说明了将单词编码为二维向量的向量空间。
Similarity Search(相似性搜索)
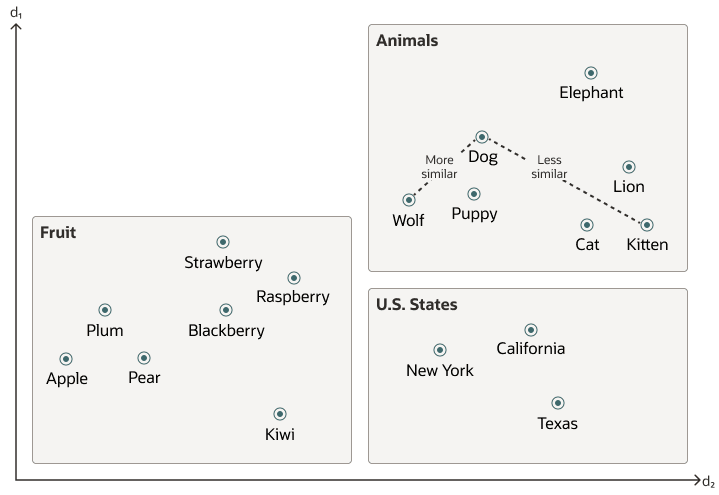
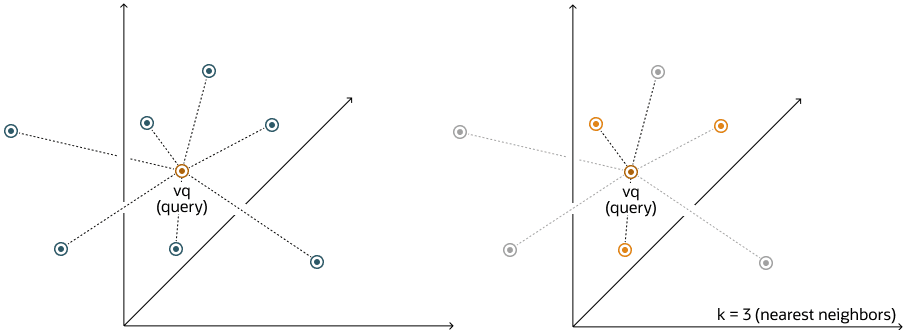
在数据集中搜索语义相似性现在等同于在向量空间中搜索最近邻居,而不是使用带有查询谓词的传统关键字搜索。如下图所示,在该向量空间中,"dog"和"wolf"之间的距离比"dog"和"kitten"之间的距离短。在这个空间中,狗与狼的相似度高于与小猫的相似度。有关更多信息,请参见执行精确相似性搜索。
向量数据往往分布不均匀,并聚类成语义相关的组。基于给定查询向量进行相似性搜索,等同于在向量空间中检索与查询向量最接近的 K 个向量。基本上,您需要通过对向量进行排名来找到一个有序的向量列表,其中列表的第一行是距离查询向量最近或最相似的向量,第二行是第二近的向量,依此类推。在进行相似性搜索时,真正重要的是距离的相对顺序,而不是实际距离。
使用前面的向量空间,这里是一个语义搜索的图示,其中您的查询向量对应于单词"Puppy",并且您想要识别四个最接近的单词:
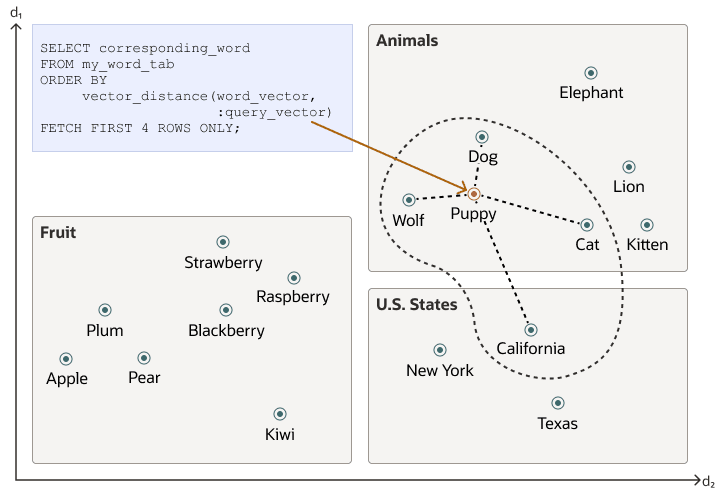
相似性搜索倾向于根据查询向量的值和获取大小从一个或多个簇中获取数据。
使用向量索引的近似搜索可以将搜索限制在特定的簇中,而精确搜索则会访问所有簇中的向量。有关更多信息,请参见使用向量索引。
Vector Embedding Models(向量嵌入模型)
创建此类向量嵌入的一种方法是使用某人的领域专业知识来量化一组预定义的特征或维度,例如形状、纹理、颜色、情感以及许多其他特征,具体取决于您正在处理的对象类型。但是,这种方法的效率取决于用例,并且并不总是具有成本效益。
相反,向量嵌入是通过神经网络创建的。大多数现代向量嵌入使用 transformer 模型,如下图所示,但也可以使用卷积神经网络。
Figure 21-1 Vector Embedding Model(图 21-1 向量嵌入模型)
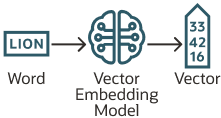
根据数据类型的不同,您可以使用不同的预训练开源模型来创建向量嵌入。例如:
- 对于文本数据,句子转换器(sentence transformers)将单词、句子或段落转换为向量嵌入。
- 对于视觉数据,您可以使用残差网络 (ResNet) 生成向量嵌入。
- 对于音频数据,您可以使用音频数据的视觉声谱图表示,将其归入视觉数据的情况。
每个模型还决定了向量的维数。例如:
- Cohere 的嵌入模型 embed-english-v3.0 有 1024 个维度。
- OpenAI 的嵌入模型 text-embedding-3-large 有 3072 个维度。
- Hugging Face 的嵌入模型 all-MiniLM-L6-v2 有 384 个维度。
当然,您始终可以创建自己的模型,并用自己的数据集进行训练。
