概率论基础:贝叶斯思维与不确定性
本文适合谁:对概率感到陌生的读者,或者觉得"概率跟AI有什么关系"的读者。读完后你将明白:为什么LLM每次输出不一样、Temperature参数是什么意思、LLM为什么会产生幻觉。这些问题的答案都在本文里。
一、为什么AI需要概率论
传统编程是确定性的:给定同样的输入,永远得到同样的输出。但AI面对的世界根本不是确定性的。
想想看,同一张图片,人类有时候会认错;同一道问题,不同的人会给出不同的回答;同一个病人的化验结果,医生也可能有不同判断。现实世界充满了噪声、歧义和不完整信息。
早期的专家系统试图用确定性规则来描述这个世界------穷举所有可能的情况,写出对应的规则。结果规则复杂度爆炸,这条路走不通。
概率论提供了一个根本不同的思路:不去寻找"确定的答案",而是去估计"每种可能的答案有多大可能性"。
AI领域对概率论的依赖体现在三个层次:
第一层:表示不确定性。模型的输出不是一个确定值,而是一个概率分布。"这张图片80%是猫,15%是狗,5%是其他"------比直接说"这是猫"包含更多信息,也更诚实地反映了模型的置信度。
第二层:从数据中学习。学习的本质是:根据观测到的数据,更新对"什么输入对应什么输出"的概率估计。贝叶斯定理正是这种"根据新证据更新信念"的数学框架。
第三层:生成文本。这是最关键的。LLM生成文字的过程,本质上就是在做概率采样:给定前面所有词,计算下一个词的概率分布,然后从这个分布中采样一个词。这个过程反复执行,逐词生成文本。没有概率论,LLM根本无法运作。
二、生活中无处不在的概率
概率不是数学家发明的抽象概念,它本来就存在于每个人的日常思维中。
天气预报说"明天下雨的概率是70%",这是概率。医生说"这种手术的成功率是95%",这是概率。你买彩票,知道中大奖的概率极低,所以不会把全部积蓄都押进去------你在用概率做决策。
概率论的贡献是:把这种直觉精确化,变成可以计算的数学工具。
概率的核心规则很简单:一个事件的概率是0到1之间的数字,所有可能结果的概率之和等于1。
python
# 抛硬币
# P(正面) = 0.5,P(反面) = 0.5
# P(正面) + P(反面) = 1.0 ← 所有可能结果之和必须为1
# 天气预报
# P(晴天) = 0.3,P(多云) = 0.5,P(下雨) = 0.2
# 0.3 + 0.5 + 0.2 = 1.0 ✓
# LLM预测下一个词
probs = {
"很好": 0.35,
"不错": 0.28,
"晴朗": 0.20,
"糟糕": 0.10,
"其他所有词": 0.07
}
print(sum(probs.values())) # 1.0 ← 所有词的概率之和等于1为什么"所有概率之和为1"很重要?
这个约束强迫模型"诚实"地分配置信度。对一种可能更确信,就意味着对其他可能的确信度要相应降低。这确保了模型在表达不确定性时是自洽的。
三、LLM输出的概率本质
LLM是一个巨大的条件概率机器
在深入学习概率论细节之前,先把最重要的结论说清楚:LLM生成文本的全过程,就是在反复做一件事------计算下一个词的概率分布,然后采样。
没有更复杂的机制。整个LLM的运作,从数学角度看,就是一个极其复杂的概率预测器。
python
# 概念示意:LLM每次生成一个词的过程
# 输入:"今天天气"
# 模型计算下一个词的概率分布:
probs_next_word = {
"很好": 0.35, # 最可能的词
"不错": 0.28,
"晴朗": 0.20,
"糟糕": 0.10,
"其他...": 0.07
}
