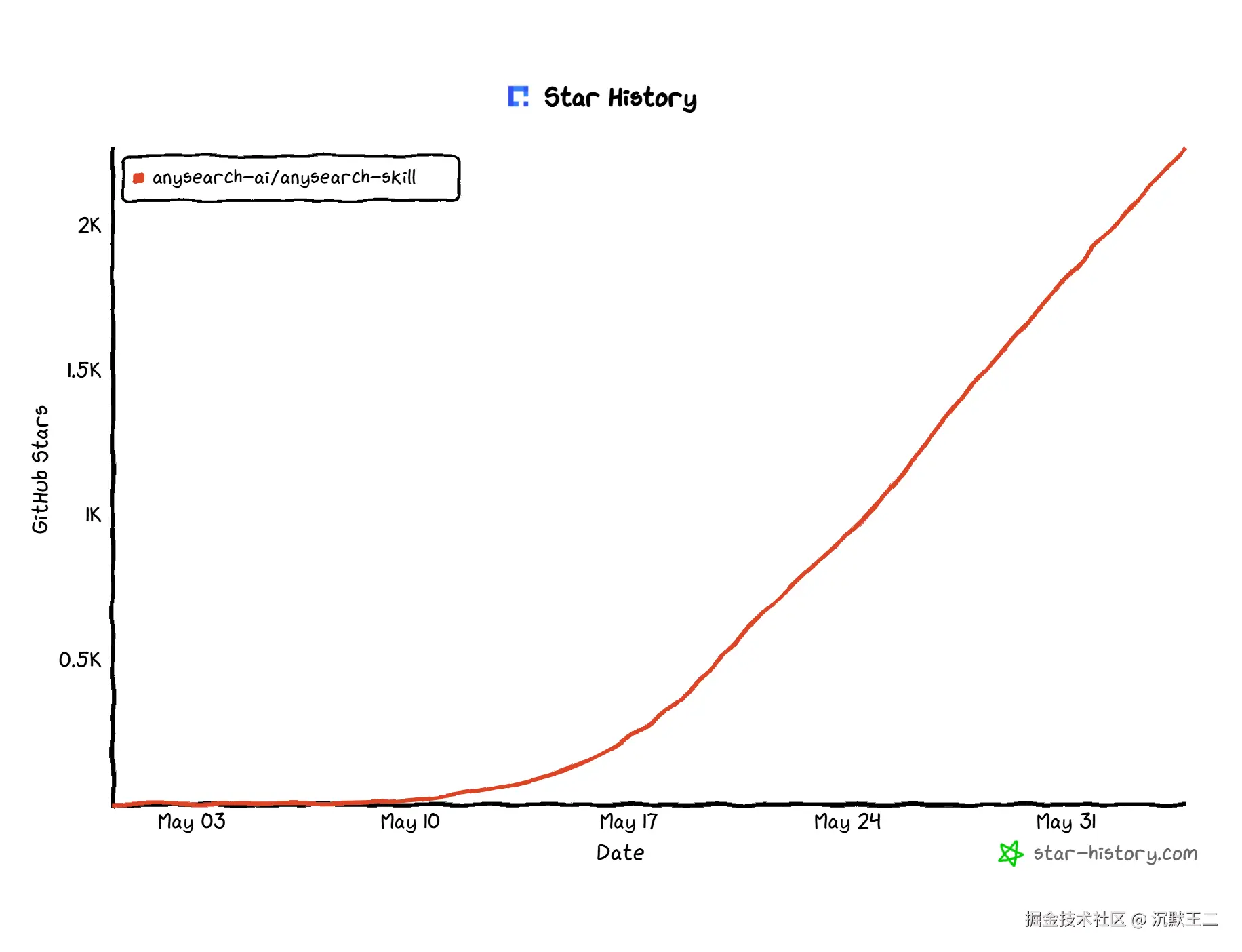
上个月,一个叫 AnySearch 的项目上线仅一周就冲上了 Skills.sh 热榜 TOP1,截至目前为止,它在 GitHub 上的 Star 数量已经来到了2.3K了。
就冲这个上升势头,我昨天把这个 Skill 给装上了,深度体验了一把,并详细研究了一下它的设计思路。
这篇内容就来跟大家聊聊 AnySearch 到底做了什么、怎么用、实测效果怎么样。
01、AnySearch 是什么
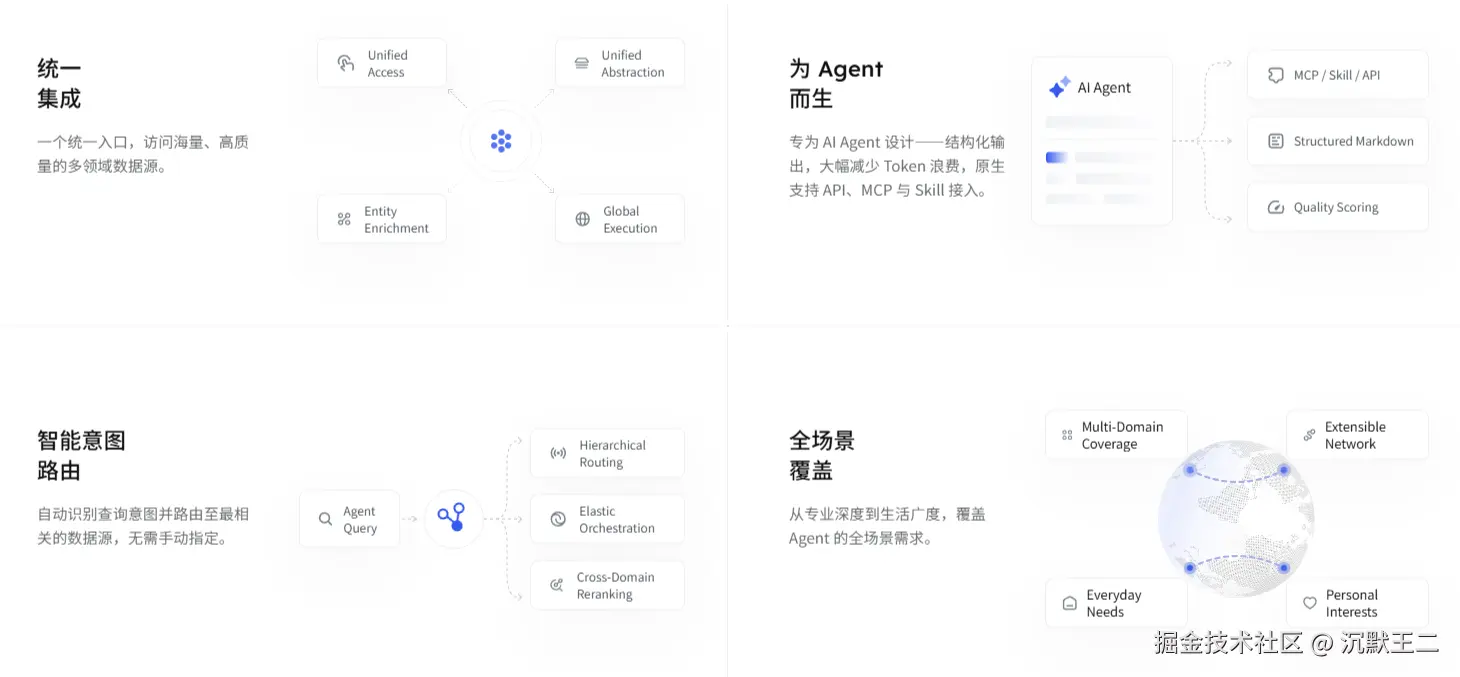
AnySearch 不是一个搜索引擎,不是 Google 的替代品。它是一个搜索基础设施,专为 AI Agent 设计的数据检索层。
用过 Agent 联网功能的都知道,现在的 Agent 搜索流程是这样的:用户提问题 → Agent 调 WebSearch 搜关键词 → 拿到一堆网页链接 → 用 WebFetch 抓内容 → 从 HTML 里提取文字 → 整理给用户。
这个链路有三个问题:第一个,搜不到深网内容。
第二个,Agent 拿到搜索结果之后还要自己去解析 HTML、过滤广告、提取正文,这个过程很浪费 token。
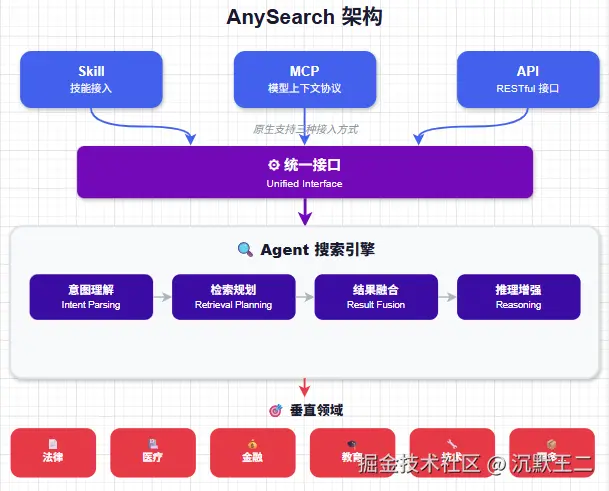
