
背景
使用 opencode + superpowers 完成一个功能需求,记录完整的真实使用过程。
模型配置
| Agent 角色 | 模型 | 用途 |
|---|---|---|
| 主 Agent | GPT5.4 | 任务调度与协调 |
| Implementer Agent | Claude-sonnet-4.6 | 代码实现 |
| Spec-Reviewer Agent | Claude-opus-4.6 | 规格验收 |
| Code-Quality-Reviewer Agent | Claude-opus-4.6 | 代码质量审查 |
开发模式:TDD(测试驱动开发)。主 agent 完成 task 拆解后,进入以下四个阶段。
阶段一:头脑风暴
耗时:18min
模型:Claude-opus-4.6
尝试了多个模型,opus 在头脑风暴环节的体验最为出色。该阶段需要较强的发散思维和深度分析能力,opus 的表现明显优于其他模型。
阶段二:Spec & Plan 制作
耗时:13min
模型:Claude-opus-4.6
Opencode + Superpowers 提供两种执行方式:
- Subagent-Driven(推荐) --- 每个 Task 分配一个独立 subagent 执行,subagent 之间互相 review,适合复杂多模块任务
- Inline Execution --- 在当前 session 中逐步执行,适合简单任务
此处我更换了主 agent 模型:从
Claude-opus-4.6切换为GPT5.4。原因是 GPT5.4 比 opus 4.6 便宜约三分之一。Spec 和 Plan 阶段需要 opus 保证质量,后续执行阶段则使用 GPT5.4 以获得更优的性价比。
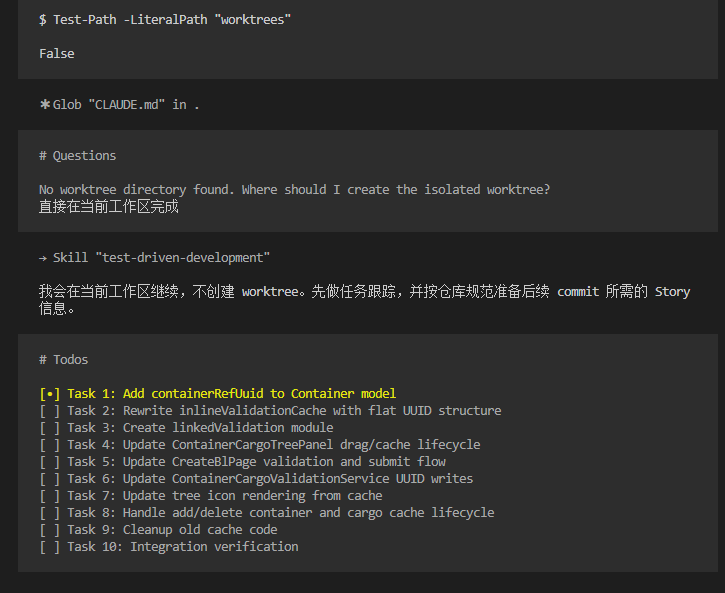
阶段三:Subagent-Driven 自动化执行
总耗时:3h10min
模型分配:
- 主 Agent:
GPT5.4 - Implementer Agent:
Claude-sonnet-4.6 - Spec-Reviewer Agent:
Claude-opus-4.6 - Code-Quality-Reviewer Agent:
Claude-opus-4.6
每开启一个 task,系统自动执行三级流水线:
1. Implementer Agent
实现 subagent 首先启动,负责代码编写。
Implementer Task - Implement Task 6
27 toolcalls · 11m 44s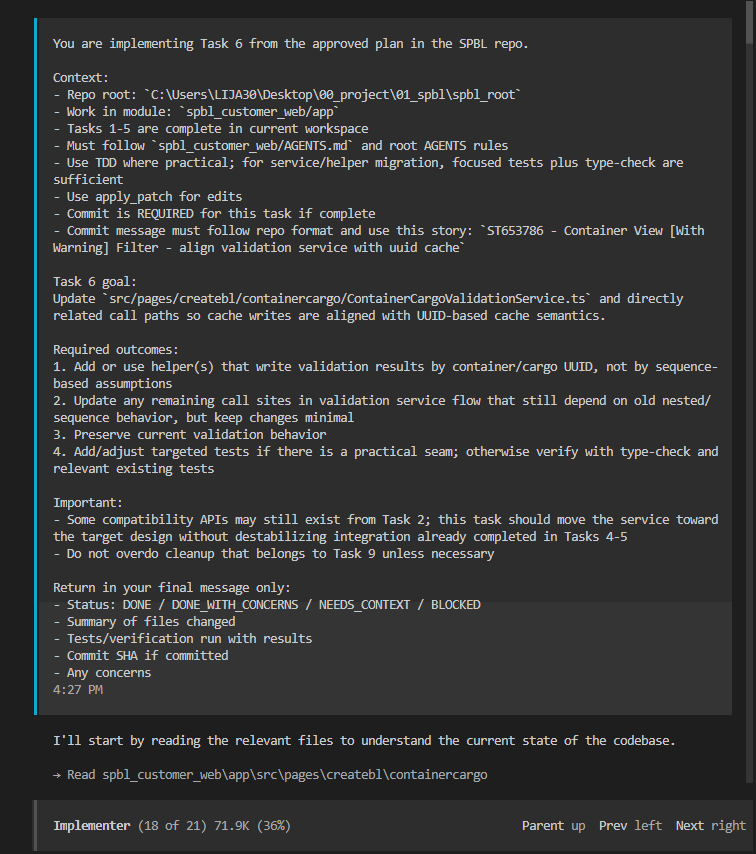
实现完成后,结果返回给主 agent。
2. Spec-Reviewer Agent
主 agent 启动规格验收 subagent,检查实现是否符合 spec 要求。
Spec-Reviewer Task - Review Task 6 spec compliance
2 toolcalls · 58.9s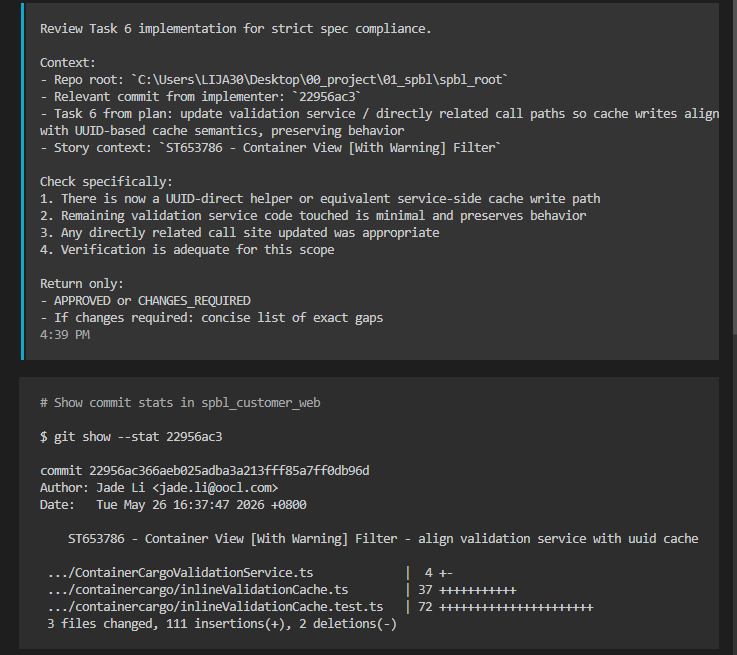
审查通过后返回主 agent。
3. Code-Quality-Reviewer Agent