# 从这个分布中采样,选择下一个词
# 采样结果:"很好"(因为概率最高)
# 然后把"很好"加入上下文,继续预测下一个词这解释了LLM的很多行为:
- 为什么每次输出不完全一样:随机采样,每次从概率分布中抽取,结果可能不同
- 为什么temperature=0时输出固定:选概率最高的词,不再随机
- 为什么temperature高时输出更"创意":增加低概率词的被选机会,让输出更多样化
四、Temperature:控制随机性的旋钮
为什么要调整随机性
LLM生成"今天天气"后面的词时,如果总是选最高概率的词,输出会很稳定,但缺乏创意,而且有时会陷入重复。如果允许低概率的词也有机会被选中,输出会更多样、更有创意,但随机性太强可能变得混乱。
Temperature参数在"确定性"和"创意"之间找平衡。
Temperature的工作原理:在把原始分数转成概率之前,先对原始分数进行缩放。Temperature越小,高分和低分的差距被放大,高概率词更突出;Temperature越大,差距被压缩,各词的概率趋于均匀。
Temperature(温度参数):控制模型输出随机程度的旋钮,值越低输出越固定,值越高输出越多样。
python
import numpy as np
def softmax(x):
# softmax:把一组任意数字转换成概率分布(所有值加起来等于1)
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
def apply_temperature(logits, temperature):
# logits是模型原始输出(未经归一化的原始分数)
# temperature调整概率分布的"尖锐程度"
scaled_logits = logits / temperature
return softmax(scaled_logits)
# 模拟模型对4个候选词的原始打分
logits = np.array([3.0, 1.5, 0.5, -1.0]) # 分数越高,词越可能
print("Temperature=0.1(低温):")
print(apply_temperature(logits, 0.1)) # 概率高度集中在第一个词
# 约 [0.99, 0.01, 0.00, 0.00]
print("\nTemperature=1.0(正常):")
print(apply_temperature(logits, 1.0)) # 正常分布
# 约 [0.71, 0.21, 0.06, 0.01]
print("\nTemperature=2.0(高温):")
print(apply_temperature(logits, 2.0)) # 概率更加均匀
# 约 [0.51, 0.28, 0.15, 0.06]运行这段代码,你会清楚地看到:
- Temperature=0.1时,概率几乎全部集中在第一个词(确定性输出)
- Temperature=1.0时,概率正常分布,偶尔会选到其他词
- Temperature=2.0时,概率更均匀,低概率词也有较大机会被选中
这就是为什么:
- 写代码/做事实查询用低temperature(需要确定性)
- 写创意文章/头脑风暴用高temperature(需要多样性)
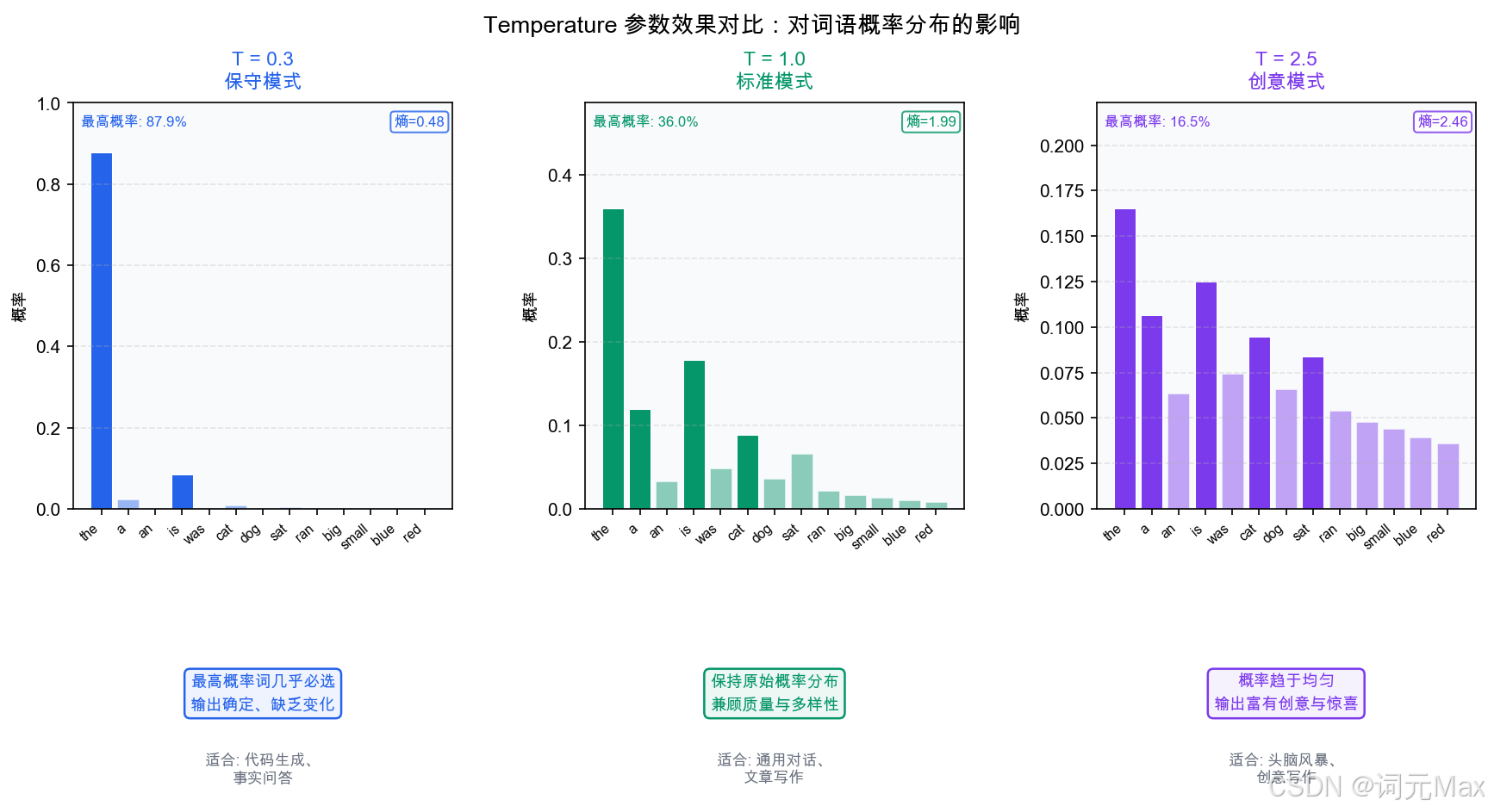
Temperature参数对词汇概率分布的影响
五、条件概率:上下文改变概率
信息改变概率
有一道经典思考题:你知道一个家庭有两个孩子,其中至少一个是男孩,那么两个都是男孩的概率是多少?
