一、FM 是什么?干什么用的?
FM(Factorization Machine,因子分解机) 由 Steffen Rendle 于 2010 年 在论文 "Factorization Machines" (ICDM) 中提出。
一句话定位 :FM 是一种 专为高维稀疏数据设计的监督学习模型 ,它在线性模型的基础上,自动建模所有特征的两两交叉(二阶交互) ,但通过 矩阵分解/隐向量内积 的技巧,把参数量从 O(n²) 压到 O(n·k),从而在稀疏场景下 既能学到交叉特征,又不会因数据稀疏而垮掉。
典型用途:
| 领域 | 具体任务 |
|---|---|
| 推荐系统 | 评分预测、个性化排序(user × item × context) |
| 计算广告 | CTR(点击率)预估、CVR(转化率)预估 |
| 风控/营销 | 高维稀疏特征下的二分类/回归预测 |
| 搜索排序 | Learning-to-Rank 中的特征交互建模 |
本质上,FM 是 多项式回归的表达力 与 矩阵分解的参数效率 的结合体。
二、为什么需要 FM:传统方法的痛点
线性模型太"笨"------忽略特征交互
在 CTR 预估中,一个经典事实是:
"男性 ∧ 大学生 ∧ 游戏类广告" → 点击率很高
但单独的「男性」「大学生」「游戏类」每个都不够说明问题
如果用纯线性模型(如 Logistic Regression):
y^=w0+∑i=1nwixi\hat{y} = w_0 + \sum_{i=1}^{n} w_i x_iy^=w0+i=1∑nwixi
它把每个特征当独立变量,完全捕捉不到"特征之间的组合效应"。
人工特征交叉不可行------维度爆炸 + 极度稀疏
一个朴素的改进:加入 二阶交叉项(二次多项式模型):
y^=w0+∑iwixi+∑i=1n∑j=i+1nwij⋅xixj\hat{y} = w_0 + \sum_{i} w_i x_i + \sum_{i=1}^{n}\sum_{j=i+1}^{n} w_{ij} \cdot x_i x_jy^=w0+i∑wixi+i=1∑nj=i+1∑nwij⋅xixj
问题来了:
- 特征维度 n 动辄 上万甚至百万(想想 user_id、item_id 做了 one-hot 之后)
- 交叉项参数 wijw_{ij}wij 的数量是 O(n²) → 根本存不下、学不了
- 更致命的是:数据是 极度稀疏的 (每行只有极少几个非零值),绝大多数交叉组合在训练集里 从未同时出现过 → 对应的 wijw_{ij}wij 根本没有样本支撑,无法估计
这就是为什么 FM 的诞生如此关键------它需要一种方式,让"没见过的特征组合"也能被合理估计。
三、FM 的核心原理:用「隐向量内积」替代独立权重
核心思想
与其给每个交叉组合 (i,j)(i, j)(i,j) 分配一个 独立参数 wijw_{ij}wij,不如:
给 每个特征 i 分配一个 低维隐向量(latent vector) vi∈Rk\mathbf{v}_i \in \mathbb{R}^kvi∈Rk,然后令交叉权重等于两个隐向量的 内积:
wij=⟨vi,vj⟩=∑f=1kvi,f⋅vj,fw_{ij} = \langle \mathbf{v}i, \mathbf{v}j \rangle = \sum{f=1}^{k} v{i,f} \cdot v_{j,f}wij=⟨vi,vj⟩=f=1∑kvi,f⋅vj,f
这就叫 Factorization(因子分解) ------把原本需要 O(n2)O(n^2)O(n2) 个独立参数的交叉权重矩阵 W\mathbf{W}W,分解为两个 n×kn \times kn×k 的低秩隐矩阵的乘积(近似),k≪nk \ll nk≪n。
完整 FM 预测公式(二阶 FM)
y^(x)=w0+∑i=1nwixi+∑i=1n∑j=i+1n⟨vi,vj⟩⋅xixj\boxed{\hat{y}(\mathbf{x}) = w_0 + \sum_{i=1}^{n} w_i x_i + \sum_{i=1}^{n}\sum_{j=i+1}^{n} \langle \mathbf{v}_i, \mathbf{v}_j \rangle \cdot x_i x_j}y^(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑n⟨vi,vj⟩⋅xixj
| 项 | 含义 |
|---|---|
| w0w_0w0 | 全局偏置(bias) |
| ∑wixi\sum w_i x_i∑wixi | 一阶项:每个特征自身的线性贡献 |
| ∑∑⟨vi,vj⟩xixj\sum\sum \langle\mathbf{v}_i,\mathbf{v}_j\rangle x_i x_j∑∑⟨vi,vj⟩xixj | 二阶交互项:所有特征两两交叉的贡献,权重由隐向量内积给出 |
其中隐向量维度 k 是超参数(常见取 8~128,实践中 10~50 就很好)。
为什么隐向量内积能解决"稀疏"问题?
