摘 要
图像分类是计算机视觉领域的核心研究内容,在智能监控、医学影像分析、农业监测、野生动物保护等多个领域具有重要的应用价值。随着深度学习技术的快速发展,特别是卷积神经网络(CNN)的广泛应用,图像分类任务取得了突破性进展。传统的图像分类方法主要依赖于手工设计的特征提取器,如SIFT、HOG等,这些方法需要大量的领域知识和经验,且特征表达能力有限,在复杂场景下的泛化能力不足。深度学习方法能够自动从原始图像中学习层次化的特征表示,无需手工设计特征,在图像分类任务中表现出色。迁移学习技术通过利用在大规模数据集上预训练的模型,在小规模数据集上快速获得良好的性能,为动物图像分类任务提供了有效的解决方案。
本文针对动物图像分类任务,设计并实现一个完整的基于卷积神经网络的分类系统。系统采用迁移学习技术,利用在ImageNet数据集上预训练的深度卷积神经网络模型ResNet50,在动物图像数据集上进行微调训练。系统实了完整的数据预处理流程,包括数据清洗、尺寸归一化、数据增强等操作,数据增强技术包括随机裁剪、随机旋转、随机水平翻转、颜色抖动等,有效提高模型的泛化能力。在训练策略方面,系统使用Adam优化器和交叉熵损失函数,实现了学习率调度和早停机制,使用验证集监控训练过程并自动保存最佳模型。在模型评估方面,系统实现全面的评估指标,包括准确率、精确率、召回率、F1-Score等,并通过混淆矩阵可视化分析模型的分类错误情况。
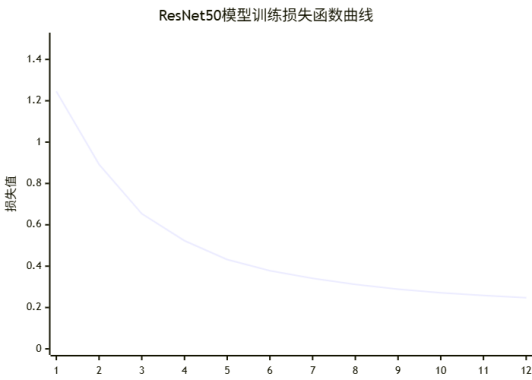
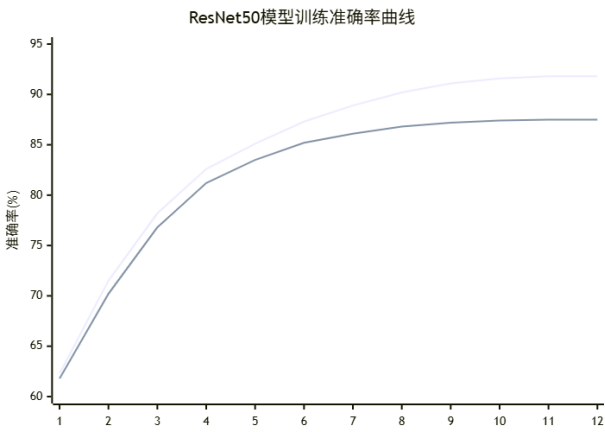
实验结果表明,基于ResNet50的迁移学习模型在CIFAR-10动物子集上取得了良好的分类性能。在端到端微调策略下,模型在测试集上达到了87.8%的分类准确率,验证了所设计系统的有效性。对比实验显示,不同模型架构的性能存在差异,ResNet50在性能和效率之间取得了良好的平衡。
关键词:卷积神经网络;图像分类;动物识别;ResNet50
1.3研究内容
本文的主要研究内容包括以下几个方面。
数据收集与预处理:搜集公开的动物图像数据集,实现数据清洗、标注统一、尺寸归一化和数据增强等功能。针对动物图像的特点,设计合适的数据预处理流程,提高数据质量和模型训练效果。
模型选择与基准测试:选取经典的CNN模型ResNet50作为基准模型,在预训练权重基础上进行迁移学习。对比不同模型架构和训练策略的性能,选择最适合的模型配置。
自定义CNN模型设计:结合任务特点,设计了一个轻量级的CNN网络结构,适用于资源受限的场景。该设计考虑了深度、卷积核大小、池化策略、激活函数选择以及防止过拟合的措施。
模型训练与优化:使用PyTorch框架搭建并训练模型,通过调节超参数来优化模型性能。使用验证集监控训练过程,实现早停机制防止过拟合。
模型评估与分析:使用测试集对训练好的模型进行全面评估,采用准确率、精确率、召回率、F1-Score等指标进行量化分析,并通过混淆矩阵可视化分析模型的分类错误情况。
系统集成与展示:将训练好的模型封装成一个Web演示系统,实现用户上传图像即可得到动物分类结果的功能,直观展示研究成果。
2.4数据集
2.4.1CIFAR-10数据集
本研究使用CIFAR-10数据集中的动物类别子集作为实验数据。CIFAR-10是一个广泛使用的图像分类数据集,由加拿大高级研究所(CIFAR)创建,包含10个类别,共60,000张32×32像素的彩色图像。其中,训练集包含50,000张图像,测试集包含10,000张图像。
CIFAR-10数据集中的10个类别包括:airplane(飞机)、automobile(汽车)、bird(鸟)、cat(猫)、deer(鹿)、dog(狗)、frog(蛙)、horse(马)、ship(船)和truck(卡车)。本研究从中选择了6个动物类别:bird(鸟)、cat(猫)、deer(鹿)、dog(狗)、frog(蛙)和horse(马),构成了动物图像分类数据集。
数据集的特点包括:图像尺寸较小(32×32像素),处理后统一调整为224×224像素以适应预训练模型的输入要求;类别数量为6个动物类别;数据质量较好,图像清晰,标注准确。