AnySearch 会自建索引,直接穿透金融、法律、学术、代码、安全、能源等 22 个垂直领域的数据源,返回的是结构化的 Markdown 数据,Agent 拿到就能直接用,不需要二次解析。
开发者只需要接 AnySearch 一个 API,就能检索所有垂直领域的内容。对 Agent 来说,就是从一个入口访问整个深网。
原生支持三种接入方式:Skill、MCP 和 API。Claude Code 用户可以装 Skill,Cursor 用户可以配 MCP,自己写应用的可以直接调 API。
02、安装 anysearch-skill
Claude Code 用户直接让 Agent 帮你装:
bash
帮我安装 anysearch skill,仓库地址是 https://github.com/anysearch-ai/anysearch-skill。Agent 会自动把 Skill 文件下载到 .claude/skills/ 目录,配置好之后就能用了。
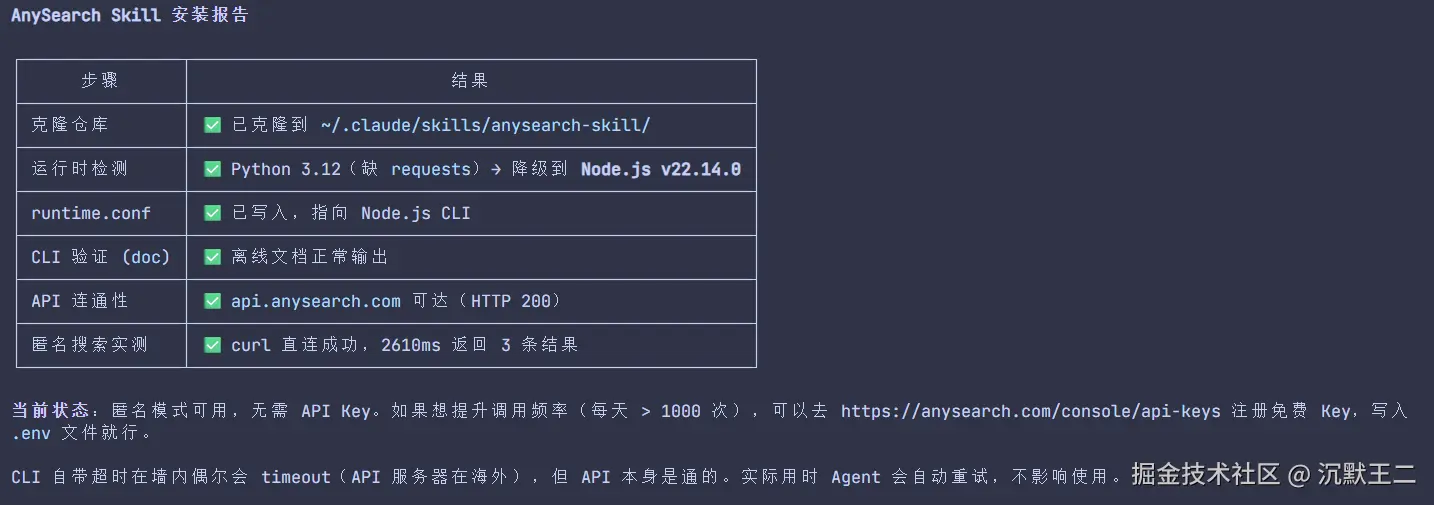
装完之后去 anysearch.com 注册一个账号,在控制台拿到 API Key,配到 Skill 的配置里。
多说一句,AnySearch 的免费额度是每天 1000 次 API 调用,面向所有个人开发者免费,这个量日常使用绰绰有余了
03、通用搜索实测
装好之后我做的第一件事就是拿它跟 WebSearch 做一个对比测试。
