一、pthread 库的由来
Linux 内核本身并不存在真正意义上的线程概念------线程在 Linux 中是通过轻量级进程(LWP,Light Weight Process)来模拟的。Linux 内核只提供创建轻量级进程的系统调用,即 clone()。clone() 与 fork() 的核心区别在于:clone() 可以通过 flags 参数精确控制父子进程之间共享哪些资源(如地址空间、文件描述符表、信号处理表等)。当 clone() 传入 CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND 等标志时,创建出来的轻量级进程就与父进程共享了几乎一切,在行为上等价于"线程"。
然而,我们在学习操作系统时接触的是线程模型而非轻量级进程模型。为了让我们能以熟悉的线程语义进行编程,Linux 在用户层提供了 pthread 库(POSIX Threads)。pthread 库把 clone() 系统调用封装起来,对外暴露为标准的线程创建、等待、同步接口。因此,Linux 的线程实现本质上是在用户层通过库完成的,这种线程被称为用户级线程,而 pthread 库则被称为原生线程库(Native POSIX Thread Library, NPTL),意为与 Linux 强相关但位于用户层的线程库。
C++11 标准也引入了多线程支持(std::thread),其底层在 Linux 平台上通常依赖 pthread 实现,但 C++11 的线程库是一个跨平台的抽象层,并非 pthread 的简单封装------在 Windows 上它底层走的是 Win32 Thread API(不知道也没关系)。编译含有 pthread 的程序时,需要在 g++ 命令后加上 -lpthread(注意没有空格,-l 后面直接跟库名)。
这里需要指出一个常见误解:vfork() 调用并不能用来创建线程。vfork() 虽然会让子进程共享父进程的地址空间,但它会阻塞父进程直到子进程调用 exec 或 _exit,且设计初衷是为了优化 fork-then-exec 场景,与现代线程模型的语义完全不同。Linux 创建线程的唯一系统调用入口是 clone()。
二、pthread 库核心函数接口
pthread_create ------ 创建线程
c
int pthread_create(pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine)(void *),
void *arg);参数说明:
thread:输出参数,函数返回时写入新线程的 ID(该 ID 由 pthread 库管理,不是内核中的 LWP ID)。attr:线程属性对象,可指定栈大小、分离状态、调度策略等。传入NULL表示使用默认属性。start_routine:新线程的执行入口函数。其类型为void *(*)(void *),即接受一个void *参数并返回void *。arg:传给入口函数的参数。
返回值:成功返回 0;失败返回错误码(非零),且此时 thread 的内容无定义,不可使用。
pthread_join ------ 等待线程并回收
c
int pthread_join(pthread_t thread, void **retval);新线程创建后,主线程应当对其进行 join 等待,以避免类似僵尸进程那般的资源泄露问题。join 的行为是:阻塞调用线程,直到指定线程结束运行,然后回收该线程的资源。
thread:要等待的线程 ID。retval:二级指针,用于接收目标线程入口函数的返回值。如果不需要返回值,可传入NULL。
注意:用户不需要意识到 LWP 的存在,因此 pthread_t 的值并不是内核中的 LWP ID,而是 pthread 库内部管理块的地址。
pthread_self ------ 获取自身 ID
c
pthread_t pthread_self(void);返回调用此函数的线程自身的线程 ID。在线程内部需要标识自己时使用(例如从一组线程中区分出当前线程)。
