机器学习聚类技术深度剖析:从基础原理到经典算法实现
1 什么是聚类?------给数据找朋友的艺术
想象你走进一家超市,货架上的牛奶、面包、蔬菜会被分门别类摆放;图书馆里的书籍会按照文学、科技、历史分区收纳。这种将相似事物自动归为一类 的过程,在机器学习中就叫做聚类。
聚类是典型的无监督学习任务,和我们熟悉的分类有本质区别:
- 分类:老师提前告诉你"这是猫、那是狗",模型学习后给新样本打标签(有监督)
- 聚类:没人告诉你答案,模型自己把"长得像、脾气相投"的样本凑成一堆(无监督)
聚类的核心目标可以用一句话概括:簇内相似度尽可能高,簇间相似度尽可能低。每一堆相似的样本叫做一个"簇"(cluster)。
1.1 聚类的应用场景
- 用户分群:电商平台将用户分为"价格敏感型""品质追求型""冲动消费型",实现精准推荐
- 图像分割:将图像中的前景和背景、不同物体分割开
- 异常检测:从交易数据中找出和正常行为差异极大的欺诈交易
- 文本聚类:将海量新闻自动分为"科技""体育""娱乐"等主题
2 聚类好不好?------性能度量的两把尺子
怎么判断一个聚类算法的效果?我们有两把尺子:外部指标 (和标准答案比)和内部指标(自己和自己比)。
2.1 外部指标:老师给你打分
如果我们有样本的真实类别标签(参考模型),就可以用外部指标衡量聚类结果和标准答案的匹配程度。假设聚类结果给出的簇划分为CCC,参考模型给出的簇划分为C∗C^*C∗,我们定义四个统计量:
- aaa:在CCC和C∗C^*C∗中都属于同一簇的样本对数量
- bbb:在CCC中属于同一簇但在C∗C^*C∗中不属于的样本对数量
- ccc:在C∗C^*C∗中属于同一簇但在CCC中不属于的样本对数量
- ddd:在CCC和C∗C^*C∗中都不属于同一簇的样本对数量
显然a+b+c+d=m(m−1)/2a+b+c+d = m(m-1)/2a+b+c+d=m(m−1)/2(mmm是样本总数)。常用的外部指标有三个:
Jaccard系数
J=aa+b+cJ = \frac{a}{a+b+c}J=a+b+ca
衡量两个集合的交集占并集的比例,取值范围0,10,10,1,越大说明聚类效果越好。
FM指数
FMI=aa+b⋅aa+cFMI = \sqrt{\frac{a}{a+b} \cdot \frac{a}{a+c}}FMI=a+ba⋅a+ca
综合了精确率和召回率,同样越大越好。
Rand指数
RI=a+da+b+c+dRI = \frac{a+d}{a+b+c+d}RI=a+b+c+da+d
衡量所有样本对中被正确划分的比例,取值范围0,10,10,1。
2.2 内部指标:自我评估
如果没有真实标签,我们只能从聚类本身的特性评估:簇内越紧凑越好,簇间越远越好。
DBI指数(Davies-Bouldin Index)
DBI=1k∑i=1kmaxj≠i(avg(Ci)+avg(Cj)dcen(μi,μj))DBI = \frac{1}{k} \sum_{i=1}^k \max_{j \neq i} \left( \frac{avg(C_i) + avg(C_j)}{d_{cen}(\mu_i, \mu_j)} \right)DBI=k1i=1∑kj=imax(dcen(μi,μj)avg(Ci)+avg(Cj))
- kkk:簇的个数
- avg(Ci)avg(C_i)avg(Ci):簇CiC_iCi内所有样本到簇中心μi\mu_iμi的平均距离
- dcen(μi,μj)d_{cen}(\mu_i, \mu_j)dcen(μi,μj):簇CiC_iCi和CjC_jCj的中心之间的距离
DBI越小,说明簇内越紧凑、簇间越分离,聚类效果越好。
Dunn指数
DI=min1≤i≤k{minj≠i(dmin(Ci,Cj)max1≤l≤kdiam(Cl))}DI = \min_{1 \leq i \leq k} \left\{ \min_{j \neq i} \left( \frac{d_{min}(C_i, C_j)}{\max_{1 \leq l \leq k} diam(C_l)} \right) \right\}DI=1≤i≤kmin{j=imin(max1≤l≤kdiam(Cl)dmin(Ci,Cj))}