Import Embedding Models into Oracle AI Database(将嵌入模型导入 Oracle AI 数据库)
尽管您可以使用预训练的开源嵌入模型或您自己的嵌入模型在 Oracle AI 数据库外部生成向量嵌入,但如果这些模型与开放神经网络交换 (ONNX) 标准兼容,您也可以选择将这些模型直接导入到 Oracle AI 数据库中。Oracle AI 数据库直接在数据库内部实现了 ONNX 运行时。这允许您使用 SQL 直接在 Oracle AI 数据库内生成向量嵌入。有关更多信息,请参见生成向量嵌入。
Vector Distance Metrics(向量距离度量)
度量向量空间中的距离是识别给定查询向量最相关结果的核心。该过程与关系数据库领域中众所周知的关键字过滤截然不同。
在处理向量时,有几种计算距离的方法可以用来确定两个向量有多相似或不相似。每种距离度量都是使用不同的数学公式计算的。计算两个向量之间的距离所需的时间取决于许多因素,包括所使用的距离度量以及向量本身的格式,例如向量维度的数量和向量维度格式。通常,最好将您使用的距离度量与用于训练生成这些向量的向量嵌入模型的距离度量相匹配。
Overview of Hierarchical Navigable Small World Indexes(层次化可导航小世界索引概述)
使用这些示例了解如何为向量近似相似性搜索创建 HNSW 索引。
对于可导航小世界 (NSW),其理念是构建一个邻近图,其中图中的每个向量都基于三个特征连接到其他几个向量:
- 向量之间的距离
- 在插入过程中的每一步搜索中考虑的最接近向量的候选对象的最大数量(EFCONSTRUCTION)
- 每个向量允许的最大连接数(NEIGHBORS)
如果上述阈值的组合过高,则最终可能会得到一个连接过于密集的图,这可能会减慢搜索过程。另一方面,如果这些阈值的组合过低,则图可能变得过于稀疏和/或断开连接,这使得在搜索期间难以在某些向量之间找到路径。
用于向量搜索的可导航小世界 (NSW) 图遍历从图中预定义的入口点开始,访问一组紧密相关的向量。搜索算法使用两个关键列表:Candidates,一个在遍历图时遇到的向量的动态更新列表;以及 Results,包含迄今为止找到的最接近查询向量的向量。随着搜索的进行,算法在图中导航,通过探索和评估可能比 Results 中的向量更接近的向量来不断改进 Candidates。一旦 Candidates 中没有比 Results 中最远的向量更接近的向量,该过程就结束了,这表明已到达局部最小值,并且已识别出最接近查询向量的向量。
下图对此进行了说明:
Figure 21-2 Navigable Small World Graph(图 21-2 可导航小世界图)
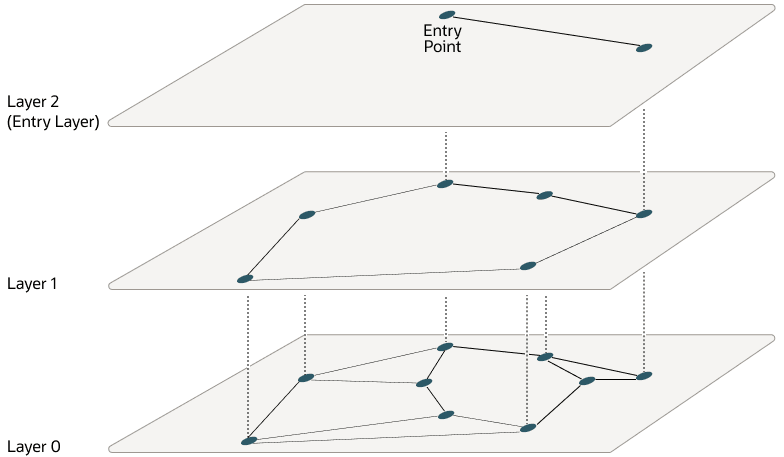