pthread_exit ------ 线程主动退出
c
void pthread_exit(void *retval);用于在线程内部显式退出线程,效果等价于在入口函数中执行 return (void *)retval;。二者的细微区别在于:pthread_exit 可以在任意调用深度退出线程,而 return 只能从入口函数返回。
pthread_cancel ------ 取消指定线程
c
int pthread_cancel(pthread_t thread);向指定线程发送取消请求。需要注意几点:
- 目标线程必须存在,否则调用失败。
- 默认场景是主线程取消新线程。
- 被取消的线程的返回值被设为
PTHREAD_CANCELED(即(void *)-1)。 - 取消并不是立即生效------目标线程必须在到达某个取消点(cancellation point,如
read、write、sleep等系统调用)时才会响应取消请求。可通过pthread_setcancelstate和pthread_setcanceltype控制取消行为。
pthread_detach ------ 分离线程
c
int pthread_detach(pthread_t thread);线程的两种生命周期状态:
- joinable (可连接状态,默认):线程结束后其资源不会被自动释放,需要其他线程调用
pthread_join来回收。 - detached (分离状态):线程结束后系统自动回收其资源,不需要任何线程来
join。
调用 pthread_detach 可以将一个 joinable 的线程变为 detached。既可以由主线程分离新线程,也可以让线程内部通过 pthread_detach(pthread_self()) 自己分离自己。
注意事项:
- 分离出去的线程仍然可以访问和操作该进程中的所有共享资源,只是主线程不再等待它。
- 对已经是 detached 状态的线程调用
pthread_join会导致调用失败。 - 分离状态不可逆------一个线程一旦被分离,无法再变回 joinable。
三、线程的一些基本规则
第一,main 函数结束即代表主线程结束。主线程结束时,默认行为是调用 exit() 进而终止整个进程(包括所有其他线程)。如果希望主线程结束后其他线程继续运行,应让主线程通过 pthread_exit 退出而非直接 return。
第二,新线程的入口函数运行完毕即代表该新线程运行结束。
第三,线程内部不能使用 exit() 退出------这会导致整个进程终止,而非仅终止当前线程。线程退出应使用 pthread_exit 或从入口函数 return。
四、线程库的实现细节
errno 的线程独立性
大部分以 pthread_ 开头的函数在出错时并不会设置全局变量 errno,而是直接将错误码通过返回值返回。这与传统的 Unix 系统调用习惯不同(后者出错返回 -1,错误详情存于 errno)。
但每个线程内部仍然拥有自己独立的 errno 变量。这不是给 pthread 系列函数用的,而是为了兼容其他会用到 errno 的标准库函数(如 open、read)。在多线程环境中,如果所有线程共享同一个 errno,则线程 A 调用 open 失败后,线程 B 恰好也去读 errno,就会读到别人的错误码。Linux 通过将 errno 实现为线程局部存储(TLS,Thread-Local Storage)的宏来解决这个问题------每个线程看到的 errno 实际上是自己独立的副本。
线程 ID 的含义
线程 ID(pthread_t)是由 pthread 库提供的标识,内核并不认识这个 ID。其本质是对应线程在 pthread 库中管理块(TCB)的起始虚拟地址,在 x86-64 平台下是一个无符号长整型。
多线程共享数据的问题
以下代码演示了不加同步时多线程访问共享数据的典型错误:
c
void *fun(void *p)
{
int n = 5;
while (n--)
{
printf("%d ", *(int *)p);