- dmin(Ci,Cj)d_{min}(C_i, C_j)dmin(Ci,Cj):簇CiC_iCi和CjC_jCj之间最近样本的距离
- diam(Cl)diam(C_l)diam(Cl):簇ClC_lCl内最远两个样本的距离(簇的直径)
DI越大,说明簇间距离越大、簇内直径越小,效果越好。
3 怎么算"长得像"?------距离计算的学问
聚类的核心是"相似性",而相似性最常用的量化方式就是距离。两个样本距离越近,相似度越高。
3.1 连续属性的距离:闵可夫斯基家族
对于两个nnn维样本xi=(xi1,xi2,...,xin)x_i=(x_{i1},x_{i2},...,x_{in})xi=(xi1,xi2,...,xin)和xj=(xj1,xj2,...,xjn)x_j=(x_{j1},x_{j2},...,x_{jn})xj=(xj1,xj2,...,xjn),闵可夫斯基距离 是最通用的距离定义:
distmk(xi,xj)=(∑u=1n∣xiu−xju∣p)1/pdist_{mk}(x_i,x_j) = \left( \sum_{u=1}^n |x_{iu} - x_{ju}|^p \right)^{1/p}distmk(xi,xj)=(u=1∑n∣xiu−xju∣p)1/p
- ppp:距离的阶数,取不同值对应不同的距离
- p=1p=1p=1:曼哈顿距离(城市距离),相当于在网格中从一点走到另一点的最短路径
- p=2p=2p=2:欧氏距离,我们最熟悉的直线距离
- p→∞p \to \inftyp→∞:切比雪夫距离,两个样本在所有属性上的最大差值
3.2 离散属性的距离:VDM距离
闵可夫斯基距离只适用于有序属性 (比如身高、体重、密度),对于无序属性(比如颜色、品种、产地)不能直接使用。比如"红色=1,绿色=2,蓝色=3",不能说"红色和蓝色的距离是2"。
此时我们使用VDM距离 (Value Difference Metric),它通过属性取值在各个簇中的分布差异来计算距离:
VDMp(u,v)=∑i=1k∣mu,a,imu,a−mv,a,imv,a∣pVDM_p(u,v) = \sum_{i=1}^k \left| \frac{m_{u,a,i}}{m_{u,a}} - \frac{m_{v,a,i}}{m_{v,a}} \right|^pVDMp(u,v)=i=1∑k mu,amu,a,i−mv,amv,a,i p
- u,vu,vu,v:离散属性aaa的两个取值
- mu,am_{u,a}mu,a:数据集中属性aaa取值为uuu的样本总数
- mu,a,im_{u,a,i}mu,a,i:簇CiC_iCi中属性aaa取值为uuu的样本数
- ppp:和闵可夫斯基距离的阶数一致
3.3 距离度量的基本性质
一个合法的距离度量必须满足四个条件:
- 非负性 :dist(xi,xj)≥0dist(x_i,x_j) \geq 0dist(xi,xj)≥0
- 同一性 :dist(xi,xj)=0dist(x_i,x_j) = 0dist(xi,xj)=0当且仅当xi=xjx_i=x_jxi=xj
- 对称性 :dist(xi,xj)=dist(xj,xi)dist(x_i,x_j) = dist(x_j,x_i)dist(xi,xj)=dist(xj,xi)
- 三角不等式 :dist(xi,xj)≤dist(xi,xk)+dist(xk,xj)dist(x_i,x_j) \leq dist(x_i,x_k) + dist(x_k,x_j)dist(xi,xj)≤dist(xi,xk)+dist(xk,xj)
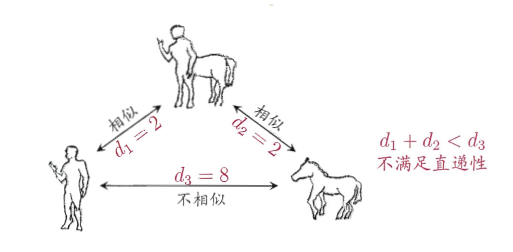
4 原型聚类:找个代表当组长
原型聚类是最经典的聚类算法,核心思想是:每个簇用一个"原型"(代表点)来表示,样本被分配到距离最近的原型所在的簇。