不加任何条件,两个都是男孩的概率是1/4。但"至少一个是男孩"这个信息改变了答案------排除了"两个都是女孩"的情况,剩下三种等可能的情况(男男、男女、女男),其中只有一种是两个都是男孩,所以概率是1/3。
这就是条件概率 的本质:新信息到来后,原有概率要相应更新。
P(B|A) = 在A发生的条件下,B发生的概率LLM的每次生成都是条件概率
LLM生成文本就是条件概率:
P(下一个词 | 之前所有词的上下文)举个例子:
- P("苹果" | "我喜欢吃") 比较高------"我喜欢吃苹果"很自然
- P("苹果" | "我刚用") 也较高------"我刚用苹果手机"
- P("苹果" | "爱因斯坦发现了") 很低------上下文暗示这里说的是科学发现
LLM正是通过学习大量文本,掌握了"在各种上下文下,下一个词的条件概率分布"。
这就是为什么:
- 上下文越清晰,模型输出越准确:提供的条件越精确,概率分布越集中
- Prompt工程本质上是在优化条件概率:好的Prompt让模型理解你想要哪种条件下的输出
六、贝叶斯定理:根据证据更新信念
医学检测的反直觉例子
假设有一种疾病,人群中患病率是1%(100个人里有1个患者)。现在有一种检测方法:患病时,检测阳性的概率是99%;没患病时,检测阳性(假阳性)的概率是5%。
你做了检测,结果是阳性。那么你实际患病的概率是多少?
很多人的第一直觉是:检测准确率99%,患病概率应该很高,可能是95%甚至更高。
但实际计算结果出乎意料:患病概率只有约16.7%。
为什么?因为患病率本来就很低(只有1%),即使检测有99%的准确率,在大量没有患病的人里,仍然会有不少假阳性------而这些假阳性的数量,比真阳性还多。
用数字来验证:假设1000个人接受检测
- 其中10人患病(1%),检测阳性的有 10 × 99% ≈ 10人(真阳性)
- 其中990人没患病,检测阳性的有 990 × 5% ≈ 50人(假阳性)
- 检测阳性的共约60人,其中真正患病的只有10人
- 所以阳性中患病的概率是 10/60 ≈ 16.7%
这个例子揭示了贝叶斯思维的核心:在评估任何证据时,都必须考虑事件本身的基础概率(先验概率)。忽略先验概率,就会得出错误的结论。
贝叶斯定理的公式
P(A|B) = P(B|A) × P(A) / P(B)用医学检测的语言来解读:
- P(A) = 患病的先验概率(没做检测前的基础概率)= 1%
- P(B|A) = 患病时检测阳性的概率 = 99%
- P(B) = 检测阳性的总体概率(真阳性+假阳性)
- P(A|B) = 检测阳性后患病的概率(我们想知道的)
贝叶斯定理的直觉:根据新证据(B)更新原有信念(P(A))。
就像你认为今天下雨概率是30%(先验),后来看到乌云(新证据),你把概率更新到80%------这就是贝叶斯思维。
python
import numpy as np
def bayes_update(prior, likelihood, false_positive_rate, population=1000):
"""
prior: 先验概率(患病率)
likelihood: 真阳性率(患病时检测阳性的概率)
false_positive_rate: 假阳性率(未患病时检测阳性的概率)
"""
n_sick = int(population * prior) # 患病人数
n_healthy = population - n_sick # 健康人数
true_positives = n_sick * likelihood # 真阳性数量
false_positives = n_healthy * false_positive_rate # 假阳性数量
total_positives = true_positives + false_positives
posterior = true_positives / total_positives # 后验概率
print(f"患病人数: {n_sick}")
print(f"健康人数: {n_healthy}")
print(f"真阳性: {true_positives:.0f}")
print(f"假阳性: {false_positives:.0f}")
print(f"阳性中实际患病的概率: {posterior:.1%}")
return posterior
# 1%患病率,99%真阳性率,5%假阳性率
bayes_update(prior=0.01, likelihood=0.99, false_positive_rate=0.05)
# 输出:阳性中实际患病的概率: 16.7%(出乎意料!)运行这段代码,你会看到即使检测准确率很高,实际患病概率仍然很低,因为患病率本来就很低。
贝叶斯定理在AI中的应用:
- 垃圾邮件过滤:根据邮件里出现了哪些词,更新"这是垃圾邮件"的概率
- RLHF中的奖励模型:根据人类对模型输出的评分,更新对"什么样的回答更好"的判断
- RAG检索:根据文档内容更新回答特定问题的概率
七、为什么LLM会产生幻觉
LLM为什么会编造不存在的事实("幻觉"问题)?