我的问题是:"OpenAI 2026 年的最新融资情况、API 定价变化、以及 Claude Code 和 Codex 在开发者社区的盲测对比。"
用传统的 WebSearch + WebFetch 组合,Agent 大概花了三四分钟,反复搜了四五次,抓了七八个网页,最后拼出一份摘要。
数据倒是没错,但很多细节缺失------融资金额没有出资方明细,API 定价只给了最新价没有历史变化,盲测对比只找到两篇文章。
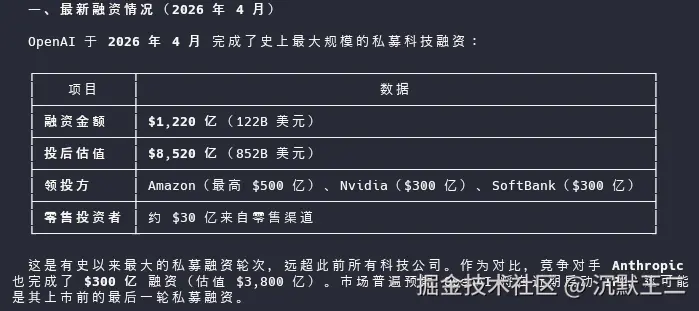
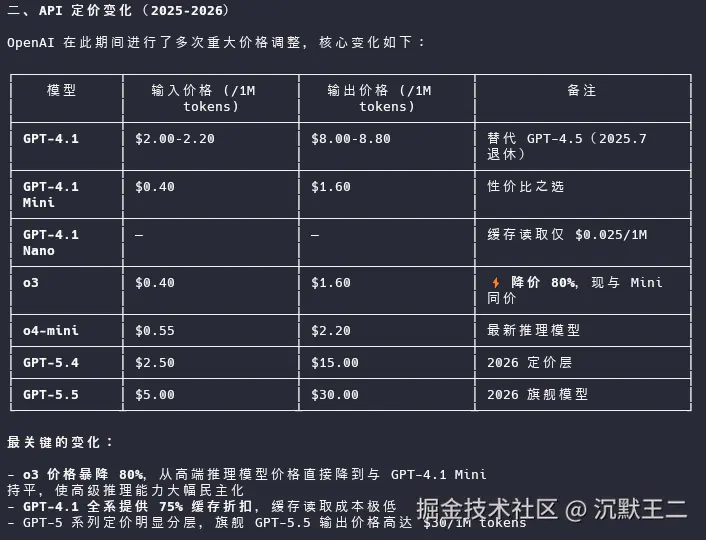

然后我把同一个问题丢给了接入 AnySearch 的 Agent。
让我第一次体验到了什么叫"AI 原生搜索"。
Agent 在几十秒内完成了检索、清洗和整理,返回了一份结构化的 Markdown 报告。融资金额精确到了每家出资方,API 定价变化按时间线列了出来,Reddit 上 Claude Code 和 Codex 的盲测胜率用表格呈现。
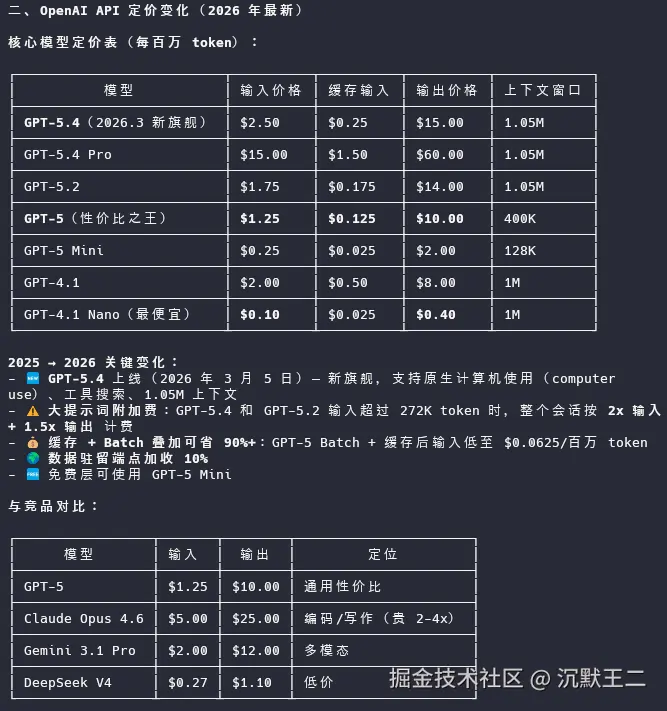
这里不难发现,AnySearch 给我们返回的结果不仅有不同模型的详细价格,还列出了和往年相比的变化趋势,同时又和竞品进行了对比。
04、垂直领域搜索
AnySearch 的另一个杀手级功能是垂直领域搜索。