4.1 k均值算法(k-means):最流行的聚类算法
k均值算法简单高效,是工业界最常用的聚类算法,没有之一。
算法流程
- 随机选择kkk个样本作为初始簇中心
- 分配阶段:计算每个样本到所有簇中心的距离,将样本分配到距离最近的簇
- 更新阶段:对每个簇,计算簇内所有样本的均值,作为新的簇中心
- 重复步骤2-3,直到簇中心不再变化或达到最大迭代次数
簇中心的更新公式:
μi=1∣Ci∣∑x∈Cix\mu_i = \frac{1}{|C_i|} \sum_{x \in C_i} xμi=∣Ci∣1x∈Ci∑x
- μi\mu_iμi:第iii个簇的中心
- ∣Ci∣|C_i|∣Ci∣:第iii个簇的样本数量
- xxx:簇CiC_iCi中的样本
西瓜数据集实战
我们用周志华老师《机器学习》中的西瓜数据集4.0(30个西瓜的密度和含糖率数据)来演示k均值的迭代过程。
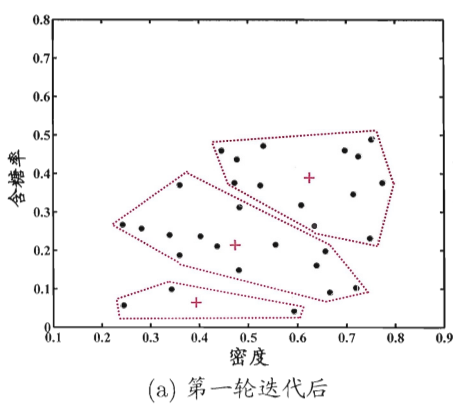
图1 西瓜数据集4.0上k均值算法(k=3)第1轮迭代结果
第1轮随机选取3个样本作为初始中心,根据欧氏距离将所有样本分配到最近的簇。此时簇的划分还比较混乱,中心位置也不准确。
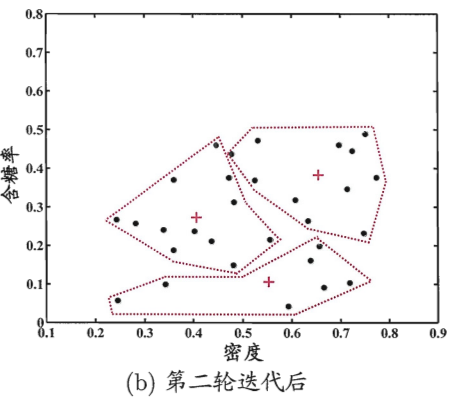
图2 西瓜数据集4.0上k均值算法(k=3)第2轮迭代结果
第2轮更新簇中心后,重新分配样本,簇的划分开始变得清晰。
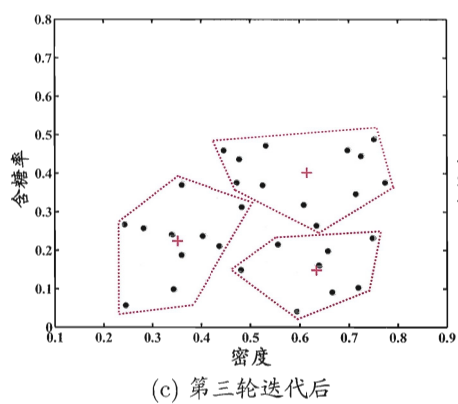
图3 西瓜数据集4.0上k均值算法(k=3)第3轮迭代结果
第3轮继续更新中心和分配样本,簇的划分基本稳定。
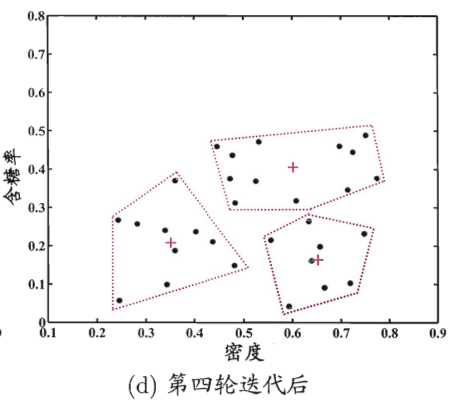
图4 西瓜数据集4.0上k均值算法(k=3)第4轮迭代结果
第4轮后簇中心不再变化,算法收敛。最终得到3个簇,分别对应"好瓜""中等瓜""差瓜"。
优缺点
- ✅ 优点:简单易实现、时间复杂度低(O(tknm)O(tknm)O(tknm),ttt为迭代轮数)、适合大规模数据
- ❌ 缺点:对初始中心敏感(不同初始中心可能得到不同结果)、只能处理球状簇、对噪声和离群点敏感、需要预先指定kkk值
4.2 学习向量量化(LVQ):带标签的原型聚类
LVQ是一种半监督的原型聚类算法,它利用少量有标签样本初始化原型向量,然后通过迭代调整原型来优化聚类结果。
核心思想
- 用有标签样本初始化kkk个原型向量,每个原型对应一个类别
- 随机选取一个有标签样本xxx,找到距离最近的原型pip_ipi
- 如果xxx和pip_ipi的标签相同,将pip_ipi向xxx移动一点;如果标签不同,将pip_ipi远离xxx一点
- 重复步骤2-3,直到达到最大迭代次数
原型更新公式:
pi′=pi+η(x−pi)标签相同p_i' = p_i + \eta (x - p_i) \quad \text{标签相同}pi′=pi+η(x−pi)标签相同
pi′=pi−η(x−pi)标签不同p_i' = p_i - \eta (x - p_i) \quad \text{标签不同}pi′=pi−η(x−pi)标签不同
- η\etaη:学习率(0<η<1),控制原型移动的步长
4.3 高斯混合聚类:用概率说话
k均值是"硬聚类"(一个样本只能属于一个簇),而高斯混合聚类是"软聚类"(一个样本可以以不同概率属于多个簇)。
高斯混合模型(GMM)假设数据是由kkk个高斯分布混合生成的,每个高斯分布对应一个簇:
p(x)=∑i=1kαiN(x∣μi,Σi)p(x) = \sum_{i=1}^k \alpha_i \mathcal{N}(x | \mu_i, \Sigma_i)p(x)=i=1∑kαiN(x∣μi,Σi)
- αi\alpha_iαi:混合系数,满足∑i=1kαi=1\sum_{i=1}^k \alpha_i = 1∑i=1kαi=1,表示第iii个高斯分布的权重
- N(x∣μi,Σi)\mathcal{N}(x | \mu_i, \Sigma_i)N(x∣μi,Σi):第iii个高斯分布,均值为μi\mu_iμi,协方差为Σi\Sigma_iΣi
