集成学习:三个臭皮匠顶个诸葛亮的机器学习哲学
1. 集成学习的核心思想:众人拾柴火焰高
想象一下看病的场景:一个医生诊断可能会出错,但如果三个不同科室的专家一起会诊,误诊率会大幅下降。机器学习里也有同样的道理------单个学习器可能存在偏差、方差或过拟合问题,但把多个"各有所长"的学习器结合起来,往往能得到比任何单个学习器都更好的性能,这就是集成学习(Ensemble Learning)的核心思想。
通俗来说,集成学习就是"搭班子":先训练一堆"弱学习器"(性能只比随机猜测好一点的模型,比如单层决策树),然后通过某种策略把它们组合成一个"强学习器"。这里有两个关键要求:
- 好:每个弱学习器不能太"菜",至少要比瞎猜强;
- 不同:学习器之间要有显著差异,否则100个一模一样的模型集成起来还是和单个模型没区别。
根据个体学习器之间的依赖关系,集成学习主要分为两大类:
- 序列化方法 :个体学习器之间存在强依赖,必须串行生成,代表是Boosting;
- 并行化方法 :个体学习器之间无依赖,可以同时生成,代表是Bagging 和随机森林。
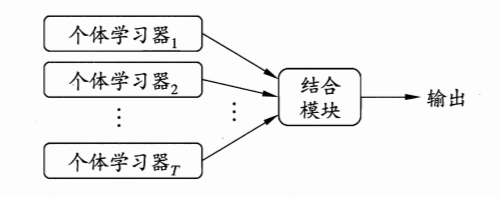
图1 集成学习基本框架
2. Boosting:查漏补缺的迭代提升
2.1 基本思想:从错误中学习
Boosting的工作机制像一个"错题本学习法":
- 先用所有样本训练第一个弱学习器;
- 把第一个学习器分错的样本找出来,给它们更高的权重(相当于让模型更关注这些难分的样本);
- 用加权后的样本训练第二个弱学习器;
- 重复上述过程,直到生成T个弱学习器;
- 把所有弱学习器加权结合(准确率高的学习器权重更大),得到最终的强学习器。
2.2 经典算法:AdaBoost
AdaBoost(Adaptive Boosting)是Boosting家族最经典的算法,它通过自适应调整样本权重 和学习器权重实现迭代提升。
2.2.1 算法推导与公式解释
AdaBoost使用指数损失函数 作为优化目标,因为它对0-1损失是一致的,且求导更方便:
lexp(H∣D)=Ex∼De−f(x)H(x)l_{exp}(H|D) = \mathbb{E}_{x\sim D}\lefte\^{-f(x)H(x)}\\rightlexp(H∣D)=Ex∼De−f(x)H(x)
- lexpl_{exp}lexp:指数损失函数值;
- H(x)H(x)H(x):集成学习器的输出,H(x)=∑t=1Tαtht(x)H(x) = \sum_{t=1}^T \alpha_t h_t(x)H(x)=∑t=1Tαtht(x);
- αt\alpha_tαt:第t个弱学习器ht(x)h_t(x)ht(x)的权重;
- f(x)f(x)f(x):样本xxx的真实标记(取值为+1或-1);
- DDD:训练集的样本分布;
- Ex∼D\mathbb{E}_{x\sim D}Ex∼D:在分布DDD下的数学期望。
对H(x)H(x)H(x)求导并令导数为0,可得最优集成输出:
H(x)=12lnP(f(x)=1∣x)P(f(x)=−1∣x)H(x) = \frac{1}{2}\ln\frac{P(f(x)=1|x)}{P(f(x)=-1|x)}H(x)=21lnP(f(x)=−1∣x)P(f(x)=1∣x)
这说明指数损失最小化等价于后验概率最大化,和0-1损失的优化目标一致。
2.2.2 AdaBoost算法步骤
输入:训练集D={(x1,y1),(x2,y2),...,(xm,ym)}D=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\}D={(x1,y1),(x2,y2),...,(xm,ym)},弱学习算法L\mathcal{L}L,迭代轮数TTT
过程:
- 初始化样本权重分布:D1(x)=1mD_1(x) = \frac{1}{m}D1(x)=m1(所有样本初始权重相同)
- 对t=1,2,...,Tt=1,2,...,Tt=1,2,...,T:
a. 用分布DtD_tDt训练弱学习器ht(x)h_t(x)ht(x)
b. 计算ht(x)h_t(x)ht(x)在DtD_tDt上的分类误差:
