本文面向 OCR 模型部署、轻量化文本识别、ONNX/MNN/C++ 推理落地等工程场景,系统说明 CRNN + CTC 的核心原理、网络结构、训练方式、解码流程、工程部署要点与适用场景。
1. 动态流程展示
下图展示了 CRNN + CTC OCR 从输入文本行图像到最终文本输出的完整过程: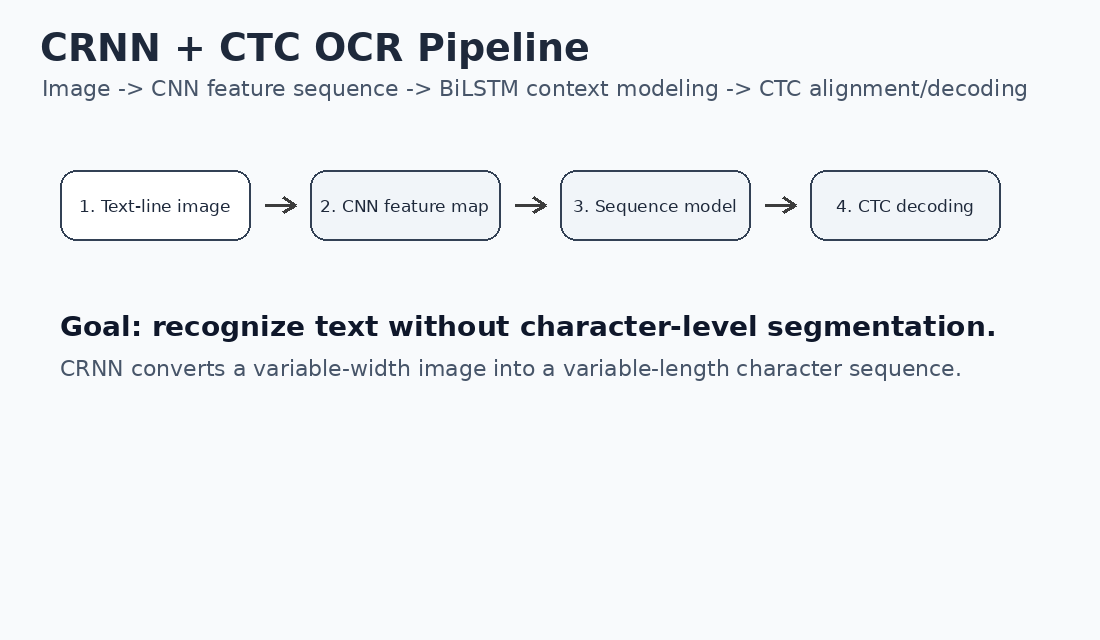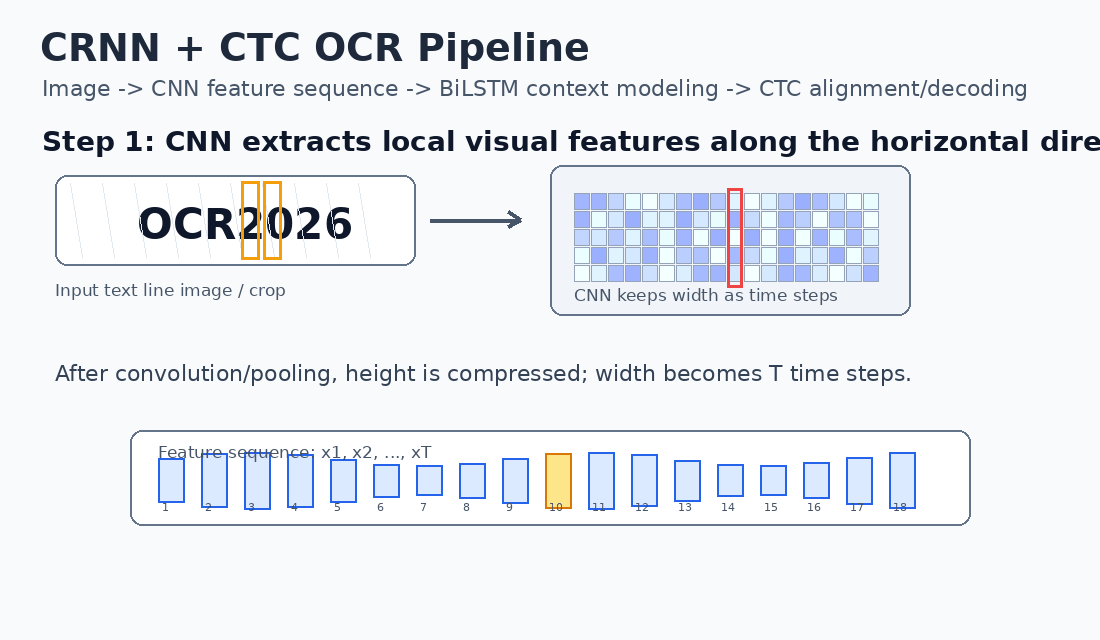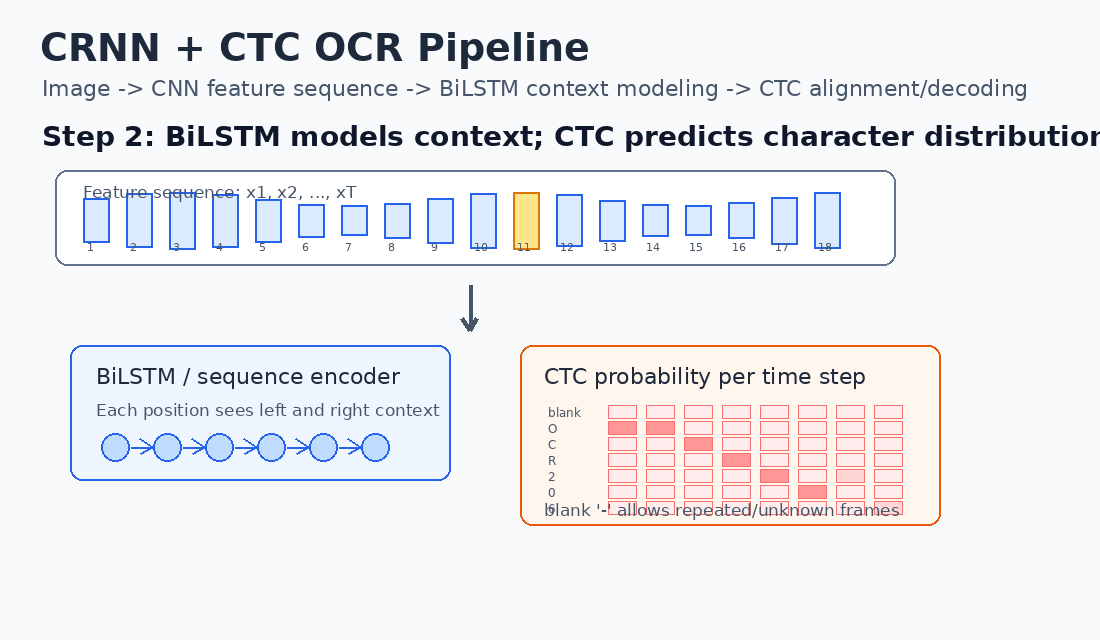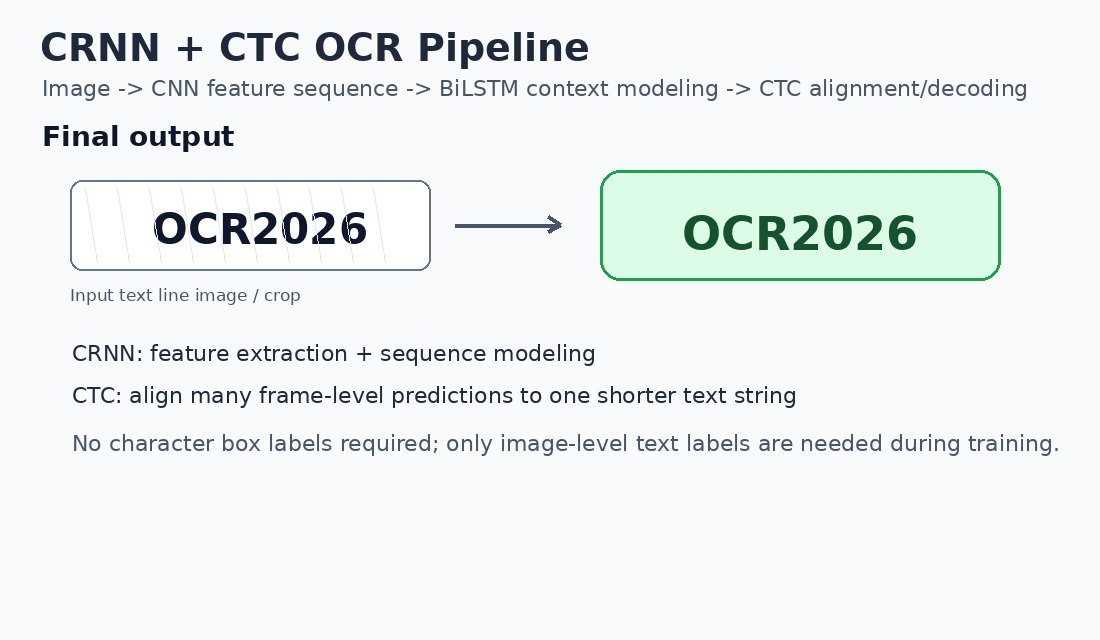
整体流程可以概括为:
text
输入文本行图像
↓
CNN 提取局部视觉特征
↓
按图像宽度方向展开为特征序列
↓
BiLSTM / 序列模型进行上下文建模
↓
CTC Head 输出每个时间步的字符概率
↓
CTC Decode 合并重复字符并删除 blank
↓
输出最终识别文本2. CRNN + CTC 的定位
CRNN + CTC 是经典 OCR 文本识别模型,常用于车牌识别、票据字段识别、工业喷码识别、仪表数字识别、商品标签识别、轻量化端侧 OCR、视频帧字幕或 HUD 文字识别等场景。
