手把手教你从0开始,在你的电脑上跑起来本地大模型,彻底告别TOKEN焦虑。
说明:大模型的能力取决于你的电脑性能,如果你的电脑很拉胯,建议直接放弃。
- 所有演示都基于Windows进行处理,目前使用的是Windows11
第一步:测试你的电脑可以跑哪些模型
本地可以跑什么模型主要取决于你本身的电脑配置,不然即使你下了一个跑不动的模型。要么内存不够直接报错,要么勉强跑起来速度慢到没法用。
这里推荐一个开源工具 llmfit扫描你的硬件信息,根据你系统的 RAM、CPU 和 GPU 为 LLM 模型匹配合适的规格。自动检测硬件,从质量、速度、适配度和上下文四个维度为每个模型打分,告诉你哪些模型能在你的机器上流畅运行。

下载地址:https://github.com/AlexsJones/llmfit
为了方便大家我把目前的最新版和用到的所有安装包直接放到网盘中供大家下载:链接:https://pan.quark.cn/s/40744fdcb070?pwd=DsdH
下载好安装包以后直接解压运行

官方给出的几种安装方式,大家可以根据自己系统进行选择
Windows
scoop install llmfit
如果尚未安装 Scoop,请参阅 Scoop 安装指南。
macOS / Linux
Homebrew
brew install llmfit
MacPorts
port install llmfit
快速安装
curl -fsSL [https://llmfit.axjns.dev/install.sh](https://llmfit.axjns.dev/install.sh) | sh
从 GitHub 下载最新发布的二进制文件并安装到 /usr/local/bin
稍微等一会 就能查看所能使用的模型(我的电脑是 4070 + 32GRAM)
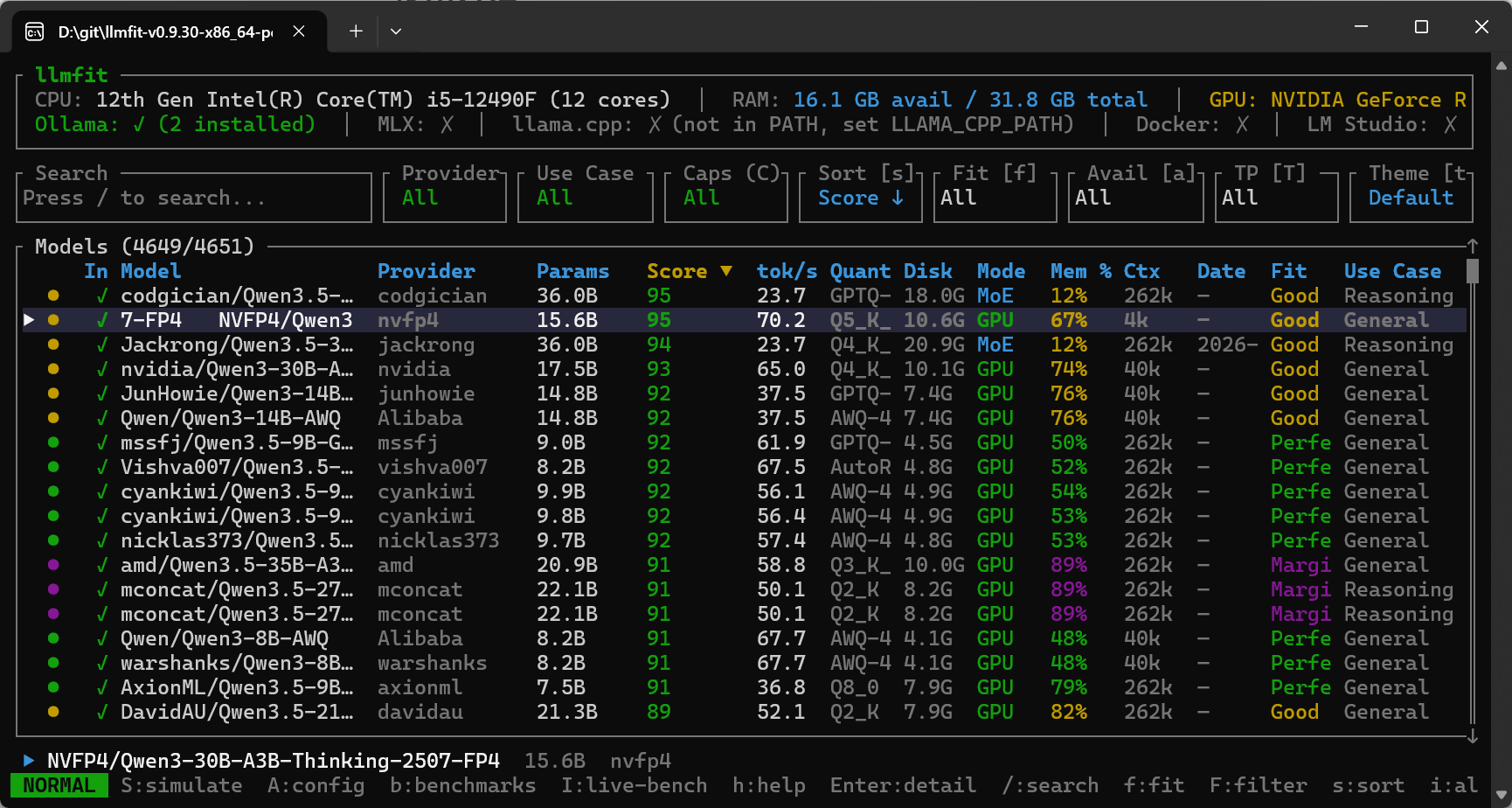
