Python 面试高频:装饰器、迭代器、生成器和上下文管理器一次讲清

开场:这些题为什么总被问?
如果面试官问 Python 基础,除了昨天讲过的对象、引用、可变默认参数、浅拷贝、GIL,后面大概率会追这几个问题:
- 装饰器本质是什么?
- 闭包为什么能记住外层变量?
functools.wraps有什么用?- 迭代器和可迭代对象有什么区别?
- 生成器为什么省内存?
yield到底暂停了什么?with语句背后发生了什么?- 上下文管理器为什么适合管理文件、连接和锁?
这些问题不是为了考你会不会背术语,而是看你有没有理解 Python 的几个核心设计:
函数可以像对象一样传递,遍历依赖统一协议,惰性计算可以保存执行现场,资源释放应该交给明确的进入和退出边界。
这句话听起来长,拆开就是今天这篇文章的四条线:
- 装饰器和闭包:函数也是对象,函数可以包函数。
- 迭代器协议:
for循环背后不是魔法,而是iter()和next()。 - 生成器:
yield让函数可以暂停、恢复、逐个产出数据。 - 上下文管理器:
with让资源进入和退出有稳定边界。
这几个点学完,再去看 FastAPI 的路由装饰器、依赖注入、流式响应和数据库连接生命周期,会顺很多。
一、装饰器:本质是"函数包一层函数"
先看最常见的写法:
python
@timer
def query_user(user_id):
return {"id": user_id}很多人第一次看到 @timer 会把它当成一种特殊语法。其实装饰器最核心的理解很简单:
装饰器就是一个接收函数、返回新函数的函数。
上面的代码基本等价于:
python
def query_user(user_id):
return {"id": user_id}
query_user = timer(query_user)也就是说,@timer 不是在函数调用时才执行。它会在函数定义完成后,把原函数传给 timer,再把返回结果重新绑定给原函数名。
写一个最小装饰器:
python
def timer(func):
def wrapper(*args, **kwargs):
print("before")
result = func(*args, **kwargs)
print("after")
return result
return wrapper
@timer
def add(a, b):
return a + b
print(add(1, 2))执行流程可以这样理解:
text
定义 add
-> 把 add 传给 timer
-> timer 返回 wrapper
-> add 这个名字重新绑定到 wrapper
-> 调用 add(1, 2) 时,实际调用 wrapper(1, 2)
-> wrapper 内部再调用原始 func(1, 2)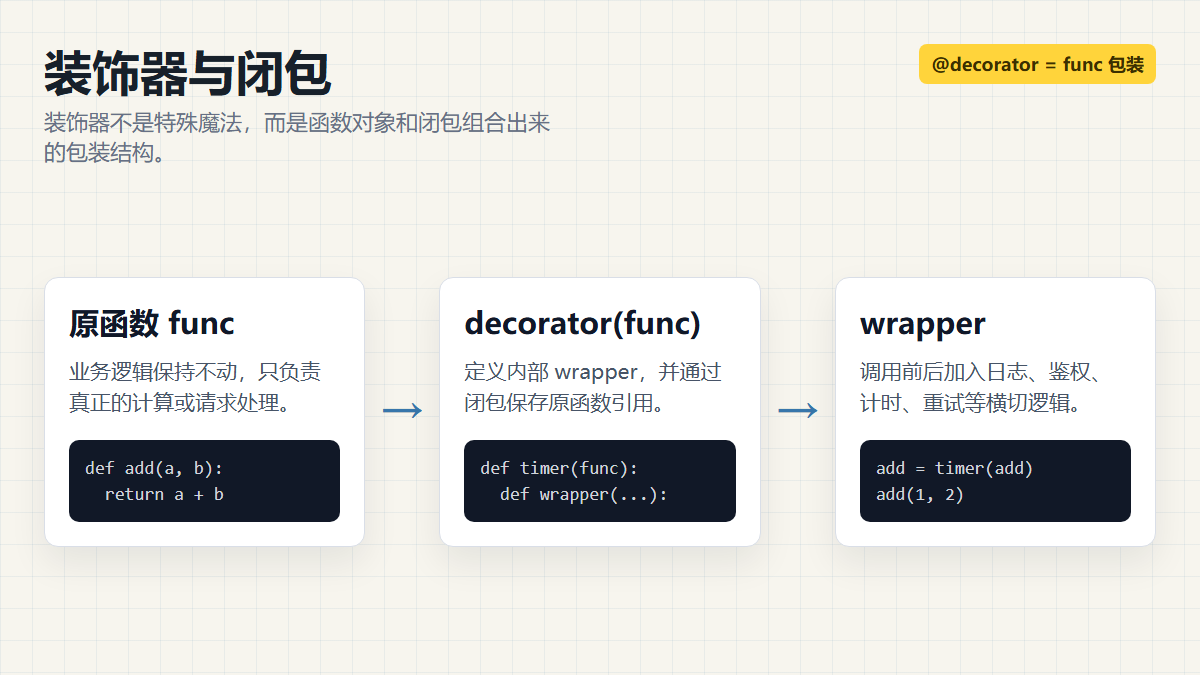