CRNN 负责将图像转为序列特征,CTC 负责解决"图像特征时间步"和"真实字符序列"之间无法直接对齐的问题。
3. 为什么需要 CTC?
传统 OCR 常见思路是:
text
图像 → 字符切割 → 单字符分类 → 拼接文本但是字符切割在真实场景中非常困难。例如:
- 字符间距不固定;
- 字符可能粘连;
- 字符可能倾斜、模糊、断裂;
- 中文字符笔画复杂;
- 英文中的
rn、m、ll等容易混淆; - 工业喷码、票据、车牌字符常有噪声和变形。
CTC 的核心优势是:
训练时只需要整行文本标签,不需要逐字符位置标注。
例如输入图像的标签是:
text
OCR2026模型不需要知道 O、C、R、2、0、2、6 分别位于图像第几列。CTC 会在训练过程中自动学习可能的对齐关系。
4. CRNN 网络结构详解
CRNN 通常由三部分组成:
text
CNN Backbone + Sequence Encoder + CTC Classification Head也可以写成:
text
图像特征提取层 + 序列建模层 + 字符分类层5. 输入图像预处理
OCR 文本行识别通常会将输入图像归一化为固定高度,例如:
text
H = 32 或 48
W = 根据文本长度自适应
C = 1 或 3常见输入尺寸形式:
text
32 × W × 1
32 × W × 3
48 × W × 3高度固定,宽度可变。这样模型可以处理不同长度的文本行,例如 OK、OCR2026、DEEPLEARNING、商品编号A20260604。
在实际部署时,为了方便 batch 推理,常会将图像 resize 到固定高度,再对宽度进行 padding。
6. CNN 特征提取
CNN 的作用是提取字符局部视觉特征,例如边缘、笔画、拐角、局部纹理、字符结构等。
输入图像:
text
Input: B × C × H × W经过 CNN 后得到特征图:
text
Feature Map: B × C' × H' × W'在 CRNN 中,通常会通过卷积和池化逐步压缩高度方向,使得高度变为 1 或接近 1:
text
B × C' × 1 × W'此时,宽度方向的每一列可以视为一个时间步:
text
x1, x2, x3, ..., xT于是二维图像被转换成一维序列:
text
X = [x1, x2, x3, ..., xT]这是 CRNN 的关键思想:
将 OCR 图像识别问题转换为序列识别问题。
7. 宽度方向为什么可以看作时间步?