主要关注Fit 一栏:Perfect 或 Good 都可以跑,Marginal 勉强,Too Tight 就别试了。
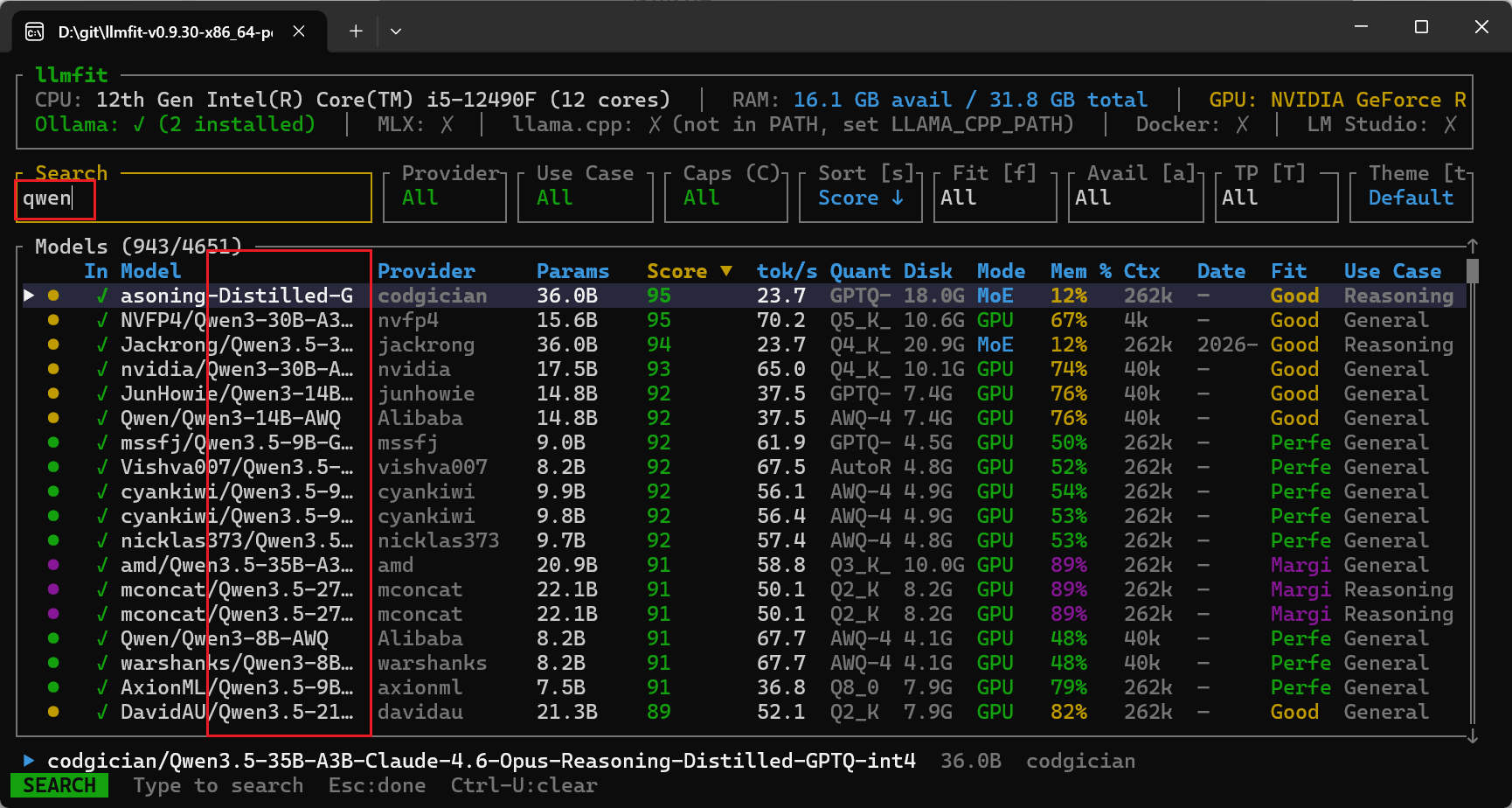
输入 / 进入搜索模式(按名称、提供商、参数量、用途模糊匹配),可以Esc 或 Enter退出搜索模式。 清楚搜索:Ctrl-U 比如我搜索一下qwen模型
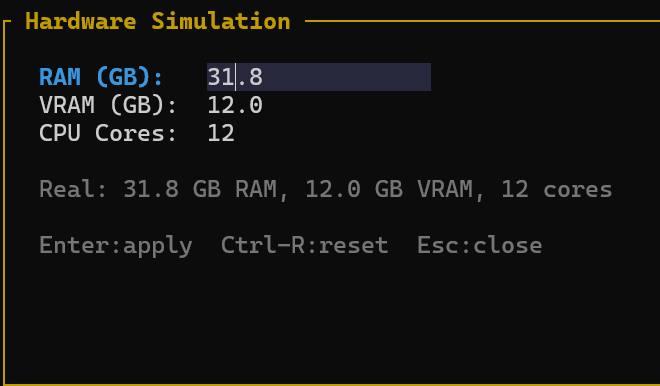
输入S可以进入硬件模拟,基于你修改后的配置给出重新计算模型的适配度。
可以直接搜索自己感兴趣的模型,这里就不详细介绍了,感兴趣的小伙伴可以自己下载下来试试。
第二步:安装Ollama
首先给出官方下载地址:https://ollama.com/
Windows可以直接在 PowerShell中执行 irm [https://ollama.com/install.ps1](https://ollama.com/install.ps1) | iex进行下载,也可以直接下载对应的安装包。如果下载太慢,可以直接从我分享的链接下载。
