Redis 持久化深度解析:数据安全与性能的完美平衡
谁说内存数据库就一定"重启即丢"?Redis 用两大绝招打破你的刻板印象
你好,欢迎回来!
上两期我们聊了 Redis 的基本概念和命令,相信你已经能在命令行里行云流水地操作了。但有个灵魂拷问一直悬在头顶:Redis 数据都在内存里,那服务器一断电或者重启,数据岂不是全没了?
答案是:不会。至少,不会全丢。
今天我们就来深度剖析 Redis 的持久化机制------这层"保险"如何让 Redis 在享受内存速度的同时,还能把数据稳稳地落在硬盘上。
一、 为什么持久化如此重要?
先来看两个真实场景:
场景一:双十一零点,缓存击穿
Redis 里缓存了所有热门商品信息。凌晨 00:00:00,Redis 突然宕机。如果没有持久化,重启后缓存是空的。接下来的一秒钟,百万级的请求直接穿透到 MySQL------数据库瞬间被打死,整个网站崩溃。
场景二:服务器意外断电
你辛辛苦苦在 Redis 里存储了 10 万条用户 Session。凌晨机房的电闸跳了。重启 Redis 后,发现所有用户都被强制登出------因为 Session 全丢了。
持久化,就是 Redis 的"后悔药"。它让内存里的瞬时数据,变成硬盘上的永恒文件。
二、 Redis 持久化的两架马车
Redis 提供了两种持久化方案,就像汽车的手动挡和自动挡:
| 方案 | 别名 | 核心思想 | 数据安全性 | 性能影响 |
|---|---|---|---|---|
| RDB | 快照模式 | 定期拍照,保存当前状态 | 可能丢最后一次快照后的数据 | 小(fork 子进程) |
| AOF | 日志模式 | 记录每条写命令 | 最多丢 1 秒数据 | 较大(需要写日志) |
| 混合持久化 | Redis 4.0+ | RDB做全量 + AOF做增量 | 高 | 适中 |
最佳实践 :生产环境两者都开启 ,或者用混合持久化。小孩子才做选择,成年人全都要。
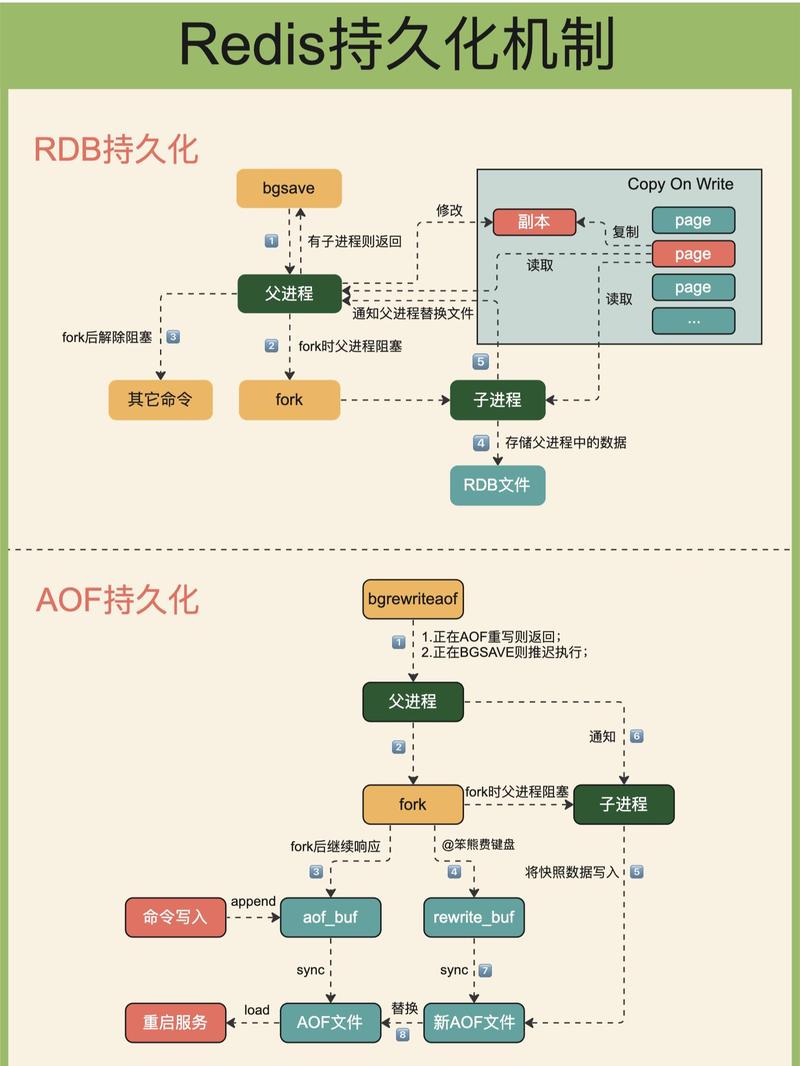
三、 RDB(Redis DataBase):简单粗暴的快照
3.1 原理是什么?