这是 FM 最精妙的地方:
假设特征对 (i,j)(i, j)(i,j) 在训练集中 从未同时非零 (所以你没有直接样本学 wijw_{ij}wij),但只要特征 iii 和 jjj 各自 在其它样本中出现过,它们的隐向量 vi\mathbf{v}_ivi 和 vj\mathbf{v}_jvj 就会被 其它交叉组合间接更新 (梯度会通过所有包含 iii 或 jjj 的项传播)。最终 ⟨vi,vj⟩\langle\mathbf{v}_i,\mathbf{v}_j\rangle⟨vi,vj⟩ 仍能给出一个 合理的估计。
这正是从 矩阵分解(Matrix Factorization) 那里借来的思想------用户没评分的物品,仍可通过隐因子推断。
四、关键优化:把 O(n²) 的计算变成 O(n·k)
直接按双重循环算交叉项是 O(n²·k),不可接受。FM 有一个著名的数学恒等式(Rendle trick):
∑i=1n∑j=i+1n⟨vi,vj⟩xixj=12∑f=1k(∑i=1nvi,fxi)2−∑i=1nvi,f2xi2\sum_{i=1}^{n}\sum_{j=i+1}^{n} \langle\mathbf{v}_i,\mathbf{v}j\rangle x_i x_j = \frac{1}{2} \sum{f=1}^{k} \left \\left(\\sum_{i=1}\^{n} v_{i,f} x_i\\right)\^2 - \\sum_{i=1}\^{n} v_{i,f}\^2 x_i\^2 \\righti=1∑nj=i+1∑n⟨vi,vj⟩xixj=21f=1∑k (i=1∑nvi,fxi)2−i=1∑nvi,f2xi2
推导直觉:
(∑ivi,fxi)2=∑ivi,f2xi2+2∑i<jvi,fvj,fxixj(\sum_i v_{i,f}x_i)^2 = \sum_i v_{i,f}^2 x_i^2 + 2\sum_{i<j} v_{i,f}v_{j,f}x_i x_j(i∑vi,fxi)2=i∑vi,f2xi2+2i<j∑vi,fvj,fxixj
移项即可得到上述等式。
复杂度对比
| 方式 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 朴素二阶交叉 | O(n²·k) | O(n²) |
| FM + Rendle 恒等式 | O(n·k)(稀疏下 ≈ O(nnz·k)) | O(n·k) |
| 多项式核 SVM | 通常 O(n²) 或依赖 dual | --- |
在稀疏场景下(每行只有几十~几百个非零值),FM 的推断/训练代价是 线性于非零特征数 的,这就让它能在工业级数据上跑起来。
五、运行原理示意流程(从原始数据到预测)
下面用一个 电影推荐/CTR 场景 走一遍完整流程:
Step 1:原始数据示例
| 样本 | 用户 | 电影 | 类型 | 时间槽 | 标签:评分/点击 |
|---|---|---|---|---|---|
| 1 | 用户#103 | 电影#579 | 动作 | 晚上 | 1(点击/喜欢) |
| 2 | 用户#887 | 电影#1203 | 喜剧 | 下午 | 0 |
Step 2:特征编码(One-hot / Multi-hot → 超高维稀疏向量)
对 user_id、movie_id、genre、time_slot 做 one-hot 编码后,每条样本变成一个 几万~百万维稀疏向量 x,其中只有少数几个位置为 1(或计数),其余全是 0。
例如:x=0,...,1user#103,...⏟user域,0,...,1movie#579,...⏟item域,0,...,1动作,...⏟genre域,...x = \\underbrace{0,...,\\mathbf{1}_{user\\#103},...}_{\\text{user域}}, \\underbrace{0,...,\\mathbf{1}_{movie\\#579},...}_{\\text{item域}}, \\underbrace{0,...,\\mathbf{1}_{动作},...}_{\\text{genre域}}, ...x=user域 0,...,1user#103,...,item域 0,...,1movie#579,...,genre域 0,...,1动作,...,...