对于文本行图像,字符通常沿水平方向排列。图像左侧对应较早的字符,图像右侧对应较后的字符。
例如:
text
图像:O C R 2 0 2 6
方向:左 → 右CNN 输出的特征图宽度方向天然对应文本阅读顺序,因此可以把每一列特征当成序列中的一个时间步。
示意如下:
text
Feature Map: C' × 1 × T
第 1 列 → x1
第 2 列 → x2
第 3 列 → x3
...
第 T 列 → xT8. 序列建模层:RNN / BiLSTM
CNN 提取的是局部视觉特征,但 OCR 识别需要上下文。
例如:
text
0 和 O 很像
1 和 l 很像
S 和 5 很像
B 和 8 很像
rn 和 m 很像如果只看局部图像,模型可能难以判断。BiLSTM 可以同时利用左侧和右侧上下文信息:
text
Forward LSTM: 左 → 右
Backward LSTM: 右 → 左因此,每个时间步的输出都包含上下文信息。
输入:
text
x1, x2, ..., xT输出:
text
h1, h2, ..., hT其中每个 ht 都融合了当前区域及其左右上下文的信息。
9. CTC Head 字符分类
序列建模后,每个时间步都会输出一个隐藏状态 ht。通过全连接层映射到字符类别空间:
text
yt = Linear(ht)输出维度为:
text
num_classes = 字符类别数 + 1额外的 1 是 CTC 的特殊符号:
text
blankblank 表示当前时间步不输出任何字符。
例如字符集为:
text
0-9 + A-Z那么类别可以设计为:
text
blank, 0, 1, 2, ..., 9, A, B, ..., Z通常 blank 放在 index 0,方便工程实现。
10. CTC 的核心思想
模型每个时间步都会输出一个字符概率分布:
text
t1: P(blank), P(O), P(C), ...
t2: P(blank), P(O), P(C), ...
t3: P(blank), P(O), P(C), ...
...