Linux的下载命令为 curl -fsSL [https://ollama.com/install.sh](https://ollama.com/install.sh) | sh
安装**Ollama **Windows下就和安装普通软件一样,
静静等待安装成功,安装以后会进入Ollama界面(我这里右下角有模型是因为我之前下载过),选择需要使用的模型
查看Ollama支持的模型(能通过Ollama进行自部署的模型)
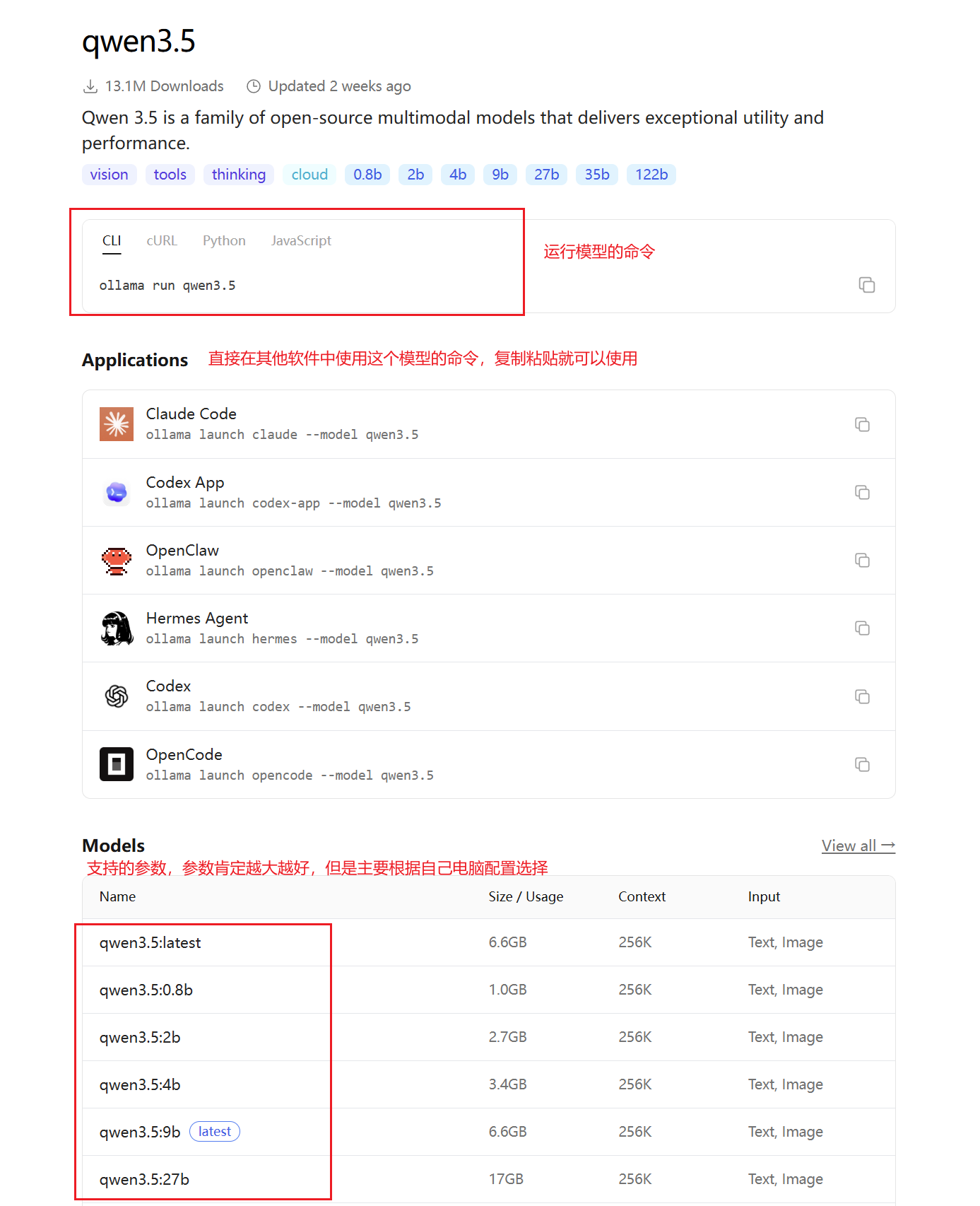
找到你想要下载的模型点进去,可以看到有哪些参数模型提供给你选择,还会给你运行命令
第三步:下载模型并使用
目前值得推荐的两个选择是谷歌的 Gemma 4 和阿里的 Qwen3.5。