ϵt=Px∼Dt(ht(x)≠f(x))=∑i=1mDt(xi)I(ht(xi)≠yi)\epsilon_t = P_{x\sim D_t}(h_t(x)\neq f(x)) = \sum_{i=1}^m D_t(x_i)\mathbb{I}(h_t(x_i)\neq y_i)ϵt=Px∼Dt(ht(x)=f(x))=i=1∑mDt(xi)I(ht(xi)=yi)- I(⋅)\mathbb{I}(\cdot)I(⋅):指示函数,条件成立时为1,否则为0
c. 若ϵt>0.5\epsilon_t > 0.5ϵt>0.5,则停止迭代(弱学习器比随机猜测还差)
d. 计算弱学习器的权重:
αt=12ln(1−ϵtϵt)\alpha_t = \frac{1}{2}\ln\left(\frac{1-\epsilon_t}{\epsilon_t}\right)αt=21ln(ϵt1−ϵt)
(误差越小,学习器权重越大)
e. 更新样本权重分布:
Dt+1(x)=Dt(x)Zt⋅{e−αt,ht(x)=f(x)eαt,ht(x)≠f(x)D_{t+1}(x) = \frac{D_t(x)}{Z_t} \cdot \begin{cases} e^{-\alpha_t}, & h_t(x)=f(x) \\ e^{\alpha_t}, & h_t(x)\neq f(x) \end{cases}Dt+1(x)=ZtDt(x)⋅{e−αt,eαt,ht(x)=f(x)ht(x)=f(x) - ZtZ_tZt:规范化因子,Zt=∑i=1mDt(xi)e−αtyiht(xi)Z_t = \sum_{i=1}^m D_t(x_i)e^{-\alpha_t y_i h_t(x_i)}Zt=∑i=1mDt(xi)e−αtyiht(xi),确保Dt+1D_{t+1}Dt+1是一个合法的概率分布
- I(⋅)\mathbb{I}(\cdot)I(⋅):指示函数,条件成立时为1,否则为0
- 输出最终集成学习器:
H(x)=sign(∑t=1Tαtht(x))H(x) = sign\left(\sum_{t=1}^T \alpha_t h_t(x)\right)H(x)=sign(t=1∑Tαtht(x))- sign(⋅)sign(\cdot)sign(⋅):符号函数,大于0输出+1,小于0输出-1
2.2.3 核心代码实现
python
import numpy as np
from sklearn.tree import DecisionTreeClassifier
class AdaBoost:
def __init__(self, n_estimators=50):
self.n_estimators = n_estimators # 弱学习器数量
self.alphas = [] # 每个弱学习器的权重
self.weak_learners = [] # 存储弱学习器
def fit(self, X, y):
m, n = X.shape
# 初始化样本权重
D = np.ones(m) / m
for t in range(self.n_estimators):
# 训练弱学习器(这里用单层决策树)
clf = DecisionTreeClassifier(max_depth=1)
clf.fit(X, y, sample_weight=D)
y_pred = clf.predict(X)
# 计算分类误差
error = np.sum(D * (y_pred != y))
# 误差超过0.5则停止
if error > 0.5:
break
# 计算学习器权重
alpha = 0.5 * np.log((1 - error) / error)
self.alphas.append(alpha)
self.weak_learners.append(clf)
# 更新样本权重
D = D * np.exp(-alpha * y * y_pred)
D = D / np.sum(D) # 规范化
def predict(self, X):
# 加权投票
y_pred = np.zeros(X.shape[0])
for alpha, clf in zip(self.alphas, self.weak_learners):
y_pred += alpha * clf.predict(X)
return np.sign(y_pred)2.3 Boosting的偏差-方差分析
从偏差-方差分解的角度看,Boosting主要降低模型的偏差。因为它基于多个高偏差的弱学习器(比如单层决策树),通过迭代聚焦难分样本,不断修正之前的错误,最终得到低偏差的强学习器。
3. Bagging与随机森林:民主投票的并行集成