主 agent 启动代码质量检查 subagent,审查代码质量。
Code-Quality-Reviewer Task - Review Task 6 code quality
3 toolcalls · 1m 17s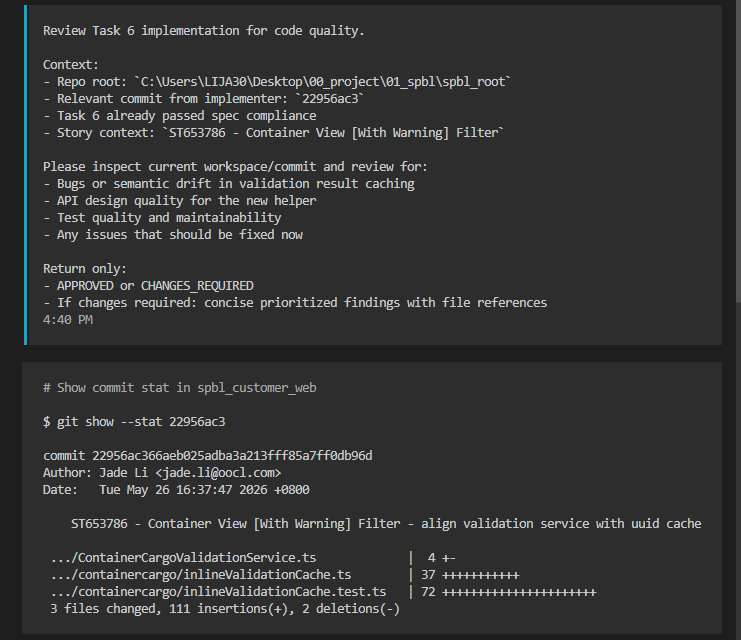
所有 subagent 和主 agent 完成全部任务后,流程结束。
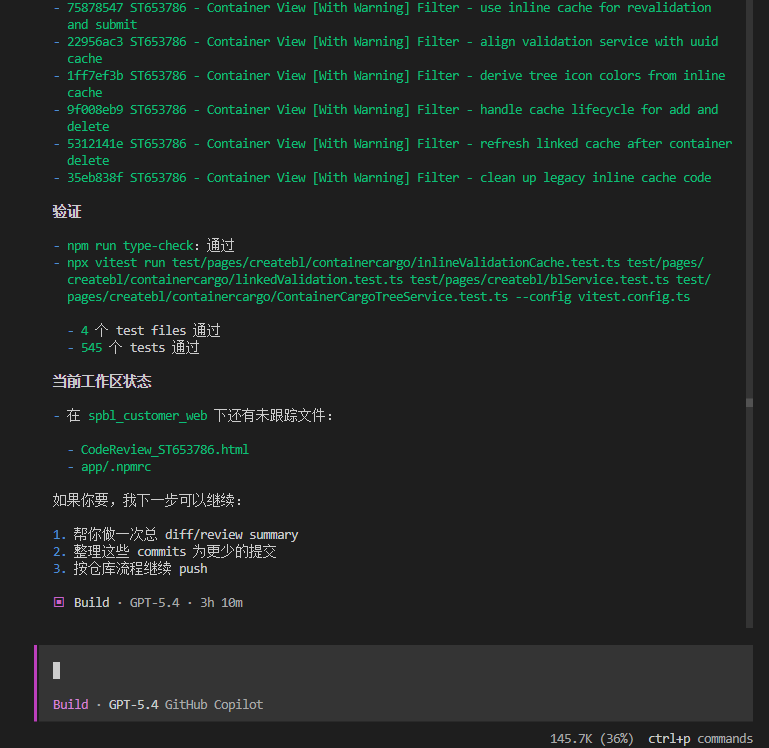
阶段四:总 Diff / Review Summary
耗时:7min
按 10 个 commit 合并分析,忽略测试文件,生成一份完整的代码变动报告(Markdown 格式 + HTML 版)。
总结与经验
整体耗时:约 3 小时 48 分钟
| 阶段 | 耗时 | 使用模型 |
|---|---|---|
| 头脑风暴 | 18min | Claude-opus-4.6 |
| Spec & Plan | 13min | Claude-opus-4.6 |
| 自动化执行 | 3h10min | 混合模型 |
| Review Summary | 7min | - |
经验总结:
- opus 适合高认知负载任务:头脑风暴、spec 审查、代码质量审查等需要深度分析的环节,opus 表现最佳
- GPT5.4 性价比高:执行调度类任务用 GPT5.4 完全够用,成本较 opus 低约三分之一
- Subagent-Driven 模式值得推荐:配置完成后全自动化执行,无需人工盯守
- 多模型协作是趋势:不同模型各司其职,在不同环节发挥各自优势,整体效率明显高于单模型方案