Gemma 4 是谷歌 DeepMind 在 2025 年发布的开源模型系列,最大亮点是原生支持多模态(文字+图片),上下文窗口达到 128K~256K,在同体量开源模型里综合表现靠前。
Qwen3.5 是阿里通义团队的最新开源版本,支持 201 种语言,中文理解和代码能力尤其突出,同时内置"思考模式",复杂问题可以先推理再回答。两个都是近期开源圈里最值得关注的选择。
具体使用哪个版本可以参考你的电脑配置,我这里就演示下载一个qwen3.5的9b版本。
命令行
bash
# 下载 Gemma 4(以 26b 为例)
ollama run gemma4:26b
# 下载 Qwen3.5(以 9b 为例)
ollama run qwen3.5:9b
# 查看当前已有模型
ollama ls
NAME ID SIZE MODIFIED
qwen3.5:9b 6488c96fa5fa 6.6 GB 1 months ago
qwen3:30b ad815644918f 18 GB 1 months ago
# 退出模型对话
/bye 测试运行一个我没有的模型qwen3.5:0.8b 他检测到你电脑中没有对用的模型时会自动帮你进行下载,下载以后就可以直接使用

测试使用其他模型对话
bash
# 运行模型,如没有这个模型会自动帮你下载
C:\Users\lc>ollama run qwen3.5:9b
>>> 你好,你是什么模型
可以使用 ollama rm xxx删除你不想使用的模型。
下载以后的模型如果你不想在命令行中使用,可以直接在图形界面中使用,就像我们在网页中和LLM对话一样
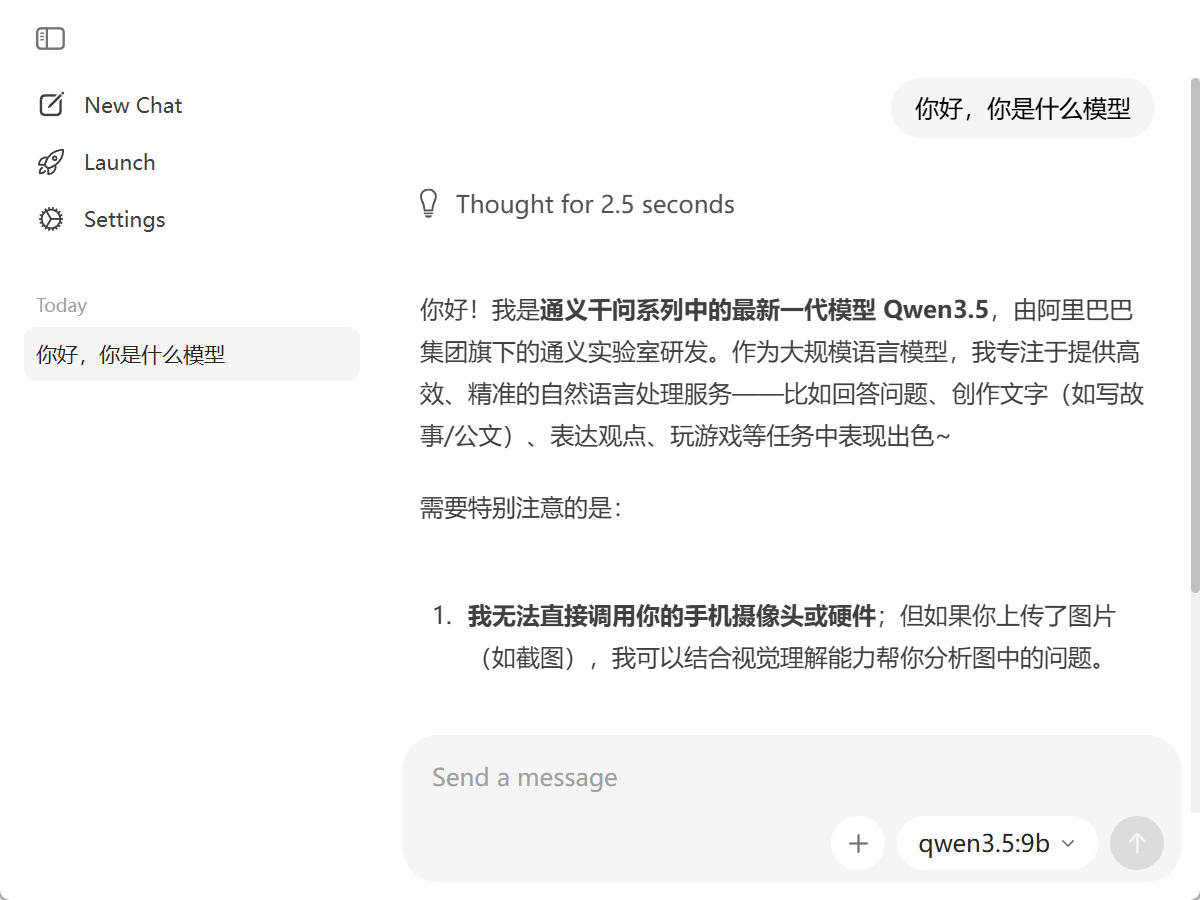
到这里你的Ollama就一句跑起来一套大模型了,开始用它愉快的玩耍吧。针对他一些资料的确实,可以通过RAG来增强模型的知识库,后面会讲到。
