一、引言
Hudi 的核心设计目标是让数据湖具备数据库级别的事务能力(ACID、upsert、增量查询、时间旅行)。这一切的基础就是文件布局------Hudi 如何在存储上组织数据文件和元数据文件,使得读写操作既能高效定位数据,又能保证多版本并发控制(MVCC)。
与"一堆 Parquet 文件随意堆放在目录里"的传统数据湖不同,Hudi 引入了严格的层次结构:Base Path → 分区 → File Group → File Slice → 物理文件,外加.hoodie/目录管理全部元数据与时序信息。
二、Hudi 文件布局的核心概念
1. Table:Hudi 表
Hudi 表由两部分组成:
/hudi_table_path/
.hoodie/ # Hudi 元数据、Timeline、表属性等
partition_path_1/ # 数据分区目录
partition_path_2/.hoodie 目录非常关键,它并不是普通隐藏目录,而是 Hudi 表的事务控制中心。里面保存了:表属性(如 hoodie.properties)、 Timeline 相关元数据、表服务元数据、Metadata Table 相关数据等。
2. Partition:分区目录
Partition 通常对应业务中的日期、地区等字段,例如:
dt=2026-06-01/
region=cn/dt=2026-06-01/Hudi支持多级分区,也支持非分区表。分区设计直接影响:
- 写入并发度
- 小文件数量
- 查询裁剪效率
- 元数据规模
- Compaction / Clustering 成本
一个常见误区是:分区越细,查询越快。
实际上,在实时写入场景中,如果按小时、分钟甚至秒级分区,很容易造成大量小文件和高频元数据操作。Hudi 更推荐根据查询模式和写入规模选择适度分区,再配合索引、Metadata Table、Column Stats、Clustering 做优化。
3. File Group:文件组
File Group 是 Hudi 文件布局中非常核心的概念,每个 File Group都有一个唯一的 fileId 标识,一个文件组包含该文件在不同时间点的所有版本(File Slices)。
在一个分区内,Hudi 会将数据划分到多个 File Group 中:
dt=2026-06-01/
fileId-001_...parquet
fileId-002_...parquet
fileId-003_...parquet对于 Upsert 场景,Hudi 会通过索引找到某条记录当前所在的 File Group,然后将更新写到对应 File Group 的新 File Slice 或 Log File 中。
4. File Slice:文件切片
File Slice 可以理解为File Group 在某个特定 Instant 的快照,一个 File Slice 通常由以下部分组成:
File Slice = Base File + 0 到多个 Log File
###示意
File Group: fg-001
Slice t1:
fg-001_..._t1.parquet
Slice t2:
fg-001_..._t2.parquet
.fg-001_t2.log.1
.fg-001_t2.log.2其中:
- Base File:列式存储文件,常见为 Parquet
- Log File:行式或块式增量日志文件,用于记录更新、删除、部分变更等增量数据