2.4.2数据集分析
对数据集进行统计分析,可以更好地了解数据的特点,为模型设计和训练策略提供参考。
从类别分布来看,CIFAR-10数据集的10个类别分布均匀,每个类别包含5,000张训练图像和1,000张测试图像。本研究选择的6个动物类别同样分布均匀,每个类别包含约5,000张训练图像。
从图像内容来看,CIFAR-10数据集中的图像内容多样,同一类别内的图像在姿态、光照、背景等方面存在较大差异。例如,bird类别包含不同种类的鸟类,cat类别包含不同颜色、姿态的猫,这些多样性增加了分类任务的难度,但也使得模型具有更好的泛化能力。
从数据质量来看,CIFAR-10数据集的图像质量较好,噪声较少,但图像分辨率较低,细节信息有限。这要求模型能够从有限的像素信息中提取有效的特征表示。
数据集的划分采用分层抽样方法,将原始训练集进一步划分为训练集、验证集和测试集,比例分别为70%、15%和15%。这种划分方式确保了每个类别在不同集合中的比例保持一致,避免了类别不平衡问题。
3.1算法/模型介绍
3.1.1特征提取部分介绍
本系统采用迁移学习技术,利用在ImageNet数据集上预训练的深度卷积神经网络模型进行特征提取。预训练模型已经在大规模数据集上学习了丰富的视觉特征,这些特征对于动物图像分类任务具有很强的通用性。系统支持多种预训练的CNN架构作为特征提取器,ResNet50是50层的残差网络,通过引入残差连接解决了深层网络的梯度消失问题。ResNet50的特征提取部分包括多个残差块,每个残差块包含多个卷积层和批归一化层。残差连接使得网络能够学习残差映射,提高了训练效率和模型性能。
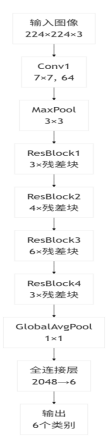
VGG16是16层的VGG网络,通过使用小卷积核(3×3)堆叠来构建深层网络。VGG16的特征提取部分包括13个卷积层和5个池化层,通过逐步下采样提取多尺度特征。VGG16的网络结构简单规整,易于理解和实现。
EfficientNet-B0是高效的复合缩放网络,通过同时缩放网络的深度、宽度和分辨率来实现更好的精度-效率平衡。EfficientNet-B0的特征提取部分使用移动倒置瓶颈卷积(MBConv)块,在保证性能的同时减少了参数量和计算量。
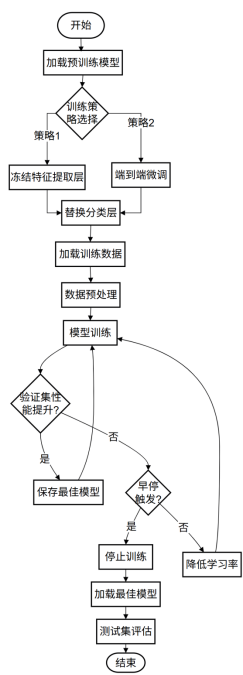
在迁移学习中,这些预训练模型的特征提取层(backbone)通常被冻结,只训练最后的分类层。这样可以充分利用预训练模型学到的特征表示,同时减少训练时间和计算资源需求。系统也支持端到端微调,解冻所有层进行训练,可能获得更好的性能,但需要更多的计算资源。
3.2数据预处理
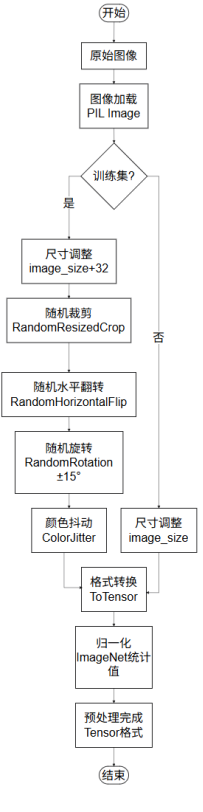
数据预处理是模型训练的重要环节,直接影响模型的性能和泛化能力。本系统实现了完整的数据预处理流程,包括图像裁剪、图像旋转、灰度图像转换等操作。

