一个真实的困境
假设你让 AI 帮你新增一个用户管理页面,用表格展示数据,写完后 review 一下代码再 commit。
这背后有一个关键问题:AI 怎么知道该调用哪些 skill?它面前可能有几十个 skill------新增页面、表格开发、code review、commit、国际化、权限配置......它必须从里面挑出需要的那几个,还要按正确的顺序组合起来。
那 skill 是怎么实现的呢?之前我之前文章已经详细说过,是给 skill 列表给大模型,让大模型自行选择。 但为什么是给 skill 让大模型自己选,而不是大模型通过查找的方式召回 skill 呢?比如用 RAG 做向量检索,或者用关键词匹配,本质都是一回事------让外部系统替模型决定该用什么。
如果通过查找召回 Skill
如果用查找来解决这个问题,以 RAG 为例,首先得在本地搭一套基础设施:一个向量数据库,一个 embedding 模型。每个 skill 的名称、描述、使用场景都要做向量化存进去。skill 新增或更新了,向量库要同步更新。
搭完之后,每次模型需要用到某个能力时,流程是这样的:
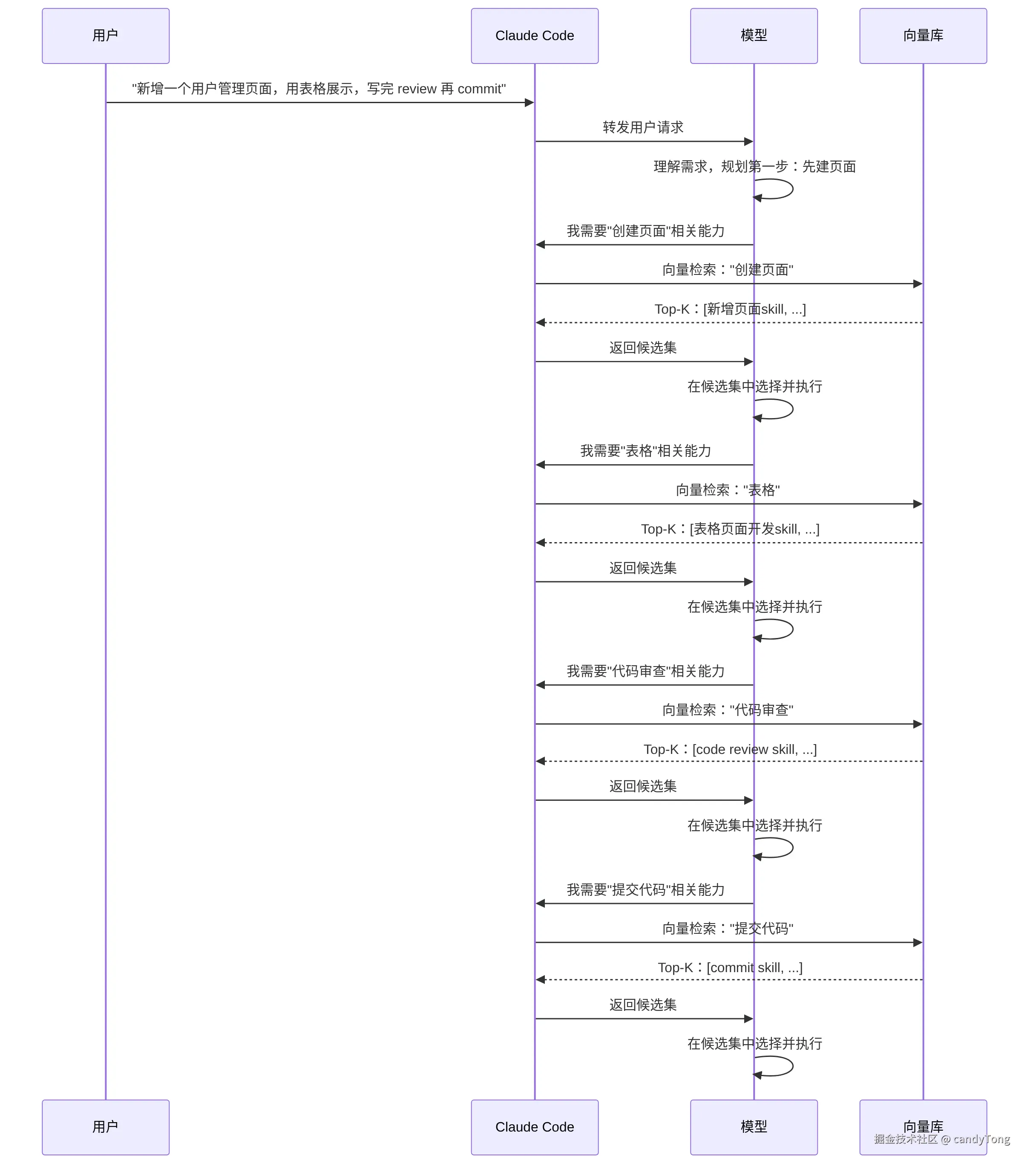
模型从头到尾都不知道有哪些 skill 可用。它只能描述"我现在需要什么能力",然后等查找系统返回候选集。模型甚至不知道自己漏掉了什么------如果某一步没有命中正确的 skill,链路就断在这里了。
这套方案有两个根本问题。
查找阶段没有模型参与
不管是向量检索还是关键词匹配,查找的本质都是数学计算------它能回答"这两段文本像不像",但不能回答"完成 A 之后应该做什么"。
"新增页面 → 表格开发 → 代码审查 → 提交"是一条有先后顺序的开发链路。查找衡量不了这种时序关系------就像搜索引擎能帮你找到相关文档,但不能帮你规划先读哪篇、再读哪篇。
模型在整个查找过程中是被动的:它只能在返回的结果里挑选,无法主动思考"我还有哪些 skill 可以用"。
模型看不到全局