- baseInstantTime:该 File Slice 对应的基准 Instant
5.文件组内部结构详解
File Group (file_id = "fg-001")
│
├── File Slice @ commit_1 (最旧)
│ └── base_file: fg-001_1_commit_1.parquet
│
├── File Slice @ commit_3
│ ├── base_file: fg-001_1_commit_3.parquet
│ ├── log_file: .fg-001_commit_3.log.1
│ └── log_file: .fg-001_commit_3.log.2
│
└── File Slice @ commit_5 (最新)
├── base_file: fg-001_1_commit_5.parquet
└── log_file: .fg-001_commit_5.log.1
###文件命名规则
Base File: [file_id]_[write_token]_[instant_time].[extension]
Log File: .[file_id]_[instant_time].log.[version]_[write_token]三、Hudi文件布局机制原理
1.COW vs MOR:两种表类型的文件布局策略

2.索引与文件定位机制
Hudi 的索引负责将记录键(Record Key)映射到文件组(File Group),这是实现高效 upsert 的关键:
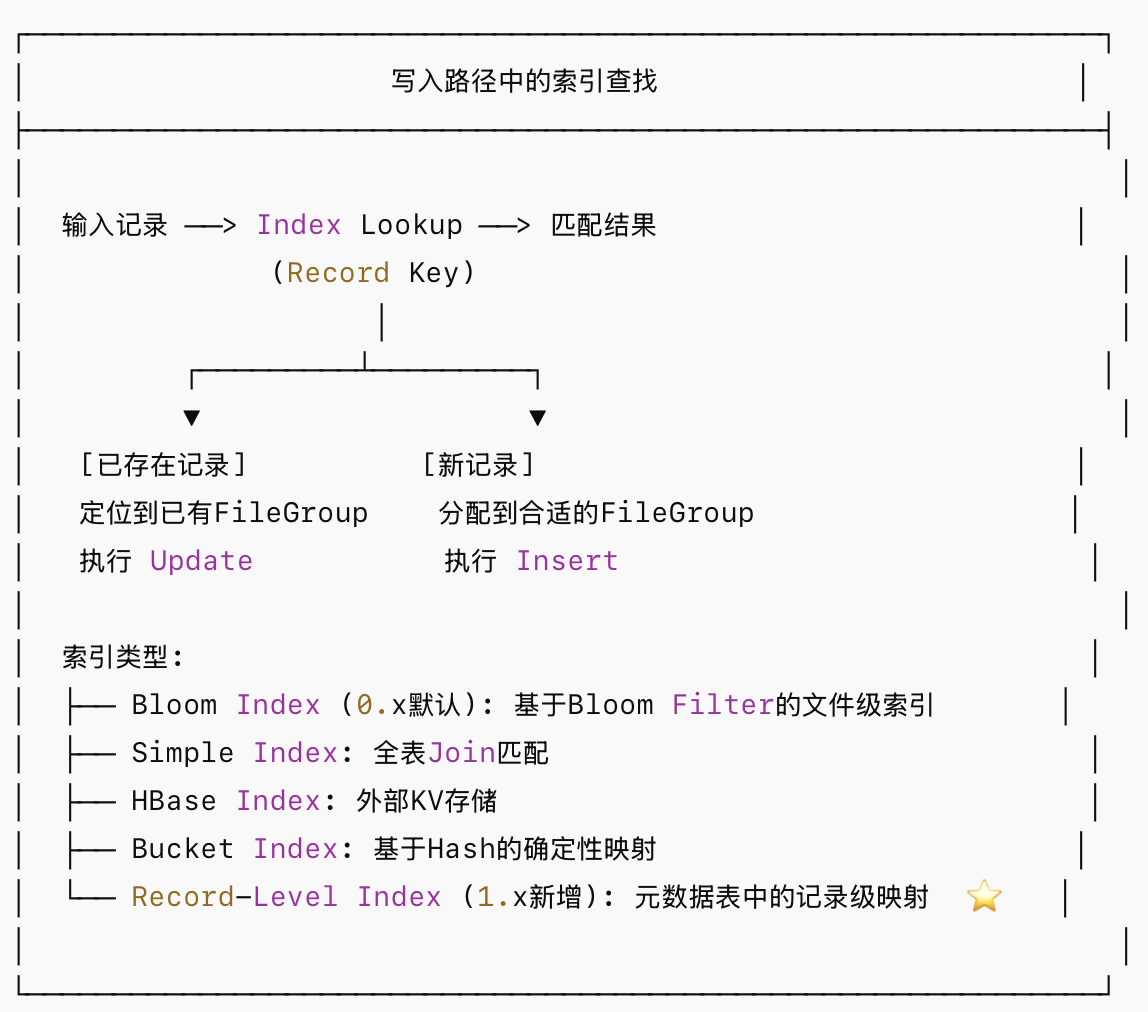
3.文件大小管理机制
Hudi 通过以下机制控制文件大小,避免小文件问题:
写入阶段 - Small File Handling:
- 写入时检测当前分区中小于目标大小的文件组
- 优先将新数据写入这些"未满"的文件组
- 配置参数:
hoodie.parquet.max.file.size(默认 120MB)
后台优化 - Clustering:
-
将多个小文件合并为更大的文件
-
可按列排序优化数据局部性(Data Locality)
-
支持同步和异步执行
Clustering 流程:
[small_1.parquet] ─┐
[small_2.parquet] ─┼──> Clustering ──> [large_1.parquet (sorted)]
[small_3.parquet] ─┘ [large_2.parquet (sorted)]策略:
├── Size-based: 按文件大小合并
└── Sort-based: 合并时按指定列排序(Z-Order/Hilbert/Linear)
4.Timeline 与文件可见性
Timeline 决定了哪些文件切片对读取可见:
Timeline: t1(commit) ─── t2(deltacommit) ─── t3(compaction) ─── t4(clean)
│ │ │ │
▼ ▼ ▼ ▼
FileGroup: [base@t1] [base@t1+log@t2] [base@t3] 清理旧版本
Snapshot Query @t2: 读取 base@t1 + merge log@t2
Snapshot Query @t3: 直接读取 base@t3
Incremental Query (t1,t3]: 返回 t1 之后变更的记录四、文件布局全景流程图
以一次 MOR 表 Upsert 写入为例,完整的文件布局交互示意图如下:
