K 个一组翻转链表:优雅的"剪贴式"迭代解法详解
摘要 :LeetCode 25 题"K 个一组翻转链表"是链表操作中的经典难题。相比于复杂的区间内指针交换,本文将介绍一种更符合直觉的 "断链 + 整体翻转" 策略。通过引入虚拟头节点和辅助函数,我们将复杂的逻辑拆解为简单的步骤,配合详细的代码注释,助你彻底掌握这一解题套路。
1. 题目回顾
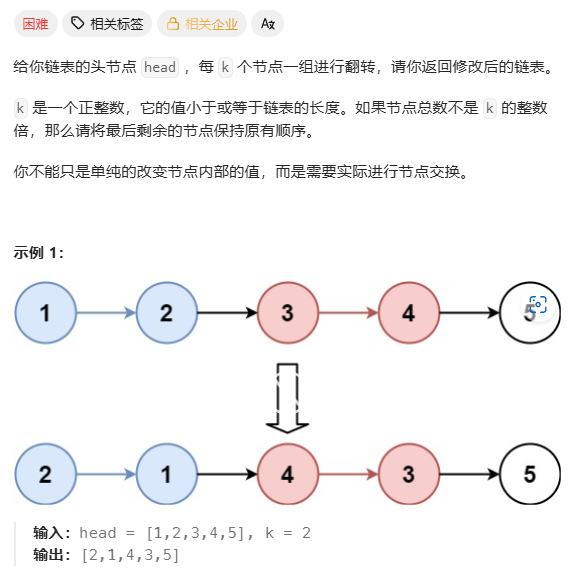
给定一个链表的头节点 head,每 k 个节点一组进行翻转,请你返回修改后的链表。
- k 是一个正整数,它的值小于或等于链表的长度。
- 如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
- 进阶要求:你只能进行常数级的额外空间复杂度(即 O(1)O(1) ),不能只是单纯的改变节点内部的值,而是要实际进行节点交换。
示例:
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
2. 核心思路:分治与模块化
面对这种"局部有序、整体重复"的问题,我们可以采用 分治法 (Divide and Conquer) 的思想,但这里我们使用 迭代 的方式来实现。
与其在一个长链表中小心翼翼地交换指针,不如把问题简化为两个子任务:
- 分解(Divide):找到当前的 k 个节点,将它们从原链表中"剪"下来。
- 解决(Conquer):对这 k 个节点组成的独立小链表,执行一次标准的【反转链表】操作。
- 合并(Combine):将反转后的小链表重新"粘"回原链表的正确位置。
这种方法的核心优势在于:复用了经典的"反转整个单链表"算法,大大降低了出错概率。
3. 算法详细步骤
3.1 递归终止条件(边界处理)
虽然这是迭代解法,但我们需要处理循环的终止条件:
- 剩余节点不足 k 个:这是最关键的条件。在每一轮开始前,我们需要先遍历一遍,确认后面是否还有 k 个节点。如果没有,直接跳出循环,保持剩余部分原样。
- 空链表 :如果
head为空,直接返回。
3.2 分解过程:寻找与断链
我们需要维护两个关键指针:
pre:指向待翻转组的前驱节点(上一组的尾部)。end:用来向后探路,找到待翻转组的最后一个节点。
操作步骤:
- 让
end向后走 k 步。 - 记录当前组的起始节点
start = pre.next。 - 记录下一组的起始节点
next = end.next。 - 断链 :执行
end.next = null。此时,[start ... end]变成了一个独立的、长度为 k 的子链表。
3.3 解决过程:调用通用反转
既然已经断链成了独立子链表,我们就可以直接调用通用的 reverse(head) 函数。
- 传入参数:
start(原头节点)。 - 返回值:新的头节点(即原来的
end)。 - 连接前驱:
pre.next = reverse(start)。
3.4 合并过程:重连与复位
翻转完成后,原来的 start 变成了这一组的尾节点。
- 重连 :执行
start.next = next,将当前组尾部连接到下一组的头部。 - 复位 :更新
pre = start,end = start,准备处理下一组。
4. 代码实现(Java 版本)
public class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
// 1. 创建虚拟头节点(dummy),它的next指向真实的头节点head
// 这样做的好处是:当第一组k个节点翻转后,头节点发生了变化,
// 有了dummy,我们最后直接返回dummy.next即可,不用单独处理头节点变化的情况。
ListNode dummy = new ListNode(0);
dummy.next = head;
// 2. 初始化两个指针 pre 和 end,都指向虚拟头节点