所描述的方法在向量插入图的规模达到一定程度时表现出稳健的性能。超过此阈值后,层次化可导航小世界 (HNSW) 方法通过引入多层层次结构来增强 NSW 模型,类似于在概率跳跃列表中观察到的结构。这种层次结构是通过将图的连接分布到多个层来实现的,以每个后续层包含下面一层向量子集的方式进行组织。这种分层确保了顶层能够捕获长距离链接,有效地充当横跨图的快速通道,而较低层则专注于较短链接,便于进行细粒度的局部导航。因此,搜索从较高层开始,以快速逼近目标向量所在区域,然后逐步向下移动到较低层进行更精确的搜索,通过利用从顶层到底层移动时向量之间更短的链接(更小的距离),显著提高了搜索效率和准确性。
为了更好地理解 HNSW 的工作原理,让我们看看这种层次结构如何用于概率跳跃列表结构:
Figure 21-3 Probability Skip List Structure(图 21-3 概率跳跃列表结构)
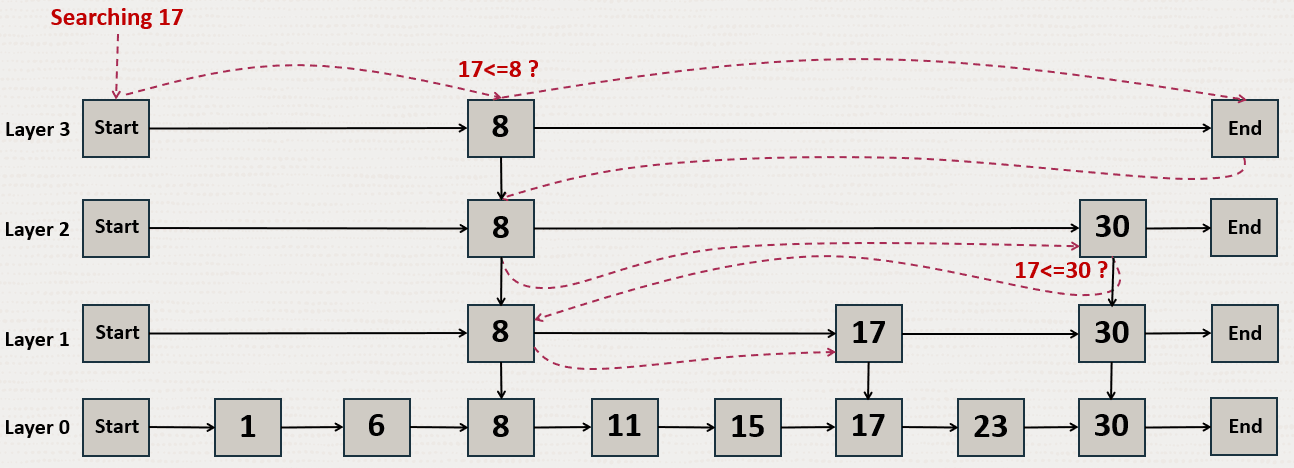
概率跳跃列表结构使用多层链表,其中上层比下层跳过更多数字。在此示例中,您尝试搜索数字 17。您从顶层开始,跳到下一个元素,直到找到 17、到达列表末尾或找到大于 17 的数字。当您到达列表末尾或找到大于 17 的数字时,则从最近一个小于 17 的数字开始回到前一层。
HNSW 在 NSW 层上使用相同的原理,在较高层中您会发现向量之间的距离更大。以下图表在二维空间中说明了这一点:
在顶层是长边,在底层是短边。
Figure 21-4 Hierarchical Navigable Small World Graphs(图 21-4 层次化可导航小世界图)
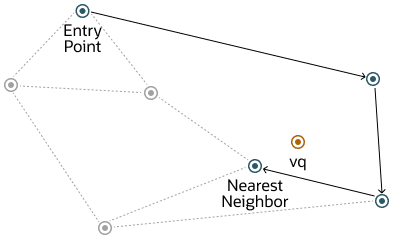
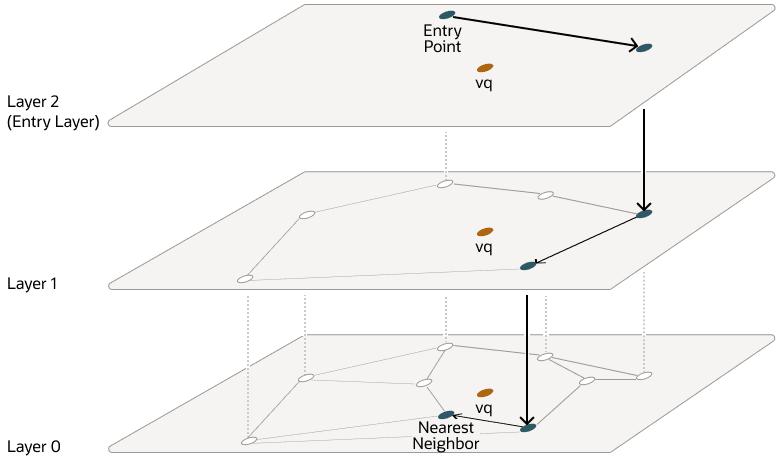
从顶层开始,每一层的搜索都从入口向量开始。然后对于每个节点,如果存在一个比当前节点更接近查询向量的邻居,则跳转到该邻居。算法会持续此过程,直到找到查询向量的局部最小值。当在一个层中找到局部最小值后,搜索会通过使用新层中的相同向量进入下一层,并在该层中继续搜索。这个过程重复进行,直到找到包含所有向量的底层的局部最小值为止。此时,搜索转变为近似相似性搜索,使用 NSW 算法围绕最新找到的局部最小值,提取与查询向量最相似的前 k 个向量。上层的每个向量连接数最大可由 NEIGHBORS 参数设置,而第 0 层可以有此数量的两倍。此过程如下图所示:
Figure 21-5 Hierarchical Navigable Small World Graphs Search(图 21-5 层次化可导航小世界图搜索)
层是使用内存中图形(而非 Oracle 内存中图形)实现的。每个层使用一个独立的内存中图形。如前所述,在创建 HNSW 索引时,您可以使用 NEIGHBORS 参数来微调上层中每个向量的最大连接数,也可以使用 EFCONSTRUCTION 参数来设置插入过程中的每一步搜索中考虑的最接近向量候选对象的最大数量,其中 EF 代表 Enter Factor。
如前所述,在使用 Oracle AI 向量搜索通过 HNSW 索引运行近似搜索查询时,您可以指定执行近似搜索的目标精度。