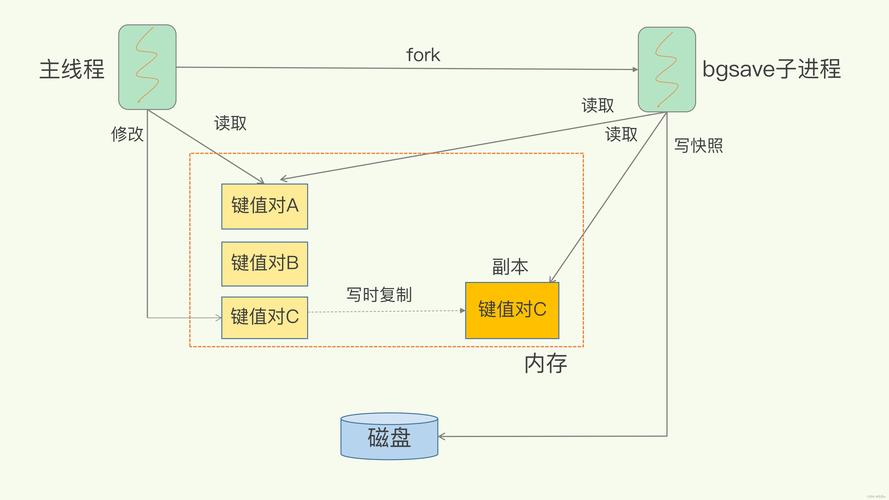
RDB 就像给你的数据拍照片 。在某个时间点,Redis 会把内存中的所有数据完整地写入一个二进制文件(dump.rdb)。
执行流程:
- Redis 调用
fork()创建一个子进程 - 父进程继续处理客户端请求
- 子进程负责把数据写入临时 RDB 文件
- 写入完成后,用临时文件替换旧文件
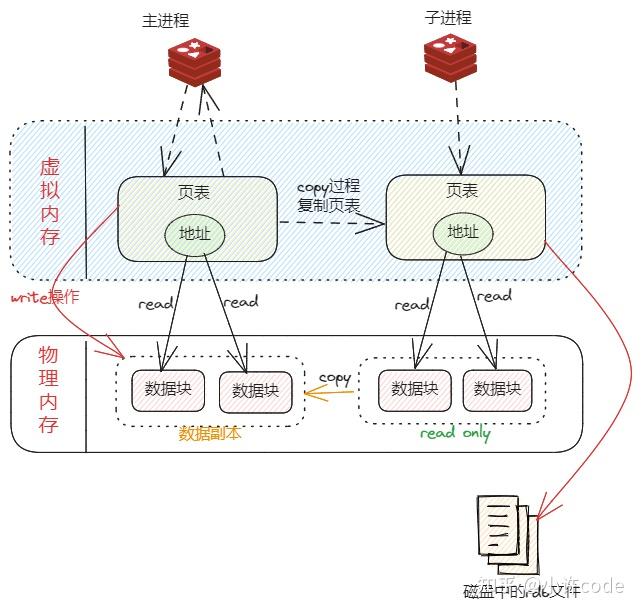
核心优势 :fork 利用了 Linux 的写时复制(Copy-On-Write) 技术。子进程和父进程共享同一份内存,只有当父进程修改数据时,才会复制被修改的那一页内存。因此 RDB 对性能影响很小。
3.2 如何配置?