这里有两个关键点:
第一,函数在 Python 里是对象。
函数可以赋值给变量:
python
def hello():
return "hello"
f = hello
print(f())函数也可以作为参数传给另一个函数:
python
def run(fn):
return fn()
print(run(hello))函数还可以作为返回值:
python
def outer():
def inner():
return "inner"
return inner
fn = outer()
print(fn())装饰器就是把这三个能力组合起来:函数传进去,新函数返回来。
第二,wrapper(*args, **kwargs) 是为了尽量兼容原函数参数。
如果原函数有不同参数:
python
def add(a, b): ...
def get_user(user_id, verbose=False): ...
def save(**payload): ...装饰器不应该把参数写死。*args 接收位置参数,**kwargs 接收关键字参数,这样包装函数才能转发不同形状的调用。
面试回答模板
如果面试官问"装饰器本质是什么",可以这样答:
装饰器本质上是一个接收函数并返回函数的可调用对象。
@decorator只是语法糖,等价于func = decorator(func)。它通常通过内部的wrapper函数在调用原函数前后加入日志、鉴权、计时、缓存等逻辑。
二、闭包:为什么 wrapper 还能拿到原函数?
上面的 timer 里有一个容易被忽略的问题:
python
def timer(func):
def wrapper(*args, **kwargs):
result = func(*args, **kwargs)
return result
return wrappertimer 已经执行结束了,为什么 wrapper 后面还能用 func?
答案就是闭包。
闭包是指内部函数引用了外部函数作用域里的变量,并且这个内部函数被返回或传递到外部继续使用。
看一个更小的例子:
python
def make_counter():
count = 0
def inc():
nonlocal count
count += 1
return count
return inc
counter = make_counter()
print(counter()) # 1
print(counter()) # 2
print(counter()) # 3make_counter() 执行结束后,局部变量 count 并没有马上消失,因为返回的 inc 函数还引用着它。
这就是闭包的作用:
text
外部函数变量
-> 被内部函数引用
-> 内部函数返回到外部
-> 变量随内部函数一起保留下来装饰器里的 wrapper 能继续拿到 func,也是这个原因。
nonlocal 是干什么的?