目前支持 16 个垂直领域,包括 code(代码)、tech(技术)、finance(金融)、academic(学术)、legal(法律)、security(安全)、health(医疗)、energy(能源)等等。每个领域背后有专门的数据源和索引策略。
我选了三个领域做了实测。
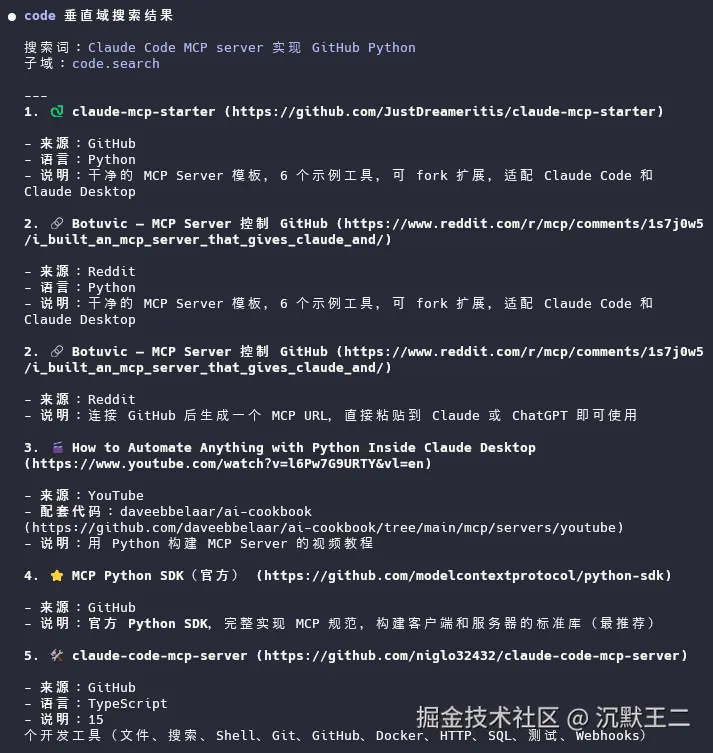
代码搜索,我让它搜 "Claude Code MCP server 实现 GitHub Python",指定 domain: code。
搜出来的不仅有github上的推荐项目,还有论坛上的热门文章。我们还可以让 Agent 做的更多,比如进一步筛选出最近三个月还在活跃更新的、Python 写的、跟 MCP 相关的项目等等。
学术搜索,我搜了 "transformer attention mechanism optimization 2025 2026",指定 domain: academic。
返回的是来自 arXiv 和学术数据库的论文列表,有标题、作者、机构、链接等结构化信息。以前做技术调研时,大家往往需要自己去 arXiv 一篇篇翻,现在 Agent 就可以直接帮我们完成初筛。

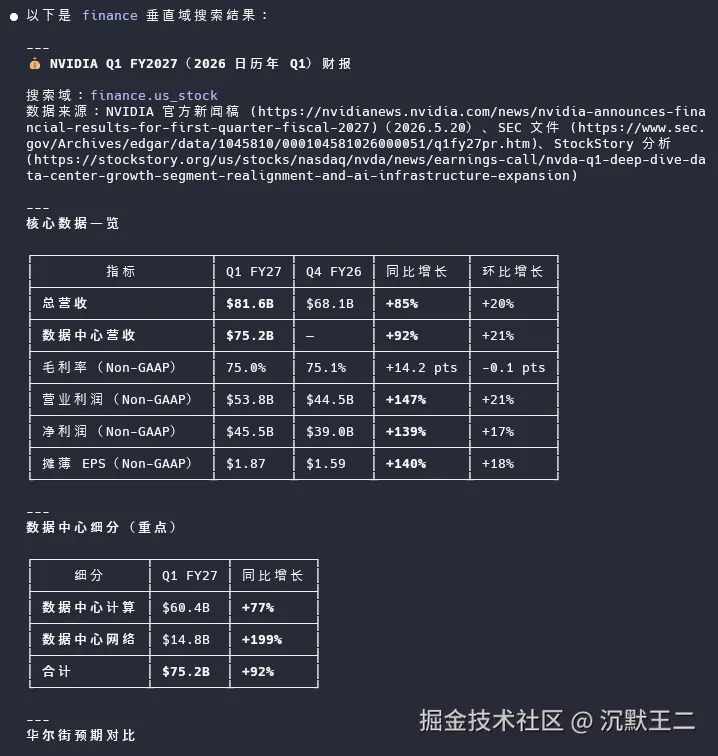
金融搜索,我搜了 "NVIDIA 2026 Q1 revenue data center growth",指定 domain: finance。