在 redis.conf 中配置触发条件:
conf
# 格式:save <秒数> <修改次数>
# 以下条件满足任意一条,自动执行 BGSAVE
save 900 1 # 900秒(15分钟)内,至少有1个key被修改
save 300 10 # 300秒(5分钟)内,至少有10个key被修改
save 60 10000 # 60秒内,至少有10000个key被修改
# RDB 文件名
dbfilename dump.rdb
# RDB 文件存储路径
dir /var/lib/redis
# 开启压缩(默认开启,节约空间但消耗 CPU)
rdbcompression yes
# 开启 CRC64 校验(防止文件损坏)
rdbchecksum yes3.3 手动执行命令
bash
# 同步执行(阻塞主进程,生产环境禁用)
SAVE
# 异步执行(fork 子进程,推荐)
BGSAVE
# 查看最后一次 RDB 保存时间
LASTSAVE3.4 触发快照的方式
- 执行shutdown命令,会触发快照
- 执行flushall命令,会触发快照
- 手动执行save或者bgsave命令,会触发快照
- 在指定的时间间隔内,执行指定次数的写操作(自动触发)(两个条件要都成立)
3.5 优缺点分析
优点:
- ✅ 文件紧凑:二进制文件体积小,适合备份和跨版本迁移
- ✅ 恢复超快:直接加载 RDB 文件,比 AOF 重放快得多
- ✅ 性能好:fork 子进程,父进程几乎无阻塞
缺点:
- ❌ 可能丢数据:如果 Redis 在两次快照之间宕机,最后一次快照之后的写操作全部丢失
- ❌ fork 开销:当数据量很大(几十 GB)时,fork 可能卡顿几百毫秒甚至几秒
- ❌ 大数据量备份慢:全量快照,数据越大耗时越长
3.6 典型配置场景
conf
# 适用于:可以容忍丢失几分钟数据的场景
# 比如:缓存、排行榜、计数器等非核心数据
save 900 1
save 300 10
save 60 10000
# 关闭 RDB(如果你只想要 AOF)
save ""四、 AOF(Append Only File):滴水不漏的日志
4.1 原理是什么?