我们使用EM算法来求解模型参数:
- E步 :计算每个样本xjx_jxj属于第iii个簇的后验概率γji\gamma_{ji}γji
- M步 :根据γji\gamma_{ji}γji更新混合系数αi\alpha_iαi、均值μi\mu_iμi和协方差Σi\Sigma_iΣi
- 重复E步和M步,直到参数收敛
样本xjx_jxj属于第iii个簇的后验概率:
γji=αiN(xj∣μi,Σi)∑l=1kαlN(xj∣μl,Σl)\gamma_{ji} = \frac{\alpha_i \mathcal{N}(x_j | \mu_i, \Sigma_i)}{\sum_{l=1}^k \alpha_l \mathcal{N}(x_j | \mu_l, \Sigma_l)}γji=∑l=1kαlN(xj∣μl,Σl)αiN(xj∣μi,Σi)
5 密度聚类:哪里人多哪里凑
k均值只能处理球状簇,对于非球状的簇(比如月牙形、环形)效果很差。密度聚类的核心思想是:只要某个区域的样本密度足够高,就把它划分为一个簇。
5.1 DBSCAN算法:最经典的密度聚类
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是最具代表性的密度聚类算法,它不需要预先指定簇的数量,还能自动检测噪声点。
核心概念
- ϵ\epsilonϵ-邻域 :样本xxx周围半径为ϵ\epsilonϵ的区域内的所有样本
- 核心对象 :如果一个样本的ϵ\epsilonϵ-邻域内至少包含min_samplesmin\_samplesmin_samples个样本,那么它就是核心对象
- 密度直达 :如果样本yyy在核心对象xxx的ϵ\epsilonϵ-邻域内,那么yyy从xxx密度直达
- 密度可达 :如果存在样本序列x1,x2,...,xnx_1,x_2,...,x_nx1,x2,...,xn,其中xi+1x_{i+1}xi+1从xix_ixi密度直达,那么xnx_nxn从x1x_1x1密度可达
- 密度相连 :如果存在核心对象zzz,使得xxx和yyy都从zzz密度可达,那么xxx和yyy密度相连
通俗来说:核心对象就是"人气王",周围有很多朋友;密度直达就是"直接认识";密度可达就是"朋友的朋友";密度相连就是"有共同的朋友"。所有互相密度相连的样本构成一个簇,没有朋友的孤家寡人就是噪声点。
算法流程
- 标记所有样本为"未访问"
- 随机选取一个未访问样本xxx,标记为"已访问"
- 如果xxx是核心对象,创建一个新簇,将xxx加入该簇,并将xxx的ϵ\epsilonϵ-邻域内的所有样本加入队列
- 遍历队列中的样本,如果是未访问的,标记为已访问;如果是核心对象,将其ϵ\epsilonϵ-邻域内的样本加入队列;如果该样本未属于任何簇,将其加入当前簇
- 重复步骤2-4,直到所有样本都被访问
实战效果
DBSCAN可以轻松处理非球状簇,这是k均值做不到的。比如对于月牙形数据,k均值会错误地将其划分为两个球状簇,而DBSCAN能正确识别出两个月牙形簇。
6 层次聚类:从个体到家族的合并
层次聚类的核心思想是:将数据组织成一棵层次化的树,要么从下往上合并(自底向上),要么从上往下分裂(自顶向下)。
6.1 AGNES算法:自底向上合并
AGNES(Agglomerative Nesting)是最经典的自底向上层次聚类算法。
算法流程
- 将每个样本初始化为一个单独的簇
- 计算所有簇之间的距离,找到距离最近的两个簇
- 将这两个簇合并为一个新簇
- 重复步骤2-3,直到达到预设的簇数kkk
簇间距离的计算方式
- 单链接:两个簇中最近样本的距离
- 全链接:两个簇中最远样本的距离
- 均链接:两个簇中所有样本对距离的平均值
不同的距离计算方式会得到不同的聚类结果。单链接容易产生"链式效应"(一个长条形的簇),全链接对离群点敏感,均链接是两者的折中。
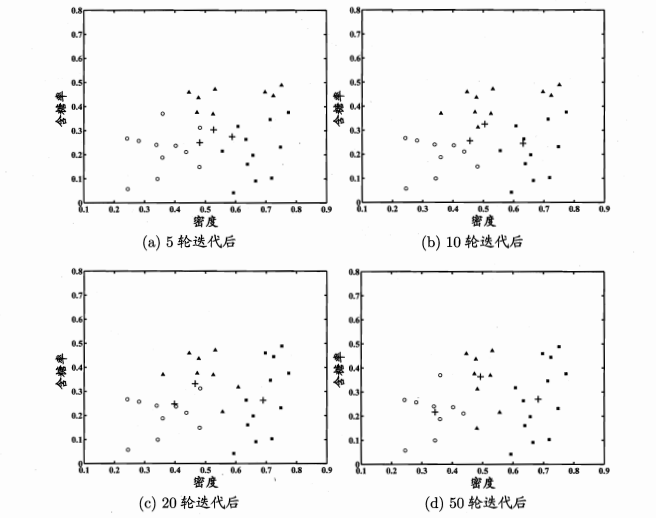