它返回了英伟达最新的季度营收数据,包括数据中心业务增长率、毛利率变化、同比和环比增长率等。数据也精确到了具体数字,而不是模糊的"大幅增长"。
05、并行批量搜索
AnySearch 的 Skill 里还有一个 batch_search 工具,支持同时发起最多 5 个搜索请求,并行执行。
这个功能对于需要同时调研多个主题的场景特别实用。
我拿它做了一次多维度技术情报搜集。任务是:同时调研 Claude Code、Codex、Cursor、Windsurf 这四个 AI 编程工具最近一个月的功能更新。
Agent 把四个工具的更新内容整理成了一份横向对比表。
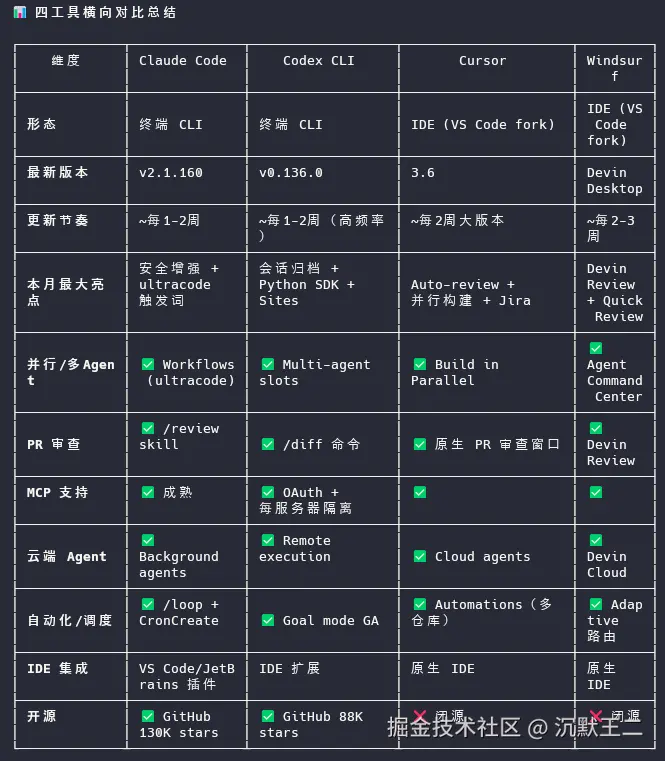
说实话,并行搜索这个功能在技术上不算什么创新------就是并发请求而已,任何一个后端开发都能做。但 AnySearch 把它封装成了 Agent 可以直接调用的工具,而且和垂直领域搜索、结构化输出能力结合得很好。
06、AnySearch 和传统搜索
前面聊了很多实测体验,这一节我想从技术角度认真聊聊 AnySearch 和传统搜索方案的本质差异。
传统 Agent 搜索依赖的是通用搜索引擎 API------Google Custom Search、Bing Search API 之类的。这些 API 的设计目标是给人类用的,返回的是网页列表。Agent 拿到网页列表之后要自己去抓取、解析、提取,每一步都可能出错,每一步都在消耗 token。
