一、技术背景与问题定义
1. 自动驾驶感知的模态特性
- 相机:能提供密集语义信息,但易受雨、雪、雾、夜间低光照、眩光等恶劣环境影响,且单目方案难以精准估计深度和物体速度,远距离检测精度下降明显。
- 毫米波雷达:具备不受光照/天气干扰、可直接测量距离与径向速度、探测距离远的优势,但存在点云稀疏、无高度信息、噪声多、易产生多径效应、语义信息缺失的缺陷。
- 二者信息高度互补,融合是低成本自动驾驶感知的重要技术方向。
2. 现有雷达-相机融合的痛点
- 前视图投影融合:雷达点投影到图像平面时因无高度信息存在对齐偏差,且依赖相机第一阶段的检测提案,若相机漏检目标,融合阶段也无法识别,性能上限受限于相机效果。
- 特征融合不充分:传统简单拼接、单向注意力融合无法有效适配雷达和相机特征的模态差异,难以充分挖掘两类特征的互补价值。
3. BEV(鸟瞰图)感知的技术优势
BEV视角可以统一不同传感器的坐标空间,避免前视图的几何畸变,更贴合自动驾驶下游路径规划、决策任务的需求,是多传感器融合的天然载体。
二、 BEV-radar核心技术方案
论文提出端到端的雷达-相机BEV融合框架,核心创新点包括三部分:
1. 双模态BEV特征统一表征
- 相机侧:基于BEVDet基线,提取多视角图像特征后预测深度分布,结合外参矩阵将前视图特征变换为统一的BEV特征图。
- 雷达侧:累计6帧雷达点缓解稀疏性,采用Pillar(柱体)编码方式,无需高度维度即可将稀疏雷达点转换为紧凑的BEV雷达特征图,适配雷达无高度信息的特性。
2. 双向空间融合模块**(BSF, Bidirectional Spatial Fusion)**
针对传统跨模态融合的不足,设计双向交互的融合结构:
- 双向交叉注意力:以相机BEV特征为查询、雷达BEV特征为键值做一次交叉注意力,再以雷达BEV特征为查询、相机BEV特征为键值做第二次交叉注意力,实现两类特征的双向信息交互,解决单向融合的信息损失问题;采用可变形注意力降低计算开销,适配BEV特征的空间特性。