如果内部函数只是读取外层变量,通常不用写 nonlocal:
python
def outer():
name = "python"
def inner():
return name
return inner但如果内部函数要重新赋值,就要写 nonlocal:
python
def make_counter():
count = 0
def inc():
nonlocal count
count += 1
return count
return inc不写 nonlocal,Python 会把 count += 1 里的 count 当成内部函数的局部变量处理,结果就会报错。
带参数的装饰器,其实多包了一层
普通装饰器:
python
@timer
def add(a, b):
return a + b等价于:
python
add = timer(add)带参数的装饰器:
python
@retry(times=3)
def request_api():
pass等价于:
python
request_api = retry(times=3)(request_api)所以带参数装饰器通常是三层函数:
python
def retry(times):
def decorator(func):
def wrapper(*args, **kwargs):
last_error = None
for _ in range(times):
try:
return func(*args, **kwargs)
except Exception as exc:
last_error = exc
raise last_error
return wrapper
return decorator三层分别负责:
| 层级 | 作用 |
|---|---|
retry(times) |
接收装饰器参数 |
decorator(func) |
接收被装饰的原函数 |
wrapper(*args, **kwargs) |
接收原函数调用参数 |
这个结构一旦看懂,很多 Python 框架里的 @xxx(...) 就不会显得神秘了。
闭包常见坑:状态会被保留下来
闭包能保留状态,这是优点,也可能是坑。
比如下面这个装饰器记录调用次数:
python
def count_calls(func):
count = 0
def wrapper(*args, **kwargs):
nonlocal count
count += 1
print(f"call count = {count}")
return func(*args, **kwargs)
return wrapper每个被装饰的函数都会有自己的 count。如果你把这个状态用于缓存、鉴权、限流,就要想清楚状态的作用域:是每个函数独立,还是全局共享,是否线程安全,是否会在长生命周期进程里越积越多。
面试回答模板
如果面试官问"闭包是什么",可以这样答:
闭包是内部函数引用了外部函数作用域中的变量,并且内部函数在外部函数结束后仍然继续存在。Python 会把被引用的外层变量随内部函数一起保存下来。装饰器里的
wrapper能记住原函数func,就是典型闭包。
三、为什么装饰器要加 functools.wraps?
上面的装饰器还能跑,但有一个问题:
python
def timer(func):
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
@timer
def add(a, b):
"""Add two numbers."""
return a + b
print(add.__name__)
print(add.__doc__)你可能会得到:
text
wrapper
None因为 add 这个名字已经被重新绑定到 wrapper 了。此时外部看到的函数元信息,不再是原来的 add,而是包装后的 wrapper。
这在普通脚本里可能没什么问题,但在框架里就可能出事:
- 日志里函数名全是
wrapper,排查困难。 - 文档工具拿不到原函数说明。
- 测试和调试信息变得不直观。
- 某些依赖函数签名或元信息的框架会受到影响。
所以正式写装饰器时,通常要加 functools.wraps:
python
from functools import wraps
def timer(func):
@wraps(func)
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapperwraps 会把原函数的一些元信息复制到 wrapper 上,比如 __name__、__doc__、__module__、__annotations__ 等。
