在蓝牙音频开发中,字符集乱码问题一直是困扰无数开发者的顽疾。很多人都知道InformDisplayableCharacterSet命令是解决乱码的关键,但90%的开发者都对这个命令的交互逻辑存在根本性误解。最常见的错误就是搞反了命令的发送方向,以及错误理解了PDU结构。本文通过两个官方标准的时序图,彻底拆解这个命令的完整交互流程和两种典型工作场景,从根源上解决乱码问题。
目录
[4.1 正确的PDU结构](#4.1 正确的PDU结构)
[4.2 常用字符集ID对照表](#4.2 常用字符集ID对照表)
[4.3 必须避免的开发坑点](#4.3 必须避免的开发坑点)
[5.1 CT端发送命令](#5.1 CT端发送命令)
[5.2 TG端处理命令](#5.2 TG端处理命令)
一、先纠正一个致命误解:命令方向搞反了是万恶之源
绝大多数中文资料都错误地声称,InformDisplayableCharacterSet是媒体源(TG)向控制器(CT)发送自己支持的字符集列表。这完全颠倒了协议的设计逻辑。
我们可以用一个非常贴切的比喻来理解这个过程:CT是餐厅里的客人,TG是后厨的厨师。客人走进餐厅,厨师默认先上原味(UTF-8)的菜品。如果客人有特殊口味要求,比如喜欢吃辣,就会主动告诉厨师:我能吃辣和原味,优先给我做辣的。厨师根据自己的能力,如果会做辣的,就以后都给客人上辣菜;如果不会做辣的,就继续上原味的菜。
对应到协议中:
所有AVRCP设备必须强制支持UTF-8作为默认字符集,连接建立后默认使用UTF-8通信
CT(显示端,如车载、耳机)主动向TG(媒体源,如手机)发送自己支持的字符集列表
列表按照CT的优先级从高到低排列,UTF-8必须作为最后一个兜底选项
TG收到列表后,选择第一个自己也支持的字符集,用于后续所有字符串响应
这种设计的合理性在于,显示能力是CT的固有属性,只有CT自己知道显示屏能正确显示哪些字符。TG只需要根据CT的要求提供对应编码的内容即可,不需要预先了解所有可能的CT设备的显示能力。
二、场景一:TG仅支持默认UTF-8
这是最常见的场景之一,特别是一些老旧的手机或播放器设备,只实现了强制要求的UTF-8字符集,不支持任何其他编码。
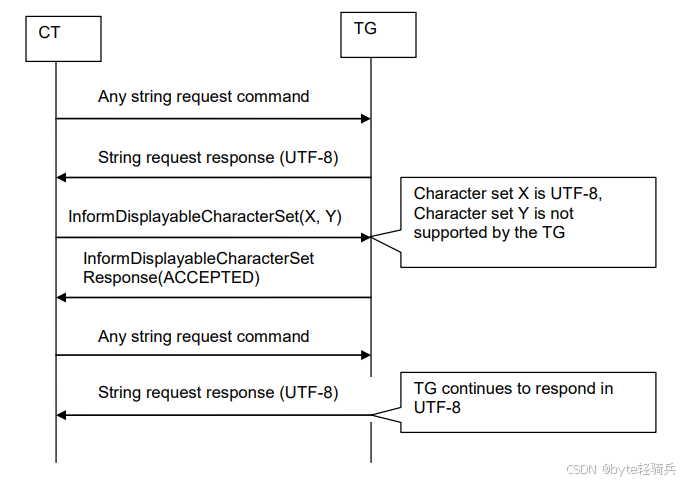
我们逐步骤解析这个交互过程:
-
初始默认通信阶段:连接建立完成后,双方默认使用UTF-8进行通信。CT发送任意字符串请求命令,比如获取歌曲标题、艺术家名称等,TG返回UTF-8编码的响应。这一步是所有AVRCP设备都必须支持的基础功能。
-
CT发送 字符集 偏好:CT在合适的时机,通常是第一次获取媒体信息之前,发送InformDisplayableCharacterSet命令,携带自己支持的字符集列表。例如一个中文车载设备可能会发送GBK, UTF-8,表示优先使用GBK编码,如果不行再用UTF-8。
-
TG 检查支持能力:TG收到命令后,遍历CT提供的字符集列表,逐个检查自己是否支持。在这个场景中,TG只支持UTF-8,不支持GBK。
-
TG 返回ACCEPTED响应:这里有一个非常重要的规范细节,无论TG是否支持CT提供的非UTF-8字符集,只要命令格式正确,都必须返回ACCEPTED响应,而不是任何错误响应。很多开发者以为不支持就应该返回错误,这会导致CT端协议栈出现异常。
-
后续通信保持 UTF-8:由于没有找到双方共同支持的非UTF-8字符集,TG将继续使用默认的UTF-8编码发送所有后续的字符串响应。
三、场景二:TG支持CT的高优先级字符集
当TG是一个功能完善的现代设备,支持多种字符集时,就会进入这个场景,这也是最理想的工作状态。
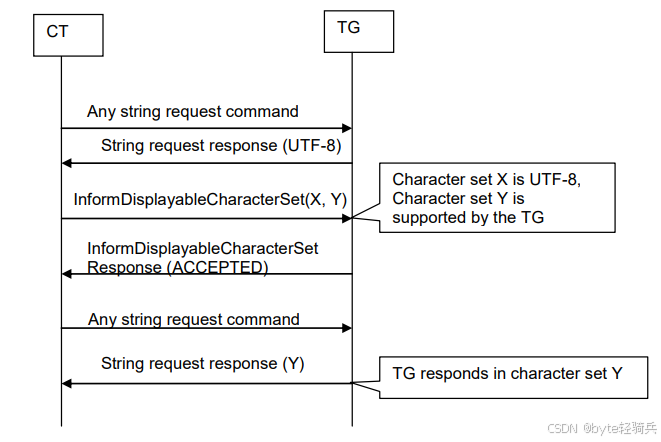
交互流程如下:
-
初始默认通信阶段:和场景一完全相同,双方默认使用UTF-8进行初始通信。
-
CT发送相同的 字符集 列表:CT仍然发送GBK, UTF-8的字符集列表,表达自己的编码偏好。
-
TG 检查支持能力:TG遍历列表后发现,自己同时支持GBK和UTF-8两种字符集。
-
TG 返回ACCEPTED响应:同样返回标准的ACCEPTED响应,没有任何额外参数。
-
后续通信切换到高优先级 字符集:从下一个字符串响应开始,TG将使用CT列表中第一个自己支持的字符集,也就是GBK,来编码所有文本内容。