Ollama 运行后会在本地开放一个 API 接口,默认地址是 localhost:11434。支持自定义 API endpoint 的工具都可以接入,比如:
- Claude Code:命令行编程助手,可以指定本地模型
- Cherry Studio:桌面客户端,支持多模型切换
- Spring AI 、Langchain:大模型开发框架
每个工具的配置方式略有不同。
在这里Ollama也给我提供了对应的接入命令,如果你不知道命令你可以直接打开
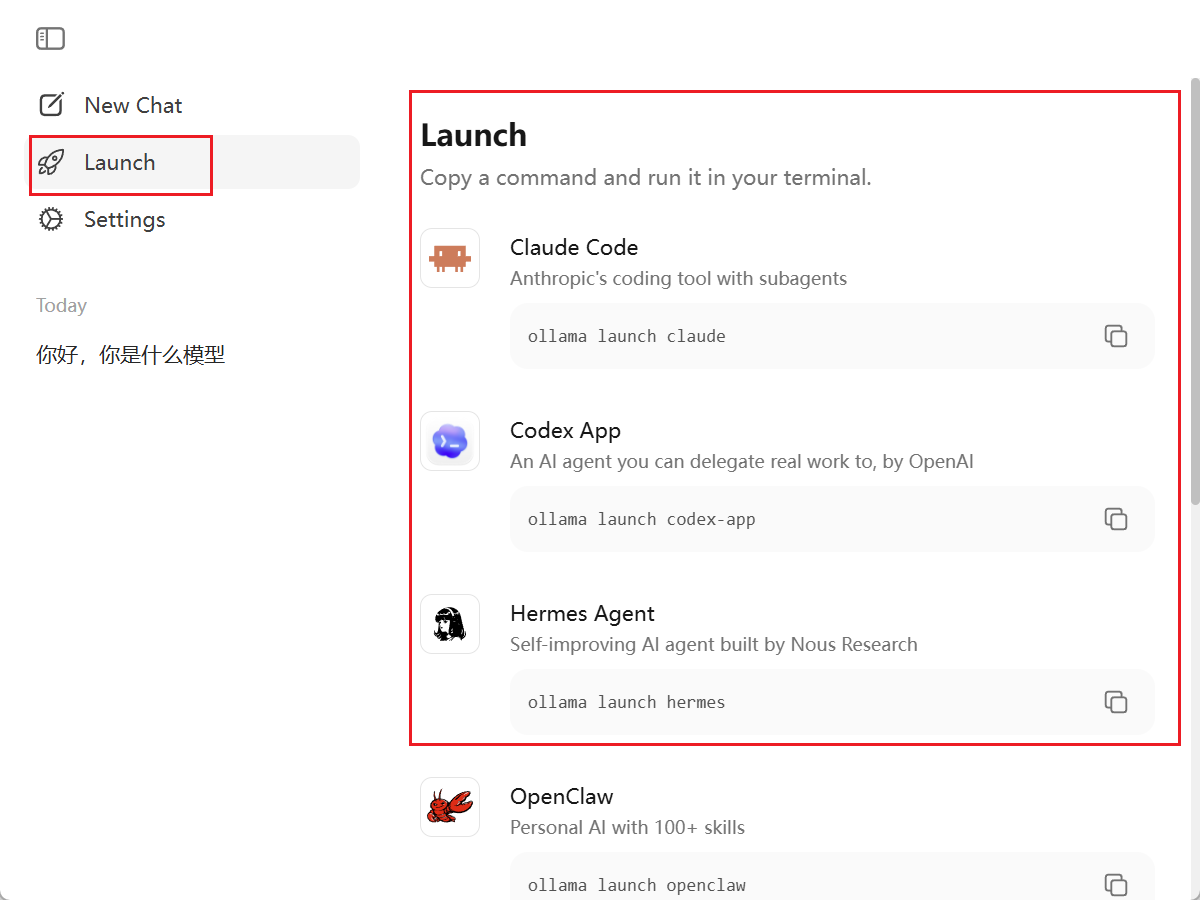
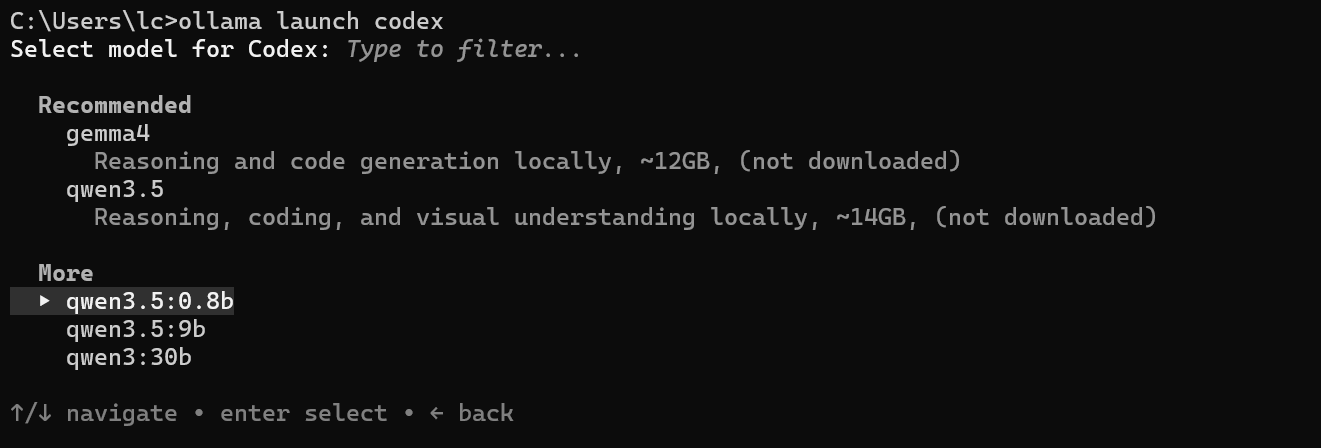
比如我直接运行 ollama launch codex
首先需要你选择运行的模型,这里选择我们自己有的就可以,我就直接用个9b的
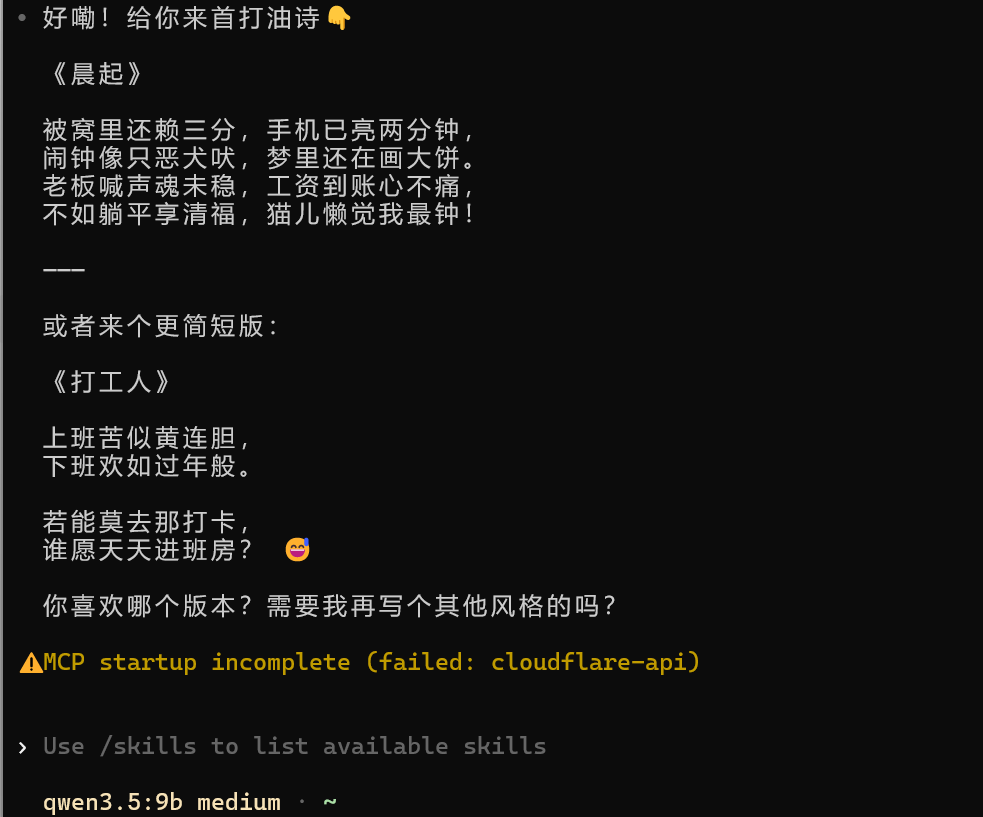
这个时候我们就使用codex调用我们本机的Ollama模型,接下来就和我们正常使用codex一样,比如我让他帮我写一首诗