每一步查找都只返回一个候选集,模型只能在这个"小窗口"里做决策。它不知道全局有哪些 skill 可用,也无法提前规划多步工作流。
如果某一步的查询没有命中正确的 skill,整个链路就断了。用户说"写完 review 再 commit",但查找系统认为"review"和 code review skill 的描述不够相似,模型就会漏掉这一步------它甚至不知道自己漏掉了什么。
更麻烦的是组合场景。假设你有四个 skill:新增页面、表格开发、code review、commit。用户说"帮我新增一个用户管理页面,用表格展示,写完 review 再 commit"。查找方案下,模型可能在第一步匹配到"新增页面",执行完后不知道还有"表格开发"------因为它从未看到过完整的 skill 列表,每一步都只能看到查找系统给的局部结果。
让模型自己选 Skill
另一种思路更直接:把所有可用 skill 的列表一次性交给模型,让模型自己决定调用哪些。
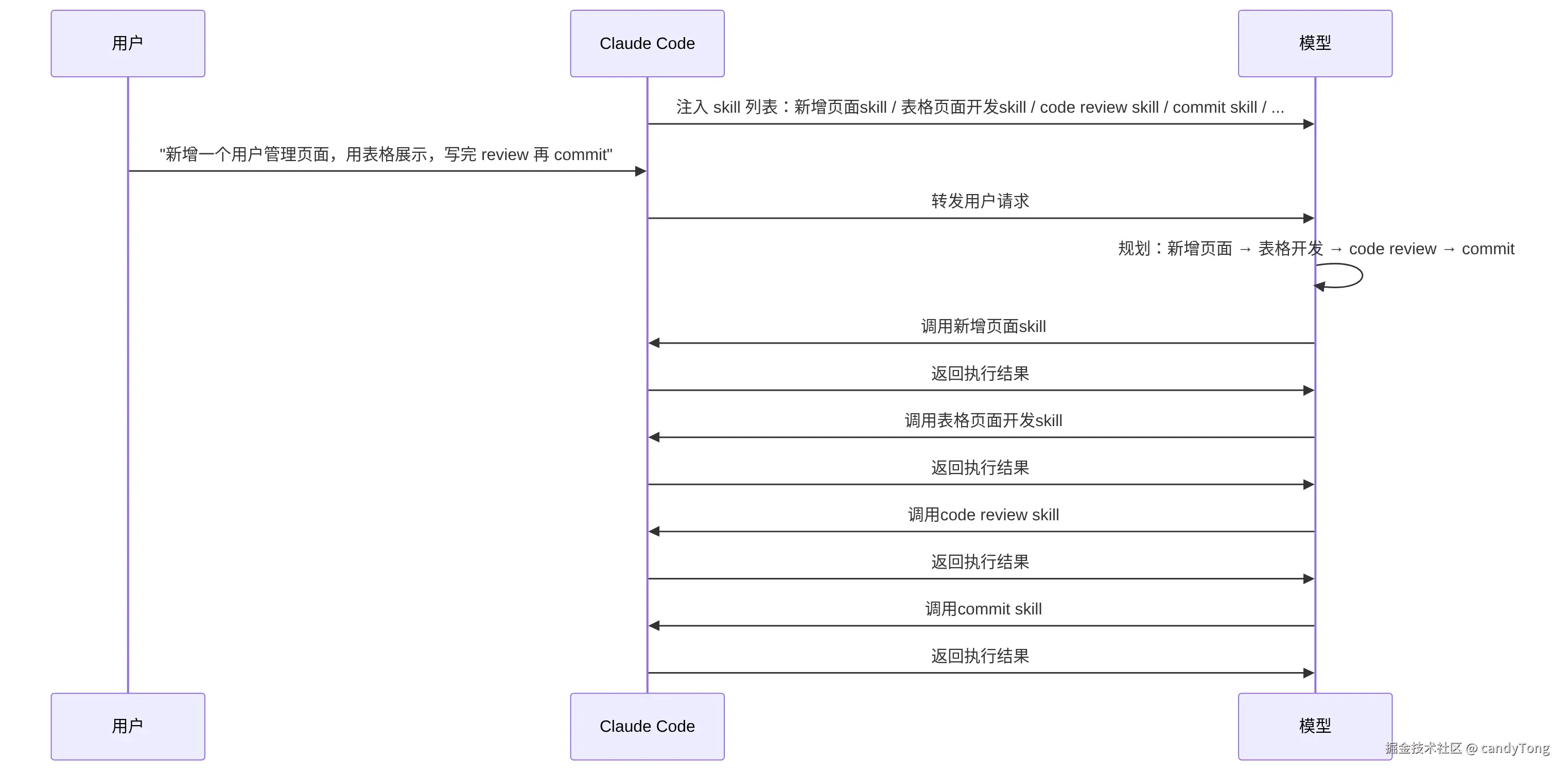
关键区别在于:模型在对话开始时就知道有哪些 skill 可用,不需要每一步都去问别人。
这种方案下,模型能做的远不止"找到匹配的 skill":
- 提前规划:看到用户说"新增页面,用表格展示,review 再 commit",模型一开始就知道四个 skill 都在列表里,直接规划出完整链路
- 组合编排:模型能自行决定先调哪个、再调哪个,比如先建页面骨架,再填充表格组件,最后审查和提交
- 灵活应变:如果开发过程中发现页面需要路由配置,模型知道列表里有哪些相关 skill,可以中途插入调用
查找 vs Skill 列表:核心区别
两种方案的本质差异不在于"用了什么技术",而在于决策权在谁手里。
| 查找召回(RAG 等) | Skill 列表 | |
|---|---|---|
| 决策链 | 用户输入 → 查找系统检索 → 候选集 → 模型在候选集中选择 | 用户输入 → 模型直接面对全量 skill 列表 → 模型自主选择 |