这不是为了"好看",而是为了让包装后的函数尽量像原函数。
面试回答模板
装饰器会用
wrapper替换原函数,如果不加functools.wraps,外部看到的函数名、文档、注解等元信息可能变成wrapper。wraps的作用是把原函数的元信息复制到包装函数上,方便调试、文档生成和框架反射。
四、迭代器:for 循环背后不是魔法
接着看第二组高频题:迭代器和可迭代对象。
先看平时最常见的写法:
python
for item in [1, 2, 3]:
print(item)你可以把它理解成:
python
items = iter([1, 2, 3])
while True:
try:
item = next(items)
except StopIteration:
break
print(item)也就是说,for 循环背后主要依赖两个动作:
| 动作 | 含义 |
|---|---|
iter(obj) |
拿到一个迭代器 |
next(iterator) |
从迭代器里取下一个值 |
当没有更多数据时,迭代器会抛出 StopIteration,for 循环捕获它并结束循环。
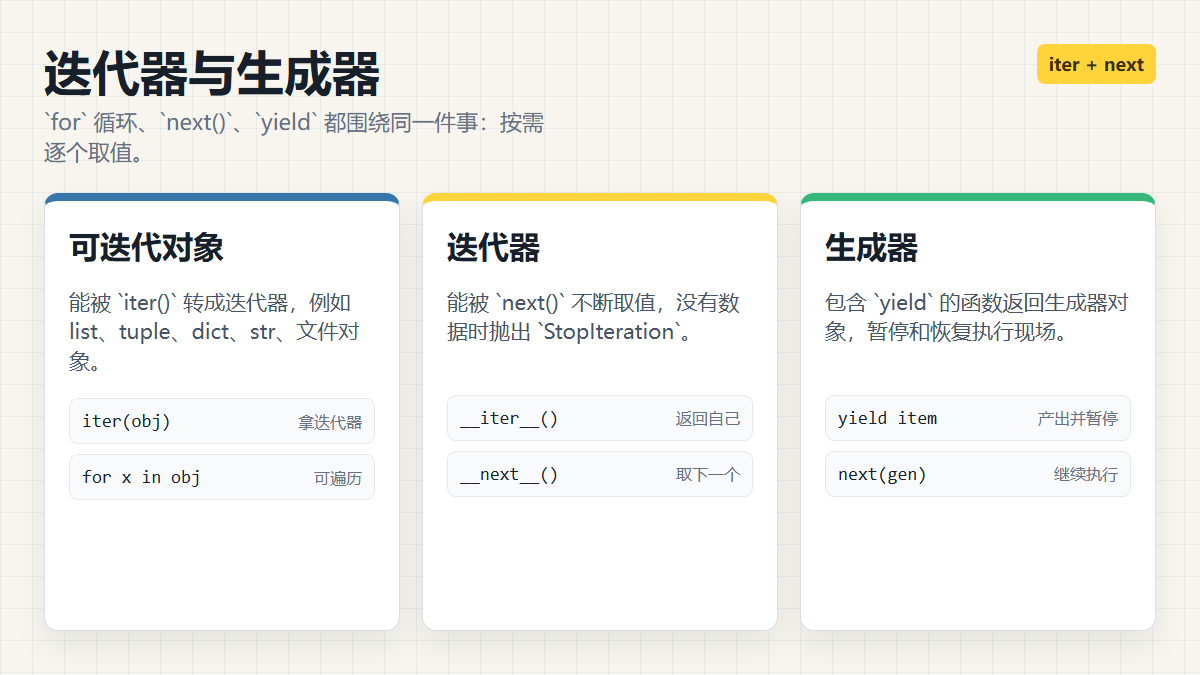
可迭代对象和迭代器有什么区别?
一句话:
可迭代对象是"能被
iter()转成迭代器的对象";迭代器是"能被next()不断取值的对象"。
常见可迭代对象:
listtupledictsetstr- 文件对象
- 生成器对象
迭代器对象要实现两个方法:
python
class CountDown:
def __init__(self, start):
self.current = start
def __iter__(self):
return self
def __next__(self):
if self.current <= 0:
raise StopIteration
value = self.current
self.current -= 1
return value
for n in CountDown(3):
print(n)输出:
text
3
2
1这里 CountDown 同时是可迭代对象,也是迭代器,因为它的 __iter__() 返回了自己。
但列表不是迭代器:
python
nums = [1, 2, 3]
it = iter(nums)
print(next(it)) # 1
print(next(it)) # 2nums 是可迭代对象,it 才是迭代器。
这个区别在面试里很容易被问:
list可以for循环,但它本身不是迭代器。它是可迭代对象,调用iter(list)后才会得到迭代器。
迭代器是有状态的
迭代器会记住自己遍历到哪里了:
python
nums = [1, 2, 3]
it = iter(nums)
print(next(it)) # 1
print(next(it)) # 2
for x in it:
print(x) # 只会输出 3这意味着迭代器通常是一次性消费的。你把一个迭代器传给两个地方一起用,很容易出现"怎么少数据了"的问题。
面试回答模板
可迭代对象是实现了可迭代协议、能被
iter()获取迭代器的对象;迭代器是实现了__next__()的对象,每次next()返回一个值,没有值时抛出StopIteration。for循环本质上就是先调用iter(),再不断调用next()。
五、生成器:yield 让函数暂停和恢复
生成器是 Python 面试里非常高频的点。
先看普通函数:
python
def build_list():
result = []
for i in range(3):
result.append(i)
return result
print(build_list()) # [0, 1, 2]普通函数一调用,就会一路执行到 return,然后结束。
再看生成器函数:
python
def gen_numbers():
for i in range(3):
yield i
g = gen_numbers()
print(next(g)) # 0
print(next(g)) # 1
print(next(g)) # 2只要函数体里出现 yield,调用这个函数时不会立刻执行函数体,而是返回一个生成器对象。
真正执行发生在你调用 next(g) 的时候。
执行到 yield i 时,函数会:
- 产出当前值
i。 - 暂停在这一行。
- 保存当前局部变量和执行位置。
- 等下一次
next()再从暂停处继续。
这就是生成器和普通函数最大的区别:
text
普通函数:一次执行到 return
生成器函数:多次 next,多次暂停和恢复生成器为什么省内存?