对于 HNSW 近似搜索,您可以指定一个目标精度百分比值来影响用于探测搜索的候选对象数量。这是由算法自动计算的。值为 100 时,将倾向于产生与精确搜索类似的结果,尽管系统可能仍会使用索引,不会执行精确搜索。优化器可能会选择仍然使用索引,因为考虑到查询中的谓词,这样做可能更快。除了指定目标精度百分比值,您还可以指定 EFSEARCH 参数,以限制在探测索引时要考虑的最大候选对象数量。该数值越高,精度越高。
注意
- 如果您在近似搜索查询中未指定任何目标精度,那么您将继承在创建索引时设置的目标精度。您将看到,在索引创建时,您可以根据要创建的索引类型,通过百分比值或参数值来指定目标精度。
- 可以在索引搜索时指定不同于索引创建时设置的目标精度。对于 HNSW 索引,您可以使用
EFSEARCH参数(高于索引创建时指定的EFCONSTRUCTION值)查看更多的邻居,以获得更准确的结果。您在索引创建期间给出的目标精度决定了索引创建参数,并作为向量索引搜索的默认精度值。
Understand Inverted File Flat Vector Indexes(了解倒排文件扁平向量索引)
倒排文件扁平向量索引是一种旨在通过使用邻居分区或簇来缩小搜索区域从而提高搜索效率的技术。
下图描绘了在使用二维空间表示法进行的近似搜索中,分区或簇是如何创建的。但这可以推广到更高维度的空间。
Figure 21-6 Inverted File Flat Index Using 2D(图 21-6 使用二维的倒排文件扁平索引)
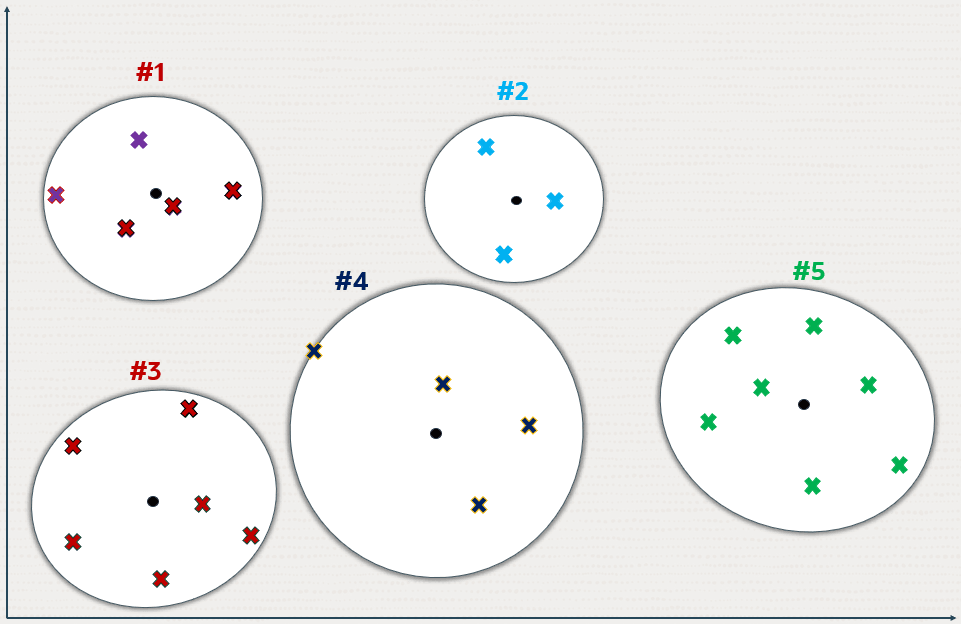
十字代表此空间中的向量数据点。
添加新的数据点(显示为小的空心圆)来识别 k 个分区质心,其中质心的数量 (k) 由数据集的大小 (n) 决定。通常,k 设置为 n 的平方根,尽管可以在索引创建期间通过指定 NEIGHBOR PARTITIONS 参数进行调整。
每个质心代表相应分区的平均向量(重心)。质心是通过对向量进行一次训练传递来计算的,其目标是最小化每个向量到最近质心的总距离。
质心最终将向量空间划分为 k 个分区。这种划分在概念上被说明为从质心开始不断扩大的圆圈,当它们相遇时停止增长,形成不同的分区。
Figure 21-7 Inverted File Flat Index(图 21-7 倒排文件扁平索引)
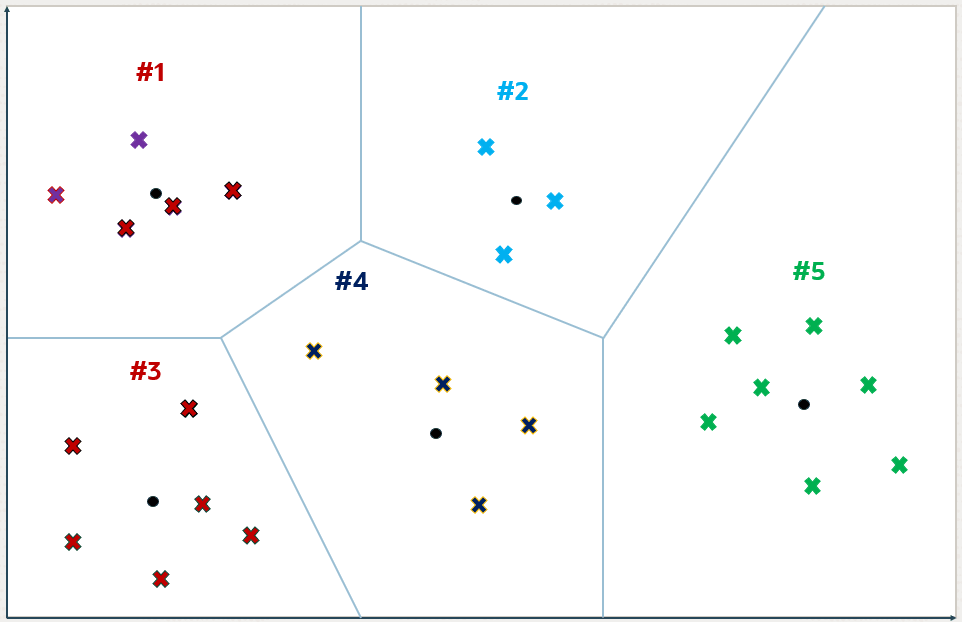
除了位于边缘的向量外,每个向量都落入与某个质心关联的特定分区内。
Figure 21-8 Inverted File Flat Index(图 21-8 倒排文件扁平索引)
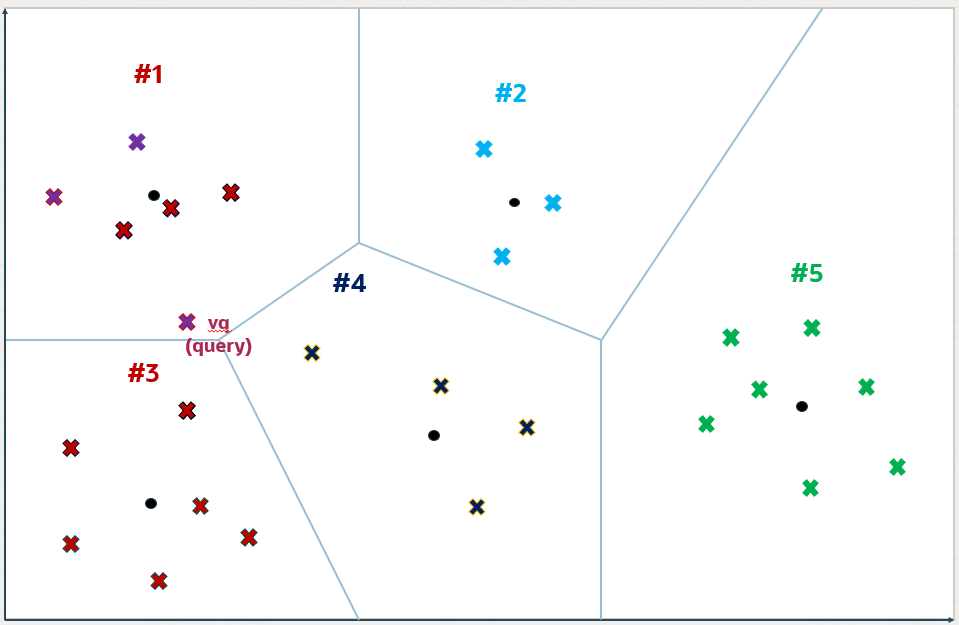
对于查询向量 vq,搜索算法会识别最近的 i 个质心,其中 i 默认为 k 的平方根,但可以通过为特定查询设置 NEIGHBOR PARTITION PROBES 参数来调整。这种调整允许在搜索速度和准确性之间进行权衡。
此参数的数字越大,结果精度越高。在这个例子中,i 设置为 2,识别的两个分区是 1 号和 3 号分区。