| 模型角色 | 被动,只能在检索结果里挑 | 主动,自己思考该调用什么 |
| 全局视野 | 看不到,每步只有局部候选集 | 看得到,一开始就知道所有可用 skill |
| 组合编排 | 依赖每步检索命中,可能断链 | 模型自行规划完整链路 |
| 基础设施 | 需要额外的查找系统(向量库、索引等) | 无额外依赖 |
| 扩展上限 | 理论上无上限 | 受上下文窗口限制,skill 描述会被截断 |
用一个日常场景类比:
- 查找 像是你问图书管理员"有没有关于机器学习的书",管理员根据关键词帮你找了几本。你不知道书架上还有什么其他书,也无法让管理员帮你规划"先读哪篇、再读哪篇"。
- Skill 列表 像是整个图书馆的目录摆在你面前,你自己决定借哪些、按什么顺序读。
查找在知识库检索、文档问答等场景仍然是最佳选择。但在"skill 选择"这个特定场景下,让模型直接面对全量列表、自主决策,比通过查找预筛选更可靠。
结论
这背后其实是一个 Agent 系统的设计模式问题:模型是决策者,还是消费者?
查找模式把模型当成消费者------外部系统先帮模型筛好候选集,模型再从里面挑一个用。模型的视野被限制在每一步的检索结果里,它不理解全局,也无法规划。
列表模式把模型当成决策者------系统负责提供上下文(skill 列表),模型负责理解任务、规划链路、选择工具。决策权在模型手里,系统不做越俎代庖的事。
人人都想当决策者掌控全局,但这不轻松。就像一个公司的老板,手下有 10 个人时,谁干什么活一目了然;手下有 100 个人时,就得设部门、设层级,不能事事亲力亲为了。
skill 列表也一样------几十个 skill,模型能直接看、直接选;几百个 skill,描述就得压缩;几千个 skill,就得分层,先看分类摘要,再看详情。这不是列表方案的缺陷,而是所有决策者都要面对的信息过载问题。
但至少,决策者知道自己缺什么、该找谁。消费者不知道。
如果你觉得这篇文章有帮助,欢迎点赞、收藏,也可以关注我。