tT: P(blank), P(O), P(C), ...由于 T 通常大于真实文本长度 L,模型会输出一个较长的路径,然后通过 CTC 规则压缩成最终文本。
例如原始路径:
text
O O blank C blank R 2 0 blank 2 6CTC 解码规则:
text
1. 合并连续重复字符
2. 删除 blank解码过程:
text
O O blank C blank R 2 0 blank 2 6
↓ 合并连续重复字符
O blank C blank R 2 0 blank 2 6
↓ 删除 blank
O C R 2 0 2 6最终结果:
text
OCR202611. blank 符号的作用
blank 是 CTC 中非常重要的符号。它主要有两个作用。
11.1 表示无字符输出
很多时间步可能对应字符之间的空白区域,或者只是过渡特征。这些时间步可以输出 blank。
例如:
text
O blank C blank R blank 2 blank 0 blank 2 blank 6删除 blank 后得到:
text
OCR202611.2 区分连续重复字符
如果要识别:
text
book其中包含连续两个 o。
如果路径是:
text
b o o kCTC 合并连续重复字符后会变成:
text
bok为了保留两个 o,可以使用 blank 分隔:
text
b o blank o k删除 blank 后:
text
book因此,blank 是处理重复字符的关键机制。
12. CTC Loss 训练原理
训练数据形式:
text
输入图像: text_line.jpg
文本标签: OCR2026模型输出:
text
T × num_classes但是训练标签只有:
text
O C R 2 0 2 6没有每个字符对应的时间步位置。
CTC Loss 的做法是:
枚举所有能够解码为正确标签的路径,将它们的概率加起来,并最大化这个总概率。
可以理解为:
text
P(label | image) = 所有可行路径概率之和训练目标:
text
Loss = -log P(label | image)即让正确文本的总概率尽可能大。
13. PyTorch 中的 CTC Loss 形式
PyTorch 中常用 torch.nn.CTCLoss:
python
import torch
import torch.nn as nn
ctc_loss = nn.CTCLoss(
blank=0,
reduction="mean",
zero_infinity=True
)
# logits: [B, T, C]
# PyTorch CTCLoss 需要 [T, B, C]
log_probs = logits.log_softmax(dim=2).permute(1, 0, 2)
loss = ctc_loss(
log_probs, # [T, B, C]
targets, # 拼接后的真实标签
input_lengths, # 每个样本的时间步长度 T
target_lengths # 每个样本真实文本长度
)注意事项:
log_probs必须是 log-softmax 后的概率;- 输入维度必须是
[T, B, C]; input_lengths表示每个样本经过 CNN 后的序列长度;target_lengths表示真实文本长度;targets通常是 batch 内所有标签拼接后的 1D 张量。
14. CTC 解码方式
CTC 常见解码方式有两种:
text
Greedy Decode
Beam Search Decode15. Greedy Decode
Greedy Decode 是最简单的解码方式:
text
每个时间步选择概率最大的字符例如:
text
t1: O
t2: O
t3: blank
t4: C
t5: blank
t6: R
t7: 2
t8: 0
t9: blank
t10: 2
t11: 6得到原始路径:
text
O O blank C blank R 2 0 blank 2 6然后执行:
text
合并连续重复字符 → 删除 blank最终输出:
text
OCR2026Greedy Decode 优点:实现简单、推理速度快、适合端侧部署、适合实时 OCR。
缺点:只取局部最优,对相似字符、低质量图像不够稳,无法很好利用语言约束。
16. Beam Search Decode
Beam Search 会在每个时间步保留多个候选路径,而不是只保留概率最大的一个。
例如保留候选:
text
OCR2026
0CR2026
OCR2O26
OCR2Q26然后综合路径概率选择最优输出。
如果结合语言模型或业务字典,可以进一步提高准确率。
适用场景包括票据字段识别、车牌识别、固定格式编号识别、商品条码附近文字识别、英文单词识别、低质量图像识别等。
17. 完整训练流程
text