*Figure 21-9 Inverted File Flat Index(图 21-9 倒排文件扁平索引)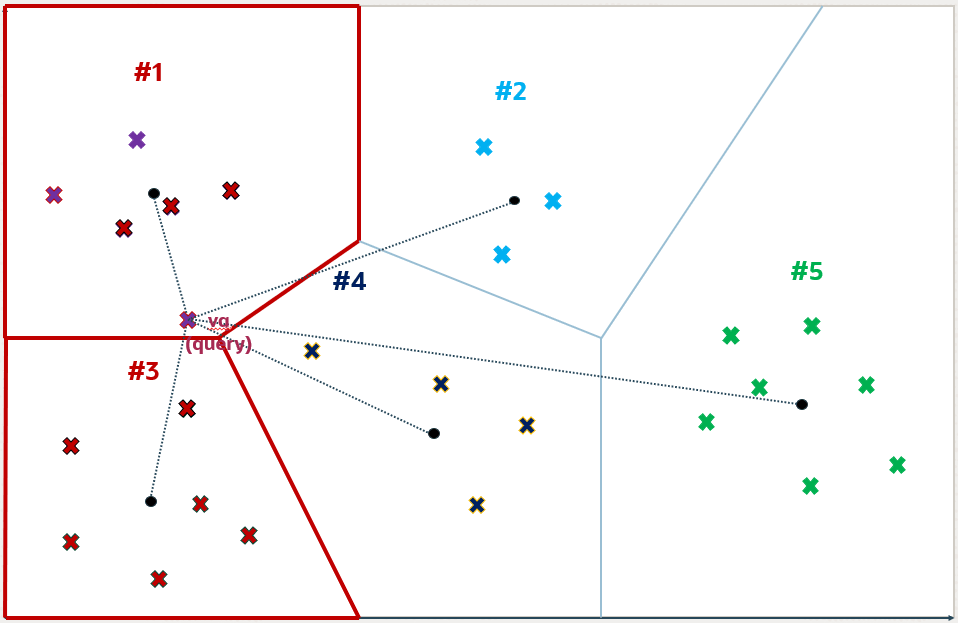
一旦确定了 i 个分区,就会对它们进行完全扫描,以识别出,在此示例中,前 5 个最近的向量。这个数字 5 可以不同于 k,并且您在查询中指定此数字。在 1 号和 3 号分区中找到的离 vq 最近的五个向量在下图中被突出显示。
此方法构成了近似搜索,因为它将搜索限制在分区的子集内,从而加快了搜索过程,但可能会遗漏未检查分区中更近的向量。这个例子说明了近似搜索结果可能不会产生距离 vq 精确最近的那些向量,展示了搜索效率和准确性之间的固有权衡。
Figure 21-10 Inverted File Flat Index(图 21-10 倒排文件扁平索引)
然而,距离 vq 精确最近的五个向量并非近似搜索找到的那几个。您可以看到,4 号分区中的一个向量比 3 号分区中检索到的其中一个向量更接近 vq。
Figure 21-11 Inverted File Flat Index(图 21-11 倒排文件扁平索引)
现在您可以明白为什么使用向量索引搜索并不总是一种精确搜索,而是被称为近似搜索。在此示例中,近似搜索的准确率仅为 80%,因为它仅检索到精确搜索结果 5 个向量中的 4 个。
Figure 21-12 Inverted File Flat Index(图 21-12 倒排文件扁平索引)
在使用 Oracle AI 向量搜索通过向量索引运行近似搜索查询时,您可以指定执行近似搜索的目标精度。
对于 IVF 近似搜索,您可以指定一个目标精度百分比值来影响用于探测搜索的分区数量。这是由算法自动计算的。值为 100 时,将倾向于执行精确搜索,尽管系统可能仍会使用索引,不会执行精确搜索。优化器可能会选择仍然使用索引,因为考虑到查询中的谓词,这样做可能更快。除了指定目标精度百分比值,您还可以指定 NEIGHBOR PARTITION PROBES 参数,以限制搜索要探测的最大分区数量。该数值越高,精度越高。
注意
- 如果您在近似搜索查询中未指定任何目标精度,那么您将继承在创建索引时设置的目标精度。您将看到,在索引创建时,您可以根据要创建的索引类型,通过百分比值或参数值来指定目标精度。
- 可以在索引搜索时指定不同于索引创建时设置的目标精度。对于 IVF 索引,您可以使用
NEIGHBOR PARTITION PROBES参数探测更多的质心分区,以获得更准确的结果。您在索引创建期间提供的目标精度决定了索引创建参数,并作为向量索引搜索的默认精度值。
Performing Similarity Searches(执行相似性搜索)
本节介绍执行相似性搜索的方法。
- Perform Exact Similarity Search(执行精确相似性搜索)
相似性搜索查找向量相对于查询向量的相对顺序。自然地,比较是使用特定的距离度量来完成的,但重要的是您的前几个最接近向量的结果集,而不是它们之间的距离。 - Understand Approximate Similarity Search Using Vector Indexes(了解使用向量索引的近似相似性搜索)