3.1 Bagging:自助采样的并行集成
Bagging(Bootstrap Aggregating)的核心思想是并行训练多个独立的学习器,然后通过投票(分类)或平均(回归)得到最终结果。
3.1.1 自助采样法(Bootstrap Sampling)
Bagging的关键是自助采样:对包含m个样本的原始数据集,有放回地随机抽取m个样本作为一个基学习器的训练集。
- 某个样本在m次采样中始终不被抽到的概率是:
limm→∞(1−1m)m=1e≈36.8%\lim_{m\to\infty}\left(1-\frac{1}{m}\right)^m = \frac{1}{e} \approx 36.8\%m→∞lim(1−m1)m=e1≈36.8% - 因此每个基学习器的训练集大约包含原始数据的63.2%,剩下的36.8%称为包外样本(Out-of-Bag, OOB),可以用来评估模型性能,无需额外划分验证集。
3.1.2 Bagging算法步骤
输入:训练集DDD,弱学习算法L\mathcal{L}L,基学习器个数TTT
过程:
- 对t=1,2,...,Tt=1,2,...,Tt=1,2,...,T:
a. 对DDD进行自助采样,得到采样集DtD_tDt
b. 用DtD_tDt训练基学习器ht(x)h_t(x)ht(x) - 输出最终集成学习器:
- 分类任务:相对多数投票
- 回归任务:简单平均
3.2 随机森林:Bagging的进阶版
随机森林(Random Forest, RF)是Bagging的一个重要变体,它在Bagging的基础上引入了属性随机采样,进一步增强了学习器的多样性。
传统Bagging中,每个基决策树在分裂节点时会从所有属性 中选择最优属性;而随机森林中,每个节点分裂时会先从所有属性中随机选择kkk个属性,再从这kkk个属性中选择最优分裂属性。
- 推荐k=log2dk = log_2 dk=log2d,其中ddd是原始属性个数;
- 当k=dk=dk=d时,随机森林退化为Bagging;
- 当k=1k=1k=1时,完全随机选择属性分裂。
图2 随机森林结构示意图
3.3 实验对比:单树 vs Bagging vs 随机森林
我们在UCI的三个经典数据集上对比了单个决策树、Bagging(50棵树)和随机森林(50棵树)的分类准确率,结果如下:
| 数据集 | 样本数 | 属性数 | 单个决策树 | Bagging | 随机森林 |
|---|---|---|---|---|---|
| Iris | 150 | 4 | 94.7% | 96.0% | 96.7% |
| Wine | 178 | 13 | 91.6% | 94.4% | 96.1% |
| Breast Cancer | 569 | 30 | 92.8% | 95.4% | 96.8% |
结果分析:
- 集成方法的准确率普遍高于单个决策树,验证了集成学习的有效性;
- 随机森林的性能优于Bagging,因为属性随机采样带来了更高的多样性;
- 在高维数据集(Breast Cancer,30个属性)上,随机森林的提升更明显。
3.4 随机森林的优点
- 训练速度快:可以并行生成多棵树;
- 抗过拟合能力强:多棵树的投票机制抵消了单棵树的过拟合;
- 无需特征选择:能自动评估特征重要性;
- 对缺失值和异常值不敏感。
4. 学习器结合策略:怎么把多个模型的意见整合起来
4.1 平均法(回归任务)
-
简单平均法 :所有学习器的输出取算术平均
H(x)=1T∑t=1Tht(x)H(x) = \frac{1}{T}\sum_{t=1}^T h_t(x)H(x)=T1t=1∑Tht(x)
适用于基学习器性能相近的场景。
-
加权平均法 :给性能好的学习器更高的权重
H(x)=∑t=1Twtht(x),∑t=1Twt=1,wt≥0H(x) = \sum_{t=1}^T w_t h_t(x), \quad \sum_{t=1}^T w_t = 1, w_t \geq 0H(x)=t=1∑Twtht(x),t=1∑Twt=1,wt≥0
适用于基学习器性能差异较大的场景。
4.2 投票法(分类任务)
- 绝对多数投票法:得票超过半数的类别作为最终结果,否则拒绝预测;
- 相对多数投票法:得票最多的类别作为最终结果;
- 加权投票法:每个学习器的投票乘以其权重,再统计总票数。
举个例子:3个学习器对样本xxx的预测结果分别是A、A、B,相对多数投票结果是A;如果是绝对多数投票,因为A得票2/3超过半数,结果也是A。