这种场景的优势非常明显:对于中文等非拉丁语言,GBK的编码效率比UTF-8高约30%,可以减少蓝牙传输的数据量。同时,一些老旧的显示设备只支持GBK编码,不支持UTF-8,这种切换可以保证这些设备正常显示中文内容。
四、关键规范细节与开发坑点
4.1 正确的PDU结构
这是另一个重灾区,绝大多数资料都错误地描述了PDU结构。正确的结构如下:
命令 PDU ( CT → TG )
|----------|--------------------|------------|--------------------------|
| 字节偏移 | 字段名称 | 长度(字节) | 说明 |
| 0 | Ctype | 1 | 固定为0x00(CONTROL) |
| 1 | Subunit Type & ID | 1 | 高5位为Panel(0x09),低3位为0x00 |
| 2 | Opcode | 1 | 固定为0x20 |
| 3 | 字符集数量 | 1 | CT支持的字符集总数 |
| 4 | 字符集ID 1 | 2 | 优先级最高的字符集ID,大端序 |
| 6 | 字符集ID 2 | 2 | 次高优先级的字符集ID,大端序 |
响应 PDU ( TG → CT )
|----------|--------------------|------------|--------------------------|
| 字节偏移 | 字段名称 | 长度(字节) | 说明 |
| 0 | Ctype | 1 | 固定为0x09(STABLE/ACCEPTED) |
| 1 | Subunit Type & ID | 1 | 高5位为Panel(0x09),低3位为0x00 |
| 2 | Opcode | 1 | 固定为0x20 |
响应PDU只有3个字节,没有任何操作数。这一点和绝大多数AVRCP命令都不同,也是最容易出错的地方。
4.2 常用字符集ID对照表
AVRCP规范中的字符集ID完全遵循IANA MIBenum标准,以下是最常用的正确ID:
|------------|--------------|-----------|----------|
| 字符集名称 | MIBenum值 | 十六进制值 | 适用语言 |
| UTF-8 | 106 | 0x006A | 所有语言 |
| GBK | 113 | 0x0071 | 简体中文 |
| GB18030 | 114 | 0x0072 | 简体中文 |
| Big5 | 2026 | 0x07EA | 繁体中文 |
| Shift_JIS | 17 | 0x0011 | 日文 |
| EUC-KR | 38 | 0x0026 | 韩文 |
| ISO-8859-1 | 4 | 0x0004 | 西欧语言 |
4.3 必须避免的开发坑点
-
命令方向错误:不要让TG主动发送字符集列表给CT,这是完全错误的行为。
-
CT列表不包含UTF-8:规范强制要求CT的字符集列表必须包含UTF-8,否则TG可能无法处理。
-
TG返回错误响应:只要命令格式正确,无论是否支持字符集,都必须返回ACCEPTED。
-
切换时机错误:TG必须在返回ACCEPTED响应之后的下一个字符串响应才切换字符集,ACCEPTED响应本身仍然使用UTF-8。
-
字符集顺序错误:CT应该把自己最希望使用的字符集放在列表最前面,UTF-8放在最后。
五、正确的代码实现示例
5.1 CT端发送命令
cpp
// CT端发送InformDisplayableCharacterSet命令
void avrcp_ct_send_inform_displayable_char_set(uint16_t handle)
{
BT_HDR *p_buf;
uint8_t *p_data;
uint8_t num_char_sets = 2;
// 分配缓冲区:3字节头部 + 1字节数量 + 2个字符集ID
p_buf = (BT_HDR *)osi_malloc(sizeof(BT_HDR) + 3 + 1 + num_char_sets * 2);
p_buf->offset = AVCT_MSG_OFFSET;
p_buf->len = 3 + 1 + num_char_sets * 2;
p_data = (uint8_t *)(p_buf + 1) + p_buf->offset;