AOF 就像日记本 。你执行的每一条写命令,都会被追加到 AOF 文件末尾。
当 Redis 重启时,会重放(replay)AOF 文件中的所有命令,恢复数据。
执行流程:
- 客户端发送写命令(比如
SET name "Tom") - Redis 执行命令,修改内存数据
- Redis 把命令追加到 AOF 缓冲区
- 根据配置的策略,把缓冲区内容写入并同步到 AOF 文件
4.2 三种同步策略
这是 AOF 的核心配置,决定了性能与安全性的平衡:
conf
# redis.conf
# 策略1:每次写操作都同步(最安全,最慢)
appendfsync always
# 策略2:每秒同步一次(默认,推荐)
appendfsync everysec
# 策略3:由操作系统决定何时同步(最快,最不安全)
appendfsync no| 策略 | 数据安全性 | 性能 | 场景 |
|---|---|---|---|
always |
最多丢一条命令 | 极差(约 200 次写/秒) | 金融、银行 |
everysec |
最多丢 1 秒数据 | 良好(约 2-4 万次写/秒) | 大多数场景 |
no |
可能丢 30 秒以上 | 最快 | 可容忍丢失大量数据的场景 |
4.3 AOF 重写(Rewrite):解决文件无限膨胀
问题:AOF 记录了每一条命令。如果你对同一个 key 修改了 1000 次,AOF 文件里就有 1000 条命令,但恢复时只需要最后一条。
解决方案 :AOF 重写。Redis 会读取当前内存中的数据,生成最少量的命令集合,写入新的 AOF 文件,然后替换旧文件。
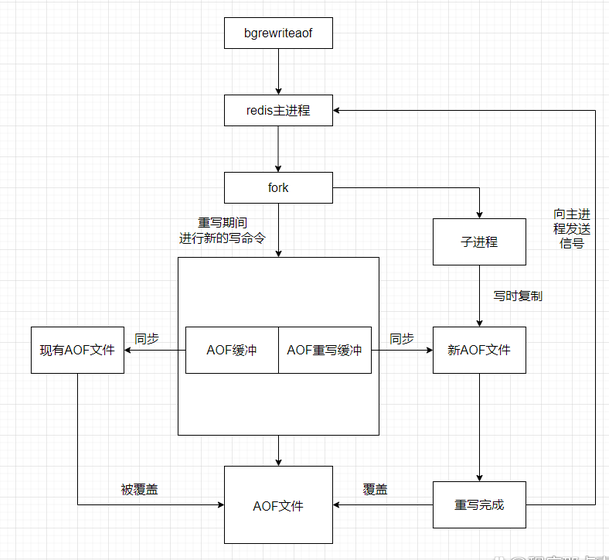
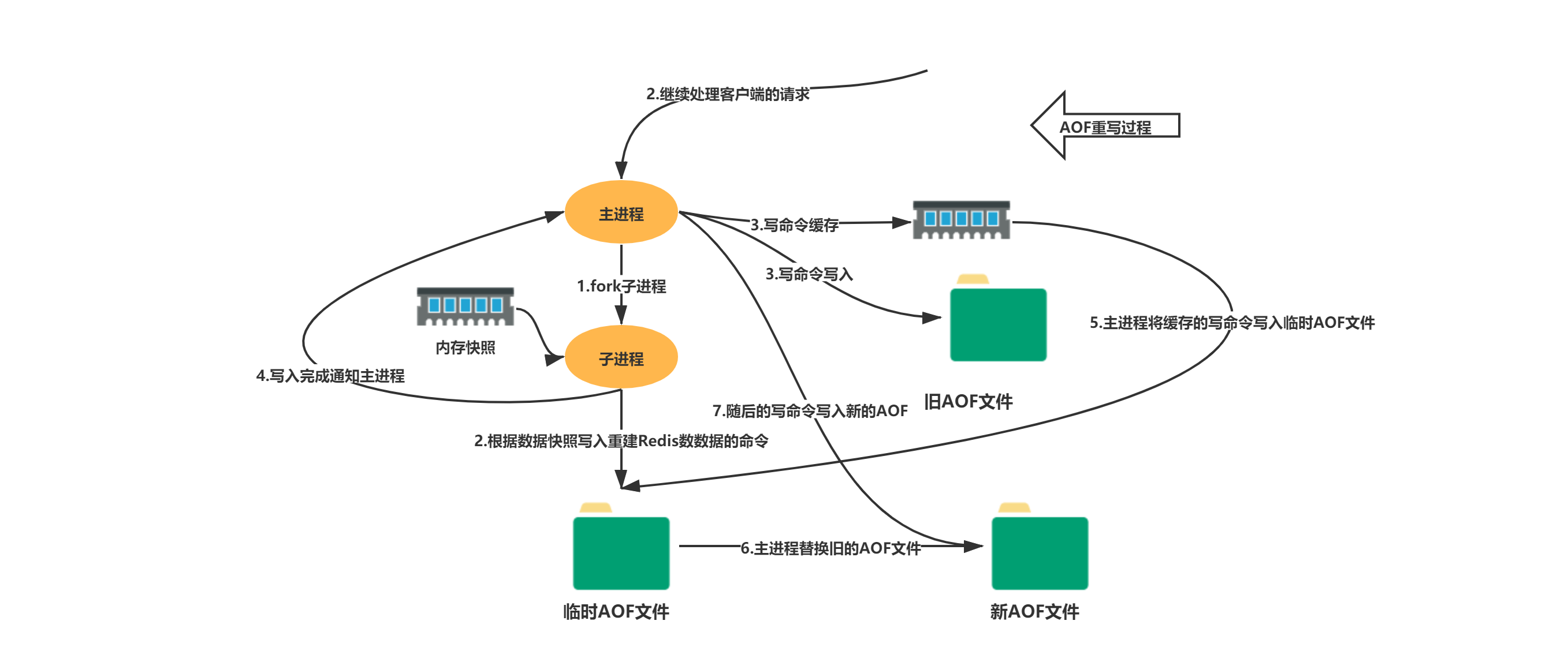
执行流程:
bash
# 手动触发 AOF 重写
BGREWRITEAOF
conf
# 自动触发配置
# 当 AOF 文件大小超过上次重写时大小的 100%(即翻倍)时触发
auto-aof-rewrite-percentage 100
# 只有当 AOF 文件大于 64MB 时才触发重写
auto-aof-rewrite-min-size 64mb举例:
- 初始 AOF 文件 100MB