因为LLM本质上是概率机器,它的目标是生成**"看起来合理"的文字序列**,而不是**"在事实上正确"的文字序列**。一个词是否会被选中,取决于它在给定上下文下出现的概率有多高------概率高,反映的是"这个词在训练数据的类似语境中出现的频率高",不代表它在现实中是真实的。
理解了这一点,你就理解了:
- 为什么要对LLM的输出保持批判性思维
- 为什么RAG能减少幻觉------它通过把真实文档加入上下文,改变了条件概率分布,让模型生成时更倾向于与文档事实一致的输出
八、常用概率分布速查
AI里最常见的几种概率分布:
| 分布 | 直觉 | 在AI中的用途 |
|---|---|---|
| 正态分布 | 钟形曲线,大部分值集中在中间 | 神经网络权重初始化 |
| 均匀分布 | 所有值等可能 | 随机采样 |
| 伯努利分布 | 只有是/否两种结果 | 二分类输出 |
| 多项式分布 | 多个类别各有概率 | 词汇表采样(LLM的每次生成) |
为什么神经网络权重用正态分布初始化?
如果所有权重初始化为0,所有神经元计算出相同的结果,模型永远无法学到多样化的特征。用正态分布随机初始化,每个权重有不同的起点,打破了这种对称性,让不同神经元可以学习不同的特征。
为什么LLM输出用多项式分布采样?
LLM的词汇表通常有几万到十几万个词,每次生成一个词就是从这个巨大的多项式分布中采样------给每个词一个概率,然后按概率随机选取。这就是LLM生成文本的数学机制。
九、熵:不确定性的度量
信息熵(Entropy)衡量一个概率分布有多不确定------值越大说明越不确定,值越小说明越确定。
直觉:如果硬币两面完全对称,每次抛掷你完全无法预测结果,熵最高。如果硬币两面一样,每次都能预测结果,熵为0。
python
def entropy(probs):
probs = np.array(probs)
return -np.sum(probs * np.log2(probs + 1e-8))
# 完全确定(只有一种可能)
print(entropy([1.0, 0.0, 0.0])) # ≈ 0,完全确定
# 完全不确定(均匀分布)
print(entropy([0.33, 0.33, 0.34])) # ≈ 1.58,不确定性最高
# LLM在不同情况下的输出不确定性
# 问"2+2=?":概率集中在"4",熵很低
# 问"今天吃什么?":很多答案都可能,熵很高交叉熵损失(Cross-Entropy Loss)就是基于熵的概念,衡量预测分布和真实分布的差距------预测越准,交叉熵越小。
在LLM训练中,"预测下一个词"本质上是一个分类任务:词汇表里每个词是一个类别。训练时使用交叉熵损失,就是在告诉模型:让你预测到真实下一个词的概率尽可能高。
小结
| 概念 | AI中的意义 | 实际影响 |
|---|---|---|
| 概率分布 | LLM输出是词汇表上的概率分布 | 每次生成可能不同 |
| Temperature | 控制采样的随机程度 | 低温确定性高,高温创意多 |
| 条件概率 | LLM根据上下文预测下一个词 | Prompt写法影响输出质量 |
| 贝叶斯定理 | 根据新证据更新对事件的概率估计 | 垃圾邮件过滤、RLHF等 |
| 交叉熵损失 | 衡量预测分布与真实分布的差距 | 分类任务训练的损失函数 |
| 熵 | 衡量概率分布的不确定性程度 | 信息量的数学度量 |
理解了概率论,你就理解了LLM的"随机性"从哪里来,以及如何通过Temperature来控制它。
更重要的是,你理解了AI和传统编程的根本区别:传统程序处理确定性规则,AI处理不确定性分布。概率论是理解这个区别的数学语言。
下一章将进入机器学习基础,看概率论和线性代数如何共同支撑经典的ML算法。