1. 准备文本行图像和对应字符串标签
2. 构建字符字典 char_dict
3. 将字符串标签编码为数字序列
4. 图像 resize / padding / normalize
5. 输入 CRNN 模型
6. CNN 提取视觉特征
7. 特征图按宽度方向展开为序列
8. BiLSTM 建模上下文
9. Linear Head 输出每个时间步字符概率
10. 使用 CTC Loss 计算损失
11. 反向传播更新模型18. 完整推理流程
text
1. 输入待识别图像
2. 图像预处理
3. 输入 CRNN 模型
4. 得到 logits
5. softmax 得到概率
6. 每个时间步取最大概率字符
7. 合并连续重复字符
8. 删除 blank
9. 得到最终文本伪代码:
python
def ctc_greedy_decode(pred_ids, blank_id=0):
result = []
last = None
for idx in pred_ids:
if idx != blank_id and idx != last:
result.append(idx)
last = idx
return result19. 模型结构示例
一个典型 CRNN 结构如下:
text
Input: 1 × 32 × W
CNN:
Conv + BN + ReLU
MaxPool
Conv + BN + ReLU
MaxPool
Conv + BN + ReLU
MaxPool
Feature:
C × 1 × T
Sequence:
Permute → T × B × C
BiLSTM
BiLSTM
Head:
Linear(hidden, num_classes)
Output:
T × B × num_classes20. 优点与局限性
20.1 优点
- 不需要字符级标注;
- 支持变长文本;
- 模型结构清晰;
- 推理速度快;
- 容易导出 ONNX;
- 适合 TensorRT、MNN、NCNN 等部署;
- 工程实现成熟;
- 对规则文本行识别效果稳定。
20.2 局限性
- 对弯曲文字识别能力较弱;
- 对强透视畸变文本识别能力有限;
- 对复杂二维排版不适合;
- 对长文本上下文建模不如 Transformer;
- CTC 假设各时间步之间条件独立,表达能力有限;
- 容易混淆相似字符。
常见混淆:
text
O / 0
I / 1 / l
S / 5
B / 8
rn / m
cl / d21. 适用场景分析
21.1 适合场景
text
单行文本识别
规则文本识别
车牌识别
数字识别
工业字符识别
票据关键字段识别
低算力端侧 OCR
移动端 OCR
嵌入式 OCR
C++ 实时推理21.2 不适合场景
text
复杂文档版面理解
表格结构还原
公式识别
多行自然段识别
弯曲艺术字识别
复杂自然场景长文本识别这些场景更适合使用 SVTR、SAR、ASTER、ABINet、SATRN、TrOCR、PARSeq、Vision Transformer OCR 等方法。
22. 和 Attention OCR / Transformer OCR 的区别
| 方案 | 核心思想 | 优点 | 缺点 |
|---|---|---|---|
| CRNN + CTC | 帧级分类 + CTC 对齐 | 简单、快速、易部署 | 上下文能力有限 |
| Attention OCR | Encoder + Decoder + Attention | 序列建模更灵活 | 推理较慢,部署复杂 |
| Transformer OCR | 全局注意力建模 | 准确率高,长文本能力强 | 算力需求较高 |
| ABINet | 视觉模型 + 语言模型迭代纠错 | 语义纠错能力强 | 模型复杂 |
| PARSeq | Permuted autoregressive decoding | 准确率高 | 端侧部署成本较高 |
23. 工程部署建议
23.1 轻量化 Backbone 选择
端侧部署推荐:
text
MobileNetV3
ShuffleNetV2
RepVGG-lite
PP-LCNet
ResNet-lite
SVTR-tiny23.2 序列层选择
如果追求精度,可以使用 BiLSTM。
如果追求部署简单,可以考虑:
text
1D Conv
Transformer Encoder Lite
SVTR Block部分部署框架对 LSTM 支持不够友好,因此在 MNN、NCNN、TensorRT 场景中,可以考虑用卷积或轻量 Transformer 替代 BiLSTM。
24. ONNX / MNN 部署注意事项
24.1 导出建议
导出 ONNX 时建议:
- 固定输入高度;
- 允许动态宽度;
- 尽量避免复杂控制流;
- 解码逻辑放在后处理端实现;
- 模型只输出 logits 或 log_probs;