sleep(1);
}
return NULL;
}
int main()
{
int *p = malloc(sizeof(int));
for (int a = 0; a < 10; a++)
{
pthread_t tid;
*p = a;
pthread_create(&tid, NULL, fun, p);
}
// 缺少 join,主线程可能先于子线程结束
return 0;
}这段代码的问题在于:for 循环中连续创建了 10 个线程,而所有线程共享同一个 p 指针指向的内存。在第一个新线程被调度运行之前,循环可能已经全部执行完毕,此时 *p 已经被最后一轮循环改写为 9。因此所有线程看到的都是 9。
不仅如此,这段代码还存在另一个隐患:main 函数直接 return 而没有 join 子线程,导致子线程可能还未执行就被进程退出强制终止。
如果要在不加锁的情况下避免数据不一致,只能在每次 pthread_create 之后让主线程 sleep 一小段时间,等待上一个线程运行完毕再创建下一个------但这当然不是真正的解决方案。正确的做法是为每个线程分配独立的参数副本,或者使用互斥锁同步访问。
五、线程的地址空间布局
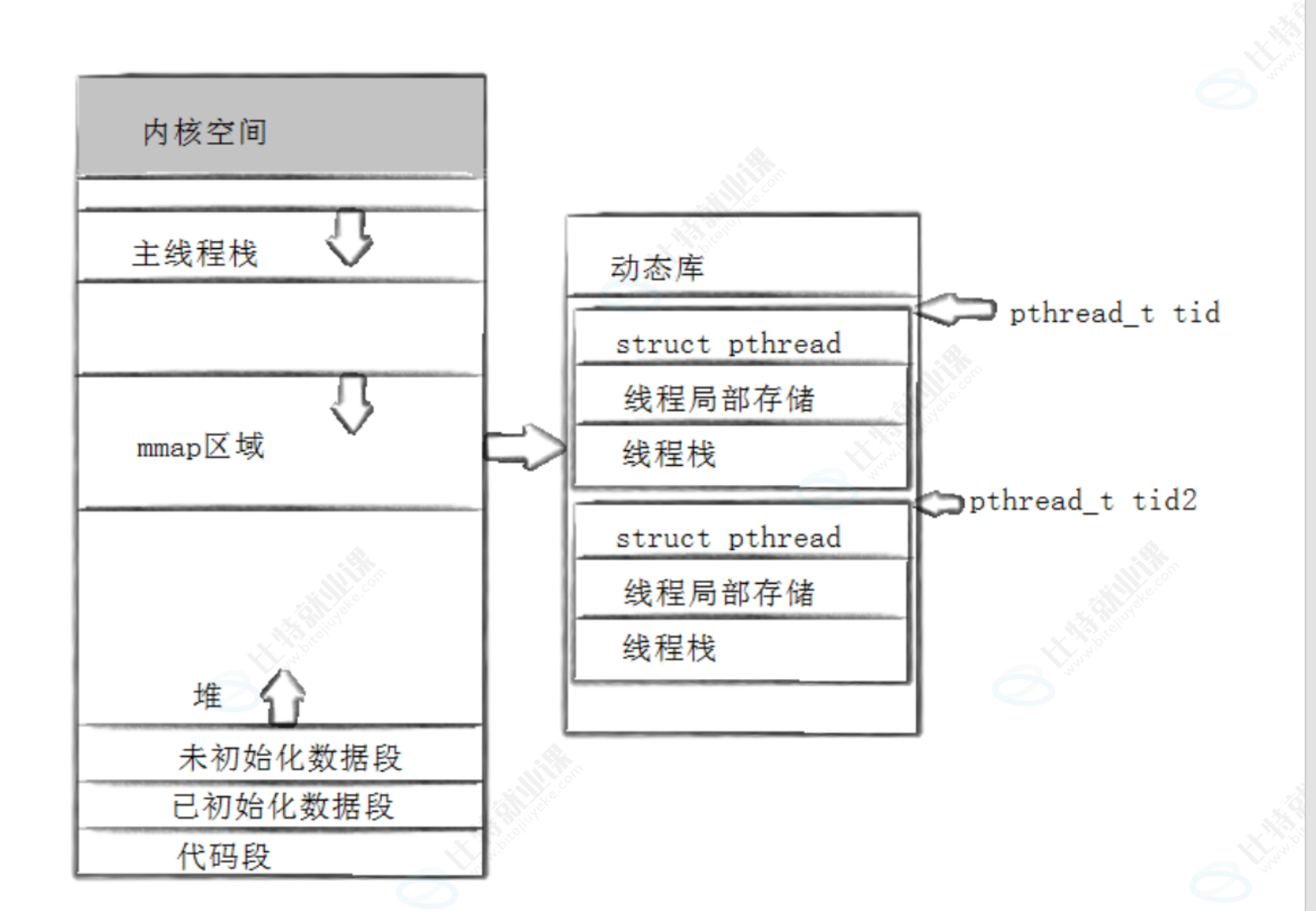
线程在 pthread 库中采用"先描述,再组织"的方式管理。pthread 库自身加载在进程虚拟地址空间的 mmap 区域中。每个线程对应一个结构体,称为 TCB(Thread Control Block),即 struct pthread。该结构体位于线程栈空间的起始处。
pthread_t 的本质就是对应线程的 TCB 在库中的起始虚拟地址------这就是为什么多线程打印 pthread_self() 的值看起来像是一堆大数字。
TCB 中包含一个成员 void *ret,用于存储线程入口函数运行完毕后的返回值。线程入口函数结束时,其 TCB 并不会在第一时间被销毁------pthread_join 回收的核心数据正是这个管理块,而 pthread_join 的二级参数 retval 就是用来接收 ret 中存储的返回值的。
换言之,主线程 join 新线程时做的事情就是:等待新线程结束,然后从新线程的 TCB 中取出返回值,最后回收 TCB 所占用的资源。
六、pthread_create 的底层实现
pthread_create 在底层做了两件事:
第一,在用户层:在 pthread 库中创建用于线程管理的 TCB,初始化其中的成员(如入口函数地址、参数、栈空间指针、joinable 状态等)。
第二,在内核层:调用 clone() 系统调用创建轻量级进程。clone() 的原型大致为:
c
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...);各参数含义:
fn:轻量级进程的执行入口函数。stack:分配给该轻量级进程的栈空间(用户态栈的顶/底地址,取决于架构)。flags:共享标志位,控制父子之间共享哪些内核数据结构。arg:传给fn的参数。
clone() 的行为是:创建新的 task_struct,以 fn 为执行入口,并将 stack 所指的栈空间分配给该轻量级进程使用。这块栈空间用于管理该轻量级进程的临时数据(局部变量、函数调用帧等)。
用户级线程与轻量级进程之间的关系可以概括为:用户级线程是"指挥者",轻量级进程是"执行者"。pthread 库中的调度逻辑(TCB 管理、同步原语)在用户层运行,而真正的 CPU 时间片由内核通过 LWP 来调度。
关于 TCB 中的其他重要成员:
joinable:标识该线程是否处于可连接状态,pthread_detach正是修改此标志。- 指向栈空间的指针:TCB 中记录了分配给该线程的栈的起始地址和大小。
- 线程局部存储(TLS)相关数据。