假设你要处理 1000 万行数据。
列表写法:
python
def load_all_rows(path):
rows = []
with open(path, "r", encoding="utf-8") as f:
for line in f:
rows.append(line.strip())
return rows这个函数会把所有数据都放进内存。
生成器写法:
python
def read_rows(path):
with open(path, "r", encoding="utf-8") as f:
for line in f:
yield line.strip()这个函数每次只产出一行。调用方需要一行,就取一行。
python
for row in read_rows("data.txt"):
handle(row)所以生成器省内存的原因不是它"压缩了数据",而是:
它不一次性构造完整结果,而是按需逐个产出。
生成器也是迭代器
生成器对象可以直接用于 for 循环:
python
def gen():
yield 1
yield 2
for x in gen():
print(x)因为生成器对象本身就是迭代器。它有 __iter__(),也有 __next__()。
生成器常见坑:只能消费一次
python
g = (x * 2 for x in range(3))
print(list(g)) # [0, 2, 4]
print(list(g)) # []第二次为什么是空?
因为第一次 list(g) 已经把生成器消费完了。生成器记住自己的执行位置,走到终点后就结束了。
如果你需要重复遍历,就要重新创建生成器:
python
def make_gen():
return (x * 2 for x in range(3))
print(list(make_gen()))
print(list(make_gen()))yield 和 return 有什么关系?
生成器函数里可以写 return,但它不是像普通函数那样返回最终列表。
python
def gen():
yield 1
return
yield 2return 会结束生成器。外部继续 next() 时会触发 StopIteration。
日常面试里不需要把生成器协议讲得特别深,但要能说清楚:
yield产出值并暂停。- 下一次
next()从暂停位置继续。 - 生成器按需产出,所以适合大数据流、文件读取、分页拉取、流式响应。
- 生成器是一次性消费的。
面试回答模板
生成器函数是包含
yield的函数,调用它不会立即执行函数体,而是返回生成器对象。每次next()会执行到下一个yield,产出值后暂停,并保存当前执行状态。生成器按需产出数据,不需要一次性把所有结果放进内存,所以适合处理大文件、数据流和惰性计算。
六、上下文管理器:with 解决的是资源退出边界
最后看 with。
最常见写法:
python
with open("data.txt", "r", encoding="utf-8") as f:
content = f.read()它解决的问题很朴素:
无论代码正常结束,还是中途抛异常,都要把文件关掉。
不用 with,你可能会写:
python
f = open("data.txt", "r", encoding="utf-8")
try:
content = f.read()
finally:
f.close()with 就是把这种 try/finally 资源管理模式变成了协议。

with 背后的两个方法
一个对象只要实现了上下文管理协议,就可以放进 with:
python
class ManagedResource:
def __enter__(self):
print("enter")
return self
def __exit__(self, exc_type, exc, traceback):
print("exit")
return False
with ManagedResource() as resource:
print("use resource")执行顺序:
text
调用 __enter__()
-> 把返回值绑定给 as 后面的变量
-> 执行 with 代码块
-> 调用 __exit__()即使代码块中抛异常,__exit__() 也会被调用。
__exit__() 的三个参数用于接收异常信息:
| 参数 | 含义 |
|---|---|
exc_type |
异常类型 |
exc |
异常对象 |
traceback |
异常调用栈 |
如果 __exit__() 返回 True,表示异常被处理,不再向外抛;返回 False 或 None,异常会继续向外传播。
日常写资源管理时,大多数情况下应该让异常继续抛出去,不要随便吞异常。
用 contextlib.contextmanager 简化写法
如果不想专门写一个类,可以用 contextlib.contextmanager:
python
from contextlib import contextmanager
@contextmanager
def managed_resource():
print("enter")
try:
yield "resource"
finally:
print("exit")
with managed_resource() as resource:
print(resource)这个写法里:
yield前面的代码相当于__enter__()。yield产出的值会绑定给as resource。finally里的代码相当于__exit__(),负责释放资源。
这也解释了为什么今天把生成器和上下文管理器放在一起讲:contextmanager 装饰器就是用生成器来写上下文管理器。
上下文管理器适合哪些场景?