Step 3:FM 模型参数初始化
- w0∈Rw_0 \in \mathbb{R}w0∈R:全局偏置
- w∈Rn\mathbf{w} \in \mathbb{R}^nw∈Rn:一阶权重(实际只需存非零特征对应的)
- V∈Rn×k\mathbf{V} \in \mathbb{R}^{n \times k}V∈Rn×k:每个特征的隐向量(同样只需存活跃特征对应的行)
初始化一般用小的随机值(如 Gaussian(0, 0.01))。
Step 4:前向预测(对一条样本 x)
① 一阶项:linear = w₀ + Σᵢ∈active(wᵢ · xᵢ)
② 二阶项(用Rendle trick):
for f = 1..k:
s₁ = Σᵢ∈active(vᵢ,ₙ · xᵢ) // 先求 sum
s₂ = Σᵢ∈active(vᵢ,ₙ² · xᵢ²) // 求平方和
interaction += (s₁² - s₂)
interaction = 0.5 · interaction
③ ŷ = linear + interaction
④ 如果是CTR→ p_click = sigmoid(ŷ)Step 5:训练(SGD / Mini-batch SGD / Adam)
对二分类(CTR),损失用 LogLoss:
L=−ylogσ(y\^)+(1−y)log(1−σ(y\^))+λ(∥w∥2+∥V∥2)\mathcal{L} = -y \\log \\sigma(\\hat{y}) + (1-y)\\log(1-\\sigma(\\hat{y})) + \lambda(\|\mathbf{w}\|^2 + \|\mathbf{V}\|^2)L=−ylogσ(y\^)+(1−y)log(1−σ(y\^))+λ(∥w∥2+∥V∥2)
梯度(关键):
∂y^∂w0=1,∂y^∂wi=xi,∂y^∂vi,f=xi(∑j=1nvj,fxj)−vi,fxi2\frac{\partial \hat{y}}{\partial w_0} = 1, \quad \frac{\partial \hat{y}}{\partial w_i} = x_i, \quad \frac{\partial \hat{y}}{\partial v_{i,f}} = x_i\left(\sum_{j=1}^{n} v_{j,f} x_j\right) - v_{i,f} x_i^2∂w0∂y^=1,∂wi∂y^=xi,∂vi,f∂y^=xi(j=1∑nvj,fxj)−vi,fxi2
注意到 ∑jvj,fxj\sum_j v_{j,f} x_j∑jvj,fxj 对每个样本只需要算一次 (就是上面 trick 里的 s₁),然后分发到每个活跃特征 iii。
Step 6:推断/排序
训练完后,对新用户-物品对构造稀疏向量 x ,跑一次前向预测,输出的 y^\hat{y}y^(或 sigmoid 后概率)就是 预估分数,用于排序推荐。
六、FM 的优劣势一览
| 优势 | 局限 |
|---|---|
| 自动二阶交叉,不需人工特征工程 | 只显式建模 二阶交互(不擅长更高阶) |
| 参数量 O(n·k),适合高维稀疏 | 隐向量是"全局共享"的,无法区分特征所属的 field 语义差异(FFM 解决) |
| 稀疏数据下泛化能力强(没见过的组合也能估) | 二阶表达能力有天花板,复杂非线性关系需更深模型 |
| 训练和推断复杂度线性于 nnz,工程友好 | 相比纯 DNN 方案,拟合能力上限较低 |
| 可作为强基线,也可嵌入更大网络(DeepFM等) | --- |
七、应用场景全景
1. 推荐系统(最核心阵地)
- 协同过滤的泛化版:FM = 矩阵分解 + 还能用 side information(用户画像、物品属性、上下文)
- 场景:电商"猜你喜欢"、视频推荐 feed 排序、豆瓣评分预测
- 特征一般分域编码:
[user_id_onehot | item_id_onehot | user_age_bucket | item_category | hour_of_day | ...]
