在开始之前,我们先理清一个关键背景:Kafka 正在经历一个重要的架构演进------逐步移除对 ZooKeeper 的依赖,转向自研的 KRaft (Kafka Raft) 模式。这不仅是安装方式的差异,更代表了Kafka未来的架构方向,理解这一点对你后续的学习和选型很有帮助。
为适应新版本的变化,本文以KRaft (Kafka Raft) 模式进行讲解。
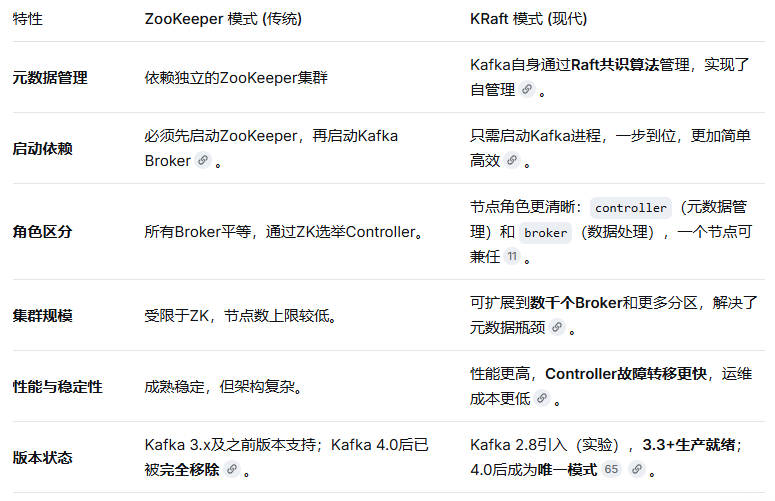
一、历史版本对比
二、安装
这里以KRaft模式为例,使用 Docker Compose 安装,展示Kafka 3.x+的快速启动过程:
1.前置条件:Linux服务器安装 Docker 和 Docker Compose。
2.文件目录:/apps/kafka
3.创建 docker-compose.yml:
bash
services:
kafka:
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/apache/kafka:3.8.0
container_name: kafka
hostname: kafka
ports:
- "9092:9092"
- "9093:9093"
volumes:
- /apps/kafka/data:/var/lib/kafka/data
- /apps/kafka/logs:/opt/kafka/logs
restart: always
environment:
TZ: Asia/Shanghai
# KRaft 核心配置
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka:9093
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
# Listener 配置
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://你的服务器IP:9092
# 其他必要配置
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
KAFKA_DELETE_TOPIC_ENABLE: "true"
# 生产优化
KAFKA_HEAP_OPTS: -Xms1G -Xmx1G
KAFKA_NUM_PARTITIONS: 3
KAFKA_LOG_RETENTION_HOURS: 168
KAFKA_LOG_SEGMENT_BYTES: 536870912
kafka-ui:
image: ghcr.io/kafbat/kafka-ui:latest
container_name: kafka-ui
ports:
- "8088:8080"
restart: always
environment:
TZ: Asia/Shanghai
KAFKA_CLUSTERS_0_NAME: local-kafka
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: 你的服务器IP:9092
depends_on:
- kafka
networks:
default:
name: app-net
external: true4.启动:docker compose up -d
*注意*:swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/apache/kafka:3.8.0,这个镜像仓库可能会拉取失败;需要手动拉取:命令:docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/apache/kafka:3.8.0;再执行:docker compose up -d
5.验证:docker compose logs -n 200 kafka
三、常用命令行操作 (CLI)
熟悉Kafka自带的命令行工具,是进行开发和运维的基础。
所有命令都在Kafka安装目录的/bin目录下。
1.主题管理:kafka-topics.sh
是管理Topic的核心工具,基本操作如下:

关键参数补充:
-
--partitions:指定Topic的分区数,决定了数据的并行处理能力上限。 -
--replication-factor:指定Topic的副本数(必须 ≤ Broker数量),保障数据高可用。 -
--config:设置特定配置,如消息保留时间--config retention.ms=172800000。
2.消息收发:kafka-console-producer.sh 和 kafka-console-consumer.sh
这两个工具是用于快速测试消息生产与消费的利器。
生产者示例:
|-------------------------------------------------------------------------------------------------------------------------------|
| # 启动生产者,向 topic 为 'test' 发送消息 ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test > 输入第一条消息 > 输入第二条消息 |
输入消息内容,每行是一条独立的Kafka消息。
常用参数--property parse.key=true让你可以按key:value格式发送带key的消息。
消费者示例:
|-------------------------------------------------------------------------------------------------------------------------------|
| # 启动消费者,从 topic 为 'test' 读取消息 ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning |
该命令会实时打印从test主题拉取到的消息。
注意--from-beginning参数,它会让消费者从该主题的最起始位置开始消费。
📌 消费者组管理:kafka-consumer-groups.sh
消费者组是Kafka实现高吞吐和可扩展消费的核心,该命令用于监控和管理消费者组的状态。
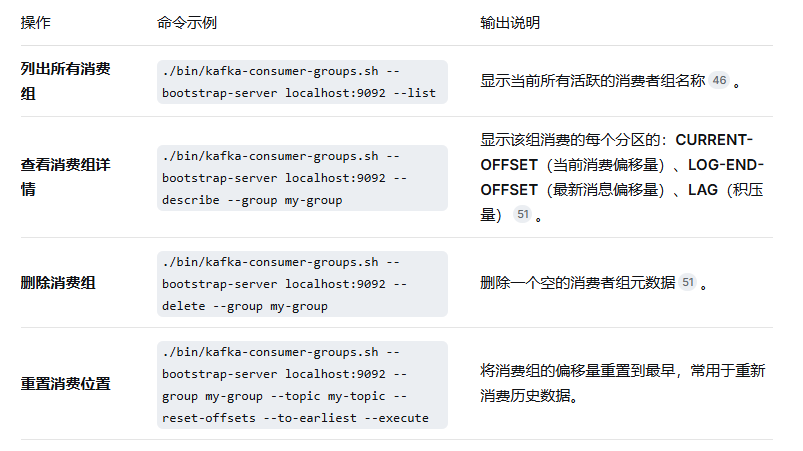
核心监控指标:LAG (消息积压)
在 --describe 的输出中,LAG是最关键的指标之一。它表示生产者速度 > 消费者速度,即有多条消息尚未被消费,这是排查消费性能问题的首要入口。