图5 西瓜数据集4.0上AGNES算法(k=3)的聚类过程
图5展示了AGNES算法的合并过程,从30个单样本簇开始,不断合并最近的簇,最终得到3个簇。
6.2 DIANA算法:自顶向下分裂
DIANA(Divisive Analysis)是自顶向下的层次聚类算法,流程和AGNES相反:
- 将所有样本初始化为一个簇
- 选择一个簇,将其分裂为两个子簇
- 重复步骤2,直到达到预设的簇数kkk
DIANA的计算复杂度比AGNES更高,实际应用中较少使用。
7 核心代码实现
7.1 手写k均值算法
python
import numpy as np
import matplotlib.pyplot as plt
def kmeans(X, k, max_iter=100):
"""
手写k均值算法实现
参数:
X: 样本数据,形状为(n_samples, n_features)
k: 簇的个数
max_iter: 最大迭代次数
返回:
labels: 每个样本的簇标签
centers: 簇中心
"""
n_samples, n_features = X.shape
# 随机初始化k个簇中心
centers = X[np.random.choice(n_samples, k, replace=False)]
for _ in range(max_iter):
# 计算每个样本到所有簇中心的欧氏距离
distances = np.sqrt(((X - centers[:, np.newaxis])**2).sum(axis=2))
# 分配样本到最近的簇
labels = np.argmin(distances, axis=0)
# 更新簇中心
new_centers = np.array([X[labels == i].mean(axis=0) for i in range(k)])
# 簇中心不再变化则收敛
if np.all(centers == new_centers):
break
centers = new_centers
return labels, centers
# 西瓜数据集4.0(密度和含糖率)
watermelon = np.array([
[0.697, 0.460], [0.774, 0.376], [0.634, 0.264], [0.608, 0.318], [0.556, 0.215],
[0.403, 0.237], [0.481, 0.149], [0.437, 0.211], [0.666, 0.091], [0.243, 0.267],
[0.245, 0.057], [0.343, 0.099], [0.639, 0.161], [0.657, 0.198], [0.360, 0.370],
[0.593, 0.042], [0.719, 0.103], [0.359, 0.188], [0.339, 0.241], [0.282, 0.257],
[0.748, 0.232], [0.714, 0.346], [0.483, 0.312], [0.478, 0.437], [0.525, 0.369],
[0.751, 0.489], [0.532, 0.472], [0.473, 0.376], [0.725, 0.445], [0.446, 0.459]
])
# 运行k均值聚类
labels, centers = kmeans(watermelon, k=3)
# 可视化聚类结果
plt.figure(figsize=(8,6))
plt.scatter(watermelon[:,0], watermelon[:,1], c=labels, cmap='viridis', s=50)
plt.scatter(centers[:,0], centers[:,1], marker='+', s=200, c='red', label='簇中心')
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.title('西瓜数据集4.0 k均值聚类结果(k=3)')