3.2.1图像裁剪
图像裁剪是数据预处理中的常用操作,主要用于统一图像尺寸和提取感兴趣区域。本系统实现中心裁剪和随机裁剪两种裁剪方式。
中心裁剪将图像从中心裁剪到指定尺寸,保证裁剪后的图像包含图像的主要信息。中心裁剪通常用于验证集和测试集,确保评估的一致性。

随机裁剪从图像中随机选择区域进行裁剪,增加了数据的多样性。随机裁剪通常用于训练集,通过随机性提高模型的泛化能力。本系统使用RandomResizedCrop实现随机裁剪,支持缩放比例在0.8到1.0之间随机选择,然后裁剪到指定尺寸。

3.2.2图像旋转
图像旋转是数据增强的重要手段,通过旋转图像增加数据的多样性。本系统实现了随机旋转功能,旋转角度在-15度到+15度之间随机选择。随机旋转能够模拟动物图像在拍摄时的角度变化,提高模型对旋转的鲁棒性。
旋转操作使用PIL库的rotate函数实现,支持双线性插值保证图像质量。为了避免旋转后图像边缘出现黑边,系统在旋转前会适当扩大图像尺寸。

3.2.3灰度图像转换
虽然本系统主要处理彩色图像,但也支持灰度图像转换功能。灰度图像转换将RGB图像转换为单通道灰度图像,可以减少数据维度和计算量。在某些场景下,灰度图像可能包含足够的分类信息,使用灰度图像可以简化模型结构。
灰度图像转换使用标准的RGB到灰度转换公式:Gray=0.299R+0.587G+0.114BGray = 0.299R + 0.587G + 0.114BGray=0.299R+0.587G+0.114B,其中R、G、B分别为红、绿、蓝通道的值。

3.2.4其他预处理技术
除了上述预处理技术外,本系统还实现了其他常用的数据增强技术。
随机水平翻转:以50%的概率对图像进行水平翻转,模拟动物图像在拍摄时的镜像变化。水平翻转是简单有效的数据增强方法,不会改变图像的语义信息。

颜色抖动:随机调整图像的亮度、对比度和饱和度,模拟不同光照条件下的图像。颜色抖动通过ColorJitter实现,亮度、对比度、饱和度的调整范围均为±20%。

归一化:将图像像素值从0, 255范围归一化到0, 1范围,然后使用ImageNet数据集的均值和标准差进行标准化。归一化使用ImageNet的统计值(mean=0.485, 0.456, 0.406, std=0.229, 0.224, 0.225),这是预训练模型训练时使用的归一化参数,保持一致有助于迁移学习的效果。