常见场景:
- 文件打开和关闭。
- 数据库连接获取和释放。
- 事务提交和回滚。
- 锁的获取和释放。
- 临时切换配置,再恢复旧配置。
- 测试里临时 mock 某个资源。
它的价值不是少写几行代码,而是把资源生命周期写成明确边界:
text
进入 with:拿资源
代码块中:使用资源
离开 with:释放资源这比依赖对象析构、垃圾回收或"记得手动 close"稳定得多。
面试回答模板
上下文管理器用于管理资源的进入和退出。
with语句会先调用对象的__enter__(),代码块结束后调用__exit__(),即使中间抛异常也会执行退出逻辑。它适合管理文件、连接、锁和事务,本质上是把try/finally资源释放模式协议化。
七、把这几个点串起来
今天这几个知识点看起来分散,其实可以串成一条线:
| 知识点 | 一句话理解 | 常见用途 |
|---|---|---|
| 装饰器 | 函数包一层函数 | 日志、鉴权、缓存、重试、路由注册 |
| 闭包 | 内部函数记住外层变量 | 装饰器参数、状态保存、函数工厂 |
wraps |
保留原函数元信息 | 调试、文档、框架反射 |
| 迭代器 | 按协议逐个取值 | for 循环、自定义遍历 |
| 生成器 | 暂停和恢复的惰性迭代器 | 大文件、数据流、分页、流式返回 |
| 上下文管理器 | 明确资源进入和退出 | 文件、连接、事务、锁 |
后面学 FastAPI 时,这些点会反复出现:
@app.get(...)是装饰器。- 自定义鉴权、日志、限流,也常用装饰器或中间件。
- 依赖函数、路由函数的签名和元信息很重要,所以装饰器不能乱丢函数信息。
- 流式响应常常和生成器、异步生成器有关。
- 数据库 Session、事务、文件资源,都绕不开上下文管理。
所以今天这篇不是为了堆语法,而是先把 Python 框架背后的语言机制补齐。
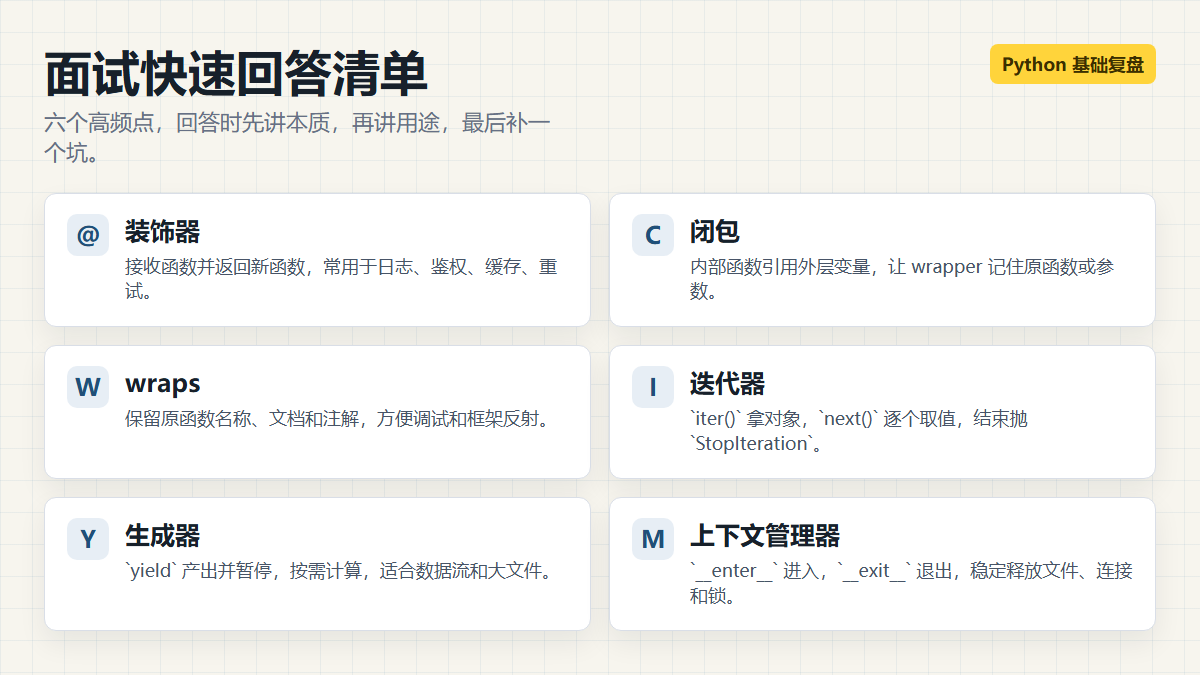
八、面试快速复盘
最后给一份可直接复述的回答清单。
1. 装饰器是什么?
装饰器是接收函数并返回新函数的可调用对象,@decorator 等价于 func = decorator(func)。它常用于在不修改原函数代码的情况下增加日志、计时、鉴权、缓存、重试等逻辑。
2. 闭包是什么?
闭包是内部函数引用外部函数作用域里的变量,并且内部函数在外部函数结束后仍然存在。Python 会把这些被引用的变量和内部函数一起保存下来。
3. 为什么装饰器要用 functools.wraps?
因为装饰器会用 wrapper 替换原函数。如果不加 wraps,函数名、文档、注解等元信息可能丢失,影响日志、调试、文档生成和框架反射。
4. 可迭代对象和迭代器有什么区别?