// 填充PDU头部
p_data[0] = 0x00;
p_data[1] = 0x48;
p_data[2] = 0x20;
// 填充字符集列表:优先GBK,其次UTF-8
p_data[3] = num_char_sets;
// GBK: 113
p_data[4] = 0x00;
p_data[5] = 0x71;
// UTF-8: 106
p_data[6] = 0x00;
p_data[7] = 0x6A;
avctp_send_msg(handle, AVCT_CMD, p_buf, AVCT_DATA_CTRL);
}5.2 TG端处理命令
cpp
// TG支持的字符集列表
static const uint16_t supported_char_sets[] = {106, 113, 17};
static uint16_t current_char_set = 106; // 默认UTF-8
void avrcp_tg_handle_inform_displayable_char_set(BT_HDR *p_msg, uint16_t handle)
{
BT_HDR *p_rsp;
uint8_t *p_data = (uint8_t *)(p_msg + 1) + p_msg->offset;
uint8_t num_char_sets;
uint16_t char_set_id;
int i, j;
// 跳过头部,解析字符集数量
p_data += 3;
num_char_sets = *p_data++;
// 遍历CT提供的列表,选择第一个支持的字符集
current_char_set = 106;
for (i = 0; i < num_char_sets; i++) {
char_set_id = (p_data[0] << 8) | p_data[1];
p_data += 2;
for (j = 0; j < sizeof(supported_char_sets)/sizeof(uint16_t); j++) {
if (char_set_id == supported_char_sets[j]) {
current_char_set = char_set_id;
goto found;
}
}
}
found:
// 发送ACCEPTED响应
p_rsp = (BT_HDR *)osi_malloc(sizeof(BT_HDR) + 3);
p_rsp->offset = AVCT_MSG_OFFSET;
p_rsp->len = 3;
p_data = (uint8_t *)(p_rsp + 1) + p_rsp->offset;
p_data[0] = 0x09;
p_data[1] = 0x48;
p_data[2] = 0x20;
avctp_send_msg(handle, AVCT_RSP, p_rsp, AVCT_DATA_CTRL);
}六、测验
问题:AVRCP协议中InformDisplayableCharacterSet命令的发送方向是什么?它携带的核心参数是什么?(某知名TWS耳机厂商2025年蓝牙协议栈开发面试题)
答案:
该命令由控制器(CT)发送给目标设备(TG)。命令携带的核心参数是CT支持的可显示字符集ID列表,列表按照CT的使用优先级从高到低排列,并且必须包含UTF-8作为最后的兜底选项。
问题:当TG收到InformDisplayableCharacterSet命令后,如果不支持CT提供的任何非UTF-8字符集,应该如何响应?后续通信使用什么字符集?(某车载电子公司2024年蓝牙开发工程师面试题)
答案:
无论TG是否支持CT提供的非UTF-8字符集,只要命令格式正确,都必须返回ACCEPTED响应,Ctype字段值为0x09。如果不支持任何非UTF-8字符集,TG将继续使用默认的UTF-8字符集进行后续所有字符串通信。
问题:TG在收到CT的字符集列表后,应该按照什么规则选择要使用的字符集?切换字符集的正确时机是什么?
答案:
TG应该从CT提供的字符集列表的第一个元素开始依次检查,选择第一个自己也支持的字符集。切换字符集的正确时机是在返回ACCEPTED响应之后的下一个字符串响应。ACCEPTED响应本身必须仍然使用默认的UTF-8字符集编码。