为了提高大向量空间的搜索速度,您可以使用向量索引进行近似相似性搜索。 - Perform Multi-Vector Similarity Search(执行多向量相似性搜索)
向量搜索的另一个主要用例是多向量搜索。多向量搜索通常与多文档搜索相关联,在多文档搜索中,文档被分割成块,这些块被单独嵌入到向量中。
Perform Exact Similarity Search(执行精确相似性搜索)
相似性搜索查找向量相对于查询向量的相对顺序。自然地,比较是使用特定的距离度量来完成的,但重要的是您的前几个最接近向量的结果集,而不是它们之间的距离。
例如,给定一个特定的查询向量,您可以计算它与数据集中所有其他向量的距离。这种类型的搜索,也称为平坦搜索或精确搜索,能产生最准确的结果,具有完美的搜索质量。然而,这是以显著的搜索时间为代价的。下图说明了这一点:
Figure 21-13 Exact Search(图 21-13 精确搜索)
在精确搜索中,您通过计算查询向量 vq 到空间中每个其他向量的距离,将其与空间中的所有其他向量进行比较。在计算完所有这些距离之后,搜索返回其中最近的 k 个作为最近匹配。这称为 k-最近邻 (kNN) 搜索。
例如,欧几里得相似性搜索涉及检索相对于欧几里得距离度量和查询向量而言,空间中前 k 个最近的向量。以下是一个示例,它使用以下精确相似性搜索查询,从 vector_tab 表中检索距离 query_vector 最近的前 10 个向量:
sql
SELECT docID
FROM vector_tab
ORDER BY VECTOR_DISTANCE( embedding, :query_vector, EUCLIDEAN )
FETCH EXACT FIRST 10 ROWS ONLY;在此示例中,docID 和 embedding 是在 vector_tab 表中定义的列,并且 embedding 具有 VECTOR 数据类型。
在欧几里得距离的情况下,比较平方距离等同于比较距离。因此,当排序比距离值本身更重要时,欧几里得平方距离非常有用,因为它比欧几里得距离计算得更快(避免了平方根计算)。因此,将查询重写如下会更简单、更快:
sql
SELECT docID
FROM vector_tab
ORDER BY VECTOR_DISTANCE( embedding, :query_vector, EUCLIDEAN_SQUARED)
FETCH FIRST 10 ROWS ONLY;注意
EXACT关键字是可选的。如果在连接到 ADB-S 实例时省略,则如果存在向量索引,系统会尝试使用向量索引进行近似搜索。有关更多信息,请参见使用向量索引执行近似相似性搜索。
注意确保使用在训练嵌入模型时使用的距离函数。
另请参见
《Oracle AI 数据库 SQL 语言参考》,了解 ROW_LIMITING_CLAUSE 的完整语法