2. 广告 CTR / CVR 预估
- Criteo、Avazu 等经典 CTR 竞赛中 FM/FFM 曾拿冠军
- 特征包括:广告 id、广告主 id、用户兴趣标签、设备类型、媒体站点、时段......
- 这些数据天然 高基数 + one-hot → 极稀疏 → FM 的理想战场
3. 搜索排序(Learning to Rank)
- 将 query 特征、doc 特征、query×doc 匹配特征编码为稀疏向量,FM 捕捉交叉
4. 风控 / 反欺诈 / 营销响应
- 客群标签 × 产品类型 × 渠道 × 时段的稀疏交叉建模
八、FM 家族 & 类似模型:从 FM 到今天的全景对比
这是理解 FM 在模型进化树上位置的 最关键部分:
演进脉络
Linear Model (LR)
│
├── 人工交叉特征 + LR → 繁琐、爆炸、不可持续
│
├── 二次多项式模型(Poly-2)→ 参数 O(n²),稀疏下崩
│ │
│ └── ★ FM ← 用隐向量内积降参到 O(n·k),救活了交叉
│ │
│ ├── FFM(Field-aware FM):每个特征在每个field用不同隐向量
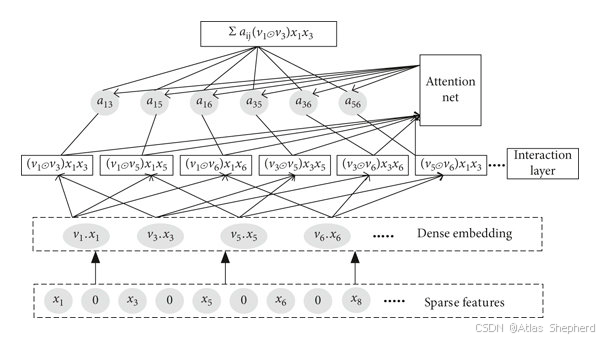
│ ├── AFM(Attention FM):给交叉项加权(注意力机制)
│ ├── NFM(Neural FM):用神经网络替代/增强交叉池化
│ │
│ └── FM + DNN 融合路线:
│ ├── Wide & Deep(Google '16):Wide=人工交叉 + Deep=DNN
│ ├── DeepFM(华为 '17):直接用FM替掉Wide部分 → 全自动
│ ├── xDeepFM:显式向量级高阶交叉
│ └── DCN / DCN-M:cross network 做特征交叉详细对比表
| 模型 | 核心机制 | 交叉能力 | 参数量 | 是否需要人工交叉 | 典型场景 |
|---|---|---|---|---|---|
| LR | 纯线性 | ❌ 无 | O(n) | ✅ 必须手工做 | 早期工业基线 |
| Poly-2 | 显式二阶交叉,独立 wijw_{ij}wij | 二阶 | O(n²) | 不需要 | 理论可用,但稀疏下不可行 |
| ★ FM | 二阶交叉,但 wij=⟨vi,vj⟩w_{ij}=\langle v_i,v_j\ranglewij=⟨vi,vj⟩(共享隐向量) | 二阶(参数共享) | O(n·k) ✅ | ❌ 全自动 | 推荐/CTR 主力基线 |
| FFM | FM + Field 概念:特征 iii 在不同 field 用不同隐向量 vi,fjv_{i,f_j}vi,fj | 二阶(field感知) | O(n·k·F) | ❌ | 竞赛利器,效果常优于FM,但更慢 |
| AFM | FM + Attention:交叉项加注意力权重,αij\alpha_{ij}αij 学出哪些组合更重要 | 二阶(加权) | O(n·k) | ❌ | 想强化"关键交叉" |
| NFM | FM的BI层(交叉池化) → 接MLP,学高阶 | 二阶→高阶 | O(n·k)+DNN | ❌ | 兼顾表达能力与交叉 |
| Wide & Deep | Wide=线性/人工交叉 + Deep=DNN高阶 | 低阶+高阶 | 取决于DNN | ✅ Wide部分要人工 | Google Play 推荐 |
| DeepFM | FM部分 (自动低阶交叉)+ DNN部分(高阶),共享Embedding | 低阶+高阶,全自动 | O(n·k)+DNN | ❌ ✅ | 工业界最常用的 FM+DL 融合 |