关于 stack 地址的传递:malloc 开辟的空间从低地址向高地址增长,但返回值指向的是这块空间的最低地址。而线程在压栈时是从高地址向低地址增长。因此传给 clone() 的 stack 参数应当是 malloc 返回的起始地址加上所分配空间的大小(即栈顶地址)。在现代 Linux 中,pthread 库通常使用 mmap 而非 malloc 来分配线程栈,以获得更好的对齐和独立性。
七、mmap 函数简介
c
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);mmap 的本质是向内核申请一块虚拟内存空间,并将这块空间映射到当前进程的地址空间中。它的用途非常灵活:
- 作为仅属于单个线程的私有栈空间(
flags中指定MAP_PRIVATE | MAP_ANONYMOUS)。 - 作为进程间通信的共享内存区域(
flags中指定MAP_SHARED | MAP_ANONYMOUS)。 - 将磁盘文件的内容直接映射到内存中进行读写(提供
fd参数,可实现零拷贝的文件 I/O)。
实现不同功能只需传入对应的 flags 和 prot 参数,其他不相关的参数设为 0 或 NULL 即可。例如:
- 分配一块匿名私有内存:
mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); - 映射文件到内存:
mmap(NULL, size, PROT_READ, MAP_PRIVATE, fd, 0);
注意:mmap 的返回值类型是 void *,不是 void。调用失败时返回 MAP_FAILED(即 (void *)-1),需要通过此常量而非 NULL 来判断失败。
八、线程的独立上下文与栈空间
每个线程都拥有自己独立的上下文,这由两部分构成:
- 内核层 :独立的 PCB(Process Control Block),即
task_struct。内核通过 PCB 来调度和管理轻量级进程。 - 用户层 :独立的 TCB(Thread Control Block),即
struct pthread。pthread 库通过 TCB 来管理线程的生命周期和属性。
每个线程拥有独立的栈空间。区别在于:
- 主线程的栈空间位于进程地址空间中的传统栈区,且是动态的------不够用时操作系统会自动扩容(受
RLIMIT_STACK限制)。 - 新线程的栈空间是通过
mmap在 mmap 区域中分配的,大小在创建时由线程属性(pthread_attr_t中的stacksize)确定,创建后不可动态扩容。默认大小通常为 8MB(可通过ulimit -s查看和调整)。
线程之间能否互相访问栈数据
由于新线程的大部分内核数据结构是从主线程浅拷贝(共享指针而非深拷贝数据)而来的,加上所有线程共享同一进程地址空间,新线程之间实际上是可以互相访问彼此的栈数据的------只是没有确定性的地址可以引用。
以下代码验证了这一事实:
c
int *p = NULL;
void *threadrun(void *args)
{
int a = 123;
p = &a; // 将局部变量的地址暴露给全局指针
while (1); // 线程在此阻塞,防止栈帧被回收
return NULL;
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, threadrun, NULL);
sleep(1); // 等待新线程将 p 指向其栈上的变量
printf("%d\n", *p); // 主线程通过全局指针读取新线程栈中的数据
return 0;
}执行结果:主线程打印出了 123。这说明主线程成功访问了新线程栈空间中的局部变量。
这个现象揭示了线程编程中的一个关键事实:线程之间的"隔离"是逻辑上的而非物理上的。所有线程共享同一进程地址空间,所谓"独立的栈"只是意味着每个线程拥有一块专属的内存区域作为运行时栈,但其他线程只要拿到了这块内存的地址,就可以直接读写。这也是多线程编程中数据竞争和野指针风险的根本来源之一------一个线程的栈变量地址一旦通过全局指针、函数参数等方式泄露给另一个线程,后者就可能在不恰当的时机访问已被销毁的栈帧,造成未定义行为。