Understand Approximate Similarity Search Using Vector Indexes(了解使用向量索引的近似相似性搜索)
为了提高大向量空间的搜索速度,您可以使用向量索引进行近似相似性搜索。
使用向量索引进行相似性搜索称为近似搜索 。近似搜索使用向量索引,以牺牲准确性为代价换取性能。
大向量空间的近似搜索
当搜索质量是您的首要任务而搜索速度不那么重要时,精确相似性搜索是一个不错的选择。对于较小的向量空间,或者当您使用高性能服务器执行搜索时,搜索速度可能无关紧要。然而,机器学习算法经常在拥有数十亿嵌入的向量空间上执行相似性搜索。例如,Deep1B 数据集包含由卷积神经网络 (CNN) 生成的 10 亿张图像。计算语料库中每个向量的向量距离,以 100% 的准确率找到前 K 个匹配,速度非常慢。
幸运的是,您可以使用向量索引执行多种类型的近似搜索。向量索引可能不太准确,但它们可以消耗更少的资源,并且效率更高。与传统数据库索引不同,向量索引是使用基于启发式的算法来构建和执行搜索的。
由于启发式方法无法保证 100% 的准确率,因此向量索引搜索使用目标精度。在内部,用于索引创建和索引搜索的算法都尽力达到尽可能高的精度。但是,您可以通过指定目标精度来影响这些算法。在创建索引或搜索索引时,您可以指定非默认的目标精度值,方法是指定百分比值,或者指定内部参数值,具体取决于您所使用的索引类型。
目标精度示例
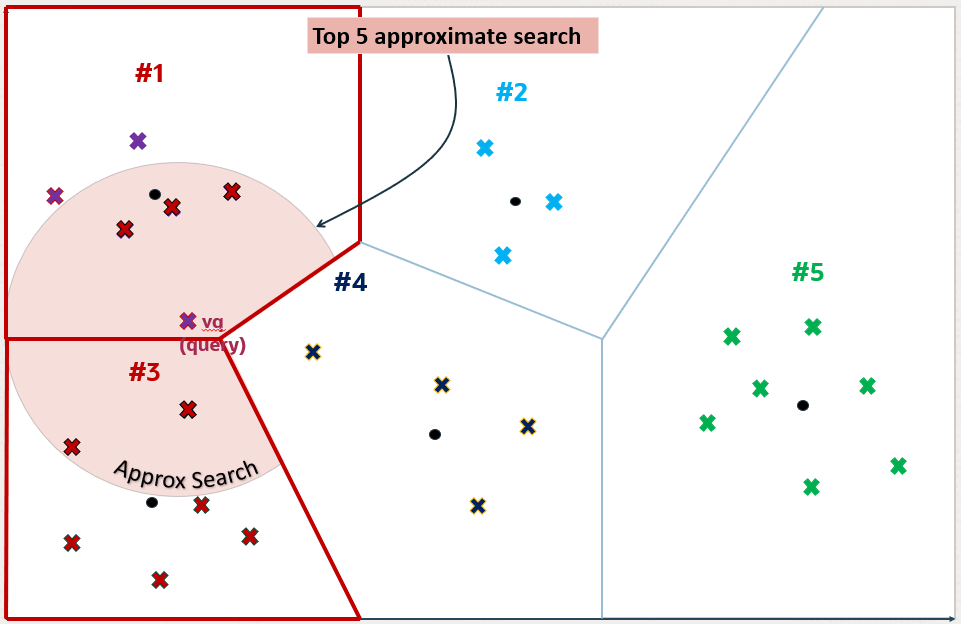
为了更好地理解什么是目标精度,请看下图。第一个图说明了一个向量空间,其中每个向量由一个小十字表示。红色的那个代表您的查询向量。
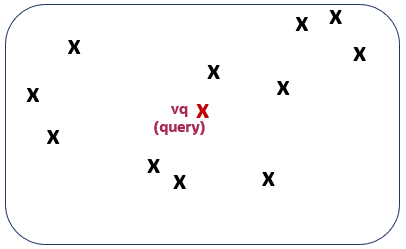
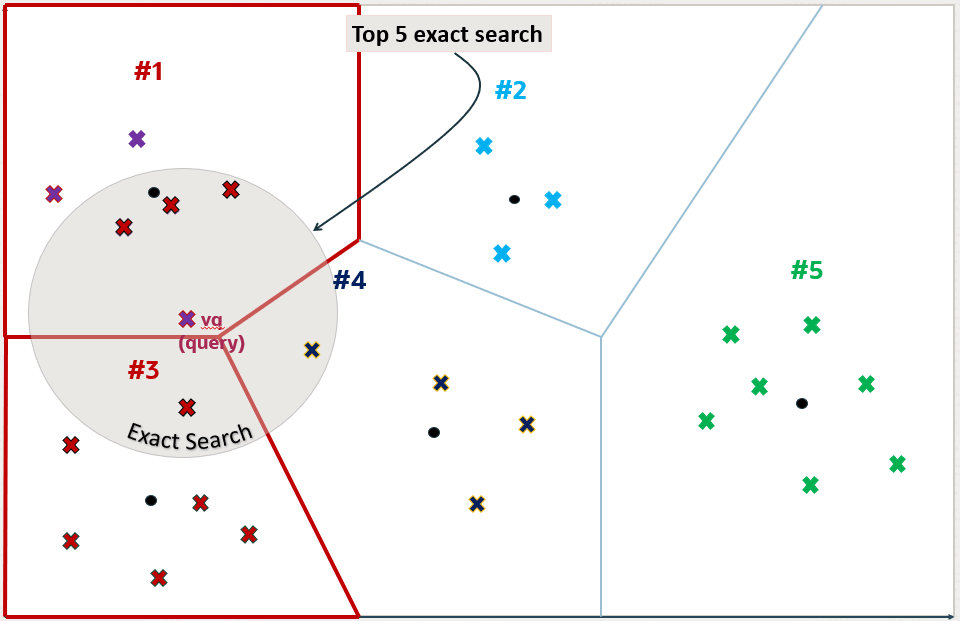
在该上下文中运行前 5 个精确相似性搜索将返回第二个图上显示的五个向量:
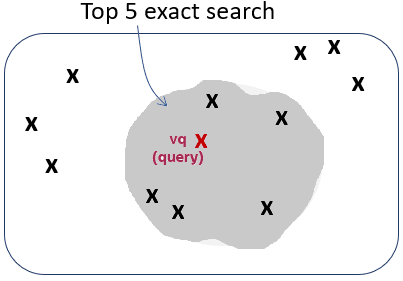
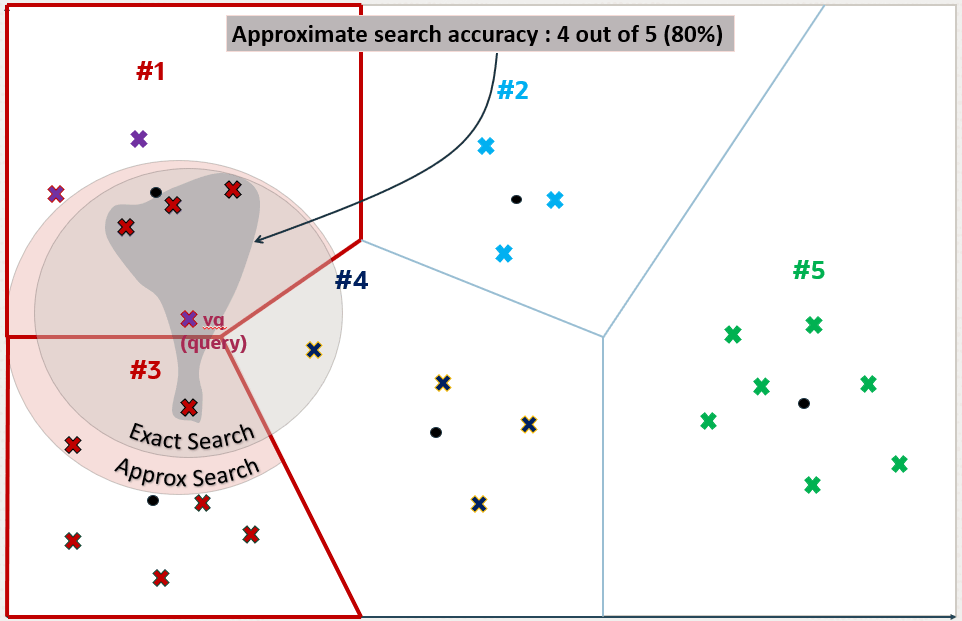
根据向量索引的构建方式,在该上下文中运行前 5 个近似相似性搜索可能会返回第三个图上显示的五个向量。这是因为索引创建过程使用了启发式方法。因此,通过向量索引进行搜索可能会产生与精确搜索不同的结果:
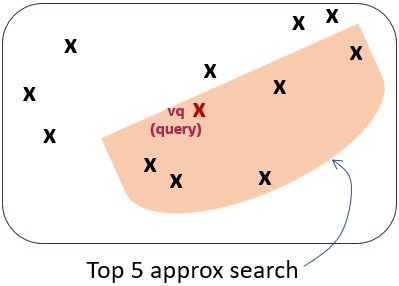
如您所见,检索到的向量是不同的,并且在这种情况下,它们相差一个向量。这意味着,与精确搜索相比,相似性搜索正确地检索了 5 个向量中的 4 个。与精确相似性搜索相比,该相似性搜索具有 80% 的准确率。这在第四个图上进行了说明:
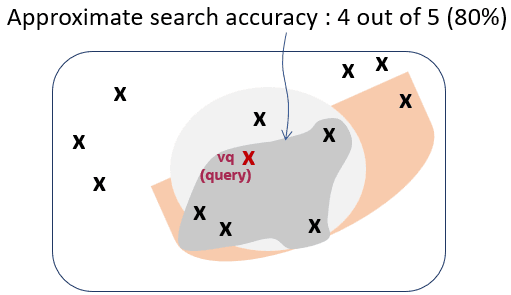
由于向量索引本质上是近似搜索结构,因此在 top-K 相似性搜索中,返回的行数可能少于 K 行。
有关如何设置向量索引的信息,请参见创建向量索引。