| DCN / xDeepFM | Cross Network / Compressed Interaction Network 做结构化高阶交叉 | 显式高阶 | 可控 | ❌ | 追求更强交叉表达 |
FFM 的关键补充
FM 中每个特征只有一个隐向量 vi\mathbf{v}_ivi,跟谁交叉都用同一个。
FFM 认为:特征 iii 来自 user 域还是 item 域语义不同,所以给它 按 field 分组 :特征 iii 在与 field fjf_jfj(特征 jjj 所属 field)交叉时用 vi,fj\mathbf{v}_{i,f_j}vi,fj。参数量变为 n·F·k(F = field数),效果更好但慢一些。
九、极简 NumPy 示意代码(帮助建立直觉)
python
import numpy as np
class FM:
def __init__(self, n_features, k=10, lr=0.05, reg=1e-3):
self.w0 = 0.0
self.W = np.zeros(n_features)
self.V = np.random.randn(n_features, k) * 0.01
self.lr = lr
self.reg = reg
def _predict(self, x_sparse_indices, x_sparse_values):
"""x 是稀疏表示: indices=非零位列表, values=对应值"""
# 一阶
linear = self.w0 + np.dot(self.W[x_sparse_indices], x_sparse_values)
# 二阶 (Rendle trick)
vx = self.V[x_sparse_indices] * x_sparse_values[:, None] # (nnz, k)
sum_vx = vx.sum(axis=0) # (k,)
sum_sq = (vx ** 2).sum(axis=0) # (k,)
interaction = 0.5 * ((sum_vx ** 2) - sum_sq).sum()
return linear + interaction
def fit(self, data, epochs=50):
"""data: list of (indices, values, y)"""
for ep in range(epochs):
np.random.shuffle(data)
for idxs, vals, y in data:
y_hat = self._predict(idxs, vals)
p = 1.0 / (1.0 + np.exp(-y_hat))
err = p - y # ∂L/∂y_hat for LogLoss
# 更新
self.w0 -= self.lr * (err + self.reg * self.w0)
self.W[idxs] -= self.lr * (err * vals + self.reg * self.W[idxs])
vx = self.V[idxs] * vals[:, None]
sum_vx = self.V[idxs].T @ vals # 或直接累: vx.sum(0)
# 完整梯度更新省略细节------工程实现建议用现成库实际生产中别手写------用
xlearn、libffm、lightfm或 PyTorch 版实现更稳。