4.3 学习法:Stacking
当简单的平均或投票效果不好时,可以用Stacking(堆叠集成):把初级学习器的输出作为次级学习器的输入,训练一个"元学习器"来整合结果。
注意 :不能用同一个数据集同时训练初级和次级学习器,否则会严重过拟合。通常用交叉验证的方式:把训练集分成k份,用k-1份训练初级学习器,剩下1份生成次级学习器的训练数据。
5. 多样性:集成学习的灵魂
集成学习的性能本质上依赖于个体学习器的准确性 和多样性 。我们可以用误差-分歧分解 来量化它们的关系:
E=Eˉ−AˉE = \bar{E} - \bar{A}E=Eˉ−Aˉ
- EEE:集成学习器的泛化误差;
- Eˉ\bar{E}Eˉ:所有个体学习器的平均泛化误差;
- Aˉ\bar{A}Aˉ:所有个体学习器的平均分歧(即多样性)。
这个公式告诉我们:在个体准确率不变的情况下,多样性越高,集成的泛化误差越小。
5.1 增强多样性的常用方法
- 数据样本扰动:通过自助采样、交叉验证等方式生成不同的训练集,代表是Bagging;
- 输入属性扰动:随机选择属性子集训练不同的学习器,代表是随机森林;
- 输出表示扰动:对样本标记进行轻微修改,比如纠错输出码(ECOC);
- 算法参数扰动:给基学习器设置不同的参数,比如不同的树深度、学习率。
6. 实战:用sklearn实现集成学习
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, AdaBoostClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 单个决策树
dt = DecisionTreeClassifier(random_state=42)
dt.fit(X_train, y_train)
y_pred_dt = dt.predict(X_test)
print(f"单个决策树准确率: {accuracy_score(y_test, y_pred_dt):.4f}")
# Bagging
bagging = BaggingClassifier(DecisionTreeClassifier(), n_estimators=50, random_state=42)
bagging.fit(X_train, y_train)
y_pred_bagging = bagging.predict(X_test)
print(f"Bagging准确率: {accuracy_score(y_test, y_pred_bagging):.4f}")
# 随机森林
rf = RandomForestClassifier(n_estimators=50, random_state=42)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print(f"随机森林准确率: {accuracy_score(y_test, y_pred_rf):.4f}")
# AdaBoost
adaboost = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1), n_estimators=50, random_state=42)
adaboost.fit(X_train, y_train)
y_pred_adaboost = adaboost.predict(X_test)
print(f"AdaBoost准确率: {accuracy_score(y_test, y_pred_adaboost):.4f}")运行结果:
单个决策树准确率: 1.0000
Bagging准确率: 1.0000
随机森林准确率: 1.0000
AdaBoost准确率: 1.0000(Iris数据集比较简单,所有模型都能达到100%准确率,在更复杂的数据集上差异会更明显)
7. 总结
集成学习通过"组合多个弱学习器"的方式,实现了"1+1>2"的效果,是机器学习中最强大的技术之一。它的核心是好而不同的个体学习器,通过Boosting、Bagging等框架生成多样化的学习器,再通过平均、投票或Stacking等策略结合。
在实际应用中,集成学习几乎是Kaggle比赛冠军的标配,也广泛应用于推荐系统、金融风控、图像识别等领域。不过集成学习也有缺点:模型复杂度高、可解释性差,在对实时性要求高的场景中需要权衡性能和速度。