- 当文件增长到 200MB(增长 100%)时,触发重写
- 重写后可能变成 50MB(因为合并了重复命令)
4.4 AOF 文件损坏修复
AOF 文件可能因为磁盘错误、断电等原因损坏。Redis 提供了修复工具:
bash
# 检查 AOF 文件并修复
redis-check-aof --fix appendonly.aof4.5 优缺点分析
优点:
- ✅ 数据安全性高 :
everysec最多丢 1 秒数据 - ✅ 可读性好 :AOF 文件是纯文本格式,可以
cat查看 - ✅ 文件自动修复 :
redis-check-aof可以修复损坏文件
缺点:
- ❌ 文件体积大:通常比 RDB 文件大好几倍
- ❌ 恢复速度慢:重放命令比直接加载 RDB 慢得多
- ❌ 性能开销大 :尤其是
always策略
五、 RDB vs AOF:正面交锋
| 维度 | RDB | AOF |
|---|---|---|
| 文件大小 | 小(二进制压缩) | 大(文本格式) |
| 恢复速度 | 快(直接加载) | 慢(重放命令) |
| 数据安全性 | 低(可能丢几分钟) | 高(最多丢 1 秒) |
| 性能影响 | 小(fork 子进程) | 中(需要写日志) |
| 可读性 | 差(二进制) | 好(纯文本) |
| 适用场景 | 备份、快速恢复 | 核心数据、不能丢数据 |
我的建议:
- 缓存场景:只用 RDB,丢了也不怕,数据库里有
- 核心数据:两者都开,或者用混合持久化
- 金融/支付 :AOF
always+ 主从备份 + 实时备份到其他存储
六、 混合持久化(Redis 4.0+):鱼与熊掌兼得
Redis 4.0 引入了混合持久化,结合了 RDB 和 AOF 的优点。
6.1 原理是什么?
在执行 AOF 重写时,Redis 不再只写 AOF 命令,而是:
- 先写 RDB 格式的数据:把当前内存数据以 RDB 格式写入 AOF 文件开头
- 再写 AOF 格式的增量:把重写期间新产生的写命令以 AOF 格式追加在后面
结果:AOF 文件 = RDB 头部 + AOF 尾部增量
6.2 如何开启?
conf
# redis.conf
# 开启混合持久化(需要同时开启 AOF)
aof-use-rdb-preamble yes6.3 为什么混合持久化更好?