可迭代对象能被 iter() 获取迭代器;迭代器能被 next() 不断取值,没有数据时抛出 StopIteration。for 循环本质上就是 iter() 加 next()。
5. 生成器为什么省内存?
生成器不会一次性构造完整结果,而是每次执行到 yield 时产出一个值并暂停。下一次 next() 再从暂停位置继续,所以适合大文件、数据流和惰性计算。
6. with 语句背后是什么?
with 背后是上下文管理协议。进入代码块前调用 __enter__(),离开代码块时调用 __exit__(),即使中间抛异常也会执行退出逻辑,适合管理文件、连接、事务和锁。
总结
Python 基础面试里,装饰器、迭代器、生成器和上下文管理器不是孤立语法点。
它们共同指向一件事:
Python 很多"简洁写法"的背后,都是对象、协议和执行状态管理。
装饰器靠函数对象和闭包扩展行为;迭代器靠协议统一遍历;生成器靠暂停和恢复做惰性计算;上下文管理器靠进入和退出边界管理资源。
把这些机制搞懂,再去看 FastAPI、Django、SQLAlchemy、pytest 这些框架时,很多"框架魔法"都会变成可以解释的普通 Python 机制。
参考资料
- Python 官方文档:Data model - Objects, values and types:https://docs.python.org/3/reference/datamodel.html
- Python 官方文档:Compound statements - Function definitions and decorators:https://docs.python.org/3/reference/compound_stmts.html#function-definitions
- Python 官方文档:Iterator types:https://docs.python.org/3/library/stdtypes.html#iterator-types
- Python 官方文档:Yield expressions:https://docs.python.org/3/reference/expressions.html#yield-expressions
- Python 官方文档:With statement:https://docs.python.org/3/reference/compound_stmts.html#the-with-statement
- Python 官方文档:contextlib:https://docs.python.org/3/library/contextlib.html
- Python 官方文档:functools.wraps:https://docs.python.org/3/library/functools.html#functools.wraps