3.7系统功能模块
系统功能模块采用分层架构设计,从上到下分为Web前端界面层、Flask后端服务层、核心处理层、数据存储层和资源层。Web前端界面层提供用户交互界面,用户可以通过浏览器访问系统功能。Flask后端服务层包含API路由层和四个核心功能模块:模型训练模块、模型评估模块、图像预测模块和系统监控模块。核心处理层负责数据预处理、模型管理和推理引擎等核心功能。数据存储层包括MySQL数据库和文件系统,分别用于存储预测结果和模型文件、训练日志等。资源层提供GPU/CPU计算资源、模型文件和数据集文件等底层资源支持。系统功能模块划分如图3-13所示。
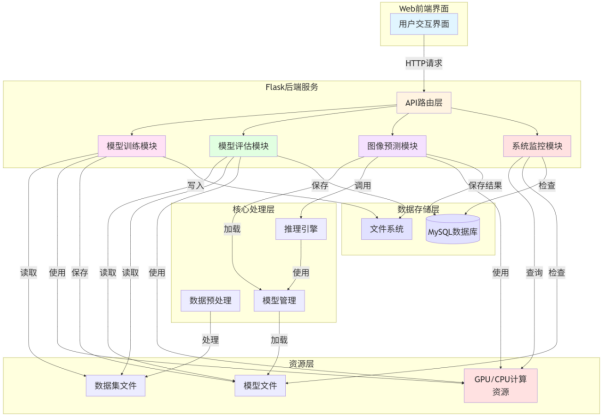
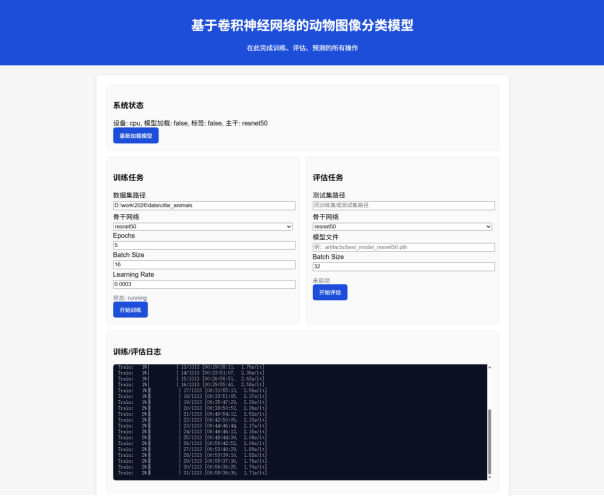
模型训练模块:接收用户通过Web界面配置的训练参数,包括数据集路径、模型架构(ResNet50、VGG16、EfficientNet等)、训练轮数、批次大小、学习率等。模块启动后台训练任务,实时记录训练日志,支持用户查看训练进度。训练过程中使用GPU/CPU计算资源,训练完成后将模型保存到文件系统。
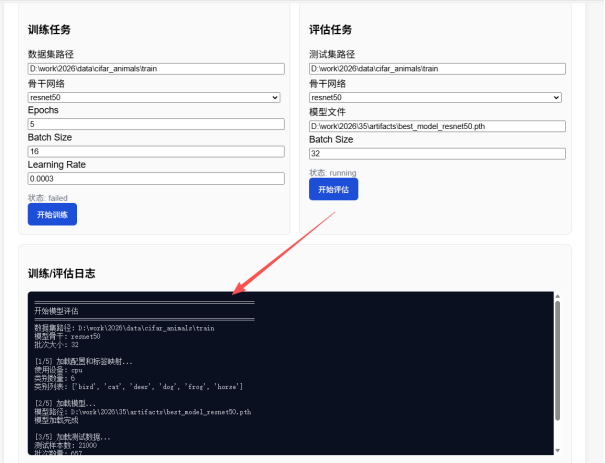
模型评估模块:接收用户配置的评估参数,包括数据集路径、模型路径、批次大小等。模块加载训练好的模型,在测试集上进行评估,计算准确率、精确率、召回率、F1-Score等指标,并生成混淆矩阵可视化图表。评估结果保存到文件系统,用户可以通过Web界面查看。
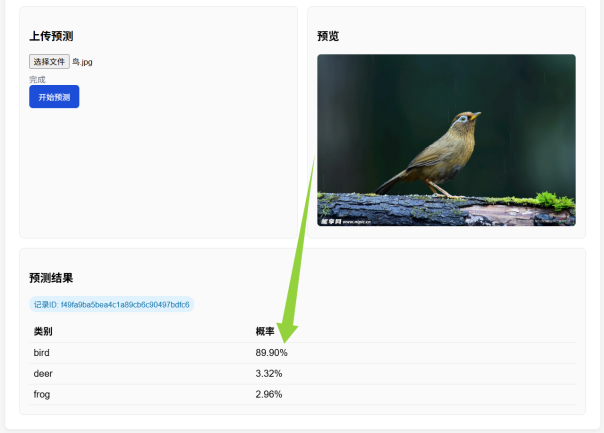
图像预测模块:接收用户上传的图像文件,加载已训练的模型,对图像进行预处理和推理,返回Top-3类别及其对应的概率值。预测结果保存到MySQL数据库,包括图像文件名、预测类别、概率值和时间戳等信息,便于后续查询和分析。
系统监控模块:实时监控系统状态,包括设备信息(CPU/GPU类型和状态)、模型加载状态(是否成功加载模型和标签映射)、数据库连接状态等。用户可以通过Web界面查看系统健康状态,确保系统正常运行。
实现效果展示