// pre:指向【待翻转组】的前一个节点(前驱节点)
// end:用来向后探路,找到【待翻转组】的最后一个节点
ListNode pre = dummy;
ListNode end = dummy;
// 3. 只要 end 后面还有节点,就说明可能还有需要翻转的组,继续循环
while (end.next != null) {
// 4. 让 end 指针向后走 k 步,找到当前这一组的尾节点
// 循环条件加上 end != null 是为了防止链表长度不足 k 时出现空指针异常
for (int i = 0; i < k && end != null; i++) {
end = end.next;
}
// 5. 判断剩余节点是否足够 k 个
// 如果 end 变成了 null,说明刚才没走够 k 步链表就到头了
// 根据题目要求,剩余不足 k 个的节点保持原样,直接跳出循环结束处理
if (end == null) break;
// 6. 记录关键节点,为断链和重新拼接做准备
ListNode start = pre.next; // start 是当前待翻转组的第一个节点(翻转后会变成这一组的尾节点)
ListNode next = end.next; // next 是下一组链表的头节点(先保存起来,防止断链后找不到后面的路)
// 7. 【关键操作:断链】
// 将当前组的尾节点(end)的 next 置为 null
// 这样我们就把 [start ... end] 这 k 个节点从原链表上完整地"剪"了下来,形成了一个独立的小链表
end.next = null;
// 8. 调用通用的反转链表函数,翻转刚才剪下来的这 k 个节点
// 翻转后,pre.next 应该指向翻转后的新头节点(也就是原来的 end)
pre.next = reverse(start);
// 9. 【关键操作:重新拼接】
// 刚才的 start 节点经过翻转后,已经变成了当前组的尾节点
// 让它指向之前保存好的下一组头节点(next),把断开的链表重新连起来
start.next = next;
// 10. 指针后移,准备处理下一组 k 个节点
pre = start; // pre 移动到当前组的尾部(即 start),作为下一组的前驱节点
end = pre; // end 也重置到 pre 的位置,准备开始下一轮的"探路"
}
// 返回虚拟头节点的 next,也就是处理完后的真实头节点
return dummy.next;
}
// 辅助函数:经典的"反转整个单链表"
private ListNode reverse(ListNode head) {
ListNode pre = null; // 前一个节点,初始为 null
ListNode curr = head; // 当前节点,初始为头节点
// 遍历链表,逐个反转指针方向
while (curr != null) {
ListNode next = curr.next; // 1. 先保存当前节点的下一个节点,防止断链
curr.next = pre; // 2. 将当前节点的 next 指向前一个节点(实现反转)
pre = curr; // 3. pre 指针后移
curr = next; // 4. curr 指针后移
}
// 遍历结束后,curr 为 null,pre 指向的就是新的头节点
return pre;
}
}5. 复杂度分析
- 时间复杂度 : O(N)O(N) 。其中 N 是链表的长度。虽然我们在每一组内部调用了
reverse函数,但每个节点在整个过程中只会被访问常数次(探路一次、翻转一次、重连一次)。 - 空间复杂度 : O(1)O(1) 。我们只使用了
dummy,pre,end,start,next等几个指针变量,没有使用额外的数组或递归栈空间(辅助函数reverse也是迭代的)。