AnySearch 的设计出发点完全不同。
它面向的不是人类用户,而是 AI Agent。所以它的整个技术流程是反过来的:先理解 Agent 的查询意图,再路由到最匹配的数据源,最后返回结构化的 Markdown 数据。中间没有 HTML 解析、没有广告过滤、没有无关内容的干扰。
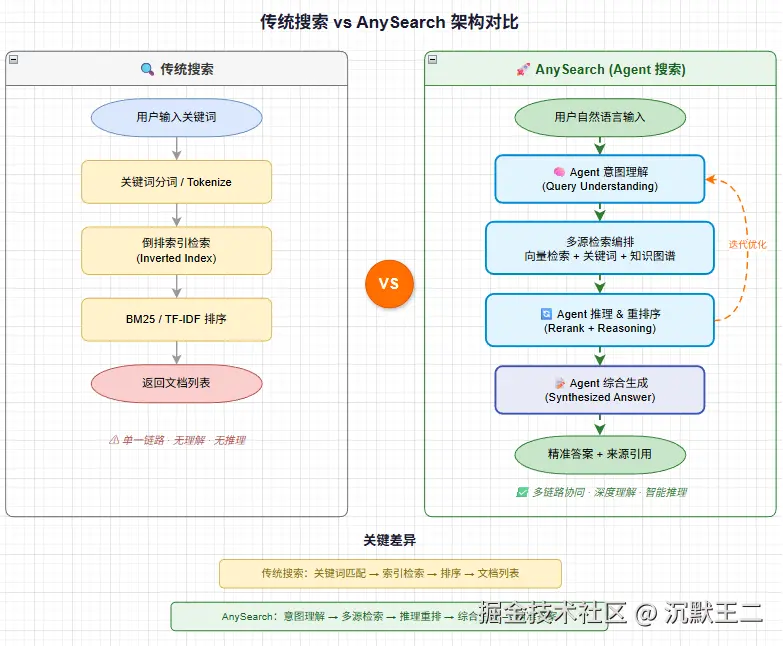
这让我想起一个很有意思的现象。
以前大家讨论 Agent 能力的时候,关注点都在模型本身------模型够不够聪明、推理够不够强、上下文够不够长。但 AnySearch 说明了一件事:搜索层的质量,对 Agent 最终表现的影响可能比我们想象的更大。
就像一个很聪明的人被关在一个乱糟糟的图书馆里找资料,他再聪明也得花很多时间翻书架。但如果图书馆的索引系统做得好,普通人也能很快找到需要的东西。AnySearch 做的就是给 Agent 建了一套好用的索引系统。
07、社区生态
AnySearch 官方开源了两个项目,一个是 anysearch-skill(Skill 插件),一个是 anysearch-mcp-server(MCP 服务器)。
两个都是 MIT 协议,随便用随便改。
最值得一提的是GitHub上一个叫 luoqianyi 开发的 easy_anysearch_skill 的项目,它的最大卖点是免 API Key,用了一个代理池机制来绕过速率限制。
安装方式也很简单:
bash
git clone git@github.com:luoqianyi/easy_anysearch_skill.git ~/.claude/skills/easy_anysearch_skill使用时通过 uv 运行,不需要手动安装 Python 依赖:
bash
uv run ~/.claude/skills/easy_anysearch_skill/search.py "搜索关键词"AnySearch 现在也上线了 Skills.sh、ClawHub、Glama、LobeHub 这些 Skill/MCP 市场。在 Skills.sh 上排进了 TOP1,说明开发者的认可度确实很高。
ending
以前我觉得 Agent 联网就是搜网页、抓内容、拼答案,就是个信息搬运工。现在我发现,搜索层的设计水平直接决定了 Agent 的天花板在哪里。
一个好用的搜索基础设施应该做到三件事:帮 Agent 找到传统搜索引擎找不到的内容,帮 Agent 用最低的成本获取最干净的数据,帮开发者用一套接口搞定所有数据源。
AnySearch 在这三个方向上迈出了一大步。
如果你也在用 Claude Code、Codex 或者 PaiCLI 做开发,我强烈建议装上试试。
【好的基础设施,不是让你多一个选择,而是让你不需要再做选择。】