- CTC Decode 在 C++ 侧实现。
推荐模型输出:
text
logits: [B, T, C]C++ 后处理执行:
text
argmax → merge repeated → remove blank → map id to char24.2 C++ 后处理伪代码
cpp
std::string ctc_greedy_decode(
const std::vector<int>& pred_ids,
const std::vector<std::string>& charset,
int blank_id = 0
) {
std::string result;
int last = -1;
for (int id : pred_ids) {
if (id != blank_id && id != last) {
result += charset[id];
}
last = id;
}
return result;
}中文字符建议使用 std::string 保存 UTF-8 字符串列表,避免直接按 char 拼接导致乱码。
25. 字符集设计建议
字符集需要与业务场景匹配。
25.1 数字场景
text
blank + 0-9适合仪表读数、金额识别、计分板识别、编号识别。
25.2 英文数字场景
text
blank + 0-9 + A-Z + a-z适合车牌、商品编码、快递单号、设备序列号。
25.3 中文场景
text
blank + 常用汉字 + 数字 + 英文 + 标点适合票据、合同、商品标签、中文场景文本。
字符集越大,分类难度越高,模型输出层越大,训练数据需求也越高。
26. 数据增强建议
CRNN + CTC 对图像质量较敏感,因此训练时建议加入数据增强:
text
随机模糊
随机亮度
随机对比度
随机噪声
随机透视
轻微旋转
文字拉伸
背景干扰
JPEG 压缩
随机遮挡对于工业 OCR,还可以增加:
text
喷码断裂
字符腐蚀
字符膨胀
低对比度
反光
运动模糊27. 常见问题与优化策略
27.1 相似字符混淆
问题:
text
O / 0
I / 1 / l
S / 5
B / 8优化:
text
增加混淆样本
使用 Beam Search
加入业务字典
增加语言模型
提高输入分辨率
增强图像清晰度27.2 文本过长识别不完整
原因:
text
输入宽度压缩过度
CNN 下采样过强
T 小于标签长度优化:
text
减少宽度方向下采样
增大输入宽度
检查 input_lengths
过滤异常长标签27.3 CTC Loss 变成 inf
常见原因:
text
input_length < target_length
标签字符不在字典中
blank id 设置错误
log_probs 维度错误解决:
text
设置 zero_infinity=True
检查字典映射
检查 input_lengths
检查 target_lengths
确认 logits.log_softmax(dim=2)27.4 中文识别乱码
原因:
text
C++ 后处理按 char 拼接
字符集文件编码不是 UTF-8解决:
text
字符表逐行读取 UTF-8 字符
使用 std::string 保存每个字符
不要按单字节处理中文28. 推荐部署架构
对于轻量化 OCR 部署,可以采用如下结构:
text
Python 训练
↓
PyTorch CRNN + CTC
↓
导出 ONNX
↓
ONNXRuntime 验证
↓
转换 MNN / NCNN / TensorRT
↓
C++ 推理
↓
CTC Greedy Decode 后处理
↓
业务规则修正在生产系统中,可以进一步加入:
text
检测模型 DBNet / YOLO
↓
文本行裁剪
↓
CRNN + CTC 文本识别
↓
后处理规则
↓
结构化字段输出29. 与 OCR 检测模型的关系
CRNN + CTC 通常只负责识别,不负责检测文本位置。
完整 OCR 系统一般包括:
text
文本检测模型 + 文本识别模型例如:
text
DBNet / EAST / CRAFT / YOLO-Text
↓
文本框裁剪与矫正
↓
CRNN + CTC
↓
文本输出如果输入已经是裁剪好的文本行图像,则可以直接使用 CRNN + CTC。
30. 总结
CRNN + CTC 的核心思想是:
用 CNN 将文本行图像转换成宽度方向的特征序列,再用 RNN 或其他序列模型进行上下文建模,最后通过 CTC 在没有字符级对齐标注的情况下完成文本序列识别。
它的优势是结构简单、部署方便、训练标注成本低、推理速度快,适合规则文本行识别。
它的不足是复杂版面能力弱、弯曲文本能力弱、语义上下文能力有限、对相似字符较敏感。
在端侧 OCR、工业 OCR、车牌识别、票据字段识别、游戏 HUD OCR、商品标签识别等场景中,CRNN + CTC 仍然是非常实用的基线方案。