Perform Multi-Vector Similarity Search(执行多向量相似性搜索)
向量搜索的另一个主要用例是多向量搜索。多向量搜索通常与多文档搜索相关联,在多文档搜索中,文档被分割成块,这些块被单独嵌入到向量中。
多向量搜索包括使用基于文档特征的分组标准(称为分区)来检索前 K 个向量匹配。这种基于文档块与所搜索查询向量的相似度来对文档进行评分的能力,在 SQL 中通过分区行限制子句得以实现。
通过多向量搜索,可以更轻松地编写 SQL 语句来回答以下类型的问题:
- 如果存在,在最佳匹配的两本书中,最佳匹配的三个段落里,找到的四个最佳匹配句子是什么?
例如,假设您数据库中的每本书都被组织成包含句子的段落,这些句子具有向量嵌入表示,那么您可以使用如下单个 SQL 语句来回答前面的问题:
sql
SELECT bookId, paragraphId, sentence
FROM books
ORDER BY vector_distance(sentence_embedding, :sentence_query_vector)
FETCH FIRST 2 PARTITIONS BY bookId, 3 PARTITIONS BY paragraphId, 4 ROWS ONLY;您也可以使用近似相似性搜索代替精确相似性搜索,如下例所示:
sql
SELECT bookId, paragraphId, sentence
FROM books
ORDER BY vector_distance(sentence_embedding, :sentence_query_vector)
FETCH APPROXIMATE FIRST 2 PARTITIONS BY bookId, 3 PARTITIONS BY paragraphId,
4 ROWS ONLY
WITH TARGET ACCURACY 90;注意
返回的所有行均按
VECTOR_DISTANCE()排序,而不是按分区子句分组。
从语义上讲,前面的 SQL 语句被解释为:
- 按句子与查询向量之间的向量距离的降序对
books表中的所有记录进行排序。 - 对于此顺序中的每条记录,检查其
bookId和paragraphId。如果满足以下三个条件,则生成此记录:- 它的
bookId是排序顺序中前两个不同bookId之一。 - 它的
paragraphId是同一bookId内排序顺序中前三个不同paragraphId之一。 - 它的记录是同一
bookId和paragraphId组合内的前四条记录之一。
- 它的
- 否则,该记录将被过滤掉。
多向量相似性搜索不仅仅用于文档,也可用于回答以下问题:
- 返回前 K 个最接近的匹配照片,但要确保它们是不同人的照片。
- 找出具有两个或更多音频片段且最匹配此声音片段的前 K 首歌曲。
注意
- 此分区行限制子句扩展是 SQL 语言的通用扩展。它不必仅适用于向量搜索。
- 目前,IVF 索引支持多向量搜索。
另请参见
《Oracle AI 数据库 SQL 语言参考》,了解 ROW_LIMITING_CLAUSE 的完整语法