重启恢复时:
- 先读取 RDB 头部,快速加载大部分数据
- 再重放 AOF 尾部增量命令
效果:
- 恢复速度接近 RDB(不用逐条重放所有命令)
- 数据安全性接近 AOF(最多丢 1 秒数据)
结论 :如果你的 Redis 版本 ≥ 4.0,强烈建议开启混合持久化。
七、 持久化性能优化实战
7.1 fork 耗时过长怎么办?
问题 :当 Redis 内存达到 20GB+ 时,fork() 可能耗时 1-3 秒,导致服务抖动。
解决方案:
-
降低内存使用:用集群分片,单实例 ≤ 10GB
-
调整 Linux 内核参数 :
bash# 允许进程快速 fork echo 1 > /proc/sys/vm/overcommit_memory # 关闭透明大页(THP),避免写时复制性能下降 echo never > /sys/kernel/mm/transparent_hugepage/enabled -
更换更快的存储:用 NVMe SSD 替代机械硬盘
7.2 AOF 同步磁盘太慢怎么办?
问题 :appendfsync always 模式下,每次写操作都要 fsync,性能暴跌。
解决方案:
- 换
everysec策略,最多丢 1 秒数据 - 用更快的磁盘(SSD)
- 把 AOF 文件放到单独的磁盘上,避免与 RDB 或日志争抢 IO
7.3 主从复制的持久化策略
conf
# 在从库上开启 AOF(主库可以不开启,减轻压力)
# 从库重启时,从 AOF 快速恢复,然后继续从主库同步八、 实际配置模板
8.1 场景一:缓存 + 排行榜(允许丢一点数据)
conf
# 只用 RDB,不开 AOF
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir /var/lib/redis
rdbcompression yes8.2 场景二:核心业务(如用户 Session、交易记录)
conf
# RDB + AOF 都开,混合持久化
save 900 1
save 300 10
appendonly yes
appendfsync everysec
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-use-rdb-preamble yes
dir /var/lib/redis8.3 场景三:极致性能,完全不关心丢数据
conf
# 不开持久化,纯内存
save ""
appendonly no
# 或者用 AOF no 策略
appendfsync no九、 常见面试题
Q1:Redis 宕机后如何恢复数据?
A:重启 Redis 后,如果开启了 AOF,优先加载 AOF 文件;如果只开了 RDB,加载 RDB 文件。如果两者都开,加载 AOF(因为 AOF 数据更完整)。
Q2:SAVE 和 BGSAVE 有什么区别?
A:SAVE 是同步的,会阻塞所有客户端请求;BGSAVE 是异步的,fork 子进程执行,主进程继续服务。
Q3:AOF 重写期间还能处理请求吗?
A:能。Redis 会把重写期间的新命令同时写到旧的 AOF 缓冲区和重写缓冲区,重写完成后,再把重写缓冲区的命令追加到新 AOF 文件末尾。
Q4:RDB 和 AOF 能同时关闭吗?
A:能。但 Redis 就变成了纯内存数据库,重启后数据全丢。仅限纯缓存场景。
十、 写在最后
持久化是 Redis 生产环境绕不开的话题。
- RDB 是你的"后悔药",适合备份和快速恢复
- AOF 是你的"行车记录仪",让你能追查到每一笔操作
- 混合持久化 是鱼与熊掌兼得的"终极方案"
给新手的建议:
- 开发测试环境:不开持久化,无所谓
- 小规模生产(内存 < 4GB):开 AOF
everysec就够了 - 大规模生产(内存 > 10GB):主库用 RDB,从库开混合持久化
- 无论什么配置,定期把 RDB/AOF 文件备份到其他机器!
下一期预告:Redis 主从复制与哨兵模式------高可用实战。我们聊聊如何让 Redis 从单机到集群,自动故障转移,永不宕机。
数据安全无小事,持久化要趁早。下期见!