- 卷积局部增强:注意力交互后加入卷积层,提取特征的局部空间关联,强化目标的空间位置约束,弥补纯注意力结构对空间信息建模的不足。
- 多层堆叠:通过堆叠多个BSF模块,逐步实现两类特征的域对齐与深度融合。
3. 检测头与损失设计
融合后的BEV特征输入基于Transformer的检测头,采用DETR的二分匹配范式(无需NMS后处理)预测3D框;总损失由分类损失、回归损失、IoU损失加权求和构成,适配3D检测任务需求。
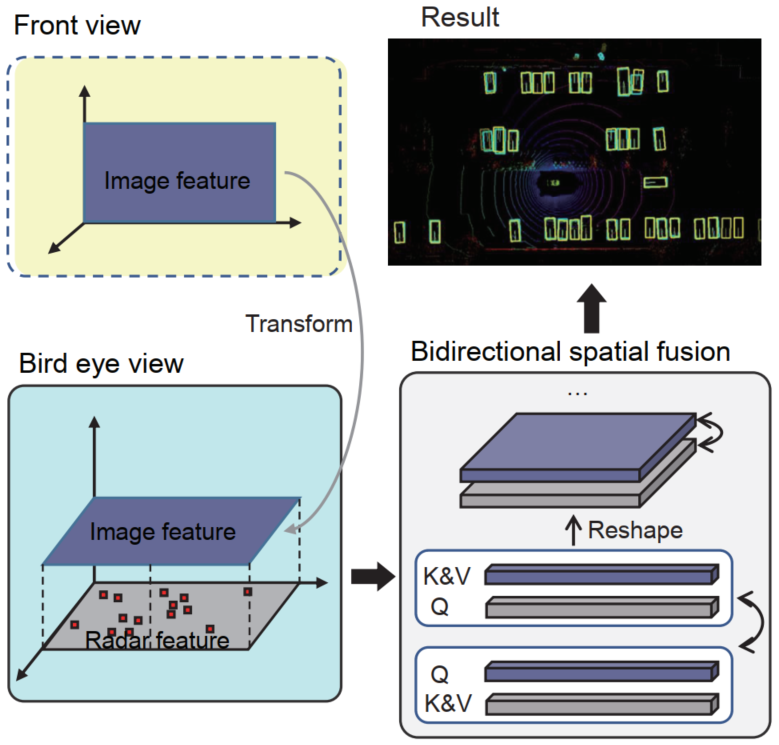
BEV-radar通过在鸟瞰图(BEV)视角下对齐摄像头和雷达特征,简化了三维目标检测,并采用双向查询式Transformer方法实现互补信息交换,从而提升融合效果。
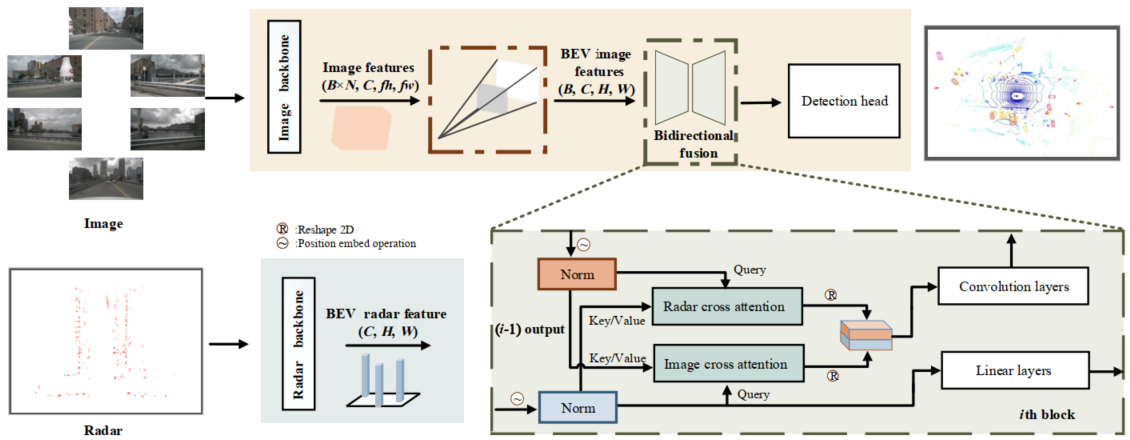
图2. 框架的整体架构。我们的模型基于独立的骨干网络分别提取图像BEV特征和雷达BEV特征。我们的BSF(双向空间融合)模块由多个依次连接的模块组成:首先,通过一个共享的双向交叉注意力机制实现两者之间的信息交互形式。空间对齐后,用于定位雷达和相机的鸟瞰图特征。所有模块处理完成后,两个输出将被送入一个反卷积模块以降低通道数。
三、 实验验证与结论
所有实验在自动驾驶公开数据集nuScenes上开展,验证了方案的有效性:
1. 主性能结果
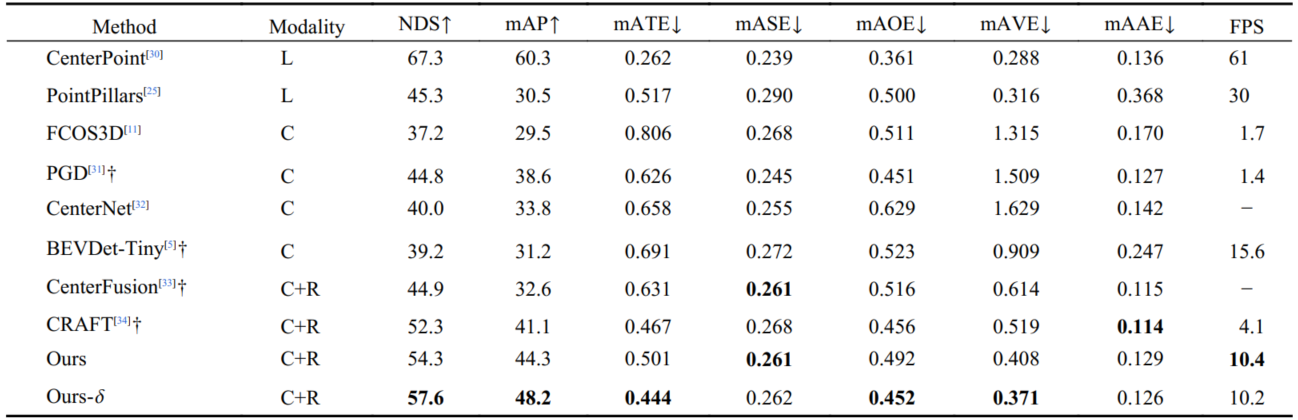
- 在nuScenes测试集上达到48.2 mAP、57.6 NDS,相比纯相机基线提升17% mAP,相比其他主流雷达-相机融合方案(如CRAFT)提升7% mAP、5% NDS,推理速度达10.2 FPS,满足实时性需求。
- 速度预测精度大幅提升:相比纯相机模型速度误差降低53%,相比其他雷达融合方案速度误差降低14%-24%,充分发挥了雷达的速度测量优势。
2. 细粒度性能分析