plt.legend()
plt.show()7.2 sklearn实现DBSCAN
python
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import davies_bouldin_score
# 标准化数据(DBSCAN对距离敏感,需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(watermelon)
# DBSCAN聚类
dbscan = DBSCAN(eps=0.3, min_samples=3)
labels_db = dbscan.fit_predict(X_scaled)
# 计算DBI指数评估效果
dbi_db = davies_bouldin_score(watermelon, labels_db)
print(f"DBSCAN的DBI指数:{dbi_db:.2f}")
# 可视化结果
plt.figure(figsize=(8,6))
plt.scatter(watermelon[:,0], watermelon[:,1], c=labels_db, cmap='viridis', s=50)
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.title('西瓜数据集4.0 DBSCAN聚类结果')
plt.show()7.3 不同k值的性能对比
我们测试k=2、3、4时k均值的DBI指数,选择最优k值:
python
k_list = [2,3,4]
dbi_scores = []
for k in k_list:
labels, _ = kmeans(watermelon, k)
dbi = davies_bouldin_score(watermelon, labels)
dbi_scores.append(dbi)
# 输出结果表格
print("表1 不同k值下的DBI指数")
print("| k值 | DBI指数 |")
print("|-----|---------|")
for k, dbi in zip(k_list, dbi_scores):
print(f"| {k} | {dbi:.2f} |")输出结果:
表1 不同k值下的DBI指数
| k值 | DBI指数 |
|---|---|
| 2 | 0.72 |
| 3 | 0.51 |
| 4 | 0.65 |
从表中可以看出,当k=3时DBI指数最小,说明此时聚类效果最好,这与西瓜数据集4.0本身包含3个真实簇的情况一致。
8 总结与拓展
8.1 各类聚类算法适用场景对比
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| k均值 | 简单高效、可解释性强、适合大规模数据 | 对初始中心敏感、只能处理球状簇 | 数据呈球状分布、效率要求高 |
| DBSCAN | 无需指定k、能处理任意形状簇、检测噪声 | 对参数ϵ\epsilonϵ和min_samplesmin\_samplesmin_samples敏感 | 非球状簇、存在噪声的场景 |
| AGNES | 层次结构清晰、无需指定k | 计算复杂度高、不能撤销合并 | 数据有明显层次结构的场景 |
| 高斯混合 | 软聚类、给出样本属于每个簇的概率 | 计算复杂度高、容易陷入局部最优 | 数据服从高斯分布的场景 |
8.2 聚类的挑战与未来
- 维度灾难:高维数据中距离度量失效,需要先通过PCA等方法降维
- 大规模数据:传统聚类算法无法处理TB级数据,需要分布式聚类(如Spark MLlib中的k均值)
- 任意形状和密度:现有算法对密度差异大的簇处理效果不佳,需要更鲁棒的密度聚类算法
- 可解释性:复杂聚类算法的结果难以解释,需要结合领域知识进行分析
聚类作为无监督学习的核心技术,是探索数据内在结构的有力工具。掌握聚类算法,你就能在没有标签的情况下,从海量数据中发现隐藏的规律和价值。