常见问题
Ollama默认是开机自启的,在它的设置中没有配置可以关闭自启
可以通过任务管理器或者其他启动项管理工具进行禁用
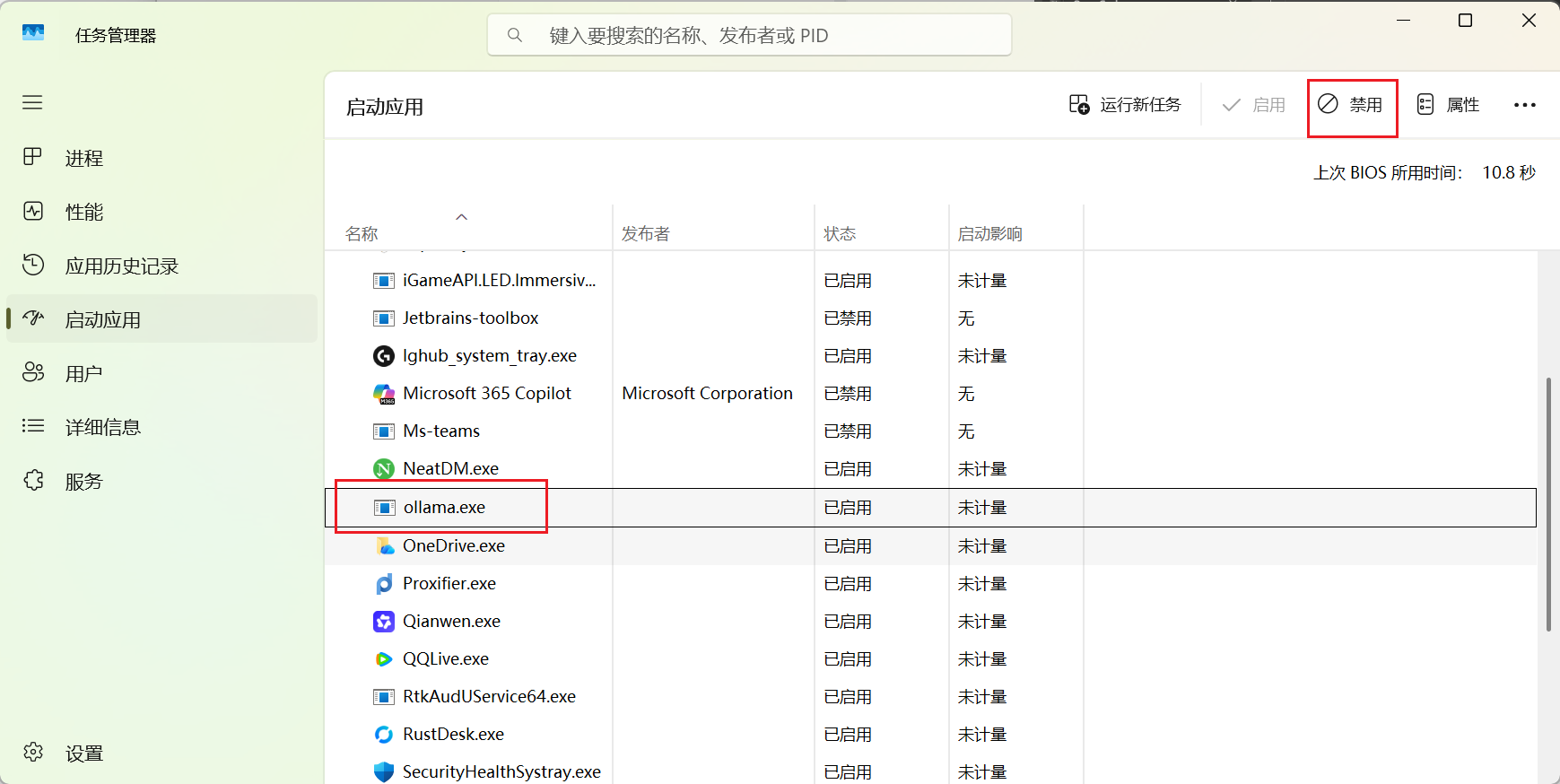
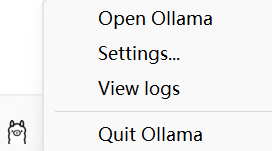
怎么查看Ollama是否运行
只要在桌面任务栏看到Ollama的图标则表示正在运行
** 模型下载失败或速度极慢 **
如果下载中断,重新执行 ollama run <模型名称> 会自动从断点处继续下载 。如需使用国内镜像加速,可以退出托盘中的 Ollama,在系统环境变量中添加系统变量 OLLAMA_ORIGINS 值为 *,或使用代理工具。
调整上下文长度
默认支持的上下文较小(通常为 2048 token),运行模型时输入 /set parameter num_ctx 4096 可将其扩大。