- 类别适配性:对金属材质的大型动态目标(汽车、卡车、公交)提升最显著(20%左右mAP增益),对非金属小目标(行人、自行车)也有10%-20%的提升;对长尾类别、静态目标的增益相对较低,受雷达RCS(雷达散射截面)特性和数据集分布影响。
- 距离鲁棒性:远距离检测性能提升明显,40米距离的汽车AP仍有20%的增益,缓解了相机远距离分辨率不足的问题。
- 恶劣环境鲁棒性:夜间场景mAP相比纯相机提升10%,雨天场景提升12%,验证了雷达对相机环境短板的补充作用。
3. 消融实验验证
双向融合比简单特征拼接提升4.2 mAP,加入卷积空间增强的BSF模块比基础双向融合进一步提升1.3 mAP,3个BSF堆叠达到最优性能,验证了核心模块的有效性。
表1.在nuScenes测试集上的最新方法对比。"L"、"C"和"R"分别表示激光雷达、相机和雷达。 表示测试时增强。特别地,BEVDet-Tiny 是我们仅使用相机的BEV基线模型,CenterNet 用于 CenterFusion 和 CRAFT。 表示与基础版本相比,采用 SECOND29 网络作为解码器。粗体数字表示对应指标的最佳值。
四、 方案价值与局限
1. 技术价值
- 摆脱了传统融合方法对相机第一阶段检测结果的依赖,可移植到其他BEV感知框架中,适配多传感器扩展。
- 实现了低成本雷达+相机方案的性能突破,在环境鲁棒性、速度预测、远距离检测上的优势贴合量产自动驾驶的实际需求。
2. 局限
雷达本身无法独立提供语义信息,相机仍是融合效果的下限,当相机完全失效时融合方案也无法正常工作;稀疏雷达点对小目标、非金属目标的支撑能力仍有不足。
3. 应用方向
可为中低阶量产自动驾驶、恶劣场景下的感知冗余设计提供技术参考,也为多模态BEV融合的结构设计提供了新的思路。

图4. 检测结果的定性分析。3D边界框预测结果分别投影到六个不同视角和BEV图像上。
不同类别的框用不同颜色标注,且未标注真实地面。在BEV可视化中,黄色表示预测框,蓝色表示真实框,而LiDAR点则以背景形式显示。